1. 背景
近年來,隨著社交媒體、流媒體平臺以及XR設備的快速發展,沉浸式3D空間視頻的需求迅猛增長,尤其是在短視頻、直播和電影領域,正在重新定義觀眾的觀看體驗。2023年,蘋果公司發布的空間視頻技術為這一趨勢注入了新的活力,2025年以來,輕量化AI/AR眼鏡迎來爆發,持續推動對3D空間視頻內容的需求。然而,盡管消費端對3D內容的需求不斷上升,供給端仍面臨創作瓶頸,主要體現在可用于拍攝3D視頻內容的專業相機設備稀缺、制作專業度要求高以及成本高昂等問題。
我們創新性地提出了一種基于3D視覺和AIGC生成技術的方法,將存量的2D視頻資源不斷轉化為3D空間視頻資源,極大降低了3D內容的供給成本,提升了覆蓋量。最新的研究成果已被多媒體領域的旗艦會議ICME 2025接受,并在京東.Vision視頻頻道等業務場景落地。ICME(International Conference on Multimedia and Expo)是由IEEE主辦的國際多媒體與博覽會,2025年會議將在法國舉行,主題涵蓋3D多媒體、增強現實(AR)、虛擬現實(VR)、沉浸式多媒體和計算機視覺等領域。本次會議共計收到來自全球3700多篇投稿,錄用率為27%。我們提出的基于人工智能的2D視頻轉換為3D空間視頻的方法,涉及深度估計、圖像生成等算法,并構建了一個3D視頻數據集,作為后續行業發展的評測基準。

圖1 研究成果被ICME 2025接收
2. 技術方案
3D空間視頻生成屬于新視角合成任務(Novel View Synthesis),指的是在給定源圖像和目標姿態的情況下,通過算法渲染生成與目標姿態對應的圖像。最新的通用新視角合成方案包括基于NeRF神經輻射場、Gaussian Splatting高斯噴射以及Diffusion Model擴散模型等。與通用的任意視角合成不同,3D空間視頻需為雙眼分別提供具有視角差的畫面,算法需根據輸入的一幀左視角圖像,生成對應的固定姿態右眼視角圖像。
為了實現端到端的3D空間視頻生成,我們的算法技術方案主要包含三個部分,分別是單目深度估計、新視角合成(包括視差圖計算、Warp和空洞區域填充)以及MV-HEVC編碼,整體方案如下圖2所示。

圖2 3D空間視頻生成架構
我們的最新研究成果基于上述架構,針對單目深度估計、新視角合成和MV-HEVC編碼等三個核心模型進行了創新和優化。此外,考慮到該領域內用于訓練與評測的Benchmark數據集在質量和規模上普遍較差的現狀,我們創建了一個高質量、大規模的立體視頻數據集StereoV1K。該數據集包含在各種真實場景中捕獲的1000個視頻,分辨率為1180×1180,總幀數超過50萬幀。StereoV1K將作為該領域的重要基準數據集。
