前言
筆記的內容主要參考與《Rust 程序設計語言》,一些也參考了《通過例子學 Rust》和《Rust語言圣經》。
Rust學習筆記分為上中下,其它兩個地址在Rust學習筆記(中)和Rust學習筆記(下)。
編譯與運行
Rustup(updater)
它是一個管理 Rust 版本和相關工具的命令行工具。
Rustc(compiler)
Rust 是一種預編譯靜態類型(ahead-of-time compiled)語言,這意味著你可以將編譯程序生成的可執行文件送給其他人,他們甚至不需要安裝 Rust 就可以運行。而像其它動態語言(Ruby、Python 或 JavaScript)則做不到,需要分別安裝對應的環境,這一切都是語言設計上的權衡取舍。
# 編譯成功后,Rust會輸出一個二進制的可執行文件(main)。
$ rustc main.rs
# 運行
$ ./main
Cargo(package manager)
僅僅使用 rustc 編譯簡單程序是沒問題的,不過隨著項目的增長,你可能需要管理你項目的方方面面,并讓代碼易于分享。這需要用到Cargo。Cargo 是 Rust 的構建系統和包管理器。
$ cargo new hello_cargo
$ cd hello_cargo
\hello_cargo
|-- src|-- main.rs
|-- Cargo.toml
對于 cargo new 命令,它會自動添加 Git 進行版本管理,如不想使用,可以添加 -- vcs(version control system)進行改變,例如 cargo new hello_cargo --vcs none
在 Cargo.toml 文件中,使用 TOML(Tom’s Obvious, Minimal Language)格式編寫。第一行,[package],是一個片段(section)標題,表明下面的語句用來配置一個包。隨著我們在這個文件增加更多的信息,還將增加其他片段(section)。在 [package] 中,包含了項目的名稱、版本、作者以及要使用的 Rust 版本。最后一行,[dependencies],是用來羅列項目依賴,在 Rust 中,代碼包被稱為 crates。也可通過命令的方式安裝 cargo add xxx,它會默認從 Crates.io(提供 Rust 的各種依賴)安裝最新版。也可使用 cargo update 來更更新依賴的版本。
[package]
name = "hello_cargo"
version = "0.1.0"
authors = ["Your Name <you@example.com>"]
edition = "2018"[dependencies]
Cargo 生成項目的區別是 Cargo 將代碼放在 src 目錄,同時項目根目錄包含一個 Cargo.toml 配置文件。Cargo 期望源文件存放在 src 目錄中。項目根目錄只存放 README、license 信息、配置文件和其他跟代碼無關的文件。
使用Cargo編譯與運行用到了如下命令:
# 這個命令會創建一個可執行文件target/debug/hello_cargo,可以通過./target/debug/hello_cargo運行
$ cargo build
# 更簡單的運行方式,是使用下面的語句
$ cargo run
# 該命令快速檢查代碼確保其可以編譯,但并不產生可執行文件
$ cargo check
當使用 cargo build 時,會在項目根目錄創建一個新文件:Cargo.lock, 這個文件記錄項目依賴精確版本信息。
通常 cargo check 要比 cargo build 快得多,因為它省略了生成可執行文件的步驟。如果你在編寫代碼時持續的進行檢查,cargo check 會加速開發。
最后,當項目最終準備好發布時,可以使用 cargo build --release 來優化編譯項目。這會在 target/release 而不是 target/debug 下生成可執行文件。這些優化可以讓 Rust 代碼運行的更快,不過啟用這些優化也需要消耗更長的編譯時間。
為什么需要 Cargo.lock
Cargo.lock 可以確保構建是可重現的,在第一次運行 cargo build 時創建,Cargo 會計算出所有符合要求的依賴版本(包含間接依賴文件)寫入該文件。這樣在大型項目中,能夠鎖定整個項目依賴樹的精確版本,這包括所有的直接和間接依賴,因為可能有多個依賴項共享相同的間接依賴,或不同的間接依賴。總之就是避免沖突,保證重現。
基本語法
變量與常量(Variable and constant)
// 直接使用let聲明,類型可以不寫,Rust會自動識別。對于整型這種會取為默認i32,只有明顯大于或小于i32范圍才會換為別的
let word = "abc";
let price: i32 = 199;
// mut:mutable,聲明變量是可變的,否則變量無法更改
let mut checked = true;
