基本介紹
1.HKELM混合核極限學習機+NSGAII多目標優化算法,工藝參數優化、工程設計優化!(Matlab完整源碼和數據)
多目標優化是指在優化問題中同時考慮多個目標的優化過程。在多目標優化中,通常存在多個沖突的目標,即改善一個目標可能會導致另一個目標的惡化。因此,多目標優化的目標是找到一組解,這組解在多個目標下都是最優的,而不是僅僅優化單一目標。
2.先通過HKELM混合核極限學習機封裝因變量(y1 y2 y3 y4)與自變量(x1 x2 x3 x4 x5)代理模型,再通過nsga2尋找y極值(y1極大;y2 y3 y4極小),并給出對應的x1 x2 x3 x4 x5Pareto解集。
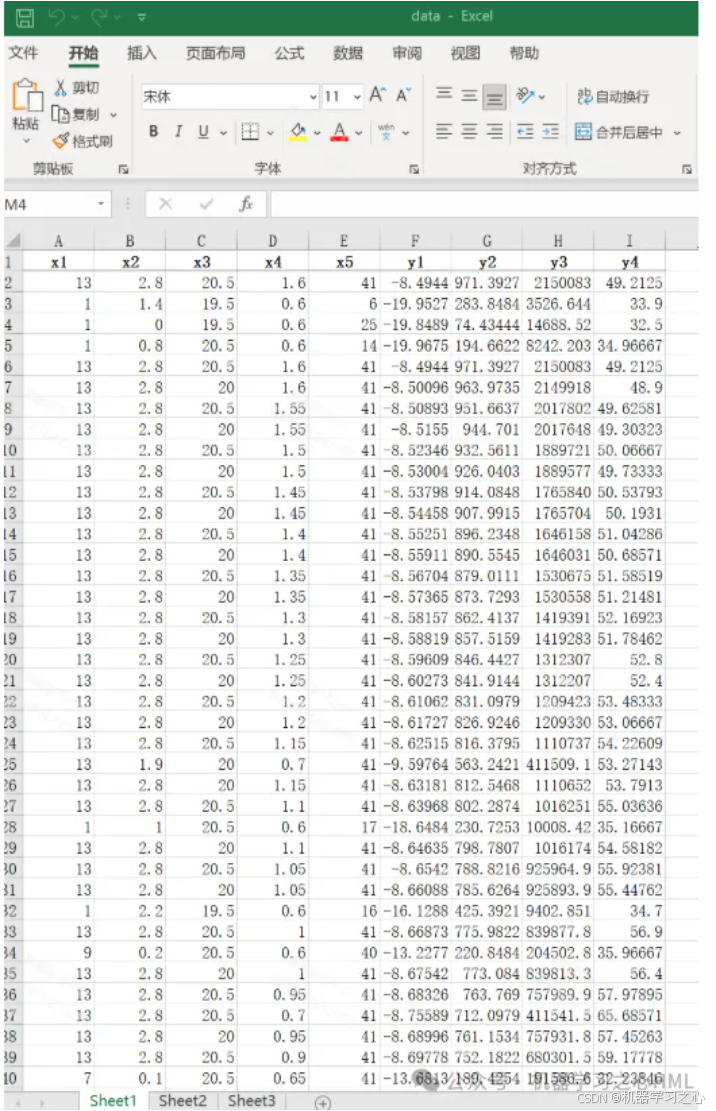
3.data為數據集,5個輸入特征,4個輸出變量,NSGAII算法尋極值,求出極值時(max y1; min y2;min y3;min y4)的自變量x1,x2,x3,x4,x5。
