一、TL;DR
- 為什么要做:傳統的referring分割無法使用音頻模態,本文提出Reference audio-visual Segmentation
- 本文怎么做:構建首個 Ref-AVS 基準數據集+通過充分利用多模態提示,將音頻信息通過和文本融合作為載體,在時序上提供精準的分割
- 什么結果:在三個測試子集上進行定量與定性實驗,證明結果有效
paper:https://www.ecva.net/papers/eccv_2024/papers_ECCV/papers/09443.pdf
code:https://github.com/GeWu-Lab/Ref-AVS
二、方法介紹
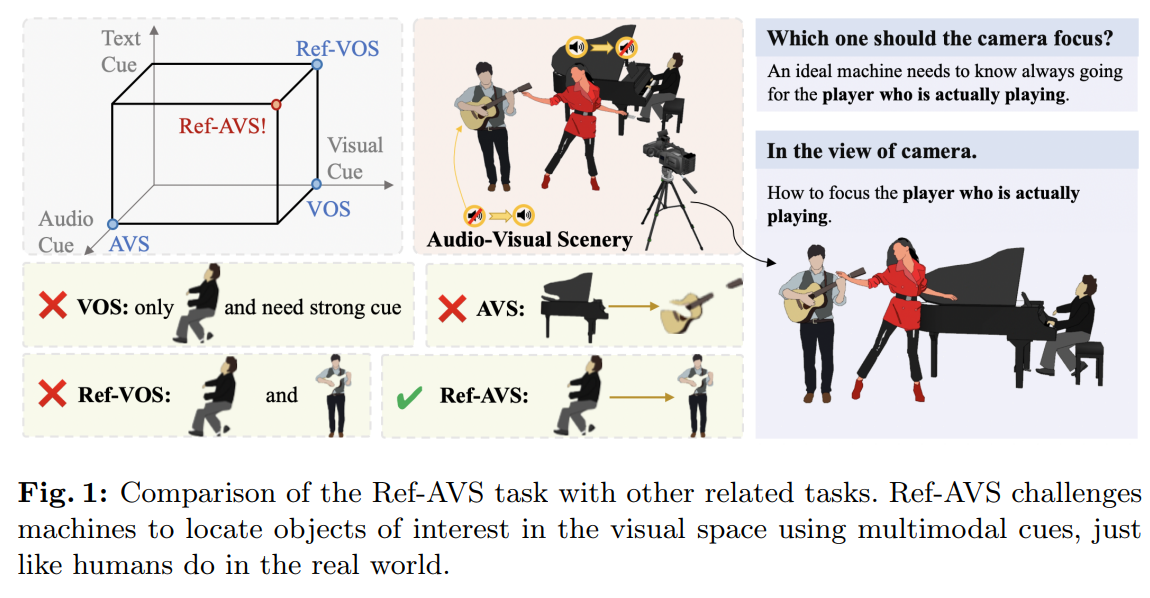
當前對指代分割(reference segmentation)的探索仍局限于較窄的場景。如圖 1 的坐標系所示,當前針對不同模態的分割方法主要有三大研究方向:
-
基于視覺提示的方向:視頻對象分割(Video Object Segmentation, VOS)以 “帶標注的第一幀掩碼” 為參考,引導后續視頻幀中特定對象的分割。嚴重依賴 “第一幀的精準標注”導致在實際應用中既困難又耗時。
-
基于文本提示的方向:指代視頻對象分割(Referring Video Object Segmentation, R-VOS)以 “屬性描述語句” 為引導,探索分割能力。R-VOS 成功用自然語言替代了 VOS 中的掩碼標注,提供了更易獲取、更用戶友好的參考形式,在 “更自然的動態音視頻場景” 中定位對象的能力仍有限。
-
基于音頻提示的方向:音視頻分割(Audio-Visual Segmentation, AVS)以音頻為引導,分割 “發出聲音的對象”。該方法有效解決了 “動態音視頻場景中對象定位” 的難題,但存在局限:無法聚焦于 “不發聲的普通對象”,也難以有效定位 “特定感興趣的對象”。
motivation:
- 現有研究尚無法讓機器在 “自然動態音視頻場景” 中定位感興趣對象。