// 常量聲明(這里的下劃線可有可無,只是提升可讀性)
const MAX_POINTS: u32 = 100_000;
// 覆蓋原值
let word = "def"
不可變變量與常量的區別
- 常量不能使用
mut。 - 常量必須標明類型。
- 常量可以在任何作用域中聲明,包括全局作用域,變量不可以。
- 常量只能被設置為常量表達式,而不能是函數調用的結果,或任何其他只能在運行時計算出的值(可以 1 + 1 ,不可以 1 + x )。
隱藏(Shadowing)
可以重新使用 let 聲明存在的值,會將其覆蓋。
數據類型(data type)
-
標量(scalar)
- 整型(integer):有符號整數類型以 i(signed)開頭,無符號以 u(unsigned)開頭。默認 i32。以有符號為例,分為了 i8(1字節)、i16(2字節)、i32(4字節)、i64(8字節)、i128(16字節)。1字節 = 8位,根據這個可算出其范圍。還有一個類型為 isize,類型依賴運行程序的計算機架構,64 位架構上它們是 64 位的, 32 位架構上它們是 32 位的。
- 浮點型(floating-point numbers):Rust 的浮點數類型是 f32 和 f64,分別占 32 位和 64 位。默認類型是 f64,因為在現代 CPU 中,它與 f32 速度幾乎一樣,不過精度更高。聲明時要像這樣
let x = 2.0;。 - 布爾型(bool):true 和 false。
- 字符類型(character):為char,像
let c = 'z',大小為四個字節(four bytes),代表了一個 Unicode 標量值(Unicode Scalar Value),這意味著它可以比 ASCII 表示更多內容。
-
復合(compound)
-
元組(tuple):可以將多個其他類型的值組合進一個復合類型方式。元組長度固定,一旦聲明,其長度不會增大或縮小。
// 也可不寫類型 let tup: (i32, f64, u8) = (500, 6.4, 1); // 訪問 // 方式1:使用模式匹配(pattern matching)來解構(destructure)元組值 let (x, y, z) = tup; println!("The value of y is: {}", y); // 方式2:點號加索引 println!("The value of x is: {}", tup.0);對于元組還有另一個用處,接函數值。
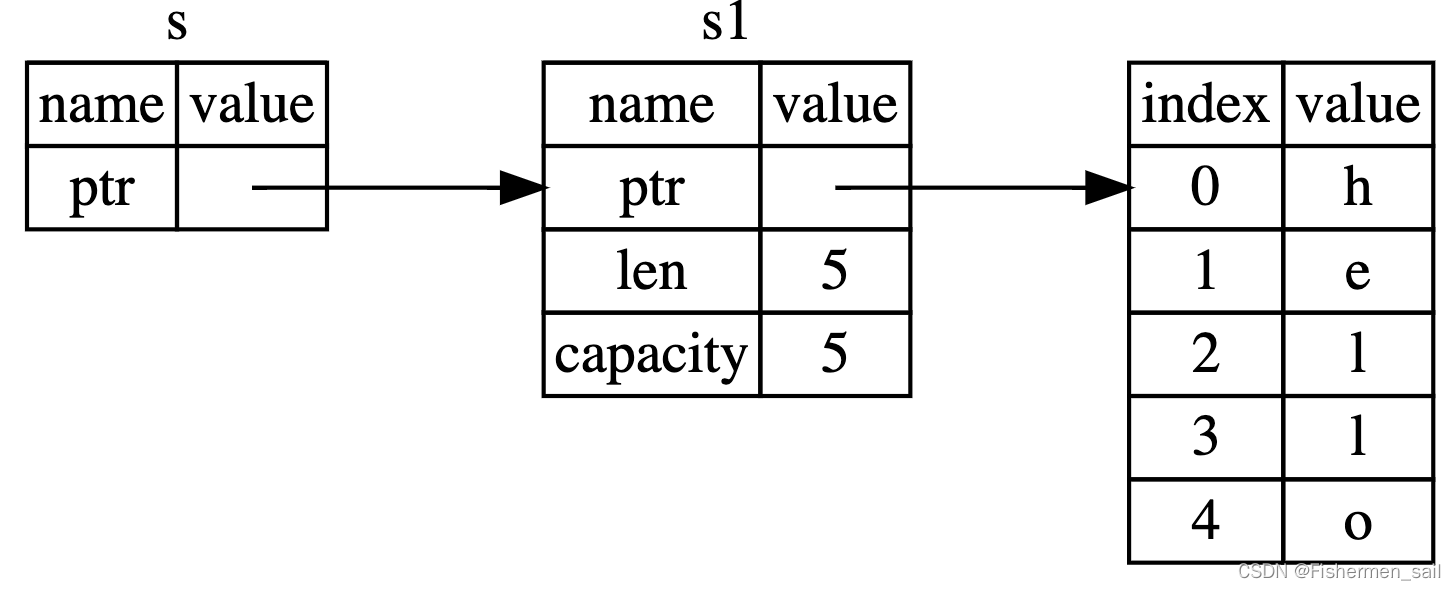
fn main() {let s1 = String::from("hello");let (s2, len) = calculate_length(s1);println!("The length of '{}' is {}.", s2, len); }fn calculate_length(s: String) -> (String, usize) {let length = s.len();(s, length) } -
數組(array):可以包含多個相同類型的值,Rust 中的數組與一些其他語言中的數組不同,因為 Rust 中的數組是固定長度的,一旦聲明,它們的長度不能增長或縮小。數組并不如 vector 類型靈活,vector 類型是標準庫提供的一個允許增長和縮小長度的類似數組的集合類型。
// 聲明 let months = ["January", "February", "March", "April", "May", "June", "July","August", "September", "October", "November", "December"]; // 也可以加上類型,和長度 let a: [i32; 5] = [1, 2, 3, 4, 5]; // 可以創多個重復值的數組(5個3) let a = [3; 5]; // 訪問 let first = a[0];
-
整型溢出(integer overflow)
比方說有一個 u8,它可以存放從零到 255 的值。那么當你將其修改為 256 時會發生什么呢?
當在 debug 模式編譯時,會使程序 panic;在 release 構建中,Rust 不檢測溢出,256 會變成 0,257 變成 1,依此類推。
數值運算
不同類型的整數之間可以隨意加減乘除(小心溢出),但對于浮點數,運算時每個值的類型都必須相同。
無效的數組元素訪問
一般程序語言數組越界訪問可能導致無效內存訪問,這可能會引起程序崩潰或安全漏洞(如緩沖區溢出)。與之相比,Rust 在運行時執行邊界檢查,當嘗試訪問超出數組長度的元素時,程序會 panic 并安全退出。這種行為防止了潛在的無效內存訪問,提高了程序的整體安全性。
函數
基本格式
fn another_function(x: i32,y: i32) -> i32 {...
