
個人主頁:@大數據蟒行探索者?

目錄
一、數據分析目標與任務
1.1背景介紹
1.2課程設計目標與任務
1.3研究方法與技術路線
二、數據預處理
2.1數據說明
2.2數據清洗
2.3數據處理
三、數據探索分析
四、數據分析模型
五、方案評估
?
摘要:隨著社會經濟的迅猛發展,房地產開發建設的速度越來越快,二手房市場迅猛發展,對二手房房產價格評估的需求也隨之增大。因此,對二手房房價預測進行研究是必要的。住宅是城市居民的剛性需求,隨著城市建設用地越來越緊缺,住宅供需成為城市發展必須解決的一大問題。二手房數量占城市住宅總量的比重較高,并且大多數二手房占據城市配套成熟的優越位置,因此成為城市居民解決剛性需求的重要選擇。城市是一個復雜的系統,二手房作為城市的“細胞”,其價格受許多要素影響,不同城市的二手房價格在空間分布上有所不同。
本文使用python爬蟲從鏈家二手房網站上爬取了深圳的在售二手房數據,并對二手房數據進行數據分析,首先查看數據,導入數據,了解數據集的維度,每列數據的數據類型,以及打印部分數據,進行觀察。然后進行數據清洗,刪除不需要的列,刪除重復行數據,刪除包含有空值的行數據,以及對異常值進行處理。
數據清洗后,使用所在行政區、參考單價、建筑面積、戶型結構、裝修情況、配備電梯、建筑結構等指標作為影響深圳二手房售賣每平米價格的主要因素,據此建立模型,使用線性回歸、支持向量機和隨機森林三種模型進行預測,最終得到較優的深圳二手房房價預測模型,為深圳二手房交易者們提供了一個有較為有實用價值的二手房定價工具。
本文基本符合一個完整數據分析案例的要求,但仍有很多可以改進的地方,如可以采用更復雜的統計學理論深入分析房價分布及其影響因素,對機器學習模型進行調參以盡可能提高預測能力,采用更加直觀的數據可視化方式展示數據,并通過數據分析為二手房購買者提供建設性意見。
關鍵詞:深圳 房價 數據清洗
一、數據分析目標與任務
1.1背景介紹
房地產行業是我國國民經濟的支柱產業之一,房地產市場的健康發展對促進我國的國民經濟發展、維護社會的和諧穩定起著十分重要的作用。近幾年,隨著我國房地產行業的迅猛發展,房價節節攀升,很多購房者對于居高不下的一手房價格“心灰意冷”,轉而將目光投向了比一手房價格低的二手房市場。深圳的二手房成交量也不斷創出歷史新高,呈現蓬勃發展的態勢。但相比于較成熟的一手房市場,二手房市場對政策過于敏感,面對此起彼落的針對樓市過熱出臺的多項嚴控政策。根據深圳中原研究中心數據顯示,2021年10月份深圳全市二手房住宅過戶套數為1605套,環比下降9.1%,過戶套數為2012年3月以來的最低值。深圳二手房月度成交量出現十連跌。
二手房市場的發展具有重要的意義。二手房市場的發展,不僅有利于住宅一級市場的繁榮、縮短新建商品住宅的銷售周期,而且可以滿足居民置業升級和梯度消費的需求,補充和保障中低收入戶的住房需求。區別于一手房,二手房交易流程長,涉及主體多,法律關系錯綜復雜,糾紛時常發生,風險無處不在,所以對深圳二手房市場現狀和政策的分析研究也就具備了可行性和必要性。同時,通過運用經濟理論和方法對北京市二手房市場現狀的研究,可以了解和學習國家相關的房貸信息和貨幣政策,從宏觀上把握二手房市場的存在價值和發展趨勢,為參與到二手房交易的個人或者家庭提供一些積極有效的參考信息和應該注意的問題,使其具有較強的現實意義和參考價值。
1.2課程設計目標與任務
住宅是城市居民的剛性需求,隨著城市建設用地越來越緊缺,住宅供需成為城市發展必須解決的一大問題。二手房數量占城市住宅總量的比重較高,并且大多數二手房占據城市配套成熟的優越位置,因此成為城市居民解決剛性需求的重要選擇。城市是一個復雜的系統,二手房作為城市的“細胞”,其價格受許多要素影響,不同城市的二手房價格在空間分布上有所不同。通過研究二手房價格空間分布及影響因素,對房地產健康發展具有重要的意義。
本次課程設計需要對二手房市場背景展開調研,爬取某一具體城市的二手房數據集,分析影響該城市二手房價格的主要因素,并構建相應的二手房房價估值模型,實現房價的預測。
1.3研究方法與技術路線
首先查看數據,導入數據,了解數據集的維度,每列數據的數據類型,以及打印部分數據,進行觀察。然后進行數據清洗,刪除不需要的列,刪除重復行數據,刪除包含有空值的行數據,以及對異常值進行處理。數據清洗后,對數據進行探索性分析找到影響房價的主要因素建立模型進行房價預測。
本次課程設計采用python編程,使用jupyter notebook開發環境進行開發。
二、數據預處理
2.1數據說明
- 數據規模:38762 rows × 29 columns
- 數據文件:本文通過對爬取到的 38762套深圳二手房數據進行數據分析,通過簡單數據清洗、可視化作圖等多個方式進行探索性分析以及房價預測。
- 數據字段:數據集中匯總了深圳市目前的38000+個二手房數據,包含房屋詳細數據、經緯度等29個字段,字段主要包括:小區名稱、行政區、區域、參考總價、參考單價、房屋戶型、所在樓層、建筑面積、戶型結構、套內面積、建筑類型、經緯度 等 29個字段,具體字段如下所示:
- 小區名稱
- 行政區
- 區域
- 編號
- 參考總價
- 參考單價
- 房屋戶型
- 所在樓層
- 建筑面積
- 戶型結構
- 套內面積
- 建筑類型
- 朝向
- 建筑結構
- 裝修情況
- 梯戶比例
- 配備電梯
- 掛牌時間
- 交易權屬
- 上次交易時間
- 房屋用途
- 房屋年限
- 產權所屬
- 抵押信息
- 房本備件
- 房協編碼
- 經度
- 緯度
- 城市
共29個字段,其中,小區名稱、行政區、區域、總價、單價等都是最常見的基本信息戶型、樓層、面積、建筑類型、房屋朝向、建筑結構等都是房屋的具體屬性信息掛牌時間、交易權屬、上次交易時間、抵押信息等都是房屋的交易信息經緯度是房屋所在的百度經緯度數據,城市是額外新增的一個字段,本次均為:深圳。
- 數據樣本:利用data.head()輸出前5行數據查看如下圖所示。
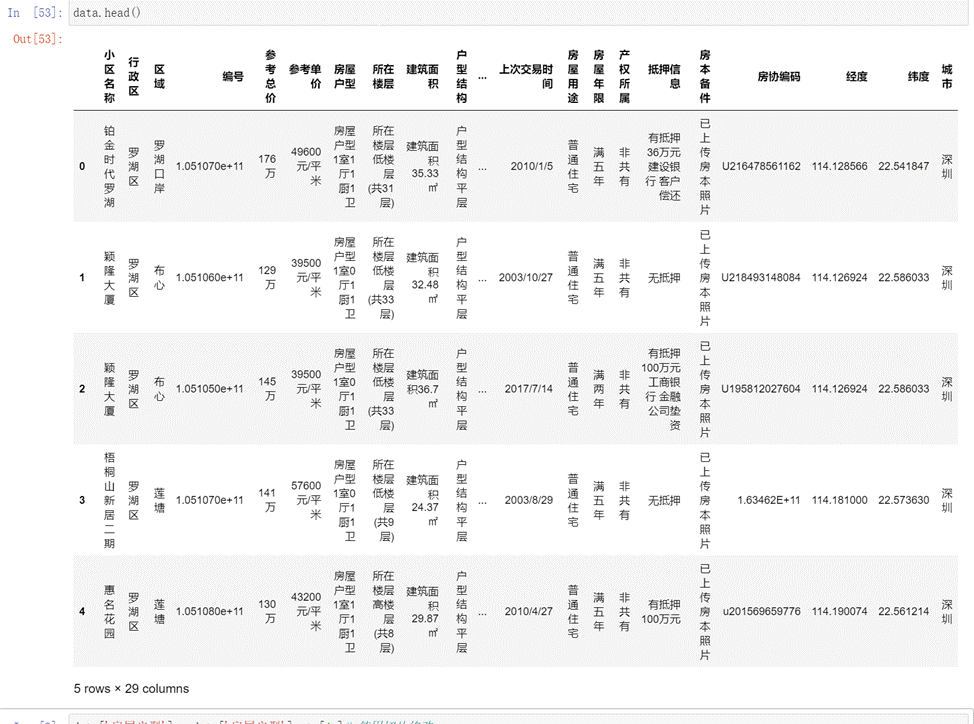
圖1 數據樣本
打印數據集每列的信息如下圖所示,其中,參考總價、參考單價、建筑面積、套內面積 等都屬于數值類型。因為在爬取數據的數據沒有進行數據清洗,網站上是什么就存儲成什么,這也是為了保護數據的真實性,但是在實際分析過程中,特別是建模中,這類數據通常都是存儲成數值型,方便可視化的同時也能保證模型快速收斂,所以在后面會轉換數據類型。

圖2 數據集每列信息
2.2數據清洗
- 缺失值處理
缺失值處理的三種方法:直接使用含有缺失值的特征;刪除含有缺失值的特征(該方法在包含缺失值的屬性含有大量缺失值而僅僅包含極少量有效值時是有效的);缺失值補全。而本次我們采用的是若是存在含有空值的行,則本地刪除含有空值的行數據。
也就是將存在遺漏信息屬性值的對象(元組,記錄)刪除,從而得到一個完備的信息表。這種方法簡單易行,在對象有多個屬性缺失值、被刪除的含缺失值的對象與信息表中的數據量相比非常小的情況下是非常有效的,類標號(假設是分類任務)缺少時通常使用。然而,這種方法卻有很大的局限性。它是以減少歷史數據來換取信息的完備,會造成資源的大量浪費,丟棄了大量隱藏在這些對象中的信息。在信息表中本來包含的對象很少的情況下,刪除少量對象就足以嚴重影響到信息表信息的客觀性和結果的正確性;當每個屬性空值的百分比變化很大時,它的性能非常差。因此,當遺漏數據所占比例較大,特別當遺漏數據非隨機分布時,這種方法可能導致數據發生偏離,從而引出錯誤的結論。
?通過處理我們發現含有缺失值的行數為494行,缺失值處理后的結果如下所示。