- 例如,如圖 1 所示,機器如何長期精準定位 “真正在演奏樂器的人”?這需要機器推斷 “哪件樂器在發聲” 以及 “誰在演奏這件樂器”。
- 提出一項 “探索自然動態音視頻場景中感興趣對象定位可能性” 的任務具備實際應用價值
怎么做:
提出像素級分割任務-指代音視頻分割(Ref-AVS):
- 要求網絡密集預測 “每個像素是否對應給定的多模態提示描述語句”(該語句包含動態音視頻信息)。
- 圖 1 左上角清晰展示了 Ref-AVS 與現有任務的區別:它要求網絡在 “更復雜、更立體的模態空間” 中精準定位并分割對象。
- 因此需要一個具備 “全面多模態理解能力” 的計算模型。
數據集:
本文引入Ref-AVS 基準測試集(Ref-AVS Bench):
- ?首個 “基于指代多模態提示描述語句定位并分割感興趣對象” 的基準。
- 考慮到現實音視頻場景的復雜性,從 YouTube 收集了約 4000 個含音頻的視頻片段(其中 60% 以上為 “多源聲音場景”),并由專家收集、驗證了超過 20000 條指代描述語句 —— 這些語句通過多模態提示,描述不同動態音視頻場景中的對象。
- 為評估模型在 “零樣本場景需求增長” 下的泛化能力,本文設計了一個 “未見過的測試集(unseen test set)”。
貢獻總結如下:
- 提出 Ref-AVS 這一具有挑戰性的場景理解任務 —— 基于多模態提示描述語句分割感興趣對象,并提供相應的 Ref-AVS 基準測試集,用于模型的訓練與性能驗證;
- 為 Ref-AVS 設計端到端框架 —— 通過跨模態 Transformer 高效處理多模態提示,為未來研究提供可行的基礎框架;
- 開展大量實驗,驗證 “在視覺分割中考慮多模態提示” 的優勢,同時證明本文方法在所有測試子集上的性能優越性。
三、核心框架-Ref-AVS 數據集
3.1 對象類別
為確保被指代對象的多樣性,精心篩選了涵蓋48 類可發聲對象與3 類靜態無聲音對象的豐富類別體系。其中,可發聲對象具體分類如下:
- 樂器類:20 個類別;
- 動物類:8 個類別;
- 機械類:15 個類別;
- 人類類:5 個類別。
