摘要:利用強化學習(RL)對語言模型(LMs)進行后訓練,無需監督微調即可增強其復雜推理能力,DeepSeek-R1-Zero便證明了這一點。然而,要有效利用強化學習訓練語言模型,需要進行大規模并行化以擴大推理規模,但這會帶來不容忽視的技術挑戰(如延遲、內存和可靠性問題),同時還會導致財務成本不斷攀升。我們提出了群體采樣策略優化算法(Swarm sAmpling Policy Optimization,SAPO),這是一種完全去中心化且異步的強化學習后訓練算法。SAPO專為異構計算節點組成的去中心化網絡而設計,在該網絡中,每個節點管理自己的策略模型,同時與網絡中的其他節點“共享”采樣軌跡(rollouts);該算法無需對延遲、模型同質性或硬件做出明確假設,且如果需要,節點可以獨立運行。因此,該算法避免了強化學習后訓練規模化過程中常見的瓶頸問題,同時還開辟了(甚至鼓勵探索)新的可能性。通過采樣網絡中“共享”的軌跡,該算法能夠促進“頓悟時刻”的傳播,從而引導學習過程。在本文中,我們展示了在可控實驗中,SAPO實現了高達94%的累積獎勵增益。此外,我們還分享了在一次開源演示中的測試見解,此次測試在一個由Gensyn社區成員貢獻的數千個節點組成的網絡上進行,社區成員在各種硬件和模型上運行了該算法。Huggingface鏈接:Paper page,論文鏈接:2509.08721
研究背景和目的
研究背景:
隨著人工智能技術的快速發展,語言模型(LMs)在自然語言處理任務中展現出強大的能力。然而,如何進一步提升語言模型的復雜推理能力,使其能夠更好地處理需要深度思考和邏輯推斷的任務,成為當前AI研究的重要方向。傳統的監督微調方法雖然有效,但往往依賴于大量標注數據,且在處理新穎或復雜任務時表現受限。強化學習(RL)作為一種通過試錯來優化模型的方法,為語言模型的后訓練提供了新的途徑。通過引入獎勵機制,RL允許模型在探索和利用過程中不斷優化其行為,從而提升復雜推理能力。
然而,將RL應用于語言模型后訓練面臨諸多挑戰。首先,傳統的分布式RL方法需要大規模的GPU集群,并且需要保持策略權重的同步,這導致了高昂的財務成本和通信瓶頸。其次,隨著模型規模的增大,訓練過程中的延遲、內存和可靠性問題變得尤為突出。為了解決這些問題,研究人員開始探索更加高效和可擴展的RL后訓練算法。
研究目的:
本研究旨在提出一種全新的、完全去中心化和異步的RL后訓練算法——Swarm Sampling Policy Optimization(SAPO),以解決傳統分布式RL方法在語言模型后訓練中的瓶頸問題。具體目標包括:
- 提高訓練效率:通過去中心化和異步的訓練方式,減少通信開銷和同步等待時間,從而提高整體訓練效率。
- 增強模型推理能力:利用集體經驗共享機制,使模型能夠從其他節點的經驗中學習,從而提升復雜推理能力。
- 降低訓練成本:避免對大規模GPU集群的依賴,降低硬件和運營成本,使RL后訓練更加經濟可行。
- 提升模型泛化能力:通過多樣化的經驗共享,增強模型對不同任務和環境的適應能力,提高泛化性能。
研究方法
1. 去中心化網絡構建:
SAPO算法構建在一個去中心化的網絡中,該網絡由多個異構的計算節點組成,每個節點都管理自己的策略模型。節點之間通過共享解碼后的策略輸出(即rollouts)來進行經驗交流,而不需要保持模型架構、學習算法或硬件的一致性。這種設計使得SAPO算法能夠靈活地應用于各種異構環境,包括邊緣設備和消費者級硬件。
2. 集體經驗共享機制:
在SAPO算法中,每個節點在生成自己的rollouts后,會將其與網絡中的其他節點共享。接收節點可以根據需要選擇性地采樣這些共享的rollouts,并將其與自己的本地rollouts結合,構建訓練集。這種集體經驗共享機制使得節點能夠從其他節點的探索中受益,從而加速學習過程。
3. 策略更新算法:
節點使用本地獎勵模型計算訓練集上的獎勵,并采用策略梯度算法(如PPO或GRPO)來更新自己的策略。這種設計允許每個節點根據自己的需求和資源情況獨立地進行策略更新,而不需要與其他節點保持同步。
4. 實驗設置:
為了驗證SAPO算法的有效性,研究團隊使用了八個Qwen2.5模型(每個模型有0.5B參數)構建了一個去中心化網絡,并在ReasoningGYM數據集上進行了實驗。ReasoningGYM數據集包含代數、邏輯和圖推理等多個領域的任務,能夠提供多樣化的訓練和評估任務。實驗過程中,節點通過Docker容器進行部署和管理,使用PyTorch的分布式包實現多GPU并行計算。
研究結果
1. 累計獎勵提升:
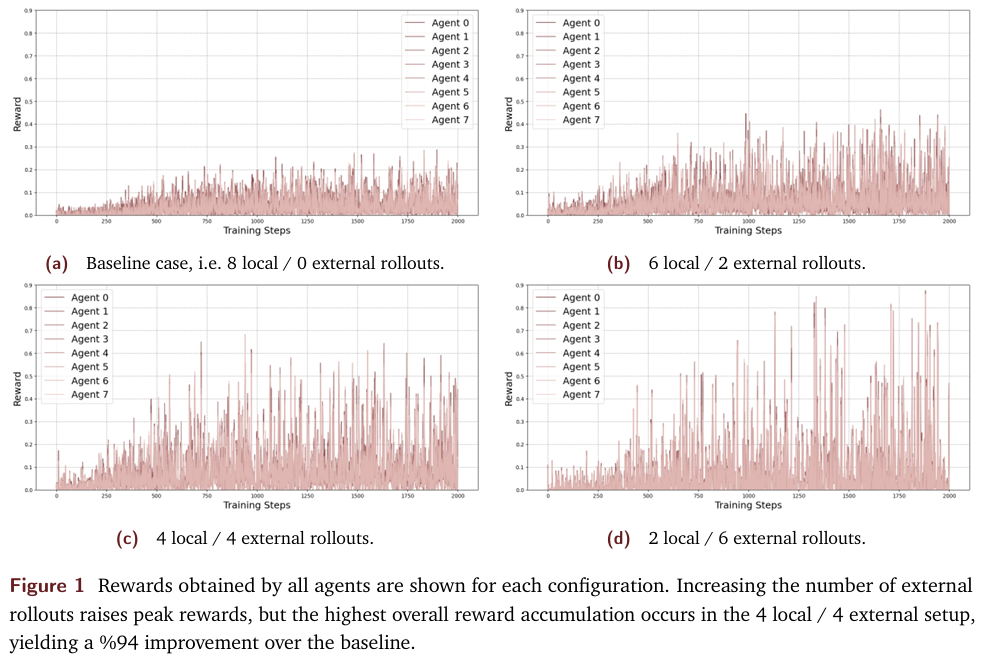
實驗結果表明,SAPO算法顯著提升了模型的累計獎勵。在4本地/4外部rollouts的配置下,SAPO算法相比無共享的基線方法實現了高達94%的累計獎勵提升。這一結果證明了集體經驗共享機制在提升模型性能方面的有效性。
2. 不同配置下的性能比較:
研究團隊還比較了不同配置下的模型性能。實驗結果顯示,隨著外部rollouts數量的增加,模型的峰值獎勵逐漸提高。然而,過度依賴外部rollouts會導致學習過程中的震蕩和遺忘行為,從而影響整體性能。在4本地/4外部的配置下,模型實現了最佳的整體性能。
3. 大規模開放源碼演示中的驗證:
為了進一步驗證SAPO算法在真實異構環境中的有效性,研究團隊組織了一個大規模開放源碼演示活動,吸引了數千名Gensyn社區成員參與。演示結果顯示,對于中等容量的模型(如0.5B參數的Qwen2.5模型),參與集體訓練的模型性能顯著優于孤立訓練的模型。而對于更高容量的模型(如0.6B參數的Qwen3模型),參與集體訓練帶來的性能提升則相對有限。這表明SAPO算法的優勢在中等容量模型中更為突出。
研究局限
盡管SAPO算法在提升語言模型復雜推理能力方面展現出了顯著優勢,但本研究仍存在一些局限性:
1. 外部rollouts采樣策略的局限性:
在當前研究中,節點采用簡單的均勻隨機采樣策略來選擇外部rollouts。這種策略可能導致無用的或低質量的rollouts被過度表示,從而影響訓練效果。未來需要探索更加智能的采樣策略,以過濾掉無用的rollouts并保留有價值的經驗。
2. 對高容量模型的適應性有限:
實驗結果顯示,SAPO算法對高容量模型(如0.6B參數以上的模型)的性能提升相對有限。這可能是因為高容量模型本身已經具備了較強的推理能力,難以通過簡單的經驗共享機制實現顯著的性能提升。未來需要探索更加適合高容量模型的集體訓練方法。
3. 穩定性和魯棒性有待提升:
在某些配置下(如2本地/6外部),模型表現出較強的學習震蕩和遺忘行為。這表明SAPO算法在穩定性和魯棒性方面仍有待提升。未來需要探索更加穩定的訓練策略和魯棒性增強技術,以提高算法的整體性能。
未來研究方向
針對SAPO算法的局限性和潛在改進空間,未來研究可以從以下幾個方面展開:
1. 探索更加智能的外部rollouts采樣策略:
未來可以探索基于模型置信度、獎勵預測或注意力機制的智能采樣策略,以過濾掉無用的rollouts并保留有價值的經驗。這將有助于提高訓練效率并減少無效計算。
2. 研究高容量模型的集體訓練方法:
針對高容量模型,未來可以研究更加復雜的集體訓練方法,如分層訓練、模型蒸餾或知識融合等。這些方法可能有助于充分利用高容量模型的潛力,并通過集體訓練實現性能的進一步提升。
3. 增強算法的穩定性和魯棒性:
為了提高SAPO算法的穩定性和魯棒性,未來可以研究基于獎勵引導的經驗共享機制、RLHF(從人類反饋中強化學習)或生成式驗證器等混合方法。這些方法可能有助于減少學習過程中的震蕩和遺忘行為,并提高算法的整體性能。
4. 探索多模態應用:
盡管本研究主要關注語言模型,但SAPO算法本身是模態無關的。未來可以探索SAPO算法在多模態學習中的應用,如文本到圖像生成、視頻理解或跨模態檢索等。這將有助于拓展SAPO算法的應用范圍,并推動多模態學習領域的發展。
5. 研究非常規策略的集成:
未來還可以探索將非常規策略(如人類)集成到SAPO算法中的可能性。通過設計適當的激勵機制,可以鼓勵非傳統策略(如人類用戶)參與到集體訓練中,并提供有價值的經驗。這將有助于豐富訓練數據的多樣性,并提高模型的泛化能力。





)
控制相機旋轉,限制角度)
歸并排序)

:項目探索)
)

)


重點與易錯點全面總結)



