1、介紹
微服務架構是一種架構模式,它提倡將原本獨立的單體應用,拆分成多個小型服務。
這些小型服務各 自獨立運行,服務與服務間的通信采用輕量級通信機制(一般基于HTTP協議的RESTful API) ,達到互相協調、互相配合的目的。
被拆分后的服務都圍繞著具體的業務進行構建,每個服務都能獨立地進 行開發、部署、擴展。
由于相互獨立且采用輕量級通信機制,因此各個小型服務能夠使用不同的語言開發,也可以使用不同的數據存儲技術
2、對比SpringBoot
Spring Boot是用于構建單個Spring應用的框架,而Spring Cloud則是用于構建分布式系統中的微服務架構的工具,Spring Cloud提供了服務注冊與發現、負載均衡、斷路器、網關等功能。
3、初始架構:單機架構
在淘寶網站最初時,應用數量與用戶數都較少,可以把Tomcat和數據庫部署在同一臺服務器上。 瀏覽器往www.taobao.com發起請求時,首先經過DNS服務器(域名系統)把域名轉換為實際IP地址 10.102.4.1,瀏覽器轉而訪問該IP對應的Tomcat。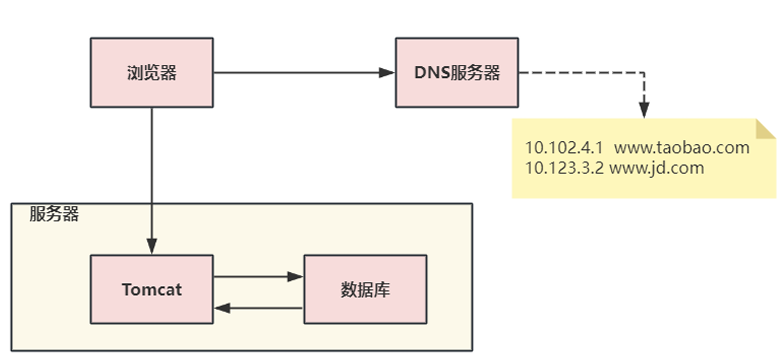
新的技術挑戰: 隨著用戶數的增長,Tomcat和數據庫之間競爭資源,單機性能不足以支撐業務,架構演 進勢在必行。
