在數據倉庫領域,Apache Doris 憑借其卓越性能與便捷性被廣泛應用。其中,FE(Frontend)作為核心組件,承擔著接收查詢請求、管理元數據等關鍵任務。然而,在實際使用中,FE 難免會遭遇各類問題,影響系統的正常運行與性能表現。本文將深入剖析 Doris FE 常見問題及其處理辦法。

一、定位 FE 問題的關鍵信息
當 FE 出現問題時,精準定位是解決問題的首要步驟。首先,需關注出問題前后 1 天左右的日志,若為多節點部署,每個節點的相關日志都至關重要。這些日志包括:
-
fe/log目錄下的fe.log(記錄 FE 運行的關鍵事件與錯誤信息)、fe.audit.log(審計日志,可用于追蹤操作記錄)、fe.gc.log(垃圾回收日志,對分析內存問題有重要參考價值)以及fe.out(包含fe啟動和宕機的相關信息)。 -
fedoris - metabdbje.info.0(bdbje 日志,其打印時間為 UTC 時間,需注意加上 8 小時轉換為北京時間)。 -
精確到 commit 號的版本信息,可通過執行
start_fe.sh --version在控制臺輸出或fe.out中獲取。 -
show frontends的全部輸出,能展示 FE 節點的詳細狀態信息。 -
若有 prometheus 監控,還需提供如 jvm heap 堆內存使用情況、線程數量、導入 job 數量、checkpoint 失敗次數等監控數據。
-
當 FE 卡住時,需通過
jstack -l $(pid)> jstack txt搜集 jstack 信息;若內存使用高達數十 GB,則需jmap信息。 -
機器的 cpu、內存、磁盤 io、網絡的 promethues 監控情況,排查是否存在 cpu 打滿、物理內存耗盡、磁盤 io 秒級延遲、網絡丟包等問題。
-
dmesg -T > dmesg txt信息,常用于定位FE OOM的問題。
二、FE 常見問題解析與應對
(一)FE 掛掉
master 節點寫達不成多數派掛
Insufficient acks for policy:SIMPLE_MAJORITY. Need replica acks: 1. Missing replica acks: 1
原因:
-
內存使用過高,可能是 cms 垃圾回收器遭遇 “promotion failed” 或者 “concurrent mode failure”,此時需排查內存使用情況,可通過
jmapdump 內存鏡像并用jprofiler進行分析(搞不了的話,可以聯系社區同學協助分析)。 -
多節點環境下,若其他節點狀態邏輯錯誤已死掉,僅剩一個 master 節點,需同時查看其他 fe 節點日志,確認其存活狀態與是否有異常退出棧。
-
某些節點機器的物理資源(cpu、內存、io)存在瓶頸,需查看機器相應監控。
-
master 因 gc 或者 io 寫 io 消耗時間太長,如在
je.info.0中出現類似日志
2025 - 03 - 04 01:27:00.165 UTC WARNING [fe_026093bb_658d_41dc_8f8b_96bd5a968c24] FSync time of 106698 ms exceeds limit (5000 ms)” 的日志。
fe 堆內存 OOM
現象與處理:fe.out中會有相應打印,出現該情況需分析 fe jvm 堆內存占用情況。 需要在后續內存高的時候dump內存出來,具體分析一下

