前言
因為項目需要(比如我們在做的兩個展廳講解訂單),近期我一直在研究VLN相關,有些工作哪怕暫時還沒開源(將來可能會開源),但也依然會解讀,比如好處之一是構建完整的VLN知識體系,本文便是其中一例
我在解讀過程中,會以最自然的理解順序去介紹每一個模塊,且每一個模塊具體的指向都盡可能直截了當的指出來
比如論文中的指令器instruction object extractor(簡稱IOE),便是下圖圖中LLM模塊下面Extractor所示的模塊。這點 其實不難,但如果我直接點明,大家理解的速度會因此翻倍
更何況,無論是讀paper、摳代碼,還是做科研復現、客戶訂單,都是不斷增強我們自信、底氣、實力的方式,具身層面,但凡?別人能做的 我們也能做到——只要客戶有需求,當然 需求不能是那種神仙來了 也沒轍的
PS,如想做、在做、曾做該方向的,歡迎私我一兩句簡介,邀你進NaVILA為代表的「七月具身: 人形導航VLN交流群」
第一部分?LOVON
1.1 引言、相關工作、問題表述
1.1.1 引言
足式機器人經過數十年的發展,如今在復雜地形中展現出了卓越的機動性。然而,目前的大多數研究主要集中在優化單一任務,如行走、跳躍、攀爬和短距離導航,缺乏對復雜長時任務的全面考量
眾所周知,足式機器人在開放環境中執行長時任務的潛力尚未被充分挖掘,將先進的語言與視覺理解能力與足式機器人機動性相結合,是實現實際應用的關鍵突破
來自1香港科技大學(廣州)、2北京仿人機器人創新中心、3 香港科技大學的研究者:Daojie Peng1?, Jiahang Cao1,2?, Qiang Zhang1,2?, Jun Ma1,3?等人提出了LOVON『其paper《LOVON: Legged Open-Vocabulary Object Navigator》、其項目地址、其GitHub地址』
如圖1所示,其集成了

- 大語言模型(LLMs)的任務規劃能力
- 開放詞匯視覺檢測的感知能力
- 以及用于精確運動預測的語言到運動模型(L2MM)
且LOVON系統解決了諸如機器人運動引起的視覺抖動等現實世界中的挑戰
