一、引言
在前序課程中,我們系統剖析了多模態理解大模型(Qwen2.5-VL、DeepSeek-VL2)的架構設計。鑒于此類模型訓練需消耗千卡級算力與TB級數據,實際應用中絕大多數的用戶場景均圍繞推理部署展開,模型推理的效率影響著用戶的實際體驗。本次將聚焦工業級部署的核心挑戰——多模態理解大模型的高性能推理優化。
飛槳(PaddlePaddle)作為國內領先的深度學習框架,在多模態模型的高性能推理方面具有顯著優勢和亮點:
- 高效的推理引擎:飛槳提供了高性能推理引擎,能夠以低比特量化壓縮等方法加速多模態模型的推理過程。
- 優化的計算算子:飛槳通過算子融合、高效KVCache的注意力算法,使得多模態大模型能夠在有限的硬件資源下實現高性能推理。
基于飛槳的高效引擎與算子優化,飛槳多模態開發套件PaddleMIX中實現了多種先進多模態理解模型的高性能推理,支持了Dense架構的Qwen2.5-VL模型以及采用稀疏激活機制的MoE架構的DeepSeek-VL2模型。我們在密集激活Dense模型與稀疏激活MoE架構均有性能優勢,在單張圖像的BF16精度推理相較于開源框架vLLM最高可提升40%的解碼速度!
接下來,本篇文章內容將對飛槳多模態開發套件 PaddleMIX 中多模態理解模型的高性能推理實現方案進行逐步解讀。
二、高性能推理優化方案
2.1 飛槳通用優化策略
低比特權重量化技術:權重量化(Weight Quantization)是一種模型壓縮和加速技術,通過降低模型權重的數值精度(如從 32 位浮點數轉為 8 位整數),顯著減少模型大小和計算量,同時盡量保持模型精度。PaddleMIX的高性能推理支持INT4、INT8權重量化技術,通過利用低比特的運算能力進一步對模型推理的過程加速。
多卡并行推理:如今深度學習模型包含的參數量已經億級別,單張顯卡或單個主機難以進行部署,PaddleMIX基于飛槳自研分布式并行功能實現對多模態大模型的分布式推理,支持張量并行(Tensor Parallelism)策略。張量并行通過切分張量計算,將模型計算任務分配到多個顯卡設備上,從而降低每個設備的顯存壓力。其中圖1為基于張量并行的MLP層進行前向計算示意圖,對一個輸入張量 X 經過權重 A 的線性層進行投影,將線性層權重矩陣切分成四份(A1,A2,A3,A4),分別在四個設備上進行X的特征投影,最后將各張顯卡上的計算結果通過all_reduce操作匯總得到與非張量并行方式的等價結果。
