目錄:
- 1. synchronized 和 ReentrantLock 的區別及應用場景
- 2. HashMap 與 LinkedHashMap 的區別
- 3. ConcurrentHashMap 的數據結構及 JDK1.7 與 JDK1.8 區別
- 4. Spring 常用的模式及應用場景
- 5. 事務的四大特性(ACID)
- 6. 鎖機制:行級鎖與游標鎖
- 7. 索引的種類與使用場景
- 8. 慢 SQL 優化
- 9. Git 常用命令與解決沖突
- 10. 如何保證線程安全
- 11. MySQL 存儲引擎
- 12. Redis 如何使用及應用場景
- 13. Redis 緩存穿透、擊穿、雪崩有什么區別?如何解決?
- 14. 你能介紹一下你日常開發一個需求的全流程嗎
- 15.你能簡單介紹一下你常用的 Spring Cloud 微服務組件嗎?
- 16. 反問問題
1. synchronized 和 ReentrantLock 的區別及應用場景
(1) 實現機制
- synchronized:Java 內置關鍵字,依賴 JVM 監視器鎖(Monitor),隱式加鎖/解鎖,不可中斷。
- ReentrantLock:顯式鎖(需手動調用 lock()/unlock()),支持嘗試鎖(tryLock)、超時、公平鎖(構造函數指定)、條件變量(Condition)。
(2) 靈活性
- synchronized 簡單但功能有限;ReentrantLock 更靈活,支持復雜場景(如定時鎖、中斷響應)。
性能 - JDK 1.6+ 后 synchronized 性能優化(偏向鎖、輕量級鎖),高競爭下 ReentrantLock 可能更優。
(3)應用場景:
- synchronized:簡單同步需求(如單例模式、小臨界區)。
- ReentrantLock:需要公平鎖、超時控制或復雜條件變量的場景(如線程池任務調度、高并發資源競爭)。
2. HashMap 與 LinkedHashMap 的區別
(1) 數據結構
- HashMap:基于哈希表實現,無序。
- LinkedHashMap:繼承自 HashMap,通過雙向鏈表維護插入順序或訪問順序(LRU 緩存)。
(2)應用場景
- HashMap:常規鍵值對存儲,無需順序控制。
- LinkedHashMap:需遍歷順序與插入/訪問順序一致(如緩存、歷史記錄)。
3. ConcurrentHashMap 的數據結構及 JDK1.7 與 JDK1.8 區別
JDK 1.7
- 分段鎖(Segment):將數據分為多個 Segment,每個 Segment 獨立加鎖,提升并發度(默認 16 個 Segment)。
- 數據結構:數組 + 鏈表。
JDK 1.8
- CAS + synchronized:使用 CAS(無鎖操作)和 synchronized(鎖單個鏈表頭節點),減少鎖粒度。
- 紅黑樹優化:鏈表長度超過閾值(默認 8)時轉為紅黑樹,查詢時間從 O(n) 降為 O(log n)。
核心改進:減少內存開銷,提升高并發性能。
4. Spring 常用的模式及應用場景

Spring 各模塊中設計模式的體現
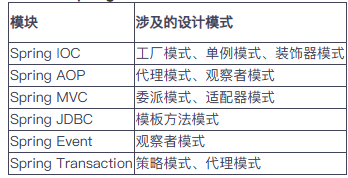
我在項目中使用過 Spring 的代理模式(AOP)實現日志記錄和權限控制,使用模板方法模式封裝通用數據庫操作,使用觀察者模式實現業務事件通知。這些設計模式提升了代碼的可維護性和擴展性。
5. 事務的四大特性(ACID)
- 原子性(Atomicity):事務內操作要么全成功,要么全失敗回滾。
- 一致性(Consistency):事務執行前后,數據庫完整性約束不變(如外鍵約束)。
- 隔離性(Isolation):多個事務并發執行時,相互隔離(隔離級別:讀未提交、讀已提交、可重復讀、串行化)。
- 持久性(Durability):事務提交后,修改永久保存到數據庫。
6. 鎖機制:行級鎖與游標鎖
- 行級鎖
鎖定特定行(如 MySQL InnoDB 的 SELECT … FOR UPDATE),減少鎖沖突,提升并發。 - 游標鎖(悲觀鎖)
在讀取數據時鎖定整個結果集(如 SQL Server 的 HOLDLOCK),防止其他事務修改,適用于高寫入沖突場景。
7. 索引的種類與使用場景
1. 種類
- B+ 樹索引:默認索引類型,適用于范圍查詢(如 WHERE id > 100)。
- 哈希索引:僅支持等值查詢(如 Redis、Memory 引擎)。
- 全文索引:文本模糊匹配(如 MATCH() AGAINST())。
- 組合索引:多列聯合索引(遵循最左前綴原則)。
2. 使用場景
- 主鍵索引:唯一標識記錄。
- 唯一索引:防止重復值(如用戶名)。
- 組合索引:優化多條件查詢(如 WHERE name=‘A’ AND age=20)。
8. 慢 SQL 優化
- 分析工具:EXPLAIN 查看執行計劃,定位全表掃描或臨時表。
EXPLAIN SELECT * FROM your_table WHERE your_condition;
-
判斷哪些索引是無效的?
(1)使用 EXPLAIN 分析執行計劃
EXPLAIN SELECT * FROM orders WHERE customer_id = 123;
查看 EXPLAIN 的輸出,重點關注以下字段:

(2) 看索引是否被使用(可通過慢查詢日志 + EXPLAIN 分析)
啟用慢查詢日志,找出執行時間長的 SQL。
對這些 SQL 執行 EXPLAIN,看是否使用了索引。
如果未使用索引,可能是索引失效或設計不合理。
(3)常見導致索引失效的 SQL 寫法
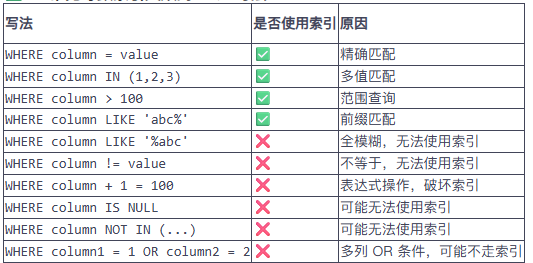
-
判斷哪些索引是有效的?
(1) 看 EXPLAIN 的 type 類型
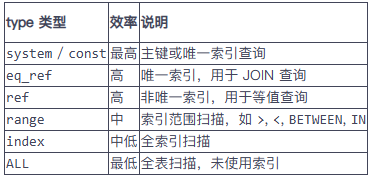
(2) 看 rows 字段
rows 表示 MySQL 估計需要掃描的行數。
越小越好。
如果 rows 很大,說明索引可能不夠高效。
(3) 看 Extra 字段
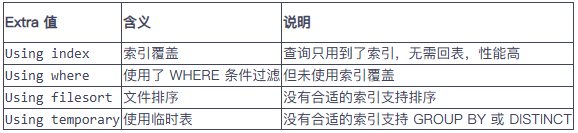
-
優化策略**
(1) 添加索引(避免在低選擇性字段建索引)。
(2) 避免 SELECT *,只查詢必要字段。
(3) 分頁優化:大分頁改用游標分頁(如 WHERE id > 1000 LIMIT 10)。
(4) 拆分復雜 SQL(減少子查詢嵌套)。
(5) 定期分析表(ANALYZE TABLE 更新統計信息)。
9. Git 常用命令與解決沖突
常用命令
- git clone:克隆倉庫。
- git add:添加修改到暫存區。
- git commit:提交本地倉庫。
- git push/pull:推送/拉取遠程分支。
- git branch:查看分支。
- git merge:合并分支。
- git rebase:變基(避免合并提交)。
解決沖突 - git pull 或 merge 時標記沖突文件。
- 手動編輯文件,刪除沖突標記(<<<<<<<, =======, >>>>>>>)。
- git add <文件> 標記沖突已解決。
- git commit 提交最終版本。
10. 如何保證線程安全
- 同步機制,使用 synchronized 或 ReentrantLock 控制臨界區訪問。
- 原子類:AtomicInteger、AtomicReference(CAS 操作)。
- 線程本地變量:ThreadLocal 存儲線程私有數據(如用戶會話)。
- 并發工具類:ConcurrentHashMap、CopyOnWriteArrayList。
- volatile:保證變量可見性(適用于狀態標志)。
11. MySQL 存儲引擎
- InnoDB
支持事務、行級鎖、崩潰恢復(默認引擎)。 - MyISAM
高速存儲,不支持事務和行鎖,適合只讀或插入密集場景。 - Memory
數據存儲在內存中,速度快,適合臨時表。 - Archive
高壓縮比,適合歸檔日志數據。
應用場景
- InnoDB:高并發寫入(如訂單系統)。
- MyISAM:只讀數據(如靜態資源表)。
- Memory:臨時緩存(如會話統計)。
12. Redis 如何使用及應用場景
Redis 是一個高性能的內存數據庫,支持多種數據結構,常用于緩存、分布式鎖、計數器、排行榜等場景。在實際項目中,我主要用 Redis 做緩存和計數器。比如在電商系統中,將商品詳情緩存到 Redis,設置 5 分鐘過期時間;在社交系統中,使用 Redis 統計用戶的點贊和評論數,避免頻繁寫數據庫。
典型使用場景包括:
- 緩存:將熱點數據緩存到 Redis,減少數據庫壓力,提升訪問速度。
- 分布式鎖:使用 SETNX 或 Redlock 實現跨服務的資源互斥訪問。
- 計數器:使用 INCR 實現點贊、瀏覽量、訂單號生成等。
- 排行榜:使用 ZSet 實現游戲積分榜、熱門文章等。
- 消息隊列:使用 List 或 Pub/Sub 實現任務隊列或事件通知。
- 限流:使用 INCR + EXPIRE 實現滑動窗口限流,保護后端服務。
- 用戶簽到:使用 Bitmap 實現簽到統計,節省空間。
13. Redis 緩存穿透、擊穿、雪崩有什么區別?如何解決?