針對人類這一特殊類別,考慮到其外貌、聲音與動作的多樣性,我們采用 “形態學分類思路”,基于年齡與性別將人類劃分為 5 個細分類別。
3.2 視頻篩選
在視頻收集過程中,采用文獻 [3, 46] 提出的技術(回頭仔細看下),確保音視頻片段與目標語義的一致性。每段視頻均被剪輯為 10 秒時長。在人工收集階段,刻意排除以下幾類視頻(詳見附錄):
- 含大量相同語義實例的視頻;
- 經大量剪輯、頻繁切換鏡頭的視頻;
- 含合成特效的非真實場景視頻。
為更貼近現實場景分布,重點篩選 “能豐富數據集場景多樣性” 的視頻:
- ?尤其優先選擇 “包含多對象交互” 的視頻(如樂器、人類、交通工具等對象間的互動場景)。
除多樣性外,我們還通過篩選確保數據集包含 “更高復雜度、更多對象數量” 的場景:
- 具體而言,56% 的視頻包含 2 個及以上對象,13% 的視頻包含 3 個及以上對象。
3.3 描述語句
描述語句的多樣性是 Ref-AVS 數據集構建的核心要素之一。每條描述語句融合音頻、視覺、時間三個維度的信息:
- 音頻維度:包含音量、節奏等特征;
- 視覺維度:涵蓋對象的外觀、空間布局等屬性;
- 時間維度:融入時序提示(如 “先發聲的那個”“后出現的那個”)。
通過整合音、視、時三維信息,我們構建了豐富的描述語句庫 —— 既準確反映多模態場景,又能滿足用戶 “精準指代” 的特定需求。圖 2 展示了不同模態組合的描述語句示例。
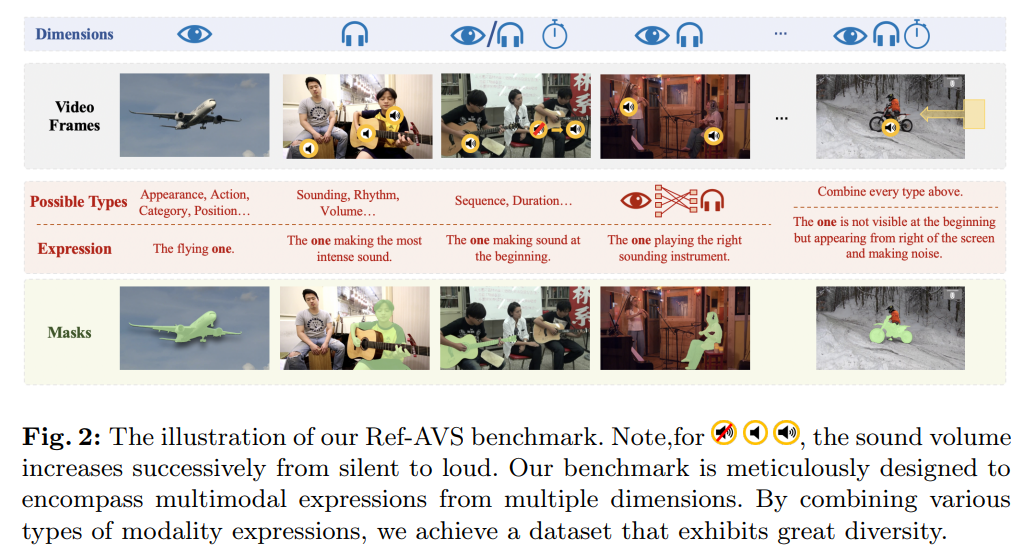
描述語句的準確性同樣是核心關注點。我們遵循三條規則生成高質量描述語句:
- 唯一性:一條描述語句僅能指代一個對象,不可同時對應多個對象;
- 必要性:可使用復雜語句進行指代,但句中每個形容詞需能 “縮小目標對象范圍”,避免冗余、不必要的對象描述;
- 清晰性:部分描述模板涉及主觀因素(如 “聲音更大的那個”),僅當場景足夠明確、無歧義時,才可使用此類語句。
除多樣性與準確性外,我們還根據 “描述語句包含的提示數量” 對其難度進行分級:簡單(easy)、中等(medium)、困難(hard)樣本在數據集中的占比分別為 20%、60%、20%。這種難度分級可為 “課程學習(curriculum learning)” 等未來研究提供支持,詳見補充材料。