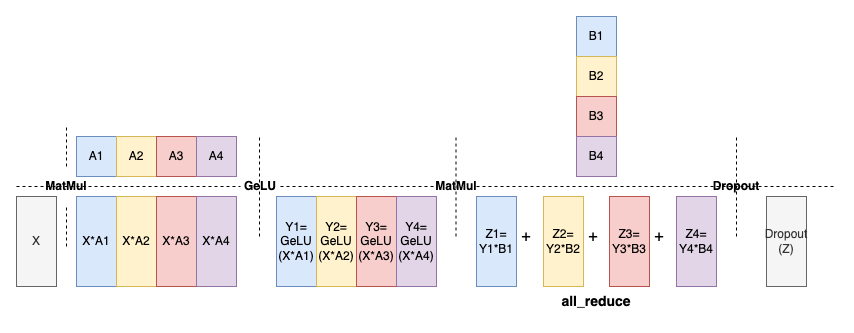
圖1 基于張量并行的MLP層計算示意圖
2.2 Qwen2.5-VL 高性能推理
首先簡單回顧下 Qwen2.5-VL 的網絡結構,整體上還是經典的 ViT + LLM 的串聯結構,采用 600M 參數量的 ViT 作為視覺編碼器,并且支持圖像和視頻統一輸入,語言模型使用Qwen2.5系列的各種模型大小版本。PaddleMIX套件在Qwen2.5-VL的高性能優化方案中將視覺與語言模型兩部分單獨優化。視覺模型采用FlashAttention-2的優化方案加速,針對高耗時的語言模型進行細粒度的推理優化:
2.2.1 高性能算子融合
目前主流深度學習框架的默認推理模式采用動態圖推理,算子將按順序逐行執行,默認不自動融合相鄰操作。主要存在兩個問題:一是需要保存更多的中間結果內存開銷增加;二是頻繁在顯存讀寫,導致計算效率下降。在推理部署階段,未融合的動態圖效率極低,尤其是長序列生成(如大模型語言模型的逐Token解碼)。
為此PaddleMIX套件對Qwen2.5結構的注意力計算、全連接層的注意力計算進行算子融合,從而顯著提升多模態大模型的推理效率。
- 注意力算子融合:Qwen2.5語言模型的推理過程,注意力計算中額外新增RoPE位置編碼、KVCache等技術,可以將RoPE應用到Q、K和緩存K、V操作合并到注意力計算過程,減少GPU訪問和計算開銷,顯著提升推理速度
- FFN算子融合:Qwen2.5語言模型FFN層中包含兩個線性投影以及SwiGLU激活函數,其中SwiGLU計算公式為 SwiGLU ( x , W , V , b , c , β ) = Swish β ( x W + b ) ? ( x V + c ) \text{SwiGLU}\left(x, W, V, b, c, \beta\right) = \text{Swish}_{\beta}\left(xW + b\right) \otimes \left(xV + c\right) SwiGLU(x,W,V,b,c,β)=Swishβ?(xW+b)?(xV+c),x為輸入特征,W、V為線性層的投影矩陣,b、c是線性層的偏置項。我們可以將W、V兩個線性層權重拼接,將兩個線性層的矩陣乘法融合成一次矩陣乘法計算然后再去調用SwiGLU激活函數。