圖3 缺失值處理
- 重復行處理
在數據的收集過程中,可能會存在重復觀測的出現,例如通過網絡爬蟲,就比較容易產生重復數據重復值一般采取刪除法來處理,看出檢測數據集的記錄是否存在重復,使用duplicated (英文單詞的意思就是重復,復制的意思)方法,但是該方法返回的是數據集每一行的檢驗結果,為了能夠得到最直接的結果,可以使用any函數,該函數表示的是在多個條件判斷中,只有一個條件為True,則any函數的結果就為True。正如結果所示,any函數的運用返回True值,說明該數據集是存在重復觀測的。然后再使用drop_duplicates刪除重復觀測。
重復行處理結果如下圖所示,可以發現只刪除了一行的數據,說明只有一行重復值。

圖4 重復行處理
- 異常值處理
- 發現房屋戶型、所在樓層、戶型結構、建筑面積、套內面積、建筑類型、朝向、建筑結構、裝修情況、配備電梯、梯戶比例這幾個字段在數據集中前四個字符都是多余的,故對其利用字符串切片進行刪除如下圖所示。

圖5 刪除多余字符
- 觀察參考總價字段發現,可以看到參考總價有兩種形式,帶單位的和不帶單位的,這里我們直接確定成數值(方便在回歸模型中應用),同理,參考單價字段可以采用同樣的處理方式。但是單價的單位是具體到元的,將參考單價的單位改成與總價的單位保持一致為萬/平方米。

圖6 參考單價與參考總價字段處理
- 在分析參考總價的時候發現有的總價小于10w,不符合邏輯,我們將這些數據提取出來觀察如下所示。

圖7 總價小于10w的數據
- 可以發現這些房屋總價的單位是億不是萬,所以需要對這部分房屋的總價進行處理如下圖所示。
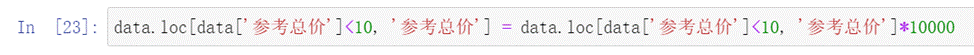
圖8 總價處理
- 觀察套內面積發現缺失的字段較多,并且在爬取數據時出現的錯誤也較多,故刪除套內面積字段如下圖所示。

圖9 套內面積處理
- 觀察戶型結構字段發現戶型結構字段存在錯誤數據,將這些存在錯誤數據的元組刪除得到新的數據集data1如下圖所示。

圖10 戶型結構處理
2.3數據處理
- 所在樓層字段過于冗長,為了方便計算,直接取描述性數據,例如中樓層、高樓層如下圖所示。

圖11 所在樓層處理
- ?觀察房屋戶型字段我們發現都是x室x廳x廚x衛,但在實際中一般我們在說戶型的時候,都只是說 xx室xx廳,很少去關注后面的廚房和衛生間個數,所以我們只取前兩個屬性,利用正則表達式進行匹配如下圖所示。

圖12 房屋戶型處理
- 分析建筑面積字段,將對應的 ㎡ 剔除掉,保證字段為數值類型,需要注意的是有部分數據為空的,官方標記的是“暫無數據”,這部分我們需要進行缺失值填充。例如:房屋價格存在缺失,可以使用同一區域內的均價進行填充;房屋類型存在缺失,可以使用同一小區的其他房屋該字段的眾數進行填充;多個房屋區域存在缺失,可以通過自定義距離函數計算最近的小區并進行相應填充。填充方法如下圖所示。

圖13 缺失值填充方法
首先col1、col2是輔助列,target_col 是目標列。例如:對建筑面積進行缺失填充,按照填充規則,會根據同一個小區同一戶型的建筑面積的均值進行填充,對應的,目標列就是 “建筑面積”,輔助列col1、col2就是 ”小區名稱、房屋戶型”。另外,當你的輔助列只有一個時,對應的 col_2 可以傳入一個空字符串,例如上述中的 “”。其次是 col1_value、col2_value 和 target_value,對應的表示建筑面積缺失該數據的輔助列字段的值。data 表示整個數據集。target_type 表示填充目標列的類型,像建筑面積就是數值型,使用均值填充;像房屋戶型是字符類型,使用眾數填充。
利用上述缺失值填充方法對建筑面積進行缺失值填充:
data.loc[data['建筑面積']=='暫無數據', '建筑面積'] = data.loc[data['建筑面積']=='暫無數據', ['小區名稱', '房屋戶型', '建筑面積']].apply(lambda x: get_nan_info("小區名稱", "房屋戶型", x[0], x[1], data, target_col="建筑面積", target_value=x[2]), axis=1)
- 對于戶型結構字段,通過觀察可以發現戶型結構中也存在“暫無數據”的缺失值,故我們利用'小區名稱', '房屋戶型'兩個字段來確定怎樣填充戶型結構字段,剩余的利用眾數來填充如下圖所示。

圖14 戶型結構填充
- 對于建筑類型字段,通過觀察可以發現建筑類型中也存在“暫無數據”和未知結構的缺失值,故我們利用'小區名稱', '房屋戶型'兩個字段來確定怎樣填充建筑類型字段,剩余的利用眾數來填充如下圖所示。
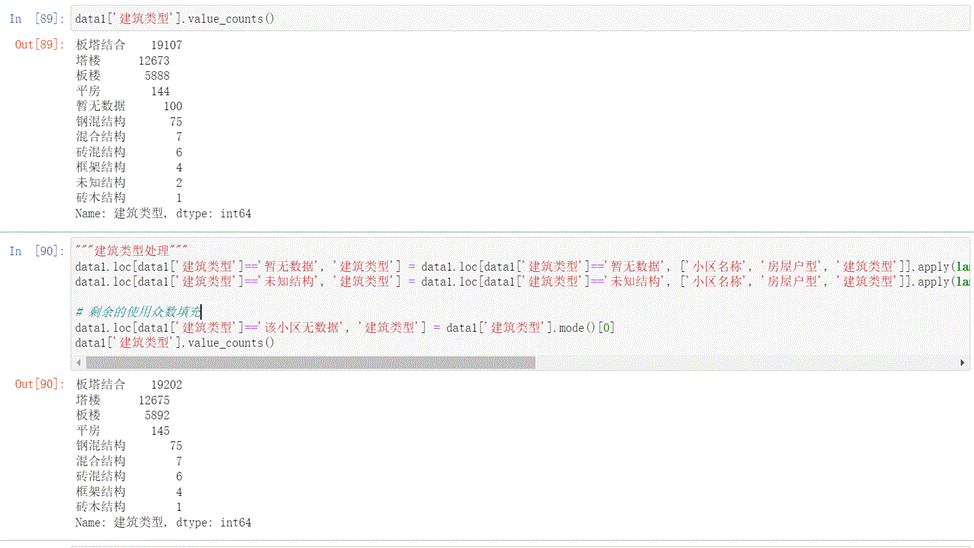
圖15 建筑類型填充
- 對于建筑結構字段,通過觀察可以發現建筑結構中也存在“暫無數據”和未知結構的缺失值,故我們利用'小區名稱', '房屋戶型'兩個字段來確定怎樣填充建筑結構字段,剩余的利用眾數來填充如下圖所示。
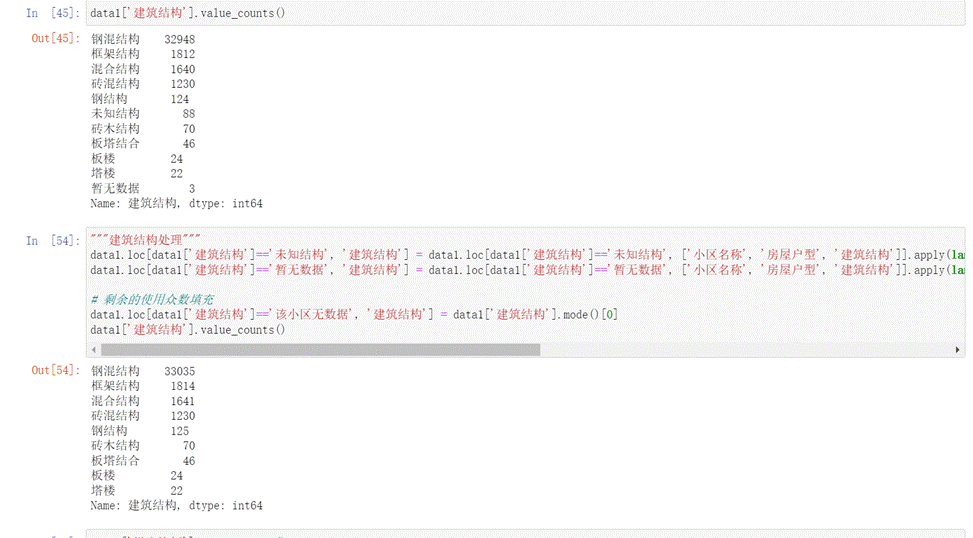
圖16 建筑結構填充
- 配備電梯、房屋年限、裝修情況和上面類似,這里就不再贅述了。
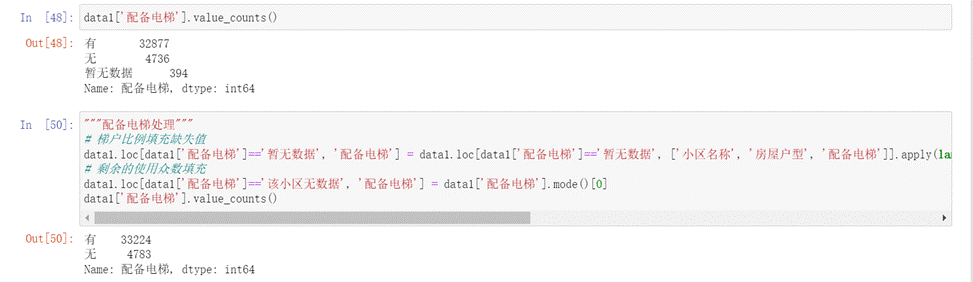
圖17 配備電梯填充

