[docker/大數據]Spark快速入門

1. 概述
1.1 誕生背景
Spark官方文檔:https://spark.apache.ac.cn/docs/latest/
Spark 由加州大學伯克利分校 AMP 實驗室于 2009 年開發,2013 年成為 Apache 頂級項目,旨在解決 MapReduce 的三大核心問題:
- 功能局限:僅支持 Map 和 Reduce 兩種操作,難以處理復雜計算
- 執行效率低:頻繁的磁盤 I/O 操作導致性能瓶頸
- 生態割裂:需要與 Storm/Hive/HBase 等組件組合才能完成完整數據處理流程
1.2 核心特點
| 特點 | 說明 | 優勢 |
|---|---|---|
| 極速處理 | 內存計算比 MapReduce 快 10-100 倍 | 實時分析能力 |
| All-in-One | 統一引擎支持多種計算范式 | 簡化技術棧 |
| 易用性 | 支持 Scala/Java/Python/R/SQL | 開發者友好 |
| 容錯性 | RDD 機制保障故障恢復 | 高可靠性 |
2. 核心概念
2.1 核心組件
Spark Core主要包含四大模塊:Spark SQL(結構化數據處理)、Spark Streaming(流批次處理)、MLib(機器學習庫)、GraphX(圖計算模塊)
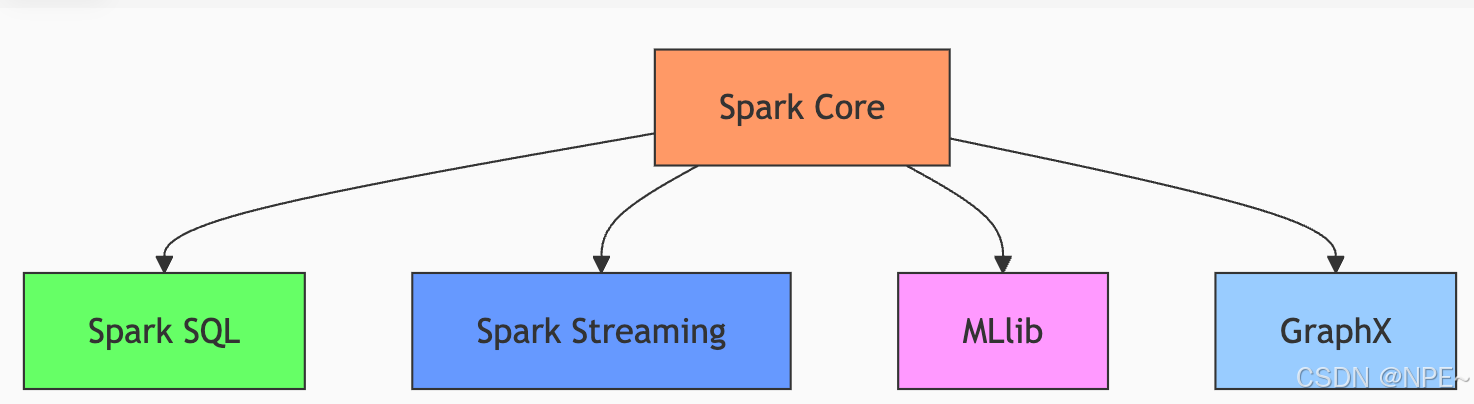
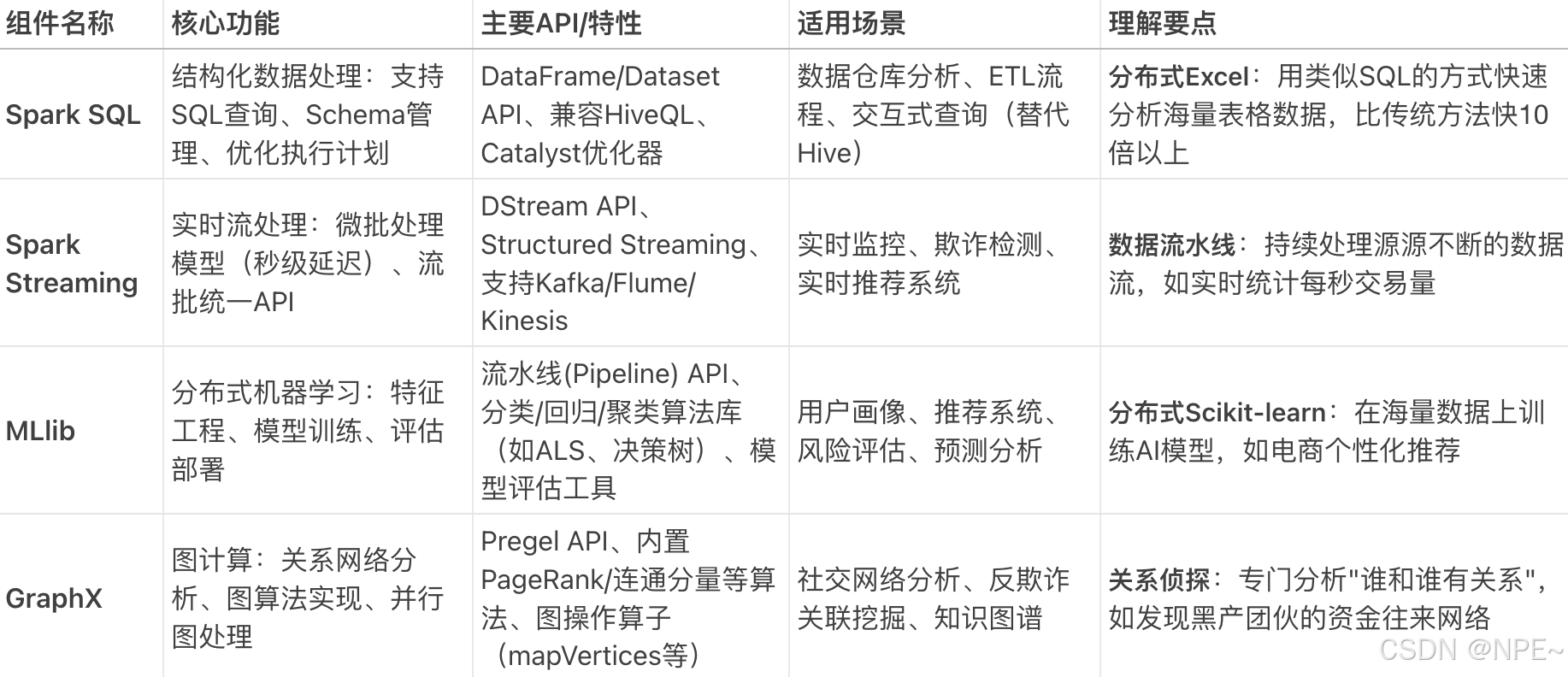
案例:比如我們要基于用戶行為日志進行分析,下面是各組件的分工:

- Streaming:實時接收用戶點擊/購買數據流
- SQL:將數據轉為結構化表格,存儲到數據倉庫
- MLlib:基于歷史數據訓練"看了又看"推薦模型
- GraphX:分析用戶間的設備/IP關聯,識別刷單團伙
- Core:底層支撐所有組件的分布式運行
2.2 RDD分布式數據集
RDD是Spark 最核心、最根本的數據抽象。如果說Spark是一個巨大的數據工廠,那么RDD就是工廠流水線上的一個個原材料零件、半成品。
2.2.1 特點
RDD(Resilient Distributed Dataset )彈性分布式數據集特點:
| 特性 | 說明 | 優勢 |
|---|---|---|
| 分布式 | 數據分區存儲在集群節點 | 并行處理 |
| 彈性 | 支持高效故障恢復 | 容錯性強 |
| 不可變 | 只讀數據集 | 避免并發問題 |
| 延遲計算 | 操作按需執行 | 優化執行計劃 |
1.分布式:
- 概念:你的數據量非常大,一臺機器存不下、算不動。RDD 會把數據自動切割成很多份(Partitions/分區),分散存儲在集群的多個機器上
- 類比: 一本1000頁的巨著,分給10個人一起讀,每人讀100頁。這10個人就是一個“集群”,每個人手里的100頁就是一個“分區”。
- 好處: 并行計算,速度極快。
2.數據集:
- 概念:表示是數據的集合。RDD 里面可以存儲任何類型的數據,比如數字、字符串、對象等。
- 類比: 上面例子中,書里的文字內容就是“數據”。
3.彈性:
- 概念:有容錯性,當有數據丟失時可以快速恢復數據,這也是 Spark 比 Hadoop MapReduce 快的關鍵原因,例如:集群中某個機器突然宕機了,它上面存儲的那個數據分片(那100頁書)丟了怎么辦?傳統方法需要從頭重新計算。Spark的解決方案: RDD 記錄了自己是如何從其他數據“計算”過來的(例如: “我是通過A文件經過filter操作再經過map操作得到的”)。這個記錄叫做血統(Lineage)。
- 類比: 讀第3章需要先讀第1章和第2章。如果某人手里的第2章丟了,我們不需要從頭開始寫書,只需要根據“依賴關系”(血統),讓他去找有第1章的人,重新讀一遍第1章,然后自己再推導出第2章即可。
- 好處: 快速恢復數據,無需昂貴的數據復制備份。
2.2.2 RDD操作類型
RDD(Resilient Distributed Dataset )又稱彈性分布式數據集,操作主要包含兩類:Transformation和Action。
①Transformation(轉換,只做規劃):主要是規劃;它會定義一個新的 RDD 是如何從現有的 RDD 計算過來的操作。它不會立即執行計算,只是在記錄一個計算邏輯,而不是真正去算。
- map(): 對數據集中每個元素都執行一個函數。(例如:把每一行文字都變成大寫)
- filter(): 過濾掉不符合條件的元素。(例如:篩選出所有包含“錯誤”關鍵詞的日志行)
- groupByKey(): 對鍵值對數據按鍵進行分組。
- reduceByKey(): 對每個鍵對應的值進行聚合計算。
類比: 廚師拿到菜譜,菜譜上寫著“1. 洗菜,2. 切菜,3. 炒菜”。此刻廚師只是在看菜譜,還沒開始動手做。菜譜就是一系列的 Transformation。
②Action(動作,觸發實際計算):實際計算;觸發實際計算,并返回結果給 Driver 程序或存儲到外部系統的操作。
- take(n): 取前n個元素。
- saveAsTextFile(path): 將數據集保存到文件系統(如HDFS)。
類比:顧客說“老板,上菜!”。這時廚師才真正開始執行菜譜上的所有步驟(洗、切、炒)。這句“上菜”就是 Action。
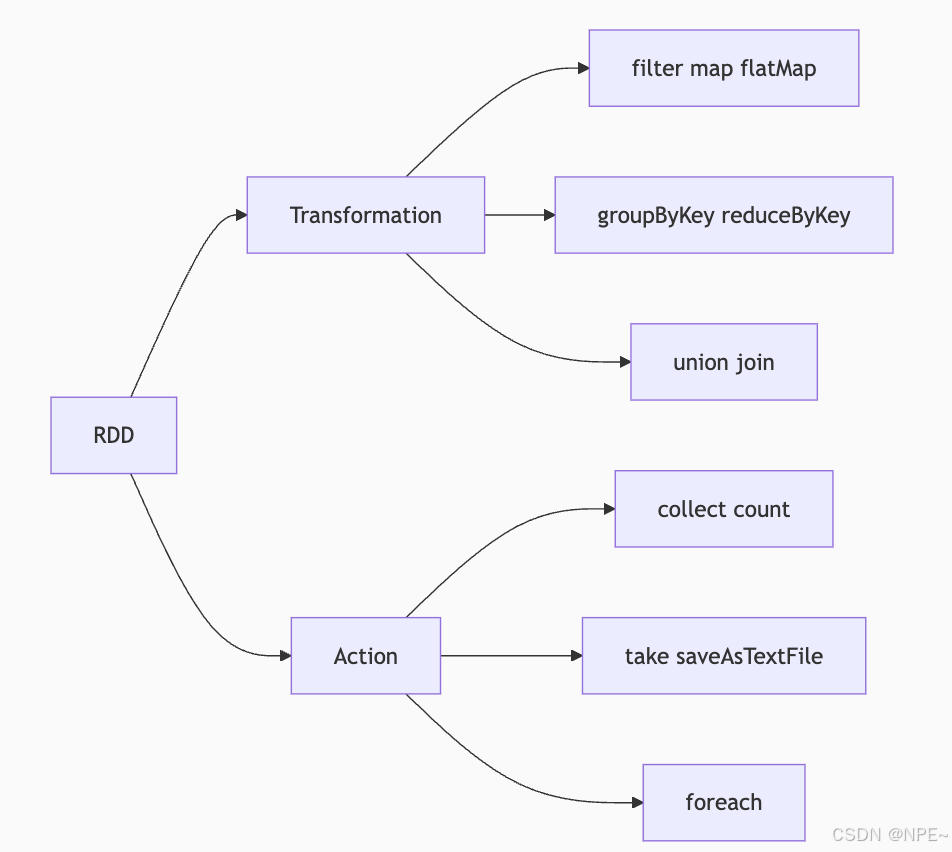
Spark計算核心流程:定義Transformations -> 最后調用Action -> Spark生成執行計劃 -> 分布式計算 -> 返回結果。
Q:為什么Spark需要惰性計算,即先規劃,后計算?
