背景
在多部門、多技術棧并存的企業環境中,日志收集與分析是保障系統穩定運行的核心能力之一。然而,不同開發團隊采用各異的日志打印方式,導致日志數據結構混亂,嚴重影響后續的收集、存儲、檢索與告警效率。
比如我們大部門就有多套日志格式,不同小部門有不同的格式,導致我們運維任務和成本大幅度增加。
典型問題場景包括:
開發團隊A使用Log4j,格式為[%d] %p %c - %m%n
團隊B采用Logback,格式為%date %level [%thread] %logger - %msg%n
微服務C輸出JSON格式日志但缺少統一字段規范

本文將介紹我們如何建立統一的日志格式規范,并基于 Filebeat + Logstash 實現多環境(宿主機/Kubernetes)下的高效日志采集、解析與存儲。
為什么要統一日志格式?
遇到的問題:
- 各部門日志格式五花八門,結構不一
- 多行異常堆棧無法完整還原,頻繁切段
- traceId/請求上下文缺失,無法鏈路追蹤
- 結構化字段難以提取,告警系統誤報頻繁
統一格式的好處:
- 日志標準化后,便于多系統集中分析
- traceId 實現服務鏈路跟蹤(可接入 Skywalking/Jaeger)
- 多行異常可合并為單條日志事件
- 方便在 Elasticsearch 中建立字段索引,用于篩選、聚合與報警
日志格式統一規范
在設計日志標準時,我們遵循以下關鍵原則:
機器可讀性:便于采集工具自動解析
人類可讀性:保留足夠上下文,便于工程師直接閱讀
完整性與高效性的平衡:包含必要字段但不過度冗余
可擴展性:支持未來增加新字段而不破壞兼容性
行業兼容性:符合主流日志框架的最佳實踐
經過多輪評審,最終確定的標準日志格式為:
%d{yyyy-MM-dd HH:mm:ss.SSS} [%-5level] [%X{traceId:-null}] [%thread] [%logger{36}] [%L] - %msg%n%wEx
樣例日志:
2025-04-09 13:36:39.947 [INFO ] [null] [main] [o.s.c.s.PostProcessorRegistrationDelegate$BeanPostProcessorChecker] [327] - Bean 'org.springframework.transaction.annotation.ProxyTransactionManagementConfiguration' of type [org.springframework.transaction.annotation.ProxyTransactionManagementConfiguration$$EnhancerBySpringCGLIB$$d712abb8] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying)
Grok語法
%{TIMESTAMP_ISO8601:date} \[\s{0,2}(?<loglevel>[^\]]+)\] \[\s{0,2}(?<traceId>[^\]]+)\] \[(?<thread>[^\]]+)\] \[(?<logger>[^\]]+)\] \[(?<codeline>\d+)\] - %{GREEDYDATA:msg}
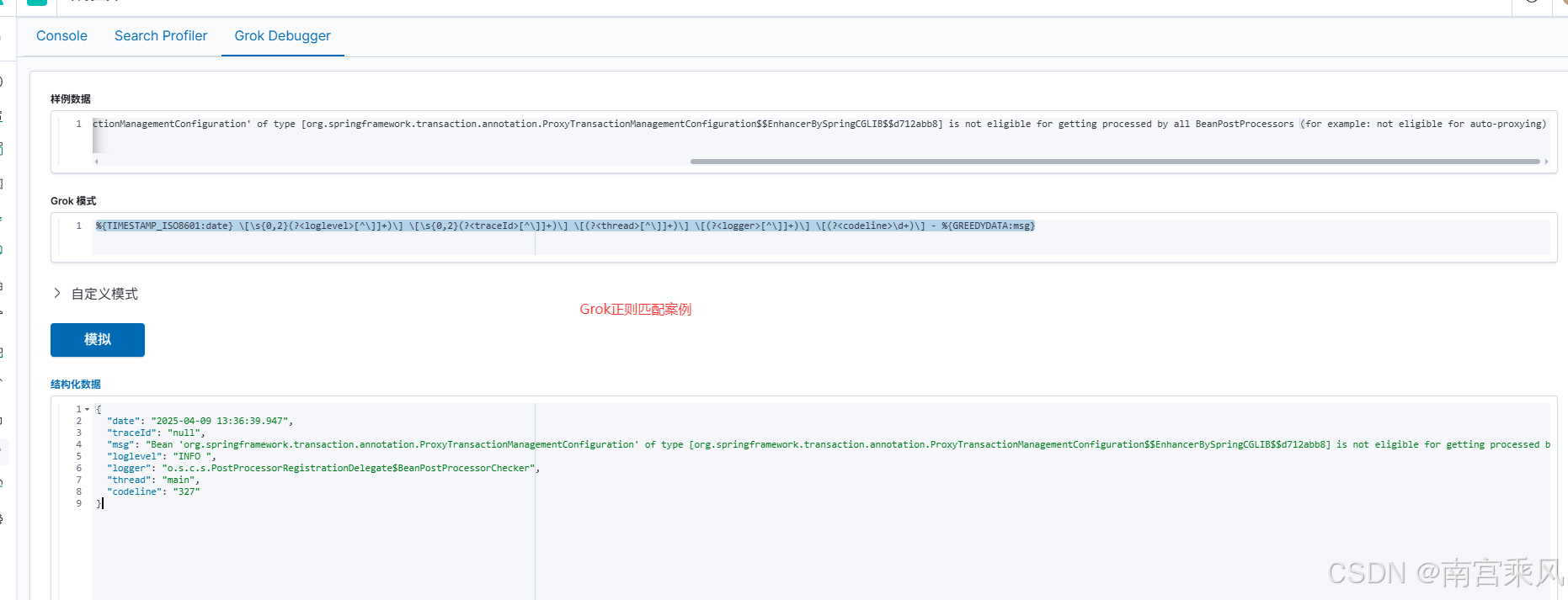
這個標準格式包含七大關鍵要素:
時間戳:精確到毫秒的ISO8601格式,確保跨時區協調
日志級別:統一5字符寬度對齊(ERROR/WARN/INFO/DEBUG)
追蹤標識:分布式系統必備的traceId,缺省為null
線程信息:幫助理解異步處理流程
類名:縮寫為36字符保持簡潔
行號:精準定位日志產生位置
消息體:包含可選的異常堆棧信息
| 字段占位符 | 對應字段 | 說明 | 必要性 | 示例 |
|---|---|---|---|---|
| %d{yyyy-MM-dd HH:mm:ss.SSS} | 時間戳 | 精確到毫秒的ISO8601格式 | 必要 | 2023-08-15 14:30:45.123 |