4.main1.m為HKELM混合核極限學習機主程序文件、main2.m為NSGAII多目標優化算法主程序文件,依次運行即可,其余為函數文件,無需運行。
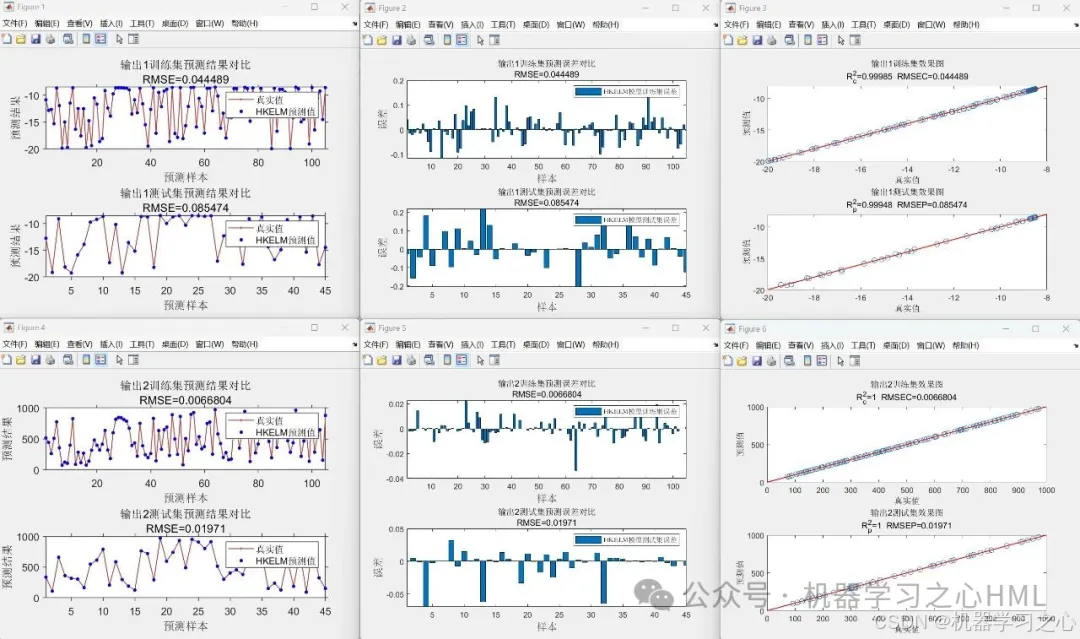
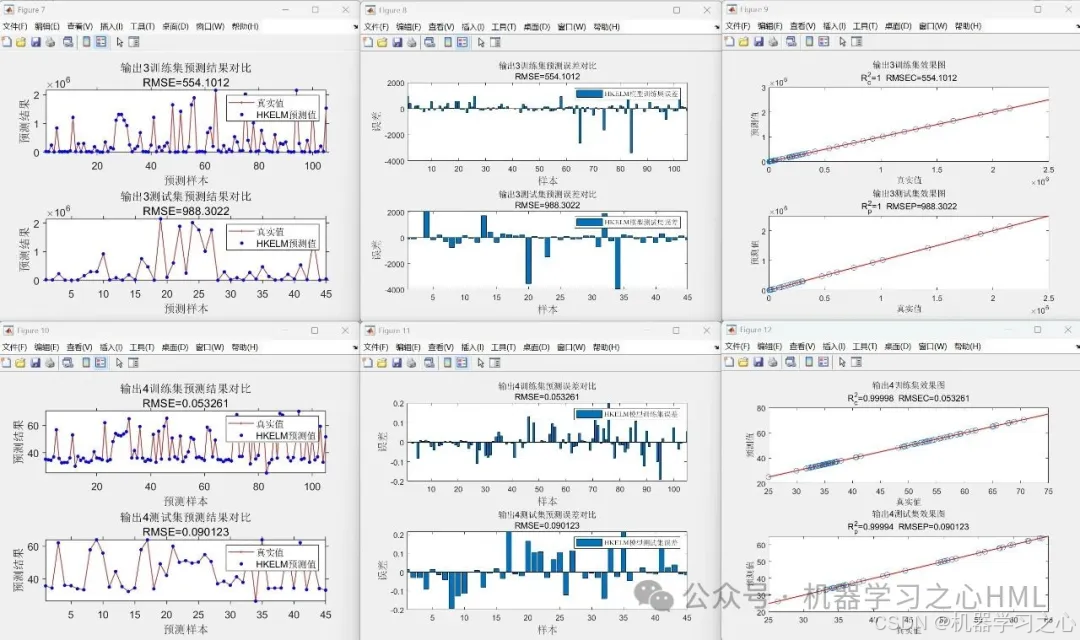
5.命令窗口輸出R2、MAE、MBE、MAPE、RMSE等評價指標,輸出預測對比圖、誤差分析圖、決定系數分析圖、多目標優化算法求解Pareto解集圖,可在下載區獲取數據和程序內容。
6.適合工藝參數優化、工程設計優化等最優特征組合領域。
NSGA-II算法
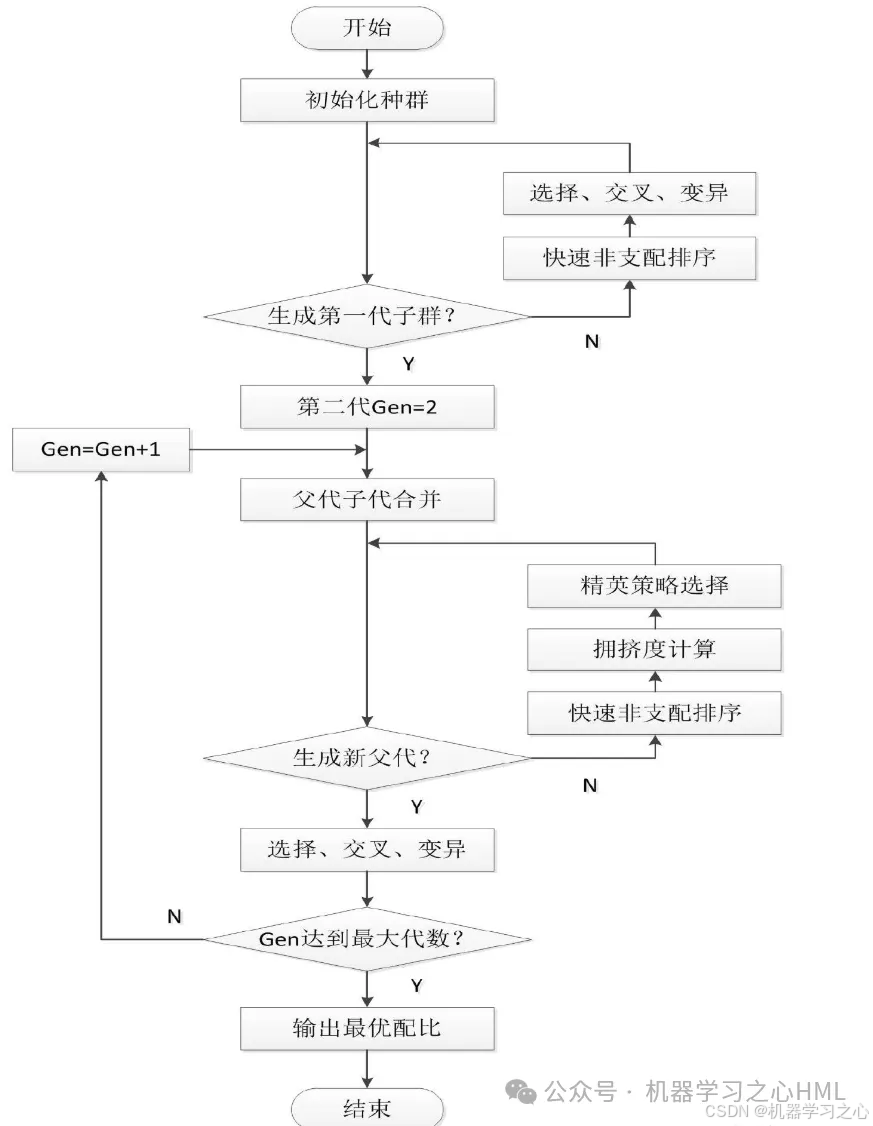
1) 隨機產生規模為N的初始種群Pt,經過非支配排序、 選擇、 交叉和變異, 產生子代種群Qt, 并將兩個種群聯合在一起形成大小為2N的種群Rt;
