導讀:隨著大語言模型和AI應用的快速普及,傳統數據庫在處理高維向量數據時面臨的性能瓶頸日益凸顯。當文檔經過嵌入模型處理生成768到1536維的向量后,傳統B-Tree索引的檢索效率會出現顯著下降,而現代應用對毫秒級響應的嚴苛要求使得這一技術挑戰變得更加緊迫。
本文將系統性地為技術團隊提供向量數據庫的全方位選型指南。從技術原理的深度剖析到主流產品的客觀對比,從Milvus、Pinecone、Qdrant等熱門解決方案的優劣分析到具體的部署架構建議,文章涵蓋了從概念驗證到生產環境的完整技術路徑。
特別值得關注的是,文章深入分析了不同數據規模下的技術選型策略。對于十億級以上的大規模場景,為什么分布式架構成為必然選擇?中小規模應用如何在成本和性能之間找到最佳平衡點?這些實踐問題的答案將幫助技術團隊避免選型誤區,制定符合業務實際的技術決策。
無論您是正在評估RAG系統技術方案的架構師,還是面臨推薦系統性能優化挑戰的開發工程師,這份基于實際應用經驗的技術指南都將為您的項目實施提供有價值的參考依據。
前言
在人工智能技術快速演進的時代背景下,向量數據庫已成為支撐現代智能應用的核心基礎設施。隨著大語言模型、推薦系統、多模態搜索等應用場景的廣泛普及,傳統數據庫在處理高維向量數據時暴露出的局限性日益明顯。本指南將系統性地探討向量數據庫的技術原理、主流產品對比分析,并深入剖析Milvus作為業界領先解決方案的架構設計與實踐應用,為技術團隊提供全方位的決策參考和實施指導。
第一部分:向量數據庫的技術價值與必要性分析
傳統數據庫面臨的技術挑戰
在處理現代AI應用產生的高維向量數據時,傳統關系型數據庫遭遇了根本性的架構瓶頸。當文檔片段經過嵌入模型處理生成向量后,這些高維數據需要專門的存儲和檢索機制來確保系統的高效運行。
維度災難的深層影響
傳統索引機制在面對高維數據時表現出的性能衰減問題構成了核心挑戰。傳統的B-Tree和Hash索引在處理超過100維的數據時,檢索效率會出現顯著下降,而現代嵌入模型生成的向量通常具備768到1536維的特征空間,這種維度差異使得傳統索引機制完全無法勝任高效檢索的業務需求。
語義相似度計算的復雜性
向量檢索的本質在于尋找語義相似的內容,這要求系統能夠高效執行余弦相似度或歐幾里得距離等復雜數學運算。在傳統數據庫架構框架下,這類計算密集型操作難以得到有效優化,從而制約了系統的整體性能表現。
實時響應的嚴苛要求
大規模應用場景對系統響應時間的要求極為嚴格。面對億級規模的向量數據,傳統暴力搜索方法的時間復雜度為O(N),響應延遲往往達到秒級水平,這完全無法滿足現代應用對毫秒級響應的核心需求。
技術能力對比分析
傳統關系型數據庫的查詢模式主要依賴精確匹配機制:
SELECT * FROM products WHERE category = 'electronics';
相比之下,向量數據庫支持的語義相似度查詢能夠深度理解查詢意圖:
# 向量數據庫查詢(相似度匹配)
Find top5 similar_products where description = '高性能游戲本';
這種查詢方式能夠返回語義相關但表達方式不同的產品信息,顯著提升了搜索系統的智能化水平和用戶體驗質量。