- 具體而言,作者設計了一種拉普拉斯方差濾波技術,有效減緩了機器人移動過程中出現的視覺不穩定性,從而確保了目標檢測的準確性和連續性
- 還提出了用于穩健任務完成的功能執行邏輯。在仿真基準Gym-Unreal [6]上的實驗表明,LOVON取得了優異的結果
此外,作者在多個腿式機器人平臺(Unitree Go2、B2 和 H1-2)上進行了大量實驗,成功完成了涉及實時檢測、搜索和導航至開放詞匯動態目標的長時任務
1.1.2 相關工作
第一,對于用于機器人任務規劃的大型語言模型
- 在機器人領域,LLM(大語言模型)已被越來越多地應用于高級任務規劃、指令執行和語義推理,例如
SayCan [8] 將LLM與機器人可供性模型結合,用于將語言指令映射為可執行的動作
而 Code as Policies [9] 則利用LLM直接根據自然語言描述為機器人控制器生成代碼 - 盡管取得了這些進展,但在將語言與現實世界機器人動作進行對齊 [10]–[12]、處理模糊或用戶指定的指令,以及確保在非結構化環境下的魯棒性能方面仍然存在挑戰
LOVON在這些基礎上進一步發展,通過將基于LLM的規劃與開放詞匯感知和腿式機器人移動能力集成,旨在解決以往方法在長時序、開放世界場景中的局限性
第二,對于開放詞匯視覺感知
- 開放詞匯視覺感知已經從早期的固定類別目標檢測器『如 Faster R-CNN [13] 和 YOLO [3]』有了顯著發展,這些方法僅能識別預定義類別,在開放世界場景下表現不佳
后續的研究,如Grounding DINO [14],通過引入基于語義關聯的預訓練,進一步提升了開放集檢測的準確性 - 對于機器人應用而言,實時性能以及對動態攝像機運動(例如由足式機器人行走引起的抖動或目標短暫遮擋)的魯棒性依然是關鍵挑戰 [15]。現有方法在此類場景下往往無法保持檢測的穩定性,缺乏根據機器人運動狀態或環境變化自適應的反饋機制
LOVON 針對這些不足,通過開發專門的預處理技術(如拉普拉斯方差濾波)來減輕運動模糊,確保視覺輸入的一致性,并將開放詞匯檢測與任務規劃和運動控制緊密集成,實現了在非結構化環境中的端到端執行