2.1 單目深度估計
深度估計是計算機視覺領域的一個基礎性問題,旨在從圖像或視頻中推斷出場景中物體的距離或深度信息。這項技術對增強現實、虛擬現實、機器人導航以及自動駕駛汽車等應用至關重要。深度估計的目標是根據給定的輸入圖像,預測每個像素點或圖像中物體的相對距離或真實深度值。常見的深度估計方法包括基于深度相機等TOF(Time of Flight)和激光雷達(LiDAR)硬件設備的方案、基于雙目圖像的立體匹配算法方案,以及基于單目深度估計(Monocular Depth Estimation, MDE)算法模型的方案。其中,單目深度估計由于成本較低、適用場景廣泛,更容易普及,但算法的難度也相對較大。
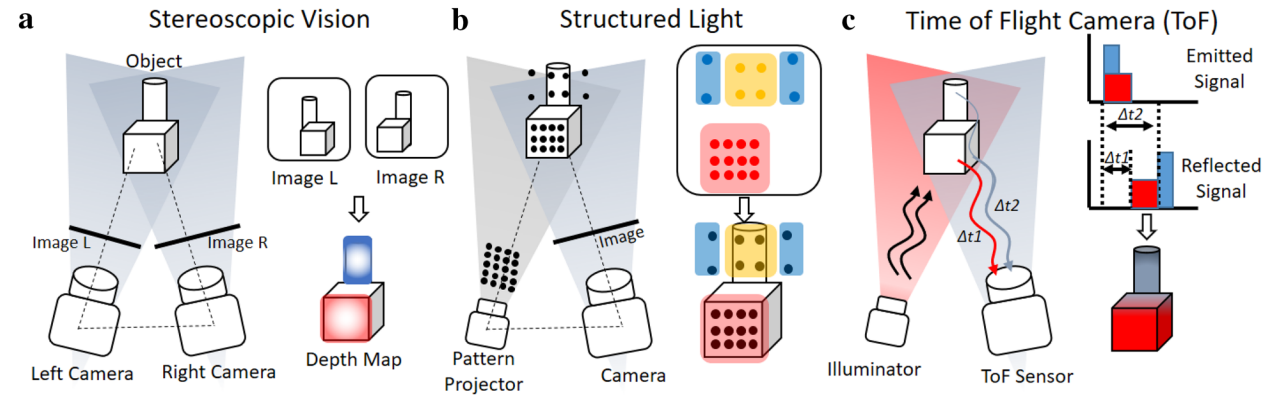
圖3 基于雙目圖像立體匹配以及硬件的深度估計方案
伴隨著AI大模型算法的快速發展,單目深度估計在技術方案上經歷了從傳統方法到基于深度學習的方法,再到最新的基于大模型或生成式方法的演變。根據處理對象的不同,單目深度估計可以進一步細分為圖像深度估計和視頻深度估計。通常情況下,圖像深度估計在細節表現上更為出色,而視頻深度估計則在時序一致性方面表現更佳。此外,從估計結果的角度來看,單目深度估計還可以分為絕對深度估計和相對深度估計。絕對深度估計指的是從圖像中估計出每個像素到攝像機的真實物理距離,而相對深度估計則關注圖像中物體之間的深度關系,而非絕對距離。基于我們的應用場景,我們采用了一種結合圖像和視頻深度估計優點的單目相對深度估計算法。該算法架構如下:我們使用DINO v2作為Backbone,并結合DPT Head,同時嘗試引入多幀序列的memory bank和注意力機制,以提升深度估計結果在時序上的準確性與穩定性。算法架構如圖4所示。
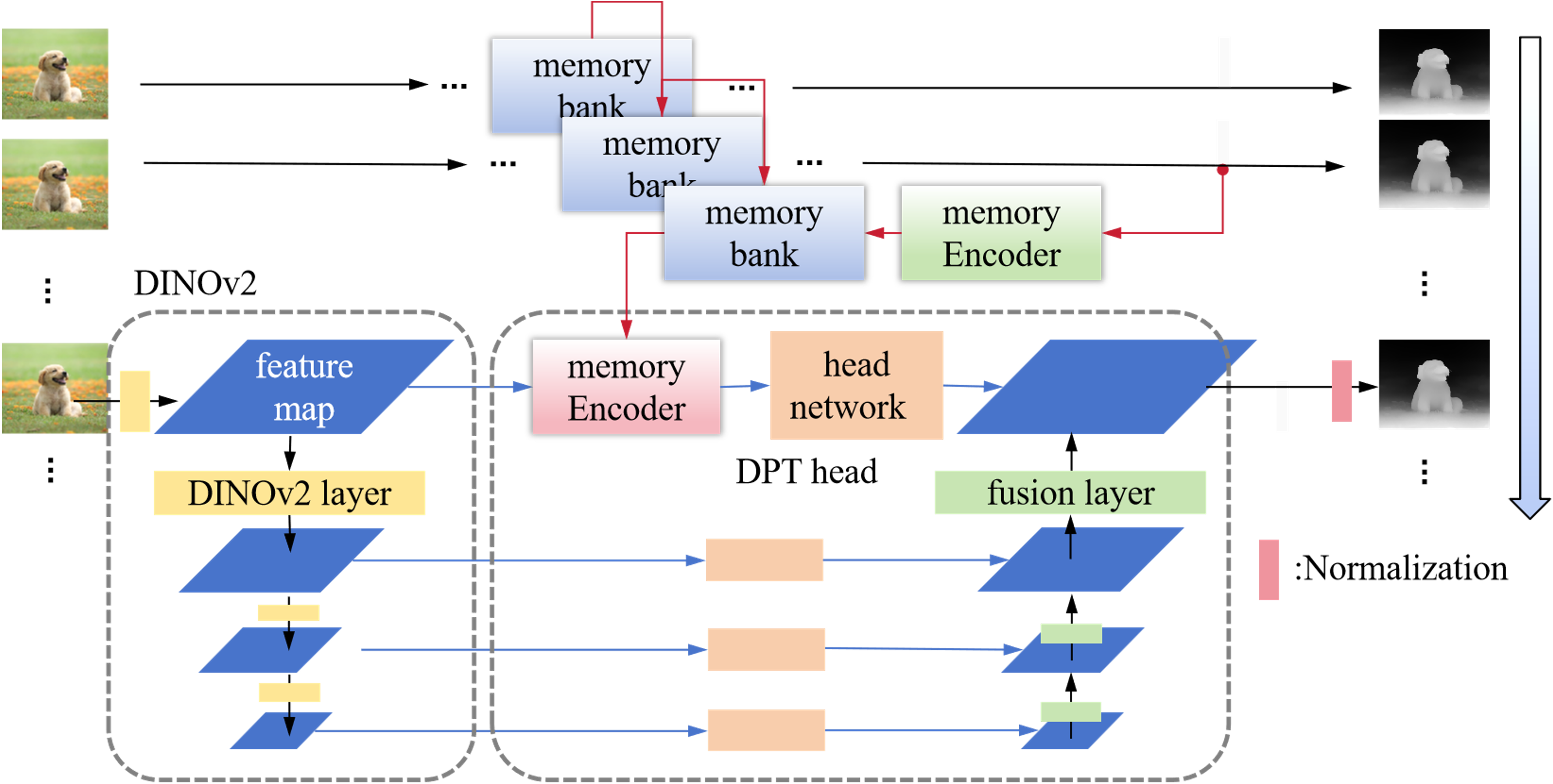
圖4 視頻單目深度估計算法架構
通過在短視頻等數據上構建百萬級的偽標簽訓練數據集,并采用SFT(Supervised Fine-Tuning)和蒸餾等技術手段,我們對開源模型進行了優化。效果如圖5所示,可以明顯看到,我們不僅提升了深度估計的細節表現,還確保了估計結果的時序穩定性。


圖5 視頻單目深度估計算法優化效果對比
2.2 新視角合成