向量數據庫的核心技術能力
現代向量數據庫通過專門的技術架構設計,系統性地解決了傳統數據庫的固有局限性,主要體現在四個關鍵技術維度:
高效相似性搜索能力作為向量數據庫的基礎功能模塊,通過實現優化的余弦相似度和歐幾里得距離計算算法,系統能夠快速識別語義相關的內容,為智能推薦和語義搜索應用提供堅實的技術基礎。
混合查詢支持機制將向量搜索與傳統條件過濾進行有機結合,使得系統既能夠進行語義匹配,又能夠滿足業務邏輯的精確篩選需求。這種綜合能力對于復雜的企業應用場景具有重要價值。
動態擴展特性確保系統能夠支持實時數據更新操作,滿足現代應用對數據實時性的核心要求。這種能力使得向量數據庫能夠靈活適應快速變化的業務需求環境。
高效存儲技術通過先進的向量壓縮算法和優化存儲技術,在顯著降低存儲成本的同時保持查詢性能的穩定性。這一技術創新使得大規模向量數據的存儲管理成為現實。
典型應用場景深度分析
向量數據庫在多個關鍵技術領域展現出強大的應用價值:
推薦系統領域的電商商品推薦代表了最典型的應用場景。系統需要在毫秒級時間內從海量商品庫中精準找到與用戶興趣最匹配的商品,這對系統的高并發處理能力和低延遲響應提出了極高的技術要求。
語義搜索應用在法律條文檢索等專業領域發揮著重要作用。傳統的關鍵詞搜索方法往往無法準確理解查詢的真實意圖,而基于向量的語義搜索技術能夠實現高精度的內容召回,顯著提升專業信息檢索的準確性。
AI代理記憶系統為GPT等大語言模型提供長期記憶存儲能力。通過快速的上下文檢索機制,AI系統能夠保持對話的連貫性和個性化特征,提升用戶交互體驗。
圖像檢索系統的以圖搜圖功能展現了向量數據庫在多模態數據處理方面的技術優勢,為視覺搜索應用提供了強有力的技術支撐。
第二部分:主流向量數據庫產品深度對比分析
在向量數據庫市場中,不同類型的解決方案各具特色,滿足不同規模和需求的應用場景。通過系統性的對比分析,我們可以更好地理解各產品的技術優勢和適用范圍。
開源解決方案技術評估
Milvus技術優勢分析
Milvus作為業界領先的開源向量數據庫,展現出顯著的技術優勢。其分布式架構設計能夠支持千億級向量規模的數據處理,系統QPS可達百萬級別的處理能力。系統提供HNSW、IVF-PQ等多樣化索引算法選擇,特別適合金融風控、生物醫藥分子庫檢索等對性能要求嚴苛的高并發應用場景。
Milvus的核心競爭優勢在于其卓越的擴展性和完善的多租戶支持機制,提供了豐富的API生態系統,支持Python、Java、Go等多種主流編程語言。然而,其部署復雜度相對較高,運維成本需要專業技術團隊的支持,更適合擁有成熟技術團隊的大型企業使用。
Qdrant性能特色
Qdrant基于Rust語言開發,在性能優化方面表現出色。其支持稀疏向量檢索功能,相比傳統解決方案的處理速度提升可達16倍。內置的標量量化和產品量化技術有效優化了存儲效率,特別適合電商推薦、廣告投放等高并發應用場景的部署需求。
Qdrant的高性能過濾能力和云原生設計理念是其主要技術優勢,同時支持地理空間數據和混合數據類型的處理。不過,由于其相對較新的市場定位,社區生態系統和文檔案例相對較少,可能會影響開發團隊的快速上手和問題解決效率。
云原生服務解決方案