A:Spark可以在看到所有“計劃”(Transformation鏈)和一個最終“目標”(Action)后,對整個計算過程進行整體優化(比如合并一些操作),然后再執行,這樣效率更高。
2.2.3 RDD依賴關系(寬窄依賴)
概念:一個 RDD 是由另一個或多個 RDD 通過 Transformation 計算得來的。這種“父子關系”就是依賴關系。
Spark 需要記錄這種關系(即血統 Lineage),目的有兩個:
- 容錯:如果某個分區的數據丟了,可以根據血統關系重新計算。
- 任務調度:根據依賴類型來規劃最有效的執行方式(這導致了 Stage 的劃分)。
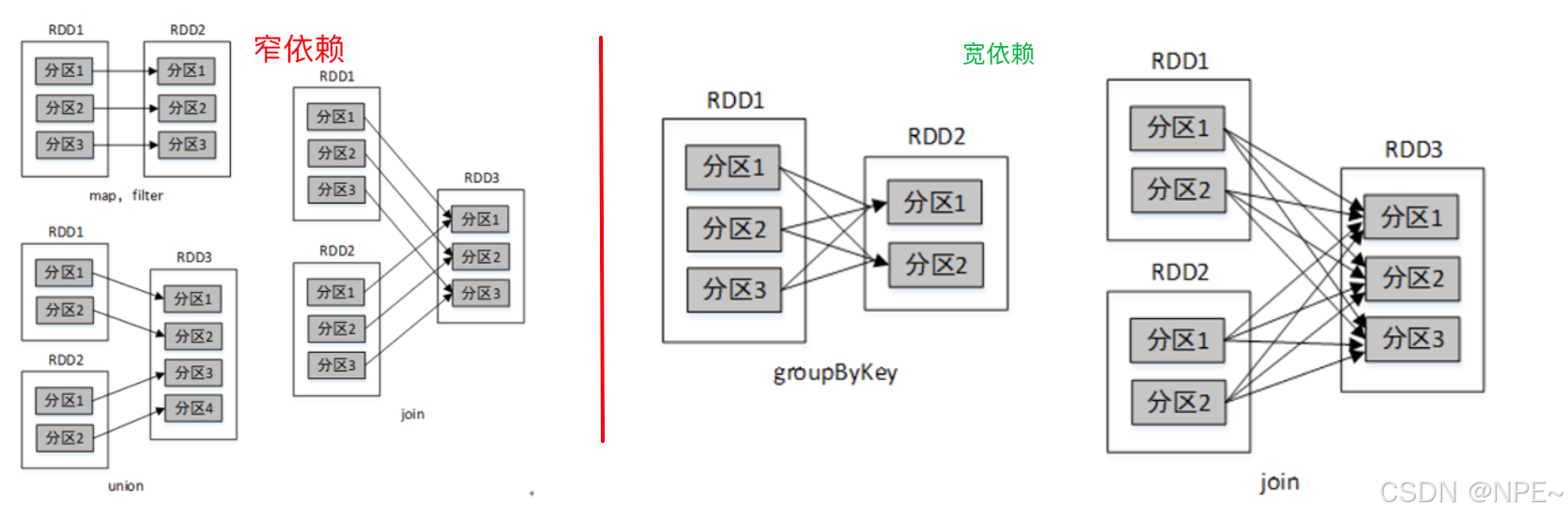
RDD的依賴關系分為兩種:窄依賴(Narrow Dependency) 和 寬依賴(Wide Dependency / Shuffle Dependency):
1. 窄依賴(窄關系):
- 一對一:父 RDD 的每一個分區最多被子 RDD 的一個分區所使用。像一對一的護送,數據不需要在不同機器間移動(無需 Shuffle)。即:上游的RDD數據最多只會流到下游的一個RDD中,一對一的關系。
- 比如:map()、filter()、union() 這些
2. 寬依賴(寬關系):
- 一對多:父RDD的一個分區被子RDD的多個分區所用。即:上游的RDD數據會流向下游多個RDD
- 比如:groupByKey()、reduceByKey()、sortByKey()這些
2.3 Spark 運行詳解
2.3.1 運行架構
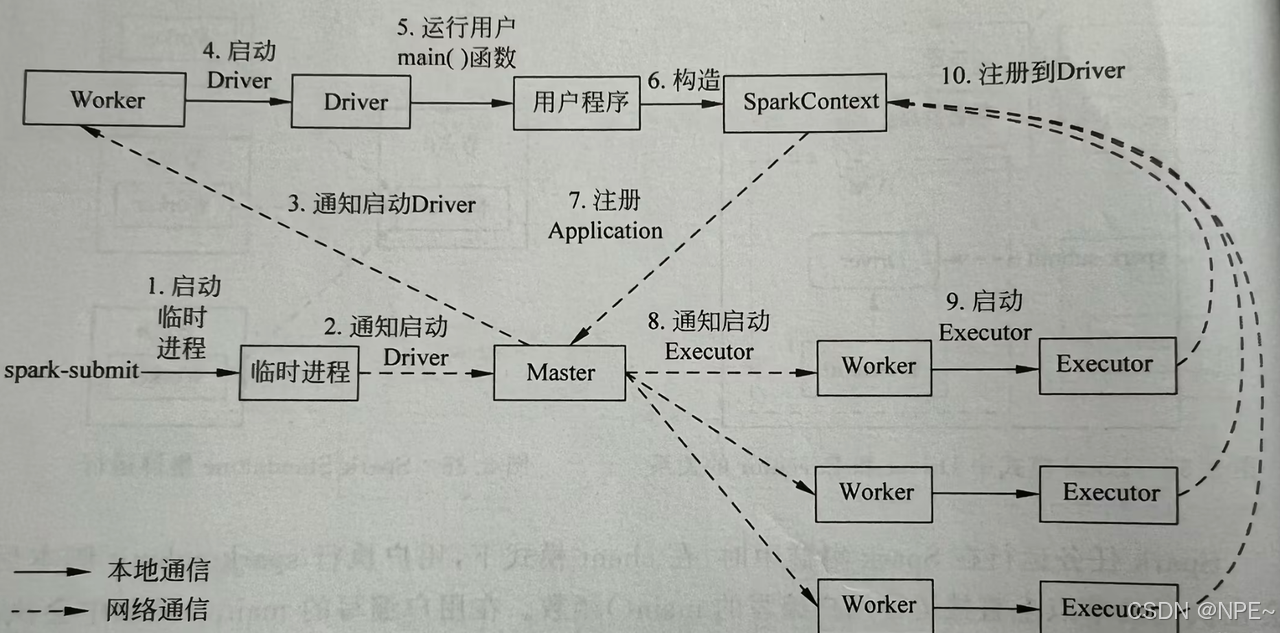
Spark應用程序以進程集合為單位在分布式集群上運行,通過driver程序的main方法創建的SparkContext對象與集群交互。
1、Spark通過SparkContext向Cluster manager(資源管理器)申請所需執行的資源(cpu、內存等)
2、Cluster manager分配應用程序執行需要的資源,在Worker節點上創建Executor
3、SparkContext 將程序代碼(jar包或者python文件)和Task任務發送給Executor執行,并收集結果給Driver。
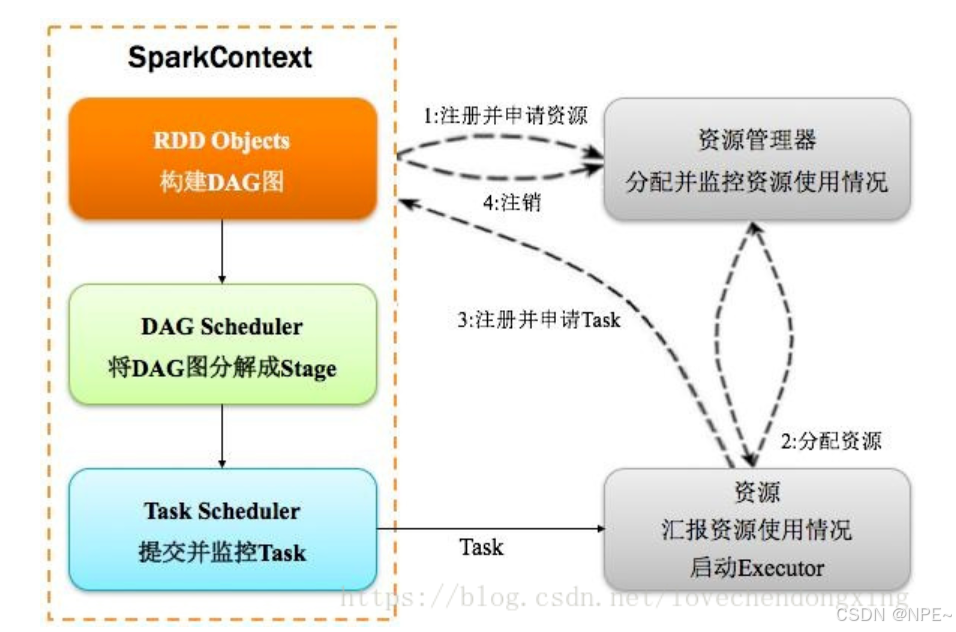
2.3.2 運行流程
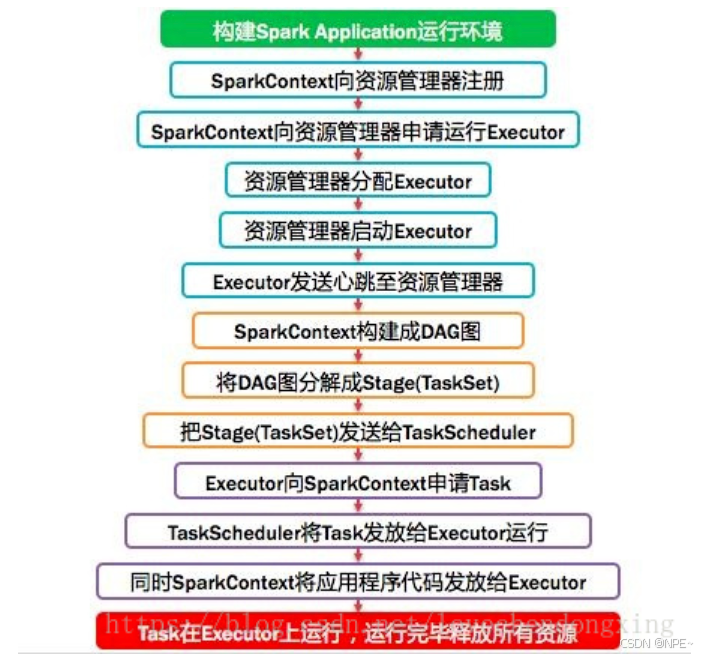
2.3.3 功能介紹
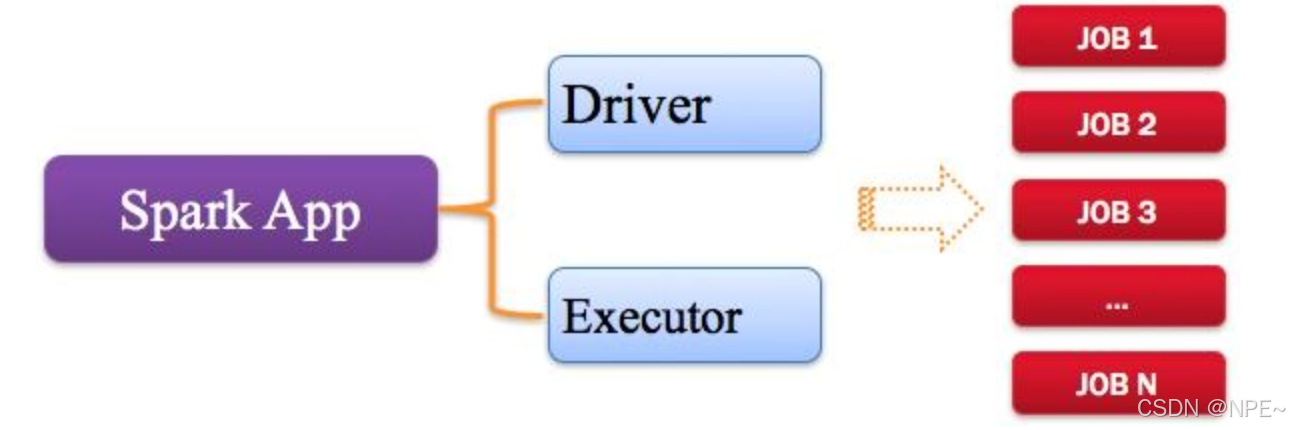
1. Application[用戶編寫的應用程序]
指的是用戶編寫的Spark應用程序,包含了Driver功能代碼和分布在集群中多個節點上運行的Executor代碼。
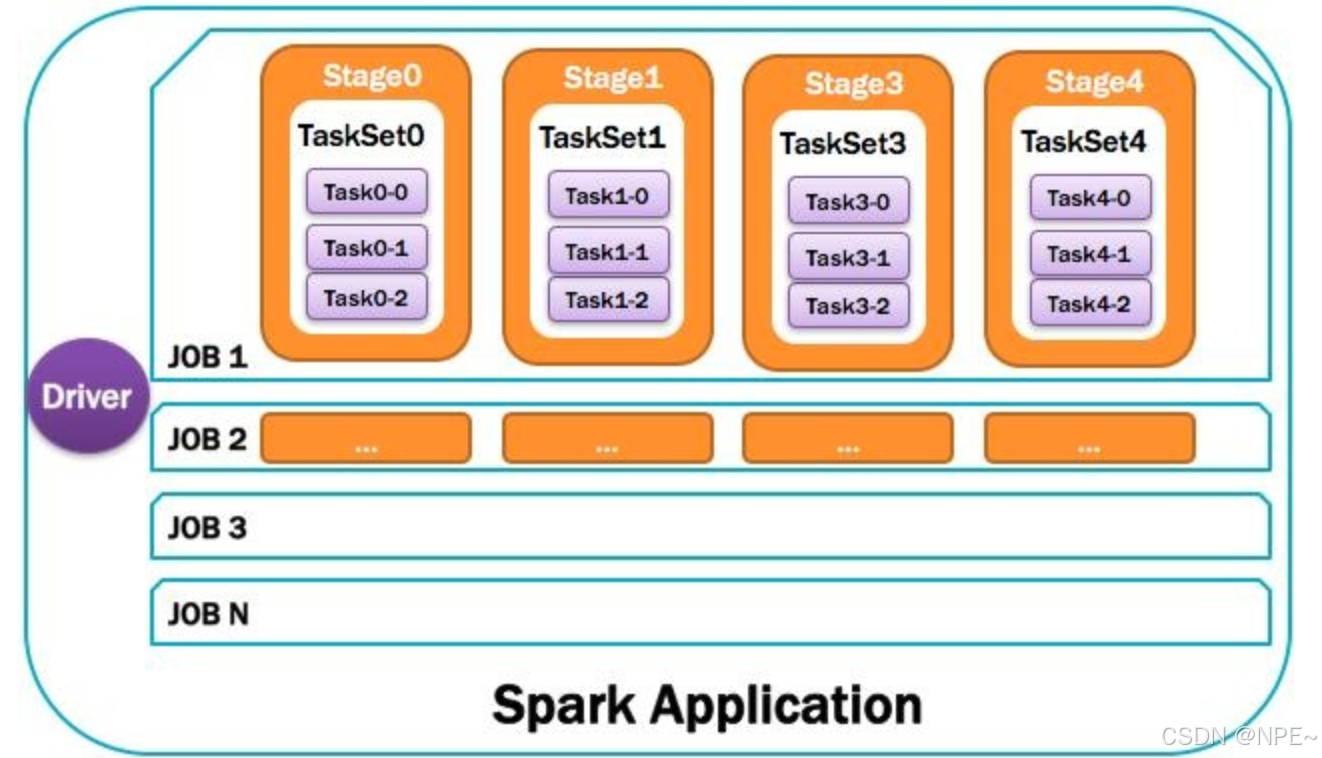
Spark應用程序,由一個或多個作業JOB組成,如下圖所示。
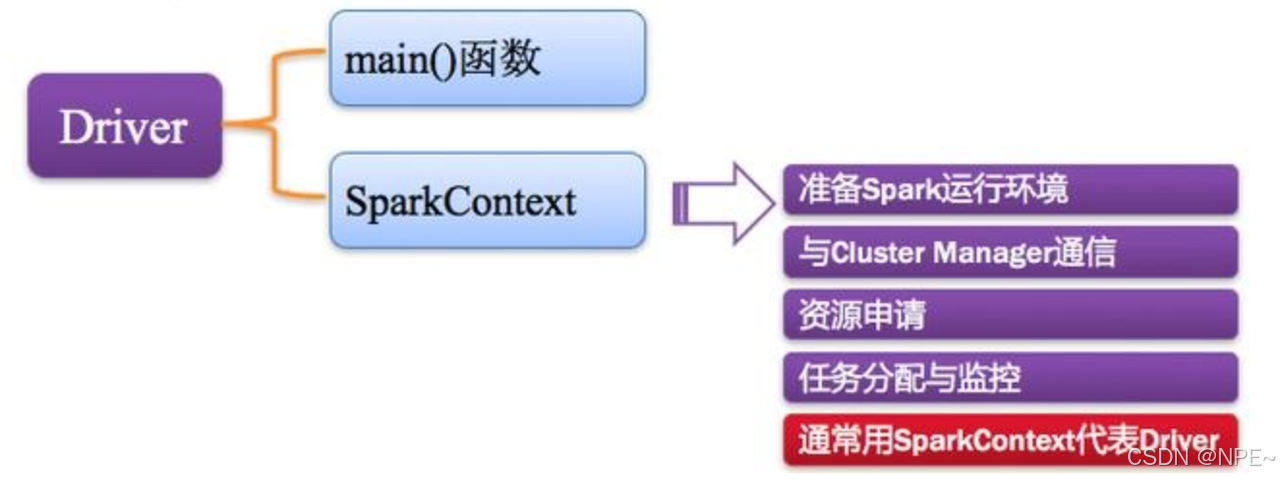
2. Driver:驅動程序
Spark中的Driver即運行上述Application的Main()函數并且創建SparkContext,其中創建SparkContext的目的是為了準備Spark應用程序的運行環境。在Spark中由SparkContext負責和ClusterManager通信,進行資源的申請、任務的分配和監控等;
當Executor部分運行完畢后,Driver負責將SparkContext關閉。通常SparkContext代表Driver,如下圖所示。
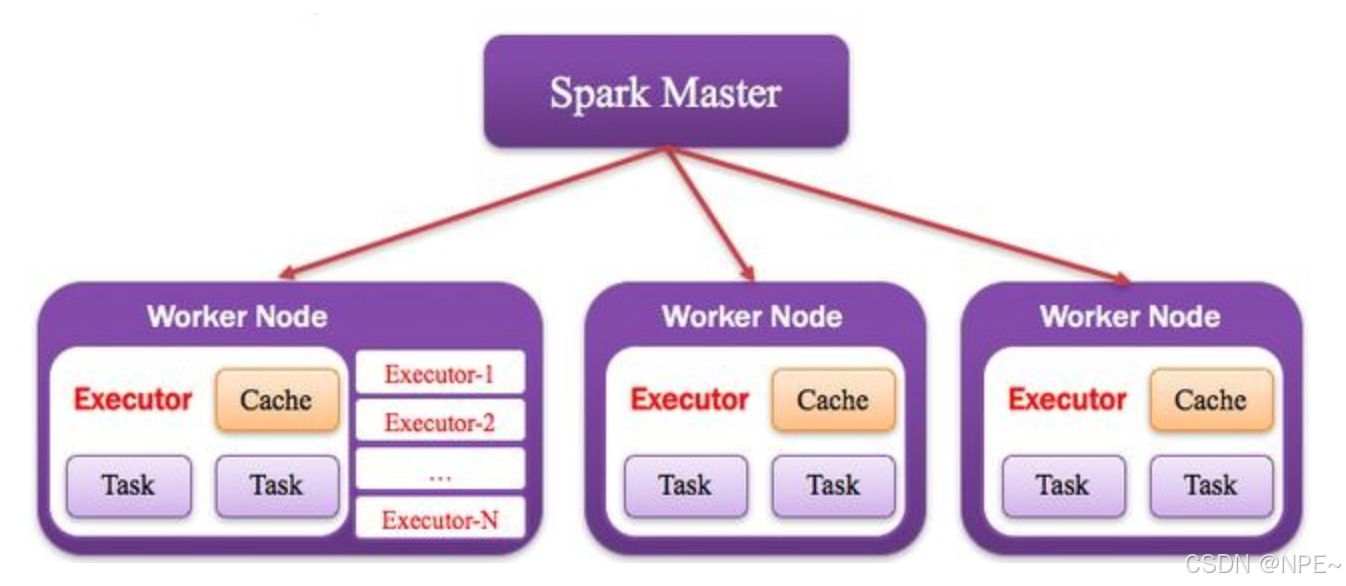
3. Cluster Manager:資源管理器
指的是在集群上獲取資源的外部服務,常用的有:Standalone,Spark原生的資源管理器,由Master負責資源的分配;Haddop Yarn,由Yarn中的ResearchManager負責資源的分配;Messos,由Messos中的Messos Master負責資源管理。
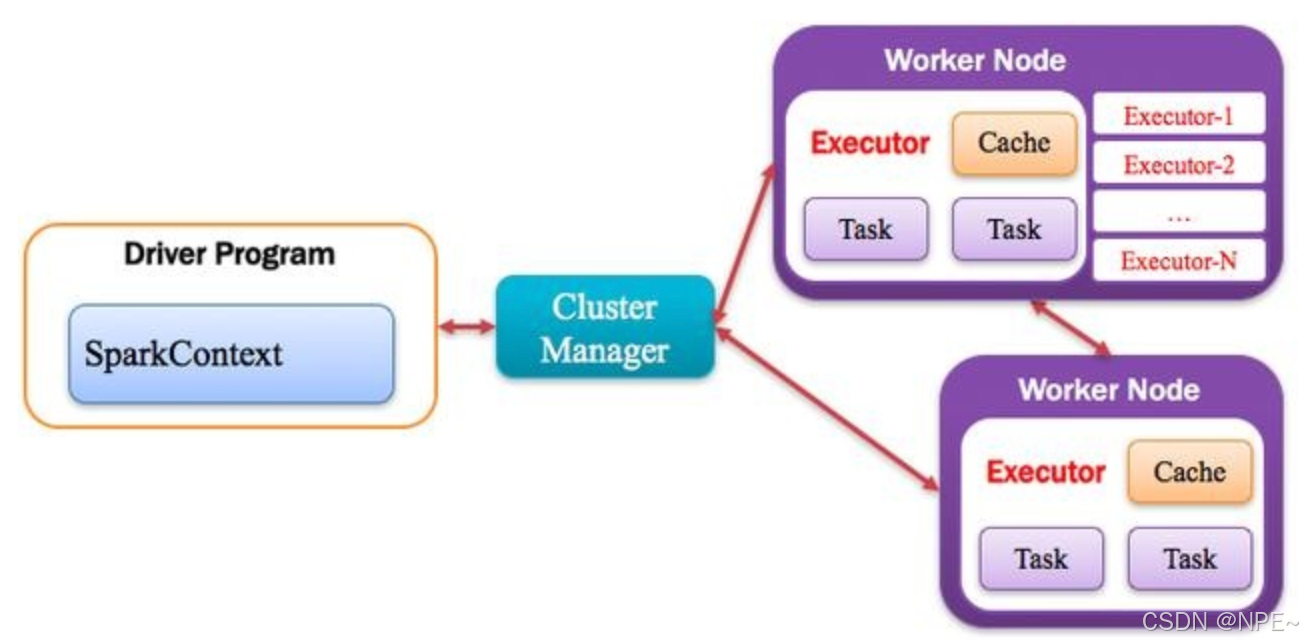
4. Executor:執行器