3.4 分割掩碼
我們將每段 10 秒視頻均分為 10 個 1 秒片段,標注目標是獲取每個片段 “首幀的掩碼”。對于這些采樣幀,真值標簽為 “基于描述語句與多模態信息生成的二值掩碼”,用于標識目標對象。
掩碼生成流程如下:
- 關鍵幀手動篩選:為每段 10 秒視頻手動選擇 “目標對象清晰可見” 的關鍵幀(關鍵幀可位于視頻開頭、中間或結尾,取決于目標對象的最佳可見時刻);
- 自動分割與人工校驗:利用 Grounding SAM 對關鍵幀進行分割與標注,隨后通過人工檢查與修正,生成關鍵幀中多個目標對象的掩碼與標簽;
- 跨幀跟蹤補全:基于關鍵幀掩碼,采用跟蹤算法對前后幀中的目標對象進行跟蹤,最終得到 10 幀序列中目標對象的完整掩碼與標簽。
3.5 數據集統計
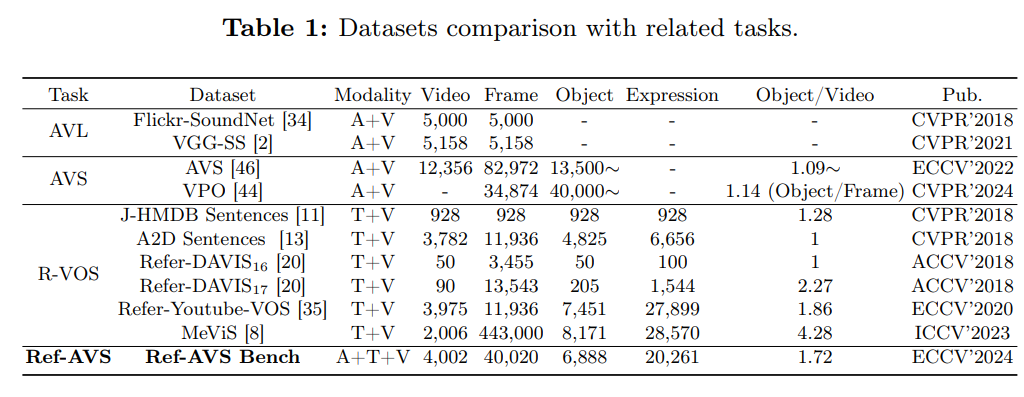
表 1 將 Ref-AVS 與其他主流音視頻基準數據集進行對比,關鍵差異如下:
- 標注精度與數量:Flickr-SoundNet 與 VGG-SS僅提供 “(patch-level)邊界框標注”,幀級標注量約 5000 個;而 Ref-AVS 提供像素級標注,標注數量顯著更高;
- 場景復雜度:與 AVS 數據集相比,Ref-AVS視頻的 “平均對象數量” 更高(約 1.72 個 / 視頻),意味著包含更多 “多聲源、多語義” 的復雜場景 —— 此類場景中,Ref-AVS 基準的價值尤為突出,因其能有效聚焦 “真正感興趣的對象”;此外,Ref-AVS 的視頻時長更統一,篩選流程更精細;
- 數據規模:相較于 R-VOS 任務的現有數據集 [8, 11, 13, 20, 35],Ref-AVS 在視頻數量上保持優勢,且包含更海量的 “對象、描述語句與復雜場景” 數據。
總體而言,Ref-AVS 數據集包含4000 段視頻、20000 條描述語句與像素級標注,總時長超 11 小時。
3.6 數據集劃分
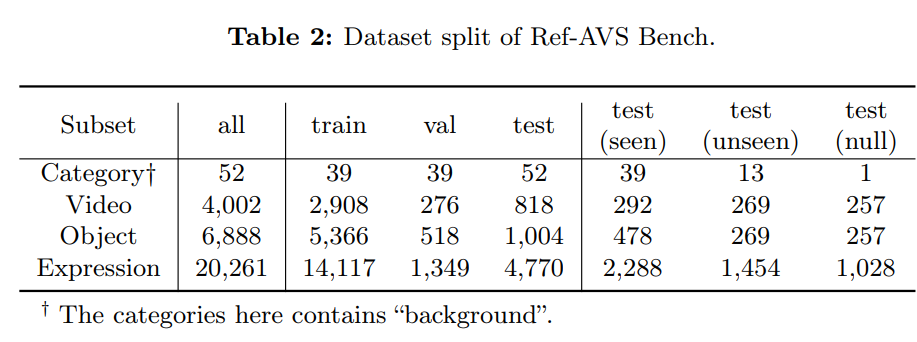