第三,對于足式機器人導航與長時域自主性
- 足式機器人導航已從低層次的移動發展到復雜任務,但現有方法往往側重于單一任務優化,缺乏對長時域任務中高層次規劃的整合[16]–[18]
盡管足式機器人在地形適應性方面表現優越[19],但其在非結構化環境中執行連續目標的潛力尚未得到充分挖掘,因為傳統系統通常將感知與運動規劃分離,并且在動態目標跟蹤方面存在困難 - LOVON通過將分層任務分解與實時運動控制相統一,解決了這一問題。基于LLM的規劃器能夠將長時域任務分解,而L2MM將指令和視覺反饋映射為動態運動向量
這使得機器人具備自適應行為,例如在目標丟失時切換至搜索狀態。該方法已在Unitree Go2、B2和H1-2等平臺上的多種地形中驗證。通過將開放詞匯感知與足式移動能力結合,LOVON使自主機器人能夠在復雜環境中導航,并適應動態任務
1.1.3 問題描述
- 關于任務
本任務要求機器人在任意開放世界環境中操作,需要執行長周期任務以搜索不同目標。長周期任務被定義為一組子任務
,其中每個子任務對應于搜索特定目標
該過程中的核心挑戰在于,機器人需自主搜索并識別不同的子目標(目標),并根據任務指令以不同速度導航至這些目標。這些子目標在任務過程中可能發生變化,因此要求機器人具備動態適應能力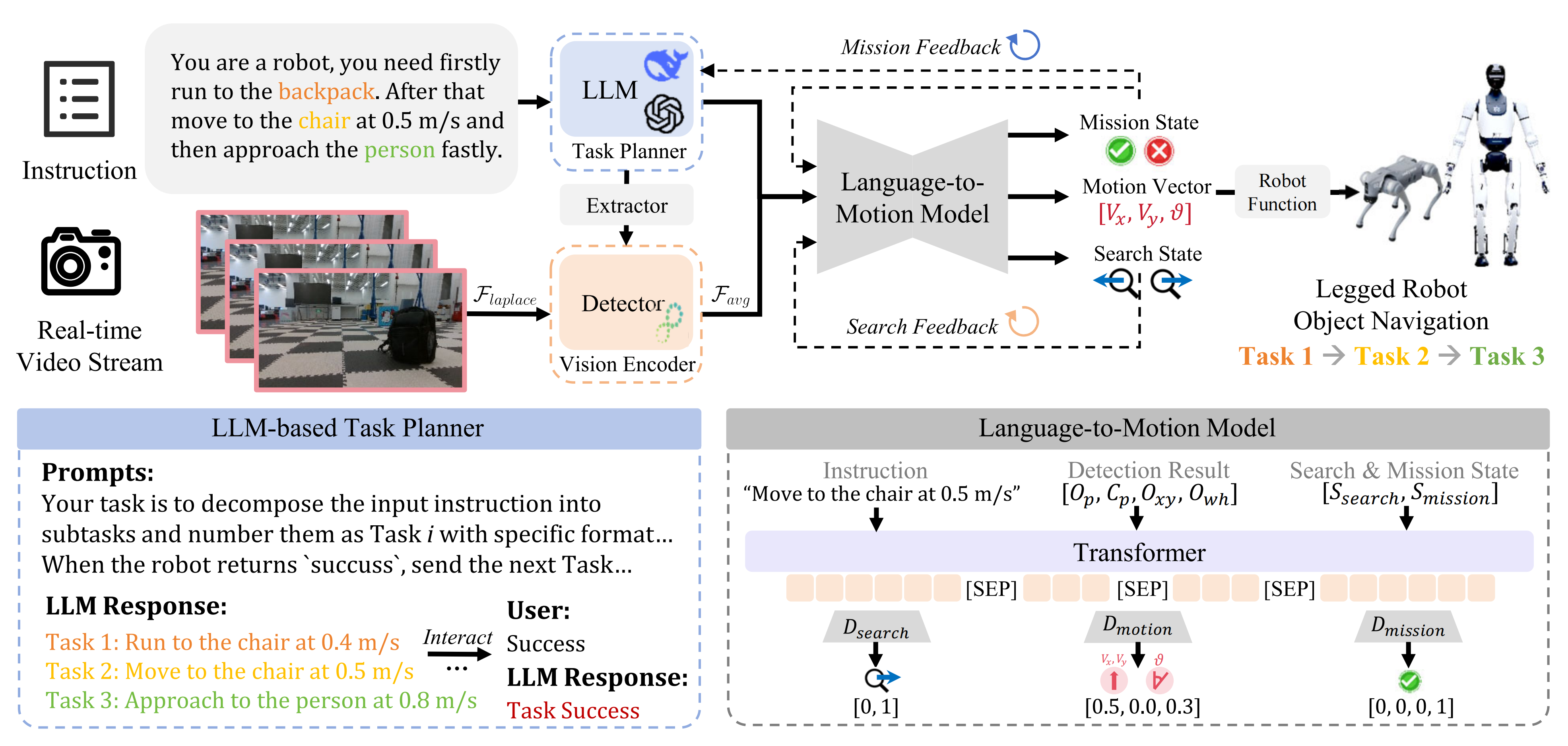
- 關于目標
作者的目標是開發一個雙系統模型:
? (I) 高層策略能夠將復雜的任務指令
分解為具體的子任務指令集
,并進行任務規劃;
和視頻流輸入
,生成運動向量
,實現精確的運動控制
該模型應能夠適應不同類型的腿式機器人,確保在現實世界應用中的多樣性和通用性
1.2?LOVON的完整方法論
LOVON 的流程如圖2所示
- 首先,大型語言模型LLM將人類的長周期任務
You are a robot, you need firstly run to the backpack. After that move to the chair at 0.5 m/s and then approach the person fastly.
