關于一致性,你該知道的事兒(下)
- 前言
- 一、并發修改單個對象
- 1.1 原子寫操作
- 1.2 顯示加鎖
- 1.3 原子的TestAndSet
- 1.4 版本號機制
- 二、 多個相關對象的一致性
- 2.1 最大努力實現
- 2.2 2PC && TCCC
- 2.3.基于可靠消息的一致性方案
- 2.4.Saga事務
- 三、 多個副本的雙寫一致性
- 3.1 寫入時更新
- 3.2 讀取時更新
- 四、后記
- 參考
前言
上篇文章講了一些關于較為底層的一致性內容,這篇文章上升一個層次,討論討論應用層面的一些一致性內容。
底層給我們提供了實現數據邏輯一致性的一些保證,但是由于上層應用多種多樣,需求也各不相同,有些系統寧愿吞吐量降低也不允許不一致的情況發生,而有的系統則可以接受一定程度的不一致,但是需要保證一定的高可用和高并發(因此這些系統可能采沒有實現事務功能的數據庫系統)。 因此,要實現整個應用的一致性,上層系統還需要注意很多東西。下面是幾點引起應用不一致的幾個常見場景。
一、并發修改單個對象
和數據庫一樣,并發操作是引起不一致的一個重要場景,但是大多數web服務場景的應用不可避免的要支持并發(一個一個串行執行的請求任務在遇到io阻塞時效率會低到哭的)。

比如說,很多業務場景都會遇到read-modfy-write的邏輯,即先從數據庫中讀取要操作的數據D,然后根據用戶請求對數據進行更新,成為D’, 然后將更新后的值寫入到數據庫中。
很常見的一個例子就是多個人更新同一個文檔, 如果多個請求同時到來,需要進行這種“read-modify-write”的操作,設計不當有可能會造成后者的更新不包括前者修改后的數據,因此導致前者的修改丟失(更新丟失)的情形。
再比如說一種情況,一個群組,每加入一個人,就需要在群資料里的總人數中進行加1操作,如果使用普通的“read-modify-write”操作,并發場景下很有可能會出現更新數目不準確狀況(兩次+1操作被因為沖突變成了一次)。
有一些方式可以應用到上述場景來一定程度上的應對上述問題。
1.1 原子寫操作
很多數據庫提供了原子更新操作,將“read-modify-write”的邏輯下沉到數據庫層面,可以解決某些場景的更新丟失問題。
比如說mongo提供單個document級別的原子操作。如果我們需要更新的數據是在同一個document中,那么使用mongo可以避免更新丟失(注意,這里是針對單個document情況,對于復雜的業務邏輯需要更新多個document,mongo只保證了每個document的原子性,而不保證整個update操作的原子性)。
redis提供的大部分單個命令操作時原子性的, 有些場景可以利用redis的原子操作實現一些防止并發沖突的功能,比如說原子自增,序列號分發等。
1.2 顯示加鎖
有些數據庫(比如說mysql)提供了對返回的結果集加鎖的功能。所以,應用程序可以根據請求對查詢的結果集加鎖,顯示鎖定待更新的對象。當其他的請求嘗試讀取對象的時候,必須等待當前請求的執行隊列完成。
Select * from page
where name = "modify_page"
for update; //for update 指示數據庫對返回的所有數據行進行加鎖
鎖是一把雙刃劍,雖然好用易理解,但是用得不好往往會引起效率的降低,使用宜謹慎。
1.3 原子的TestAndSet
有些數據庫支持原子性的testAndSet操作,即只有當前值沒有被其他人修改時才執行更新寫入操作。
比如說對于兩個用戶同時需要更新一篇文檔,只有當前頁面從上次讀取出后沒有發生變化,才會執行當前的更新操作;
如下:
update page
set content = "new content"
where id = 1234 and content = "old content"
1.4 版本號機制
有這樣一個場景,比如說要提供一個簡單的kv存儲系統給客戶,客戶通過調用接口來操作這些kv值。 但是有一個需求,客戶端需要明確知道調用是否有并發沖突,即"我調用的時候要么成功,要么失敗。但是不允許有人和我一起調用成功"。
這種kv存儲怎么設計呢?直接使用已有的kv組件(如redis)肯定是不行的,因為它無法防止并發沖突,雖然redis可以使用單個線程執行客戶端發來的請求(串行化請求),但是它會"悄咪咪"的把客戶的請求都執行了,當返回結果給客戶端時,客戶端也不知道自己的請求是不是穿插了其他的請求。