新視角合成是視覺領域中的一項關鍵任務,其目標是在有限的視圖基礎上生成場景或物體的其他視角。這項技術在虛擬現實、增強現實、電影特效和游戲開發等領域具有廣泛應用。盡管基于NeRF、3DGS和Diffusion的方法近年來取得了顯著進展,但仍面臨諸多挑戰。例如,NeRF和3DGS方法通常只能針對單一場景進行建模,而擴散模型在生成視頻時難以保證穩定性和一致性。在分析任務的特殊需求時,我們發現只需生成固定姿態的右眼視角圖像,且場景具有位移小、豐富多樣以及視頻穩定性和一致性要求高等特點。基于這些考慮,我們最終選擇采用深度Warp和空洞區域填充InPaint的方法來完成新視角合成任務。
在2.1部分獲取到視頻對應的深度信息后,我們首先計算視差圖,并引導輸入的單目視頻進行Warp操作,從而生成對應的待填充右視角視頻和掩碼視頻。接下來,我們將這些數據輸入到我們設計的InPaint填充框架中,以完成空洞區域的補全,最終得到完整的新視角結果。整體框架圖如圖6所示:
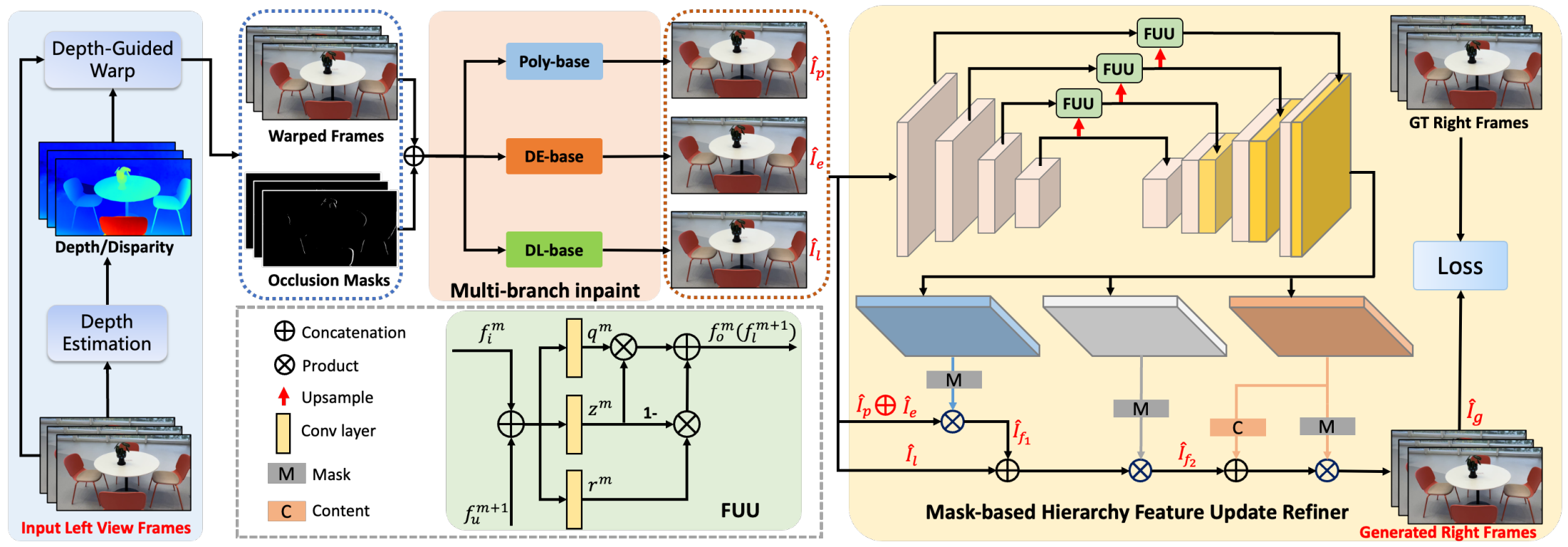
圖6 新視角合成端到端算法架構
2.2.1 多分支InPaint模塊
為了獲得高質量和高一致性的InPaint填充效果,我們采用了多分支填充策略。該模塊集成了三種InPaint分支:傳統多邊形插值修復(Poly-base)、深度學習神經網絡修復(DL-base)和視差擴展策略修復(DE-base)。每個分支各有優缺點:(i) Poly-base能夠保證視頻的穩定性并減少字幕抖動,但在邊緣填充時容易出現像素拉伸和毛刺;(ii) DL-base在前景和背景邊緣的填充效果良好,但視頻穩定性較差,可能導致字幕抖動和前景滲透;(iii) DE-base優化了像素拉伸和前景滲透問題,但在復雜背景和幾何結構處可能提供錯誤的參考像素。我們結合這些分支的互補優勢,以實現更好的填充效果。下圖展示了我們視差擴展策略的有效性。
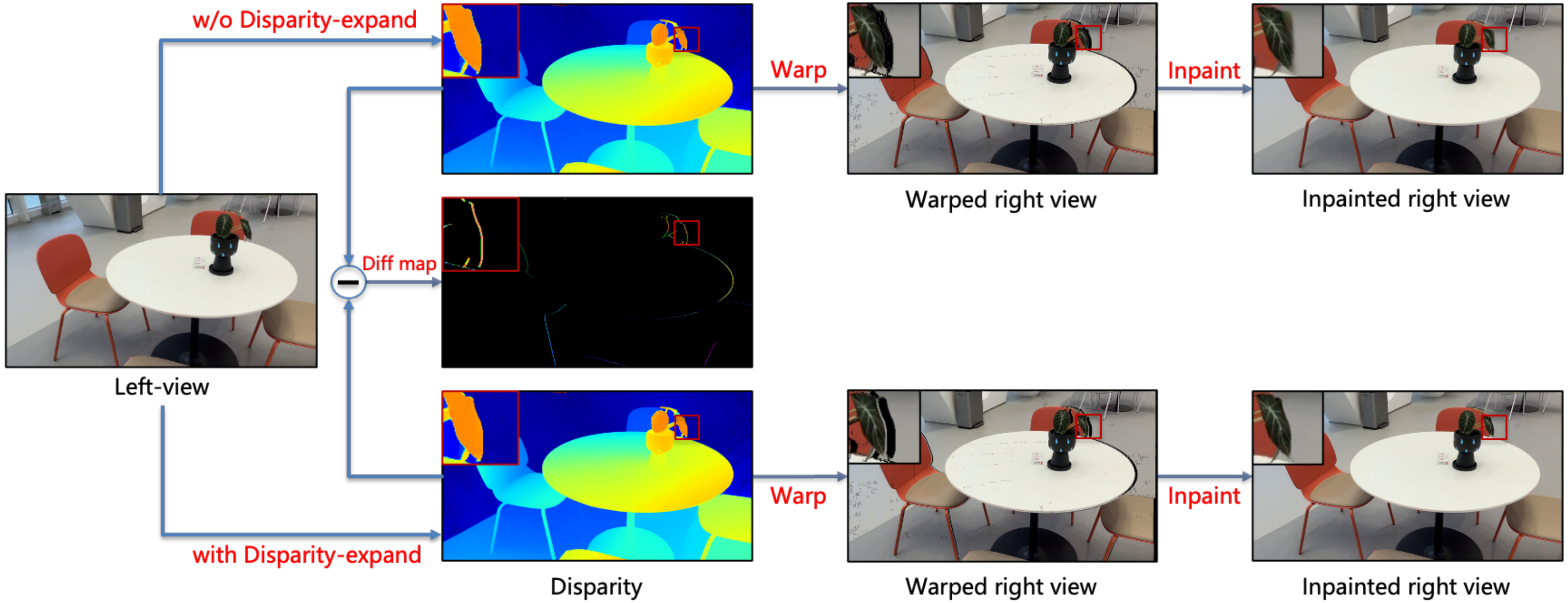
圖7 視差擴展策略與優化效果
為了更好地融合上述三個分支的結果并進行進一步優化,我們提出了一種新穎的基于層級化特征更新的掩碼融合器。該融合器的輸入為多分支填充模塊三個分支的輸出結果,輸出則為三張單通道的掩碼圖M1,M2,M3和一張三通道的內容圖C,通過融合這些信息,我們能夠獲得最終的生成結果。