Application運行在Worker節點上的一個進程,該進程負責運行Task,并且負責將數據存在內存或者磁盤上,每個Application都有各自獨立的一批Executor,如下圖所示。
5. Worker:計算節點
集群中任何可以運行Application代碼的節點,類似于Yarn中的NodeManager節點。在Standalone模式中指的就是通過Slave文件配置的Worker節點,在Spark on Yarn模式中指的就是NodeManager節點,在Spark on Messos模式中指的就是Messos Slave節點,如下圖所示。
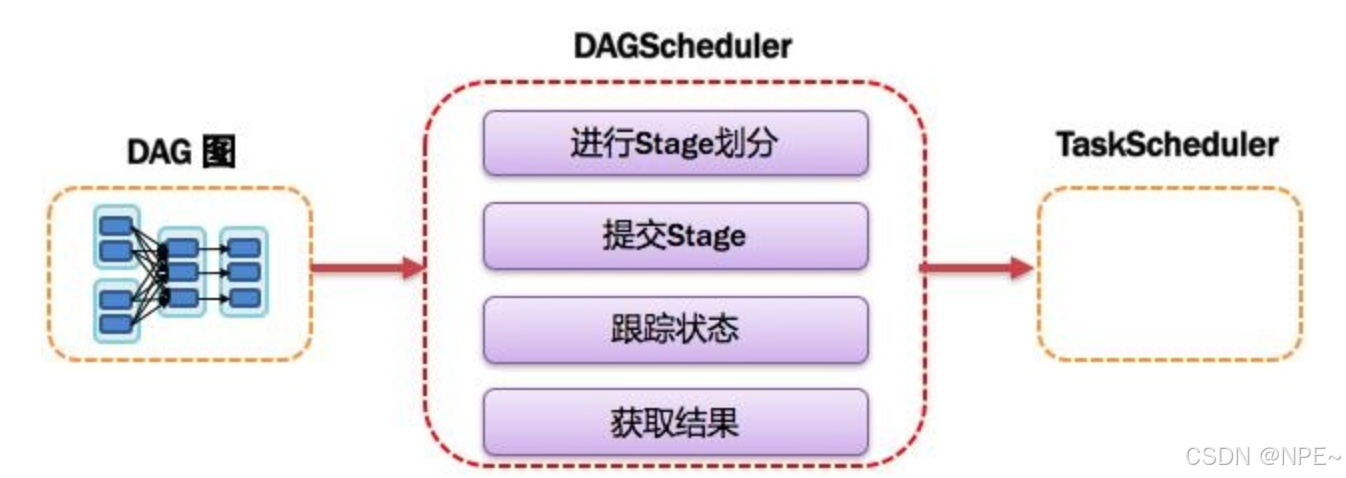
6. DAGScheduler:有向無環圖調度器
基于DAG劃分Stage 并以TaskSet的形式提交Stage給TaskScheduler;負責將作業拆分成不同階段的具有依賴關系的多批任務;最重要的任務之一就是:計算作業和任務的依賴關系,制定調度邏輯。在SparkContext初始化的過程中被實例化,一個SparkContext對應創建一個DAGScheduler。
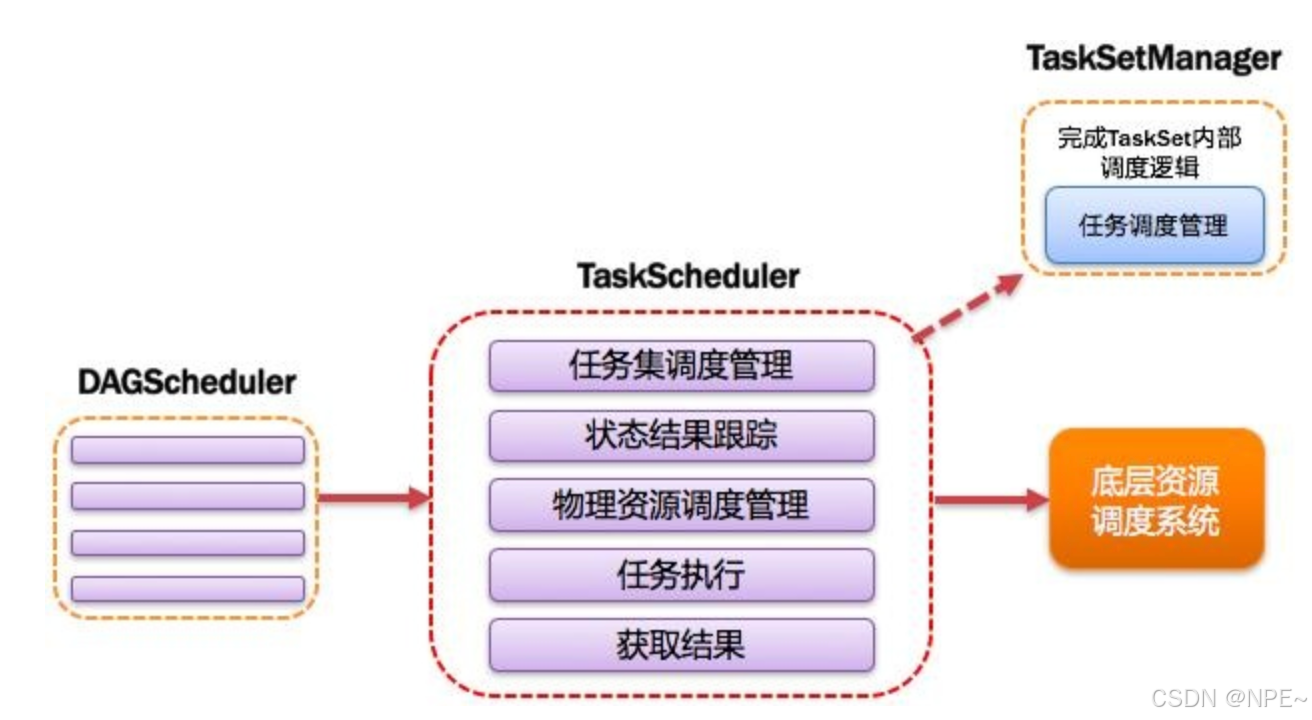
7. TaskScheduler:任務調度器
將Taskset提交給worker(集群)運行并回報結果;負責每個具體任務的實際物理調度。如圖所示。
8. Job:作業
由一個或多個調度階段所組成的一次計算作業;包含多個Task組成的并行計算,往往由Spark Action催生,一個JOB包含多個RDD及作用于相應RDD上的各種Operation。如圖所示。
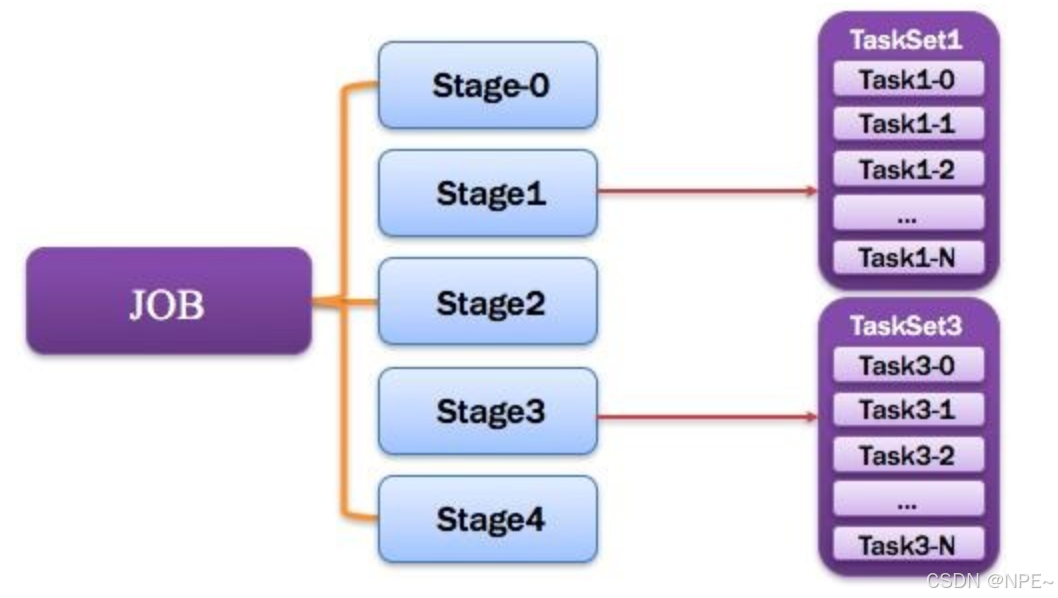
9. Stage:調度階段
一個任務集對應的調度階段;每個Job會被拆分很多組Task,每組任務被稱為Stage,也可稱TaskSet,一個作業分為多個階段;Stage分成兩種類型ShuffleMapStage、ResultStage。如圖所示。
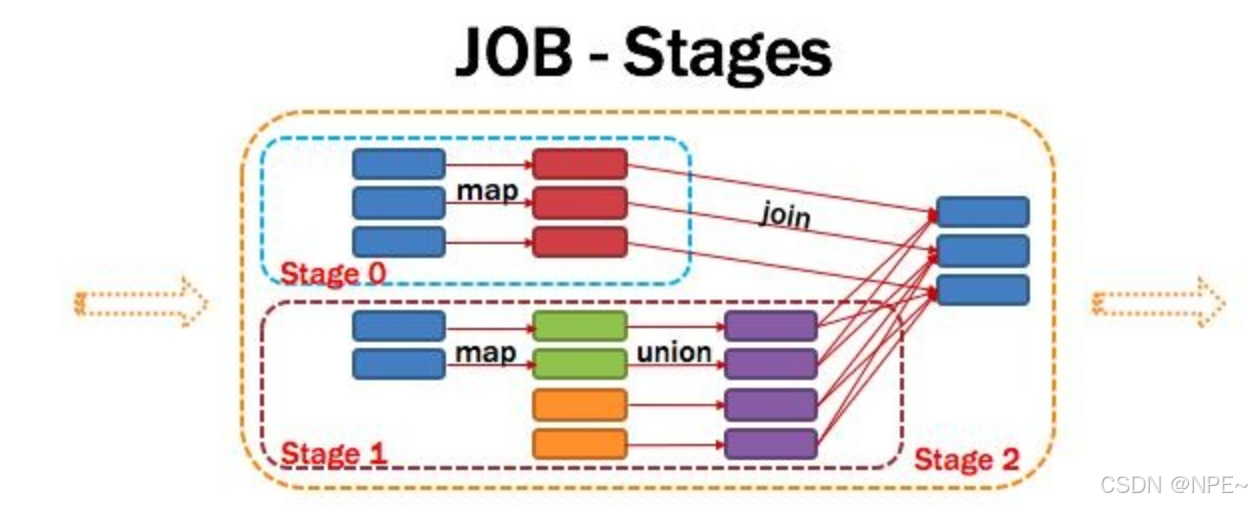
Application多個job多個Stage:Spark Application中可以因為不同的Action觸發眾多的job,一個Application中可以有很多的job,每個job是由一個或者多個Stage構成的,后面的Stage依賴于前面的Stage,也就是說只有前面依賴的Stage計算完畢后,后面的Stage才會運行。
劃分依據:Stage劃分的依據就是寬依賴,何時產生寬依賴,reduceByKey, groupByKey等算子,會導致寬依賴的產生。
核心算法:從后往前回溯,遇到窄依賴加入本stage,遇見寬依賴進行Stage切分。Spark內核會從觸發Action操作的那個RDD開始從后往前推,首先會為最后一個RDD創建一個stage,然后繼續倒推,如果發現對某個RDD是寬依賴,那么就會將寬依賴的那個RDD創建一個新的stage,那個RDD就是新的stage的最后一個RDD。然后依次類推,繼續繼續倒推,根據窄依賴或者寬依賴進行stage的劃分,直到所有的RDD全部遍歷完成為止。
將DAG劃分為Stage剖析:如上圖,從HDFS中讀入數據生成3個不同的RDD,通過一系列transformation操作后再將計算結果保存回HDFS。可以看到這個DAG中只有join操作是一個寬依賴,Spark內核會以此為邊界將其前后劃分成不同的Stage. 同時我們可以注意到,在圖中Stage2中,從map到union都是窄依賴,這兩步操作可以形成一個流水線操作,通過map操作生成的partition可以不用等待整個RDD計算結束,而是繼續進行union操作,這樣大大提高了計算的效率。
10. TaskSet:任務集
由一組關聯的,但相互之間沒有Shuffle依賴關系的任務所組成的任務集。如圖所示。
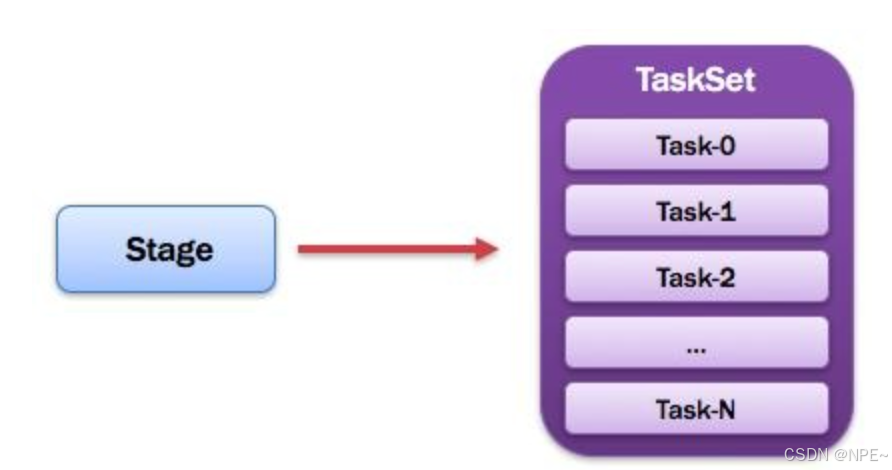
PS:
1)一個Stage創建一個TaskSet;
2)為Stage的每個Rdd分區創建一個Task,多個Task封裝成TaskSet
11. Task:任務