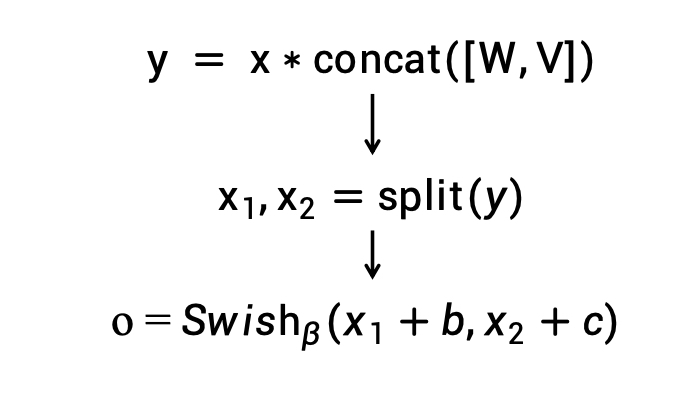
圖2 融合后的SwiGLU算子
2.2.2 高效的注意力算法:
傳統的多頭注意力Multi-Head Attention(MHA) 每個Query有獨立的Key和Value投影,Qwen2.5-VL語言模型結構中使用Group Query Attention(GQA)將Query頭分組,組內共享Key和Value投影,這種設計降低顯存占用,優化了KVCache緩存的KV數量。PaddleMIX基于自研AppendAttention算子加速語言模型部分的GQA注意力計算,實現了高效的KVCache管理、注意力并行計算算法。
- 高效RoPE融合與KVCache管理:考慮到RoPE位置編碼添加屬于浮點運算密集型操作,AppendAttention算子中使用CUDA Core實現位置編碼添加到并行計算,同時利用CUDA提供并行存儲機制將寄存器中融合編碼后的KV寫入全局內存中,從而加速了RoPE位置編碼與QKV的融合。
- GQA并行加速:AppendAttention中基于Tensor Core實現對GQA的注意力加速,使用NVIDIA GPU 提供的 PTX 內聯匯編指令對分塊后的矩陣進行加速運算,從而取得極致的矩陣乘法運算加速。
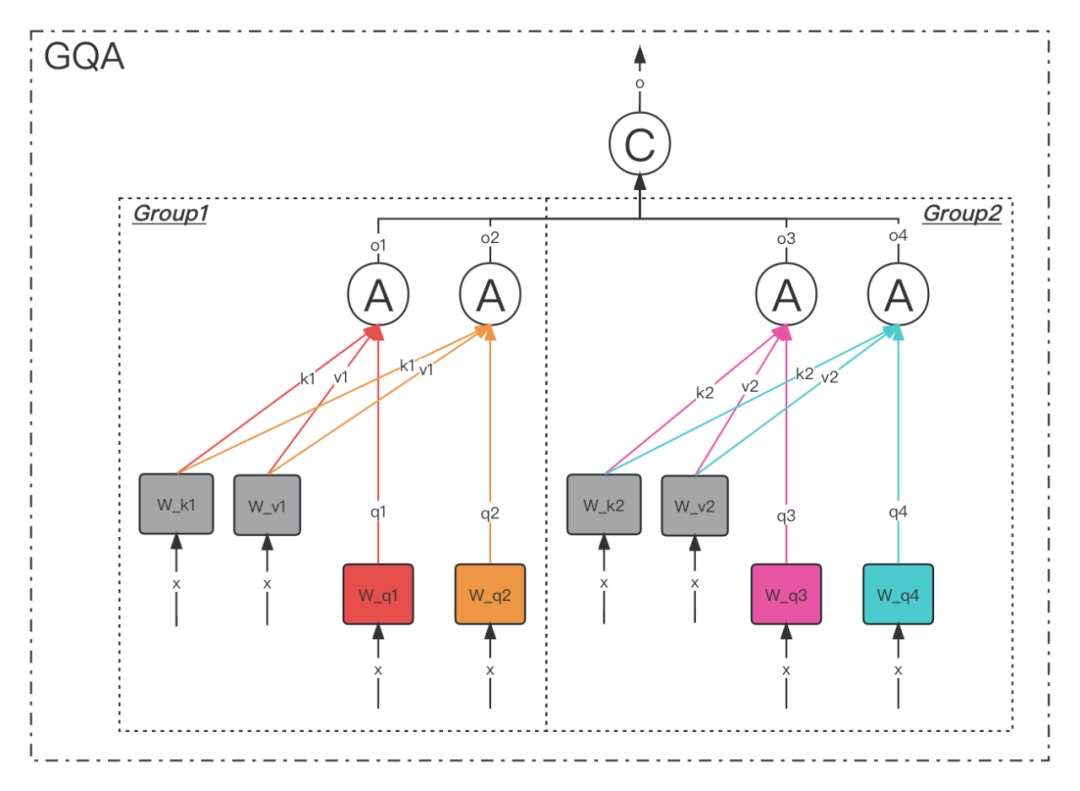
圖3 Group Query Attention 示意圖
2.2.3 Token拒絕采樣推理生成加速:
在多模態大語言模型每一步需要計算整個詞表的概率分布(Softmax),并采樣下一個Token。這一過程計算成本高,尤其是當詞表規模大時(如數萬Token),PaddleMIX套件采用Token 拒絕采樣改進Token采樣策略,減少排序等高耗時操作加速Token的采樣速度。
1.Token拒絕采樣加速的核心思想:
- 提前拒絕低概率Token:在Softmax完全計算前,通過閾值或啟發式方法過濾掉明顯低概率的候選Token,僅對高概率Token進行精確計算。
- 平衡速度與質量:通過動態調整拒絕閾值,在加速生成的同時,避免顯著影響生成文本的多樣性或合理性。
2.拒絕采樣優勢:
- 避免全量排序:傳統Top-k采樣需對所有Token排序,而拒絕采樣僅需一次閾值比較,減少計算量。
- 并行計算優化:結合GPU硬件加速,對Logits進行批量篩選。
2.2.4 Qwen2.5-VL 高性能效果展示
基于上述優化,我們展開與業內主流解決方案的性能測評。Qwen2.5-VL模型的推理時延評測環境使用單卡A800 GPU進行,與現有主流開源框架PyTorch、vLLM進行性能比較。對于不同框架,我們都采用相同的圖像、視頻和文本作為輸入,具體實驗設置參考文末項目地址進行推理復現。
首先是單張圖像推理,飛槳的BF16推理每秒輸出token數目相較于vLLM框架在Qwen2.5-VL-3B-Instruct和Qwen2.5-VL-7B-Instruct模型分別提升20%和46%,值得注意的是Qwen2.5-VL-3B-Instruct模型在8bit權重量化設置下解碼速度高達155Token/s,取得了極致的推理性能。
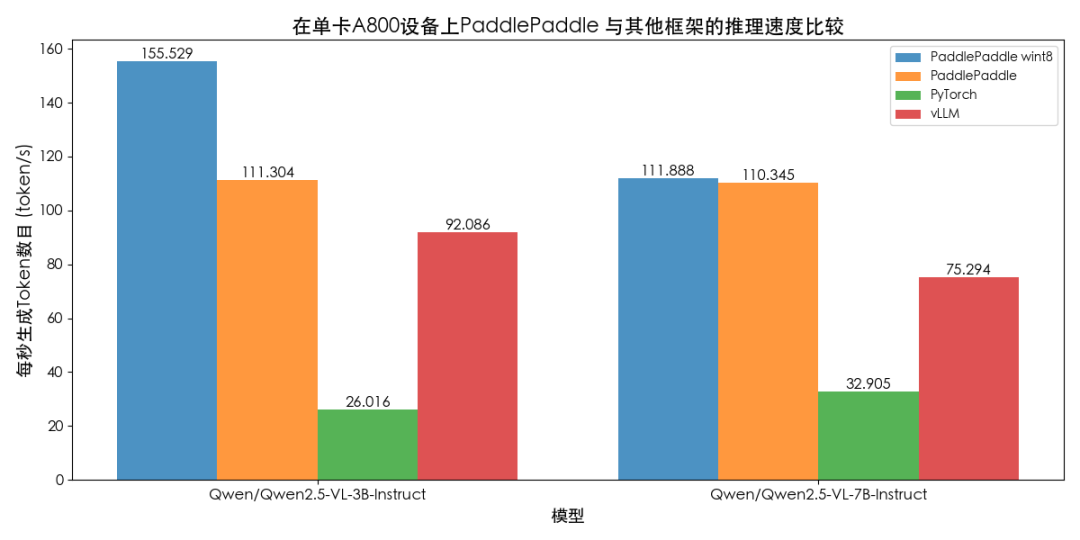
圖4 Qwen2.5-VL模型單圖測速對比
Qwen2.5-VL同樣支持視頻輸入,我們進一步評估視頻處理的推理性能。飛槳的BF16推理解碼速度相較于vLLM框架在Qwen2.5-VL-3B-Instruct和Qwen2.5-VL-7B-Instruct模型分別提升110%和33%。8bit權重量化技術帶來顯著性能提升,8bit的解碼速度(token/s)相比Paddle BF16精度推理在3B和7B上分別提升29%、33%。
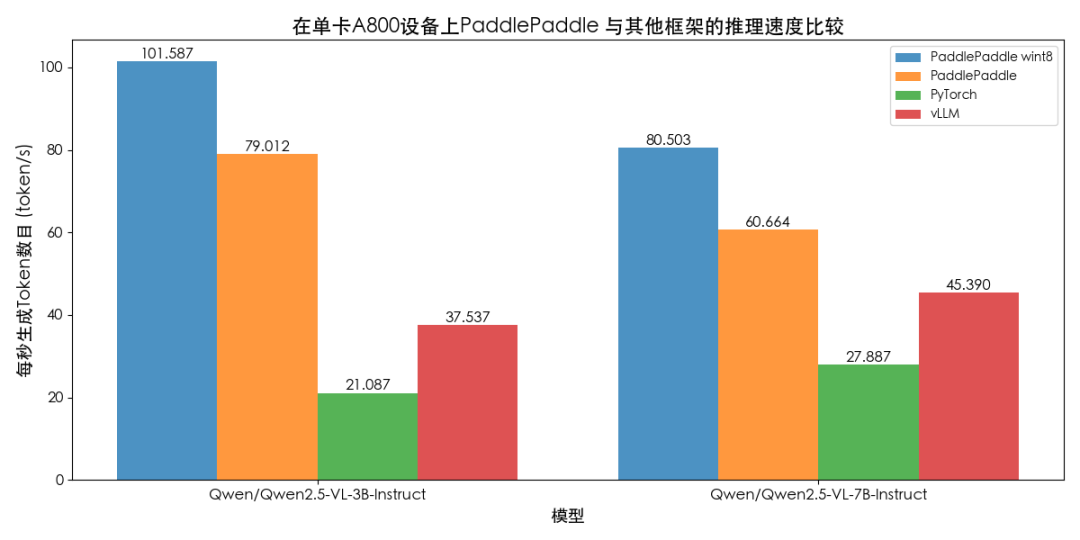
圖5 Qwen2.5-VL模型單視頻測速對比
2.3 DeepSeek-VL2 高性能推理
2.3.1 優化方案解讀