重新配置為基本的任務指令,畢竟
Task 1: Run to the chair at 0.4 m/s
Task 2: Move to the chair at 0.5 m/s
Task 3: Approach to the person at 0.8 m/s - 隨后,這些指令(Task 1/Task 2/Task 3)被傳遞給指令對象提取器instruction object?Extractor(簡稱IOE)——即,這個IOE是緊跟LLM之后 處理指令的,以識別目標對象,比如:chair、person等
- 檢測模型——比如YOLO11 處理捕獲的視頻流,輸入圖像則通過拉普拉斯濾波器進行預處理
- 最后,任務指令、目標對象、邊界框、任務狀態和搜索狀態被組合后,作為輸入傳遞給所提出的L2MM,該模塊會生成機器人的控制向量以及同時用于LLM和L2MM的反饋狀態
Finally, the mission instruction, target object, bounding box,mission state, and search state are combined as inputs to theproposed L2MM, which generates the robot’s control vectorand feedback states for both the LLM and L2MM
1.2.1?多模態輸入處理
LOVON集成了兩個預訓練模型:
- 用于長時序任務管理的大型語言模型LLM(例如,[1]、[22]、[23])
- 用于視覺輸入處理的目標檢測模型(例如,[5]、[14]、[20]、[21]
首先,對于指令,先LLM處理,之后指令對象提取器Extractor?提取目標對象
- 首先,LLM的輸入包括系統描述
、用戶的長序列任務描述
的反饋
基于這些輸入,LLM生成具體的任務指令,使LOVON能夠通過生成必要的指令來完成長序列任務,從而實現任務目標
