Unity3D開發AI桌面精靈/寵物系列 【六】 人物模型 語音口型同步 LipSync 、梅爾頻譜MFCC技術 C# 語言開發
該系列主要介紹怎么制作AI桌面寵物的流程,我會從項目開始創建初期到最終可以和AI寵物進行交互為止,項目已經開發完成,我會仔細梳理一下流程,分步講解。 這篇文章主要講關于人物模型 語音口型同步技術。
提示:內容純個人編寫,歡迎評論點贊,來指正我。
文章目錄
- Unity3D開發AI桌面精靈/寵物系列 【六】 人物模型 語音口型同步 LipSync 、梅爾頻譜MFCC技術 C# 語言開發
- 前言
- 一、語音口型同步LipSync技術概述
- ①技術原理
- ②實現方法
- ③應用場景
- ④技術挑戰
- 二、Unity開發準備階段
- 1.Unity平臺
- 2.插件:下載地址
- 3.示例:中文
- 三、uLipSync使用方法
- 1. 模型重構
- 2. 導入插件
- 3. 添加LipSync組件
- 4. 組件使用詳解
- 1. uLipsyncBlendShape 組件
- 2. uLipsync 組件
- 2. MFCC 技術
- 3. MFCC 頻譜中文數據提供
- 4. 運行查看效果,人物口型和聲音同步,并實時變化,中英文的訓練是一樣的。
- 然后就,大功告成了!!!
- 四. 完結
- 總結
前言
本篇內容主要講Unity開發桌面寵物的大模型交互功能,大家感興趣也可以了解一下這個開發方向,目前還是挺有前景的。
下面讓我們出發吧 ------------>----------------->
一、語音口型同步LipSync技術概述
人物語音口型同步(Lip Sync)是一種技術,用于確保動畫或虛擬人物的口型與配音或語音內容精確匹配。這種技術廣泛應用于動畫電影、視頻游戲、虛擬現實、增強現實以及實時視頻會議等領域,以增強角色的真實感和沉浸感。
①技術原理
人物語音口型同步通常通過分析語音信號的音素(Phoneme)來實現。音素是語言中最小的語音單位,每個音素對應特定的口型。系統通過語音識別技術將語音分解為音素序列,然后根據音素驅動角色的面部模型,生成相應的口型動畫。