圖18 房屋年限填充
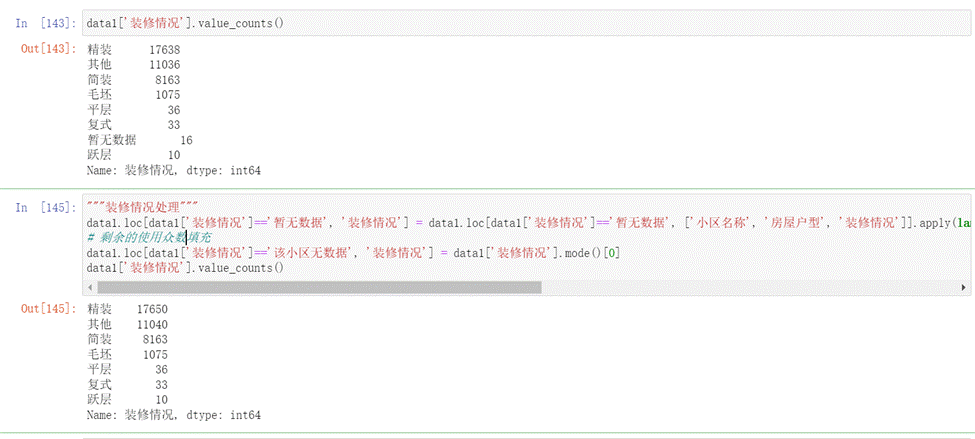
圖19 裝修情況填充
- 通過對抵押信息字段的觀察發現,抵押信息看似很多,但是其實說白了就兩種,有抵押和無抵押,直接進行處理即可,將其分為有抵押和無抵押如下圖所示。
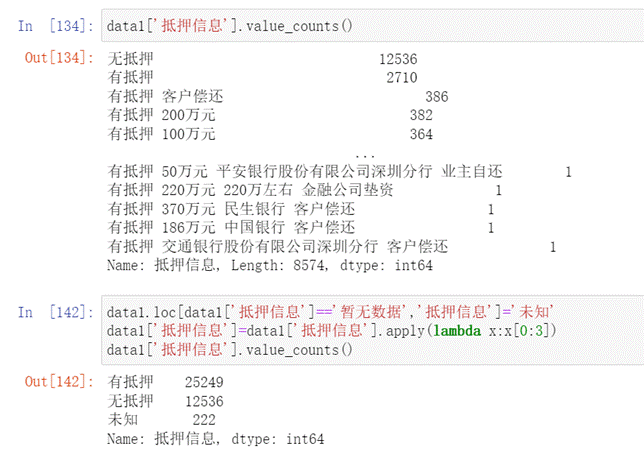
圖20 抵押信息處理
- 本次設計預處理最難的部分也就是缺失值填充部分,剛開始我們并沒有去處理“暫無數據”或者“該小區無數據”等缺失值字段進行分析,分析到后面發現了這個錯誤,想到必須對其進行填充,然后討論并分析才設計出這種填充方法。
三、數據探索分析
1. 結合可視化呈現,對數據進行探索性分析
- 整體房價分析
對深圳市的整體二手房價進行處理,包括最高價格、最低價格、平均價格和中位數價格分布。
- 地理位置對房價的影響
采用行政區劃作為地理位置的影響因素,從行政區劃方面對深圳二手房的數據進行分析。
- 建筑面積對房價的影響
作為房屋類型的影響因素之一,從建筑面積方面對深圳二手房的數據進行分析。
- 所在樓層對房價的影響
作為房屋類型的影響因素之一,從所在樓層方面對深圳二手房的數據進行分析。
- 戶型結構對房價的影響
作為房屋類型的影響因素之一,從戶型結構方面對深圳二手房的數據進行分析。
- 建筑類型對房價的影響
作為房屋類型的影響因素之一,從建筑類型方面對深圳二手房的數據進行分析。
- 建筑結構對房價的影響
作為房屋類型的影響因素之一,從建筑結構方面對深圳二手房的數據進行分析。
- 抵押信息對房價的影響
作為房屋類型的影響因素之一,從是否抵押方面對深圳二手房的數據進行分析。
- 房屋年限對房價的影響
作為房屋類型的影響因素之一,從房屋使用年限方面對深圳二手房的數據進行分析。
- 裝修情況對房價的影響
作為房屋類型的影響因素之一,從裝修情況方面對深圳二手房的數據進行分析。
- 配備電梯對房價的影響
作為房屋類型的影響因素之一,從是否配備電梯方面對深圳二手房的數據進行分析。
- 深圳二手房房屋戶型占比情況
通過繪制餅圖,展示深圳二手房的房屋戶型占比情況。
- 深圳二手房所在樓層占比情況
通過繪制柱狀圖,統計深圳各樓層二手房數量分布。
- 深圳二手房房屋朝向分布情況
通過繪制柱狀圖,統計深圳二手房房屋朝向分布情況。
- 深圳各區域二手房平均單價
通過繪制柱狀圖,展現深圳各區域二手房平均單價。
- 可視化呈現結果
- 整體房價分析

圖21 整體房價分析
從統計結果上來看,深圳二手房的最高價格超過50萬元/平方米,最低價格不高于2萬元/平方米,懸殊極大。房價的平均數和中位數均在5-6萬元/平方米。
下面展示深圳整體二手房價格與數量的柱狀圖:
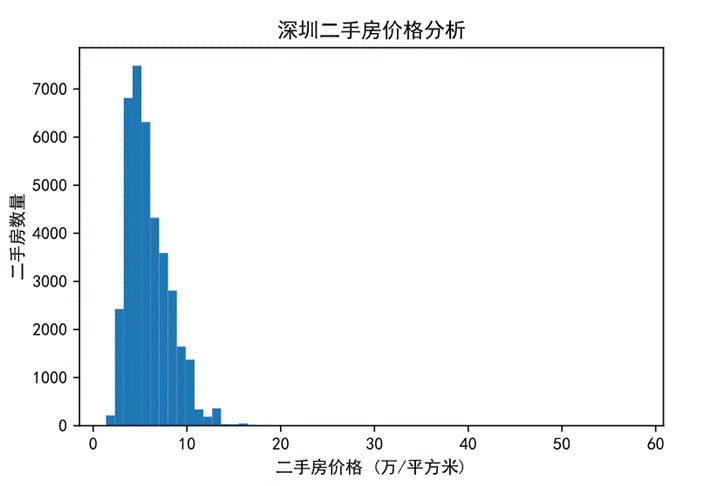
圖22 整體房價的柱狀圖
通過上圖可以看出,二手房的價格主要集中在5-6萬/平方米;從整體分布來看,其數據分布類似于正態分布,呈現單峰特點。
- 行政區化對房價的影響
①各行政區劃內房價的平均值柱狀圖(按從大到小排序)

圖23 行政區劃對平均房價的影響
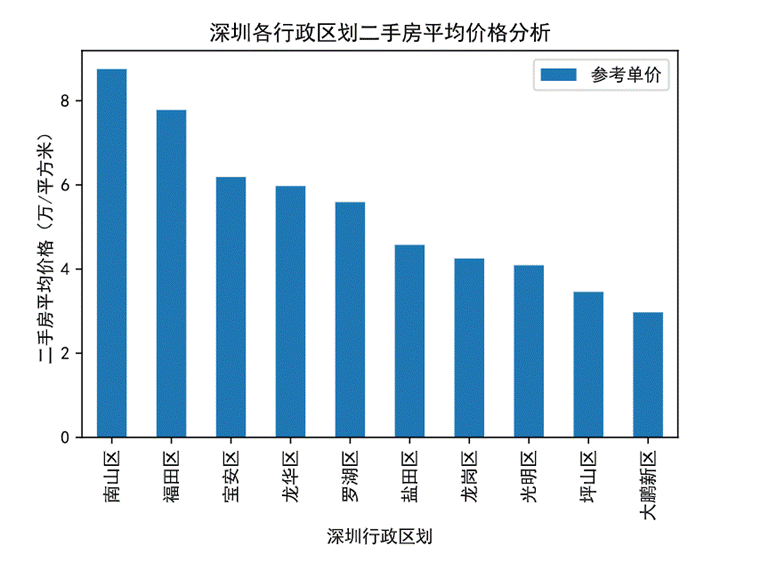
圖24 行政區劃對平均房價的影響柱狀圖
從統計結果可以看出南山區的均價最貴,超過8萬元/平方米,接下來是福安區7.7萬元/平方米左右,寶安區、龍華區和羅湖區,三者房價比較接近,在6-5萬元/平方米的區間內。
②各行政區劃二手房價格分析箱線圖

