一、庫的操作
1. 查看數據庫
語法:show databases;這里的database是要加s的
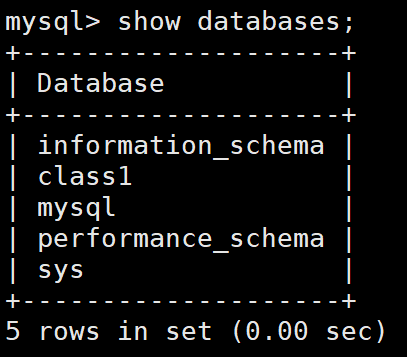
查看當前自己所處的數據庫:select database();
例如下圖,我當前所處的數據庫就是在class1數據庫
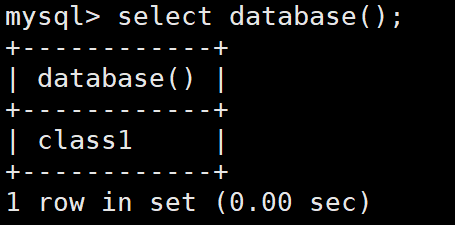
2. 創建數據庫
語法:create database [if not exists] 數據庫名;
注意這里的database不加s
創建數據庫后,再查看數據庫可以發現多了一個data1數據庫
本質就是在/var/lib/mysql 路徑下創建一個目錄
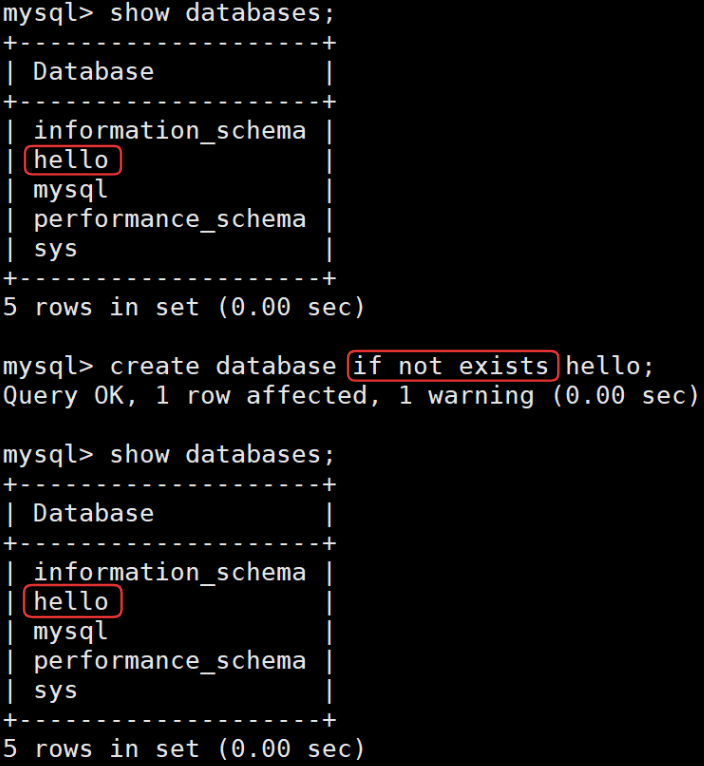
當加上if not exists后,可以發現,如果已經存在了即將要創建的數據庫,那就不再創建了
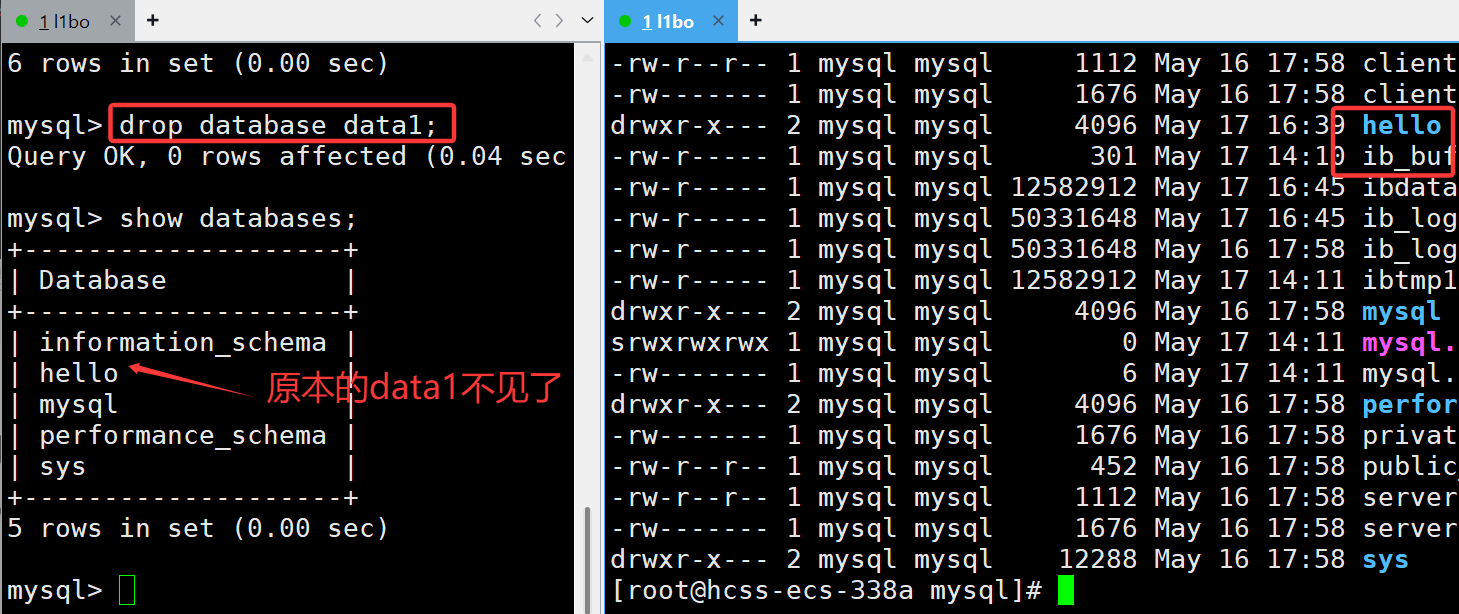
3. 刪除數據庫
語法:drop database 數據庫名;
這里我們可以看到,剛剛創建的data1數據庫不見了
本質就是把剛剛在/var/lib/mysql 路徑下創建的目錄刪除
補充知識1:編碼集,校驗集
- 數據庫編碼集:數據庫存儲數據時使用的編碼格式。
- 數據庫校驗集:數據庫進行字段比較時使用的編碼格式,本質上是一種讀取數據庫中數據采用的編碼格式。