- 然后,作者提出的IOE——即提取器instruction object Extractor,將指令映射到檢測類別。IOE采用帶有感知層的兩層Transformer來預測目標類別
其中表示檢測模型能夠識別的類別集合
其次,對于視覺處理,目標檢測模型以RGB圖像,和
作為輸入,并輸出所需的檢測信息如下
作者采用歸一化格式來表示檢測結果,其中
- 預測目標記為
- 置信度得分
- 邊界框的中心位置表示為
- 邊界框的寬度和高度表示為
此外,作者對目標檢測模型輸出的邊界框應用移動平均濾波器,以進一步提升穩定性
1.2.2?基于拉普拉斯方差的運動模糊濾波
當足式機器人運動時,由于產生的波動,捕獲的圖像幀會出現運動模糊,如圖3所示

由于機器人動態行走,前幾幀尤其模糊,這給視覺模型帶來了挑戰
為了解決這一問題,作者提出了一種基于拉普拉斯方差的方法,用于檢測和過濾運動模糊幀。該預處理步驟通過減輕機器人運動和振動引起的模糊與畸變,提高了輸入到基于目標檢測的視覺-語言處理流程的魯棒性
- 具體而言,首先將RGB幀
- 隨后,應用拉普拉斯算子以增強高頻成分,得到拉普拉斯響應
- 接著,計算拉普拉斯響應的方差,以評估幀的清晰度
如果方差低于閾值,則該幀被判定為模糊幀,并用上一幀清晰幀替換。閾值
1.2.3?語言到動作模型L2MM:負責預測動作和提供反饋
簡言之,L2MM 采用編碼器-解碼器架構設計
具體而言,編碼器接收一系列輸入,包括以下組件:
- 前一個任務指令
- 當前任務指令
- 預測目標
- 預測置信度
- 中心位置
- 歸一化邊界框的寬度和高度
- 當前任務狀態
以及當前搜索狀態
這些輸入被拼接在一起,并用特殊token [SEP] 分隔,作為,編碼器處理該序列并輸出一個潛在狀態
隨后,該信息被傳遞給解碼器,解碼器由三個獨立的頭部組成,每個頭部分別針對不同的預測任務進行處理:
- 運動向量頭
本頭根據潛在狀態預測機器人的運動向量
。其被建模為一個序列到向量的問題,輸出為機器人運動的控制向量
- 任務狀態頭
該頭用于預測任務狀態