圖25 行政區劃對平均房價的影響箱線圖代碼
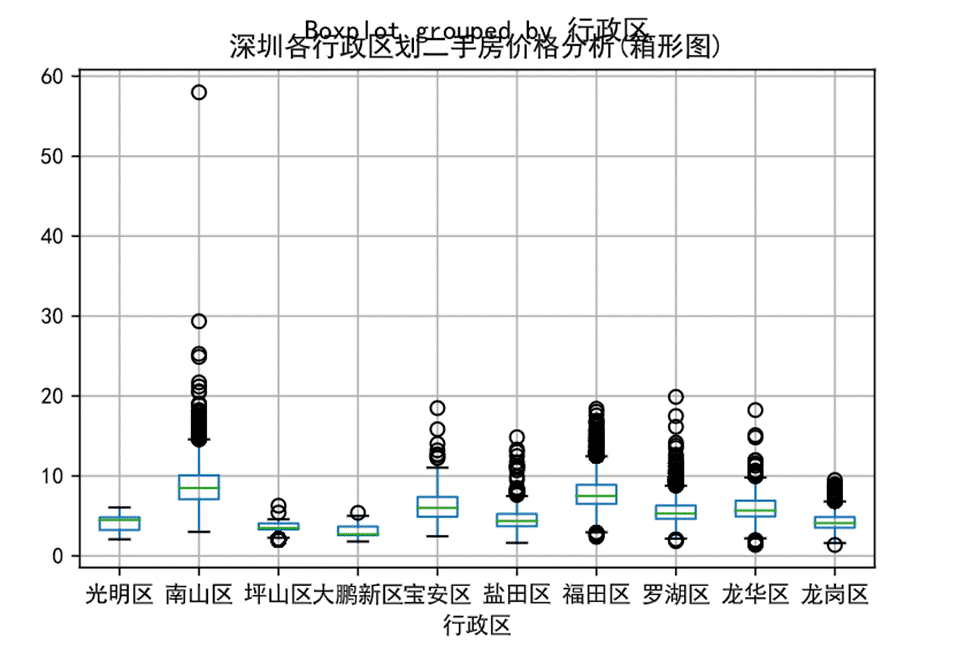
圖26 行政區劃對平均房價的影響箱線圖
從深圳各行政區劃二手房價格的箱型圖可以看出,南山區、鹽田區、福田區、羅湖區具有較多上側異常值,其中南山區最多。可想而知越靠近知名商圈的房價會特別貴。相反,深圳的周邊區劃異常值極少,如光明區沒有異常值,大鵬新區異常值為1,房價分布區間相對較小。
- 建筑面積對房價的影響
房屋面積在一定程度上反映了房屋類型。例如面積超過200平方米的房子很有可能是別墅,此類房屋往往在優質住宅區內,價格很有可能偏高。
首先查看參考單價隨房屋面積的分布,采用散點圖進行可視化:
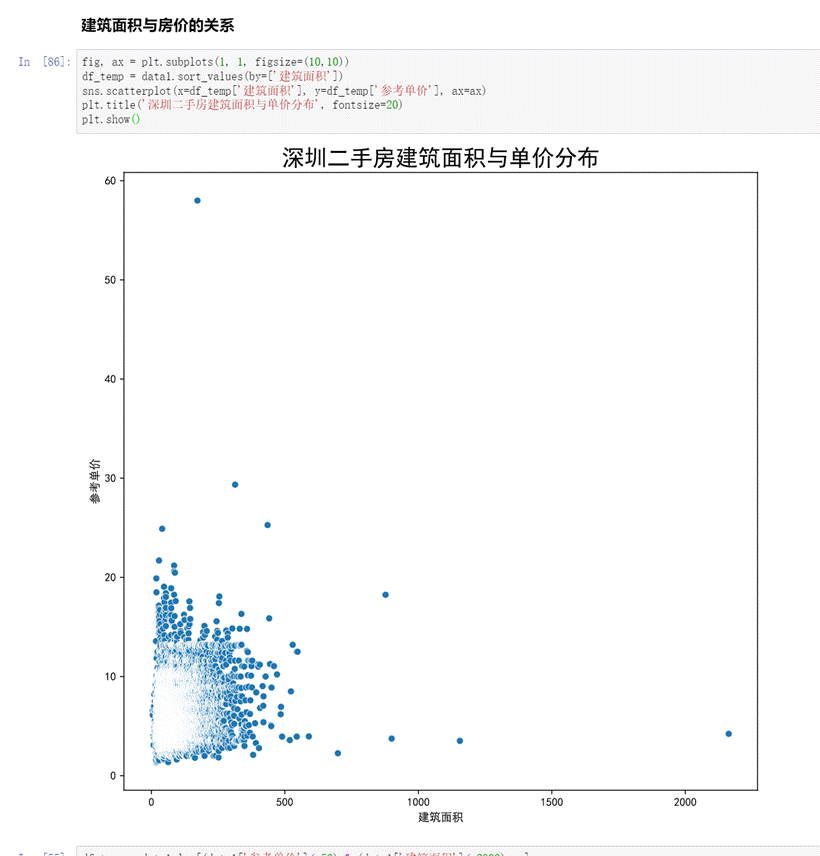
圖27 房屋面積對參考單價的影響散點圖
由上圖看出全部數據的散點圖分布較亂,看不到明顯的規律。結合前面行政區劃對房價的分析,猜想10個行政區內房價應該存在不同的分布規律,因此有必要區分各個行政區劃:

圖28 區分各個行政區劃
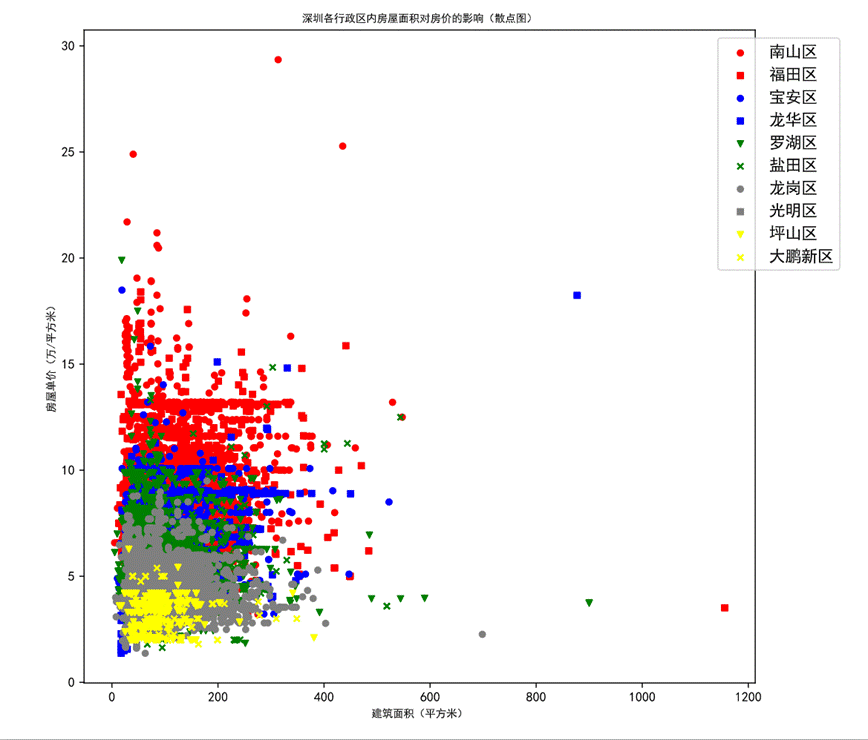
圖29 深圳各行政區內房屋面積對房價的影響(散點圖)
為了更好地體現各行政區劃房價分布的區別,將作圖范圍縮小,仍包含絕大部分數據。
圖例按照各行政區劃平均房價的順序排列,紅色為價格第一梯隊,藍色為價格第二梯隊,綠色為價格第三梯隊,灰色為價格第四梯隊,黃色為價格第五梯隊。每個梯度包含兩個行政區劃。從散點圖中可以明顯觀察到第一梯隊的紅色散點相對偏向左上方,第二梯隊藍色相比于第一梯度整體向下偏移,以此類推各個梯隊相比于上一梯隊整體向下偏移。
③為了更明顯地比較各行政區房屋面積對房價影響規律,對各區的散點進行最小二乘線性擬合。
導入優化模塊,作線性擬合:
圖30 線性擬合代碼
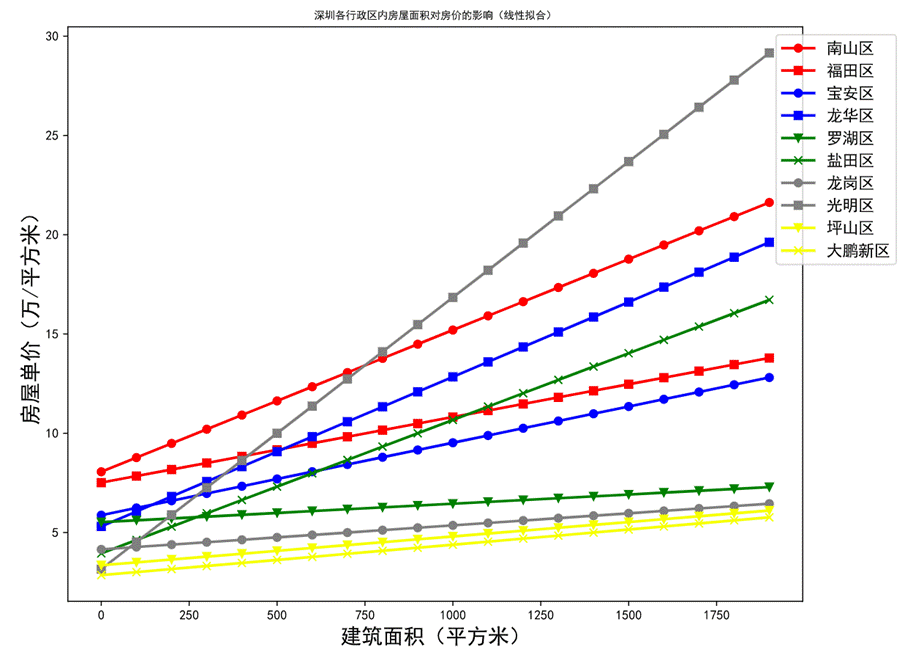
圖31 線性擬合結果圖
從線性擬合結果上來看,房屋單價隨房屋面積的變化規律與預期相符合,即平均房價越高的行政區劃,其房屋單價隨房屋面積變化的回歸線越偏向左上方。僅光明區和鹽田區存在例外,其回歸線的斜率較高。
房屋面積小時其房屋單價較低,符合預期;但隨著房屋面積增大,特別是超過200平方米后其房屋單價急劇上升。探討后認為,造成這種情況的主要原因是樣本量較少,導致一部分異常數據會顯著改變線性擬合的結果。
- 所在樓層對房價的影響
通過繪制三幅子圖分別是深圳二手房所在樓層的占比情況(餅圖)、各個行政區劃的中高樓層數量堆疊圖和各行政區劃低中高樓層的參考單價柱狀圖來分析。
圖32 所在樓層對房價的影響代碼
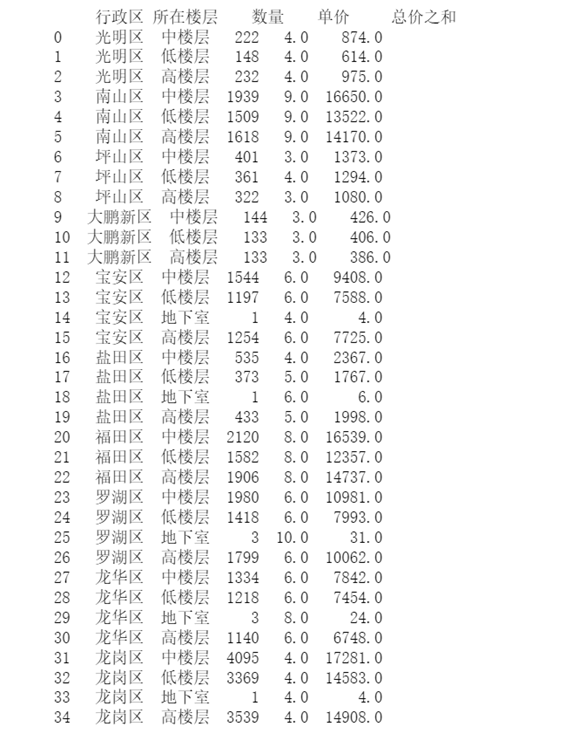
圖33 所在樓層對房價的影響結果
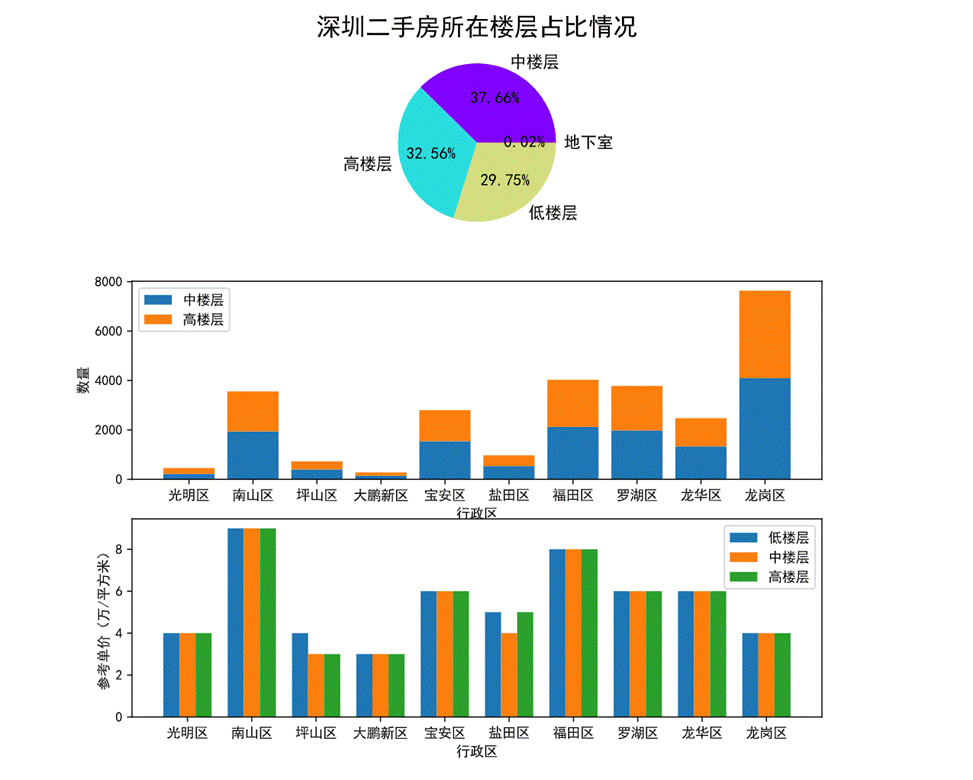
圖34 所在樓層對房價的影響可視化
首先通過第一幅餅圖可以看出,深圳二手房所在樓層的占比情況,中層占比最高達37.66%其次是高樓層占32.56%、低樓層占29.75%,最后地下室占0.02%。
通過第二幅堆疊圖可以看出各行政區劃中高樓層的占比情況及數量,基本上是各占一半。
第三幅柱狀圖可以看出低中高樓層在各個行政區劃的參考單價,其中南山區三種樓層的單價相近且最高,大鵬新區的三種樓層單價相近且最低。只有坪山區和鹽田區的三種樓層間的單價不太一致。
- 戶型結構對房價的影響
通過繪制兩幅子圖分別是深圳二手房戶型結構的占比情況(餅圖)、各行政區劃不同戶型結構的參考單價柱狀圖來分析。