4、演進
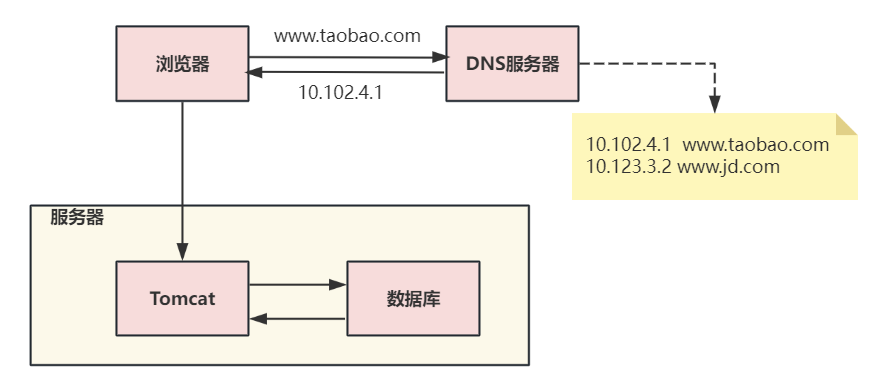
第一次演進:Tomcat與數據庫分開部署
將 Tomcat 和數據庫分別獨占服務器資源,顯著提高兩者各自性能
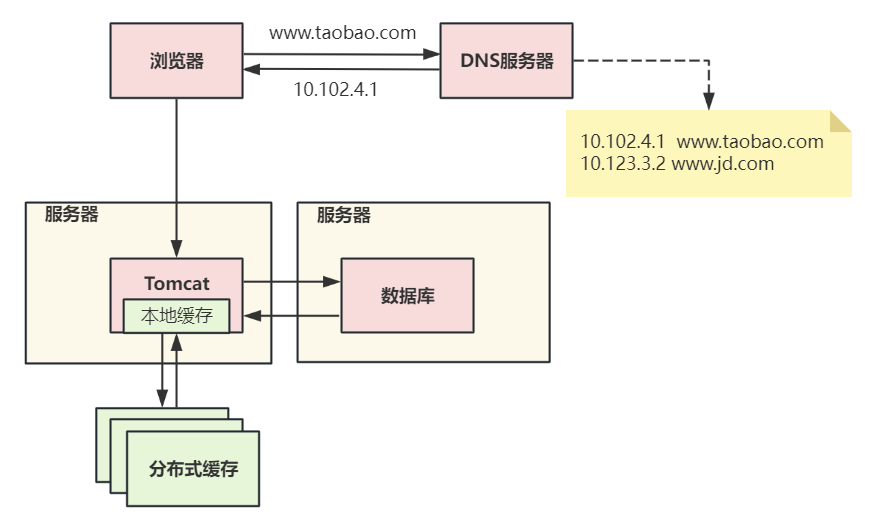
?第二次演進:引入本地緩存和分布式緩存
第二次架構演進引入了緩存,在Tomcat服務器上增加本地緩存,并在外部增加分布式緩存,緩存熱門商品信息或熱門商品的html頁面等。
通過緩存能把絕大多數請求在讀寫數據庫前攔截掉,大大降低數據庫壓力。其中涉及的技術包括:使用memcached作為本地緩存,使用Redis作為分布式緩存,還會涉及緩存一致性、緩存穿透/擊穿、緩存雪崩、熱點數據集中失效等問題。
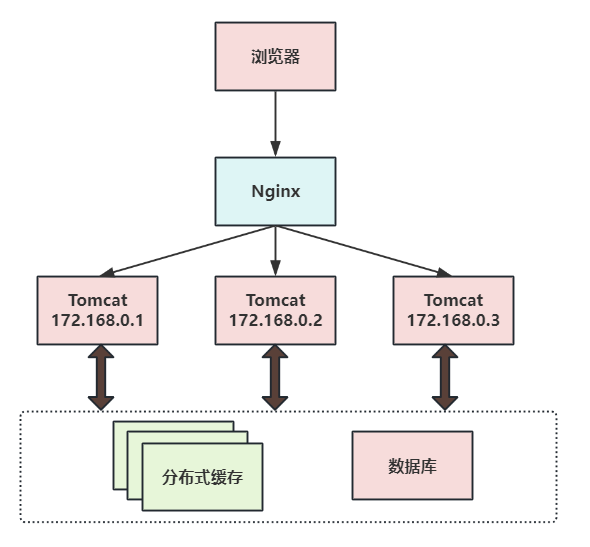
第三次演進:引入反向代理實現負載均衡?
在多臺服務器上分別部署Tomcat,使用反向代理軟件(Nginx)把請求均勻分發到每個Tomcat中。此處假設Tomcat最多支持100個并發,Nginx最多支持50000個并發,那么理論上Nginx把請求分發到500個Tomcat上,就能抗住50000個并發。
