告別等待,秒級響應!這不只是教程,這是你駕馭PB級數據的超能力!我的ClickHouse視頻課,凝練十年實戰精華,從入門到精通,從單機到集群。點開它,讓數據處理速度快到飛起,讓你的職業生涯從此開掛!
全套視頻教程聯系博主
1 寫在前面
ClickHouse 的 Kafka 引擎本質上是一個數據流的適配器(Adapter),而不是一個存儲引擎。
你需要記住的最重要的一點是:Kafka 引擎本身不存儲任何數據。它就像一根管道,直接連接到 Kafka 的 Topic。當你查詢一個 ENGINE = Kafka 的表時,ClickHouse 會實時地從 Kafka Topic 中拉取(Consume)消息,并根據你指定的格式(如 JSON, CSV)進行解析,然后將結果返回給你。
由于它不存儲數據,所以它通常不單獨使用,而是與物化視圖(Materialized View) 結合,形成一個完整、高效的數據攝取流水線(Pipeline)。
核心比喻:
Kafka Topic:一個源源不斷流淌著“原漿數據”的河流。
ClickHouse Kafka 引擎:一根直接插在河里的智能吸管,它只負責吸水,不負責存水。
ClickHouse MergeTree 表:一個巨大無比的蓄水池(我們的數據倉庫),水最終要存在這里。
物化視圖:一個永動機水泵,自動把吸管吸上來的水,源源不斷地泵入蓄水池。
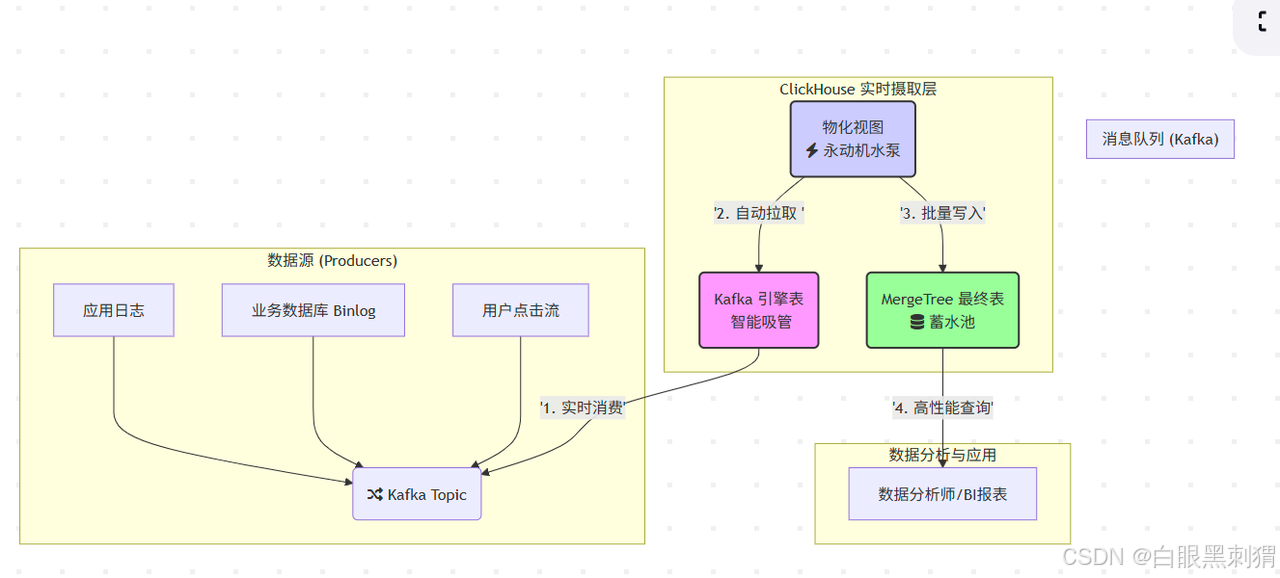
圖解:數據從各種源頭生產出來,匯入 Kafka 這條大河。我們的“智能吸管”(Kafka引擎表)從河里實時吸水,然后“永動機水泵”(物化視圖)立刻把水抽走,存入“蓄水池”(MergeTree表),最后數據分析師就可以在蓄水池里愉快地游泳(查詢)了!?