被送到某個Executor上的工作任務;單個分區數據集上的最小處理流程單元(單個stage內部根據操作數據的分區數劃分成多個task)。如圖所示。
總體如圖所示:
2.4 Spark 運行模式
Spark主要分為以下幾種運行模式:
- 本地模式;
- standalone模式;
- spark on yarn 模式,又細分為兩種子模式:yarn-client和yarn-cluster;
- spark on mesos 模式
- spark on cloud 模式
本文主要介紹前四種模式。
| 運行模式 | 資源管理者 | 核心特點 | 主要應用場景 |
|---|---|---|---|
| 本地模式 | 本地JVM | 單機多線程模擬分布式計算,簡單易用 | 開發、測試、學習 |
| Standalone模式 | Spark自帶Master | Spark自帶的獨立集群模式,無需依賴其他資源管理系統 | 中小規模Spark專屬集群 |
| Spark on YARN | Hadoop YARN | 利用Hadoop YARN進行資源調度,與Hadoop生態集成緊密,生產環境最常用 | 共享Hadoop集群的大規模生產環境 |
| Spark on Mesos | Apache Mesos | 更靈活的通用集群管理,支持細粒度調度(但細粒度模式已被棄用) | 混合負載集群(如同時運行Spark、MPI等) |
本地模式
概念:Spark不一定非要跑在hadoop集群,可以在本地,起多個線程的方式來指定。將Spark應用以多線程的方式直接運行在本地,一般都是為了方便調試,本地模式分三類
- local:只啟動一個executor
- local[k]:啟動k個executor
- local[*]:啟動跟cpu數目相同的executor
應用場景:一般用于開發測試。
執行流程:以 local[2] 為例
- 在IDE或Spark Shell中提交應用程序。
- Spark會在本地啟動一個JVM進程,這個進程既充當Driver(指揮者),又充當Executor(工作者)。
- Driver會創建 SparkContext,并初始化調度器(如 TaskScheduler)。
- SparkContext 會啟動指定數量(此處為2個)的線程作為執行線程(Executor threads)。
- 所有的任務(Tasks)會在這2個線程中并行執行。
- 任務執行完畢后,結果返回到Driver,或寫入本地文件系統。
Standalone模式
概念:它是一個主從式架構,包含Master(主節點)和Worker(從節點)。Master負責管理整個集群的資源,Worker負責在節點上啟動Executor進程來執行具體任務。
應用場景:適用于中小規模的、專用的Spark集群。如果你不想依賴Hadoop YARN等其他資源管理系統,希望Spark獨享集群資源,那么可以選擇Standalone模式。
運行流程:
- 啟動集群:事先在集群的每個節點上啟動Spark的Master和Worker守護進程。
- 提交應用:用戶通過spark-submit腳本或代碼向Master提交應用程序。
- 資源申請:應用程序中的SparkContext向Master注冊并申請資源(CPU和內存)。
- 啟動Executor:Master根據Worker的心跳報告(匯報自身資源情況),在資源充足的Worker節點上啟動Executor進程。
- 任務調度與執行:
- Executor啟動后,會向SparkContext反向注冊。
- SparkContext將應用程序代碼(JAR包或Python文件)發送給Executor。
- SparkContext根據程序中的RDD操作構建DAG圖,并由DAGScheduler將其劃分為Stage,再由TaskScheduler將每個Stage轉化為一批Task,然后分發到各個Executor上執行。
- 結果與釋放:Task執行完畢后,將結果返回給Driver或寫入外部存儲。所有任務完成后,SparkContext向Master注銷,釋放資源。
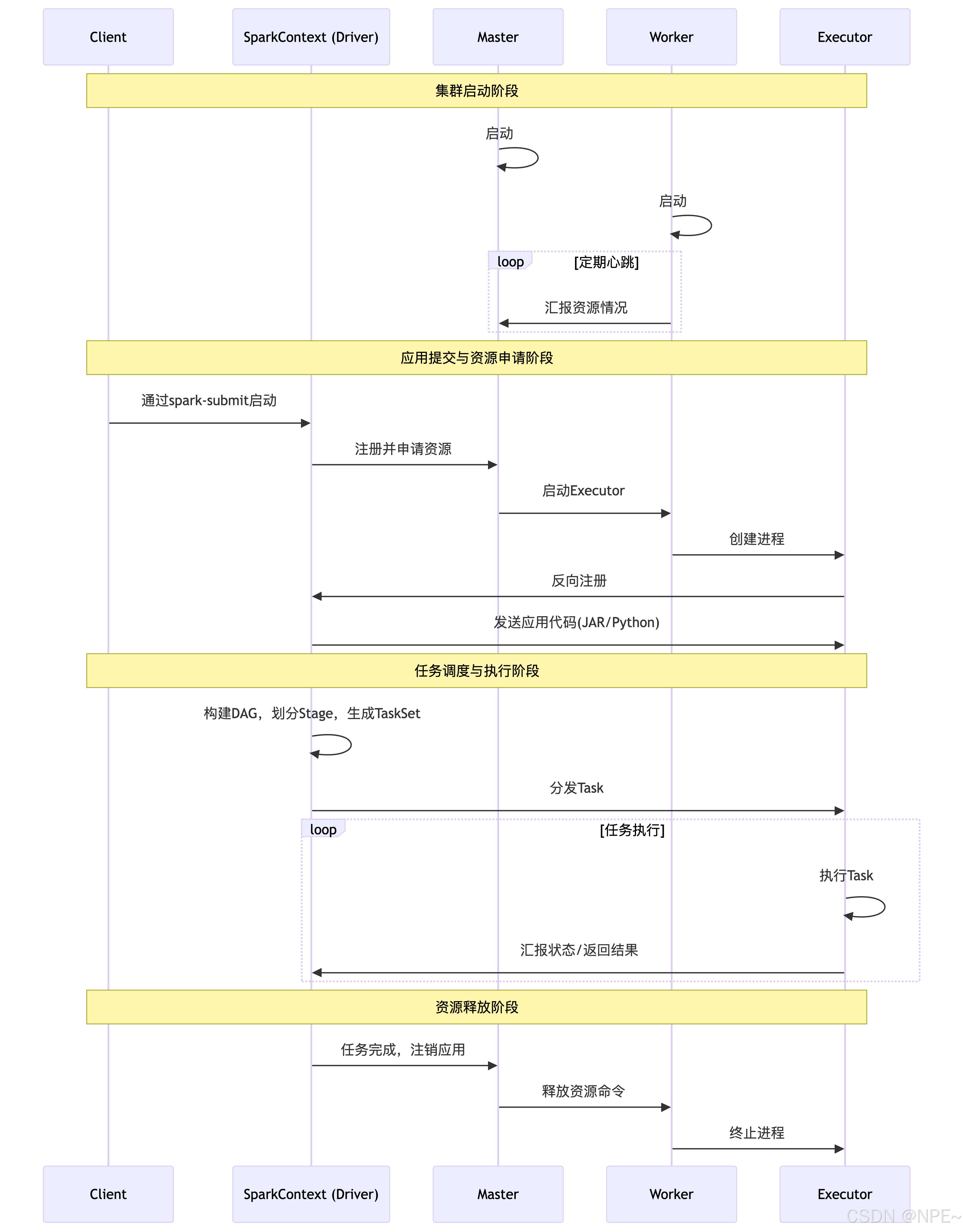
下面這個圖也非常經典:
spark on yarn 模式