Pinecone全托管服務
Pinecone提供完全托管的向量數據庫服務,實時數據更新延遲可穩定控制在100毫秒以內。其Serverless計費模式采用按查詢次數付費的方式,為SaaS產品快速集成和中小型企業提供了理想的解決方案。
Pinecone的零運維特性和優異的低延遲表現構成其核心競爭優勢,與LangChain生態系統的無縫集成進一步提升了開發效率和用戶體驗。然而,在大規模數據處理場景下,其使用成本可能會顯著上升,需要項目團隊仔細評估長期的經濟效益。
騰訊云VectorDB國產化方案
騰訊云VectorDB作為國產化向量數據庫解決方案,單索引支持千億向量規模的數據處理能力。其集成的AI套件能夠實現文檔自動向量化處理,特別適合政務、金融等對數據主權和安全性要求嚴格的應用場景。
該產品提供端到端的RAG(檢索增強生成)解決方案,與騰訊云生態系統實現深度整合。但其對騰訊云生態環境的依賴性較強,可能在跨云部署和多云架構方面存在一定限制。
輕量級工具解決方案
Chroma開發友好特性
Chroma以其開發友好的特性著稱,即使沒有深厚數據庫技術背景的開發者也能在5分鐘內完成單機部署配置。這使其成為學術研究項目和初創團隊快速概念驗證的理想選擇。
Chroma支持與LangChain框架的深度集成,便于快速原型開發和概念驗證。然而,其功能相對基礎,難以適應生產級大規模應用的部署需求。
Faiss性能標桿
Faiss作為Meta開源的GPU加速檢索庫,在性能表現方面堪稱行業標桿。百萬級向量查詢延遲可穩定控制在10毫秒以內,經常作為其他數據庫系統的底層檢索引擎使用。
Faiss提供豐富的算法選擇和混合檢索架構支持,但缺乏托管服務支持,需要開發團隊自行處理分布式部署和高可用性架構設計等復雜問題。
傳統數據庫擴展方案
MongoDB Atlas向量集成
MongoDB Atlas通過在文檔數據庫中嵌入向量索引功能,支持每個文檔存儲16MB的向量數據。這種技術方案特別適合已有MongoDB基礎設施的企業進行智能化升級改造。
其主要優勢在于能夠實現事務處理與向量檢索的一體化操作,與現有業務邏輯保持良好兼容性。但向量檢索性能相比專用數據庫存在一定差距,系統擴展性也會受到相應限制。
其他傳統數據庫擴展
PostgreSQL、ElasticSearch等傳統數據庫也通過插件方式提供了向量檢索能力,為企業漸進式技術升級提供了可行的選擇路徑。
第三部分:技術選型策略與實施建議
數據規模導向的選型策略
針對十億級以上的大規模數據處理場景,技術團隊應當選擇Milvus、騰訊云VectorDB等具備成熟分布式架構的解決方案。這些系統在設計之初就充分考慮了大規模數據的處理需求,能夠提供穩定可靠的性能保證和擴展能力。
對于百萬級以下的中小規模應用場景,可以考慮Chroma或Faiss等輕量級工具。這些解決方案部署配置相對簡單,能夠快速滿足業務需求,同時避免了過度設計帶來的系統復雜性。
部署復雜度權衡考量
對于希望將主要精力集中在業務邏輯開發而非基礎設施運維的技術團隊,云服務解決方案是優先推薦的選擇。中小企業可以選擇Pinecone或騰訊云VectorDB等服務,有效降低運維成本和技術門檻要求。