}
語句(Statements)和表達式(Expressions)
// 語句
let y = 6;
// 會報錯,不能把let語句給x
let x = (let y = 6);
// { let x = 3; x + 1}是一個表達式
let y = {let x = 3;x + 1
};
// 表達式直接返回,不能加分號。如果想加可以用return;
fn plus_one(x: i32) -> i32 {x + 1
}
兩種函數返回值的方式
fn plus_one(x: i32) -> i32 {// 第一種 2//第二種return 2;
}
控制流
判斷
fn main() {let number = 6;if number % 4 == 0 {println!("number is divisible by 4");} else if number % 3 == 0 {println!("number is divisible by 3");} else if number % 2 == 0 {println!("number is divisible by 2");} else {println!("number is not divisible by 4, 3, or 2");}
}
// 不能這樣
let number = 3;
if number {println!("number was three");
}
// let if的用法(和if let不一樣)
let condition = true;
let number = if condition {5
} else {// 上下兩個值類型需相同。Rust需要在編譯時就確切的知道number變量的類型,這樣它就可以在編譯時驗證在每處使用的number變量的類// 型是否有效。Rust并不能夠在number的類型只能在運行時確定的情況下工作,這樣會使編譯器變得更復雜而且只能為代碼提供更少的保// 障,因為它不得不記錄所有變量的多種可能的類型。6
};
循環
// loop
loop {println!("again!");
}
// 這里為什么可以?因為Rust的break不太一樣,break counter * 2像是return counter * 2
let result = loop {counter += 1;if counter == 10 {break counter * 2;}
};
// while
while number != 0 {println!("{}!", number);number = number - 1;
}
// for
let a = [10, 20, 30, 40, 50];
for element in a {println!("the value is: {}", element);
}
for number in (1..=4).rev() { // rev用來反轉rangeprintln!("{}!", number);
}
所有權(ownership)
Rust 的核心功能之一就是所有權。所有運行的程序都必須管理其使用計算機內存的方式,一些語言中具有垃圾回收機制,在程序運行時不斷地尋找不再使用的內存;在另一些語言中,程序員必須親自分配和釋放內存;Rust 則選擇了第三種方式,通過所有權系統管理內存,編譯器在編譯時會根據一系列的規則進行檢查。在運行時,所有權系統的任何功能都不會減慢程序。
棧(Stack)和堆(Heap)
在很多語言中,你并不需要經常考慮到棧與堆。不過在像 Rust 這樣的系統編程語言中,值是位于棧上還是堆上在更大程度上影響了語言的行為以及為何必須做出這樣的抉擇。
棧和堆都是代碼在運行時可供使用的內存,但是它們的結構不同。棧以放入值的順序存儲值并以相反順序取出值,這也被稱作后進先出(last in, first out)。棧中的所有數據都必須占用已知且固定的大小。在編譯時大小未知或大小可能變化的數據,要改為存儲在堆上。堆是缺乏組織的:當向堆放入數據時,你要請求一定大小的空間。操作系統在堆的某處找到一塊足夠大的空位,把它標記為已使用,并返回一個表示該位置地址的指針(pointer)。這個過程稱作在堆上分配內存(allocating on the heap)。將數據推入棧中并不被認為是分配。
入棧比在堆上分配內存要快,因為(入棧時)操作系統無需為存儲新數據去搜索內存空間;其位置總是在棧頂。相比之下,在堆上分配內存則需要更多的工作,這是因為操作系統必須首先找到一塊足夠存放數據的內存空間,并接著做一些記錄為下一次分配做準備。
在訪問時,堆上的數據比訪問棧上的數據慢,因為必須通過指針來訪問。現代處理器在內存中跳轉越少就越快。對于棧,當你的代碼調用一個函數時,傳遞給函數的值(包括可能指向堆上數據的指針)和函數的局部變量被壓入棧中。當函數結束時,這些值被移出棧。
跟蹤哪部分代碼正在使用堆上的哪些數據,最大限度的減少堆上的重復數據的數量,以及清理堆上不再使用的數據確保不會耗盡空間,這些問題正是所有權系統要處理的。一旦理解了所有權,你就不需要經常考慮棧和堆了,不過明白了所有權的存在就是為了管理堆數據,能夠幫助解釋為什么所有權要以這種方式工作。
函數與棧
我剛開始特別糾結,棧不是 LIFO 嗎,那我先存入一個變量,在存入另一個,那我想用第一個怎么用?
這里棧的應用不是我想象的呢么簡單,涉及匯編比較底層,簡單解釋一下,這里存入棧的是各種指令。像對于這種拿變量,都是直接通過什么指令給到對方地址,當函數結束,這些指令也會出棧。
所有權規則
- Rust 中的每一個值都有一個被稱為其所有者(owner)的變量。
- 值有且只有一個所有者。
- 當所有者(變量)離開作用域,這個值將被丟棄。
變量的作用域(scope)
在有垃圾回收(garbage collector*,*GC)的語言中, GC 記錄并清除不再使用的內存,而我們并不需要關心它。沒有 GC 的話,識別出不再使用的內存并調用代碼顯式釋放就是我們的責任了,跟請求內存的時候一樣。從歷史的角度上說正確處理內存回收曾經是一個困難的編程問題。如果忘記回收了會浪費內存。如果過早回收了,將會出現無效變量。如果重復回收,這也是個 bug。我們需要精確的為一個 allocate 配對一個 free。Rust 采取了一個不同的策略:內存在擁有它的變量離開作用域后就被自動釋放。
{ // s 在這里無效, 它尚未聲明let s = "hello"; // 從此處起,s 是有效的// 使用 s
} // 此作用域已結束,s 不再有效
內存與分配(Memory and allocation)
-
變量與數據交互的方式(一):移動(move)
// 正確 let x = 5; let y = x; println!("{}", x) // 錯誤 let s1 = String::from("hello"); let s2 = s1; println!("{}", s1);首先對于像整形這樣的在編譯時已知大小的類型被整個存儲在棧上,所以拷貝其實際的值是快速的意味著沒有理由在創建變量
y后使x無效。Rust 有一個叫做Copytrait 的特殊注解,可以用在類似整型這樣的存儲在棧上的類型上。如果一個類型擁有Copytrait,一個舊的變量在將其賦值給其他變量后仍然可用。
而對于像 String 這樣在堆上的值,Rust 不像別的語言可能有淺拷貝和深拷貝的說法,會直接讓第一個值無效,這個操作被稱為移動(move)。Rust 永遠也不會自動創建數據的 “深拷貝”。因此,任何自動的復制可以被認為對運行時性能影響較小。 -
變量與數據交互的方式(二):克隆(clone)
如果確實需要深度復制 String 中堆上的數據,可以使用clone來操作。let s1 = String::from("hello"); let s2 = s1.clone(); println!("s1 = {}, s2 = {}", s1, s2);
所有權與函數
這里要注意的是像整形這種值,賦給函數后,還能用。
fn main() {let s = String::from("hello"); // s 進入作用域takes_ownership(s); // s 的值移動到函數里 ...// ... 所以到這里不再有效let x = 5; // x 進入作用域makes_copy(x); // x 應該移動函數里,// 但 i32 是 Copy 的,所以在后面可繼續使用 x} // 這里, x 先移出了作用域,然后是 s。但因為 s 的值已被移走,// 所以不會有特殊操作fn takes_ownership(some_string: String) { // some_string 進入作用域println!("{}", some_string);