概念:Spark客戶端直接連接Yarn。不需要額外構建Spark集群。 分布式部署集群,資源和任務監控交給yarn管理,但是目前僅支持粗粒度資源分配方式。它根據Driver程序運行位置的不同分為cluster和client運行模式,cluster適合生產,driver運行在集群子節點,具有容錯功能,client適合調試,dirver運行在客戶端。
- yarn-client模式:Driver程序運行在提交任務的客戶端機器上。
- yarn-cluster模式:Driver程序運行在YARN集群的某個NodeManager節點上(作為ApplicationMaster的一部分)。
應用場景:適用于公司已有Hadoop YARN集群,希望Spark與其他計算框架(如MapReduce)共享集群資源,統一管理的大規模生產環境。spark on yarn-client模式適合交互和調試(如:通過spark-shell),on yarn-Cluster模式更適合生產環境。
運行流程: (以 yarn-cluster 模式為例):
- 提交應用:用戶通過spark-submit腳本,指定–master yarn和–deploy-mode cluster,向YARN的ResourceManager提交應用程序。
- 啟動ApplicationMaster:ResourceManager在某個NodeManager上分配一個Container,并在其中啟動ApplicationMaster(AM)。注意:在cluster模式下,AM本身就包含了Spark Driver。
- 申請資源:AM(Driver)向ResourceManager申請運行Executor所需的資源。
- 啟動Executor:ResourceManager分配Container后,AM與對應的NodeManager通信,在Container中啟動Executor進程。
- 任務執行:Executor啟動后,會向AM(Driver)注冊。AM(Driver)中的SparkContext將Task分發給Executor執行。
- 完成與清理:應用運行完成后,AM會向ResourceManager注銷并關閉自己,其占用的資源也隨之釋放。
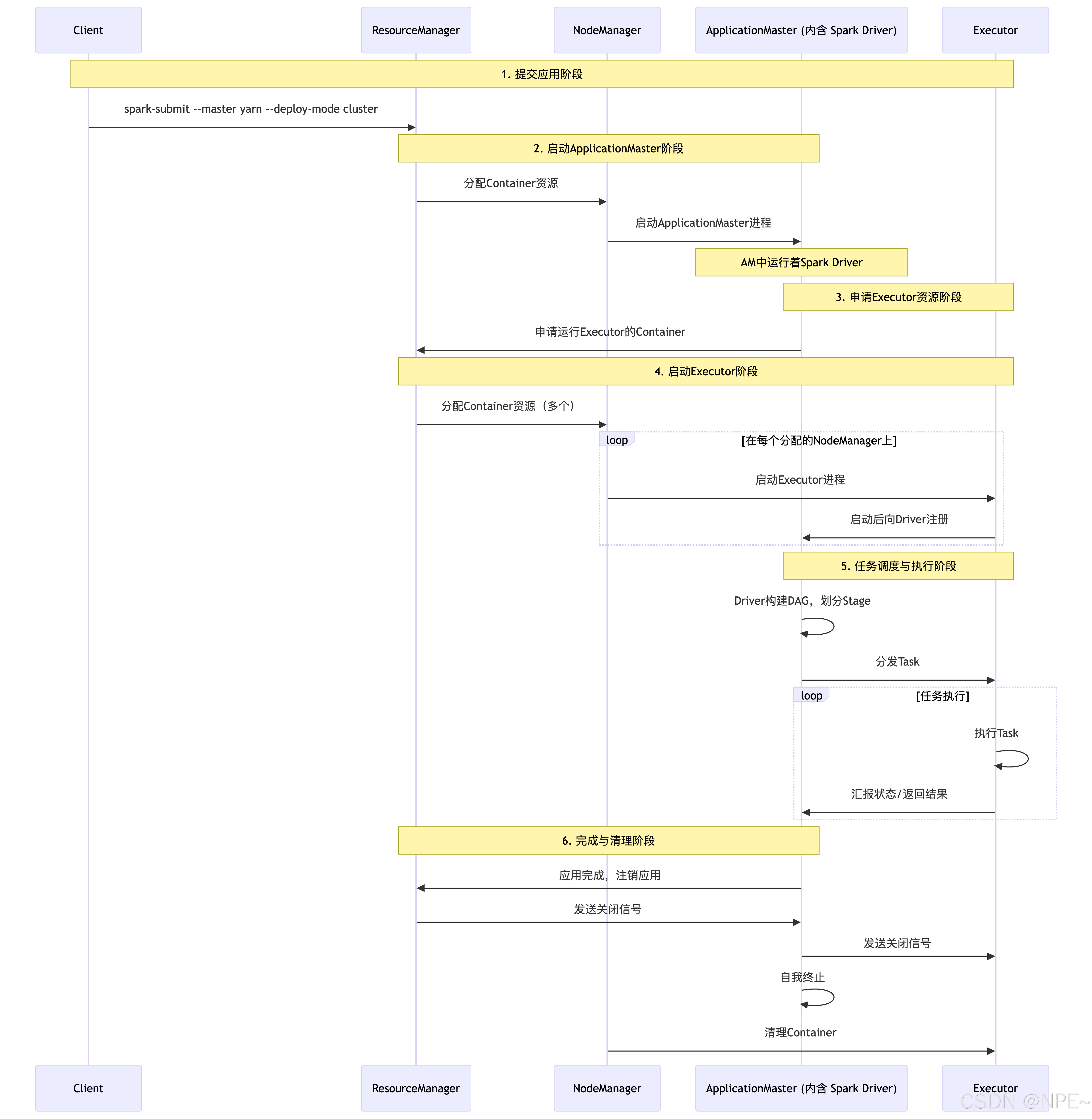
PS:client模式與cluster模式區別
| 特性 | YARN-Client 模式 | YARN-Cluster 模式 | 核心提示 |
|---|---|---|---|
| Driver 位置 | 客戶端機器上 | 集群中的 ApplicationMaster 里 | 最根本的區別,決定了其他所有不同。 |
| Application Master 角色 | 輕量,僅負責申請 Executor 資源 | 重量,就是 Driver 本身,負責全部調度 | Cluster 模式的 AM 權力更大。 |
| 客戶端要求 | 必須保持在線,直到應用結束 | 提交后即可斷開 | 想關電腦就用 Cluster。 |
| 日志輸出 | 直接輸出到客戶端控制臺,便于調試 | 需要通過 yarn logs 命令或 Web UI 查看 | 調試用 Client,生產用 Cluster。 |
| 性能 | 網絡通信可能跨網段,性能較差 | Driver 在集群內,網絡通信效率高 | Cluster 模式性能更優。 |
| 應用場景 | 測試、調試、交互式查詢 | 生產環境、長時間運行的任務 | 開發用 Client,上線用 Cluster。 |
yarn-client:
- 用于測試,因為driver運行在本地客戶端,負責調度application,會與yarn集群產生超大量的網絡通信。好處是直接執行時,本地可以看到所有的log,方便調試。
- Application Master僅僅向YARN請求Executor,Client會和請求的Container通信來調度他們工作,也就是說Client不能離開。
yarn-cluster:
- 生產環境使用, 因為driver運行在nodemanager上,缺點在于調試不方便,本地用spark-submit提價以后,看不到log,只能通過yarn application-logs application_id這種命令查看,很麻煩
