前言
? ? 📅大四是整個大學期間最忙碌的時光,一邊要忙著備考或實習為畢業后面臨的就業升學做準備,一邊要為畢業設計耗費大量精力。近幾年各個學校要求的畢設項目越來越難,有不少課題是研究生級別難度的,對本科同學來說是充滿挑戰。為幫助大家順利通過和節省時間與精力投入到更重要的就業和考試中去,學長分享優質的選題經驗和畢設項目與技術思路。
🚀對畢設有任何疑問都可以問學長哦!
?? ?選題指導:
? ? ? ? 最新最全計算機專業畢設選題精選推薦匯總
? ? ? ??大家好,這里是海浪學長畢設專題,本次分享的課題是
? ? ? ?🎯基于深度學習的噪聲過濾音頻優化系統研究
課題背景和意義
隨著智能設備和語音助手的廣泛應用,音頻識別技術在日常生活中變得愈加重要。然而,現實環境中存在各種噪聲(如交通聲、人群聲和設備噪聲),這對音頻識別的準確性造成了顯著影響。傳統的音頻處理技術在噪聲環境下往往難以有效提取清晰的語音信號,導致識別率下降。開發一種能夠在嘈雜環境中有效工作的音頻識別系統顯得尤為重要。深度學習作為一種強大的數據驅動方法,近年來在聲音處理領域取得了顯著進展。通過構建復雜的神經網絡模型,深度學習能夠學習到音頻信號的深層特征,從而在噪聲環境中實現更高的識別準確性。
實現技術思路
一、檢測方法
1.1 卷積神經網絡
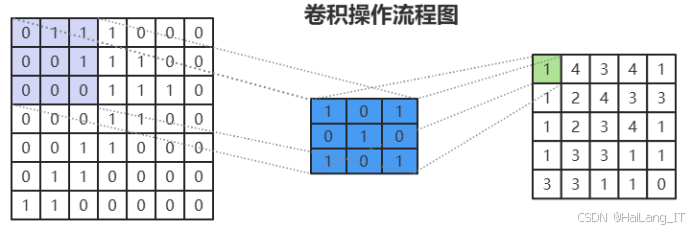
卷積神經網絡(CNN)通常由三個主要部分組成:卷積層、池化層和全連接層。卷積層是CNN的核心組件,負責提取輸入數據的局部特征,尤其在處理圖像和聲音等高維數據時顯得尤為重要。通過使用多個可學習的卷積核在輸入數據上滑動,卷積層進行逐點的卷積運算,生成特征圖。這些卷積核能夠有效識別圖像中的邊緣、角點以及其他重要特征,通過激活函數(如ReLU)引入非線性,使模型能夠學習到更復雜的特征表示。卷積層的結構設計使得其在空間上具有局部連接的特性,能夠有效捕捉輸入數據的局部特征,并通過權重共享的方式減少模型的參數數量,從而提高計算效率。這種特性使得卷積層在處理視覺任務時表現出色,能夠保持特征的平移不變性,從而增強模型的魯棒性。卷積層通過多層疊加,能夠逐步提取更高層次的特征,最終形成對圖像內容的深刻理解。
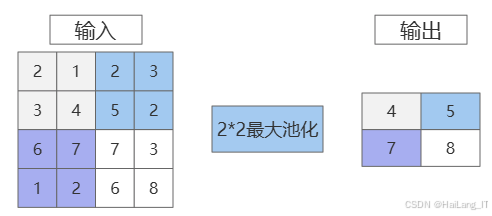
池化層是CNN中的另一個重要組成部分,主要用于降低特征圖的空間維度,有效減少計算量和過擬合風險,同時提取更具代表性的特征。池化層的常用方法包括最大池化和平均池化,其中最大池化通過選擇池化窗口內的最大值進行下采樣,從而保留最顯著的特征。池化操作通常在卷積層之后進行,其主要目的是幫助模型在一定程度上保持特征的不變性,避免因為小的變換(如平移或旋轉)而導致特征的丟失。通過池化層,特征圖的尺寸被顯著減小,這不僅降低了后續計算的復雜度,還有助于提高模型的訓練效率和泛化能力。池化層的引入使得模型在面對復雜的輸入時,能夠更好地提取和保留關鍵信息,增強模型對輸入數據的適應性。池化過程還能夠減少運算量,降低內存占用,從而加速訓練過程。
全連接層位于CNN的最后部分,負責將提取到的特征映射到最終的輸出,例如分類或回歸結果。在全連接層中,前一層的每個神經元與當前層的每個神經元都有連接,這種全連接的方式使得模型能夠綜合所有提取的特征,以進行更高層次的決策。全連接層通常采用激活函數(如Softmax),使得輸出能夠表示為不同類別的概率分布,從而進行分類任務。全連接層的設計使得模型能夠學習到復雜的特征組合,增強了模型的表達能力和預測能力。通過這一層,模型能夠將低級特征轉化為高層語義信息,從而實現最終的分類或回歸。
1.2長短期記憶網絡
長短期記憶網絡(LSTM)是一種特殊的循環神經網絡(RNN),專門設計用于處理和預測時間序列數據。LSTM的主要組成部分包括輸入門、遺忘門和輸出門。輸入門控制當前輸入的信息有多少能夠進入單元狀態,它通過sigmoid激活函數決定哪些信息需要保留,同時使用tanh激活函數生成候選值來更新單元狀態。遺忘門則決定哪些信息需要從單元狀態中丟棄。通過sigmoid函數,遺忘門可以選擇性地過濾掉不再需要的信息,從而保持對重要信息的關注。輸出門則控制單元狀態的輸出,決定哪些信息將傳遞到下一層或下一時刻的計算。
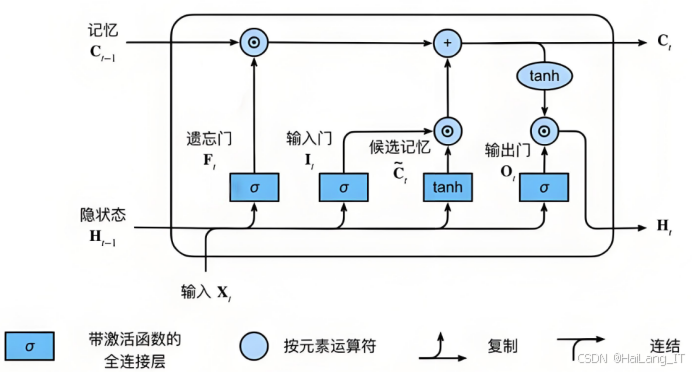
LSTM的設計使其能夠有效解決傳統RNN在長序列訓練過程中容易出現的梯度消失和梯度爆炸問題。通過引入門控機制,LSTM能夠在較長時間跨度內保持信息的有效性。這種特性使得LSTM特別適合處理語言建模、語音識別、時間序列預測等任務。在這些應用中,LSTM能夠根據歷史數據動態調整其狀態,從而捕捉長期依賴關系,增強模型對序列數據的理解能力。
LSTM網絡的結構相對復雜,但這種復雜性帶來了更強的表現力。每個LSTM單元內部包含多個參數,控制輸入、遺忘和輸出的門控機制。通過這些門的協同作用,LSTM能夠在時間序列數據中提取重要特征,記住有用的信息并遺忘無關的信息。這種靈活性使得LSTM在許多應用場景中相較于傳統RNN表現出色,尤其在需要長時間依賴的信息處理任務中展現出優勢。
