一、SDS如何防止緩沖區溢出?
Redis 的 String 類型通過 SDS(Simple Dynamic String)來防止緩沖區溢出,具體機制如下:
- Redis 的 String 類型底層采用 SDS 實現,即 Simple Dynamic String
- SDS 底層維護的數據結構包含多個關鍵部分:
- len:表示當前 SDS 字符串已經使用的字節數
- alloc:代表為 SDS 字符串預先分配的總字節數,alloc - len 即為空閑空間的大小
- flags:用于標識 SDS 的類型,不同類型的 SDS 在內存分配和存儲方式上有所不同,以適應不同長度的字符串存儲需求
- buf:實際存儲字符串內容的字符數組,其長度為 alloc,并且遵循 C 字符串以 \0 結尾的慣例,不過 \0 不包含在 len 統計范圍內
- 當對 SDS 字符串執行 append 等操作時,會先進行檢查。計算添加新內容后所需的總字節數,如果該總字節數超過了當前 alloc 的字節數,就會觸發擴容操作。擴容規則如下
- 如果當前 alloc 的字節數小于 1MB,采用兩倍擴容策略,即將原來 alloc 的字節數乘以 2
- 如果當前 alloc 的字節數大于或等于 1MB,每次擴容 1MB,也就是在原來 alloc 的字節數基礎上加上 1MB

二、跳表插入流程
(1)跳表的基本結構
跳表是在有序鏈表的基礎上,通過增加多層索引來提高查找效率。每一層都是一個有序鏈表,并且上層鏈表是下層鏈表的子集。每個節點可能會跨越多個層級,節點的層級是在插入時隨機確定的
(2)插入步驟演示


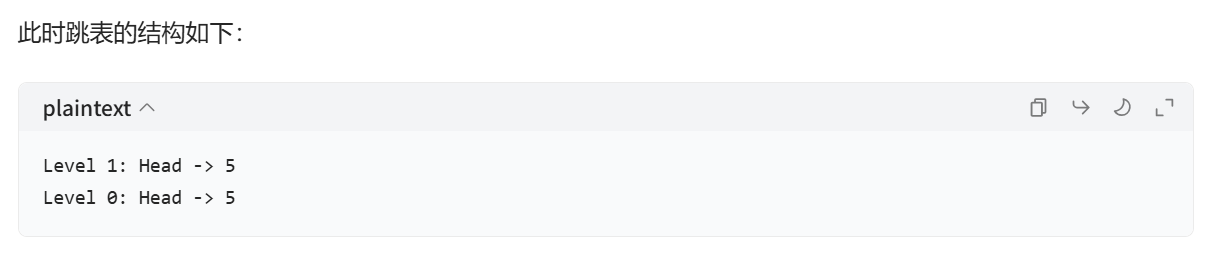

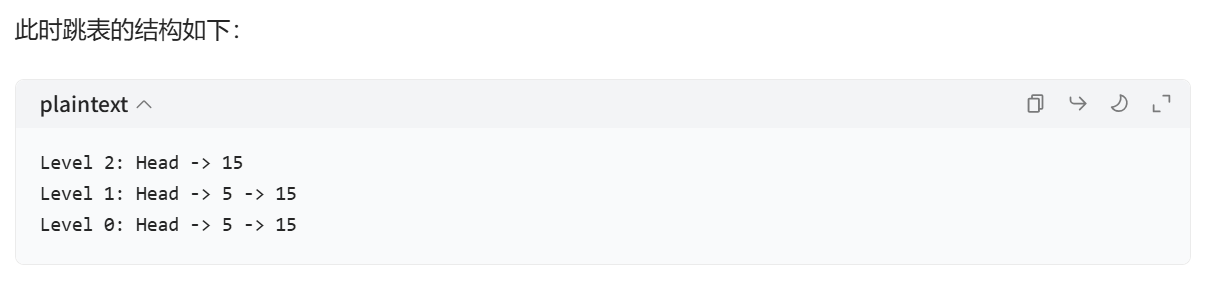
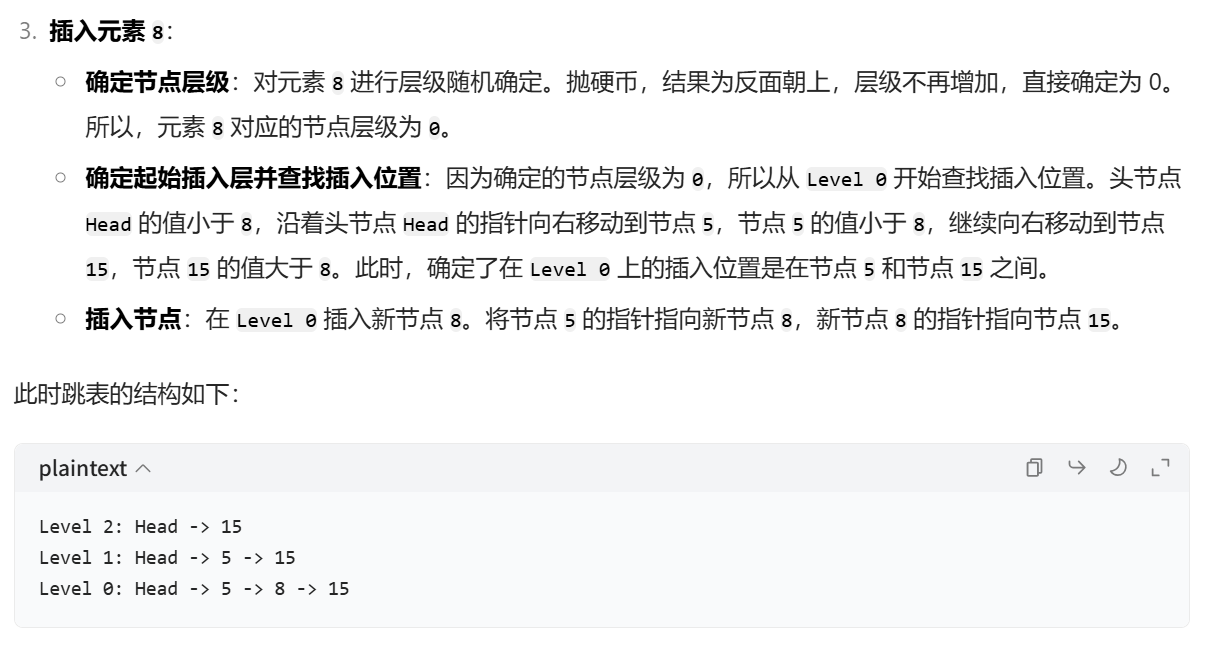

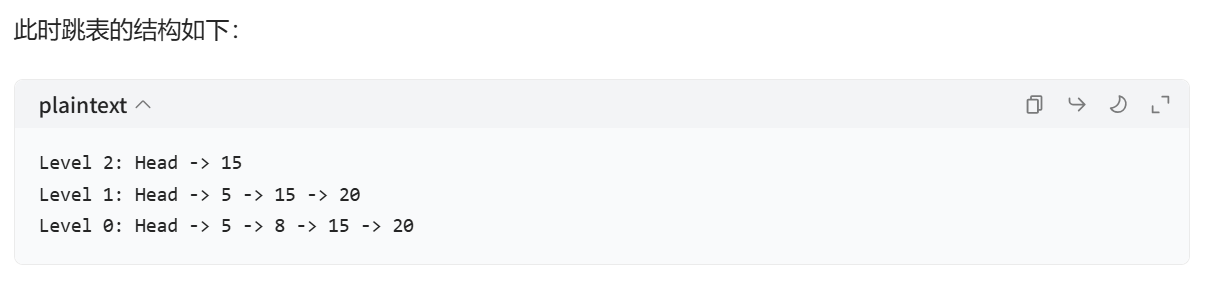
每次插入一個元素之前,采用拋硬幣的方式記錄層數,最開始的層數從 0 開始,每次拋硬幣,如果正面向上,就加 1,如果反面向上,就不加,而且會立刻停止拋硬幣。然后最終得到的層數,就是這個元素開始插入的層。從該層起,在每層找到最后一個比這個元素小的元素,把這個元素插入到該元素之后,接著依次向下,直到第 0 層都完成插入操作
三、漸進式Rehash的過程
(1)初始狀態
- 電商網站使用 Redis 存儲商品信息,每個商品信息以鍵值對形式存在,鍵為商品 ID,值為商品的詳細信息(如商品名稱、價格等)
- 初始時,Redis 中的哈希表 ht[0] 大小為 8,當前存儲了 8 個商品信息,負載因子為 1(已使用桶數量 / 哈希桶總數 = 8 / 8 = 1),ht[1] 為空
ht[0]: | 0 | -> (1001, {name: "手機", price: 3999}) | 1 | -> (1002, {name: "電腦", price: 7999}) | 2 | -> (1003, {name: "相機", price: 5999}) | 3 | -> (1004, {name: "耳機", price: 299}) | 4 | -> (1005, {name: "手表", price: 1999}) | 5 | -> (1006, {name: "鍵盤", price: 499}) | 6 | -> (1007, {name: "鼠標", price: 199}) | 7 | -> (1008, {name: "音箱", price: 399})ht[1]: | 0 | -> NULL | 1 | -> NULL | 2 | -> NULL | 3 | -> NULL | 4 | -> NULL | 5 | -> NULL | 6 | -> NULL | 7 | -> NULLrehashidx = -1