- Driver運行在AM(Application Master)中,它負責向YARN申請資源,并監督作業的運行狀況。當用戶提交了作業之后,就可以關掉Client,作業會繼續在YARN上運行,因而YARN-Cluster模式不適合運行交互類型的作業;
spark on mesos 模式
概念:Spark可以作為Mesos框架上的一個應用程序運行,由Mesos來負責資源調度和分配。
應用場景:適用于需要運行多種類型計算框架(如同時運行Spark、MPI作業等)的混合負載集群,Mesos可以提供更靈活和通用的資源調度。
運行流程:(以粗粒度模式為例)
- 用戶向Mesos Master提交Spark應用。
- Mesos Master將資源offer發送給Spark的調度器(Driver)。
- Spark Driver接受offer,并指示Mesos在提供資源的Slave節點上啟動Executor。
- Executor啟動后,直接與Spark Driver通信,注冊并申請Task。
- Driver分配Task給Executor執行。
- 執行過程中,Executor直接向Driver匯報狀態。
2.5 Stage 劃分
劃分原理
可以把 Spark 的任務執行想象成一個工廠的流水線:
- DAG(有向無環圖):這是整個產品的生產流程圖,由一系列步驟(RDD 轉換操作)組成。
- Stage(階段):流程圖會被劃分成幾個大的生產階段。劃分的原則是:能否在流水線上不間斷地完成一系列加工。
- 寬窄依賴:這是劃分 Stage 的依據。
- 窄依賴:一個父零件只用來生產一個子零件。好比在同一個工位上對零件進行打磨、拋光。這些操作可以合并成一個 Stage,無需移動零件(無 Shuffle),效率極高。
- 寬依賴:需要把所有父零件打亂重組。好比把所有零件運到一個集中的裝配區(Shuffle),按新的規則分組后才能進行下一步組裝。這里必須劃分成一個新的 Stage。
核心思想:Spark 的 DAGScheduler 會從最終結果倒推這個“流程圖”,一旦遇到寬依賴(Shuffle),就畫上一條分界線,形成一個新 Stage。每個 Stage 內部都是一連串的窄依賴,可以進行流水線優化(Pipeline),在內存中連續計算。
優化建議[調優]
| 優化方向 | 目標 | 具體方法 | 代碼示例(不推薦 → 推薦) |
|---|---|---|---|
| 減少 Shuffle | 降低網絡/磁盤IO | 使用預聚合算子;使用廣播Join | rdd.groupByKey().mapValues(sum) → rdd.reduceByKey(_ + _) |
| 持久化 (Cache) | 避免重復計算 | 對多次使用的RDD進行緩存 | “val transformed = rdd.map(…)transformed.count(); transformed.reduce() → transformed.persist().count(); .reduce()” |
| 并行度 | 充分利用資源 | 調整Shuffle后的分區數 | 使用 spark.sql.shuffle.partitions 參數 |
| 數據傾斜 | 避免長尾任務 | 對傾斜Key進行加鹽處理 | join(skewRdd) → addRandomPrefix(skewRdd).join(…).removePrefix() |
PS:優化原理
- 減少與避免 Shuffle
為什么? Shuffle 是分布式計算中最昂貴操作,涉及磁盤 I/O、網絡 I/O、序列化/反序列化。減少一次 Shuffle,性能提升立竿見影。Stage 數量 ≈ Shuffle 次數。減少 Stage 數量本質上就是減少 Shuffle 次數。- 持久化(緩存)的正確使用
為什么? 如果一個 RDD 會被多個 Action 操作重用(例如一個循環里),默認情況下每次 Action 都會從頭重新計算整個 RDD,極其浪費。- 解決數據傾斜
為什么? 如果某個 Task 的數據量遠遠超過其他 Task,導致絕大多數任務早就完成了,卻在等那一個“慢哥”,會導致資源閑置。
建議:
- 寫代碼時時刻思考:“我這一步操作會不會引起 Shuffle?”