我們的結果在與當前先進模型的定量和定性比較中均表現出色,達到了SOTA(State-of-the-Art)水平。特別是在LPIPS指標上,我們的方法相比其他方法提升了超過28%,充分體現了結果的真實性和優越性。同時,在可視化效果方面,我們的方法顯著減少了生成區域中的模糊偽影和前背景的錯誤拉伸,呈現出更加清晰自然的邊緣和內容,如圖8所示。

圖8 多分支InPaint方法與其他方法結果對比
2.2.2 StereoV1K立體視頻數據集
在3D空間視頻生成領域,現有的公開數據集存在量級小、分辨率低、場景單一和真實性差等問題,限制了行業算法的發展與提升。為了解決這些問題,我們創建了StereoV1K,這是第一個高質量的真實世界立體視頻數據集。我們使用最新的佳能 RF-S7.8mm F4 STM DUAL鏡頭和EOS R7專業相機,在室內和室外場景中拍攝了1000個空間視頻。每個視頻裁剪后的分辨率為1180×1180,時長約20秒,錄制速度為50 fps,最終整個數據集的總幀數超過了500,000幀。圖9展示了與其他數據集的對比以及我們數據集的示例。該數據集將作為該領域的基準數據集,推動行業的發展。
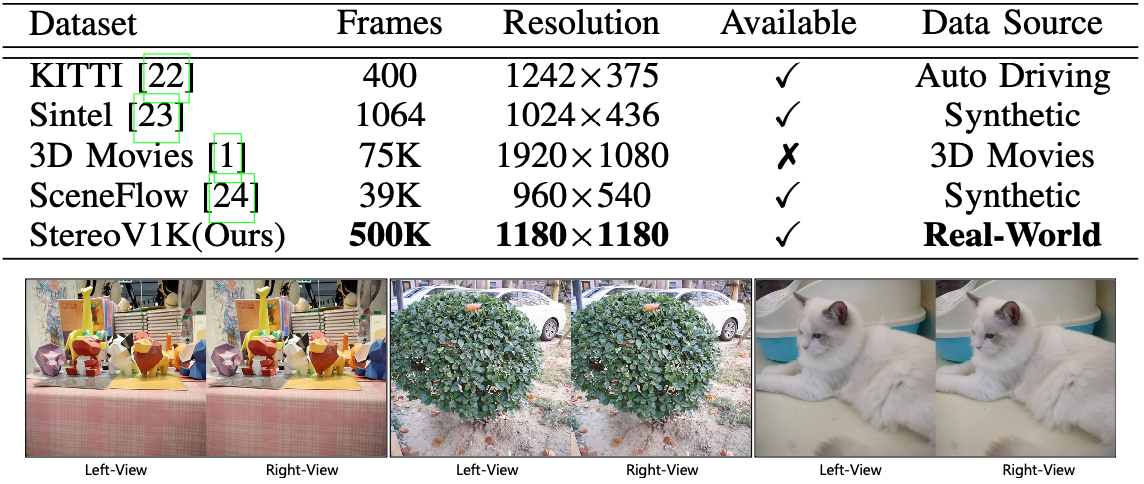
圖9 StereoV1K數據集與現有數據集對比
2.3 MV-HEVC編碼
通過上述算法框架,我們能夠生成高質量的雙目3D視頻,包括左眼視頻和右眼視頻,其數據量是傳統2D視頻的兩倍。因此,高效壓縮和編碼3D視頻在實際應用中顯得尤為重要,這直接關系到在線播放視頻的清晰度和帶寬。目前,3D視頻編碼主要分為兩類方法:傳統的SBS(Side-by-Side)HEVC編碼方式以及MV-HEVC(Multi-View HEVC)編碼。
-
SBS-HEVC:該方法將3D視頻在相同時間點的左右眼畫面拼接為一個普通的2D畫面,并采用傳統的HEVC編碼技術進行壓縮。該方案實現簡單,可以使用如ffmpeg等開源軟件進行處理。然而,SBS-HEVC的編碼壓縮率較低,因此需要更大的傳輸帶寬。
-
MV-HEVC:該方法將3D視頻的不同視角編碼到同一碼流中,允許用戶在不同視角之間自由切換。編碼器可以利用左右眼畫面之間的相似性來進一步減少冗余,從而顯著提升壓縮編碼效率。MV-HEVC編碼是對標準HEVC的擴展,目前除了蘋果AVFoundation框架中提供的閉源工具外,尚無自主可控的編碼軟件可供部署,用戶需要自定義編碼器來實現這一功能。
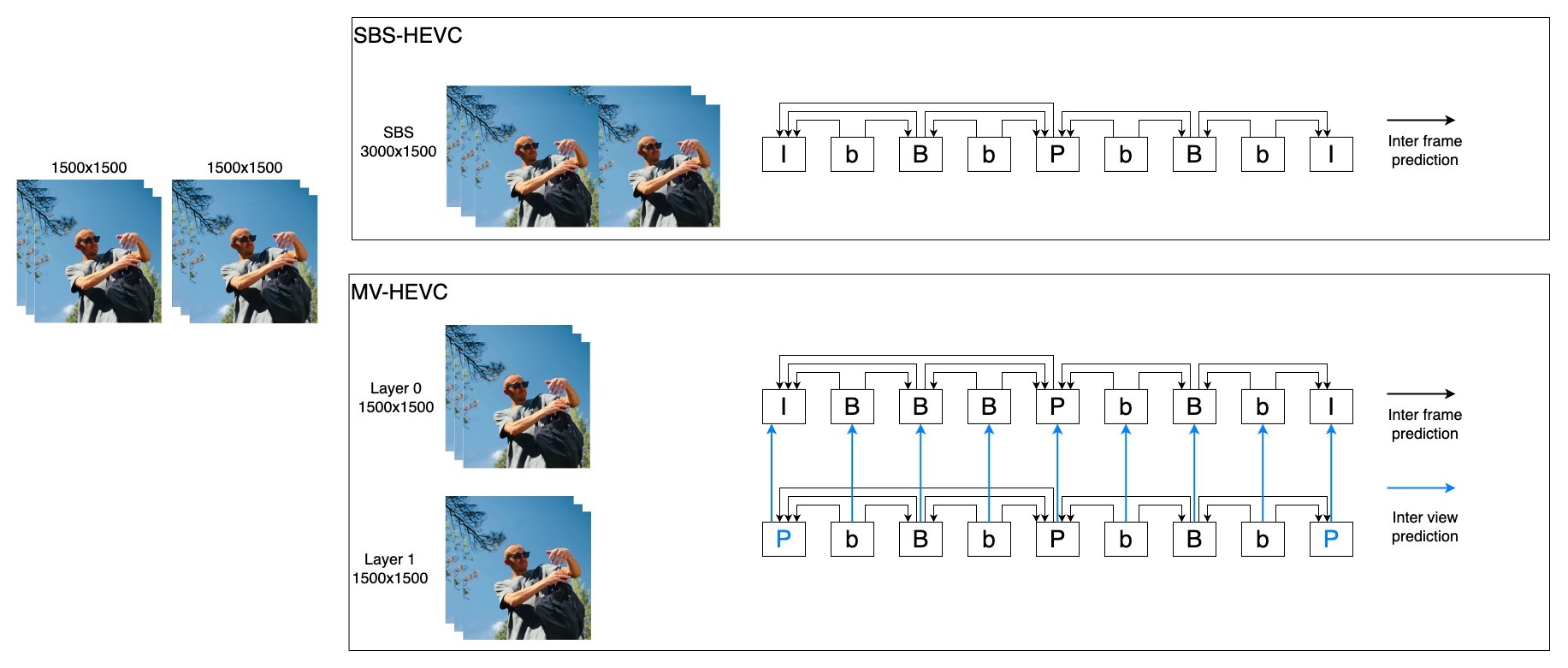
圖10 SBS-HEVC和MV-HEVC編碼方式對比
