點擊 “AladdinEdu,同學們用得起的【H卡】算力平臺”,H卡級別算力,按量計費,靈活彈性,頂級配置,學生專屬優惠。
數據清洗 × 特征可視化 × Kaggle數據集實操
讀者收獲:1周內具備數據預處理能力
數據科學家80%的時間都在處理數據,而掌握這四件套你將比90%的同行更高效。本文用可復現的Kaggle實戰,帶你7天打通數據處理任督二脈。
一、四件套定位與協同作戰
1.1 工具定位分析
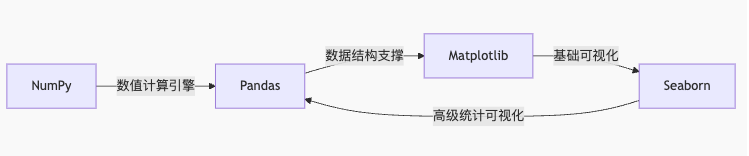
分工明細:
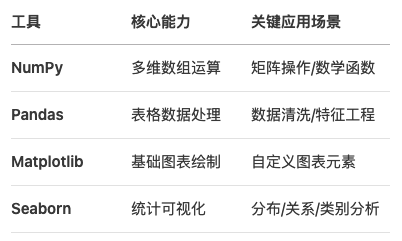
1.2 環境極速配置
# 創建虛擬環境
conda create -n data_science python=3.9
conda activate data_science # 一鍵安裝四件套
pip install numpy pandas matplotlib seaborn # 驗證安裝
import numpy as np
print(f"NumPy {np.__version__}")
二、NumPy:數據處理的原子操作
2.1 核心數據結構:ndarray
創建數組的5種方式:
import numpy as np # 從列表創建
arr1 = np.array([1, 2, 3]) # 特殊數組
zeros = np.zeros((3, 4)) # 3行4列零矩陣
ones = np.ones((2, 3)) # 2行3列單位矩陣
arange = np.arange(0, 10, 0.5) # 0-10步長0.5
random = np.random.randn(100) # 100個正態分布數
2.2 數組操作:向量化計算
傳統循環 vs 向量化:
# 低效循環(避免!)
result = []
for i in range(1000000): result.append(i * 2) # 高效向量化
arr = np.arange(1000000)
result = arr * 2 # 速度提升200倍
廣播機制實戰:
A = np.array([[1, 2], [3, 4]])
B = np.array([10, 20]) # 自動廣播計算
C = A + B # [[11,22], [13,24]]
三、Pandas:數據清洗的瑞士軍刀
3.1 核心數據結構解析