②實現方法
基于規則的方法:通過預定義的規則將音素映射到特定的口型。這種方法需要手動調整每個音素對應的口型,適用于簡單的場景,但缺乏靈活性。
基于機器學習的方法:利用深度學習模型(如卷積神經網絡或循環神經網絡)自動學習語音與口型之間的映射關系。這種方法可以處理更復雜的語音和口型變化,適用于高質量的口型同步需求。
實時口型同步:在實時應用中(如視頻會議或虛擬主播),系統需要快速處理語音并生成相應的口型動畫。這通常需要高效的算法和硬件支持,以確保低延遲和高精度。
③應用場景
動畫制作:在動畫電影和電視劇中,人物語音口型同步用于確保角色的口型與配音完美匹配,提升觀眾的觀影體驗。
游戲開發:在視頻游戲中,口型同步技術用于增強角色的互動性和真實感,使玩家更沉浸于游戲世界。
虛擬現實和增強現實:在VR和AR應用中,口型同步技術用于創建逼真的虛擬人物,提升用戶的沉浸感。
實時視頻會議:在視頻會議中,口型同步技術可以用于虛擬形象或增強現實效果,使遠程溝通更加自然和生動。
④技術挑戰
多語言支持:不同語言的音素和口型差異較大,需要針對每種語言進行優化。
情感表達:除了口型,面部表情和情感表達也是重要因素,需要綜合處理。
實時性:在實時應用中,系統需要在極短的時間內完成語音分析和口型生成,對算法和硬件性能要求較高。
人物語音口型同步技術的發展不斷推動著動畫、游戲和虛擬現實等領域的進步,為用戶帶來更加真實和沉浸的體驗。

二、Unity開發準備階段
1.Unity平臺
- 該系列全部使用Unity2021.3.44開發;
- 該系列前后文章存在關聯,不懂的可以看前面文章;
- 該系列完成之后我會上傳源碼工程,著急的小伙伴可以自己寫框架,我就先編寫各模塊的獨立功能。
2.插件:下載地址
- uLipSync For Unity
3.示例:中文
- 元音
a:發音時,口張大,舌尖抵住下齒背,舌面中部稍微隆起,聲帶振動。如“啊”。
o:發音時,口半開,舌尖抵住下齒背,舌面后部隆起,聲帶振動。如“哦”。
