-
YOLOV3 論文地址::【https://arxiv.org/pdf/1804.02767】
-
YOLOV3 論文中文翻譯地址::【YOLO3論文中文版_yolo v3論文 中文版-CSDN博客】
-
YOLOv3 在實時性和精確性在當時都是做的比較好的,并在工業界得到了廣泛應用
-
YOLOv3 改進網絡結構,使其更適合小目標檢測,改進 softmax,預測多標簽任務
-
YOLOv3 最顯著的改進就是在 3 個尺度上以相同的方式進行目標的檢測,每種 3 個錨框,共 9 個。這使其可以檢測到不同規模的目標
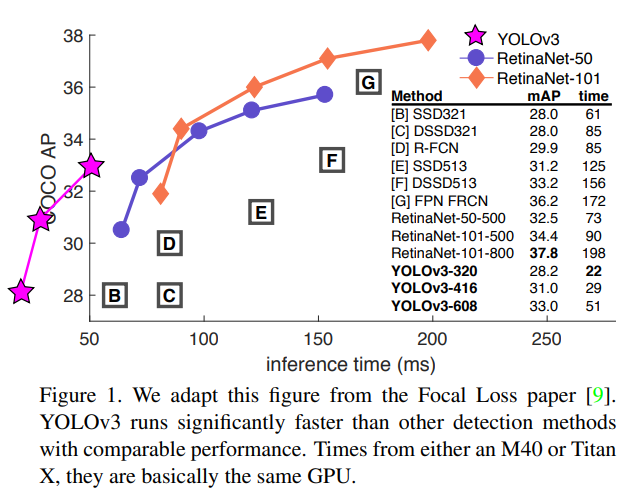
1、網絡結構
1.1 整體結構
-
CBL:CBL(Convolutional + Batch Normalization + Leaky ReLU)是 Yolov3 網絡結構中的最小組件,組成如下:
-
卷積層(Convolutional Layer)
-
批量歸一化層(Batch Normalization Layer)
-
激活函數(Leaky ReLU)
-
-
resunit:含有多個 CBL,殘差模塊中含有一個或多個殘差單元。輸入通過兩個 CBL 后,再與原輸入進行 add;這是一種常規的殘差單元。殘差單元的目的是為了讓網絡可以提取到更深層的特征,同時避免出現梯度消失或爆炸
-
梯度消失是指在反向傳播過程中,梯度值變得非常小,以至于權重更新幾乎停滯不前
-
梯度爆炸是指在反向傳播過程中,梯度值變得非常大,導致權重更新幅度過大,從而使模型的訓練不穩定甚至發散
-
-
resn:resn 是 Yolov3 中的大組件,n 表示這個 Res-block 里含有多少個 Res-unit,組成如下:
-
一個 padding
-
一個 CBL
-
N 個殘差組件
-
-
concat:將 Darknet-53 的中間層和后面的某一層的上采樣進行張量拼接,達到多尺度特征融合的目的。這與殘差層的 add 操作是不一樣的,拼接會擴充張量維度,而 add 直接相加不會導致張量維度的改變,例如 104×104×128 和 104×104×128 拼接,結果是 104×104×256