如表 2 所示,完整數據集分為三部分:訓練集(2908 段視頻)、驗證集(276 段視頻)、測試集(818 段視頻)。其中,測試集的視頻及其對應標注均經過資深標注人員的 “細致審核與重新標注”。
為全面評估模型在 Ref-AVS 任務上的性能,測試集進一步劃分為三個功能不同的子集:
已見子集(Seen)
“已見子集” 包含的對象類別均在訓練集中出現過,用于評估模型的 “基礎性能” 與 “對熟悉類別對象的泛化能力”。
未見子集(Unseen)
說人話:做開集分割的
為應對 “開放世界場景下模型泛化能力” 的需求增長,專門構建 “未見子集” 以評估模型對 “未見過的音視頻場景” 的適應能力。該子集的對象類別未在訓練集中出現,但它們的 “超類別(如動物、交通工具)” 可能在訓練集中存在 —— 旨在測試模型 “利用超類別知識,對新對象類別進行泛化” 的能力。
空指代子集(Null)
“空指代問題” 指 “描述語句所指代的對象在當前場景中不存在或不可見”。若模型能準確理解描述語句的引導,在空指代場景中不應分割任何對象 。基于此,我們設計 “空指代子集” 以測試模型的魯棒性:該子集的對象類別雖在訓練集中出現,但描述語句與場景完全不匹配 —— 視頻幀中的所有對象均與指代內容無關,因此真值掩碼為空,模型需避免分割任何對象。
4 基于多模態提示的描述語句增強
Expression Enhancing with Multimodal Cues:
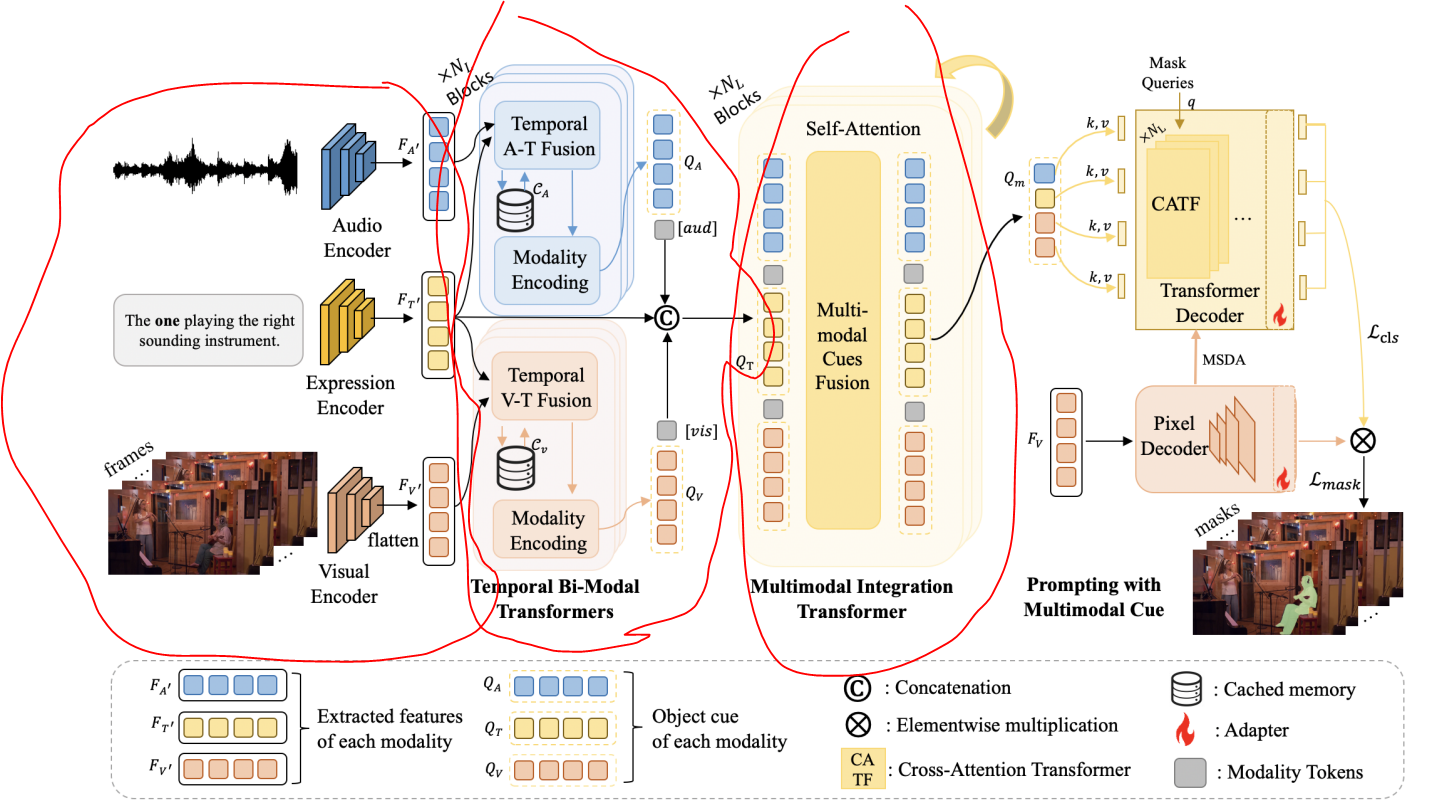
4.1 整體架構
Ref-AVS的目標:
- “利用多模態提示,在動態音視頻場景中定位感興趣對象”。
方法:
- 提出基于多模態提示的描述語句增強(EEMC)方法
- 核心思路是將 “動態音視頻場景中的多模態信息” 融入 “含對應多模態提示的指代描述語句”,形成全面的多模態指代特征;
- 同時,通過注意力機制將 “多模態指代提示” 作為 “視覺基礎模型的提示信號”,輔助完成最終的分割過程。
4.2 多模態表征
4.2.1 音頻表示(Audio)