} // 這里,some_string 移出作用域并調用drop方法,占用的內存被釋放fn makes_copy(some_integer: i32) { // some_integer 進入作用域println!("{}", some_integer);
} // 這里,some_integer移出作用域。不會有特殊操作
對于返回值,也同理。
fn main() {let s1 = gives_ownership(); // gives_ownership 將返回值// 移給 s1let s2 = String::from("hello"); // s2 進入作用域let s3 = takes_and_gives_back(s2); // s2 被移動到// takes_and_gives_back 中, // 它也將返回值移給 s3
} // 這里, s3 移出作用域并被丟棄。s2 也移出作用域,但已被移走,// 所以什么也不會發生。s1 移出作用域并被丟棄fn gives_ownership() -> String { // gives_ownership 將返回值移動給// 調用它的函數let some_string = String::from("hello"); // some_string 進入作用域.some_string // 返回 some_string 并移出給調用的函數
}// takes_and_gives_back 將傳入字符串并返回該值
fn takes_and_gives_back(a_string: String) -> String { // a_string 進入作用域a_string // 返回 a_string 并移出給調用的函數
}
引用與借用(reference and borrow)
如果我們想要函數使用一個值但不獲取所有權該怎么辦呢?可以使用 & 引用( & 引用相反的操作是 解引用(dereferencing),它使用解引用運算符,*)。我們將獲取引用作為函數參數稱為借用(borrowing)。
fn main() {let s1 = String::from("hello");let len = calculate_length(&s1);println!("The length of '{}' is {}.", s1, len);
}fn calculate_length(s: &String) -> usize {s.len()
} // 這里,s 離開了作用域。但因為它并不擁有引用值的所有權,// 所以什么也不會發生
&s1 語法讓我們創建一個指向值 s1 的引用,但是并不擁有它。因為并不擁有這個值,當引用離開作用域時其指向的值也不會被丟棄。
但是這個引用是不可變的,如想要更改原引用的值,可以使用&mut
fn main() {let mut s = String::from("hello");change(&mut s);
}fn change(some_string: &mut String) {some_string.push_str(", world");
}
不過可變引用有一個很大的限制:在特定作用域中的特定數據有且只有一個可變引用。下面的代碼會報錯。這個限制的好處是 Rust 可以在編譯時就避免數據競爭(data race)。它可由這三個行為造成:兩個或更多指針同時訪問同一數據;至少有一個指針被用來寫入數據;沒有同步數據訪問的機制。數據競爭會導致未定義行為,難以在運行時追蹤,并且難以診斷和修復;Rust 避免了這種情況的發生,因為它甚至不會編譯存在數據競爭的代碼!
// 報錯
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2); // 不用r1就沒事// 報錯
let mut s = String::from("hello");
let r1 = &s; // 沒問題
let r2 = &s; // 沒問題
let r3 = &mut s; // 大問題,這里怎么想呢,從語義來說,r1和r2認為s是不變的,結果變了
println!("{}, {}, and {}", r1, r2, r3);// 上面這個如果變成下面這樣是可以運行的,也就是說只要你之后不再用r1和r2就沒問題
let mut s = String::from("hello");
let r1 = &s;
let r2 = &s;
let r3 = &mut s;
println!("{}", r3);
懸垂引用(Dangling References)
在具有指針的語言中,很容易通過釋放內存時保留指向它的指針而錯誤地生成一個懸垂指針(dangling pointer),所謂懸垂指針是其指向的內存可能已經被分配給其它持有者。相比之下,在 Rust 中編譯器確保引用永遠也不會變成懸垂狀態:當你擁有一些數據的引用,編譯器確保數據不會在其引用之前離開作用域。
fn main() {let reference_to_nothing = dangle();
}fn dangle() -> &String { // dangle 返回一個字符串的引用let s = String::from("hello"); // s 是一個新字符串&s // 返回字符串 s 的引用
} // 這里 s 離開作用域并被丟棄。其內存被釋放。// 解決方式,直接返回s
fn no_dangle() -> String {let s = String::from("hello");s
}
Slice 類型
用于提供對集合中一段連續元素的引用,也就是能保證和原集合能夠同步變化。“字符串 slice” 的類型聲明寫作 &str:
let s = String::from("hello world");let hello = &s[0..5];
let world = &s[6..11];// 更好的寫法可能是下面的,因為它使得可以對 String 值和 &str 值使用相同的函數:
fn first_word(s: &String) -> &str {
fn first_word(s: &str) -> &str {
結構體
// 聲明
struct User {// fieldusername: String,email: String,sign_in_count: u64,active: bool,
}// 使用
let user1 = User {email: String::from("someone@example.com"),username: String::from("someusername123"),active: true,sign_in_count: 1,
};// 可變使用
// Rust并不允許只將某個字段標記為可變,要想變,整個實例都得可變
let mut user1 = User {email: String::from("someone@example.com"),username: String::from("someusername123"),active: true,sign_in_count: 1,
};
user1.email = String::from("anotheremail@example.com");// 也可直接返回一個
fn build_user(email: String, username: String) -> User {User {email: email,username: username,active: true,sign_in_count: 1,}
}// 使用沒有命名字段的元組結構體來創建不同的類型
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
注意如果要在 Struct 里用字符串只能 String,不能 &str 。因為結構體擁有它的數據的所有權,如果用 &str ,可以來自于外部 String ,那么外部 String 失效,會導致 struct 失效。
struct User {username: &str,email: &str,sign_in_count: u64,active: bool,
}fn main() {let user1 = User {email: "someone@example.com",username: "someusername123",active: true,sign_in_count: 1,};
}
一個使用結構體的示例程序
// 計算長方形面積一步一步的重構
// 這兩個參數是相關聯的,不過程序本身卻沒有表現出這一點。將長度和寬度組合在一起將更易懂也更易處理。