(2)觸發Rehash
- 當新添加商品 1009(商品 ID 為 1009,名稱為 “路由器”,價格為 199)時,ht[0] 的負載因子變為 9 / 8 > 1,觸發擴容操作
- Redis 為 ht[1] 分配新的內存空間,大小為 ht[0] 的 2 倍,即 16。同時,將 rehashidx 設置為 0,表示從 ht[0] 的第 0 個哈希桶開始進行 Rehash。由于處于 Rehash 過程中,新添加的商品 1009 會直接被添加到 ht[1] 中。假設商品 1009 計算得到的哈希值對 16 取模結果為 11,則:
ht[0]: | 0 | -> (1001, {name: "手機", price: 3999}) | 1 | -> (1002, {name: "電腦", price: 7999}) | 2 | -> (1003, {name: "相機", price: 5999}) | 3 | -> (1004, {name: "耳機", price: 299}) | 4 | -> (1005, {name: "手表", price: 1999}) | 5 | -> (1006, {name: "鍵盤", price: 499}) | 6 | -> (1007, {name: "鼠標", price: 199}) | 7 | -> (1008, {name: "音箱", price: 399})ht[1]: | 0 | -> NULL | 1 | -> NULL | 2 | -> NULL | 3 | -> NULL | 4 | -> NULL | 5 | -> NULL | 6 | -> NULL | 7 | -> NULL | 8 | -> NULL | 9 | -> NULL | 10 | -> NULL | 11 | -> (1009, {name: "路由器", price: 199}) | 12 | -> NULL | 13 | -> NULL | 14 | -> NULL | 15 | -> NULLrehashidx = 0
(3)漸進式遷移
3.3.1第一次 Rehash
- 當有用戶查詢商品 ID 為 1010 的商品信息時,由于處于 Rehash 過程中,會先將商品 1010 插入到 ht[1] 中。假設商品 1010 計算得到的哈希值對 16 取模結果為 4,插入后如下:
ht[0]: | 0 | -> (1001, {name: "手機", price: 3999}) | 1 | -> (1002, {name: "電腦", price: 7999}) | 2 | -> (1003, {name: "相機", price: 5999}) | 3 | -> (1004, {name: "耳機", price: 299}) | 4 | -> (1005, {name: "手表", price: 1999}) | 5 | -> (1006, {name: "鍵盤", price: 499}) | 6 | -> (1007, {name: "鼠標", price: 199}) | 7 | -> (1008, {name: "音箱", price: 399})ht[1]: | 0 | -> NULL | 1 | -> NULL | 2 | -> NULL | 3 | -> NULL | 4 | -> (1010, {name: "新商品", price: 888}) | 5 | -> NULL | 6 | -> NULL | 7 | -> NULL | 8 | -> NULL | 9 | -> NULL | 10 | -> NULL | 11 | -> (1009, {name: "路由器", price: 199}) | 12 | -> NULL | 13 | -> NULL | 14 | -> NULL | 15 | -> NULLrehashidx = 0 - 接著,系統會將 ht[0] 中索引為 0 的桶中的商品鍵值對 (1001, {name: "手機", price: 3999}) 重新計算哈希值。假設新的哈希值對 16 取模的結果為 3,則將該鍵值對插入到 ht[1] 的第 3 個哈希桶中,然后將 rehashidx 的值增 1,變為 1