| %-5level | 日志級別 | 右對齊,5字符寬度 | 必要 | INFO / ERROR |
| %X{traceId:-null} | 請求鏈路ID | 分布式追蹤標識 | 重要 | 3f5e8a2b1c9d4f7e |
| %thread | 線程名 | 執行線程標識 | 必要 | http-nio-8080-exec-1 |
| %logger{36} | 類名 | 截斷到36字符的類全名 | 必要 | com.fjf.service.PaymentService |
| %L | 代碼行號 | 日志調用處的行號 | 可選 | 42 |
| %msg | 日志內容 | 實際日志信息 | 核心 | “用戶支付成功,金額:100.00” |
| %wEx | 異常堆棧 | 附帶異常時的堆棧信息 | 條件 | java.lang.NullPointerException… |
多語言實現示例
Java (Log4j2):
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%-5level] [%X{traceId:-null}] [%thread] [%-36.36logger{36}] [%.-1L] - %msg%n%wEx"/>
Python:
import logging
FORMAT = '%(asctime)s [%(levelname)-5s] [%(traceId)s] [%(threadName)s] [%(name)-36s] [%(lineno)d] - %(message)s'
日志采集方案設計
混合環境下的采集策略
面對物理機與Kubernetes并存的混合環境,我們設計了分層采集方案:
宿主機 Filebeat 配置
# filebeat.inputs配置
filebeat.inputs:
- type: logenabled: truepaths:- /app/logs/app/hx-app.log- /app/logs/app/hx-consume.log- /fjf_work/logs/fujfu_member/fujfu_member_admin.log# 多行日志處理關鍵配置multiline.pattern: ^\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}[.,:]0{0,1}\d{3}multiline.negate: truemultiline.match: after# 元數據字段fields:logtype: "hx"fields_under_root: true
fields:ip: 192.18.199.160output.logstash:hosts: ["logstash.server.fjf:5044"]技術關鍵點:
- multiline.pattern使用正則嚴格匹配標準格式的時間戳開頭
- negate: true + match: after確保堆棧信息被正確關聯到主日志行
- 通過fields添加主機IP等元信息,便于后續定位問題來源
Kubernetes Pod 內部 Filebeat ConfigMap
filebeat-configmap.yaml 可以注冊到configmap中
filebeat.inputs:
- type: logenabled: truepaths:- /app/logs/app/*.logmultiline.pattern: ^\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}[.,:]0{0,1}\d{3}multiline.negate: truemultiline.match: afterfields:logtype: ${LOGTYPE:app}fields_under_root: true
fields:ip: ${POD_IP} # 自動注入Pod IPoutput.logstash:hosts: ["logstash-server.default.svc.cloudcs.fjf:5044"]? 說明:多行合并通過正則識別日志起始行(時間戳),其余行自動歸入上一條日志。