幾種常見的oom場景見下文 “fe內存問題”
操作系統 oom 殺掉 java 進程
原因:機器上其他進程占據過多內存,致使 fe 無法獲取 jvm - Xmx 配置的堆內存,操作系統啟動 oom - killer 線程殺掉 fe。
排查方法:通過dmesg -T | grep -i java查看日志信息,
(二)FE 內存問題
堆內存內存高,遇到 gc 降級,master pause 太長時間,導致 fe 掛
場景:尤其在高頻導入情況下,事務和 LoadJbb 占內存多,其他 follower 重新選舉后,原 master 退出,新接任的 master 節點重復出現該問題。
解決辦法:
- 配置label 保留參數:
label_keep_max_second = 21600 // 6 hour
streaming_label_keep_max_second = 21600 // 6 hour
- 修改FE JVM 的 gc算法為g1,參考如下
JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false -Xmx8g -XX:+UnlockExperimentalVMOptions -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:$LOG_DIR/log/fe.gc.log.$DATE -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=50M -Dlog4j2.formatMsgNoLookups=true"
schema change job 數量多
影響:可能導致 fe com 或者出現上述堆內存高的情況(較新版本有優化)。
誤開 profile 或者 profile 功能存在 bug(2.0.2版本之后已經優化了)
cms 垃圾回收器回收不及時
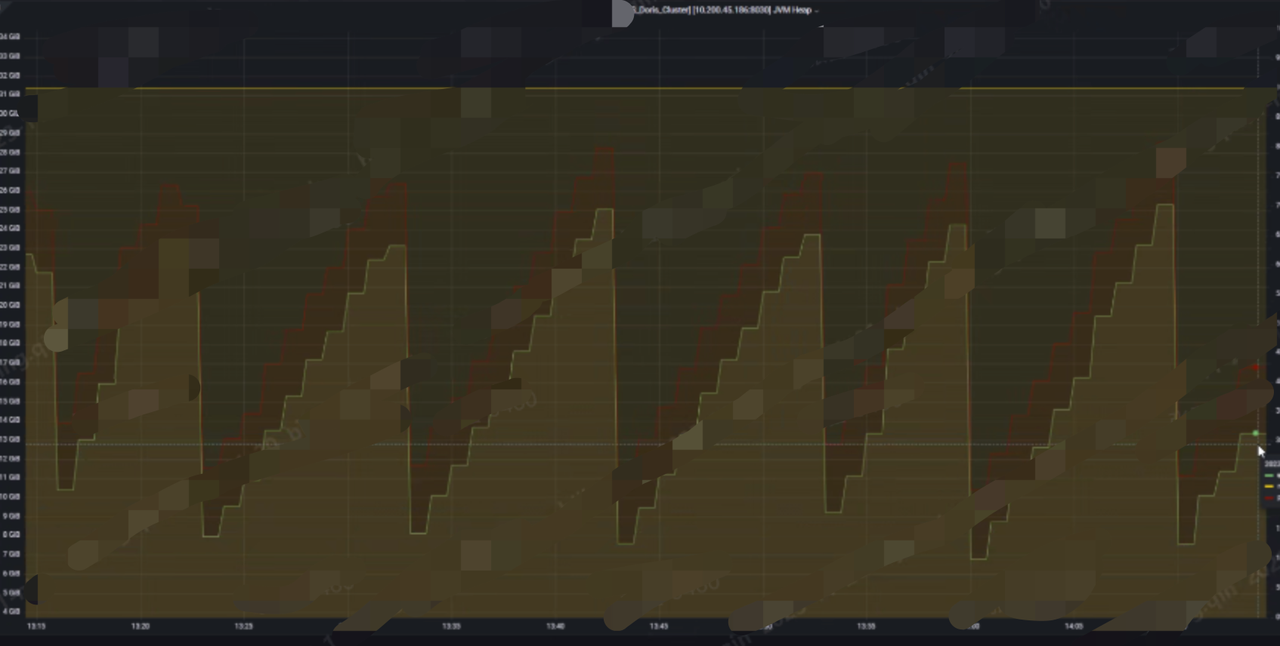
現象:待回收臨時對象多,導致內存使用高,遇到 gc 降級 fe 掛,內存使用量監控呈鋸齒狀,類似下圖(同堆內存高問題,新版本改為 g1 回收器)。
(三)FE 啟動不起來
meta out of date 或者 wait catalog to be ready
原因:
-
磁盤空間不足,bdbje 禁止寫入,出現 “com.sleepycat je.DiskLimitException” 錯誤。
-
meta out of date 偶爾打印一次屬正常,可調參數。meta_delay_toleration_second 默認值 300(5 分鐘),元數據延遲間隔時間。
啟動時打印少數幾次 meta out of date,隨后不再打印,也為正常現象。
時鐘不同步:
如出現 “Clock delta: xxxx ms.between Feeder” 類似的日志
this Replica exceeds max permissible delta: 5000 ms. HANDSHAKE_ERROR: Error during the handshake between two nodes. Some validity or compatibility check failed, preventing further communication between the nodes
這是節點間時鐘不同步,需要校正時鐘。
doris fe 代碼 bug(序列化 / 反序列化問題 / NullPointerException)等。
已經修復了,修復pr(推薦升級):
https://github.com/apache/doris/pull/26563
https://github.com/apache/doris/pull/30337
https://github.com/apache/doris/pull/30441
doris fe 非主節點寫 editlog 導致
類似下圖這種,已經修復(推薦升級):https://github.com/apache/doris/pull/29395