-
add:張量相加,張量直接相加,不會擴充維度,例如 104×104×128 和 104×104×128 相加,結果還是 104×104×128
-
上采樣:上采樣(Upsampling)是一個關鍵的技術,用于實現多尺度特征融合,從而提高模型對不同尺度目標的檢測能力
-
多尺度特征融合:YOLOv3 在多個尺度上進行目標檢測,通過上采樣將低分辨率的特征圖放大到高分辨率,與更高分辨率的特征圖進行融合,從而捕捉到更多的細節信息,有助于模型更好地檢測不同尺度的目標,尤其是小目標
-
-
255 = 3 x (4+1+80)
-
最后面的藍色立方體表示三種尺度的輸出
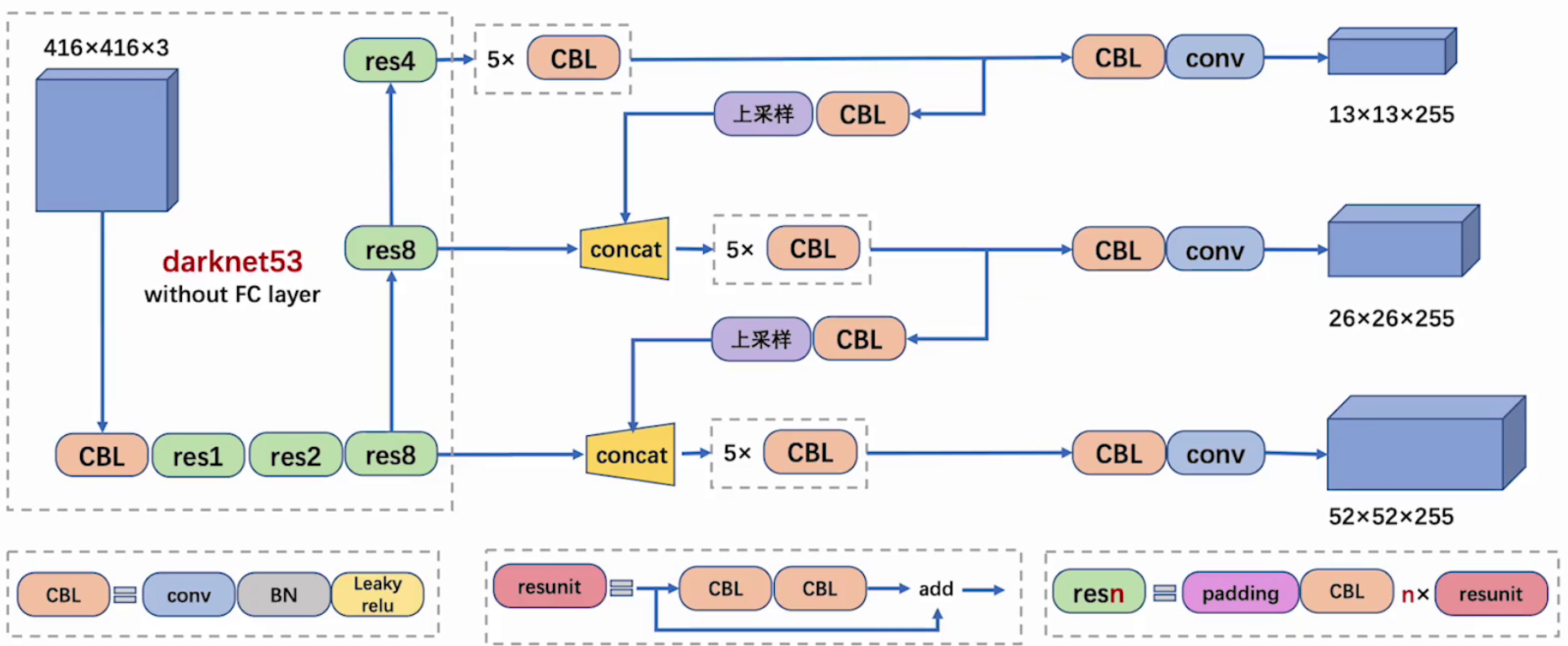
1.2 主干網絡
-
YOLOV3 主干結構采用 darknet-53,沒有池化和全連接層,尺寸變換是通過 Stride 實現的
-
整個網絡主要包括
5組殘差塊,如下:-
以
256x256輸入為例,首先經過一個3x3x32的卷積層輸出為256x256x32 -
接著經過一個
3x3x64 stride=2的卷積層輸出為128x128x64 -
接著經過一個殘差塊,輸出為
128x128x64 -
再經過一個
3x3x128 stride=2的卷積層輸出為64x64x128 -
經過
2個殘差塊后輸出為64x64x128 -
接著經過一個
3x3x256 stride=2的卷積層輸出為32x32x256 -
接著經過
8個殘差塊,輸出為32x32x256 -
再經過一個
3x3x512 stride=2的卷積層輸出為16x16x512 -
接著經過
8個殘差塊后輸出為16x16x512 -
接著經過一個
3x3x1024 stride=2的卷積層輸出為8x8x1024 -
接著經過
4個殘差塊后輸出為8x8x1024 -
最后經過池化全連接層以及