ht[0]: | 0 | -> NULL | 1 | -> (1002, {name: "電腦", price: 7999}) | 2 | -> (1003, {name: "相機", price: 5999}) | 3 | -> (1004, {name: "耳機", price: 299}) | 4 | -> (1005, {name: "手表", price: 1999}) | 5 | -> (1006, {name: "鍵盤", price: 499}) | 6 | -> (1007, {name: "鼠標", price: 199}) | 7 | -> (1008, {name: "音箱", price: 399})ht[1]: | 0 | -> NULL | 1 | -> NULL | 2 | -> NULL | 3 | -> (1001, {name: "手機", price: 3999}) | 4 | -> (1010, {name: "新商品", price: 888}) | 5 | -> NULL | 6 | -> NULL | 7 | -> NULL | 8 | -> NULL | 9 | -> NULL | 10 | -> NULL | 11 | -> (1009, {name: "路由器", price: 199}) | 12 | -> NULL | 13 | -> NULL | 14 | -> NULL | 15 | -> NULLrehashidx = 1
3.3.2后續 Rehash
后續每次對商品信息執行操作(如查詢、更新、刪除等)時,都會順帶將 ht[0] 中 rehashidx 位置的鍵值對遷移到 ht[1] 中,并將 rehashidx 加 1。例如,當有用戶更新商品 1002 的信息時,會把 ht[0] 中索引為 1 的 (1002, {name: "電腦", price: 7999}) 遷移到 ht[1] 中,假設新位置為 7:
ht[0]:
| 0 | -> NULL
| 1 | -> NULL
| 2 | -> (1003, {name: "相機", price: 5999})
| 3 | -> (1004, {name: "耳機", price: 299})
| 4 | -> (1005, {name: "手表", price: 1999})
| 5 | -> (1006, {name: "鍵盤", price: 499})
| 6 | -> (1007, {name: "鼠標", price: 199})
| 7 | -> (1008, {name: "音箱", price: 399})ht[1]:
| 0 | -> NULL
| 1 | -> NULL
| 2 | -> NULL
| 3 | -> (1001, {name: "手機", price: 3999})
| 4 | -> (1010, {name: "新商品", price: 888})
| 5 | -> NULL
| 6 | -> NULL
| 7 | -> (1002, {name: "電腦", price: 7999})
| 8 | -> NULL
| 9 | -> NULL
| 10 | -> NULL
| 11 | -> (1009, {name: "路由器", price: 199})