e:發音時,口半開,舌尖抵住下齒背,舌面后部稍微隆起,聲帶振動。如“鵝”。
i:發音時,口微開,舌尖抵住下齒背,舌面前部隆起,聲帶振動。如“衣”。
u:發音時,口微開,舌尖抵住下齒背,舌面后部隆起,聲帶振動。如“烏”。
ü:發音時,口微開,舌尖抵住下齒背,舌面前部隆起,聲帶振動。如“迂”。
- 輔音
b:發音時,雙唇緊閉,然后突然張開,氣流沖出,聲帶不振動。如“玻”。
p:發音時,雙唇緊閉,然后突然張開,氣流沖出,聲帶不振動。如“坡”。
m:發音時,雙唇緊閉,氣流從鼻腔流出,聲帶振動。如“摸”。
f:發音時,上齒和下唇接觸,氣流從唇齒間摩擦而出,聲帶不振動。如“佛”。
d:發音時,舌尖抵住上齒齦,氣流沖出,聲帶不振動。如“的”。
t:發音時,舌尖抵住上齒齦,氣流沖出,聲帶不振動。如“特”。
n:發音時,舌尖抵住上齒齦,氣流從鼻腔流出,聲帶振動。如“呢”。
l:發音時,舌尖抵住上齒齦,氣流從舌兩側流出,聲帶振動。如“勒”。
g:發音時,舌根抵住軟腭,氣流沖出,聲帶振動。如“哥”。
k:發音時,舌根抵住軟腭,氣流沖出,聲帶不振動。如“科”。
h:發音時,舌根靠近軟腭,氣流從舌根和軟腭之間摩擦而出,聲帶不振動。如“喝”。
j:發音時,舌面前部抵住硬腭,氣流從舌面和硬腭之間摩擦而出,聲帶不振動。如“基”。
q:發音時,舌面前部抵住硬腭,氣流從舌面和硬腭之間摩擦而出,聲帶不振動。如“七”。
x:發音時,舌面前部靠近硬腭,氣流從舌面和硬腭之間摩擦而出,聲帶不振動。如“希”。
zh:發音時,舌尖抵住硬腭前部,氣流從舌尖和硬腭之間摩擦而出,聲帶不振動。如“知”。
ch:發音時,舌尖抵住硬腭前部,氣流從舌尖和硬腭之間摩擦而出,聲帶不振動。如“吃”。
sh:發音時,舌尖靠近硬腭前部,氣流從舌尖和硬腭之間摩擦而出,聲帶不振動。如“詩”。
r:發音時,舌尖靠近硬腭前部,氣流從舌尖和硬腭之間摩擦而出,聲帶振動。如“日”。
z:發音時,舌尖抵住上齒齦,氣流從舌尖和上齒齦之間摩擦而出,聲帶不振動。如“資”。