該預測被表述為一個序列到數值的問題,其中輸出表示任務的當前狀態
預測公式如下
- 搜索狀態頭
本頭預測搜索狀態,用以指示機器人在尋找目標過程中的進展
這同樣是一個序列到數值的問題,輸出反映當前的搜索狀態:
- 對于運動向量頭部
,作者采用均方誤差損失函數,并使用系數
來衡量預測與實際運動向量之間的差異
- 對于任務和搜索狀態頭
和
,作者使用交叉熵損失將預測狀態與真實標簽進行比較
其中是真實標簽,
是每個類別的預測概率
每個解碼器頭都使用感知層來處理潛在狀態 并生成相應的輸出,且該模型的最終輸出是來自所有三個解碼器頭的預測結果的組合:
- 其中
,
和
分別表示機器人在 x 軸和 y 軸上的速度,θ 表示角速度
任務狀態包括success(任務成功完成)和 running(朝檢測到的目標移動)
搜索狀態包括 searching_0(向左旋轉進行搜索)和 searching_1(向右旋轉進行搜索)
狀態與其對應運動向量的關系總結見表 I
該架構使模型能夠同時預測運動向量、任務狀態和搜索狀態,從而不僅使機器人能夠精確控制自身運動,還能理解長任務序列并提供相關反饋
1.3?機器人任務執行功能邏輯與數據集的準備
1.3.1?機器人任務執行功能邏輯
一旦模型生成預測結果,機器人便按照其功能邏輯執行任務,并適應環境變化。在任務執行過程中,引導其行為的關鍵功能包括
- 執行新任務
機器人將前一次任務指令與當前指令進行比較。如果二者不同,機器人便開始執行新任務 - 跑向目標物體
在檢測到任務物體后,機器人根據運動向量和檢測結果朝其導航 - 搜索丟失的物體
如果機器人失去了對任務物體的跟蹤,它會自動切換到搜索狀態,并調整運動以重新定位該物體 - 保持當前狀態
機器人根據實時視覺輸入保持當前狀態,直到發生狀態轉換,以確保任務持續執行 - 完成任務
機器人監控任務物體,一旦進入成功閾值范圍,機器人停止并切換到成功狀態
這些功能規則確保了自主導航、任務適應性以及任務的穩健完成
1.3.2?數據集準備
如圖4所示,數據集生成流程包括三個主要部分:
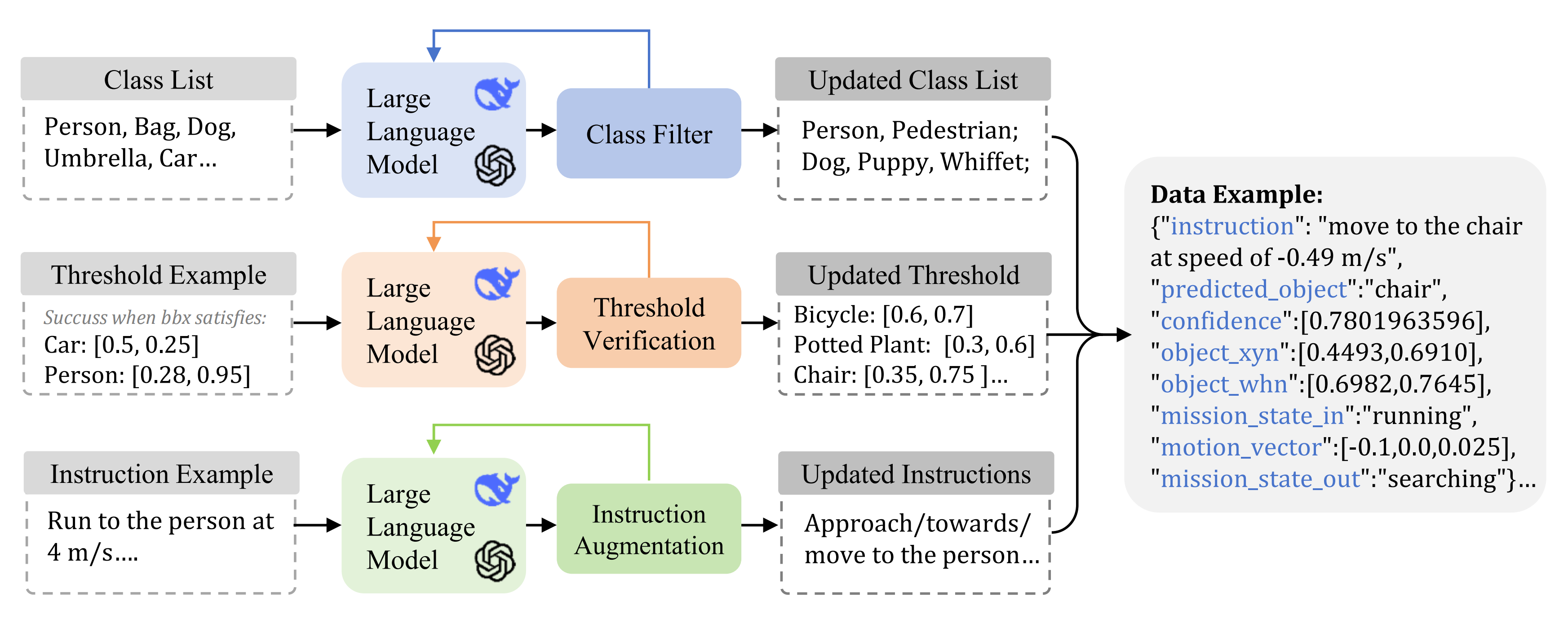