fn main() {let width1 = 30;let height1 = 50;println!("The area of the rectangle is {} square pixels.",area(width1, height1));
}fn area(width: u32, height: u32) -> u32 {width * height
}// 使用元組重構,不過元組并沒有給出元素的名稱,所以計算變得更費解了,因為不得不使用索引來獲取元組的每一部分:
fn main() {let rect1 = (30, 50);println!("The area of the rectangle is {} square pixels.",area(rect1));
}fn area(dimensions: (u32, u32)) -> u32 {dimensions.0 * dimensions.1
}// 使用結構體,賦予更多意義
struct Rectangle {width: u32,height: u32,
}fn main() {let rect1 = Rectangle { width: 30, height: 50 };println!("The area of the rectangle is {} square pixels.",area(&rect1));
}fn area(rectangle: &Rectangle) -> u32 {rectangle.width * rectangle.height
}// 其他
// 通過派生 trait 增加實用功能
#[derive(Debug)] // 直接是無法打印struct的,必須有Debug這個trait
struct Rectangle {width: u32,height: u32,
}fn main() {let rect1 = Rectangle { width: 30, height: 50 };println!("rect1 is {:?}", rect1);// 另一種風格println!("rect1 is {:#?}", rect1);
}
方法
fn 被稱作函數,而 impl 被稱作方法。與 fn 不同的是,impl 在結構體的上下文中被定義(或者是枚舉或 trait 對象的上下文),通過 impl 塊將方法與特定的結構體(或枚舉)關聯起來,這意味著這些方法是與特定類型緊密相關的操作,而不是一些獨立的、無關的函數,這有助于組織和模塊化代碼,使得代碼更加易于理解和維護。
并且 Rust 雖然不是一種傳統的面向對象語言,但它支持面向對象的一些核心概念,比如封裝、繼承(通過特質)和多態。使用 impl 塊定義方法是實現封裝和多態的一種方式。它允許類型定義它們自己的行為,以及通過特質為不同類型提供通用接口。
#[derive(Debug)]
struct Rectangle {width: u32,height: u32,
}// 這里的名字需要和struct一樣
impl Rectangle {// &self來替代rectangle: &Rectangle,如果想要改變rectangle需要變成&mut self(很少見)fn area(&self) -> u32 {self.width * self.height}
}fn main() {let rect1 = Rectangle { width: 30, height: 50 };println!("The area of the rectangle is {} square pixels.", rect1.area());
}// 關聯函數,正如名字,相關聯的,放在一個impl
// 它們仍是函數而不是方法,因為它們并不作用于一個結構體的實例
// 使用時需要"::",let sq = Rectangle::square(3);
impl Rectangle {fn square(size: u32) -> Rectangle {Rectangle { width: size, height: size }}
}
調用方法中 :: 和 . 的區別
就像上面提到的,和結構體本身沒什么聯系的用 ::,有聯系的用 .。下面是一個其他例子,這里 :: 其實就和 Java 中的 new 一個作用,就是 new 出一個實例。
也有另一種情況,比如在 main 中引入另一個包,沒有結構體,包里面全是函數,你要使用的話也得 ::。
struct Person {name: String,age: u8,
}impl Person {// 關聯函數(靜態方法),用于創建一個新的 Person 實例fn new(name: &str, age: u8) -> Person {Person {name: name.to_string(),age,}}// 實例方法,調用時需要一個 Person 的實例fn say_hello(&self) {println!("Hello, my name is {} and I am {} years old.", self.name, self.age);}
}
fn main() {// 調用關聯函數(靜態方法)來創建一個 Person 實例let person = Person::new("Alice", 30);// 調用實例方法person.say_hello();
}
枚舉
什么時候使用枚舉呢?像下面的場景,任何一個 IP 地址要么是 IPv4 的要么是 IPv6 的,而且不能兩者都是。IP 地址的這個特性使得枚舉數據結構非常適合這個場景,因為枚舉值只可能是其中一個成員。
// 聲明
enum IpAddrKind {V4,V6,
}// 使用
let four = IpAddrKind::V4; // 這樣寫也暗示了V4和V6是屬于IpAddrKind類型的
let six = IpAddrKind::V6;// 對于函數
fn route(ip_type: IpAddrKind) { }
route(IpAddrKind::V4);
枚舉還可以存放數據
// 傳統方式
enum IpAddrKind {V4,V6,
}
struct IpAddr {kind: IpAddrKind,address: String,
}
let home = IpAddr {kind: IpAddrKind::V4,address: String::from("127.0.0.1"),
};
let loopback = IpAddr {kind: IpAddrKind::V6,address: String::from("::1"),
};// 枚舉方式
enum IpAddr {V4(String),V6(String),
}
let home = IpAddr::V4(String::from("127.0.0.1"));
let loopback = IpAddr::V6(String::from("::1"));// 更夸張的,枚舉可以存放任何混合類型
enum Message {Quit,Move { x: i32, y: i32 },Write(String),ChangeColor(i32, i32, i32),
}
枚舉也可以使用 impl。
impl Message {fn call(&self) {// 在這里定義方法體}
}let m = Message::Write(String::from("hello"));
m.call();
Option
Rust 并沒有很多其他語言中有的空值功能,與之類似的是 Option。Option<T> 枚舉是如此有用以至于它甚至被包含在了 prelude 之中,你不需要將其顯式引入作用域。另外,它的成員也是如此,可以不需要 Option:: 前綴來直接使用 Some 和 None。即便如此 Option<T> 也仍是常規的枚舉,Some(T) 和 None 仍是 Option<T> 的成員。
enum Option<T> {Some(T),None,
}
如果使用 None 而不是 Some,需要告訴 Rust Option<T> 是什么類型的,因為編譯器只通過 None 值無法推斷出 Some 成員保存的值的類型。對于 <T> 是一個泛型,任意類型的數據。
// 例子
let some_number = Some(5);
let some_string = Some("a string");
let absent_number: Option<i32> = None;
當有一個 Some 值時,我們就知道存在一個值,而這個值保存在 Some 中。當有個 None 值時,在某種意義上,它跟空值具有相同的意義:并沒有一個有效的值。那么重點來了,Option<T> 為什么就比空值要好呢?