有其他的解決方案不?
可以參考版本控制的類似思想來解決這個問題。每個kv數據要保存一個版本號代表當前數據的版本 dataVersion, 每次操作完數據之后,dataVersion自增。同時當客戶端請求的時候,讓其帶一個請求的版本號reqVersion(版本號可以是一個中心的版本分發器,也可以讓app層或者redis返回時response攜帶,但必須是全局唯一的),只有reqVersion 和dataVersion 匹配時(比如說reqVersion=dataVersion+1),操作可以進行,否測返回客戶端并發沖突。
這樣當同時多個客戶端請求時,如果攜帶相同的reqVersion來請求,只有一個可以成功,其他的將返回并發操作失敗。如下圖所示。

(上述請求假設req1先到達服務端)
這種方式從某種程度上和上面的TestAndSet有點像,都是先Test,符合某種條件時才進行Set; 不一樣的一點是把判斷的條件移到了客戶端(讓客戶端請求時攜帶),這樣讓客戶端能感知到并發的處理結果。其實如果不考慮判斷的條件放在何處,TestAndSet和版本號機制本質上都是屬于樂觀鎖的方式,只有在更新時才判斷條件是否滿足,是否有其他的線程更改了條件。
二、 多個相關對象的一致性
當現在很多的互聯網應用開始劃分業務為各個微服務的時候,各個微服務之間的聯系就變得繁多了起來。很多時候,一個上游的請求會導致下游多個服務的調用;一個業務邏輯需要同時(這里的同時指的不是時間上的同時)修改多個對象,這就需要保證這多個數據對象的一致性。
一個很常見的業務場景就是訂單支付,如下圖所示。一個訂單請求涉及到下游多個服務和對應數據對象的修改,。請求之后這些數據對象要保證一致性,不能訂單數據為已支付,但是庫存數據沒修改。

我們要達成多個數據對象一致性(專業點叫做分布式事務),要么一起提交修改,要么都不提交修改的最終效果,這有哪些方式呢?
一般有常見的有幾種方式(我用的還不多,在此簡單介紹):
2.1 最大努力實現
最簡單的一種方式就是重試策略。當要修改的其中某個數據對象不成功的時候(因為網絡超時、或者機器宕機等原因),就重新發起請求,不斷重試,直到重試成功或者達到最大的重試次數。
本質上來說,這種方式不一定能達到多個數據對象的一致性,因此只能算作最大努力實現。但對于一些一致性要求沒那么高的場景,如果上層的應用設計的合理,還是可以使用這種方式的,畢竟執行失敗是少數情況,很多時候retry幾下就可以成功的。
2.2 2PC && TCCC
要么一起提交修改,要么都不提交修改。是不是和我們上面討論的2PC協議有點類似?
沒錯,2PC也是實現這種分布式事務一種經典協議(只不過之前說它是在分布式數據庫層面,現在討論的是在業務應用層面),通過"Parepare”—>“Commit/Rollback"兩個階段來實現多個數據對象的一致性。
上文中有論述,這里就不重復了。 這里介紹一個在2PC在業務層面的一個變種,TCCC。
TCC是 Try-Confirm-Cancel 的簡稱,如其名字中所表述的,它的執行過程分為3個階段:
- Try : 檢測預留留資源, 對應于2PC的Prepare階段
- Confirm: 真正的業務操作提交, 對應2PC的Commit階段
- Cancel: 預留留資源釋放, 對應2PC的Rollback階段
如下圖所示:

從某成程度上說,TCC是2PC在業務層間的套用,可以實現最終的一致性。但是2PC存在的問題,它也存在,而且這種方式對業務的侵入較強,會帶來一定的開發量。
2.3.基于可靠消息的一致性方案
還有一種基于可靠消息的一致性方案,通過消息中間件自身提供的異步+持久化+重試的策略保證(當然也不是完全保證)消息一定會被消息的訂閱方消費。 那么只需要保證業務操作(修改其中的某個數據對象)和消息的發送(傳遞修改其他對象的指令)是事務性的即可。
如下圖所示為基于消息中間件的一致性方案,通過【消息發送方】執行本地事務(修改某個數據對象)和發送消息到服務端(也就是消息中間件服務)的一個類2PC過程來實現某種程度上的原子性。
首先消息發送方會發送一個“半事務消息”,然后再執行本地事務,根據本地事務執行的結果,來給消息服務端再發送一個commit或rollback的確認消息。只有服務端收到commit消息后,才會真正的發送消息給訂閱方。