圖35 戶型結構對房價的影響
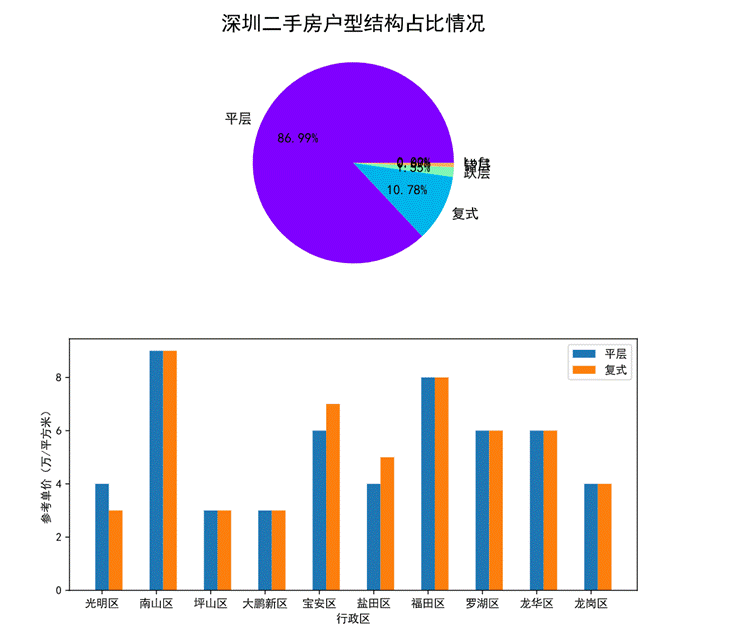
圖36 戶型結構對房價的影響可視化
通過第一幅餅圖可以看出深圳二手房戶型結構的整體占比情況,平層結構的存量居多,和第二名復式結構的比例大概是8:1,最后是錯層和躍層占比較低。這個數據也和現有普通開發商樓盤對應的戶型結構比例相近,因此我們主要分析平層和復式結構對房價的影響。
第二幅柱狀圖可以看出平層和復式在各個行政區劃的參考單價,其中南山區兩種結構戶型單價相近且最高,大鵬新區和坪山區的兩種結構戶型單價相近且最低。只有光明區、寶安區、鹽田區的三種樓層間的單價不太一致。此外還可以看出除了光明區 其他幾個區大多數都是復式價格大于平層。
- 建筑類型對房價的影響
通過繪制三幅子圖分別是深圳二手房建筑類型的占比情況(餅圖)、各個行政區劃的板塔結合和塔樓的數量堆疊圖和各行政區劃建筑類型的參考單價柱狀圖來分析。

圖37 建筑類型對房價的影響
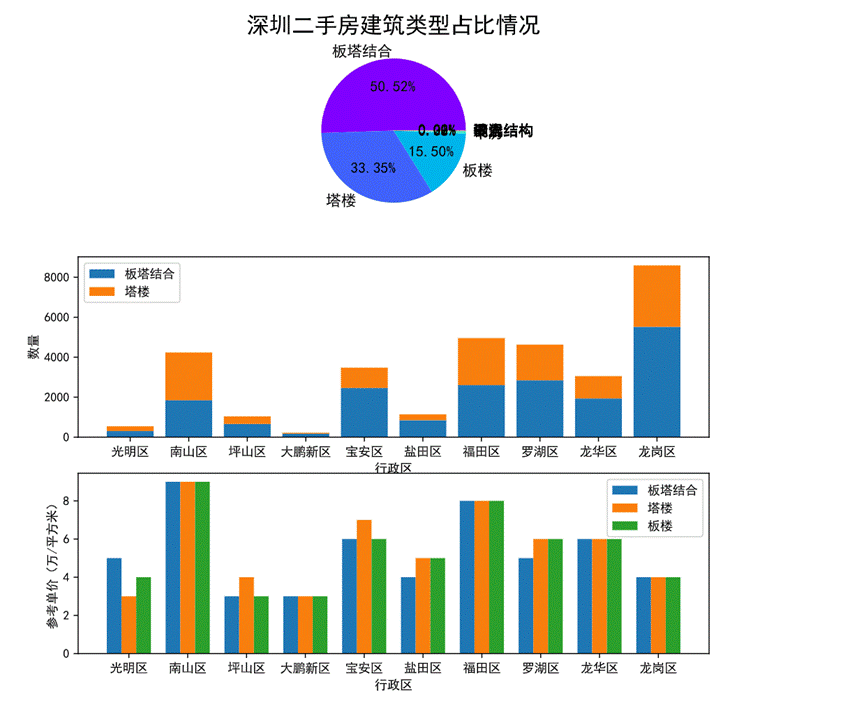
圖38 建筑類型對房價的影響可視化
首先通過第一幅餅圖可以看出,深圳二手房建筑類型整體的占比情況,板塔結合占比最高達50.52%其次是塔樓占33.35%、板樓占15.5%,平房、鋼混結構、混合結構等幾種占比較低。
通過第二幅堆疊圖可以看出各行政區劃中板塔結合和板樓兩種建筑類型的占比情況及數量。只有南山區的塔樓建筑類型比板塔結合類型多。
第三幅柱狀圖可以看出板塔結合、塔樓、板樓三中建筑類型在各個行政區劃的參考單價,其中南山區三種建筑類型的單價相近且最高,大鵬新區的三種建筑類型單價相近且最低。
- 建筑結構對房價的影響
通過繪制三幅子圖分別是深圳二手房建筑結構的占比情況(餅圖)、各個行政區劃的鋼混結構和框架結構的堆疊圖和各行政區劃不同建筑結構的參考單價柱狀圖來分析。

圖39 建筑結構對房價的影響
?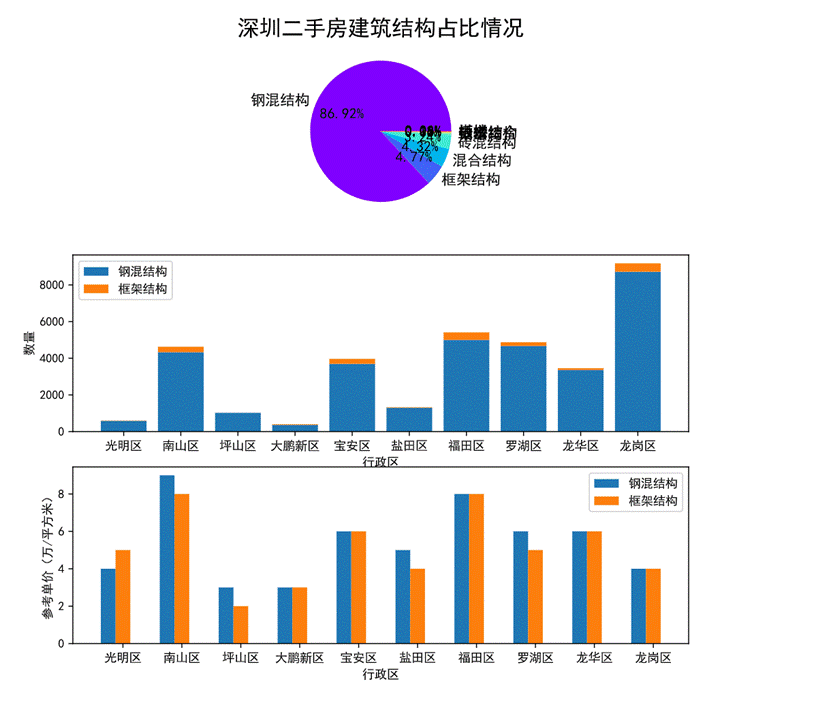
圖40 建筑結構對房價的影響可視化
第一幅餅圖可以看出,深圳二手房建筑結構整體的占比情況,鋼混結構占比最高達86.92%其次是框架結構占4.77%,這個數據也和現有建筑對使用的建筑結構相近。因此我們主要分析鋼混結構和框架結構對房價的影響。
通過第二幅堆疊圖可以看出各行政區劃中鋼混結構和框架結構兩種建筑結構的占比情況及數量,可以看出各個行政區劃的建筑結構基本上都是鋼混結構。
第三幅柱狀圖可以看出鋼混結構、框架結構這兩種建筑結構在各個行政區劃的參考單價,其中鋼混結構在南山區的參考單價最高,框架結構在南山區和福田區的參考單價相近且最高。此外只有光明區的鋼混結構單價高于框架結構單價。
- 抵押信息對房價的影響
通過繪制三幅子圖分別是深圳二手房抵押信息的占比情況(餅圖)、各個行政區劃有無抵押的堆疊圖和各行政區劃有無抵押的參考單價柱狀圖來分析。