在數據庫里進行任何操作(比如增刪改查數據)時,操作涉及的「編碼規則」必須保持一致。
講一個小故事,便于理解這兩個編碼格式。
有一篇文章用 中文(編碼集:GBK) 寫成并存放在書架上(類比數據庫存儲)。
- 美國人(讀取規則:英文編碼)打開書,試圖用英文解讀每個字的筆畫,結果看到的是一堆毫無意義的亂碼(比如 “你” 字的二進制數據被英文編碼解析成奇怪的符號)——讀取規則(校驗集)和存儲規則(編碼集)不匹配,數據 “失真”。
- 中國人(讀取規則:中文編碼)用同樣的中文規則解讀文字,順利看懂了內容 ——讀取規則和存儲規則一致,數據正確呈現。
- 如果文章里同時有中文 “蘋果” 和英文 “apple”,用UTF-8 編碼集書寫,那么無論是中國人用中文讀,還是美國人用英文讀,都能正確識別各自的語言 ——通用編碼集(如 UTF-8)能兼容多語言存儲和讀取。
4. 修改數據庫
語法:alter database 數據庫名 (加上想要修改的內容);
查看數據庫當前配置的指令:show create database 數據庫名;
(看起來的含義像是查看創建數據庫時的配置,但經過測試,實際上顯示的是數據庫當前配置)
便于修改數據庫時做出參考
暫時省略,后面找時間做補充。
5.使用數據庫
使用一個數據庫,后續可以在目標數據庫中做各種操作。
語法:use 數據庫名;