| 12 | -> NULL
| 13 | -> NULL
| 14 | -> NULL
| 15 | -> NULLrehashidx = 2(4)完成 Rehash
當 rehashidx 變為 8 時,意味著 ht[0] 中的所有鍵值對都已遷移到 ht[1] 中。此時程序將 rehashidx 屬性的值設為 -1,表示 Rehash 操作已完成。之后,電商網站對商品信息的操作就只在新的哈希表 ht[1] 上進行了
ht[0]:
| 0 | -> NULL
| 1 | -> NULL
| 2 | -> NULL
| 3 | -> NULL
| 4 | -> NULL
| 5 | -> NULL
| 6 | -> NULL
| 7 | -> NULLht[1]:
| 0 | -> (1008, {name: "音箱", price: 399})
| 1 | -> (1007, {name: "鼠標", price: 199})
| 2 | -> (1006, {name: "鍵盤", price: 499})
| 3 | -> (1001, {name: "手機", price: 3999})
| 4 | -> (1010, {name: "新商品", price: 888})
| 5 | -> (1005, {name: "手表", price: 1999})
| 6 | -> (1004, {name: "耳機", price: 299})
| 7 | -> (1002, {name: "電腦", price: 7999})
| 8 | -> (1003, {name: "相機", price: 5999})
| 9 | -> NULL
| 10 | -> NULL
| 11 | -> (1009, {name: "路由器", price: 199})
| 12 | -> NULL
| 13 | -> NULL
| 14 | -> NULL
| 15 | -> NULLrehashidx = -1

四、壓縮列表
(1)壓縮列表的基本結構
Redis 的壓縮列表(ziplist)是一種為了節省內存而設計的順序型數據結構,它被廣泛應用于列表鍵和哈希鍵中,當列表元素較少或者列表元素都是小整數值或短字符串時,以及哈希鍵中鍵值對數量較少且鍵值都是小整數值或短字符串時,Redis 會使用壓縮列表來存儲數據
(2)壓縮列表的結構
壓縮列表是由一系列特殊編碼的連續內存塊組成的順序型數據結構,其整體結構包含以下幾個部分:
- zlbytes:
- 類型:4 字節無符號整數
- 作用:記錄整個壓縮列表所占用的內存字節數,通過這個字段,Redis 可以快速定位到壓縮列表的末尾
- zltail:
- 類型:4 字節無符號整數
- 作用:記錄壓縮列表尾節點相對于壓縮列表起始地址的偏移量,借助這個字段,Redis 能夠在不遍歷整個列表的情況下直接訪問尾節點
- zllen:
- 類型:2 字節無符號整數
- 作用:記錄壓縮列表中節點的數量。不過,當節點數量超過 65535 時,這個字段的值會固定為 65535,此時需要遍歷整個壓縮列表才能獲取準確的節點數量
- entryX:
- 類型:可變長度
- 作用:壓縮列表中的節點,每個節點可以存儲一個字節數組或者一個整數值
- zlend:
- 類型:1 字節特殊值
- 取值:固定為 0xFF(十進制的 255)
- 作用:標記壓縮列表的結束
(3)節點的結構
每個壓縮列表節點由以下三個部分組成:
- prevlen:
- 類型:長度可變,1 字節或者 5 字節
- 取值及作用:
- 如果前一個節點的長度小于 254 字節,那么 prevlen 用 1 字節來存儲該長度
- 如果前一個節點的長度大于等于 254 字節,prevlen 則用 5 字節來存儲,其中第一個字節固定為 0xFE(十進制的 254),后面 4 個字節存儲實際的長度值