- 檢測類別同義詞擴展
作者利用大型語言模型(LLM)為預定義的目標類別生成同義詞,從而豐富對象類別,并提升模型在不同對象描述間的泛化能力 - 指令多樣化
為了增強語言模塊,作者利用大語言模型(LLM)生成任務指令的同義表達
這樣,模型能夠處理多樣化的句子結構,同時保留核心信息,從而提升其適應能力 - 對象類別閾值生成
根據初始示例為目標檢測定義成功閾值,然后利用LLM將這些閾值自適應擴展到其他類別,確保模型能夠處理不同尺寸的對象
在生成過程中,生成的數據會反饋到LLM中,以迭代優化數據集,避免冗余并逐步提升數據集的多樣性。數據集生成過程快速且易于擴展,使用Inteli9-12900KF CPU生成100萬條數據僅需不到15分鐘
1.4 實驗
1.4.1?實驗設置
第一,在模型細節上
- 作為任務規劃器和數據生成助手,作者使用了DeepSeek R1 [22]
- IOE 采用相同的整體架構,但特征維度縮減至64,包含2層Transformer 和4個注意力頭,前饋維度為256
- 對于目標檢測,作者采用了最新開發且高效的YOLO-11 [20],該模型兼具高性能與輕量級架構
- L2MM 是一種基于 Transformer的模型,特征維度為256,包含4層和8個注意力頭,前饋維度為1024,并配有一個線性輸出層
第二,在訓練設置上
- 作者收集的數據集包含100 萬樣本,以4:1 的比例劃分為訓練集和測試集。且使用NVIDIA RTX 3080Ti GPU 進行訓練
- L2MM 模型的訓練采用0.1 的dropout率,學習率為10?4,批量大小為512,最大序列長度為64,運動損失系數β 設為10
- 使用AdamW 優化器訓練25 個epoch。總訓練時間約為1 小時
同樣,IOE 模型在相同的訓練設置下訓練,耗時約30 分鐘
第三,在機器人設置上
LOVON 具有多功能性,可應用于多種腿式機器人。在作者的實驗中,他們評估了三種具有代表性的模型:Unitree Go2、B2 和 Unitree H1-2,如圖5所示