在多臺服務器上分別部署Tomcat,使用反向代理軟件(Nginx)把請求均勻分發到每個Tomcat中。此處假設Tomcat最多支持100個并發,Nginx最多支持50000個并發,那么理論上Nginx把請求分發到500個Tomcat上,就能抗住50000個并發。
第四次演進:數據庫讀寫分離
把數據庫劃分為讀庫和寫庫,讀庫可以有多個,通過同步機制把寫庫的數據同步到讀庫。對于需要查詢最新寫入數據場景,可通過在緩存中多寫一份,通過緩存獲得最新數據。
其中涉及的技術包括:Mycat,它是數據庫中間件,可通過它來組織數據庫的分離讀寫和分庫分表,客戶端通過它來訪問下層數據庫,還會涉及數據同步,數據一致性的問題。
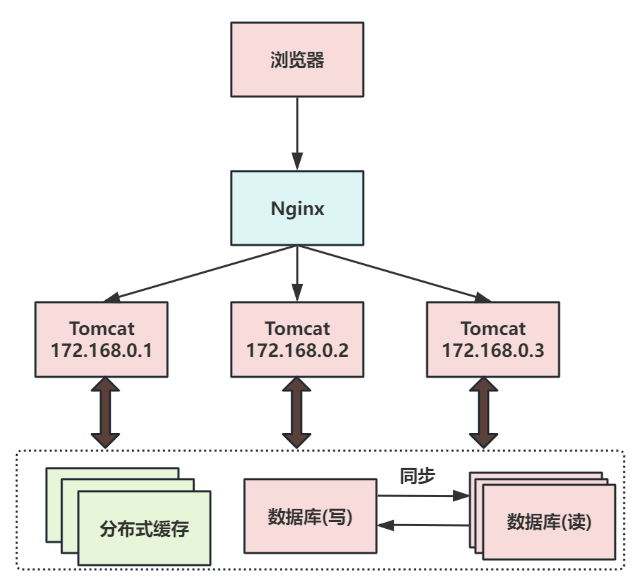
第五次演進:數據庫按業務分庫
數據庫按業務分庫,把不同業務的數據保存到不同的數據庫中,使業務之間的資源競爭降低,對于訪問量大的業務,可以部署更多的服務器來支撐。
這樣同時會導致跨業務的表無法直接做關聯分析,需要通過其他途徑來解決。
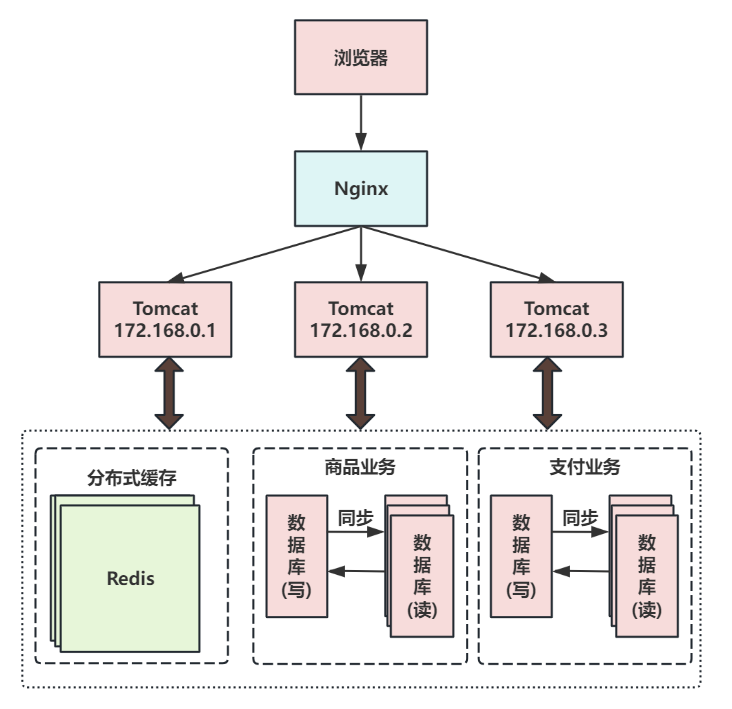
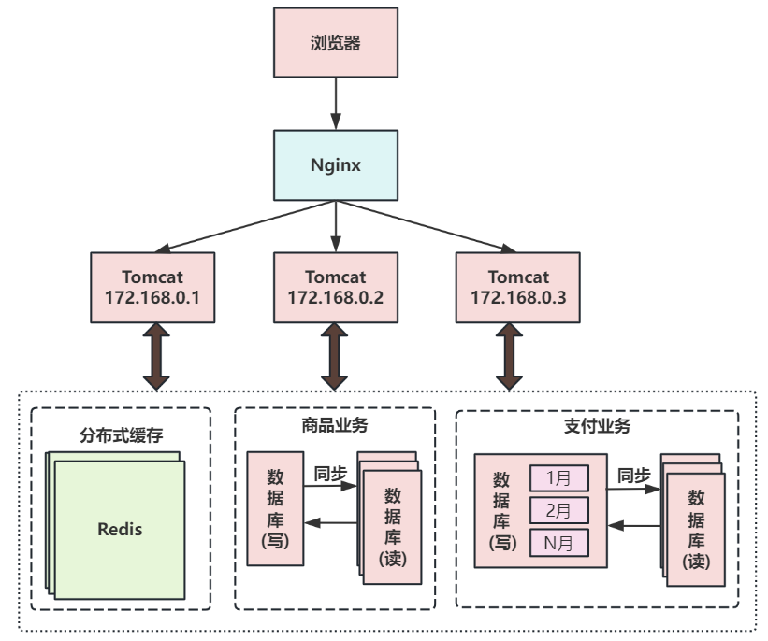
第六次演進:把大表拆分為小表?