- 與視頻處理方式類似,將音頻輸入按 1 秒間隔切分為片段。
- 音頻表征F_A通過 VGGish 模型 編碼得到(t為音頻時長,單位為秒,且與視頻幀數一致)。
- 音頻表征通過離線方式提取,音頻編碼器不進行微調。
4.2.2?視覺表示(Visual)
- 從視頻輸入中按 1 秒間隔采樣t幀,利用預訓練的 Swin-base 模型提取視覺F_V。
- 視覺編碼器不進行微調。
4.2.3 描述語句表示(Expression)
- 采用 RoBERTa 模型作為文本編碼器,提取描述語句特征F_T。
- caption表征直接采用預訓練模型的離線提取結果,不進行微調。
4.3 時序雙模態 Transformer
4.3.1 時序A-T與V-T融合
該模塊用于提取 “與caption語句相關的各模態信息”。首先,為便于后續多模態融合,我們對各模態特征進行預處理:


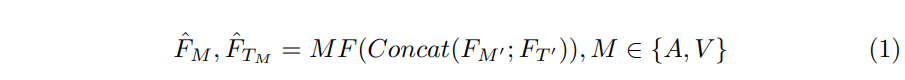
4.3.2 緩存記憶-Cached Memory
說人話:緩存歷史時序上的特征均值作為時序信息

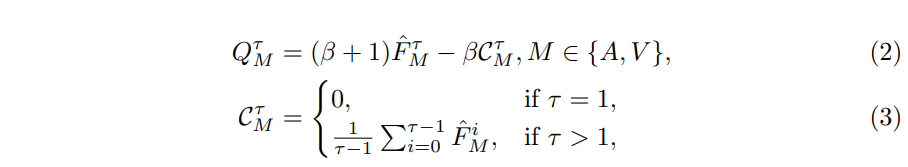

4.3.3 模態編碼-Modality Encoding
說人話:將不同模態引入標識token進行區分,然后自注意力得到新的token

4.4 基于多模態提示的引導(Prompting with Multimodal Cues)
說人話:從圖上來看,使用全模態Qm+input-mask的query得到qQ新特征,再結合當前幀的視覺特征,就得到了新的mask輸出

五、Experiments
5.1 實現細節
本文采用 Mask2Former作為視覺基礎模型,提供常用的 “基于 Transformer 的分割解碼器”。默認設置如下:
- 輸入視頻幀均縮放至 384×384 分辨率;
- 視覺特征維度為 [H=64, W=64, d_V=256],為降低計算成本,采用 8 倍下采樣;
- 音頻特征從單聲道波形中提取,維度 d_A=128;
- 文本特征維度為 [L=25, d_T=768](L 為描述語句長度);
