目錄
- Kafka入門
- 消息引擎系統ABC
- 快速搞定Kafka術語
- kafka三層消息架構
- 名詞術語
- Kafka基礎
- Kafka部署參考
- 重要配置參數
- Broker端參數
- Topic級別參數
- JVM參數
Kafka是消息引擎系統,也是分布式流處理平臺
Kafka入門
消息引擎系統ABC
民間版:系統 A 發送消息給消息引擎系統,系統 B 從消息引擎系統中讀取 A 發送的消息。
消息引擎是用于在不同系統之間傳輸消息的,那么如何設計待傳輸消息的格式從來都是一等一的大事。Kafka使用的是純二進制的字節序列。當然消息還是結構化的,只是在使用之前都要將其轉換成二進制的字節序列。
點對點模型:也叫消息隊列模型。如果拿上面那個“民間版”的定義來說,那么系統 A發送的消息只能被系統 B 接收,其他任何系統都不能讀取 A 發送的消息。日常生活的例子比如電話客服就屬于這種模型:同一個客戶呼入電話只能被一位客服人員處理,第二個客服人員不能為該客戶服務。
發布 / 訂閱模型:與上面不同的是,它有一個主題(Topic)的概念,你可以理解成邏輯語義相近的消息容器。該模型也有發送方和接收方,只不過提法不同。發送方也稱為發布者(Publisher),接收方稱為訂閱者(Subscriber)。和點對點模型不同的是,這個模型可能存在多個發布者向相同的主題發送消息,而訂閱者也可能存在多個,它們都能接收到相同主題的消息。生活中的報紙訂閱就是一種典型的發布 / 訂閱模型。
我們不禁要問,為什么系統 A 不能直接發送消息給系統 B,中間還要隔一個消息引擎呢?
答案就是“削峰填谷”。
通常來說,兩個進程進行數據流交互的方式一般有三種:
- 通過數據庫:進程1寫入數據庫;進程2讀取數據庫
- 通過服務調用:比如REST或RPC,而HTTP協議通常就作為REST方式的底層通訊協議
- 通過消息傳遞的方式:進程1發送消息給名為broker的中間件,然后進程2從該broker中讀取消息。消息傳輸協議屬于這種模式
快速搞定Kafka術語
kafka三層消息架構
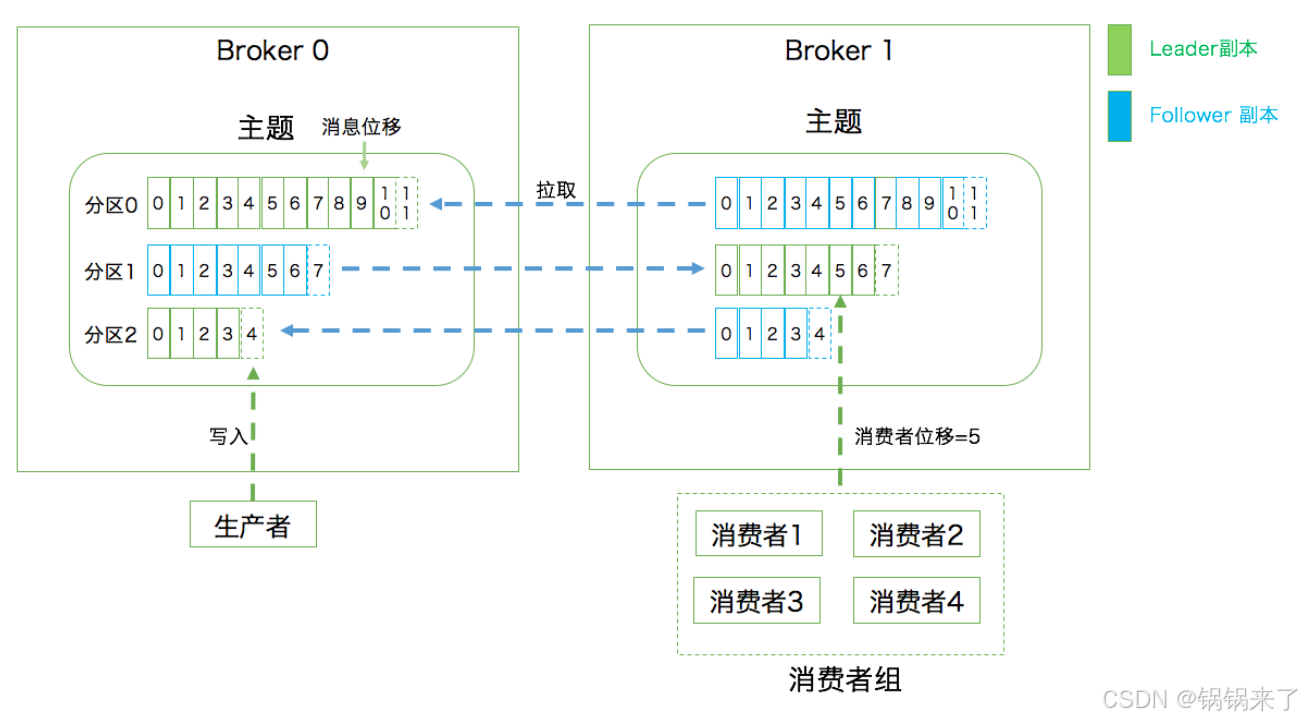
- 第一層是主題層,每個主題可以配置 M 個分區,而每個分區又可以配置 N 個副本。
- 第二層是分區層,每個分區的 N 個副本中只能有一個充當領導者角色,對外提供服務;其他 N-1 個副本是追隨者副本,只是提供數據冗余之用。
- 第三層是消息層,分區中包含若干條消息,每條消息的位移從 0 開始,依次遞增。最后,客戶端程序只能與分區的領導者副本進行交互。
名詞術語
消息:Record。Kafka 是消息引擎嘛,這里的消息就是指 Kafka 處理的主要對象。
主題:Topic。主題是承載消息的邏輯容器,在實際使用中多用來區分具體的業務。
分區:Partition。一個有序不變的消息序列。每個主題下可以有多個分區。
消息位移:Offset。表示分區中每條消息的位置信息,是一個單調遞增且不變的值。
副本:Replica。Kafka 中同一條消息能夠被拷貝到多個地方以提供數據冗余,這些地方就是所謂的副本。副本還分為領導者副本和追隨者副本,各自有不同的角色劃分。副本是在分區層級下的,即每個分區可配置多個副本實現高可用。
生產者:Producer。向主題發布新消息的應用程序。消費者:Consumer。從主題訂閱新消息的應用程序。消費者位移:Consumer Offset。表征消費者消費進度,每個消費者都有自己的消費者位移。
消費者組:Consumer Group。多個消費者實例共同組成的一個組,同時消費多個分區以實現高吞吐。重平衡:Rebalance。消費者組內某個消費者實例掛掉后,其他消費者實例自動重新分配訂閱主題分區的過程。Rebalance 是 Kafka 消費者端實現高可用的重要手段。
Kafka監控工具:
kafka manager kafka eagle JMXTrans + InfluxDB + Grafana
Kafka基礎
Kafka部署參考
重要配置參數