- 充分利用 Spark UI:提交任務后,一定要打開 Spark UI(通常是 http://:4040)。這是你最好的老師!在里面你可以看到:
- 整個執行的 DAG 可視化圖,清晰看到有幾個 Stage。
- 每個 Stage 的詳情,有多少個 Task,花了多少時間。
- Shuffle 讀寫的數據量,如果看到某個 Stage 寫入了大量數據,就要警惕了。
- 從模仿開始:先記住 reduceByKey 比 groupByKey 好,broadcast join 比普通 join 好,在實際代碼中先用起來。
3. 快速入門
搭建Spark環境
這里通過docker-compose搭建集群,如果沒有的可以通過github下載。
docker compose github:https://github.com/docker/compose
- 查看本地是否有docker-compose
docker-compose version

2. 創建spark集群掛載目錄
# 創建主目錄
mkdir -p /Users/ziyi/docker-home/spark-cluster# 創建數據目錄
mkdir -p /Users/ziyi/docker-home/spark-cluster/data# 創建 Spark Ivy 緩存目錄
mkdir -p /Users/ziyi/docker-home/spark-cluster/spark-ivy# 設置權限
chmod -R 777 /Users/ziyi/docker-home/spark-cluster/
- 進入目錄,創建docker-compose.yml文件
cd /Users/ziyi/docker-home/spark-cluster/
vi docker-compose.yml
docker-compose.yml:
networks:spark-net:driver: bridgeipam:config:- subnet: 172.30.0.0/16 # 這里子網需要是docker本地沒有被使用過的。可通過docker network ls + docker network inspect <network-id>查看services:# ================= Spark 集群配置 =================spark-master:image: bitnami/spark:3.5platform: linux/amd64container_name: spark-masterhostname: spark-masternetworks:spark-net:environment:- SPARK_MODE=master- SPARK_MASTER_HOST=spark-master- SPARK_MASTER_PORT=7077- SPARK_MASTER_WEBUI_PORT=8080- SPARK_USER=sparkvolumes:- /Users/ziyi/docker-home/spark-cluster/data:/tmp/data- /Users/ziyi/docker-home/spark-cluster/spark-ivy:/home/spark/.ivy2ports:- "8080:8080"- "7077:7077"- "6066:6066"spark-worker1:image: bitnami/spark:3.5platform: linux/amd64container_name: spark-worker1hostname: spark-worker1networks:spark-net:environment:- SPARK_MODE=worker- SPARK_WORKER_CORES=1- SPARK_WORKER_MEMORY=1g- SPARK_MASTER_URL=spark://spark-master:7077- SPARK_WORKER_PORT=8881- SPARK_WORKER_WEBUI_PORT=8081- SPARK_USER=sparkdepends_on:- spark-mastervolumes:- /Users/ziyi/docker-home/spark-cluster/data:/tmp/data- /Users/ziyi/docker-home/spark-cluster/spark-ivy:/home/spark/.ivy2ports:- "8081:8081"spark-worker2:image: bitnami/spark:3.5platform: linux/amd64container_name: spark-worker2hostname: spark-worker2networks:spark-net:environment:- SPARK_MODE=worker- SPARK_WORKER_CORES=1- SPARK_WORKER_MEMORY=1g- SPARK_MASTER_URL=spark://spark-master:7077- SPARK_WORKER_PORT=8882- SPARK_WORKER_WEBUI_PORT=8082- SPARK_USER=sparkdepends_on:- spark-mastervolumes:- /Users/ziyi/docker-home/spark-cluster/data:/tmp/data- /Users/ziyi/docker-home/spark-cluster/spark-ivy:/home/spark/.ivy2ports:- "8082:8082"spark-worker3:image: bitnami/spark:3.5platform: linux/amd64container_name: spark-worker3hostname: spark-worker3networks:spark-net:environment:- SPARK_MODE=worker- SPARK_WORKER_CORES=1- SPARK_WORKER_MEMORY=1g- SPARK_MASTER_URL=spark://spark-master:7077- SPARK_WORKER_PORT=8883- SPARK_WORKER_WEBUI_PORT=8083- SPARK_USER=sparkdepends_on:- spark-mastervolumes:- /Users/ziyi/docker-home/spark-cluster/data:/tmp/data- /Users/ziyi/docker-home/spark-cluster/spark-ivy:/home/spark/.ivy2ports:- "8083:8083"