首先看下面的例子,是會報錯的,因為Option<i8> 與 i8 類型不同,無法相加。當在 Rust 中擁有一個像 i8 這樣類型的值時,編譯器確保它總是有一個有效的值,我們可以自信使用而無需做空值檢查;而當使用 Option<i8> 的時候需要擔心可能沒有值,而編譯器會確保我們在使用值之前處理了為空的情況。換句話說,在對 Option<T> 進行 T 的運算之前必須將其轉換為 T。這意味著我們不得不處理可能為空的情況,這樣也就避免了遇到為空的問題。
// 報錯
let x: i8 = 5;
let y: Option<i8> = Some(5);
let sum = x + y;
prelude
默認情況下,Rust 會自動將 prelude 引入,使得一些非常常用的類型和特質可以直接使用。如果需要的類型不在 prelude 中,你必須使用use語句顯式地將其引入作用域。另外常見的 std 為標準庫,prelude 屬于 std。
match
// 常規用法
enum Coin {Penny,Nickel,Dime,Quarter(UsState),
}
fn value_in_cents(coin: Coin) -> u8 {match coin {Coin::Penny => 1,Coin::Nickel => 5,Coin::Dime => 10,Coin::Quarter(state) => {println!("State quarter from {:?}!", state);25},}
}// 匹配Option
fn plus_one(x: Option<i32>) -> Option<i32> {match x {None => None,Some(i) => Some(i + 1),}
}// 不像列舉所有
match some_u8_value {1 => println!("one"),3 => println!("three"),5 => println!("five"),7 => println!("seven"),_ => (),
}
注意匹配必須是窮盡的(exhaustive),也體現出上面提到過Option的意義,必須處理空值的情況
// 報錯
fn plus_one(x: Option<i32>) -> Option<i32> {match x {Some(i) => Some(i + 1),}
}
if let
let some_u8_value = Some(0u8);
// 像這里我們其實只關心為Some(3)的情況,我們可以使用if let
match some_u8_value {Some(3) => println!("three"),_ => (),
}if let Some(3) = some_u8_value {println!("three");
}
然而,這樣會失去 match 強制要求的窮盡性檢查。match 和 if let 之間的選擇依賴特定的環境以及增加簡潔度和失去窮盡性檢查的權衡取舍。
// if let也可以加
let mut count = 0;
if let Coin::Quarter(state) = coin {println!("State quarter from {:?}!", state);
} else {count += 1;
}
這里區分一下之前出現的用法:
if let 1 = 1 {println!("1");
}let a = if true { // 這里必須放bool值1
} else {2
};
項目管理
包(package)和 crate
包是提供一系列功能的一個或者多個 crate。一個包會包含有一個 Cargo.toml 文件,闡述如何去構建這些 crate。
包中所包含的內容由幾條規則來確立。一個包中至多只能包含一個庫 crate(library crate);包中可以包含任意多個二進制 crate(binary crate);包中至少包含一個 crate,無論是庫的還是二進制的。
(library crate:是提供一組特定功能的代碼庫,旨在被其它crate作為依賴項引用。它們不直接編譯成可執行文件,而是被編譯成rlib或dylib文件,供其它項目引用。通常用于定義函數、類型、trait等可以被其他項目重用的代碼。庫crate使得代碼復用、模塊化和分發變得簡單。binary crate:是編譯成單獨的可執行文件的crate,它包含一個或多個main函數作為程序入口點。用于創建最終用戶可以直接運行的應用程序。這些程序可以做任何事情,從命令行工具到服務器和客戶端應用程序。)
當我們輸入 Cargo new,Cargo 會給我們的包創建一個 Cargo.toml 文件。查看 Cargo.toml 的內容,會發現并沒有提到 src/main.rs,因為 Cargo 遵循的一個約定:src/main.rs 就是一個與包同名的二進制 crate 的 crate 根。同樣的,Cargo 知道如果包目錄中包含 src/lib.rs,則包帶有與其同名的庫 crate,且 src/lib.rs 是 crate 根。crate 根文件將由 Cargo 傳遞給 rustc 來實際構建庫或者二進制項目。如果一個包同時含有 src/main.rs 和 src/lib.rs,則它有兩個 crate:一個庫和一個二進制項,且名字都與包相同。
額外說一下,一個crate,將將其功能保持在其自身的作用域中,可以知曉一些特定的功能是在我們的 crate 中定義的還是在 別的crate 中定義的,這可以防止潛在的沖突。
模塊(Module)
模塊讓我們可以將一個 crate 中的代碼進行分組,以提高可讀性與重用性。模塊還可以控制項的私有性。
在 src/lib.rs,下面的內容就是一個包含了其他內置了函數的模塊的 front_of_house 模塊。
mod front_of_house {mod hosting {fn add_to_waitlist() {}fn seat_at_table() {}}mod serving {fn take_order() {}fn server_order() {}fn take_payment() {}}
}
在前面我們提到了,src/main.rs 和 src/lib.rs 叫做 crate 根。之所以這樣叫它們的原因是,這兩個文件的內容都是一個從名為 crate 的模塊作為根的 crate 模塊結構,稱為模塊樹(module tree)。
crate└── front_of_house├── hosting│ ├── add_to_waitlist│ └── seat_at_table└── serving├── take_order├── serve_order└── take_payment
路徑
路徑用于引用模塊樹中的項,分為絕對路徑(absolute path)從 crate 根開始,以 crate 名或者字面值 crate 開頭;相對路徑(relative path)從當前模塊開始,以 self、super 或當前模塊的標識符開頭。路徑的遞進由 :: 完成。如何調用 add_to_waitlist 函數?那就是用它的路徑。
下面文件在 src/lib.rs 中, eat_at_restaurant 函數是我們 crate 庫的一個公共API,所以我們使用 pub 關鍵字來標記它。這個模塊在模塊樹中,與 eat_at_restaurant 定義在同一層級。