2)進行快速非支配排序, 同時對每個非支配層中的個體進行擁擠度計算, 根據非支配關系以及個體的擁擠度選取合適的個體組成新的父代種群Pt+1;
3) 通過遺傳算法的基本操作產生新的子代種群Qt+1, 將Pt+1與Qt+1合并形成新的種群Rt, 重復以上操作, 直到滿足程序結束的條件。
代碼功能
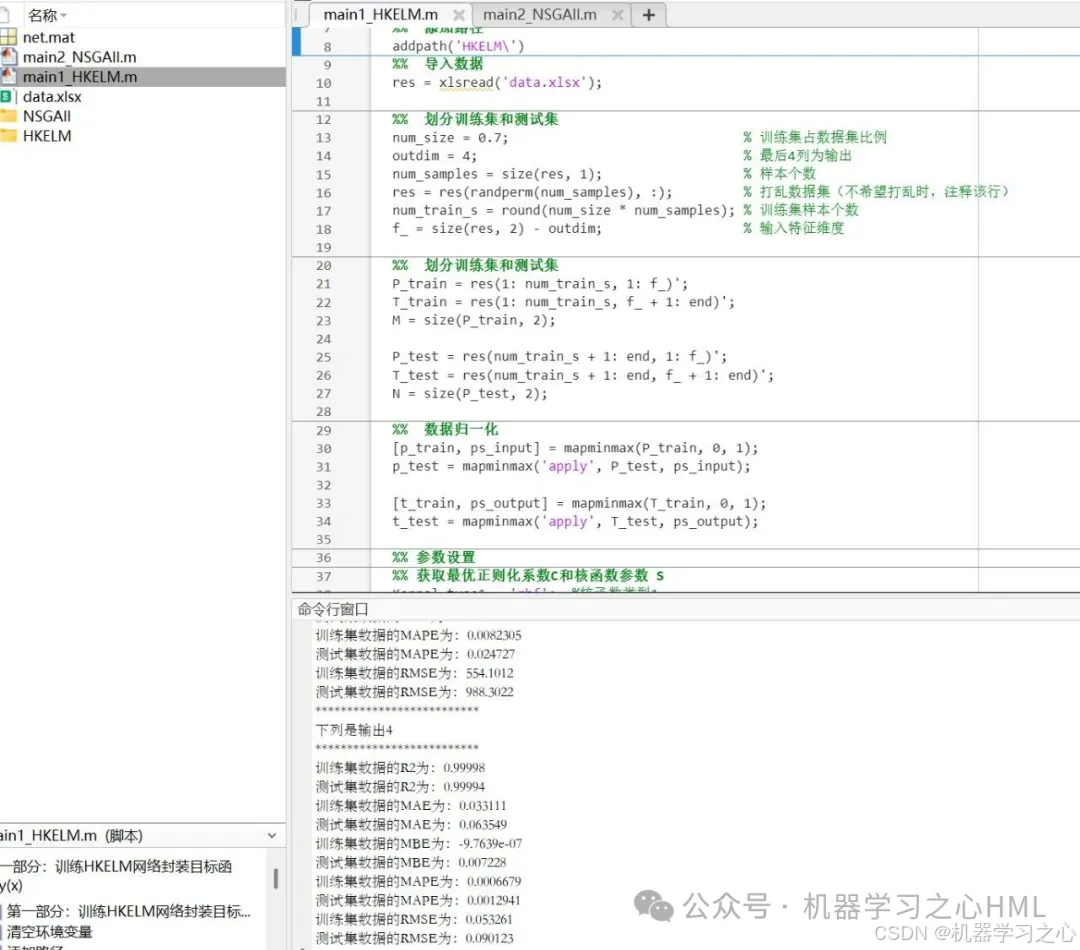
main1_HKELM.m
- 核心功能:訓練混合核極限學習機(HKELM)模型,用于多目標回歸預測(4個輸出)。
- 關鍵步驟:
- 數據預處理:導入數據、劃分訓練/測試集(70%訓練)、歸一化。
- HKELM建模:使用RBF+Poly雙核函數組合,優化正則化系數和核參數。
- 模型評估:計算RMSE、R2、MAE等指標,繪制預測結果對比圖。
- 模型保存:存儲歸一化參數、網絡權重等至
net.mat。
main2_NSGAII.m
- 核心功能:使用NSGA-II多目標優化算法,尋找使4個目標函數最優的輸入變量組合。
- 優化目標:
- 最大化輸出1(y1)
- 最小化輸出2-4(y2,y3,y4)
- 關鍵步驟:
- 初始化種群:定義5維輸入變量范圍和離散步長。
- 多目標優化:通過非支配排序、擁擠度計算、遺傳操作(交叉/變異)迭代進化。
- 輸出結果:Pareto最優解對應的輸入變量和目標函數值。
邏輯關聯
- 順序依賴:
- 必須先運行
main1_HKELM.m生成net.mat模型文件。 main2_NSGAII.m的costfunction會加載此模型預測目標函數值。
- 必須先運行
- 數據流:
算法步驟與技術路線
HKELM(混合核極限學習機)
- 技術路線:
- 核函數公式:
- 混合核:K=ω?KRBF+(1?ω)?KPolyK = \omega \cdot K_{RBF} + (1-\omega) \cdot K_{Poly}K=ω?KRBF?+(1?ω)?KPoly?