運維操作不當
- 做了降級操作,高版本的 doris - meta 元數據用低版本的 jar 包啟動。比如報錯這種(僅供參考):
Unknown meta module: workloadSchedPolicy
- 升級操作 jar 替換不全或未清理舊版本 jar 包。比如報錯(僅供參考):
“java.lang.NoSuchMethodError: 'com.google.gson.GsonBuilder com.google.gson.GsonBuilder.addReflectionAccessFilter”
長時間 checkpoint 失敗導致重新啟動慢
可通過ls doris-meta/image -l查看最近 checkpoint 成功的時間,正常情況下 10 分鐘會有一次成功的 checkpoint。
(四)doris - meta/bdb 目錄大(幾十 GB)
需先檢查所有節點狀態是否正常,master 近期是否做 checkpoint,內存使用超過 jvm heap 70% 不做 checkpoint(可通過grep -i "checkpoint' fe.log.xxx排查),master 做完 checkpoint 是否 push image 到其他節點成功,是否因 image 過大導致 push image timeout。fe.log里面會有類似日志:
[Checkpoint.doCheckpoint():210] Failed when pushing image file.
(五)doris - meta/image/image.xxx 文件大(幾十 GB)
導入 label 比較多,沒有及時刪除,可以參考前面的參數進行調整
ccr bin log 占的多:舊版本的ccr默認的 disable binlog 不會清空已經記錄的 binlog , 主要還是 ttl_seconds 沒有設置,disable 的時候仍然需要依靠 ttl_seconds 來回收。
解決方法:
舊版本把之前開過 binlog 的表都設置一下 “binlog.enable” = “true”,再設置 “binlog.ttl_seconds” 為一個合理的值。或者直接升級到最新穩定版本
(六)FE 卡住死鎖(jmap dump fe 內存鏡像)
1. 高并發點查把 cpu 打滿后,連帶導致內存高占用:在監控中會呈現 CPU 和內存先后升高的趨勢。
2. 內存本身高占用,故障時間點做 checkpoint 需要近 1 倍內存:在fe.log搜索checkpoint關鍵詞,類似下面的日志:
the memory used percent 73 exceed the checkpoint memory threshold: 70, exceeded count: 1”“2024 - 09 - 06 23:16:14,959 INFO (leader Checkpointer (99) [Checkpoint do Checkpoint () :124] begin to generate new image: image.8745633
3. 大查詢解析過程把 fe 打滿:表現為 CPU 升高。
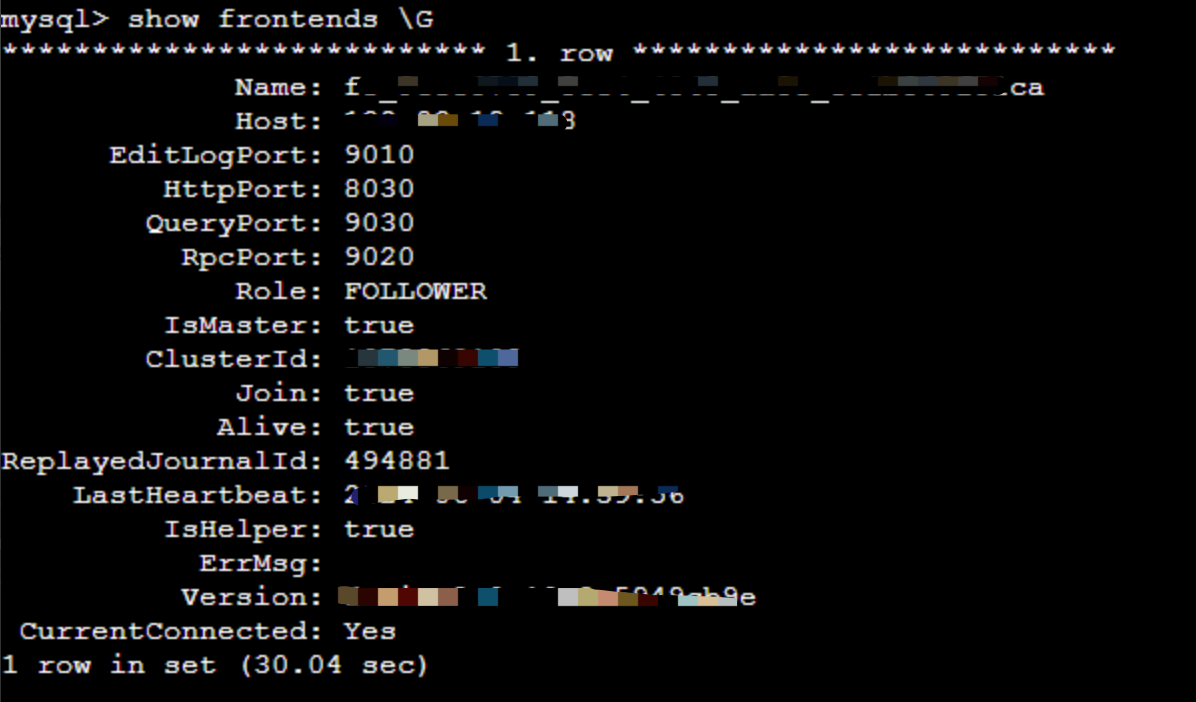
(七)FE show frontends慢
show frontends 返回耗時很長
- 已知的域名解析問題,每個機器hosts文件都加上所有fe節點的域名和ip對應關系就可以了。
- 注意/etc/resolv.conf文件內容,里面是否有云平臺廠商預置了個DNS設置。
在使用 Doris FE 過程中,遇到問題不要怕,關鍵是要掌握正確的定位與解決方法。通過對各類常見問題的深入分析,結合上述詳細的處理指南,相信大家能夠更高效地保障 Doris 系統的穩定運行,充分發揮其在數據處理與分析中的強大效能,如果還有其他相關問題歡迎補充討論。


轉串口(TTL)模塊設計講解)


(含模型、數據、可運行代碼))

:探索C++運算符重載設計精髓)



-第十六天)





)