c:發音時,舌尖抵住上齒齦,氣流從舌尖和上齒齦之間摩擦而出,聲帶不振動。如“雌”。
s:發音時,舌尖靠近上齒齦,氣流從舌尖和上齒齦之間摩擦而出,聲帶不振動。如“思”。
- 復韻母
ai:發音時,先發“a”,然后舌尖抵住下齒背,舌面前部稍微隆起,向“i”滑動,聲音由低到高。如“愛”。
ei:發音時,先發“e”,然后舌尖抵住上齒齦,舌面前部稍微隆起,向“i”滑動,聲音由低到高。如“飛”。
ui:發音時,先發“u”,然后舌尖抵住下齒背,舌面前部稍微隆起,向“i”滑動,聲音由低到高。如“歸”。
ao:發音時,先發“a”,然后舌尖抵住下齒背,舌面后部稍微隆起,向“o”滑動,聲音由低到高。如“高”。
ou:發音時,先發“o”,然后舌尖抵住下齒背,舌面后部稍微隆起,向“u”滑動,聲音由低到高。如“狗”。
iu:發音時,先發“i”,然后舌尖抵住下齒背,舌面前部稍微隆起,向“u”滑動,聲音由低到高。如“游”。
ie:發音時,先發“i”,然后舌尖抵住下齒背,舌面前部稍微隆起,向“e”滑動,聲音由低到高。如“爺”。
üe:發音時,先發“ü”,然后舌尖抵住下齒背,舌面前部稍微隆起,向“e”滑動,聲音由低到高。如“月”。
er:發音時,舌尖卷起,抵住硬腭,舌面中部稍微隆起,發出“er”的音。如“兒”。
- 鼻韻母
an:發音時,先發“a”,然后舌尖抵住上齒齦,舌面中部稍微隆起,發出“n”的音。如“安”。
en:發音時,先發“e”,然后舌尖抵住上齒齦,舌面中部稍微隆起,發出“n”的音。如“恩”。
in:發音時,先發“i”,然后舌尖抵住上齒齦,舌面中部稍微隆起,發出“n”的音。如“因”。
un:發音時,先發“u”,然后舌尖抵住上齒齦,舌面中部稍微隆起,發出“n”的音。如“溫”。
ün:發音時,先發“ü”,然后舌尖抵住上齒齦,舌面中部稍微隆起,發出“n”的音。如“云”。
ang:發音時,先發“a”,然后舌尖抵住上齒齦,舌面后部稍微隆起,發出“ng”的音。如“昂”。
eng:發音時,先發“e”,然后舌尖抵住上齒齦,舌面后部稍微隆起,發出“ng”的音。如“燈”。