以1920x1080的視頻為例,在SBS-HEVC編碼流程中,畫面以“左+右”的形式合并為3840x1080的新視頻幀,然后作為普通視頻進行HEVC編碼,此時只能使用幀間預測(Inter frame prediction)。而在MV-HEVC編碼流程中,左眼和右眼分別被稱為基本層(Layer 0)和增強層(Layer 1)。除了幀間預測外,MV-HEVC還可以利用“視間預測”(Inter view prediction),因為同一時間點的左眼和右眼畫面之間具有較高的相似性和冗余性,因此視間預測能夠進一步提升壓縮效率。
我們在標準HEVC編碼器的基礎上添加了對MV-HEVC擴展的支持,從而在編碼性能和編碼速度上都取得了顯著提升。在典型測試場景中,MV-HEVC相比SBS-HEVC的BD-Rate降低了33.28%,這意味著在相同畫質下,視頻帶寬可以減少33%;同時,編碼速度平均提升了31.62%,具體數據如圖11所示。
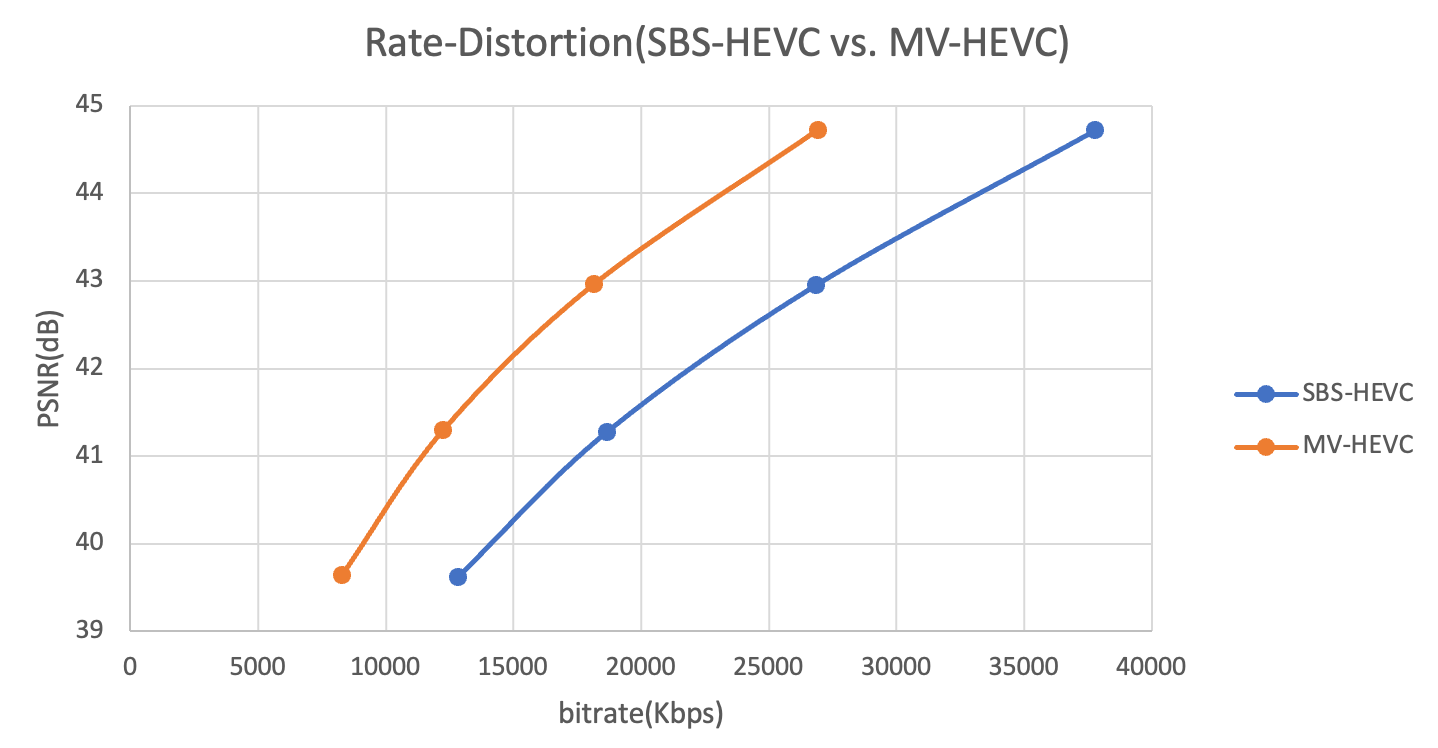
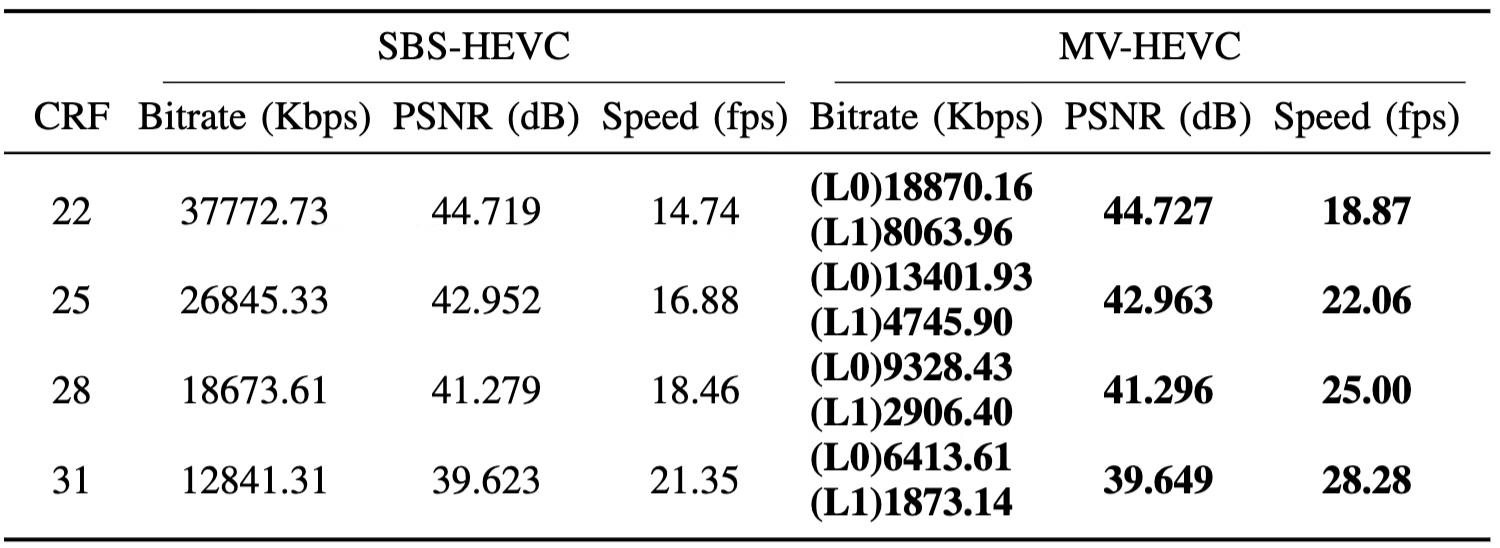
圖11 SBS-HEVC和MV-HEVC的編碼RD性能對比
在使用MV-HEVC解決雙目3D視頻的壓縮編碼問題后,還需要將視頻和音頻數據打包存儲,以實現在線流媒體播放。蘋果為MV-HEVC定制了封裝格式,但通過ffmpeg、mp4box等開源媒體工具封裝的文件在Vision Pro、iPhone等蘋果設備上無法正常顯示立體視頻。為此,我們對由AVFoundation封裝出的正常碼流進行了逆向分析,從中提取出與蘋果設備兼容的碼流格式,并在自研編碼器中實現了這一格式。與蘋果設備兼容的碼流格式為:
-
使用mov格式,整體符合QuickTime File Format Specification;同時符合mp4格式標準ISO/IEC 14496-15的標準定義。
-
在視頻軌道的描述信息中,在stsd中重新定義hvc1、hvcC、lhvC,增加對于不同視角視頻的描述,其中hvcC描述基本層碼流信息,包括VPS, SPS, PPS, SEI這4個HEVC NAL頭信息;lhvC描述增強層碼流信息,包括 SPS, PPS信息。
-
增加蘋果自定義信息vexu、hfov,用于描述自定義信息,其數據結構如圖12所示,其中關鍵字段有:blin:定義baseline,表示相機基線,以實際數值的1000倍來記錄,例如Vision Pro的63.54mm記錄為63540。dadj:定義disparity,表示水平視差調整,以實際數值的10000倍來記錄,例如Vision Pro的2.93%記錄為293。hfov:表示水平視場角,以實際數值的1000倍來記錄,例如Vision Pro的71.59度記錄為71590。