需要私有化部署的大型企業則應考慮Milvus、Qdrant等開源解決方案,但需要配備專業的技術團隊來支持系統的部署、運維和持續優化工作。
成本效益深度分析
從長期發展角度來看,開源方案如Milvus、Qdrant能夠提供更好的成本可控性。雖然初期投入相對較高,但隨著業務規模的不斷擴大,總體擁有成本的優勢會逐漸顯現。
對于處于概念驗證和試驗階段的小規模項目,Pinecone的Serverless按需付費模式提供了靈活的成本結構選擇,有助于有效控制初期投資風險。
生態兼容性需求分析
在國產化需求較強的應用場景中,騰訊云VectorDB或華為云等國產解決方案能夠更好地滿足合規性和數據主權要求。
對于已有成熟技術棧的企業組織,PostgreSQL、MongoDB的向量擴展插件提供了漸進式技術改造的實施路徑,有助于顯著降低系統遷移的風險和成本投入。
綜合選型對比矩陣
從部署模式維度分析,Pinecone提供全托管云服務,Milvus支持自建和云部署的靈活選擇,Qdrant同樣支持自建和云部署模式,而Chroma則采用輕量級嵌入式部署方式。
學習曲線復雜度方面,Pinecone最為簡單直觀,Chroma極其簡潔易用,Qdrant處于中等復雜度水平,而Milvus相對復雜但功能最為完整。
系統擴展能力上,Pinecone支持自動擴展機制,Milvus需要手動分片管理,Qdrant提供自動分片功能,Chroma僅支持單機部署模式。
典型應用場景中,Pinecone適合生產級SaaS應用,Milvus適合企業私有云環境,Qdrant滿足高性能應用需求,Chroma則主要用于本地開發和原型驗證。
成本模型方面,Pinecone采用按用量付費機制,其他三者都需要綜合考慮基礎設施和運維成本,Chroma可免費使用但功能有限。
第四部分:Milvus架構深度解析與實踐指導
基于前面的技術選型分析,Milvus作為業界領先的開源向量數據庫解決方案,其技術架構和實踐應用值得深入探討。
Milvus產品定位與技術指標
Milvus是一種高性能、高可擴展性的向量數據庫系統,專為處理大規模向量數據而精心設計。該系統能夠在從筆記本電腦到大規模分布式環境等各種計算環境中高效運行,為現代AI應用提供強大的向量存儲和檢索能力支撐。
核心技術指標表現
從數據規模角度,Milvus支持千億級向量存儲,PB級存儲容量能力。查詢性能方面,系統能夠實現億級向量亞秒級響應,支持GPU加速優化。擴展性設計上,采用水平擴展架構,支持動態增刪節點操作。查詢類型涵蓋相似度搜索、混合查詢、多向量聯合查詢等多種模式。生態兼容性方面,支持Python、Java、Go、REST API等多種接口,整合主流AI開發框架。
全球企業用戶驗證
Milvus已被眾多知名企業成功采用,包括NVIDIA、ROBLOX、AT&T、BOSCH、eBay、Shopee、LINE、IKEA、Walmart等全球領先企業,這些實際應用案例充分驗證了其在生產環境中的穩定性和可靠性。
Milvus部署架構選項分析
Milvus提供多種靈活的部署選項,以滿足不同規模和環境的具體需求。用戶可以根據實際應用場景選擇最適合的部署方式。
Milvus Lite輕量級方案