DeepSeek-VL2 的結構也是由三部分核心模塊組成:視覺編碼器 Vision Encoder、視覺-語言適配器 VL Adaptor 和 DeepSeek-MoE 語言模型。DeepSeek-VL2 在視覺編碼器和語言建模部分都有了顯著提升,這主要是因為DeepSeek-VL2引入了兩項重大改進:動態切片策略,以及采用多頭潛在注意力(Multi-head Latent Attention,MLA)機制的 DeepSeek-MoE 語言模型。這些創新使得 DeepSeek-VL2 能夠更高效地處理高分辨率視覺輸入和文本數據。

圖6 DeepSeek-VL2 架構
PaddleMIX對DeepSeek-VL2的語言模型進行高性能優化,總結如下:
1.高效MLA機制
- 通過多級流水線編排、精細的寄存器及共享內存分配,深度調優MLA算子性能,性能優于業內方法FlashMLA。
2.長序列注意力機制量化加速
- 長序列推理,由于自注意力機制計算復雜度與Token序列長度的平方成正比,量化和稀疏都能取得非常好的加速。飛槳框架3.0大模型推理集成了自注意力動態量化方案SageAttention,在精度近乎無損的基礎上,實現了長序列輸入Prefilling階段的高性能注意力計算。
- 如下圖7所示,SageAttention通過動態的將Q、K矩陣量化為INT8,V矩陣量化為FP8來重新組織注意力計算各階段的數據類型;在Softmax階段先將INT32的QK轉換為FP32,之后進行QK的反量化,再采用Online Softmax加速計算;將Softmax后的注意力權重P量化為FP8,與經過FP8量化的V矩陣相乘,之后在進行對V的反量化,得到Attention的計算結果O。上述兩次量化和反量化過程**在保證精度的前提下,大幅度提升了注意力計算的性能****。**
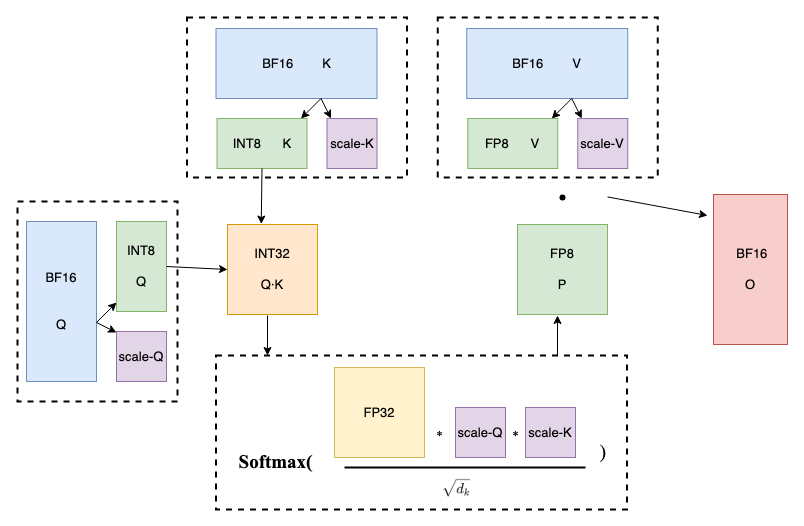
圖7 SageAttention量化流程
2.3.2 高性能展示
在講解完DeepSeek-VL2的優化策略,我們采取與Qwen2.5-VL相同的環境進行測試,樣例覆蓋單圖、多圖測試。 DeepSeek-VL2-small 是一個16B總參數量3B激活參數的混合專家模型,這在推理部署上添加了更大難度。得益于飛槳的高效推理引擎與先進優化策略,我們的BF16推理速度與PyTorch動態圖推理相比提升3倍以上,相較于vLLM框架提升10%!