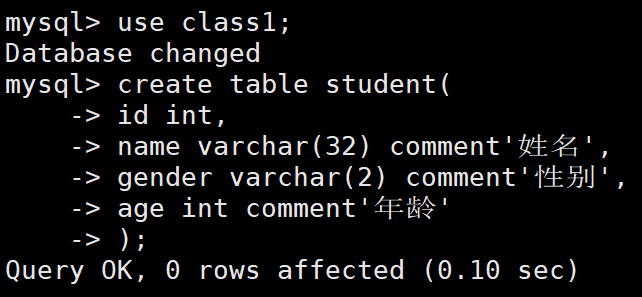
例如:使用數據庫后,創建表
二、表的操作
1. 增加表
語法:
create table 表名(列名1 列類型,列名2 列類型,列名3 列類型
)character set 字符集 collate 校驗規則 engine 存儲引擎;
'注意:如果沒有指定字符集 / 校驗規則 / 存儲引擎,則以所在數據庫的默認為準'
示例:
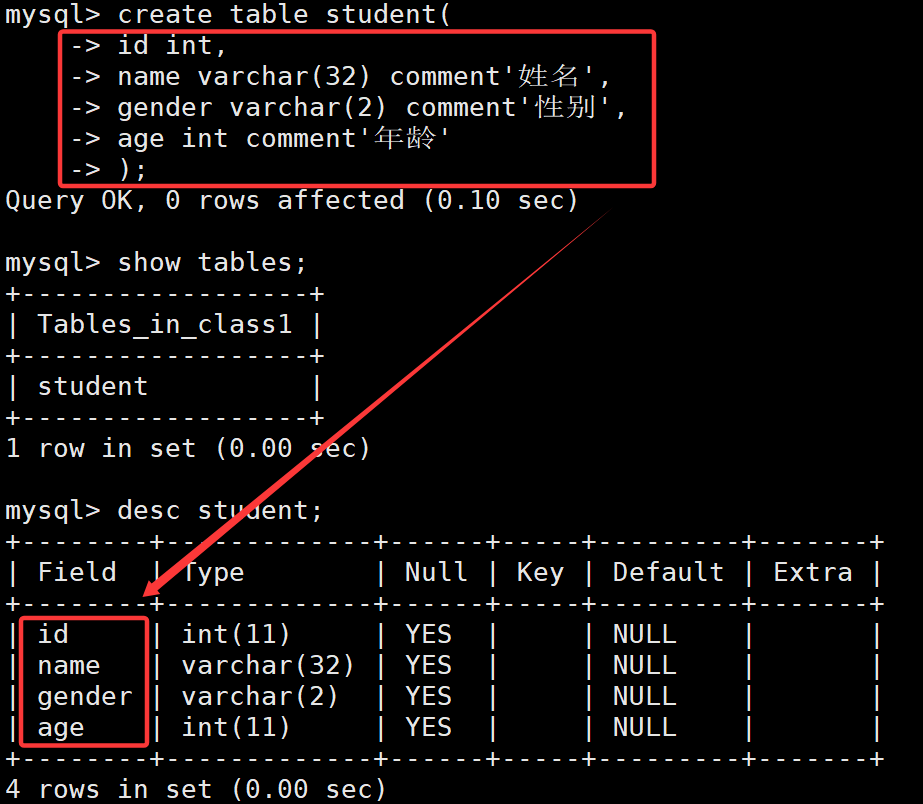
create table student(id int,name varchar(32) comment'姓名',gender varchar(2) comment'性別',age int comment'年齡'
);
'注意:在創建表的時候最后一列的結尾不要加逗號!!!,如上就是年齡列結尾不加逗號'
2. 查看表
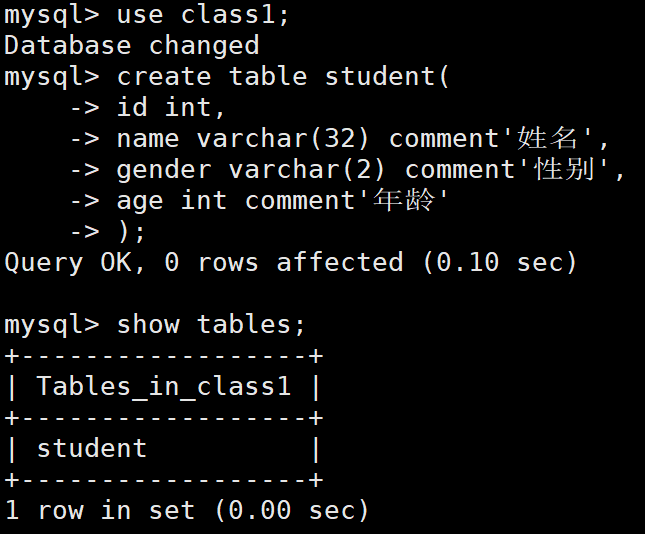
(1)查看所有表
查看當前數據庫中的所有表
語法:show tables;
(2)查看表結構
查看單個目標表的表結構
語法:desc 表名;
示例:
可以看到查看的表結構和剛剛創建的表結構是一致的
查看創建表時的詳細信息:show create table 表名;
格式化顯示:show create table 表名\G(把;替換成\G)



