K8s特定優化:
- 使用環境變量動態注入POD_IP和LOGTYPE
- 通配符路徑匹配適配不同應用的日志文件
- 通過DaemonSet確保每個節點都有采集器
Logstash 解析規則設計
在 Logstash 中通過 filter 插件完成日志結構化處理,區分標準格式、PowerJob 特例與 JSON 格式:
filter {# JSON日志特殊處理if [fields][json] == "true" {json {source => "message"remove_field => ["message","agent","tags","ecs"]}}# 標準格式解析else {grok {match => { "message" => ["%{TIMESTAMP_ISO8601:date} \[\s{0,2}(?<loglevel>[^\]]+)\] \[\s{0,2}(?<traceId>[^\]]+)\] \[(?<thread>[^\]]+)\] \[(?<logger>[^\]]+)\] \[(?<codeline>\d+)\] - %{GREEDYDATA:msg}",# 備用模式匹配歷史格式]}}}# 添加業務標記ruby {code => 'event.set("projectname", event.get("host")["name"].split(".")[0])'}# 時間處理date {match => ["date","ISO8601","yyyy-MM-dd HH:mm:ss.SSS"]target => "@timestamp"timezone => "Asia/Shanghai"}
}生產案例:
# ===========================
# 1. 輸入配置(Beats 輸入)
# ===========================
input {beats {port => 5044 # 接收來自 Filebeat 的數據ssl => false # 未啟用 SSL(可以視需求啟用)client_inactivity_timeout => 36000 # 客戶端連接空閑超時(秒)}
}
# ===========================
# 2. 過濾器(filter)
# ===========================
filter {# 如果是 JSON 格式日志(如前端或Node服務打印的 JSON 日志)if [fields][json] == "true" {json {source => "message" # 指定從 message 字段中解析 JSONremove_field => ["message", "agent", "tags", "ecs"] # 清理多余字段add_field => {"loglevel" => "%{[severity]}" # 從 JSON 中提取 severity 字段作為 loglevel}}# 如果是 PowerJob 的日志格式(特殊格式日志單獨處理)} else if [fields][logtype] == "powerjob" {grok {match => {"message" => "%{TIMESTAMP_ISO8601:date} \s{0,1}(?<severity>.*?) (?<pid>.*?) --- \[(?<thread>.*?)\] (?<class>.*?) \s*: (?<rest>.*+?)"}remove_field => ["message", "agent", "tags"]add_field => {"loglevel" => "%{[severity]}"}}mutate {update => {"[fields][logtype]" => "logstash" # 為統一索引,將 logtype 設置為 logstash}}# 默認解析邏輯:標準日志格式(適配多種格式)} else {grok {match => { "message" => [# 標準推薦格式日志"%{TIMESTAMP_ISO8601:date} \[\s{0,2}(?