深度學習模型結合了卷積神經網絡(CNN)和長短期記憶網絡(LSTM),旨在實現噪聲過濾以優化音頻信號。輸入層接受時頻圖作為輸入數據,這些時頻圖可以是梅爾頻率倒譜系數(MFCC)或短時傅里葉變換(STFT)生成的圖像,輸入的形狀為 (時間步長, 特征維度, 1)。模型的第一部分是卷積層,首先通過使用二維卷積操作的卷積層1,卷積核大小設為 (3, 3),激活函數選擇ReLU,輸出通道數為32。接下來,池化層1采用最大池化層,池化窗口大小為 (2, 2),用于下采樣特征圖,減少計算量。卷積層2再次使用二維卷積操作,卷積核大小同樣為 (3, 3),輸出通道數增加到64,并繼續使用ReLU激活函數。池化層2再次進行最大池化操作,進一步降低特征圖的維度。最后,通過Flatten層將卷積層的輸出展平,為后續的全連接層做準備。
下一部分是全連接層,連接一個或多個全連接層,激活函數仍為ReLU,節點數設定為128,以增強模型的表達能力。隨后引入LSTM層,使用64個LSTM單元處理時序特征,捕捉音頻信號的長期依賴關系。這一部分對于處理音頻信號中的時間特性至關重要。最后,輸出層使用全連接層,節點數與音頻信號輸出的維度相同,激活函數為線性,以生成經過噪聲過濾后的音頻信號。整體架構設計結合了CNN在特征提取方面的優勢以及LSTM在時序建模上的能力,使得模型能夠有效處理復雜的音頻數據,提高噪聲過濾的準確性和效果。
二、實驗及結果分析
?在開始訓練之前,確保已安裝TensorFlow,并且擁有穩定的網絡連接和足夠的磁盤空間以下載超過1GB的訓練數據。此外,訓練過程可能需要幾個小時,因此請確保你有一臺可以長時間使用的機器。在準備工作中,用戶需要確保Python環境配置正確,并安裝TensorFlow庫,可以使用以下命令安裝:
收集多種環境下的音頻數據,包括清晰的語音片段和不同類型的噪聲(如交通噪聲、人群噪聲、風聲等),可以通過訪問公開數據集獲取,或者通過專門的錄音設備在各種實際環境中自行錄制,確保所收集的數據涵蓋多種場景和說話者,以提高模型的泛化能力和適應性。使用音頻處理工具(Audacity)對音頻進行人工標注,標記出清晰的語音片段和背景噪聲。手動標注雖然耗時,但可以確保數據的準確性,幫助模型更好地學習,還需要剔除音頻中的靜默部分,聚焦于有效的語音信號。可以通過設定音量閾值來判斷靜默段,并使用音頻處理庫(Librosa)進行自動化處理。所有的音頻信號都應進行歸一化處理,這樣可以確保數據在相同的尺度上,減少模型訓練時的偏差。歸一化處理可以提高神經網絡的收斂速度,確保模型在訓練過程中更穩定。
? ? ? ? import librosa
import numpy as npdef preprocess_audio(file_path):# 加載音頻文件signal, sr = librosa.load(file_path, sr=None)# 去除靜默部分non_silent_intervals = librosa.effects.split(signal, top_db=20)segments = [signal[start:end] for start, end in non_silent_intervals]# 合并處理后的片段processed_signal = np.concatenate(segments)# 歸一化normalized_signal = processed_signal / np.max(np.abs(processed_signal))return normalized_signal, sr特征提取階段,使用梅爾頻率倒譜系數(MFCC)作為主要特征,因為MFCC能夠有效捕捉音頻的音質和語音特征。MFCC通過將音頻信號分幀、加窗、進行傅里葉變換、通過梅爾濾波器組處理以及最終的離散余弦變換等步驟獲得。這些步驟能提取出音頻信號中頻率的變化,使得模型能夠更好地理解和分類音頻信號中的內容。在特征提取過程中,還可以考慮其他特征,如譜圖、Chroma特征或零交叉率等。這些特征能夠提供更豐富的信息,幫助模型捕捉更多的音頻信號細節。結合不同類型的特征將增強模型的表現力,使其在復雜的噪聲環境中更具魯棒性。
? ? ?import librosa
import numpy as np