softmax輸出
-
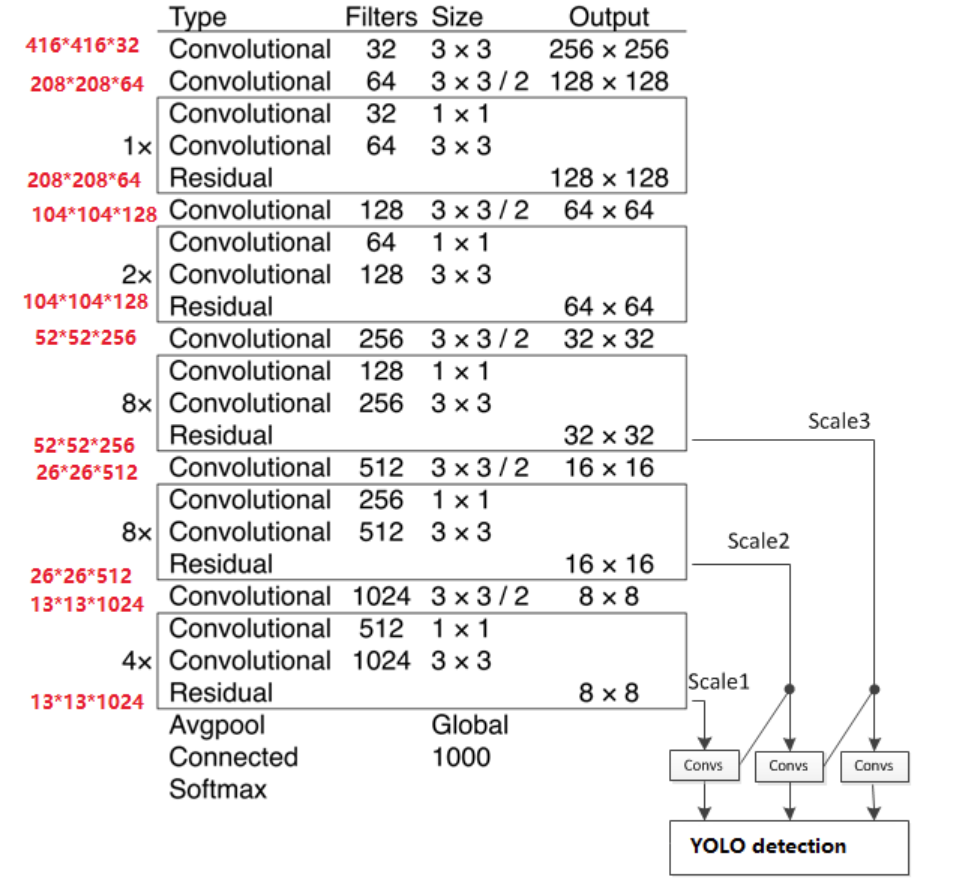
1.3 特征輸出
-
特征圖尺寸越小,感受野越大,他們分別適配不同大小的目標:
-
52 × 52 感受野小,更適合檢測小型目標
-
26 X26 感受野中等,更適合檢測中小型目標
-
13 × 13 感受野大,更適合檢測大型目標
-

1.4 特征融合
1.4.1 FPN思想
-
在目標檢測任務中,不同尺度的目標(如遠處的小人和近處的大車)對特征提取的要求不同:
-
大目標:需要高層語義信息(如類別、整體形狀)
-
小目標:需要低層細節信息(如邊緣、紋理)
-
-
傳統的單尺度特征提取網絡(如 YOLOv2)往往只使用最后一層特征圖進行預測,對小目標檢測效果較差
-
FPN(Feature Pyramid Network),就是特征金字塔網絡,目標是:融合多尺度特征,使每個尺度的特征圖都具備豐富的語義信息,從而提升對不同尺度目標的檢測能力,尤其是小目標
-
FPN 的主要思想如下:
-
特征提取:使用骨干網絡(如 ResNet、Darknet-53 等)提取不同尺度的特征圖。這些特征圖通常有不同的分辨率,例如 13x13、26x26 和 52x52
-
自頂向下路徑:從最高層的特征圖開始,逐層進行上采樣,并與下一層的特征圖進行拼接,通過 CBL 模塊對拼接后的特征圖進行進一步處理,作用是將高層語義信息“傳遞”到低層,增強低層特征的語義表達能力
-
橫向連接:在每個尺度上,將自頂向下路徑的特征圖與同尺度的骨干網絡輸出特征圖進行通道拼接(Concatenate),作用是融合低層的細節信息 + 高層的語義信息,提升多尺度檢測能力
-
特征融合:在每個尺度的橫向連接后,使用一個 CBL 模塊(Conv + BN + Leaky ReLU) 或普通卷積層,對拼接后的特征圖進行進一步處理,通常使用 3×3 卷積進行特征融合,作用是增強特征表達能力,減少信息冗余
-
-
觀察下面四張圖:
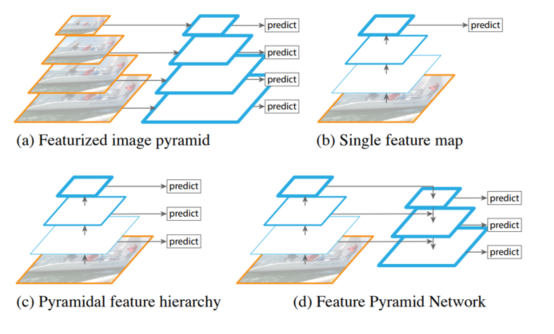
-
圖 a:特征化圖像金字塔
-
當我們要檢測不同的尺度目標時,需要把圖像送入不同的尺度
-
需要根據不同的尺度圖片一次進行預測
-
需要多少個不同尺度就需要預測多少次,效率較低
-
-
圖 b:單特征映射
-
得到一個特征圖并進行預測
-
特征丟失,對于小目標效果不好
-
-
圖 c:金字塔特征層次結構
-
把圖像傳給 backbone,在傳播的過程中分別進行預測
-
相互之間獨立,特征沒有得到充分利用
-
-
圖 d:特征金字塔網絡
-
不是簡單的在不同特征圖上進行預測
-
會對不同的特征圖進行融合后再進行預測
-
1.4.2 FPN融合
-
和前面描述的一樣,為了進一步降低模型的復雜度進而提升速度,YOLOv3 選擇了重用主干網絡所提取的不同尺寸的特征圖,主要是 8 倍、16 倍以及 32 倍下采樣的特征圖,同時采用了 FPN 的設計思想,分別對 16 倍、32 倍以及各自上采樣后的結果進行了融合,但是也對其進行了一定的改進,在傳統的 FPN 中,特征圖通常是通過 加法(Add) 來進行融合的。但在 YOLOv3 中,作者選擇使用 通道拼接(Concatenate) 來代替加法操作,這是為了:
-
增加特征圖的通道數:使得模型能夠捕捉到更多的信息
-
避免信息丟失:加法操作可能會導致某些重要信息被掩蓋,而拼接則保留了所有原始信息
-
-
1×1 卷積完成通道的一致性
-
2×up(上采樣)完成尺寸的一致性
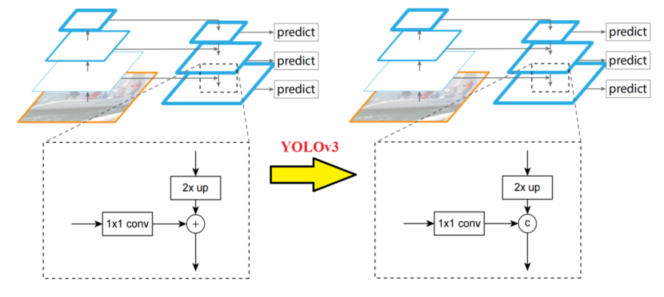
1.4.3 上采樣融合
-
特征融合更有利于檢測各種尺寸的物體,下圖是特征融合架構圖:
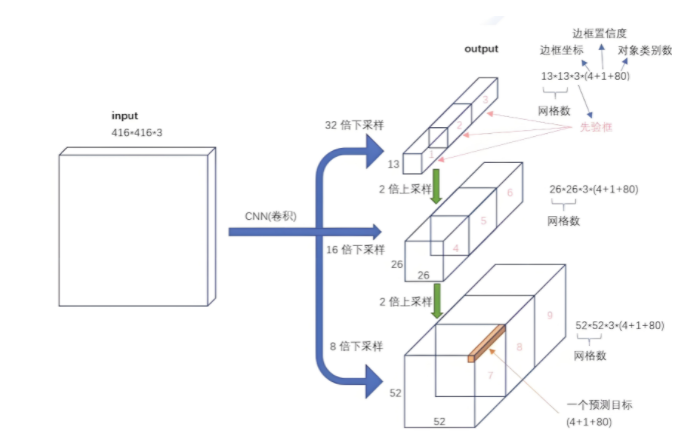
2、多尺度預測
-