Broker端參數
log.dirs: 指定了Broker需要使用的若干個文件目錄路徑。在線上生產環境中一定要為log.dirs配置多個路徑,具體格式是一個 CSV 格式,也就是用逗號分隔的多個路徑,比如/home/kafka1,/home/kafka2,/home/kafka3這樣。如果有條件的話你最好保證這些目錄掛載到不同的物理磁盤上。
zookeeper.connect:
這也是一個 CSV 格式的參數,比如我可以指定它的值為zk1:2181,zk2:2181,zk3:2181。2181 是 ZooKeeper的默認端口。
如果我讓多個 Kafka 集群使用同一套ZooKeeper 集群,那么這個參數應該怎么設置呢?這時候chroot 就派上用場了。這個 chroot 是 ZooKeeper 的概念,類似于別名。
如果你有兩套 Kafka 集群,假設分別叫它們 kafka1 和kafka2,那么兩套集群的zookeeper.connect參數可以這樣指定:zk1:2181,zk2:2181,zk3:2181/kafka1和zk1:2181,zk2:2181,zk3:2181/kafka2。切記 chroot只需要寫一次,而且是加到最后的。
zookeeper.connect=172.20.38.137:34983,172.20.38.148:34983,172.20.38.125:34983
listeners:
listeners:學名叫監聽器,其實就是告訴外部連接者要通過什么協議訪問指定主機名和端口開放的 Kafka 服務。
監聽器的概念,從構成上來說,它是若干個逗號分隔的三元組,每個三元組的格式為<協議名稱,主機名,端口號>。這里的協議名稱可能是標準的名字,比如PLAINTEXT 表示明文傳輸、SSL 表示使用 SSL 或 TLS 加密傳輸等;也可能是你自己定義的協議名字
listeners=PLAINTEXT://172.20.38.148:34984
advertised.listeners:
和 listeners 相比多了個advertised。Advertised 的含義表示宣稱的、公布的,就是說這組監聽器是 Broker 用于對外發布的。
advertised.listeners主要是為外網訪問用的。如果clients在內網環境訪問Kafka不需要配置這個參數。
log.retention.{hour|minutes|ms}
log.retention.hour=168
自動刪除 7 天前的數據
log.retention.bytes:這是指定 Broker 為消息保存的總磁盤容量大小
message.max.bytes:
message.max.bytes=10485760(10M)
auto.create.topics.enable:是否允許自動創建Topic。
unclean.leader.election.enable:是否允許Unclean Leader 選舉。
auto.leader.rebalance.enable:是否允許定期進行 Leader 選舉。
Topic級別參數
Topic級別參數會覆蓋全局Broker參數的值,可以通過kafka-configs自帶腳本修改Topic級別參數。
retention.ms:規定了該 Topic 消息被保存的時長。默認是 7 天,即該 Topic 只保存最近 7 天的消息。一旦設置了這個值,它會覆蓋掉 Broker 端的全局參數值。
retention.bytes:規定了要為該 Topic 預留多大的磁盤空間。和全局參數作用相似,這個值通常在多租戶的Kafka 集群中會有用武之地。當前默認值是 -1,表示可以無限使用磁盤空間。
JVM參數
- KAFKA_HEAP_OPTS:指定堆大小。(一般設置6G)
- KAFKA_JVM_PERFORMANCE_OPTS:指定 GC 參數
VNetStack 深度技術解析)


)

:Cookie與會話)



失敗用例截圖與重試)

)






技術)
)