Milvus Lite是專為快速原型開發設計的輕量級Python庫。該版本特別適合在Jupyter Notebooks中進行實驗開發,或在資源有限的邊緣設備上運行。其輕量化特性使開發者能夠快速驗證技術概念和進行小規模功能測試。
Milvus Standalone單機部署
Milvus Standalone采用單機服務器部署模式,將所有必要組件整合在統一的Docker鏡像中,大大簡化了部署流程復雜度。這種部署方式適合中小規模應用和開發測試環境,提供了便捷的一鍵部署體驗。
Milvus Distributed分布式架構
Milvus Distributed是為大規模生產環境專門設計的分布式部署方案。該架構可以部署在Kubernetes集群上,采用云原生設計理念,能夠處理十億規模甚至更大的數據量。分布式架構確保了關鍵組件的冗余性,提供高可用性保障機制。
Milvus系統架構深度剖析
數據處理流程機制
插入數據→生成日志→持久化到存儲層→構建索引→支持查詢。
Milvus的數據處理遵循清晰的工作流程:數據插入操作首先生成詳細的操作日志,隨后進行持久化存儲處理,系統會自動構建優化索引以提升查詢性能,最終為用戶提供高效的查詢服務支持。
核心組件功能解析
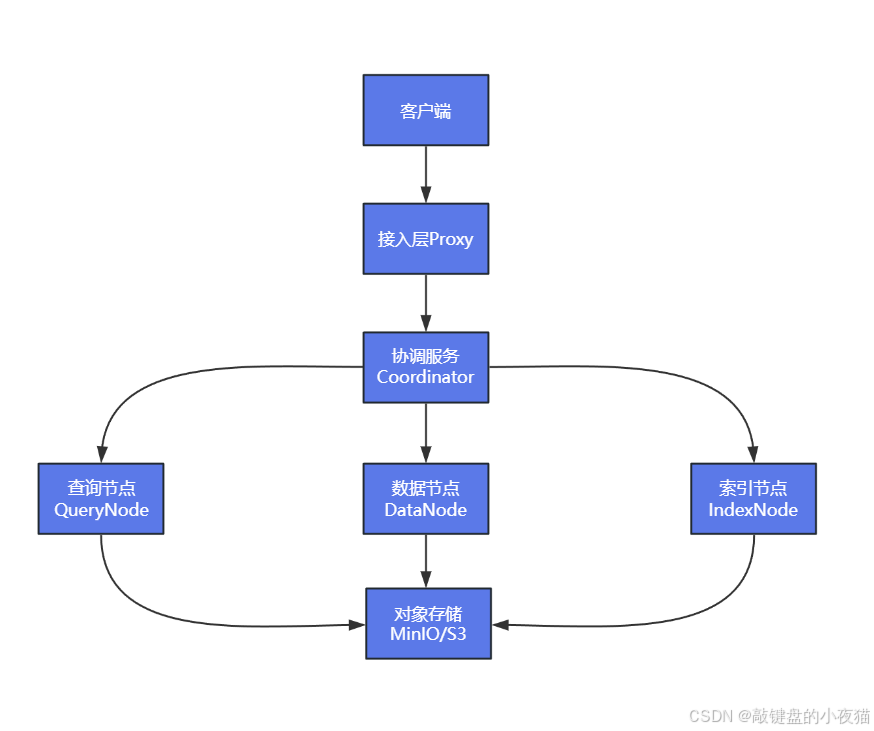
Proxy組件作為客戶端請求的統一入口,負責路由轉發、負載均衡與協議轉換,支持gRPC和RESTful協議,提供負載均衡和連接池管理功能。
Query Node組件執行向量搜索、標量過濾、向量相似度計算與混合過濾操作,支持內存索引加載和GPU加速處理,確保查詢性能的高效表現。
Data Node組件處理數據插入、日志流處理與數據持久化存儲操作,通過寫入日志機制保障數據一致性和系統可靠性。
Index Node組件負責索引構建與優化工作,支持后臺異步索引構建,不影響正常的數據讀寫操作。
Coordinator組件管理集群元數據和任務調度,采用高可用部署方式,通過etcd存儲重要的元數據信息。
Milvus核心概念與數據結構
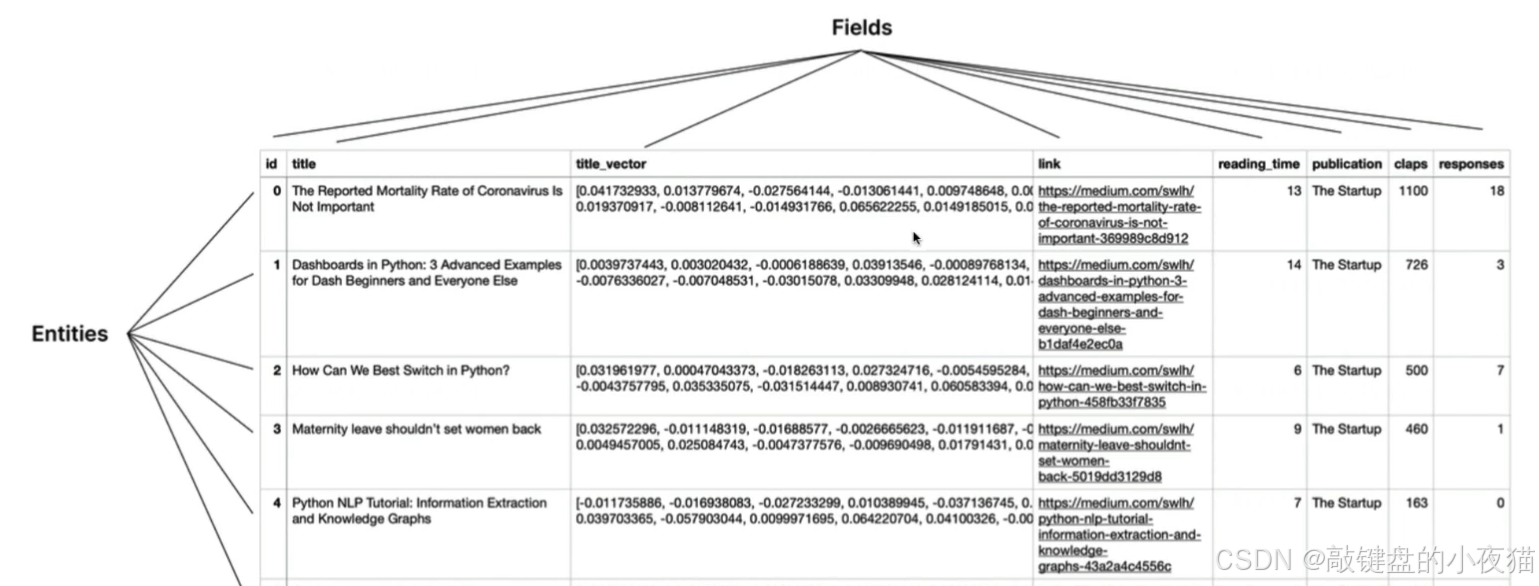
為了更好地理解Milvus向量數據庫的設計理念,我們將其核心概念與傳統關系型數據庫進行對比分析。
概念映射關系
Milvus向量數據庫中的Collection對應關系型數據庫的Table概念,作為數據的邏輯容器。Entity對應Row概念,代表單條數據記錄。Field對應Column概念,定義數據屬性結構。
Collection集合詳解
Collection是Milvus中最重要的數據組織單位,每個Collection用于存儲和管理一組具有相同結構的實體數據。主要特性包括Schema定義功能,明確指定字段結構,包括主鍵、向量字段和標量字段。Milvus 2.3及以上版本支持動態字段功能,提供可選的唯一ID自動生成機制。
實踐代碼示例
# 安裝必要依賴
pip install pymilvus==2.5.5from pymilvus import FieldSchema, CollectionSchema, DataType, Collection# 定義字段結構