這種方式使用消息中間件的方式解耦了修改兩個對象數據的過程,對性能的損耗和業務的入侵更小。現在很消息中間件都實現了事務消息的功能,可以很好的幫上層業務實現多個對象的一致性問題。
2.4.Saga事務
還有一種應用于長事務的Saga方案,通過將長事務拆分為多個本地短事務來執行,如果正常結束那就正常完成,如果某個步驟失敗,則根據相反順序一次調用補償操作。(有點類似于數據庫中的undo操作,出有問題了就逆向操作)。
如下圖所示:


從上文介紹的幾種應對多個相關聯對象的一致性方案來看,很多方案或多或少都能看到重試的影子(第2、3哥方案中間過程也依賴于重試),或多或少也都有點加鎖的味道。 一般來說,有鎖就影響并發,影響性能。 在性能、可用性和一致性方面,具體采用哪種方案還是要看具體的業務場景和需求。
三、 多個副本的雙寫一致性
如前所述,除了數據庫系統給我們提供的多副本機制,我們還會遇到不同異構層次涉及的多個副本,具體來說是緩存系統涉及到的多個副本。在應用中常見的就是類似 本地內存-> redis緩存->數據庫系統這種,我們為了提供系統的讀寫性能,把一部分常用的數據緩存到更快訪問的介質之上,對用上層應用來說這個過程也涉及到一致性的相關問題。 雖然一般來說這種方式不會要求多么強的一致性,但是不同的操作順序也會對一致性有不同的影響。
這里簡要討論一下【Redis緩存—>數據庫】這種緩存架構,應用層不同的操作順序帶來的不同結果。
對于【Redis緩存—>數據庫】這種緩存架構方式,讀取方式肯定是先從Redis中讀取,如果Redis不存在,再從數據庫中讀取。
但是寫入更新就有好幾種方式了,按照緩存更新的時機,分為寫入時更新,或者讀取時更新。
這么一說下來,就有如下幾種操作方式了。
3.1 寫入時更新
寫入時更新分為【更新緩存–>更新數據庫】 和 【更新數據庫–>更新緩存】兩種方式。這兩種方式都會有并發沖突帶來的不一致現象。比如說第一種方式吧,A、B兩個進程并發來一套上述的流程。

【更新緩存–>更新數據庫】
最終發生了Redis和數據庫中數據不一致的情況。
第二種方式也是一樣,都會產生這種A1->B1->B2->A2(A1:表示A進程執行第1個操作)的問題。

【更新數據庫–>更新緩存】
?
我們這里沒考慮執行失敗,或者宕機的情況,如果考慮這種情況的話,第一種方式要比第二種方式影響更大些,因為在第一種方式里,如果Redis更新成功了,但是數據庫失敗了,數據就不僅僅是不一致的問題,而是產生了臟數據,緩存畢竟是緩存,我們最終要是要以數據庫中的數據為準。
3.2 讀取時更新
【刪除緩存–>更新數據庫】和【更新數據庫–> 刪除緩存】是兩種讀取時更新的方式,這兩方式先刪除緩存,然后下一次讀取的時候就可以從數據庫中讀取更新的數據。這兩種方式相當于是把寫寫沖突造成的不一致轉移到了讀寫上。比如說下面的并發場景:

【刪除緩存–>更新數據庫】

【更新數據庫–> 刪除緩存】
這兩種方式也會造成最終的緩存Dc和數據庫Db不一致。相比來說,第四種方式要比第三種方式發生不一致的概率更小點,因為更新緩存的速度要遠遠大于更新數據庫,第四種方式中ClientA 把數據庫都更新了,緩存也刪了,ClientB還沒有更新緩存,這種情況不能說沒有,但是概率上要少些。
但是采用刪緩存有一個緩存穿透問題需要考慮:就是刪除了緩存之后要防止突然大量的并發請求到數據庫中。
上述只是簡單討論了一下,實際的現實的情況要更復雜(比如說哪個過程執行失敗了),也更靈活(有些場景不需要太高的一致性),需要具體問題,具體分析。
四、后記
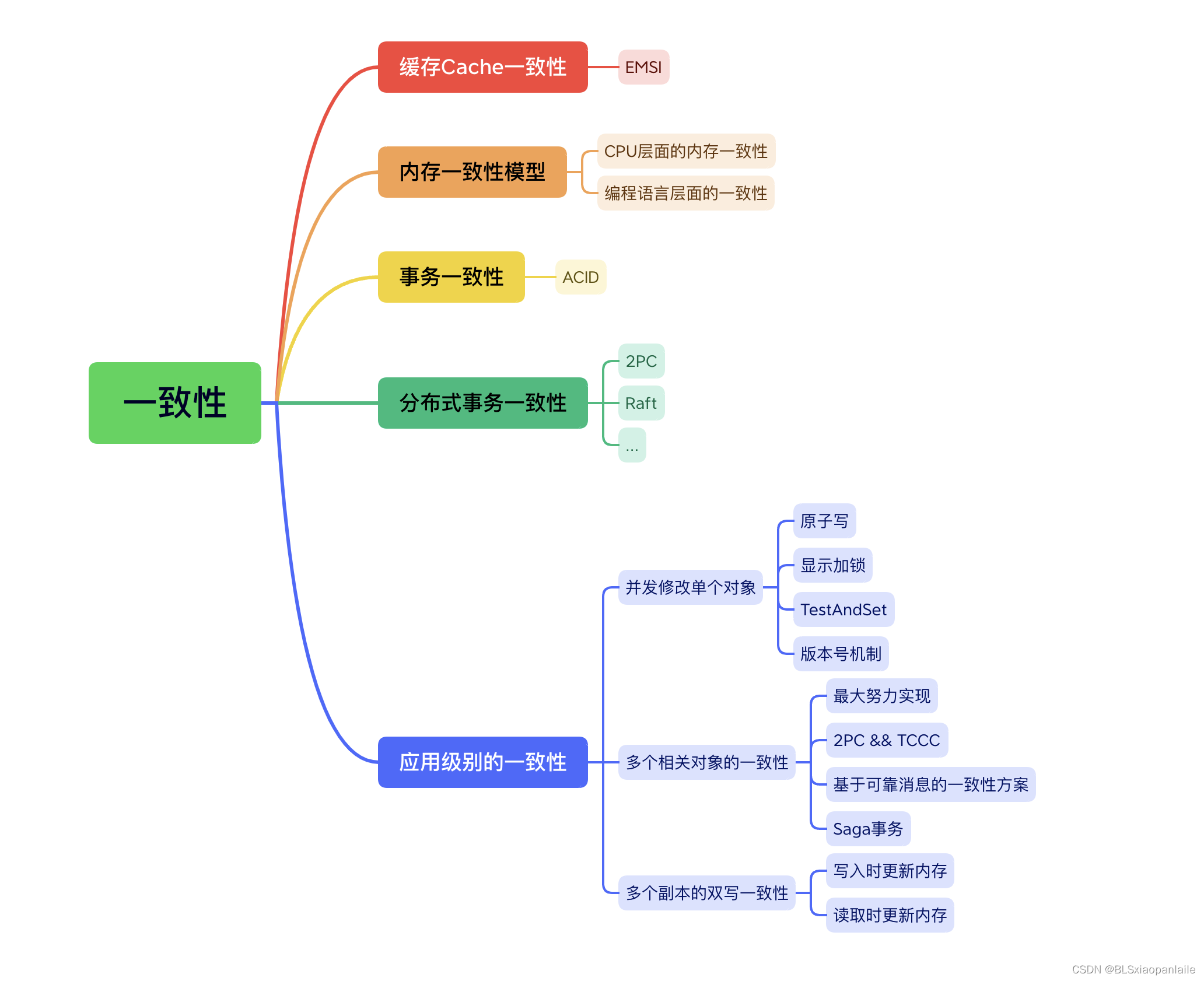
一致性是個大問題,這兩篇文章從單機和分布式的角度,從數據庫和應用層面,大概梳理了一致性的相關內容。內容有點多, 因此很多內容只是簡單過了個囫圇吞棗。這兩篇文章主要是想通過梳理一下一致性的相關內容,來對編程過程中涉及到的一致性有個大概的認識(知道是怎么回事兒,算是屬于哪個分類,該往哪個方向考慮問題),以后遇到一致性問題不至于 賣蝦米不拿秤-抓瞎。
但是如果從更高的層次來看,這兩篇文章的很多內容其實非常相似,抽象的看,研究的可能就是一個東西,只是在實際中被用到了不同的場景,因而有些變化。因此如果能從宏觀上來看這些內容,會對一致性有更深的理解(當然,我現在還沒到這個程度)。
最后總結以一張“一致性全家圖”來結束這兩篇關于一致性的文章。
參考
【1】《DDIA》
【2】 挑戰大型系統的緩存設計——應對一致性問題
【3】 不就是分布式事務,這下徹底清楚了😎
【4】 一致性問題與分布式事務
【5】 TCC分布式事務,最終一致性分布式事務
【6】Seata-go: Simple Extensible Autonomous Transaction Architecture(Go version)
【7】關于一致性,你該知道的事兒(上)






表達式語言(EL)的隱式對象及其作用)
)


如何學習OMXNodeInstance)
)

:區間DP)




)