import osdef extract_mfccs_from_directory(directory, n_mfcc=13, max_length=100):mfccs_list = []labels = []for filename in os.listdir(directory):if filename.endswith('.wav'): # 只處理.wav文件file_path = os.path.join(directory, filename)signal, sr = librosa.load(file_path, sr=None)# 提取 MFCC 特征mfccs = librosa.feature.mfcc(y=signal, sr=sr, n_mfcc=n_mfcc)mfccs = np.mean(mfccs.T, axis=0) # 計算每個特征的均值# 限制特征長度if len(mfccs) > max_length:mfccs = mfccs[:max_length]else:mfccs = np.pad(mfccs, (0, max_length - len(mfccs)), 'constant')mfccs_list.append(mfccs)labels.append(get_label_from_filename(filename)) # 從文件名提取標簽return np.array(mfccs_list), np.array(labels)def get_label_from_filename(filename):# 根據文件名定義標簽提取邏輯# 例如, "traffic_noise_1.wav" -> "traffic"return filename.split('_')[0]# 示例使用
directory = 'path_to_audio_directory'
mfcc_features, labels = extract_mfccs_from_directory(directory)? ?結合卷積神經網絡(CNN)和長短期記憶網絡(LSTM)的深度學習模型架構,使其能夠充分發揮兩者的優勢。CNN在處理圖像數據時表現出色,能夠有效提取時頻圖中的空間特征,而LSTM則能夠處理時間序列數據中的長期依賴關系。該模型架構包括輸入層、多個卷積層、池化層、Flatten層、全連接層和LSTM層,最終輸出經過噪聲過濾的音頻信號。卷積層的設計可以包括多層卷積和池化操作,以逐步抽取音頻特征的高層表示。通過使用ReLU激活函數,模型能夠引入非線性,增強特征提取的能力。LSTM層則用于對處理后的特征進行時序建模,使得模型能夠捕捉音頻中的時間相關性,處理長時間依賴關系。這種復雜的模型架構能夠適應音頻信號的多樣性,使得模型在不同的噪聲條件下都能保持較高的性能。
import tensorflow as tf
from tensorflow.keras import layers, modelsdef create_model(input_shape):model = models.Sequential()# 卷積層1model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=input_shape))model.add(layers.MaxPooling2D((2, 2)))# 卷積層2model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.MaxPooling2D((2, 2)))# Flatten層model.add(layers.Flatten())# 全連接層model.add(layers.Dense(128, activation='relu'))# LSTM層model.add(layers.Reshape((1, 128))) # Reshape為LSTM輸入格式model.add(layers.LSTM(64))# 輸出層model.add(layers.Dense(output_dim, activation='linear')) # output_dim為音頻信號輸出維度return modelinput_shape = (time_steps, feature_dim, 1) # 需要根據實際數據設置
model = create_model(input_shape)模型訓練階段,采用均方誤差(MSE)作為損失函數,評估模型輸出與真實語音信號之間的差異。使用Adam或RMSprop優化算法進行模型訓練,調整學習率和其他超參數以提高收斂速度和準確性。在訓練過程中,可以通過監控訓練集和驗證集的損失和準確率,及時調整超參數,以獲得最佳的模型性能。
為了進一步增強模型的魯棒性,進行數據增強也是非常必要的。通過添加背景噪聲、進行音頻變速、改變音高和添加混響等方法,可以增加模型對不同環境的適應能力。這些數據增強手段不僅能提高模型的泛化能力,還能有效避免過擬合現象的發生。
from sklearn.model_selection import train_test_split
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint# 假設 mfcc_features 和 labels 已經準備好
X_train, X_val, y_train, y_val = train_test_split(mfcc_features, labels, test_size=0.2, random_state=42)# 需要調整輸入形狀