mod front_of_house {mod hosting {fn add_to_waitlist() {}}
}pub fn eat_at_restaurant() {// Absolute pathcrate::front_of_house::hosting::add_to_waitlist();// Relative pathfront_of_house::hosting::add_to_waitlist();
}
什么時候用絕對路徑什么時候相對路徑呢?如果我們要將 front_of_house 模塊和 eat_at_restaurant 函數一起移動到一個名為新的 customer_experience 的模塊中,我們需要更新 add_to_waitlist 的絕對路徑,但是相對路徑還是可用的。然而,如果我們要將 eat_at_restaurant 函數單獨移到一個名為新的 dining 的模塊中,還是可以使用原本的絕對路徑來調用 add_to_waitlist,但是相對路徑必須要更新。我們更傾向于使用絕對路徑,因為它更適合移動代碼定義和項調用的相互獨立。
模塊不僅對于你組織代碼很有用。他們還定義了 Rust 的私有性邊界(privacy boundary):這條界線不允許外部代碼了解、調用和依賴被封裝的實現細節。所以,如果你希望創建一個私有函數或結構體,你可以將其放入模塊。
Rust 中默認所有項(函數、方法、結構體、枚舉、模塊和常量)都是私有的。父模塊中的項不能使用子模塊中的私有項,但是子模塊中的項可以使用他們父模塊中的項。這是因為子模塊封裝并隱藏了他們的實現詳情,但是子模塊可以看到他們定義的上下文。
像上面的代碼其實是錯誤的,如果想訪問 hosting 以及 add_to_waitlist 需要為它添加 pub 字段。
mod front_of_house {pub mod hosting {pub fn add_to_waitlist() {}}
}pub fn eat_at_restaurant() {// Absolute pathcrate::front_of_house::hosting::add_to_waitlist();// Relative pathfront_of_house::hosting::add_to_waitlist();
}
還可以使用 super 開頭來構建從父模塊開始的相對路徑。這么做類似于文件系統中以 .. 開頭的語法。下面的例子也可體現出子訪問父不需要 pub。
fn serve_order() {}mod back_of_house {fn fix_incorrect_order() {cook_order();super::serve_order();}fn cook_order() {}
}
還可以使用 pub 來設計公有的結構體和枚舉,不過有一些額外的細節需要注意。如果我們在一個結構體定義的前面使用了 pub ,這個結構體會變成公有的,但是這個結構體的字段仍然是私有的。我們可以根據情況決定每個字段是否公有。
mod back_of_house {pub struct Breakfast {pub toast: String,seasonal_fruit: String,}impl Breakfast {pub fn summer(toast: &str) -> Breakfast {Breakfast {toast: String::from(toast),// eat_at_restaurant無法更改,所以必須在方法中做這步seasonal_fruit: String::from("peaches"),}}}
}pub fn eat_at_restaurant() {let mut meal = back_of_house::Breakfast::summer("Rye");meal.toast = String::from("Wheat");println!("I'd like {} toast please", meal.toast);
}
與之相反,如果我們將枚舉設為公有,則它的所有成員都將變為公有。給枚舉的所有成員挨個添加 pub 是很令人惱火的,因此枚舉成員默認就是公有的。結構體通常使用時,不必將它們的字段公有化,因此結構體遵循常規,內容全部是私有的,除非使用 pub 關鍵字。
mod back_of_house {pub enum Appetizer {Soup,Salad,}
}pub fn eat_at_restaurant() {let order1 = back_of_house::Appetizer::Soup;let order2 = back_of_house::Appetizer::Salad;
}
use
mod front_of_house {pub mod hosting {pub fn add_to_waitlist() {}}
}// 相對路徑也是可以的
use crate::front_of_house::hosting;pub fn eat_at_restaurant() {hosting::add_to_waitlist();hosting::add_to_waitlist();hosting::add_to_waitlist();
}
為什么不用 use crate::front_of_house::hosting::add_to_waitlist; 呢?要想使用 use 將函數的父模塊引入作用域,我們必須在調用函數時指定父模塊,這樣可以清晰地表明函數不是在本地定義的,而且可以避免和本地函數命名重復
另一方面,使用 use 引入結構體、枚舉和其他項時,習慣是指定它們的完整路徑,直接用。沒什么原因,就是習慣用法。但是如果名稱相同還是要引入父模塊。
use std::collections::HashMap;fn main() {let mut map = HashMap::new();map.insert(1, 2);
}use std::fmt;
use std::io;fn function1() -> fmt::Result {
}fn function2() -> io::Result<()> {
}
也可使用 as 關鍵字提供新的名稱
use std::fmt::Result;
use std::io::Result as IoResult;fn function1() -> Result {
}fn function2() -> IoResult<()> {
}
如果想讓外部調用你的代碼的代碼去調用 crate::front_of_house::hosting 可以加個 pub。
pub use crate::front_of_house::hosting;
使用外部包
// 需要安裝
use rand::Rng;
嵌套路徑
use std::cmp::Ordering;
use std::io;
// 化簡
use std::{cmp::Ordering, io};use std::io;
use std::io::Write;
// 化簡
use std::io::{self, Write};
想要引入所有
use std::collections::*;
以上所有的例子都在一個文件中定義多個模塊。如何將模塊分出去呢?