<loglevel>[^\]]+)\] \[\s{0,2}(?<traceId>[^\]]+)\] \[(?<thread>[^\]]+)\] \[(?<logger>[^\]]+)\] \[(?<codeline>\d+)\] - %{GREEDYDATA:msg}",# 其他兼容格式 (防止有漏網之魚,加的格式,注意格式越多,處理也耗費CPU)"%{TIMESTAMP_ISO8601:date} (?<loglevel>.*?)\s{1,2}\| \[(?<threadname>.*?)\] (?<classname>.*?) \[(?<codeline>.*?)\] \| \[(?<traceid>.*?)\] \| (?<msg>.*+?)","%{TIMESTAMP_ISO8601:date} (?<loglevel>.*?)\s{1,2}\| \[(?<threadname>.*?)\] (?<classname>.*?) \[(?<codeline>.*?)\] \| (?<msg>.*+?)","\[%{TIMESTAMP_ISO8601:date}\] \[(?<loglevel>.*?)\s{0,2}\] \[(?<threadname>.*?)\] (?<classname>.*?) (?<codeline>.*?) - (?<msg>.*+?)","%{TIMESTAMP_ISO8601:date} \[(?<threadname>.*?)\] (?<loglevel>.*?)\s{0,2} (?<classname>.*?) (?<codeline>.*?) - (?<msg>.*+?)"]}remove_field => ["message", "agent", "tags"] # 刪除原始 message 字段等無用字段}}# Ruby 腳本:提取主機名的前綴作為項目名ruby {code =>'arr = event.get("host")["name"].split(".")[0]event.set("projectname", arr)'}# 時間字段統一轉換為 @timestamp,便于時序檢索date {match => ["date", "ISO8601", "yyyy-MM-dd HH:mm:ss.SSS"]target => "@timestamp"timezone => "Asia/Shanghai" # 設置中國時區,避免時間錯亂}}# ===========================
# 3. 輸出到 Elasticsearch
# ===========================
output {elasticsearch {hosts => ["elasticsearch-log.prod.server.fjf:9200"] # ES 地址user => "elastic"password => "xxxxxxxxxxxx"manage_template => false # 不自動覆蓋 ES 模板(防止沖突)index => "%{[fields][logtype]}-prod-%{+YYYY.MM.dd}" # 動態索引名(按日志類型和日期)}
}關鍵處理階段:
- 格式識別路由:區分JSON和文本日志
- 多模式Grok解析:主模式匹配標準格式,備用模式兼容歷史格式
- 元數據豐富:從主機名提取項目標識
- 時間標準化:統一轉化為ES兼容的時間戳
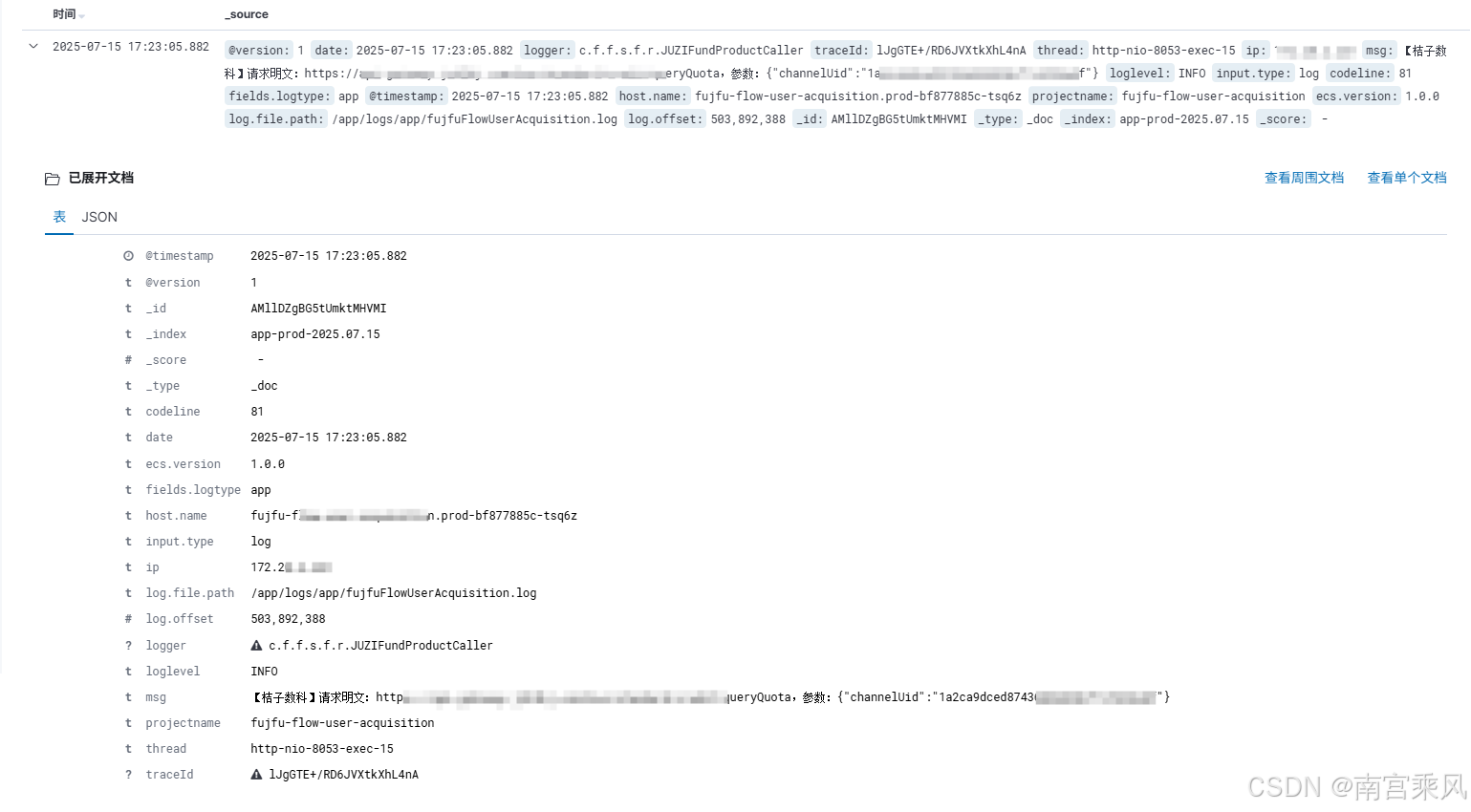
實踐效果
引入統一日志系統后取得的可測量改進:
- 故障定位時間:從平均2.5小時縮短至30分鐘
- 日志存儲量:通過合理字段設計減少25%存儲需求
- 日志利用率:結構化日志使90%的日志可被監控系統利用
- 異常檢測:基于標準字段建立的規則發現率提升40%
:實現一個音樂列表的頁面)
 47(題目+回答))
)
)







VNetStack 深度技術解析)


)

:Cookie與會話)