比如針對評論數據,可按照商品ID進行hash,路由到對應的表中存儲。
針對支付記錄,可按照小時創建表,每個小時表繼續拆分為小表,使用用戶ID或記錄編號來路由數據。
只要實時操作的表數據量足夠小,請求能夠足夠均勻的分發到多臺服務器上的小表,那數據庫就能通過水平擴展的方式來提高性能。其中前面提到的Mycat也支持在大表拆分為小表情況下的訪問控制。
這種做法顯著的增加了數據庫運維的難度,對DBA的要求較高。數據庫設計到這種結構時,已經可以稱為分布式數據庫。
第七次演進:使用LVS或F5來使多個Nginx負載均衡?
由于瓶頸在Nginx,因此無法通過兩層的Nginx來實現多個Nginx的負載均衡。LVS和F5是工作在網絡第四層的負載均衡解決方案,其中LVS是軟件,運行在操作系統內核態,可對TCP請求或更高層級的網絡協議進行轉發,因此支持的協議更豐富,并且性能也遠高于Nginx,可假設單機的LVS可支持幾十萬個并發的請求轉發。
F5是一種負載均衡硬件,與LVS提供的能力類似,性能比LVS更高,但價格昂貴。
由于LVS是單機版的軟件,若LVS所在服務器宕機則會導致整個后端系統都無法訪問,因此需要有備用節點。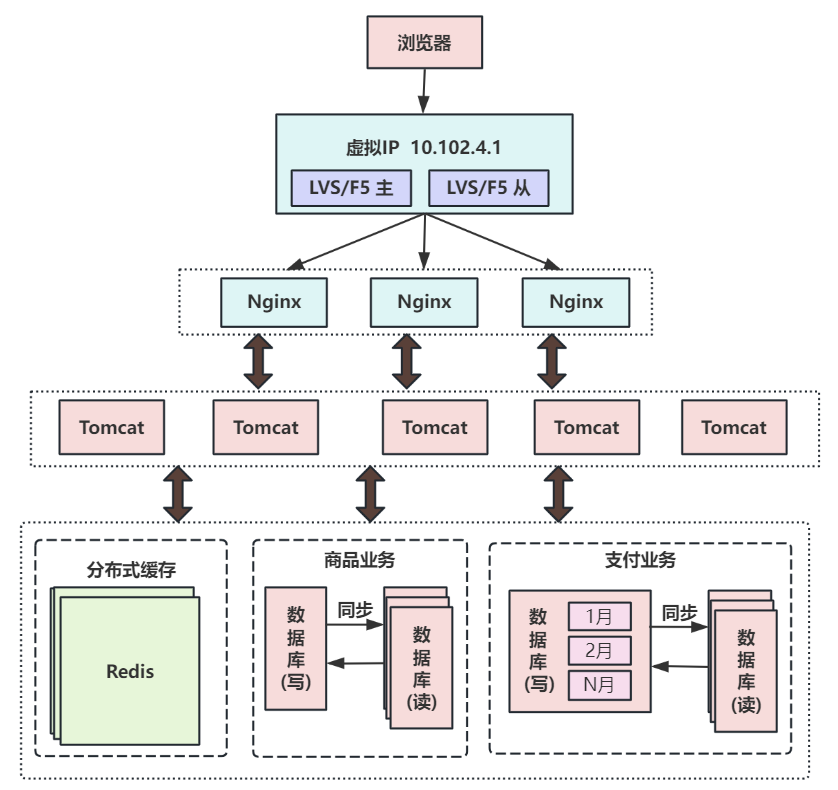
第八次演進:通過DNS輪詢實現機房間的負載均衡?