對于src/front_of_house.rs,在src/lib.rs,使用 mod 實現
mod front_of_house;pub use crate::front_of_house::hosting;pub fn eat_at_restaurant() {hosting::add_to_waitlist();hosting::add_to_waitlist();hosting::add_to_waitlist();
}
一個使用相對路徑的例子
src/front_of_house.rs
pub mod hosting;
src/front_of_house/hosting.rs
pub fn add_to_waitlist() {}
集合
Vector
// 聲明,需要類型
let v: Vec<i32> = Vec::new();// 直接利用vec宏來創建
let v = vec![1, 2, 3];// 更新,需要用mut聲明
let mut v = Vec::new();
v.push(5);
對于獲取其元素,有兩種方式。對于第一種方式,當使用一個不存在的元素時 Rust 會造成 panic,這個方法更適合當程序認為嘗試訪問超過 vector 結尾的元素是一個嚴重錯誤的情況,這時應該使程序崩潰。對于第二個方式,當 get 方法被傳遞了一個數組外的索引時,它不會 panic 而是返回 None。當偶爾出現超過 vector 范圍的訪問屬于正常情況的時候可以考慮使用它,接著代碼可以有處理 Some 或 None 的邏輯。
let v = vec![1, 2, 3, 4, 5];let does_not_exist = &v[100];match v.get(2) {Some(third) => println!("The third element is {}", third),None => println!("There is no third element."),
}
可能會遇到的錯誤。
// 同時存在可變和不可變
let mut v = vec![1, 2, 3, 4, 5];
let first = &v[0];
v.push(6);
println!("The first element is: {}", first);
為什么要用引用訪問,下面的代碼會報錯,可以發現,不能僅僅把一個值的所有權轉移,要轉一起轉。而對于整數這種,i32 實現了 Copy trait,所以取出來的是復制的值,所以不會有影響。所以還是加引用吧,因為你不需要拿到所有權。
fn main() {let a = String::from("hello");let v = vec![a];{// 報錯let a = v[0];// 可以這么寫,不會報錯// let a = v;println!("{}", a);}println!("{}", v[0]);
}// 不會報錯
fn main() {let v = vec![1, 2, 3];{let a = v[0];println!("{}", a);}println!("{}", v[0]);
}
遍歷:
let v = vec![100, 32, 57];
for i in &v {println!("{}", i);
}// 更改值
let mut v = vec![100, 32, 57];
for i in &mut v {// 引用的原值是無法改變的,需要解引用*i += 50;
}
如何在 Vector 中存儲多種不同類型的值,可以利用 enum
enum SpreadsheetCell {Int(i32),Float(f64),Text(String),
}let row = vec![SpreadsheetCell::Int(3),SpreadsheetCell::Text(String::from("blue")),SpreadsheetCell::Float(10.12),
];
字符串
新建字符串
// 第一種方式
let mut s = String::new();
let data = "initial contents";
let s = data.to_string();
// 或者
let s = "initial contents".to_string();// 第二種方式
let s = String::from("initial contents");
更新字符串
let mut s = String::from("foo");
s.push_str("bar");// s2還是能用的,因為push_str方法采用字符串slice,因為我們并不需要獲取參數的所有權。
let mut s1 = String::from("foo");
let s2 = "bar";
s1.push_str(s2);
println!("s2 is {}", s2);// 單獨字符
let mut s = String::from("lo");
s.push('l');// 拼接
let s1 = String::from("Hello, ");
let s2 = String::from("world!");
// +必須這么用,第一個不加引用,后面的加
let s3 = s1 + &s2; // 注意 s1 被移動了,不能繼續使用
這里會出現個問題,下面的代碼為什么 s 不會隨著 s2 改變。這是因為 + 實際調用了 fn add(self, s: &str) -> String { 函數,里面會將s的值復制,而不是用它的引用。這里還有個問題,為什么 &String能傳進 add 中,是因為 &String 可以被 強轉(coerced)成 &str,Rust 使用了一個被稱為解引用強制多態(deref coercion)的技術,你可以將其理解為它把 &s2 變成了 &s2[..]。
let s1 = String::from("tic");
let mut s2 = String::from("toe");
let s = s1 + &s2;
s2 = "678".to_string();
println!("{}", s);
索引字符串
// String不支持字符串索引
let s1 = String::from("hello");
let h = s1[0];
為啥不行,Rust 提供了多種不同的方式來解釋計算機儲存的原始字符串數據,這樣程序就可以選擇它需要的表現方式,而無所謂是何種人類語言,包括字節、標量值(不一定是字符,有的語音比較特別,會加語調)、字形簇(類似字符)。而且索引操作預期總是需要常數時間 (O(1))。但是對于 String 不可能保證這樣的性能,因為 Rust 必須從開頭到索引位置遍歷來確定有多少有效的字符。
字符串 slice
不好用
let hello = "Здравствуйте";
let s = &hello[0..4];
// 實際輸出為Зд
// 如果&hello[0..1],會報錯
遍歷
for c in "??????".chars() {println!("{}", c);
}
//? ? ? ? ? ?for b in "??????".bytes() {println!("{}", b);
}
// 224 164 165 135// 從字符串中獲取字形簇是很復雜的,所以標準庫并沒有提供這個功能。crates.io 上有些提供這樣功能的 crate
哈希map
新建
use std::collections::HashMap;let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);// 另一個不常用的方法
let teams = vec![String::from("Blue"), String::from("Yellow")];
let initial_scores = vec![10, 50];
let scores: HashMap<_, _> = teams.iter().zip(initial_scores.iter()).collect();
所有權
let field_name = String::from("Favorite color");
let field_value = String::from("Blue");let mut map = HashMap::new();
// 插入后會剝奪所有權
map.insert(field_name, field_value);
訪問
let mut scores = HashMap::new();scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);let team_name = String::from("Blue");
let score = scores.get(&team_name);
// 直接遍歷
for (key, value) in &scores {println!("{}: {}", key, value);
}
修改值
// 直接覆蓋
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Blue"), 25);// 只在鍵沒有對應值時插入
scores.insert(String::from("Blue"), 10);
scores.entry(String::from("Blue")).or_insert(50);//
let text = "hello world wonderful world";
let mut map = HashMap::new();
for word in text.split_whitespace() {// or_insert會返回一個可變引用// 你如果想用or_insert,就得用entry,它用于查找是否存在一個鍵let count = map.entry(word).or_insert(0);// 引用不能加減,要解引用*count += 1;
}


 - 用 C 語言自定義命令)





指南)

)