- 通過這個字段,Redis 可以從后向前遍歷壓縮列表
- encoding:
- 類型:長度可變
- 作用:記錄節點所保存的數據的類型以及長度。不同的編碼方式會使用不同的字節數來表示數據類型和長度
- data:
- ???????類型:長度可變
- 作用:節點實際保存的數據
(4)示例說明
假設我們有一個簡單的壓縮列表,用于存儲一個包含三個元素的列表:["apple", 100, "banana"]。下面是這個壓縮列表的結構示例:
+--------+
| zlbytes| 29(4 字節無符號整數,記錄整個壓縮列表所占用的內存字節數)
+--------+
| zltail | 20(4 字節無符號整數,記錄壓縮列表尾節點相對于壓縮列表起始地址的偏移量)
+--------+
| zllen | 3(2 字節無符號整數,記錄壓縮列表中節點的數量)
+--------+
| entry1 |
| | prevlen | 0(1 字節,表示前一個節點長度,因為是第一個節點,所以為 0)
| | encoding| 0b10000101(1 字節,高 2 位 10 表示字符串,低 6 位 000101 表示字符串 "apple" 的長度 5)
| | data | "apple"(5 字節,實際存儲的字符串內容)
+--------+
| entry2 |
| | prevlen | 7(1 字節,前一個節點 "apple" 長度為 5 字節,加上 prevlen 和 encoding 各 1 字節,共 7 字節)
| | encoding| 0b00000011(1 字節,表示存儲的是 1 字節整數)
| | data | 100(1 字節,實際存儲的整數 100)
+--------+
| entry3 |
| | prevlen | 3(1 字節,前一個節點總長度為 3 字節,即 prevlen 1 字節 + encoding 1 字節 + data 1 字節)
| | encoding| 0b10000110(1 字節,高 2 位 10 表示字符串,低 6 位 000110 表示字符串 "banana" 的長度 6)
| | data | "banana"(6 字節,實際存儲的字符串內容)
+--------+
| zlend | 0xFF(1 字節,固定值,標記壓縮列表結束)
+--------+五、Set數據結構
(1)存儲小數據時采用的結構:整數集合(intset)
- 適用場景:當集合中的元素全部為整數,并且元素數量不超過 set-max-intset-entries(默認值為 512)時,Redis 會采用整數集合來存儲集合元素
- 結構特點:
- ???????內存緊湊:整數集合是一塊連續的內存區域,其存儲效率較高,能有效節省內存空間
- 有序存儲:集合中的元素按照從小到大的順序排列,這樣可以利用二分查找來快速定位元素,時間復雜度為?O(logn)
- 自動升級:整數集合支持不同的編碼方式,如 INTSET_ENC_INT16、INTSET_ENC_INT32 和 INTSET_ENC_INT64。當插入的新元素無法用當前編碼表示時,整數集合會自動升級編碼方式,以適應新元素的存儲需求
- 示例說明:假設集合中存儲的元素為 {1, 2, 3, 4, 5},且元素數量未超過 set-max-intset-entries,Redis 會使用整數集合來存儲這些元素。存儲結構如下
+------------+-----------------+ | encoding | 表示當前的編碼方式,如 INTSET_ENC_INT16 +------------+-----------------+ | length | 集合中元素的數量,這里為 5 +------------+-----------------+ | contents | 依次存儲元素 1, 2, 3, 4, 5 +------------+-----------------+