圖41 抵押信息對房價的影響
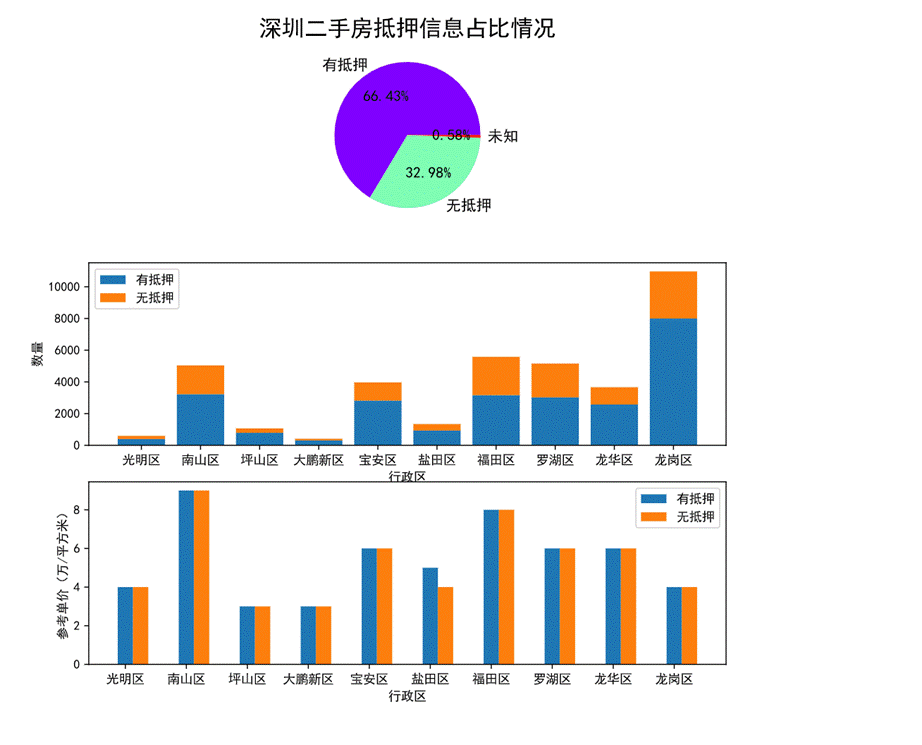
圖42 抵押信息對房價的影響可視化
第一幅餅圖可以看出有抵押的二手房是無抵押的兩倍,基本上每個房源都有明確的是否抵押信息。
第二幅堆疊圖可以看出福田區的無抵押的房源占比相比于其他行政劃區而言最高。
第三幅柱狀圖可以看出,只有鹽田區的有抵押房源單價高于無抵押的房源單價,其余行政劃區有無抵押的房源單價均相近。
- 房屋年限對房價的影響
通過繪制三幅子圖分別是深圳二手房房屋年限的占比情況(餅圖)、各個行政區劃有房屋年限堆疊圖和各行政區劃有房屋年限的參考單價柱狀圖來分析。

圖43 房屋年限對房價的影響
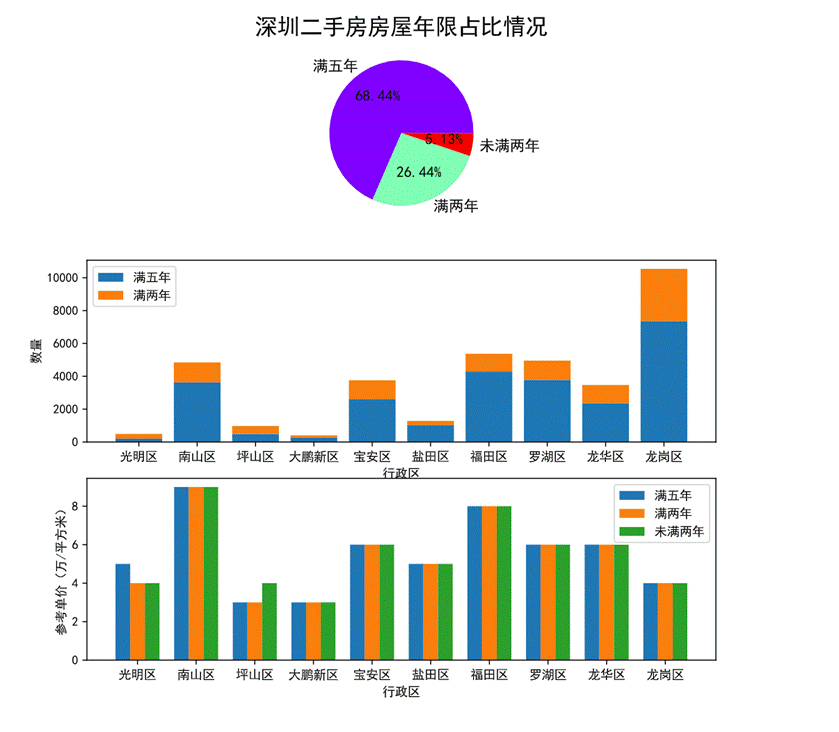
圖44 房屋年限對房價的影響可視化
通過第一幅餅圖可以看出深圳二手房的房屋年限已滿五年的占比達68.44%超過整體房源的一半,其次是滿兩年的占整體的26.44%,未滿兩年的僅占5.13%。
第二幅堆疊圖展現了各個行政區劃房屋年限滿五年和滿兩年的占比及數量。其中鹽田區房源滿五年的占比最高。可以看出鹽田區相比于其他行政區劃舊樓要多一點。
第三幅柱狀圖展現了各個行政區劃不同房屋年限的參考單價,其中南山區不論房屋年限多少參考單價都相近且最高,光明區滿五年的參考單價比其他兩種高,坪山區未滿兩年的房屋單價比其他兩種高。
- 裝修情況對房價的影響
通過繪制三幅子圖分別是深圳二手房裝修情況的占比情況(餅圖)、各個行政區劃有裝修情況堆疊圖和各行政區劃有裝修情況的參考單價柱狀圖來分析。
圖45 裝修情況對房價的影響
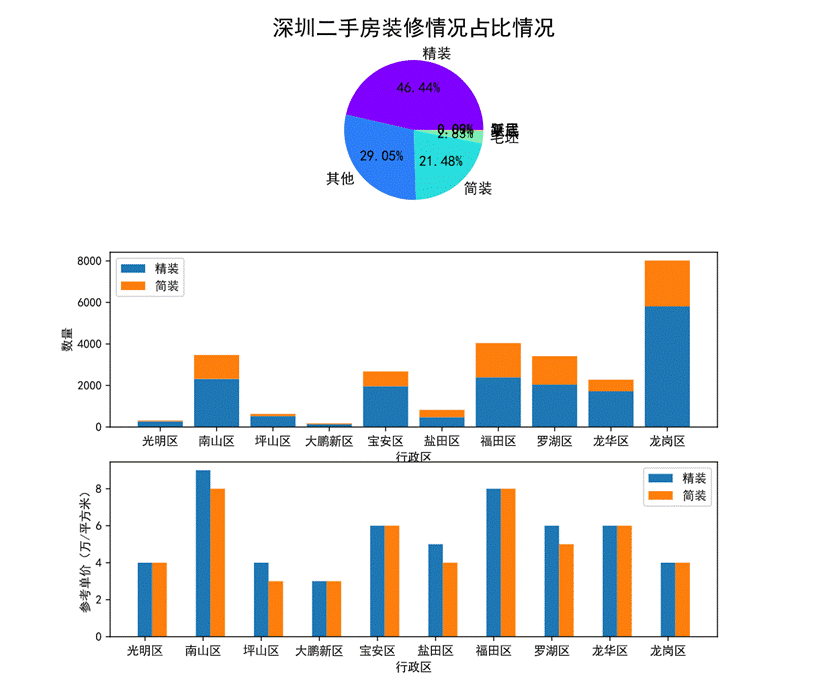
圖46 裝修情況對房價的影響可視化
第一幅餅圖展現了深圳二手房裝修情況的占比,精裝房源將近占整體的一半(46.44%),有29.05%的房源并未說明裝修情況,21.48%的房源是簡裝。
第二幅堆疊圖展現了各行政區劃精裝和簡裝的房源數量及占比,其中光明區的房源基本都是精裝,福田區簡裝的房源占福田區整體房源比例最大。
第三幅柱狀圖可以看出各個行政區劃簡裝和精裝的參考單價,南山區的精裝參考單價最高,對于簡裝的單價福田區和南山區相近且最高。
- 配備電梯對房價的影響
通過繪制三幅子圖分別是深圳二手房是否配備電梯的占比情況(餅圖)、各個行政區劃是否配備電梯情況的堆疊圖和各行政區劃是否配備電梯的參考單價柱狀圖來分析。