在DNS服務器中可配置一個域名對應多個IP地址,每個IP地址對應到不同的機房里的虛擬IP。
當用戶訪問www.taobao.com時,DNS服務器會使用輪詢策略或其他策略,來選擇某個IP供用戶訪問。此方式能實現機房間的負載均衡
至此,系統可做到機房級別的水平擴展,千萬級到億級的并發量都可通過增加機房來解決,系統入口處的請求并發量不再是問題。
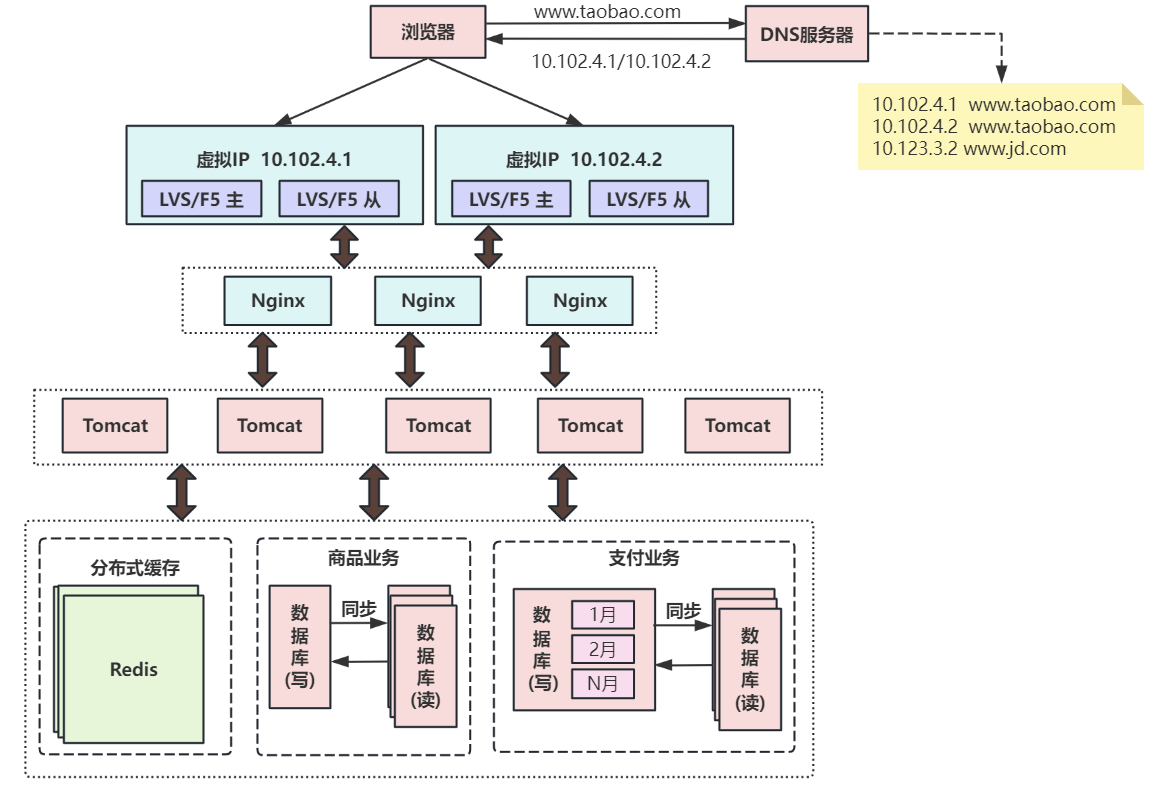
第九次演進:引入NoSQL數據庫和搜索引擎等技術?