如果輸入的是 416×416x3 的圖像,YOLOv3 會產生 3 個尺度的特征圖,分別為:13×13、26×26、52×52,也對應著網格個數,即總共產生 13×13+26×26+52×52 個網格。對于每個網格,對應 3 個錨框,于是,最終產生了(13×13+26×26+52×52)×3=10647 個預測框,利用閾值過濾掉置信度低于閾值的預選框,每個網格同樣最終只預測一個結果,取置信度最大的
-
在 COCO 數據集上,YOLOv3 使用了 9 種不同形狀的 Anchor Box,這 9 個 Anchor Box 被分配到三個不同的尺度中,每個尺度使用其中的 3 個來匹配適合該尺度的目標大小。具體來說:
-
13×13 特征圖:適用于較大的目標,因為這個尺度的特征圖感受野較大,能夠捕捉到更全局的信息
-
26×26 特征圖:適用于中等大小的目標
-
52×52 特征圖:適用于較小的目標,因為這個尺度的特征圖分辨率更高,能捕捉到更多細節
-

-
對于每個網格,其都對應一個 85 維度的 Tensor(80 + 5)
-
5=4+1:中心點坐標、寬、高,置信度
-
80:80 個類別的類別概率(COCO數據集的類別是80個)
-
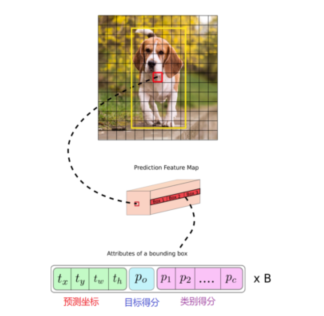
3、類別預測
-
在有的數據集中,一個目標可能同時具有多個標簽(如“女性”和“人”)。使用 softmax 會隱式地假設每個邊界框只屬于一個類別,而現實中這種情況并不總是成立。因此,多標簽分類的方式更符合實際數據分布,能夠更好地建模多類別共存的場景
-
YOLOv3 使用獨立的邏輯回歸分類器代替 softmax,采用多標簽分類方式處理類別預測,這種設計更適合現實場景中目標類別重疊的情況,提升了模型對復雜任務的適應能力
4、損失函數
-
YOLOv3 的損失函數由三個主要部分組成:定位損失(Localization Loss)、置信度損失(Confidence Loss)和分類損失(Classification Loss)
-
定位誤差損失:對于每一個與真實邊界框(ground truth)匹配的先驗框(anchor box),YOLOv3 會計算其在位置(x, y)和尺寸(w, h)上的預測誤差。該部分損失采用均方誤差(Mean Squared Error, MSE)進行計算。需要注意的是,YOLOv3 僅對負責預測目標的 anchor box 計算定位損失,其余框不參與該部分損失的計算