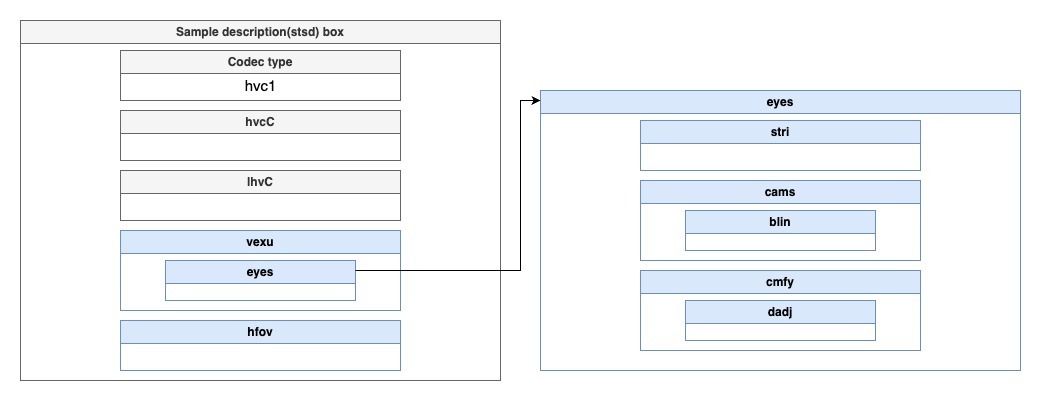
圖12 蘋果自定義信息vexu、hfov示意圖
2.4 應用與落地
為了在實際業務中落地,我們首先簡化了單目深度估計模型的尺寸,采用ViT-S作為特征編碼器,并對模型進行了SFT微調。隨后,我們將論文中的InPaint基礎模型更換為全新輕量的Transformer方案,并在自建的StereoV1K數據集上訓練了多分支InPaint模型。通過這些手段,我們實現了速度與質量的平衡。在對實際業務中的大量視頻進行測試后,我們發現我們的算法生成的3D空間視頻很好地滿足了業務需求,但仍有少數生成結果存在一些不理想的情況。未來,我們將持續迭代優化相關模型。此外,當前的生成速度也是一個重點優化方向。
當前,3D空間視頻可以在多種XR設備上觀看與體驗,包括Vision Pro、Pico、Quest以及AI眼鏡等雙目設備。例如,我們為京東.Vision視頻頻道提供了空間視頻內容的算法服務,通過將2D商品短視頻、宣傳片和發布會等資源轉換為3D立體空間視頻,極大提升了用戶的沉浸式和立體觀看體驗。此外,在更輕量的AI/AR眼鏡中,用戶也可以方便地體驗到3D視頻內容帶來的震撼與沉浸感。
3. 未來展望
上述介紹的3D空間視頻為用戶帶來了全新的沉浸式體驗,并為3D視頻域提供了批量內容供給。然而,3D領域的內容表現形式還有很多種,例如3D模型、3D/4D空間和完整世界等。隨著大模型的快速發展,算法對人類世界的建模正經歷以下幾個階段:大語言生成模型 → 圖像生成模型 → 視頻、3D/4D生成模型 → 世界模型。可以預見,未來將有更多的工作集中在AIGC 3D/4D和世界模型生成等方向。
3.1 AIGC 3D/4D
2024年,3D/4D領域的AIGC發展迅速,尤其是從下半年開始,呈現出加速趨勢。同時,新的發展方向也開始顯現。從技術路線來看,有Google的CAT3D,通過單圖到多圖再到3D表示的方式;還有使用LRM的單圖到3D表示的方案,如InstantMesh,以及近期基于結構化3D表征的Trellis。此外,一些學者正在基于4D Gaussian Splatting實現空間序列的建模。值得一提的是,3D/4D模型的可編輯性是一個重要的關注點,因為即使是專業建模師也要在生產過程中需要不斷編輯和修改。最新的研究方向也開始關注生成過程的可控性與可編輯性等屬性。圖13所示為AIGC 3D模型與4D視頻生成示例。