計算平臺采用 Jetson Orin,視覺平臺則包括機器人內置攝像頭以及 Realsense D435i 攝像頭
1.4.2?運動模糊幀過濾的性能
為了研究運動模糊對目標檢測性能的影響,作者進行了實驗,分析拉普拉斯方差與檢測置信度之間的關系
- 他們指令機器人以0.3、0.5或0.7 m/s的固定速度接近背包、椅子或人
相機以約15Hz的頻率更新,確保目標始終處于視野中 - 捕獲圖像幀后,作者計算每一幀的拉普拉斯方差,并將其輸入目標檢測模型,以獲得預測的置信度分數
如圖6所示
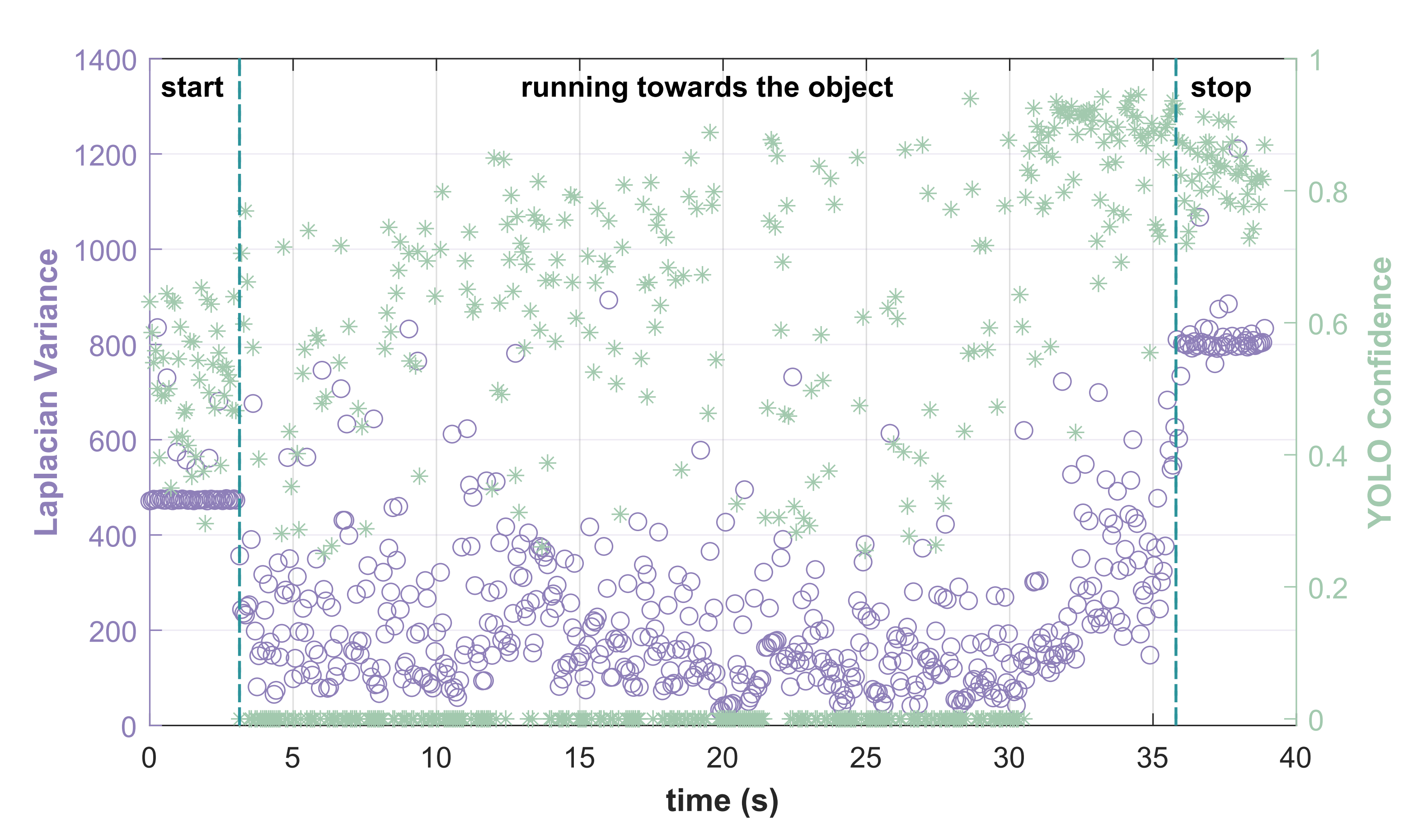
拉普拉斯方差與YOLO置信度之間的關系波動顯著。例如,在機器人運行階段,盡管目標始終處于視野范圍內,檢測模型在許多幀中始終無法識別目標對象
- 為了解決這一問題,作者采用了所提出的運動模糊幀過濾方法。通過設置上文引入的模糊閾值,能夠過濾掉運動模糊過度的幀
圖7中研究了不同模糊閾值的影響,他們觀察到,較高的閾值會帶來更高的合格幀比例,但閾值設置過高又會導致有效幀被不必要地剔除
經過測試,作者將閾值設定為Tblur=150,這使得所有數據集的合格幀比例提升了約15%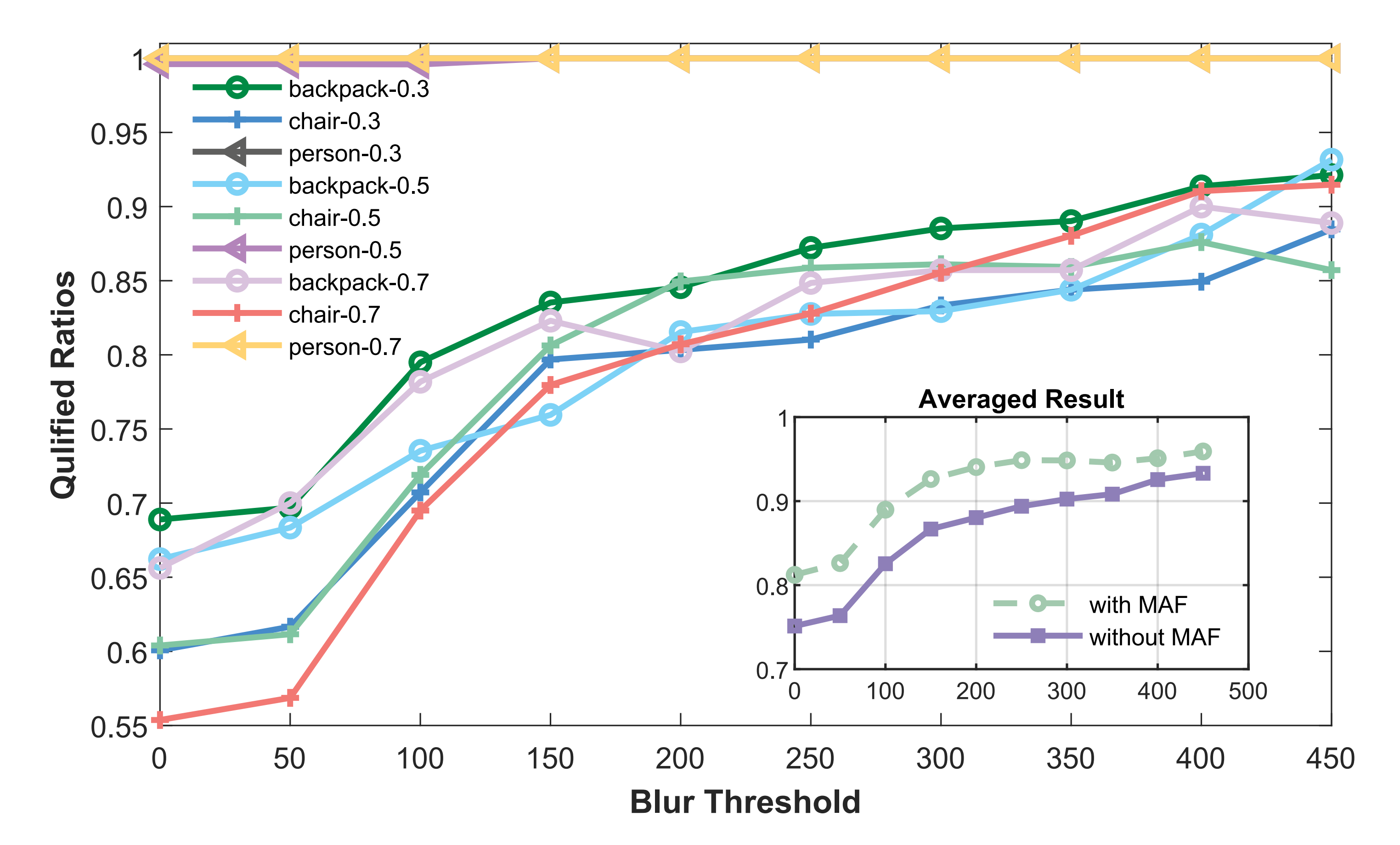
- 隨后,作者將該過濾方法集成到目標檢測流程中。被判定為模糊的幀會被排除,并由上一幀合格幀替換,同時檢測置信度通過移動平均濾波器(MAF)進行平滑處理。如圖7子圖所示,這一集成方法使合格幀率整體提升了25%,證明了他們運動模糊幀過濾方法的有效性
// 待更



)






、數據標準化與歸一化、特征降維】)




![[免費]【NLP輿情分析】基于python微博輿情分析可視化系統(flask+pandas+echarts)【論文+源碼+SQL腳本】](http://pic.xiahunao.cn/[免費]【NLP輿情分析】基于python微博輿情分析可視化系統(flask+pandas+echarts)【論文+源碼+SQL腳本】)


)
)