-
置信度誤差損失:YOLOv3 使用二元交叉熵損失(Binary Cross Entropy, BCE)來計算置信度損失。該損失分為兩個部分:
-
對于負責預測目標的 anchor box,置信度的目標值為預測框與真實框之間的 IOU
-
對于不負責預測的 anchor box,目標值為 0。 這種設計有助于模型學習區分包含目標與不包含目標的邊界框
-
-
分類誤差損失?:與早期版本不同,YOLOv3 放棄了使用 softmax 的多類分類方式,轉而采用獨立的二元分類器,并對每個類別使用二元交叉熵損失(Binary Cross-Entropy Loss)。這種多標簽分類的設計允許一個邊界框同時屬于多個類別(如“女性”和“人”),從而更好地建模現實世界中復雜的標簽重疊情況
-
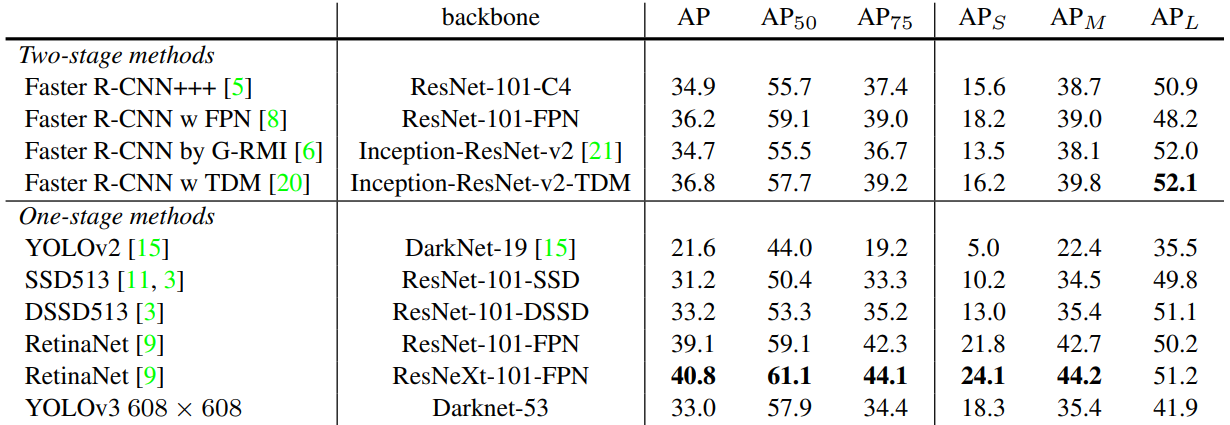
5、性能對比
-
AP50:IoU 閾值為 0.5 時的 AP 測量值
-
AP75:IoU 閾值為 0.75 時的 AP 測量值
-
APs:對于小目標的 AP 值
-
APm:對于中等目標的 AP 值
-
APL:對于大目標的 AP 值





![[Linux入門] Linux 防火墻技術入門:從 iptables 到 nftables](http://pic.xiahunao.cn/[Linux入門] Linux 防火墻技術入門:從 iptables 到 nftables)

![[源力覺醒 創作者計劃]_文心4.5開源測評:國產大模型的技術突破與多維度能力解析](http://pic.xiahunao.cn/[源力覺醒 創作者計劃]_文心4.5開源測評:國產大模型的技術突破與多維度能力解析)


和時序圖(Sequence Diagram)畫圖流程圖工具)
)





)

)