- RBF核:KRBF(xi,xj)=exp?(?∥xi?xj∥2σ2)K_{RBF}(x_i,x_j) = \exp\left(-\frac{\|x_i-x_j\|^2}{\sigma^2}\right)KRBF?(xi?,xj?)=exp(?σ2∥xi??xj?∥2?)
- Poly核:KPoly(xi,xj)=(xi?xj+c)dK_{Poly}(x_i,x_j) = (x_i \cdot x_j + c)^dKPoly?(xi?,xj?)=(xi??xj?+c)d
- 參數設定:
Kernel_para = [σ, c, d, ω](示例值:[0.001, 360, 5.0, 0.1])- 正則化系數
C=0.001
NSGA-II(非支配排序遺傳算法)
- 優化流程:
- 關鍵公式:
- 非支配排序:比較解之間的支配關系
- 擁擠度:Id=∑m=1Mfm(i+1)?fm(i?1)fmmax??fmmin?I_d = \sum_{m=1}^M \frac{f_m^{(i+1)} - f_m^{(i-1)}}{f_m^{\max} - f_m^{\min}}Id?=∑m=1M?fmmax??fmmin?fm(i+1)??fm(i?1)??
- 參數設定:
- 種群大小
npop=50 - 迭代次數
maxit=100 - 交叉概率
pc=0.85, 變異概率mu=0.2 - 變量范圍:
x1∈[1,13],x2∈[0,2.8],x3∈[3,21],x4∈[0.6,1.6],x5∈[6,41]
- 種群大小
運行環境
- 依賴項:
- MATLAB基礎庫
- 自定義函數包:
HKELM/+NSGAII/ - 數據文件:
data.xlsx
- 硬件要求:
- 無特殊要求(NSGA-II迭代100代屬輕量級優化)
創新點總結
- 兩階段架構:
- 階段1:HKELM建立高精度代理模型(替代物理模型)
- 階段2:NSGA-II在代理模型上高效尋優
- 混合核優勢:
RBF核捕獲局部特征 + Poly核描述全局趨勢,提升回歸泛化能力。 - 離散變量處理:
create_x()函數實現帶步長的離散變量生成(如x2步長0.1)。
注:完整運行需確保自定義函數包路徑正確,且
data.xlsx的格式與代碼匹配(最后4列為輸出)。
代碼運行效果
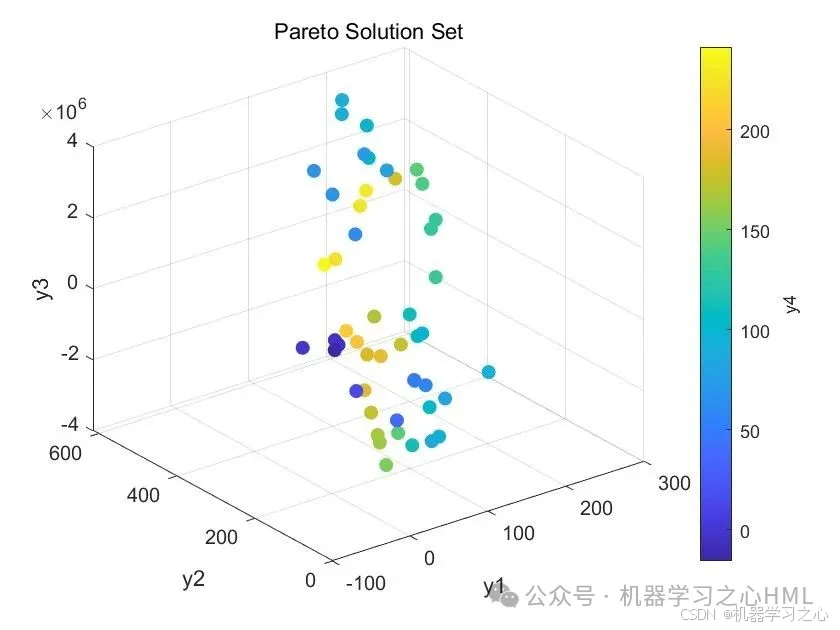
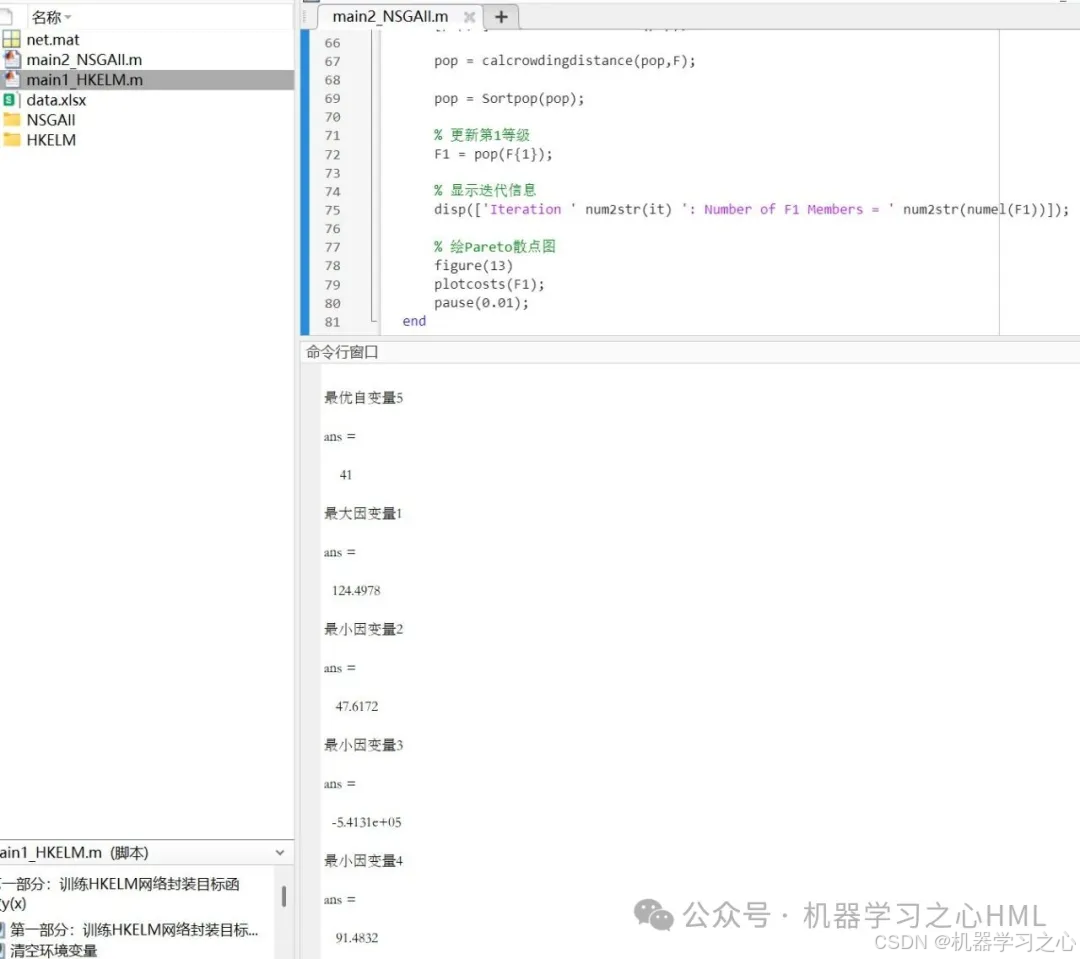
數據集




![[Rust 基礎課程]使用 Cargo 創建 Hello World 項目](http://pic.xiahunao.cn/[Rust 基礎課程]使用 Cargo 創建 Hello World 項目)

)
操作方法和屬性匯總詳解和代碼示例)

:實現一個音樂列表的頁面)
 47(題目+回答))
)
)