(2)存儲大數據時采用的結構:哈希表(hashtable)
- 適用場景:當集合中的元素不全部為整數,或者元素數量超過 set-max-intset-entries 時,Redis 會使用哈希表來存儲集合元素
- 結構特點:
- ???????高效查找:哈希表的查找、插入和刪除操作的平均時間復雜度為 O(1),這使得 Redis 在處理大量元素時能保持高效的性能
- 鍵值對存儲:哈希表以鍵值對的形式存儲元素,其中鍵為集合中的元素,值統一為 NULL。這樣可以利用哈希表的特性來確保元素的唯一性
- 漸進式 rehash:當哈希表的負載因子過高時,Redis 會進行 rehash 操作,將元素從舊的哈希表遷移到新的哈希表中。為了避免一次性遷移大量元素導致的性能問題,Redis 采用了漸進式 rehash 的方式,在每次操作時逐步遷移一部分元素
- 示例說明:假設集合中存儲的元素為 {"apple", "banana", "cherry", "date"},由于元素為字符串,Redis 會使用哈希表來存儲這些元素。存儲結構如下
+-----------------+-----------------+ | 哈希表數組 | 存儲多個哈希桶 +-----------------+-----------------+ | 哈希桶 1 | 鏈表,存儲鍵值對 ("apple", NULL) +-----------------+-----------------+ | 哈希桶 2 | 鏈表,存儲鍵值對 ("banana", NULL) +-----------------+-----------------+ | 哈希桶 3 | 鏈表,存儲鍵值對 ("cherry", NULL) +-----------------+-----------------+ | 哈希桶 4 | 鏈表,存儲鍵值對 ("date", NULL) +-----------------+-----------------+
(3)結構轉換
當集合從滿足使用整數集合的條件轉變為不滿足時,Redis 會自動將整數集合轉換為哈希表。例如,當向一個原本使用整數集合存儲的集合中插入一個非整數元素,或者元素數量超過 set-max-intset-entries 時,Redis 會觸發轉換操作
六、Zset數據結構
(1)存儲小數據時采用的結構:壓縮列表(ziplist)
- 適用場景:當有序集合同時滿足元素數量少于 zset-max-ziplist-entries(默認值為 128),且每個元素的成員長度和分數長度都小于 zset-max-ziplist-value(默認值為 64 字節)時,Redis 使用壓縮列表存儲 Zset 數據
- 結構特點:
- 內存緊湊,是連續的內存塊,通過特殊編碼存儲數據節省內存
- 元素按分數從小到大順序存儲,每個元素的成員和分數依次存于壓縮列表,一個元素由兩個連續節點表示
- 示例說明:假設有序集合存儲 {"apple": 1.0, "banana": 2.0, "cherry": 3.0} 且滿足使用壓縮列表條件,其存儲結構如下