- 緩存穿透:查詢一個既不在緩存也不在數據庫中的數據(如非法 ID),導致每次請求都打到數據庫。
- 解決:布隆過濾器(Bloom Filter)攔截非法請求;緩存空值并設置短過期時間。
- 緩存擊穿:某個熱點 key 突然失效,大量并發請求直接打到數據庫。
- 解決:設置熱點 key 永不過期;使用互斥鎖(Mutex)或分布式鎖控制重建緩存的并發。
- 緩存雪崩:大量 key 同時過期或 Redis 宕機,導致數據庫壓力激增。
- 解決:設置過期時間加隨機值;使用高可用 Redis 集群;緩存降級、限流熔斷。
14. 你能介紹一下你日常開發一個需求的全流程嗎
日常開發一個需求的全流程,我理解為:從需求評審 → 技術設計 → 開發實現 → 代碼審查 → 測試驗證 → 上線部署 → 上線后維護。我會在每個階段都保持清晰的文檔和溝通,確保需求高質量落地。
15.你能簡單介紹一下你常用的 Spring Cloud 微服務組件嗎?
我常用的 Spring Cloud 微服務組件包括 Eureka/Nacos(服務注冊)、Feign(服務調用)、Ribbon(負載均衡)、Hystrix/Sentinel(熔斷限流)、Gateway(網關)、Config(配置中心)、Sleuth/Zipkin(鏈路追蹤),它們分別承擔了服務注冊、通信、容錯、統一入口、配置管理、鏈路監控等職責。
(補充知識)
- 1. Eureka / Nacos(服務注冊與發現)
- 功能:服務注冊中心,用于微服務之間的服務發現。
- 說明:服務啟動后會自動注冊到 Eureka 或 Nacos,其他服務可以通過服務名發現并調用目標服務。
區別:Nacos 還支持配置中心功能,適合需要動態配置管理的場景。
- 2. Ribbon(客戶端負載均衡)
- 功能:在服務調用時,自動選擇一個可用的服務實例,實現負載均衡。
- 使用場景:結合 Feign 使用,支持輪詢、隨機等策略,實現服務調用的負載均衡。
- 3. Feign(聲明式服務調用)
- 功能:簡化服務間調用,通過聲明式接口實現遠程調用。
- 使用場景:服務 A 調用服務 B 的接口時,只需定義一個接口即可完成調用,底層自動集成 Ribbon 實現負載均衡。
- 4. Hystrix(服務熔斷與降級)
- 功能:在服務調用失敗或超時時,觸發熔斷機制,返回降級結果,防止雪崩效應。
- 使用場景:保護系統穩定性,避免一個服務故障導致整個系統不可用。
- 注意:Hystrix 已進入維護模式,目前我們項目中使用 Sentinel 替代。
- 5. Zuul / Gateway(API 網關)
- 功能:統一入口、路由轉發、權限校驗、限流、鑒權等。
- 使用場景:所有外部請求都經過網關進入系統,進行統一的鑒權、限流、日志記錄等操作。
- 區別:Zuul 是 Netflix 的網關組件,性能較差;Spring Cloud Gateway 基于 WebFlux,性能更優,是目前主流選擇。
- 6. Config(配置中心)
- 功能:集中管理微服務的配置文件,支持不同環境(dev、test、prod)的配置。
- 使用場景:微服務啟動時從 Config Server 獲取配置,支持動態刷新,避免頻繁修改配置文件。
- 7. Sleuth + Zipkin(分布式鏈路追蹤)
- 功能:記錄請求鏈路,分析服務調用耗時,定位性能瓶頸。
- 使用場景:排查慢接口、分析調用鏈、查看服務依賴關系。
16. 反問問題
- 目前團隊的技術棧是怎樣的?
- 項目中是否使用了微服務?使用的是 Spring Cloud 還是 Dubbo?
- 這個崗位主要負責哪些模塊?是業務開發、中間件維護,還是平臺開發?
- 目前團隊正在做的項目或產品是什么?主要的業務場景有哪些?
 選擇器詳解:為什么它是“父選擇器”?如何實現真正的容器查詢?)

后訓練方法)





)
控制相機旋轉,限制角度)
歸并排序)

:項目探索)
)

)


重點與易錯點全面總結)