2 實操(上代碼)
光說不練假把式!我們來親手搭建這個系統。假設 Kafka 的 user_actions topic 里有如下JSON數據流: {"user_id": 101, "event": "login", "ts": "2023-10-27 10:00:00"} {"user_id": 102, "event": "purchase", "ts": "2023-10-27 10:00:05"}
第一步:建造蓄水池 (創建 MergeTree 目標表)
我們得先有個地方存數據。這是我們的最終歸宿,必須堅固耐用(性能好)。
-- 這是我們的“蓄水池”,用來存最終的數據
CREATE TABLE account_store (user_id UInt64,name String,city String
) ENGINE = MergeTree()
PARTITION BY city
ORDER BY (user_id);第二步:安裝智能吸管 (創建 Kafka 引擎表)
現在,把我們的吸管插到 Kafka 河里。
-- 這是我們的“智能吸管”,它本身不存水!
CREATE TABLE account (user_id UInt64,name String,city String
) ENGINE = Kafka
SETTINGSkafka_broker_list = 'linux01:9092,linux01:9092,linux03:9092',kafka_topic_list = 'zk_data',kafka_group_name = 'g1', -- 非常重要!每個流用獨立組名kafka_format = 'JSON', -- 告訴吸管,水里的是啥味道的(數據格式)kafka_num_consumers = 1;靈魂拷問:如果我現在 SELECT * FROM user_actions_pipe,會發生什么? 答案:你會看到 當前 Kafka Topic 中的數據!就像你用吸管吸了一口河水嘗嘗味道。但你關掉查詢,數據就沒了,因為它不存儲。
第三步:啟動永動機水泵 (創建物化視圖)
-- 這是我們的“永動機水泵”,連接吸管和蓄水池
CREATE MATERIALIZED VIEW user_actions_pump TO account_store AS
SELECT user_id, name, city
FROM account ;工作原理:
TO account_store: 告訴水泵,水要泵到哪個池子。AS SELECT ... FROM account: 告訴水泵,要從哪個吸管抽水,以及抽水的方式(可以直接抽,也可以在抽的時候過濾、轉換一下)。
大功告成! 從現在起,任何進入 account Topic 的新消息,都會被這套全自動系統捕捉,并在幾秒鐘內出現在 account_store 表中,隨時可以查詢!
3 性能優化: 如果管道堵了怎么辦
關鍵監控指標:消費延遲 (Lag) Lag 指的是你的消費速度和你上游數據生產速度之間的差距。Lag 持續增大,說明你的“水泵”馬力不足,水快要從河里溢出來了!
-- 查水表!看看我們的消費組狀態
SELECTtable,partition,last_committed_offset, -- 水泵上次匯報說“我抽到這兒了”current_offset, -- 河流的最新水位(current_offset - last_committed_offset) AS lag, -- 水位差last_error -- 水泵有沒有發出警報?
FROM system.kafka_consumers
WHERE table = 'user_actions_pipe';
問題:Lag 持續增長
原因:ClickHouse寫入慢(目標表結構復雜、硬件瓶頸)或消費能力不足。
解決:
優化
MergeTree表的ORDER BY鍵。增加
kafka_num_consumers數量(不能超過Topic分區數)。給 ClickHouse 服務器加配置!
問題:
last_error顯示錯誤,消費停止
原因:遇到了“毒丸消息” (Poison Pill)!比如你的數據流里混進了一個非JSON格式的字符串,解析器直接卡住。
解決:給 Kafka 引擎表加上“金剛不壞之身”。
壞(臟)數據怎么辦?設置一下就可以了--針對格式不正確的數據
-- 加上這個設置,遇到10個連續的壞數據就跳過,不影響大部隊
ALTER TABLE user_actions_pipe MODIFY SETTING kafka_skip_broken_messages = 10;




操作詳解)






——文本分塊優化)
)