+--------+ | zlbytes| 記錄整個壓縮列表占用字節數 +--------+ | zltail | 尾節點相對于起始地址的偏移量 +--------+ | zllen | 壓縮列表中節點數量 +--------+ | entry1 | | | prevlen | 前一節點長度,首節點為 0 | | encoding| 編碼表示 "apple" 為字符串及長度 | | data | "apple" +--------+ | entry2 | | | prevlen | entry1 的長度 | | encoding| 編碼表示 1.0 分數格式 | | data | 1.0 +--------+ | entry3 | | | prevlen | entry2 的長度 | | encoding| 編碼表示 "banana" 為字符串及長度 | | data | "banana" +--------+ | entry4 | | | prevlen | entry3 的長度 | | encoding| 編碼表示 2.0 分數格式 | | data | 2.0 +--------+ | entry5 | | | prevlen | entry4 的長度 | | encoding| 編碼表示 "cherry" 為字符串及長度 | | data | "cherry" +--------+ | entry6 | | | prevlen | entry5 的長度 | | encoding| 編碼表示 3.0 分數格式 | | data | 3.0 +--------+ | zlend | 固定值 0xFF 標記結束 +--------+
(2)存儲大數據時采用的結構:跳躍表(skiplist)與哈希表(hashtable)結合
- 適用場景:當有序集合不滿足使用壓縮列表的條件時,采用跳躍表和哈希表的組合結構存儲
- 結構特點:
- 跳躍表(skiplist):
- 能高效排序與查找,通過節點維護多個指向其他節點的指針,平均時間復雜度 O(logn) 完成插入、刪除和查找
- 節點高度隨機生成,可在不同數據分布下保持較好性能
- 哈希表(hashtable):
- 能快速查找元素,以元素成員為鍵、分數為值,平均時間復雜度 O(1) 完成查找
- 兩者共享元素的成員和分數信息,操作時同時更新保證數據一致
- 跳躍表(skiplist):
- 示例說明:
- ??????????????跳躍表:
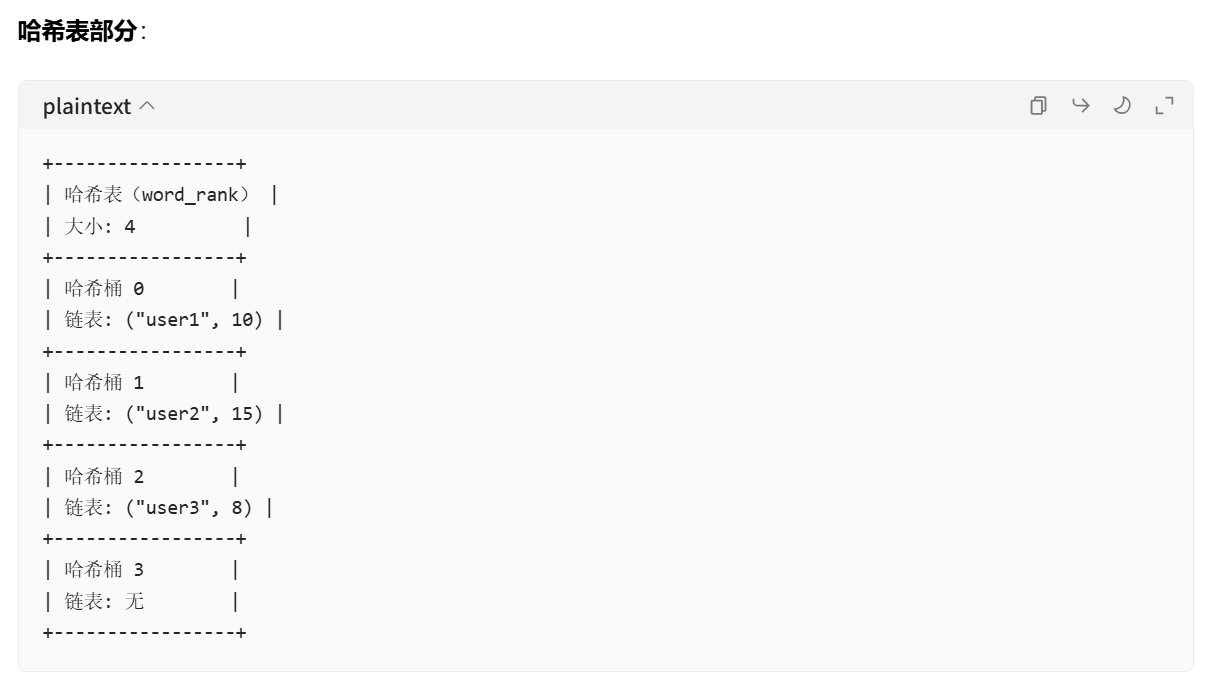
+--------+--------+--------+--------+--------+ Level 2 | Head | "cat" | "elephant" | | Tail |+--------+--------+--------+--------+--------+| | | | | || | | | | | Level 1 | Head | "cat" | "dog" | "elephant" | "fox" | Tail |+--------+--------+--------+--------+--------+--------+| | | | | | || | | | | | | Level 0 | Head | "cat" | "dog" | "elephant" | "fox" | Tail |+--------+--------+--------+--------+--------+--------+節點詳情: - Head 節點:- 各層前進指針分別指向對應層的下一個節點 - "cat" 節點:- 成員: "cat"- 分數: 2.5- 后退指針: 無- 層數: 2- 第 0 層前進指針: 指向 "dog" 節點- 第 1 層前進指針: 指向 "dog" 節點- 第 2 層前進指針: 指向 "elephant" 節點 - "dog" 節點:- 成員: "dog"- 分數: 3.5- 后退指針: 指向 "cat" 節點- 層數: 1- 第 0 層前進指針: 指向 "elephant" 節點- 第 1 層前進指針: 指向 "elephant" 節點 - "elephant" 節點:- 成員: "elephant"- 分數: 4.5- 后退指針: 指向 "dog" 節點- 層數: 2- 第 0 層前進指針: 指向 "fox" 節點- 第 1 層前進指針: 指向 "fox" 節點- 第 2 層前進指針: 指向 Tail 節點 - "fox" 節點:- 成員: "fox"- 分數: 5.5- 后退指針: 指向 "elephant" 節點- 層數: 1- 第 0 層前進指針: 指向 Tail 節點- 第 1 層前進指針: 指向 Tail 節點 - Tail 節點:- 無成員和分數 - 哈希表:
+-----------------+ | 哈希表數組 | | 大小: 4 | +-----------------+ | 哈希桶 0 | | 鏈表: ("cat", 2.5) +-----------------+ | 哈希桶 1 | | 鏈表: ("dog", 3.5) +-----------------+ | 哈希桶 2 | | 鏈表: ("elephant", 4.5) +-----------------+ | 哈希桶 3 | | 鏈表: ("fox", 5.5) +-----------------+
- ??????????????跳躍表:
- 查找過程說明:


(3)結構轉換
當有序集合元素數量或元素長度超出壓縮列表使用條件,Redis 自動將壓縮列表轉換為跳躍表和哈希表的組合結構,且此轉換不可逆
七、總結
Redis 一共有五種基本數據結構:
- String:鍵對應的值為 String 類型,其底層實現是簡單動態字符串(SDS)。SDS 不僅能存儲普通字符串、數字,還能存儲二進制數據。存儲的數據存放在 SDS 的 buf 數組部分,同時 SDS 通過額外的元數據(如長度信息等)來優化字符串操作性能,相比傳統 C 字符串,SDS 在追加、修改等操作時能更高效地管理內存,避免緩沖區溢出等問題
- List:列表類型,底層實現有壓縮列表和雙向鏈表兩種。當數據量較少且每個元素的長度較短時,Redis 會選擇壓縮列表來存儲。每次向列表中添加一個數據,該數據就會成為壓縮列表中的一個節點。壓縮列表是緊湊的連續內存結構,適合從頭部或尾部遍歷,并且可以通過 zllen 字段快速獲取元素數量。當數據量較多時,會采用雙向鏈表存儲。雙向鏈表在插入和刪除操作上具有優勢,無需移動大量元素,時間復雜度為?O(1),但在內存占用和隨機訪問性能上不如壓縮列表
- Hash:底層基于哈希表結構。當插入一個鍵值對時,先對鍵進行哈希計算,然后對哈希表的大小取模,得到對應的哈希桶索引,將鍵值對存儲到該哈希桶中。哈希桶中可能存在多個鍵值對(通過鏈表解決哈希沖突)。隨著數據量的增加,哈希表可能會出現負載因子過高的情況,此時會觸發 rehash 操作,Redis 采用漸進式 rehash 來避免一次性大量數據遷移帶來的性能問題,即在每次對哈希表進行操作時,順帶遷移一部分數據到新的哈希表中
- Set:對于小數據量且元素全為整數的情況,使用整數集合存儲。整數集合是緊湊的有序結構,能有效節省內存。當數據量較大或元素類型不全為整數時,采用哈希表存儲。向 Set 中添加數據時,如果使用哈希表存儲,數據會以鍵值對形式存儲在哈希桶中,其中鍵為數據本身,值統一為 NULL,利用哈希表的特性來保證元素的唯一性
- Zset:小數據量時采用壓縮列表存儲。壓縮列表中,每個元素的成員和分數依次存儲,元素按分數從小到大排列。當數據量較大時,采用跳躍表和哈希表結合的方式存儲。跳躍表基于節點的多層指針結構,在范圍查詢(如按分數范圍查找成員)上具有?O(logn) 的時間復雜度優勢。哈希表則用于通過成員快速查找對應的分數,因為哈希表以成員為鍵、分數為值,查找時間復雜度平均為?O(1),二者結合能高效地滿足 Zset 各種操作需求







——不僅僅是簡單的基礎設施遷移)












轉串口(TTL)模塊設計講解)


(含模型、數據、可運行代碼))