- 為統一處理,將所有模態的特征維度均映射至 d_V;
- 超參數 β 默認設為 1;
- “時序雙模態 Transformer”“多模態整合 Transformer” 與 “交叉注意力 Transformer(CATF)” 的 Transformer 層數(N_L)默認均設為 4;
- 掩碼查詢數量(N_q)固定為 100。
5.2 評價指標
為全面評估 Ref-AVS 方法的性能,采用以下指標:
- 交并比(Jaccard Index, J)與F 分數(F-score, F):作為核心性能指標,用于衡量分割結果與真值的匹配度;
- 空指代指標(S):僅用于 “空指代測試集”,評估模型對描述語句引導的遵循能力。S 的計算方式為 “預測掩碼面積與背景面積比值的平方根”——S 值越高,表明預測掩碼占背景的比例越大,意味著模型對描述語句的精準引導能力越弱。
5.3 定量結果
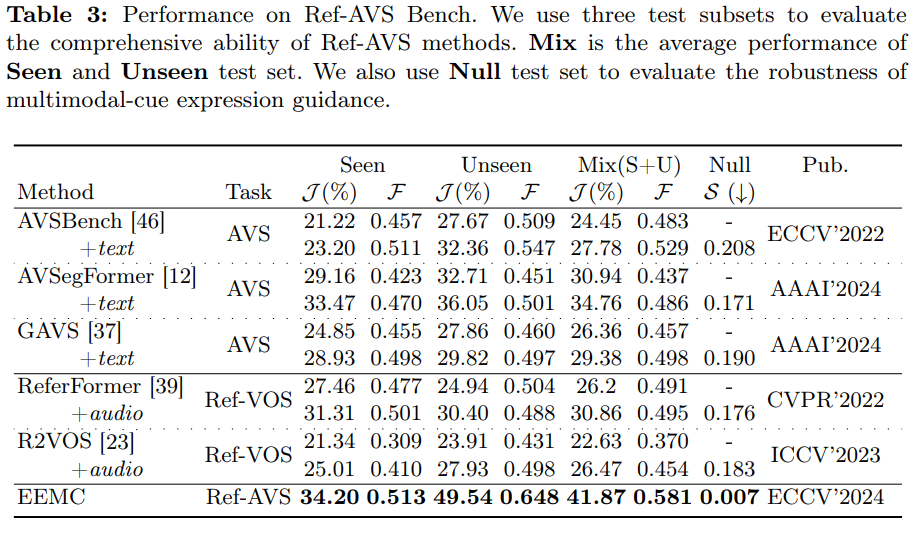
在 Ref-AVS 基準上,我們將本文方法與相關領域的現有方法進行對比,關鍵結果如下:
-
已見測試集(Seen):本文方法表現顯著優于其他方法。簡單的模態融合不足以解決 Ref-AVS 任務中 “多模態提示理解” 的難題;而本文方法未直接融合音視頻信息,而是選擇 “文本表示” 作為多模態信息的載體 —— 因其包含與 “當前音視頻環境” 相關的豐富語義與提示,故能更有效利用多模態信息。
-
未見測試集(Unseen)與空指代測試集(Null):為驗證模型的泛化能力與 “多模態提示遵循能力”,我們在這兩個子集上進行測試:
- Unseen測試集:本文方法仍保持領先 —— 原因在于我們以 “具有高度抽象語義能力的文本” 作為多模態信息載體,而非直接融合音視頻信息,因此生成的多模態提示能提供更穩健的語義引導;
- Null測試集:本文方法在所有方法中表現最優,表明模型能較精準地感知多模態提示,避免在 “無目標對象” 場景中錯誤分割。
5.4 定性結果
我們在 Ref-AVS 基準的測試集上可視化分割掩碼,并與 AVSegFormer(AVS 任務方法)、ReferFormer(R-VOS 任務方法)進行對比(如圖 4 所示)。從定性結果可觀察到:

- AVSegFormer 與 ReferFormer 均無法精準分割 “描述語句所指向的對象”:
- AVSegFormer:難以完全理解描述語句,傾向于直接分割 “聲源對象”。例如左下角樣本中,該方法錯誤分割吸塵器,而非描述語句指向的 “男孩”;
- ReferFormer:無法充分理解音視頻場景,易出現語義誤判。例如右上角樣本中,該方法誤將 “學步兒童” 識別為 “鋼琴演奏者”;
- 本文 Ref-AVS 方法:具備 “同時處理多模態描述語句與場景” 的優勢,能準確解讀用戶指令,分割出目標對象。
5.5 消融實驗
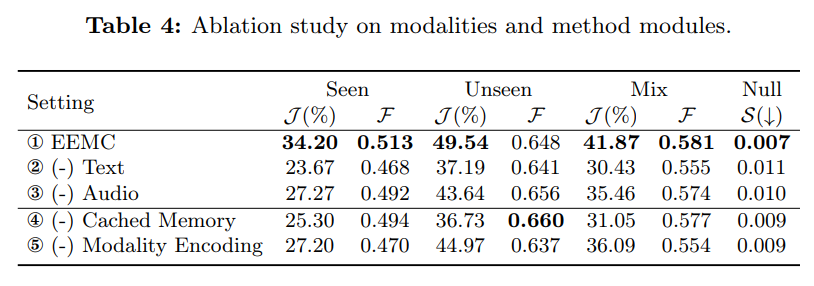
為驗證 “音頻、文本雙模態信息” 對 Ref-AVS 任務的影響,以及本文方法各模塊的有效性,我們開展消融實驗,結果如表 4 所示:
5.5.1 雙模態信息的影響
- 移除文本信息(設置②):J 值下降 11.44%,F 值下降 2.60%,性能降幅顯著;
- 移除音頻信息(設置③):J 值下降 6.41%,F 值下降 0.70%,降幅遠小于移除文本的情況。
這一現象的核心原因是:文本信息作為 “指代源” 具有清晰性與直接性;而僅依賴音頻信息時,模型易忽略 “指代內容”,轉而聚焦于 “視覺上與發聲行為相關的對象”,導致分割偏差。
5.1.2 各模塊的有效性
- 緩存記憶(Cached Memory):用于捕捉時序域內的顯著變化;
- 模態編碼(Modality Encoding):用于從多模態提示中提取 “更獨特、更全面的特征”,增強模態感知能力。
表 4 中 “設置④(移除緩存記憶)” 與 “設置⑤(移除模態編碼)” 的結果表明,這兩個模塊的移除會導致性能下降,驗證了它們對模型性能的提升作用。

![[計算機畢業設計]基于深度學習的噪聲過濾音頻優化系統研究](http://pic.xiahunao.cn/[計算機畢業設計]基于深度學習的噪聲過濾音頻優化系統研究)






)


)