當數據庫中的數據多到一定規模時,數據庫就不適用于復雜的查詢了,往往只能滿足普通查詢的場景。
對于統計報表場景,在數據量大時不一定能跑出結果,而且在跑復雜查詢時會導致其他查詢變慢。
對于全文檢索、可變數據結構等場景,數據庫天生不適用。因此需要針對特定的場景,引入合適的解決方案。
如對于海量文件存儲,可通過分布式文件系統HDFS解決,對于key value類型的數據,可通過Redis解決,對于全文檢索場景,可通過搜索引擎如ElasticSearch解決,對于多維分析場景,可通過Kylin或Druid等方案解決。
當然,引入更多組件同時會提高系統的復雜度,不同的組件保存的數據需要同步,需要考慮一致性的問題,需要有更多的運維手段來管理這些組件等。
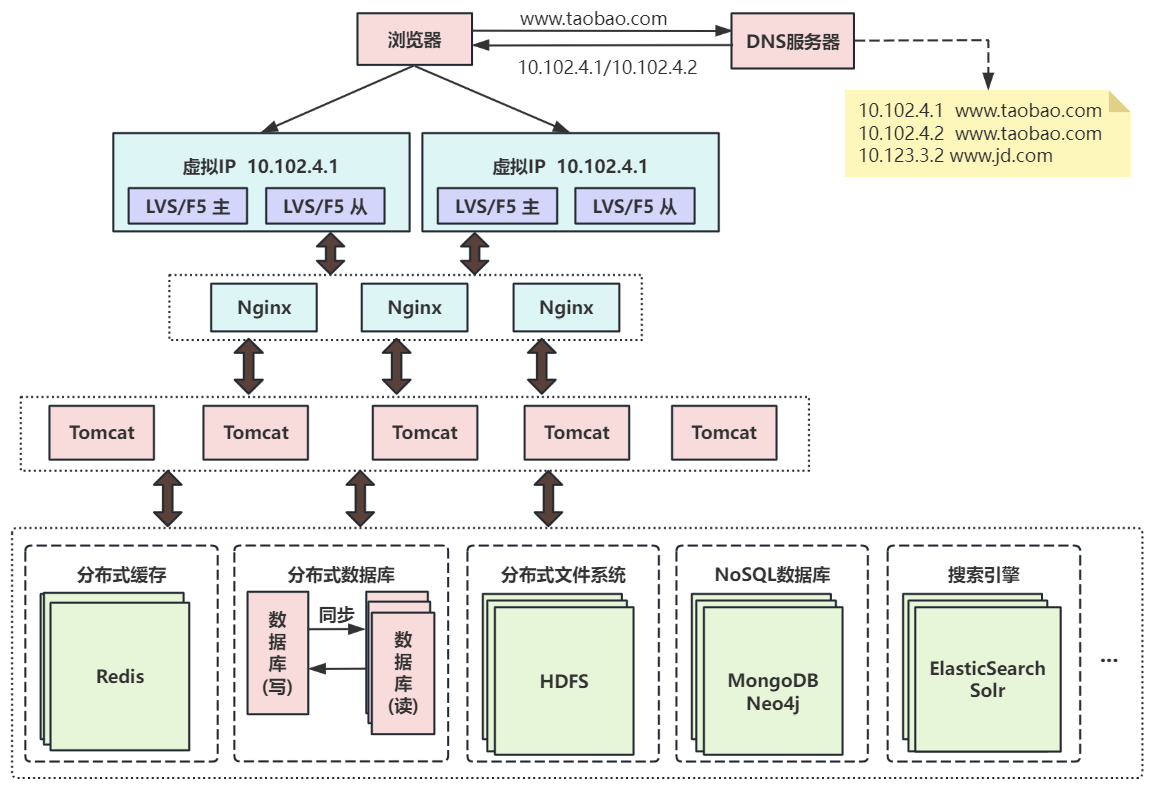
第十次演進:大應用拆分為小應用?