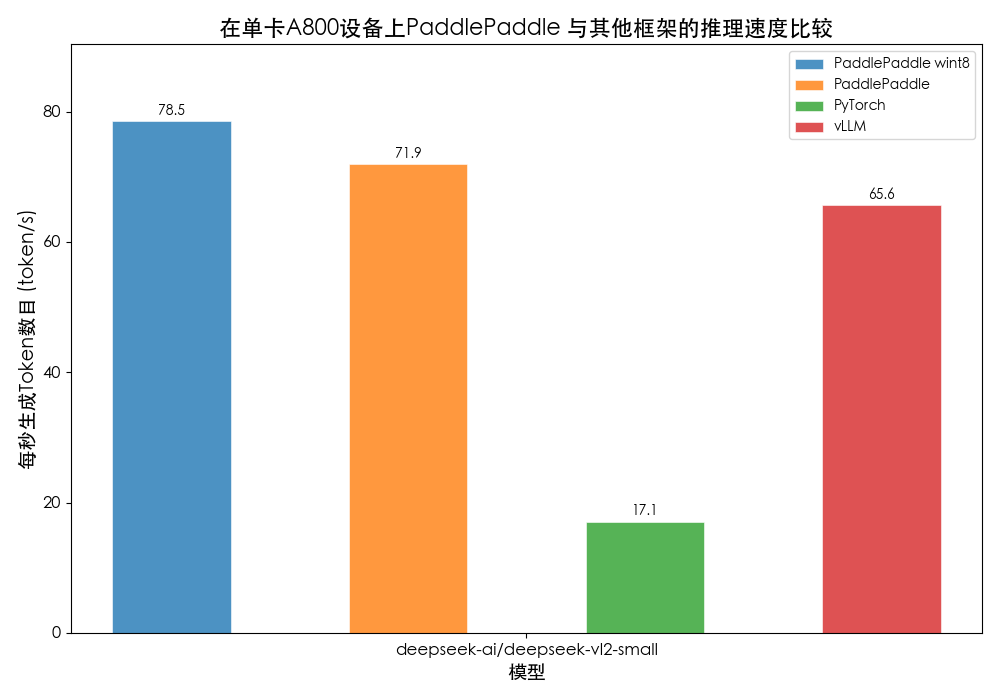
圖8 DeepSeek-VL2模型單圖測速對比
我們在多張圖像推理評測上也極具競爭力,飛槳的BF16精度推理每秒輸出token數目相較于vLLM提升11%。其中Paddle 8bit權重量化方法的解碼速度在相同設置下最優,平均一秒輸出77個Token數目,相比vLLM最高可提速22%!
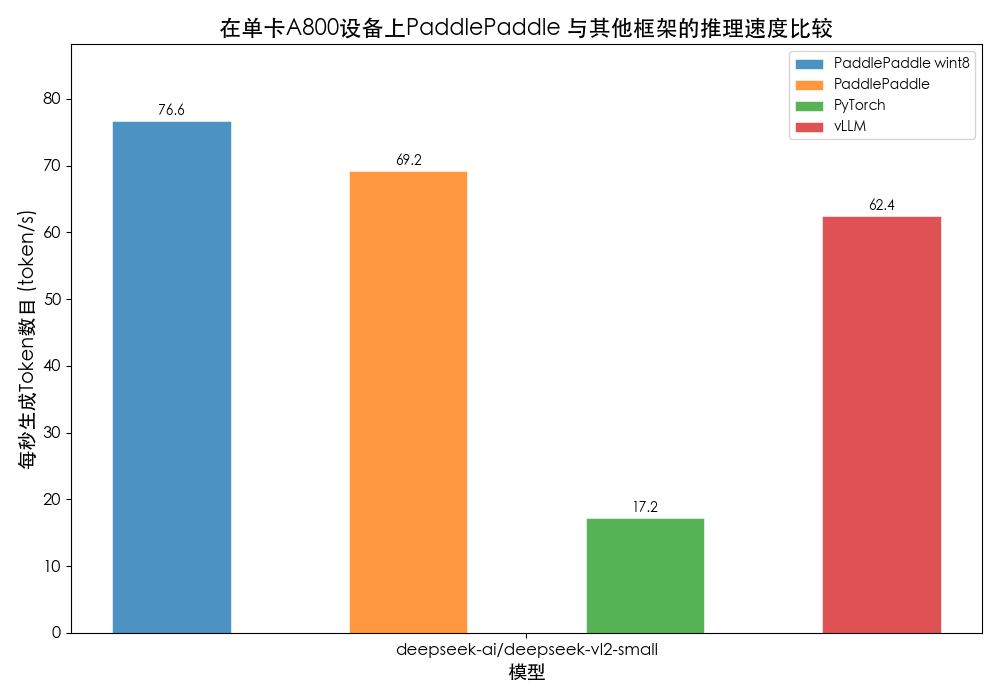
圖9 DeepSeek-VL2模型多圖測速對比
三、上手教程
多模態理解模型高性能推理
- 環境安裝
# 以CUDA11.8版本為例安裝Paddle
# 3.0版本和nighly build 版本均可以使用(推薦使用paddlepaddle-gpu==3.0.0版本)
# 更多版本可以參考https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/develop/install/pip/linux-pip.html
python -m pip install --pre paddlepaddle-gpu -i https://www.paddlepaddle.org.cn/packages/nightly/cu118/
python -m pip install paddlepaddle-gpu==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/# 安裝PaddleMIX以及PaddleNLP,目前高性能推理只支持PaddleNLP的develop版本
git clone https://github.com/PaddlePaddle/PaddleMIX
cd PaddleMIX
sh build_env.sh --nlp_dev# 此處提供兩種paddlenlp_ops安裝方法,如果CUDA版本11.8建議建議使用預編譯的paddlenlp_ops進行安裝
# 如果CUDA版本不是11.8可以手動編譯安裝paddlenlp_ops
cd csrc
python setup_cuda.py install# 安裝pre-build paddlenlp_ops,pre-build 版本paddlenlp_ops目前暫時只支持CUDA11.8版本
wget https://paddlenlp.bj.bcebos.com/wheels/paddlenlp_ops-ci-py3-none-any.whl -O paddlenlp_ops-0.0.0-py3-none-any.whl