fields = [FieldSchema(name="id", dtype=DataType.INT64, is_primary=True), FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=768),FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=50)
]# 創建集合Schema
schema = CollectionSchema(fields, description="商品向量庫")# 創建Collection實例
collection = Collection(name="products", schema=schema)
Entity實體結構
Entity代表數據庫中的基本數據單位,包含多個不同類型的字段。每個Entity都是Collection中的一條完整記錄,組成要素包括主鍵、向量字段和標量字段。
需要特別注意的是,Milvus目前不支持主鍵去重功能,系統允許重復主鍵的存在。在實際應用中需要在業務層面確保主鍵的唯一性要求。
Field字段類型分析
Milvus支持標量字段和向量字段兩種主要類型。標量字段存儲結構化數據,支持過濾查詢操作,用于存儲業務元數據和屬性信息。向量字段存儲高維向量數據,支持向量相似性搜索功能,是進行語義搜索和推薦系統的核心組件。
查詢方式與索引系統
查詢模式分析
Milvus提供向量搜索和混合查詢兩種主要查詢方式。向量搜索通過輸入查詢向量,系統返回最相似的Top-K結果,這是向量數據庫的核心功能。混合查詢結合向量相似度計算和標量字段過濾條件,實現更精確的業務查詢需求。
索引系統優化
索引是提高查詢性能的關鍵技術,Milvus提供多種索引類型以適應不同的應用場景。索引基于原始向量數據構建,存儲在內存中,不直接存儲數據而是存儲指向數據位置的指針,顯著提高向量相似性搜索的速度。
常用索引類型包括FLAT索引適用于小數據集精準搜索,IVF_FLAT索引適合平衡型應用場景,HNSW索引滿足高召回率需求,IVF_PQ索引適用于超大規模數據集處理。
相似度計算方法
Milvus支持多種向量相似度計算方法。歐氏距離計算兩個向量在歐氏空間中的直線距離,數值越小表示向量越相似。內積方法計算效率高,適用于推薦系統等場景。余弦相似度基于向量夾角計算相似度,只考慮向量方向而忽略模長差異,適用于文本相似性分析等場景。
實施總結
向量數據庫的技術選型需要綜合考慮數據規模、業務場景、團隊能力和成本預算等多個關鍵維度。云原生解決方案雖然成本相對較高,但在易用性和可靠性方面具有明顯優勢,特別適合希望快速上線并專注業務邏輯開發的技術團隊。
對于AI驅動的應用場景,如RAG系統和多模態搜索應用,建議優先考慮云原生服務或分布式開源方案。這些解決方案在技術成熟度和生態系統支持方面具有顯著優勢,能夠為復雜應用提供穩定可靠的技術支撐。
傳統業務系統的智能化升級可以考慮數據庫擴展插件的實施方式,通過漸進式改造有效降低系統遷移風險。這種方式能夠在保持現有系統穩定性的前提下,逐步引入向量檢索能力,實現平滑的技術過渡。

















)