為了應對日益復雜的業務場景,通過使用分而治之的手段將整個網站業務拆分成不同的產品線,通過分布式服務來協同工作。
按照業務板塊來劃分應用代碼,使單個應用的職責更清晰,相互之間可以做到獨立升級迭代。這時候應用之間可能會涉及到一些公共配置,可以通過分布式配置中心Zookeeper來解決。
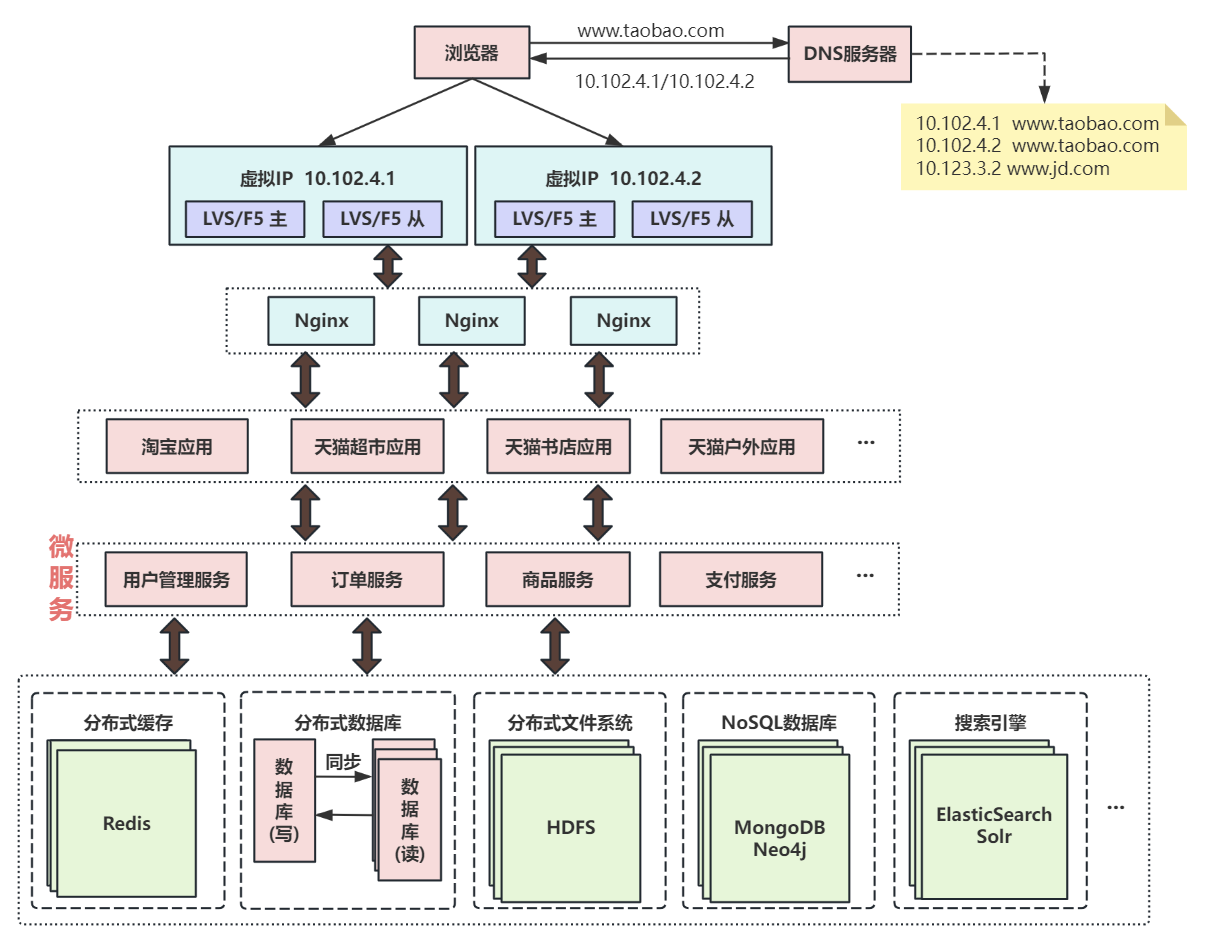
第十一次演進:復用的功能抽離成微服務
如用戶管理、訂單、支付、鑒權等功能在多個應用中都存在,那么可以把這些功能的代碼單獨抽取出來形成一個單獨的服務來管理,這樣的服務就是所謂的微服務。應用通過HTTP、TCP或RPC請求等多種方式來訪問服務,每個單獨的服務都可以由單獨的團隊來管理。
此外,可以通過Dubbo、SpringCloud等框架實現服務治理、限流、熔斷、降級等功能,提高服務的穩定性和可用性。
5、微服務架構的優缺點?
1、優點
更易于開發和維護
快速迭代+靈活
系統的伸縮性增強
技術選型靈活
錯誤隔離
2、缺點
落地一個微服務架構項目比較復雜
服務依賴和調用鏈路更復雜
微服務架構中的單個微服務,不可避免地會出現依賴性及由此導致的問題。比如,H服務依賴S服務,S服務依賴A服務,如果A服務在線上出現問題或A服務需要修改部分邏輯,那么S服務和H服務也可能受到牽連,或者級聯修改。雖然已經做了服務拆分,影響范圍不大,但是這些問題還是存在的。
數據一致性問題
問題排查的鏈路加長
學習成本高





)










)