pip install paddlenlp_ops-0.0.0-py3-none-any.whl
- Qwen2.5-VL高性能推理
# 在PaddleMIX目錄下運行以下命令
sh deploy/qwen2_5_vl/scripts/qwen2_5_vl.sh
- DeepSeek-VL2高性能推理
sh deploy/deepseek_vl2/scripts/deepseek_vl2.sh
四、總結
本文介紹了基于PaddleMIX套件的多模態模型的高性能推理實現,在推理性能上取得顯著提升,上手容易降低了模型部署成本!其中多模態理解模型以 Qwen2.5-VL 和 DeepSeek-VL2 為例逐步拆解飛槳高性能優化策略,兩個模型高性能推理均優于vLLM框架。
百度飛槳團隊推出的PaddleMIX套件現已支持 Qwen2.5-VL、DeepSeek-VL2 這兩個熱門模型的高性能推理,通過深入解析其代碼實現,研究人員和開發者能夠更透徹地理解模型的核心技術細節與創新突破。我們誠摯推薦您訪問AI Studio平臺的專項教程(點擊以下鏈接🔗),通過實踐演練掌握前沿多模態模型的開發與應用技巧。
AI Studio教程鏈接:
https://aistudio.baidu.com/projectdetail/8964029
論文鏈接:
Qwen2.5-VL Technical Report
https://arxiv.org/abs/2502.13923
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
https://arxiv.org/pdf/2412.10302
項目地址:
Qwen2.5-VL:
https://github.com/PaddlePaddle/PaddleMIX/tree/develop/deploy/qwen2_5_vl
DeepSeek-VL2:
https://github.com/PaddlePaddle/PaddleMIX/tree/develop/deploy/deepseek_vl2
為了幫助您通過解析代碼深入理解模型實現細節與技術創新,基于PaddleMIX框架實操多模態高性能推理,我們將開展“多模態大模型PaddleMIX產業實戰精品課”,帶您實戰操作多模態高性能推理。5月26日正式開營,報名即可免費獲得項目消耗算力(限時一周),名額有限,立即點擊鏈接報名:https://www.wjx.top/vm/wpv02PB.aspx?udsid=554465










)


)






)