圖47 配備電梯對房價的影響
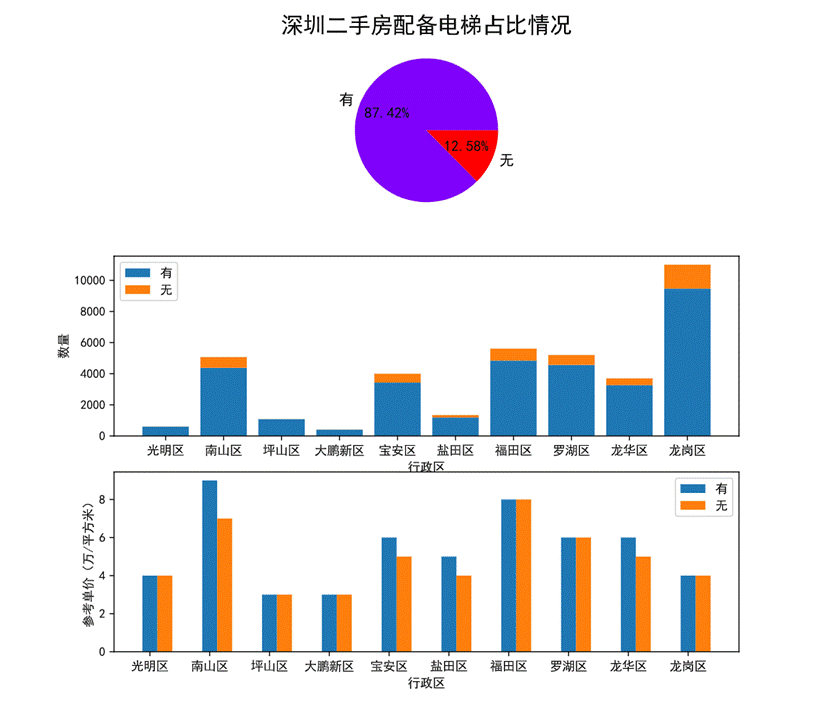
圖48 配備電梯對房價的影響可視化
第一幅餅圖展示了深圳二手房是否配備電梯的比例情況,可以看出大部分房源都是配備了電梯的,與沒有配備電梯相比接近9:1的比例。
第二幅圖堆疊圖可以看出各個行政區劃是否配置電梯的數量及比例,光明區、坪山區、大鵬新區的房源基本上都有電梯。
第三幅圖柱狀圖展示了各個行政區劃是否配置電梯的參考單價,南山區兩者的參考單價懸殊較高可以看出南山區配置了電梯的房源的參考價格高于其他所有地區的價格,屬于繁華地段。
- 深圳二手房房屋戶型占比情況
繪制餅圖如下所示。

圖49 深圳二手房房屋戶型占比情況
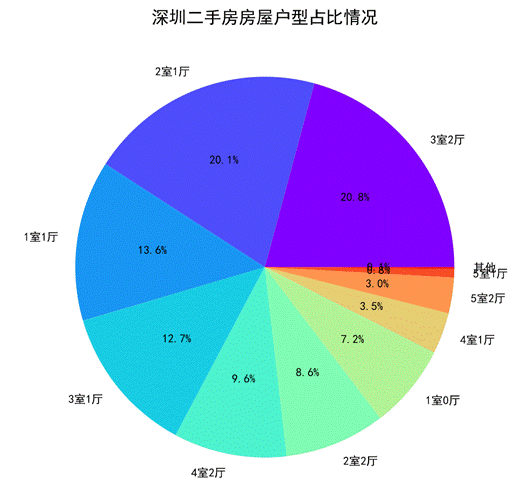
圖50 深圳二手房房屋戶型占比餅圖
通過餅圖展示的深圳二手房房屋戶型占比情況可以看出,2室1廳和3室2廳這種房源比較普遍,也比較符合當下的社會需求。5室1廳和5室2廳的房源較少,這種戶型可能不太適用。
- 深圳二手房所在樓層占比情況
繪制柱狀圖如下。

圖51 二手房所在樓層數量分布
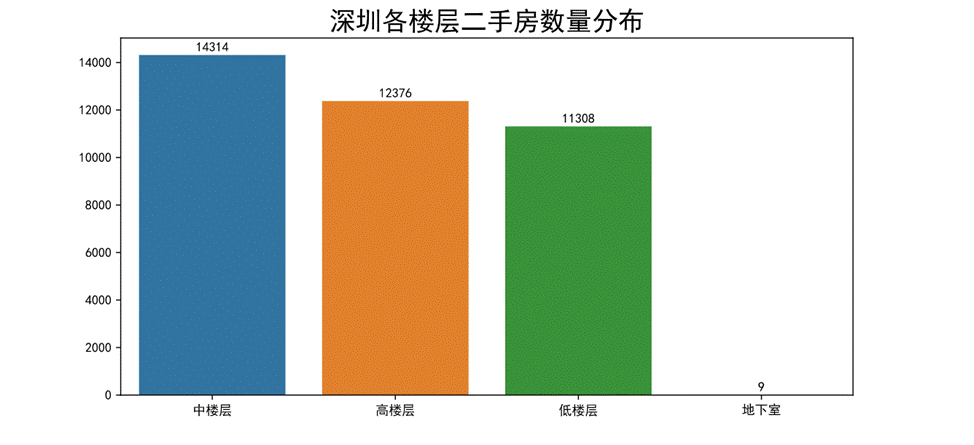
圖52 二手房所在樓層數量分布柱狀圖
通過柱狀圖可以看出深圳二手房樓層為中樓層的房源數目較多,高樓層和低樓層的房源數目相差不大,地下室的數目極少幾乎沒有這種房源。
- 深圳二手房房屋朝向分布情況
繪制柱狀圖如下。

圖53 二手房房屋朝向的占比情況
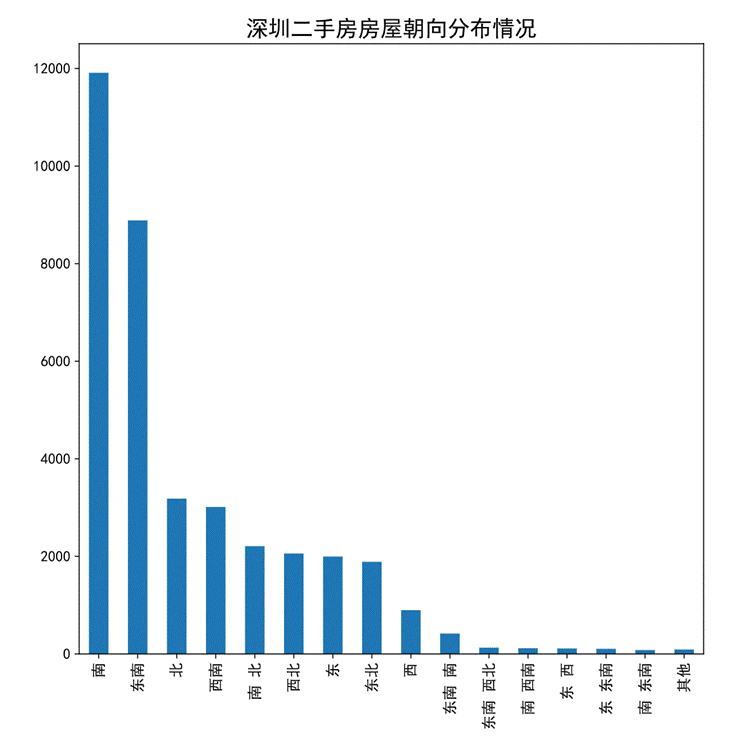
圖54 二手房所在樓層占比情況柱狀圖
通過柱狀圖可以看出,房屋朝向為南的數目最多,其次為東南朝向,朝向為北和朝向為西南的房源數目相近,朝向為南北、西北、東、東北的數目相近,縱觀整個圖以指數遞減的趨勢。
- 深圳各區域二手房平均單價

圖55 二手房平均單價
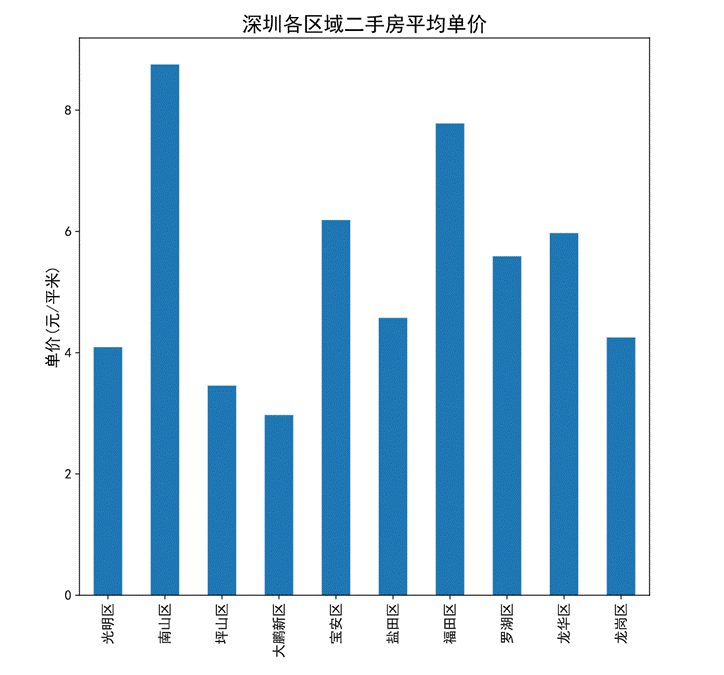
圖56 二手房平均單價柱狀圖
通過柱狀圖可以看出深圳二手房的單價從高到底依次是南山區,福田區,寶安區,龍華區,羅湖區,鹽田區,龍崗區,光明區,坪山區最后是大鵬新區。可以看出南山區較為繁華房價較高,與大鵬新區相比單價差距較大。
- 結論
上述探索式分析主要從七大方面來展開,分別是整體房價分析、地理因素對房價的影響、房屋類型(再細分為建筑面積、所在樓層、戶型結構、建筑結構、建筑類型、抵押信息、房屋年限、裝修情況、配備電梯九大因素)對房價的影響,以及深圳二手房房屋戶型占比情況、朝向分布情況、所在樓層分布情況、平均房價占比情況。
整體房價分析得出深圳二手房的最高價格超過50萬元/平方米,最低價格不高于2萬元/平方米,差距極大,房價的平均數和中位數均在5-6萬元/平方米。
通過探討九種不同房屋類型因素對房價的影響,南山區的參考單價無論在是何種因素下都位列第一,屬于繁華地段。相反,大鵬新區的參考單價基本上均是最低。總的來說對房價影響較大的因素有六個分別是行政區、建筑面積、戶型結構、裝修情況、配備電梯、建筑結構。
對于戶型而言,2室1廳和3室2廳這種房源比較普遍,也比較符合當下的社會需求。5室1廳和5室2廳的房源較少,可能不太適用。因此通過滿足不同個人或家庭對于戶型的需求,對于房屋均價較高的深圳而言,2室1廳足夠滿足大部分家庭的需要,因此較受歡迎。
對于朝向而言,房屋朝向為南的數目最多,其次為東南朝向。根據歷史情況而言,從古至今,坐北朝南都是公認的最好的朝向,朝南房間明亮一些,干燥些,朝北的房子陰暗潮濕一點,因此房屋朝向為南的房屋數目最多,也比較隨主流。
對于二手房樓層而言,中樓層的房源數目較多,高樓層和低樓層的房源數目相差不大。在現實生活中,如果樓層過高,停水停電會很麻煩,太低會很潮濕,終日見不到陽光。
對于平均單價而言,從高到底依次是南山區,福田區,寶安區,龍華區,羅湖區,鹽田區,龍崗區,光明區,坪山區最后是大鵬新區。
四、數據分析模型
- 結合分析的目標,擬采用哪一種模型(如聚類、分類、回歸)開展分析
綜合考慮多個因素對房價的影響,并建立預測模型。通過對數據進行一系列的分析,選擇對房價有明顯影響的6個因素(行政區、建筑面積、戶型結構、裝修情況、配備電梯、建筑結構)。
因為預測目標—房價是一個連續變量,所以本實驗中的房價預測屬于一個回歸問題。
常見的機器學習回歸模型有線性回歸、K近鄰、支持向量機、回歸樹和隨機森林等。本次實驗選用三類模型分別是線性回歸、支持向量機和隨機森林來進行對房價的預測。
- 模型評估
選用的模型是線性回歸、支持向量機和隨機森林三種模型。在訓練模型和預測完成后,需要對模型的預測效果進行評價。常用的評價指標有:平均絕對誤差(mean_absolute_error)、均方誤差(mean_squared_error)、中位數絕對誤差(median_absolute_error)、解釋方差得分(explained_variance_score)以及R方得分(r2_score)。
本次實驗使用均方誤差和R方得分兩個指標,期望均方誤差盡量低,R方得分盡量高。
- 可視化結果
- 對數據進行了一系列的分析,所選的因素均對房價有明顯影響,并且所有數據不存在缺失現象。但行政區劃為文字,所以需要使用one-hot編碼,one-hot編碼是將定類的非數值型類型量化的一種方法,在pandas中使get_dummies() 方法實現。