3.2 數據清洗六步法
以泰坦尼克數據集為例:
import pandas as pd # 1. 數據加載
titanic = pd.read_csv("titanic.csv") # 2. 數據概覽
print(titanic.info())
print(titanic.describe()) # 3. 處理缺失值
titanic['Age'] = titanic['Age'].fillna(titanic['Age'].median())
titanic['Embarked'] = titanic['Embarked'].fillna('S') # 4. 刪除無效列
titanic.drop(columns=['Cabin', 'PassengerId'], inplace=True) # 5. 特征工程
titanic['FamilySize'] = titanic['SibSp'] + titanic['Parch']
titanic['IsAlone'] = (titanic['FamilySize'] == 0).astype(int) # 6. 類型轉換
titanic['Pclass'] = titanic['Pclass'].astype('category')
3.3 高級數據處理技巧
數據分組聚合:
# 按艙位統計生存率
survival_by_class = titanic.groupby('Pclass')['Survived'].mean() * 100 # 多維度分析
class_sex_grouping = titanic.groupby(['Pclass','Sex']).agg( avg_age=('Age', 'mean'), survival_rate=('Survived', 'mean')
)
數據合并:
# 創建模擬票價表
fare_df = pd.DataFrame({ 'Pclass': [1, 2, 3], 'BaseFare': [100, 50, 25]
}) # 合并到主表
titanic = titanic.merge(fare_df, on='Pclass', how='left')
四、Matplotlib:可視化基礎構建
4.1 繪圖三步法
import matplotlib.pyplot as plt # 1. 創建畫布
fig, ax = plt.subplots(figsize=(10, 6)) # 2. 繪制圖形
ax.plot(survival_by_class.index, survival_by_class.values, marker='o', linestyle='--', color='b', label='生存率') # 3. 美化設置
ax.set_title('泰坦尼克號艙位生存率', fontsize=14)
ax.set_xlabel('艙位等級', fontsize=12)
ax.set_ylabel('生存率(%)', fontsize=12)
ax.grid(True, linestyle='--', alpha=0.7)
ax.legend() # 保存輸出
plt.savefig('survival_rate.png', dpi=300, bbox_inches='tight')
4.2 常用圖表類型速查
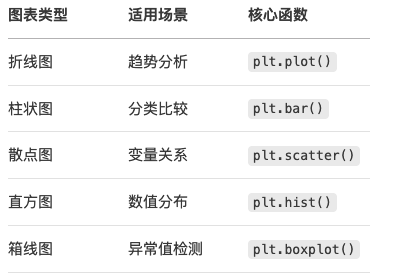
五、Seaborn:統計可視化進階
5.1 關系分析三劍客
import seaborn as sns # 1. 分布關系圖
sns.jointplot(data=titanic, x='Age', y='Fare', kind='scatter') # 2. 多變量關系
sns.pairplot(titanic[['Age','Fare','Pclass','Survived']], hue='Survived') # 3. 熱度圖
corr = titanic.corr()
sns.heatmap(corr, annot=True, cmap='coolwarm')
5.2 分類數據可視化
# 1. 箱線圖
sns.boxplot(x='Pclass', y='Age', hue='Survived', data=titanic) # 2. 小提琴圖
sns.violinplot(x='Sex', y='Age', hue='Survived', split=True, data=titanic) # 3. 計數圖
sns.countplot(x='Pclass', hue='Survived', data=titanic)
特征關聯分析矩陣:
g = sns.PairGrid(titanic[['Age','Fare','Pclass','Survived']])
g.map_diag(sns.histplot)
g.map_offdiag(sns.scatterplot)
g.add_legend()
六、Kaggle實戰:房價預測全流程
6.1 數據集加載與探索
# 加載Kaggle房價數據集
house = pd.read_csv('house_prices.csv') # 快速探索
print(house.shape)
print(house.info()) # 目標變量分布
sns.histplot(house['SalePrice'], kde=True)
plt.title('房價分布')
plt.show()
6.2 數據清洗與特征工程
# 1. 處理缺失值
missing = house.isnull().sum().sort_values(ascending=False)
missing = missing[missing > 0]
house.drop(columns=missing.index[:5], inplace=True) # 刪除高缺失列 # 2. 數值型特征填充
num_cols = house.select_dtypes(include=['int64','float64']).columns
house[num_cols] = house[num_cols].fillna(house[num_cols].median()) # 3. 類別型特征轉換
cat_cols = house.select_dtypes(include='object').columns
house[cat_cols] = house[cat_cols].fillna('Unknown')
house = pd.get_dummies(house, columns=cat_cols) # 4. 特征工程
house['TotalSF'] = house['TotalBsmtSF'] + house['1stFlrSF'] + house['2ndFlrSF']
house['Age'] = house['YrSold'] - house['YearBuilt']
6.3 特征可視化分析
# 1. 房價與關鍵特征關系
fig, axes = plt.subplots(1, 3, figsize=(18, 6))
sns.scatterplot(x='TotalSF', y='SalePrice', data=house, ax=axes[0])
sns.boxplot(x='OverallQual', y='SalePrice', data=house, ax=axes[1])
sns.scatterplot(x='GrLivArea', y='SalePrice', data=house, ax=axes[2]) # 2. 特征相關性
corr_matrix = house.corr()
plt.figure(figsize=(14, 12))
sns.heatmap(corr_matrix[['SalePrice']].sort_values(by='SalePrice', ascending=False), annot=True, cmap='viridis')
七、7天速通學習計劃
每日學習路線
gantt title 7天速通計劃 dateFormat YYYY-MM-DD section Day1-2 NumPy基礎 數組創建與操作 :active, des1, 2023-08-01, 2d section Day3-4 Pandas核心 數據清洗實戰 :crit, des2, 2023-08-03, 2d section Day5 Matplotlib 圖表繪制技巧 :des3, 2023-08-05, 1d 
)










)






、數據標準化與歸一化、特征降維】)