圖13 AIGC 3D模型與4D視頻生成示例
在當前的AIGC 3D模型生成技術中,像Trellis這樣采用3D表征的端到端訓練方案展現出顯著優勢。通過對3D表征進行直接的結構化編碼,該模型在幾何形狀和紋理貼圖的生成上實現了更高的準確性和魯棒性,能夠生成高質量且多樣化的3D資產,具備復雜的形狀和紋理細節。此外,由于模型處理的是結構化信息,它支持靈活的3D編輯,例如根據文本或圖像提示進行局部區域的刪除、添加和替換,如圖14左圖所示。在4D視頻生成技術中,當前主流的方案是采用帶有時序的Gaussian Splatting表征進行建模,如圖14右圖所示。由于高斯表征本身的大小以及存在維度提升,4D視頻面臨著數據體量大、模型復雜度高、渲染性能壓力大等挑戰。

圖 14 Trellis根據文本提示詞進行紋理材質以及幾何結構的局部編輯以及典型4D Gaussian Splatting架構
3.2 世界模型
目前,世界模型在學術界和工業界尚未形成明確的概念,關于其是模擬世界還是感知世界也沒有統一的范式。然而,從近期的進展來看,世界模型需要具備時序和立體空間的結構化建模能力。建模后的數據應具有稠密的語義表征和局部可編輯性,同時整個時序與空間域需具備可交互性。最終目標是實現對現實空間的復刻,甚至對現實空間進行創作與未來預測。圖15所示為World Labs世界模型以及Meta orion AI 眼鏡空間萬物感知。


圖15 World Labs世界模型以及Meta orion AI 眼鏡空間萬物感知
我們將持續關注并深入跟進3D領域的最新進展,特別是在技術創新和應用實踐方面的動態。結合京東廣泛的業務場景,我們致力于將這些前沿技術落地并轉化為實際應用,以滿足用戶日益增長的需求。通過不斷探索3D技術在電商、廣告、內容等多個領域的潛力,我們希望為用戶帶來全新的體驗,提升他們的購物樂趣和互動感。我們的目標是通過創新的解決方案,推動行業的發展,為用戶創造更高的價值和更豐富的體驗。
4.參考文獻
-
Zhang J, Jia Q, Liu Y, et al. SpatialMe: Stereo Video Conversion Using Depth-Warping and Blend-Inpainting[J]. arXiv preprint arXiv:2412.11512, 2024.