- 啟動集群
# 后臺拉取鏡像并啟動集群
docker-compose up -d
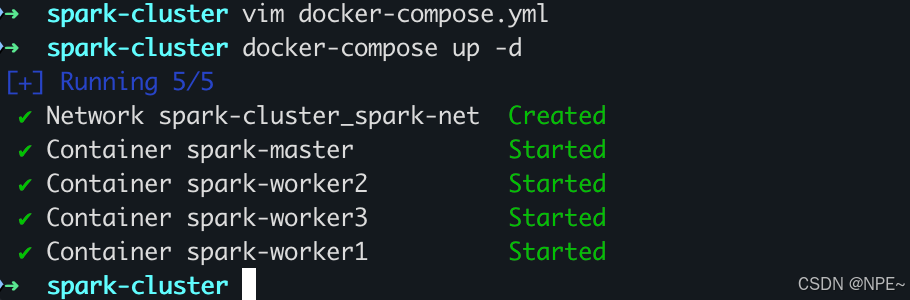
5. 查看集群狀態
docker-compose ps -a

可以看到所有容器狀態都為Up,接下來可以訪問UI頁面:
- Spark Master UI頁面: http://localhost:8080
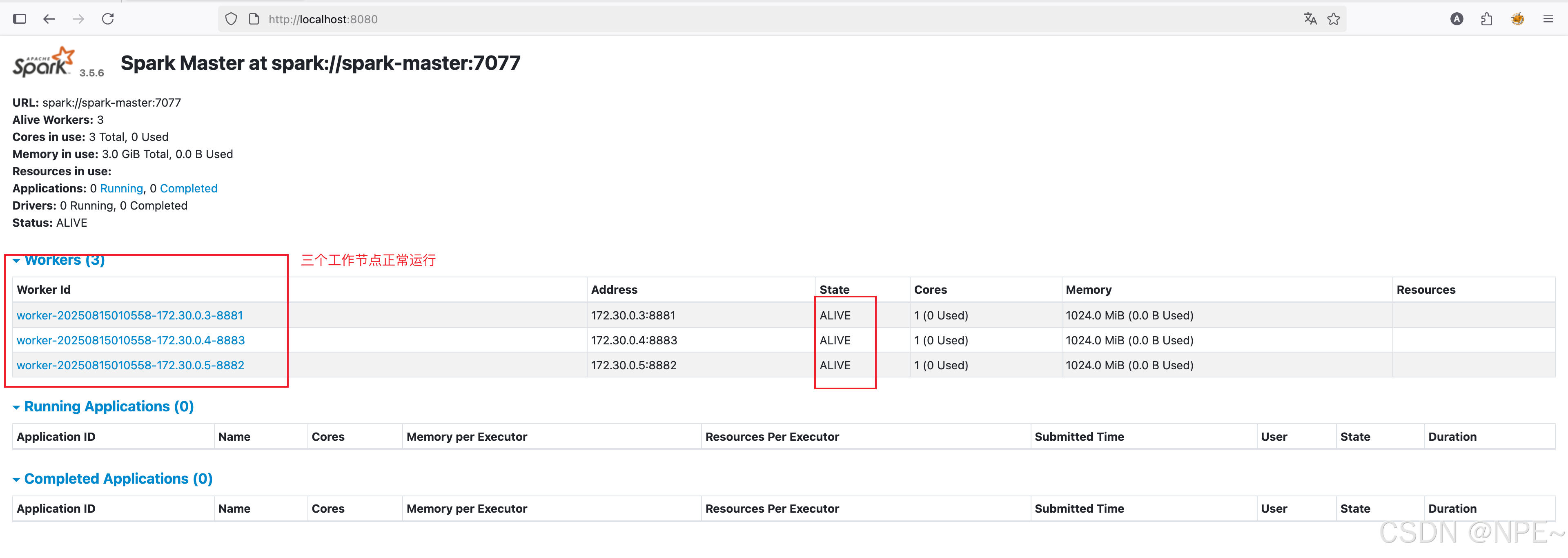
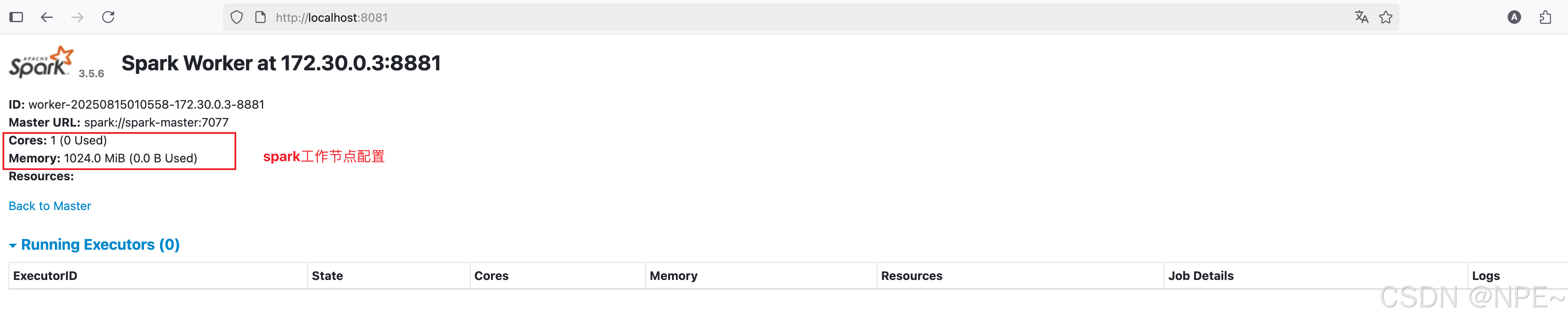
- Spark 工作節點UI頁面:
- Worker 1 Web UI: http://localhost:8081
- Worker 2 Web UI: http://localhost:8082
- Worker 3 Web UI: http://localhost:8083
Spark功能測試
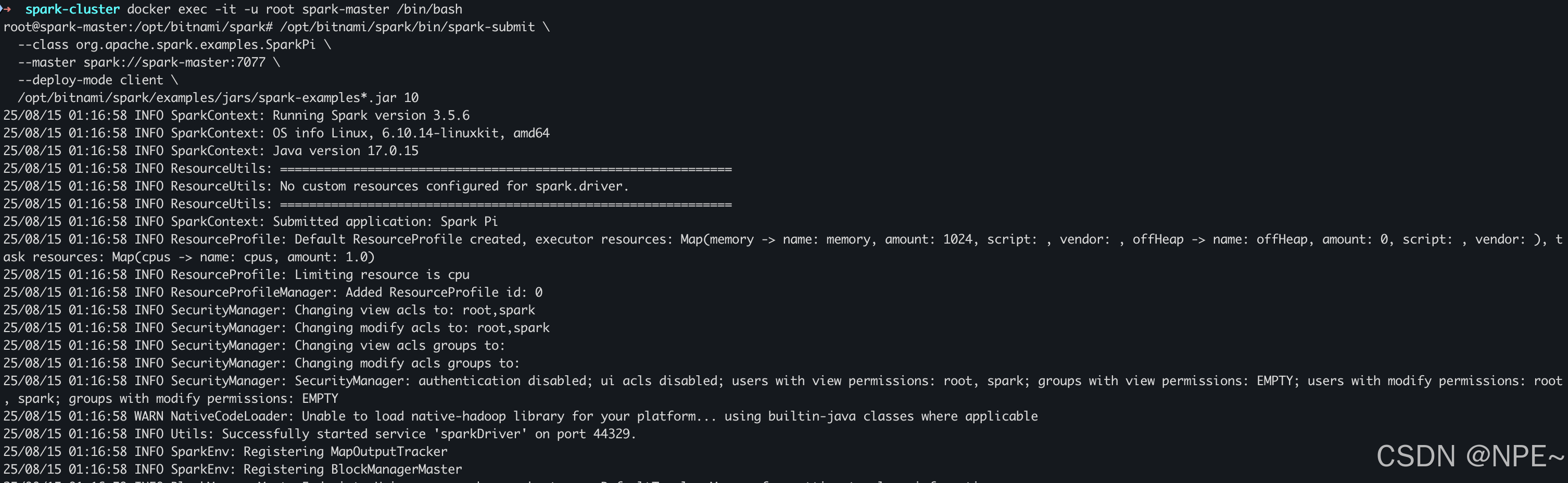
方式一:使用spark-submit測試jar包
# 以 root 用戶身份進入容器
docker exec -it -u root spark-master /bin/bash# 執行命令,提交運行spark測試任務
/opt/bitnami/spark/bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://spark-master:7077 \--deploy-mode client \/opt/bitnami/spark/examples/jars/spark-examples*.jar 10
效果:
在Spark管理臺上也可以看到作業運行狀態:http://localhost:8080/
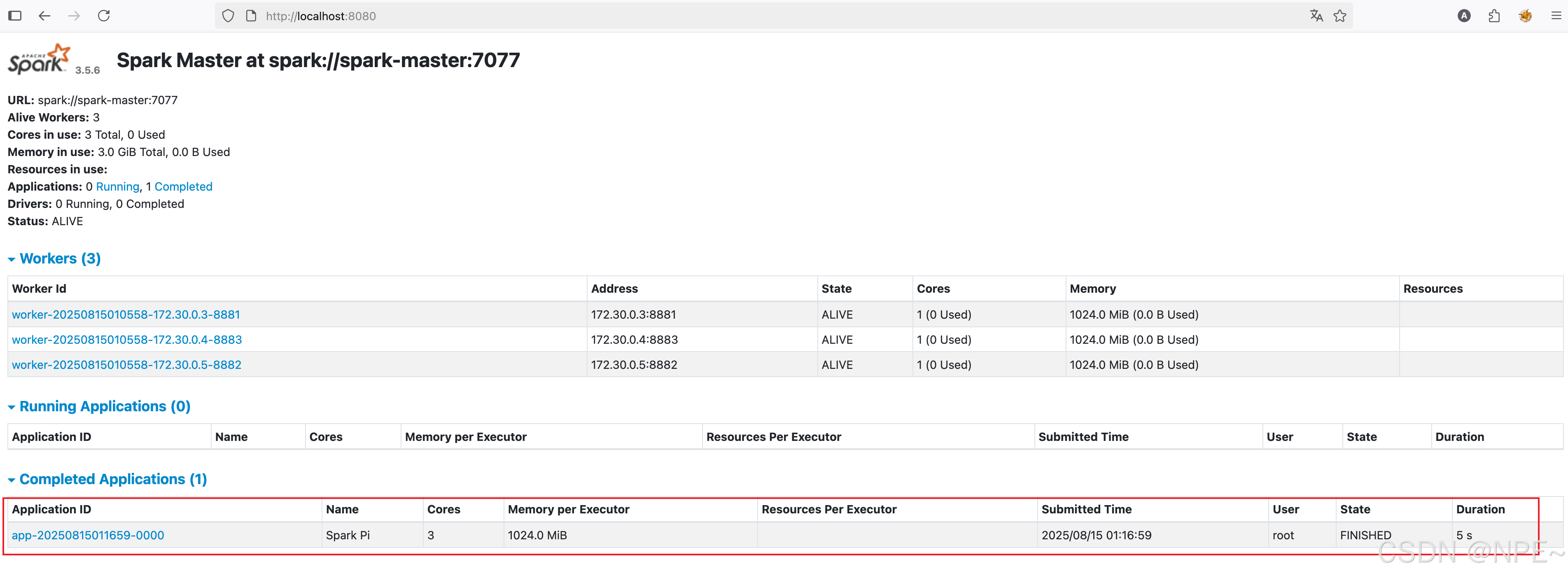
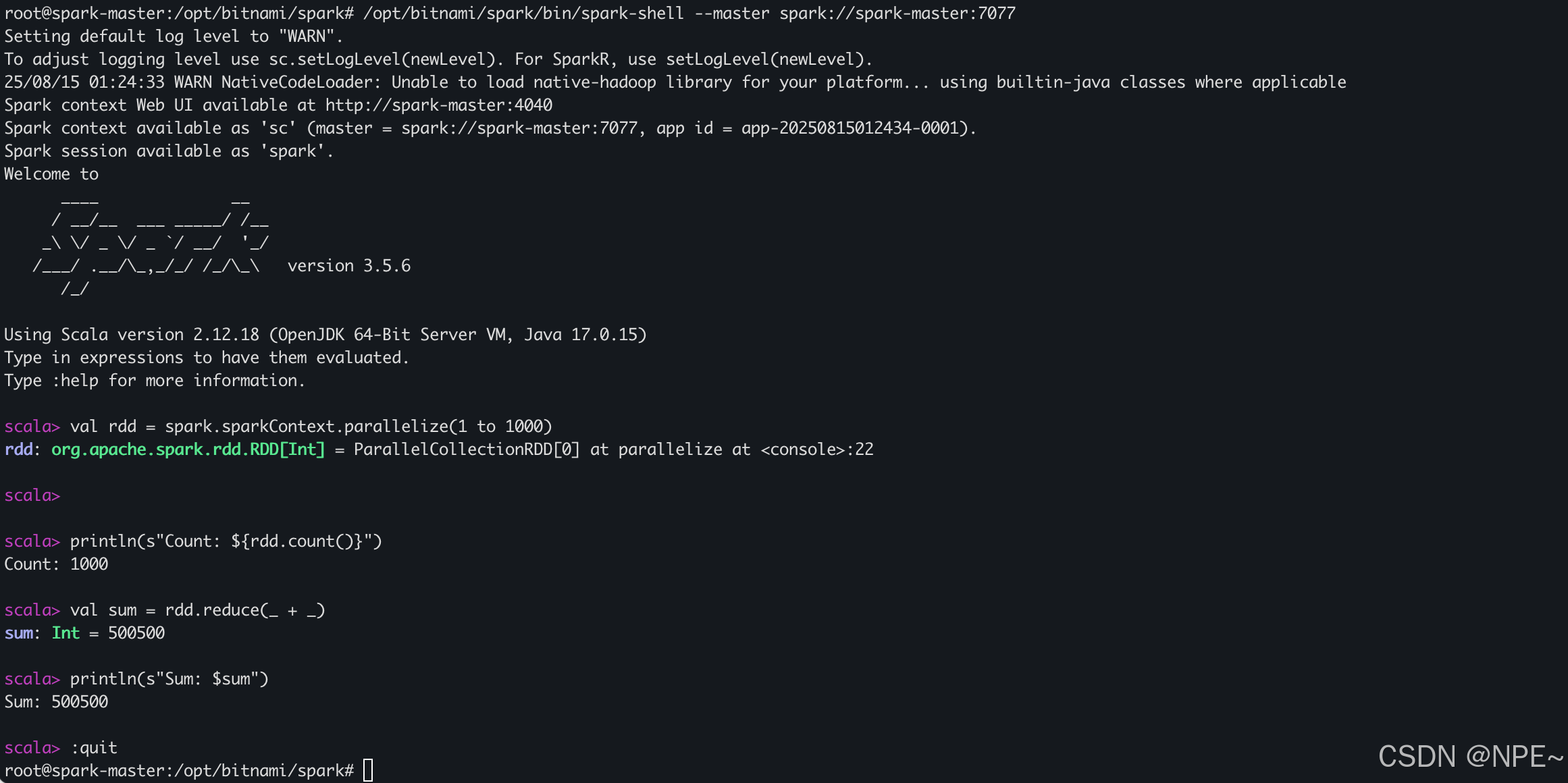
方式二:使用spark命令行驗證
# 進入 spark-master 容器
docker exec -it -u root spark-master /bin/bash# 啟動 Spark Shell
/opt/bitnami/spark/bin/spark-shell --master spark://spark-master:7077# 通過spark代碼測試
scala> val rdd = spark.sparkContext.parallelize(1 to 1000)
scala> println(s"Count: ${rdd.count()}")
scala> val sum = rdd.reduce(_ + _)
scala> println(s"Sum: $sum")
scala> :quit
效果:
Spark Scala 案例:電商數據分析
官方API:https://spark.apache.org/docs/3.5.3/api/scala/org/apache/spark/index.html
- 案例文件創建
# 在主機上創建測試文件創建銷售數據文件,因為我們集群搭建時將本地目錄掛載到了容器內部的/tmp/data
# 所以容器/tmp/data/目錄下可直接訪問sales.csv文件
cat > /Users/ziyi/docker-home/spark-cluster/data/sales.csv << 'EOF'
id,product,category,price,quantity,date
1,ProductA,Electronics,100.0,2,2024-01-15
2,ProductB,Clothing,50.0,3,2024-01-16
3,ProductC,Electronics,200.0,1,2024-01-17
4,ProductD,Books,30.0,5,2024-01-18
5,ProductE,Clothing,80.0,2,2024-01-19
6,ProductF,Electronics,150.0,1,2024-01-20
7,ProductG,Books,25.0,4,2024-01-21
8,ProductH,Clothing,60.0,2,2024-01-22
EOF
- 進入容器,啟動spark-shell
## 進入容器
docker exec -it -u root spark-master /bin/bash
## 進入spark-shell
/opt/bitnami/spark/bin/spark-shell --master spark://spark-master:7077
- 編寫Scala語言,加載并分析數據
案例:電商銷售數據分析。讀取本地文件并分析
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession// 1. 讀取數據
// 通過file協議讀取本地CSV 文件 (后續有hdfs可直接通過hdfs://讀取hdfs數據分析)
val salesDF = spark.read.option("header", "true").option("inferSchema", "true").csv("file:///tmp/data/sales.csv")
salesDF.show()
salesDF.printSchema()
// 2. 添加計算列
val enrichedSales = salesDF.withColumn("revenue", $"price" * $"quantity")
enrichedSales.show()
// 3. 執行聚合分析
val analysisResult = enrichedSales.groupBy("category").agg(
count("*").as("transaction_count"),
sum("revenue").as("total_revenue"),
avg("revenue").as("avg_revenue"))// 4. 排序并顯示最終結果
analysisResult.orderBy(desc("total_revenue")).show()
運行效果:
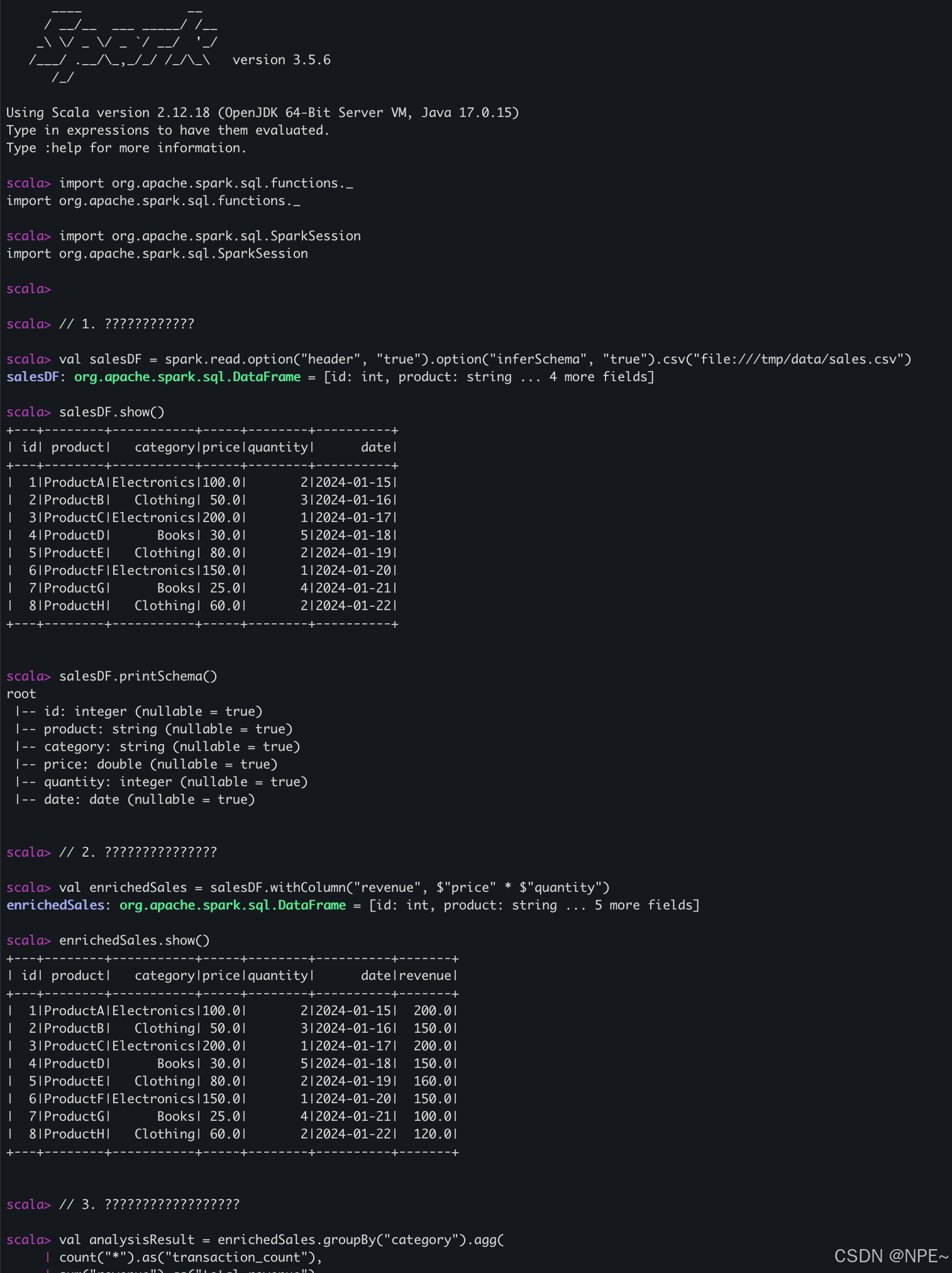
參考文章:
https://blog.csdn.net/lovechendongxing/article/details/81746988
https://spark.apache.org/streaming/





)

)




:mybaits if標簽test條件判斷等號=解析異常解決方案)