圖57 one-hot編碼
使用one-hot編碼修改特征“行政區”、“戶型結構”、“裝修情況”、“配備電梯”、“建筑結構”后結果如下:
圖58 編碼結果
繪制熱力圖結果如下所示。

圖59 繪制熱力圖
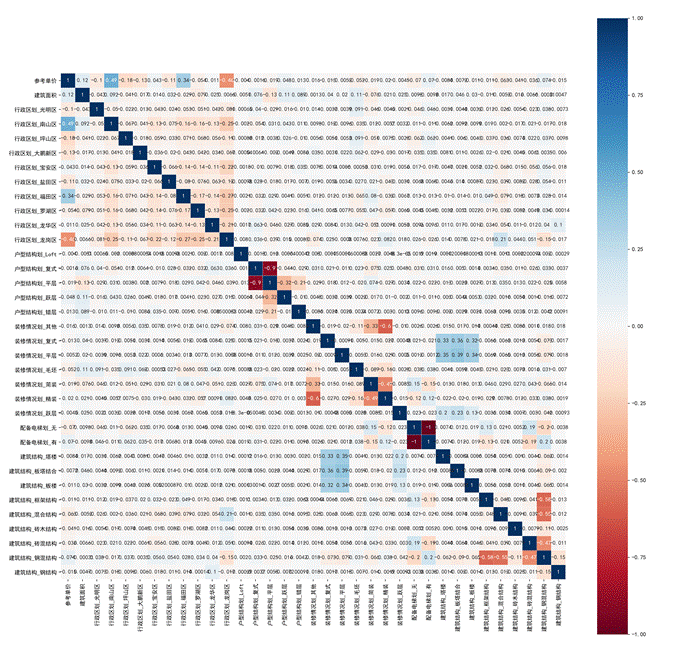
圖60 熱力圖
可以根據顏色觀察特征的相關性。顏色偏紅或者偏藍都說明相關系數較大,即兩個特征對于目標變量的影響程度相似,也就是說存在嚴重的重復信息,會造成過擬合現象。通過特征相關性分析,可以找出哪些特征有嚴重的重疊信息,然后擇優選擇。
- 確定數據中的特征與標簽、數據分割,隨機采樣25%的數據作為測試樣本,其余作為訓練樣本,最后進行數據標準化處理。

圖61 分割及標準化
- 使用線性回歸模型預測
圖62 線性回歸模型預測
- 使用支持向量機模型預測

圖63 支持向量機模型預測
- 使用隨機森林回歸

圖64 隨機森林回歸
- 本實驗中調用均方誤差MSE和R方得分兩個指標,期望均方誤差盡量低,R方得分盡量高:
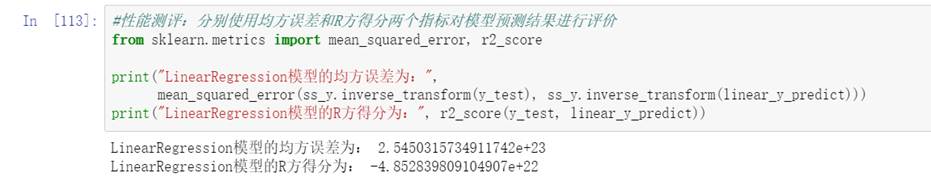
圖65 線性回歸模型R方

圖66 支持向量機模型R方

圖67 隨機森林模型R方
通過比較三種回歸模型的兩種評價指標的結果,可以看出,R方得分與均方誤差成負相關關系,因此只看一個指標即可。R方得分越高,模型的預測能力越強。則本實驗中所用到的回歸模型中隨機森林回歸模型的預測能力最強。
(7)為能更加直觀地對比不同模型的預測能力,下面對線性回歸模型、支持向量機模型、隨機森林回歸預測結果進行可視化處理。
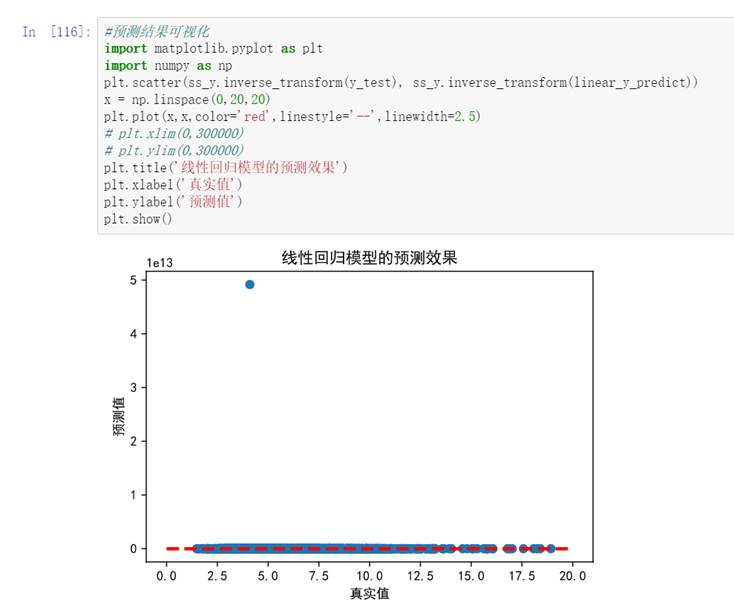
圖68 線性回歸模型預測效果
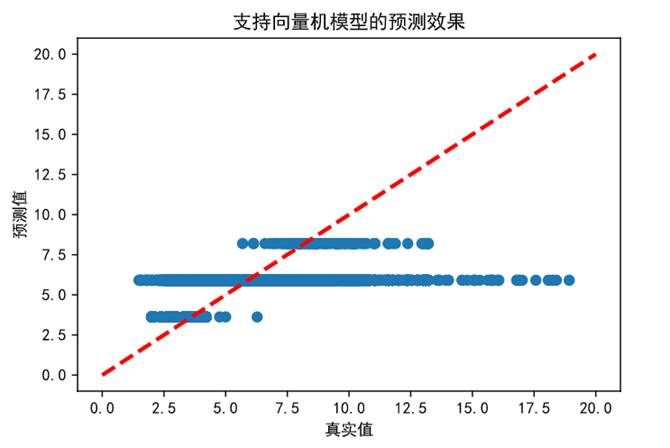
圖69 支持向量機模型預測效果
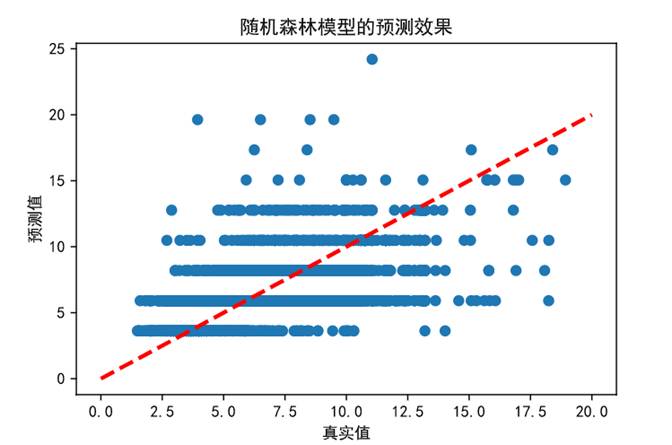
圖70 隨機森林模型預測效果
上幅圖隨機森林回歸模型在低房價區間預測效果較好,但隨著房價超過14萬元/平方米后預測值偏低。
五、方案評估
本次課程設計達到了預期的目標,完成了所有設計任務,體現在四個方面分別是明確分析目標與任務、進行數據預處理、數據探索分析(七大方面)、數據分析模型。課程設計可以說是一門課程的總結,設計難度中等,仍存在著一些問題,在爬取數據時,有些數據的字段位置錯亂,數量較少,故我們直接將它刪除,可能預測結果的準確性會略微降低一點。并且在進行探索分析的時候,有的字段對房價影響不大,有的字段影響較大,對于影響不那么明顯的字段我們也選取了來進行預測,可能會出現問題。最后存在的問題是在使用隨機森林模型預測的時候R方只有0.3左右,過于低,預測效果很不好,需要進行進一步檢查以及優化。



