-
Yang, Sung-Pyo, et al. "Optical MEMS devices for compact 3D surface imaging cameras."Micro and Nano Systems Letters7 (2019): 1-9.
-
Bhat S F, Birkl R, Wofk D, et al. Zoedepth: Zero-shot transfer by combining relative and metric depth[J]. arXiv preprint arXiv:2302.12288, 2023.
-
LiheYang, BingyiKang, ZilongHuang, ZhenZhao, XiaogangXu, Jiashi Feng, and Hengshuang Zhao, “Depth anything v2,” arXiv preprint arXiv:2406.09414, 2024.
-
Teed Z, Deng J. Raft: Recurrent all-pairs field transforms for optical flow[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16. Springer International Publishing, 2020: 402-419.
-
Zhang K, Fu J, Liu D. Flow-guided transformer for video inpainting[C]//European conference on computer vision. Cham: Springer Nature Switzerland, 2022: 74-90.
-
Shangchen Zhou, Chongyi Li, Kelvin CK Chan, and Chen Change Loy, “Propainter: Improving propagation and transformer for video inpainting,” in ICCV, 2023, pp. 10477–10486.
-
Han Y, Wang R, Yang J. Single-view view synthesis in the wild with learned adaptive multiplane images[C]//ACM SIGGRAPH 2022 Conference Proceedings. 2022: 1-8.
-
Wang L, Frisvad J R, Jensen M B, et al. Stereodiffusion: Training-free stereo image generation using latent diffusion models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 7416-7425.
-
Zhen Lv, Yangqi Long, Congzhentao Huang, Cao Li, Chengfei Lv, and Dian Zheng, “Spatialdreamer: Self-supervised stereo video synthesis from monocular input,” arXiv preprint arXiv:2411.11934, 2024.
-
Mildenhall B, Srinivasan P P, Tancik M, et al. Nerf: Representing scenes as neural radiance fields for view synthesis[J]. Communications of the ACM, 2021, 65(1): 99-106.
-
Kerbl B, Kopanas G, Leimkühler T, et al. 3d gaussian splatting for real-time radiance field rendering[J]. ACM Trans. Graph., 2023, 42(4): 139:1-139:14.
-
Gao R, Holynski A, Henzler P, et al. Cat3d: Create anything in 3d with multi-view diffusion models[J]. arXiv preprint arXiv:2405.10314, 2024.
-
Xu J, Cheng W, Gao Y, et al. Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models[J]. arXiv preprint arXiv:2404.07191, 2024.
-
Xu Z, Xu Y, Yu Z, et al. Representing long volumetric video with temporal gaussian hierarchy[J]. ACM Transactions on Graphics (TOG), 2024, 43(6): 1-18.
-
Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
-
Xiang, Jianfeng, et al. "Structured 3d latents for scalable and versatile 3d generation." arXiv preprint arXiv:2412.01506 (2024).
-
Wu G, Yi T, Fang J, et al. 4d gaussian splatting for real-time dynamic scene rendering[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2024: 20310-20320.
-
Meng-Li Shih, Shih-Yang Su, Johannes Kopf, and Jia-Bin Huang. “3d photography using context-aware layered depth inpainting.” in CVPR, 2020, pp. 8028–8038.
-
https://zhuanlan.zhihu.com/p/17003931453
-
https://zhuanlan.zhihu.com/p/15449644319
-
Gerhard T, Ying Chen, Karsten Müller, et al. Overview of the Multiview and 3D Extensions of High Efficiency Video Coding. IEEE TRANS. ON CSVT, VOL. 26, NO. 1, JANUARY 2016
-
https://developer.apple.com/av-foundation/HEVC-Stereo-Video-Profile.pdf
-
H.265?:?High efficiency video coding Spec, H.265?:?High efficiency video coding
-
ISO/IEC 14496-15:2022(en), https://www.iso.org/obp/ui/en/#iso:std:iso-iec:14496:-15:ed-6:v1:en
-
QuickTime File Format, QuickTime File Format | Apple Developer Documentation
-
BBScloud用戶社區
-
World Labs
-
Introducing Orion, Our First True Augmented Reality Glasses | Meta
-
Encoding Spatial Video – Mike Swanson's Blog
-
Li T, Slavcheva M, Zollhoefer M, et al. Neural 3d video synthesis from multi-view video[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 5521-5531.









轉串口(TTL)模塊設計講解)


(含模型、數據、可運行代碼))

:探索C++運算符重載設計精髓)



-第十六天)