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1) # 調整為 (樣本數, 特征維度, 1)
X_val = X_val.reshape(X_val.shape[0], X_val.shape[1], 1)# 創建模型
model = create_model((X_train.shape[1], 1)) # 輸入形狀為 (特征維度, 1)# 編譯模型
model.compile(optimizer='adam', loss='mean_squared_error', metrics=['mae'])# 設置回調函數
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
model_checkpoint = ModelCheckpoint('best_model.h5', save_best_only=True, monitor='val_loss')# 訓練模型
history = model.fit(X_train, y_train, epochs=100, batch_size=32, validation_data=(X_val, y_val), callbacks=[early_stopping, model_checkpoint])# 可視化訓練過程
import matplotlib.pyplot as pltplt.plot(history.history['loss'], label='train_loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend()
plt.show()使用準確率、召回率和F1-score等指標來評估模型的性能,以確保其在不同噪聲環境下的有效性。此外,采用k折交叉驗證的方法可以幫助確認模型的泛化能力,防止過擬合。在k折交叉驗證中,將數據集分為k個子集,依次使用每個子集作為驗證集,其余作為訓練集,這樣可以更全面地評估模型的性能。
from sklearn.metrics import classification_report# 預測并評估
y_pred = model.predict(X_test)
report = classification_report(y_test, y_pred)
print(report)# k折交叉驗證示例
from sklearn.model_selection import KFoldkf = KFold(n_splits=5)
for train_index, val_index in kf.split(X):X_train, X_val = X[train_index], X[val_index]y_train, y_val = y[train_index], y[val_index]model.fit(X_train, y_train, epochs=50, validation_data=(X_val, y_val))將訓練好的模型部署到實際應用中,以實現實時音頻識別和噪聲過濾。可以使用Flask等Web框架將模型集成到Web應用中,或者使用TensorFlow Serving進行高效的模型部署。在處理實時音頻流時,需確保保持低延遲,以提高用戶體驗。
在部署過程中,需考慮系統的可擴展性和可維護性,確保模型能夠適應未來的數據和需求變化。此外,定期監測模型的性能,及時進行更新和優化,以保持其在實際應用中的有效性。
from flask import Flask, request, jsonify
import numpy as npapp = Flask(__name__)@app.route('/filter', methods=['POST'])
def filter_audio():audio_data = request.files['audio']# 處理音頻數據并進行預測signal, sr = preprocess_audio(audio_data)mfcc_features = extract_mfcc(signal, sr)mfcc_features = np.expand_dims(mfcc_features, axis=0) # 為模型輸入添加批次維度filtered_audio = model.predict(mfcc_features)# 返回處理后的音頻return jsonify({'filtered_audio': filtered_audio.tolist()})if __name__ == '__main__':app.run(debug=True)最后
我是海浪學長,創作不易,歡迎點贊、關注、收藏。
畢設幫助,疑難解答,歡迎打擾!






)


)









| 從技術架構到團隊組織)