ing:發音時,先發“i”,然后舌尖抵住上齒齦,舌面后部稍微隆起,發出“ng”的音。如“丁”。
ong:發音時,先發“o”,然后舌尖抵住上齒齦,舌面后部稍微隆起,發出“ng”的音。如“紅”
- 上述操作很簡單
- 重點來了
三、uLipSync使用方法
1. 模型重構
- 重構模型 BlendShape組件
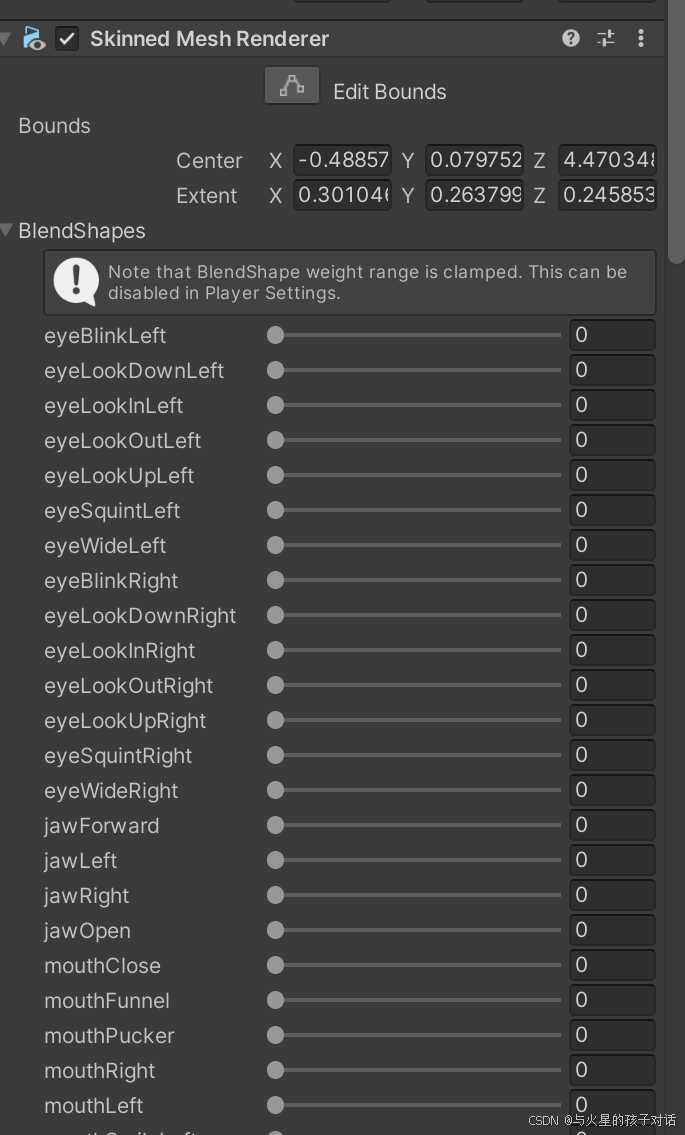
- 中文加入以下組件:
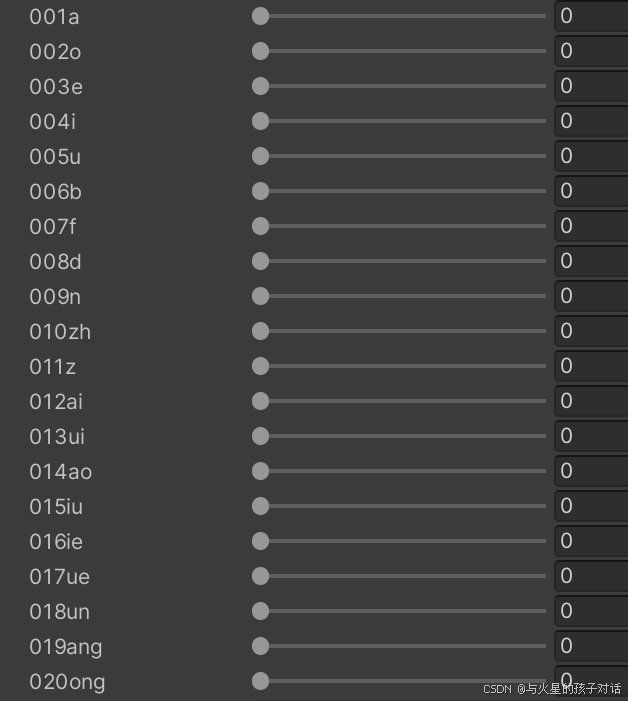
- 英文加入以下組件:
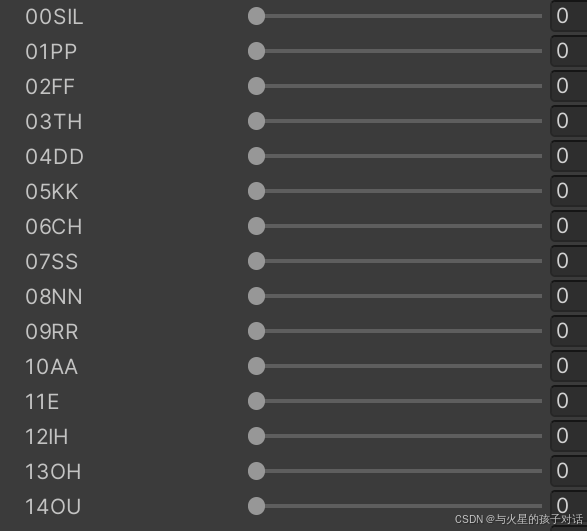
- 以上組件均為美工制作模型時添加,后續要用到,也可以用基礎自帶的52個BlendShape組件,只不過效果不是很好。
2. 導入插件
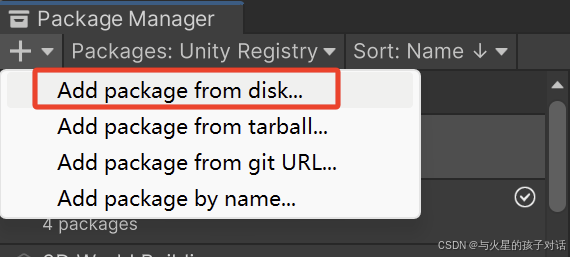
- 導入成功
3. 添加LipSync組件
- 在模型根節點添加這兩個組件。
4. 組件使用詳解
1. uLipsyncBlendShape 組件
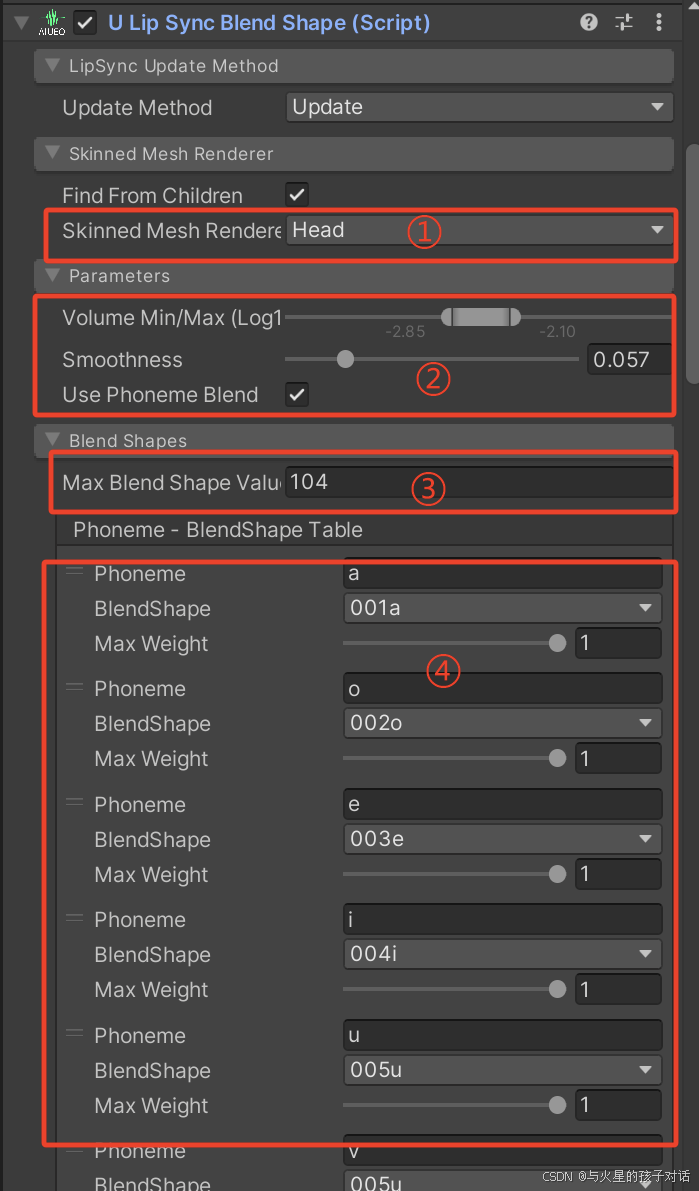
- ① 選擇你的模型上帶有BlendShape組件的物體
- ② 調節口型變化的平滑度和最大最小值,根據需求自行調節
- ③ BlendShape全部組件的值大小,默認是100,根據需求調整幅度
- ④ 綁定你的美術資源上添加的BlendShape組件對應的某個音素,并自己命名區分
2. uLipsync 組件
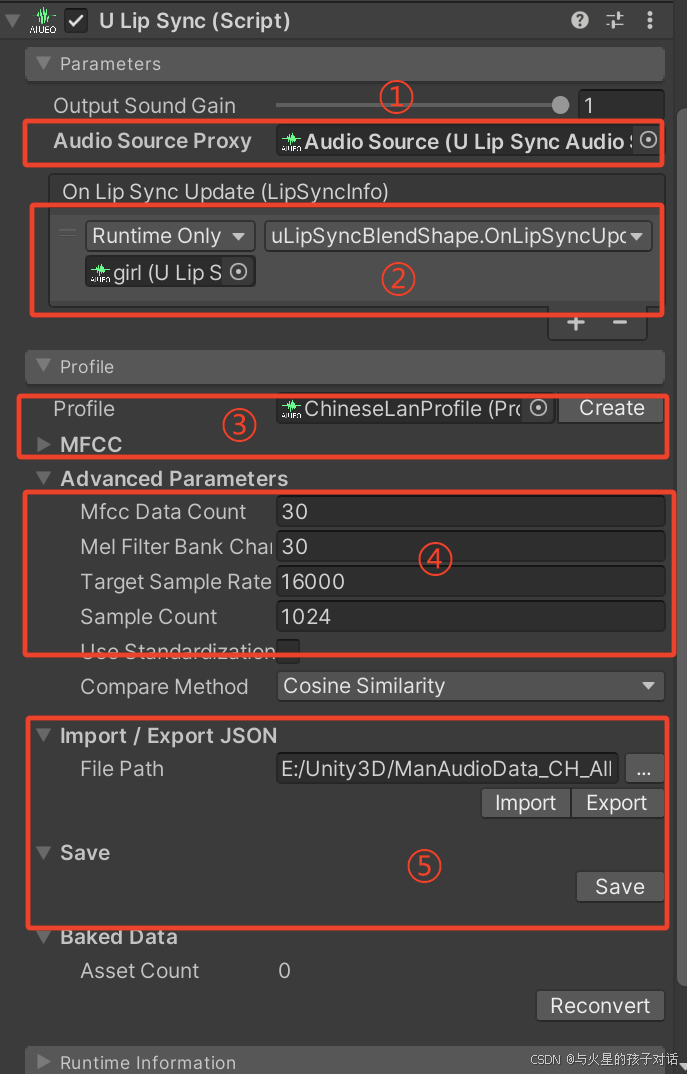
- ① 選擇你的聲音來源,新建個AudioSource拖進來
- ② 選擇當前物體,并選擇OnLipSyncUpdate方法,表示實時運行檢測
- ③ 可以自己導入保存好的數據,也可以新建,接下來重點講MFCC
- ④ 調整數據大小和采樣率的,默認我這種就可以
- ⑤ 可以將數據保存到本地,其他資源可以直接使用,也可以導入其他數據
2. MFCC 技術
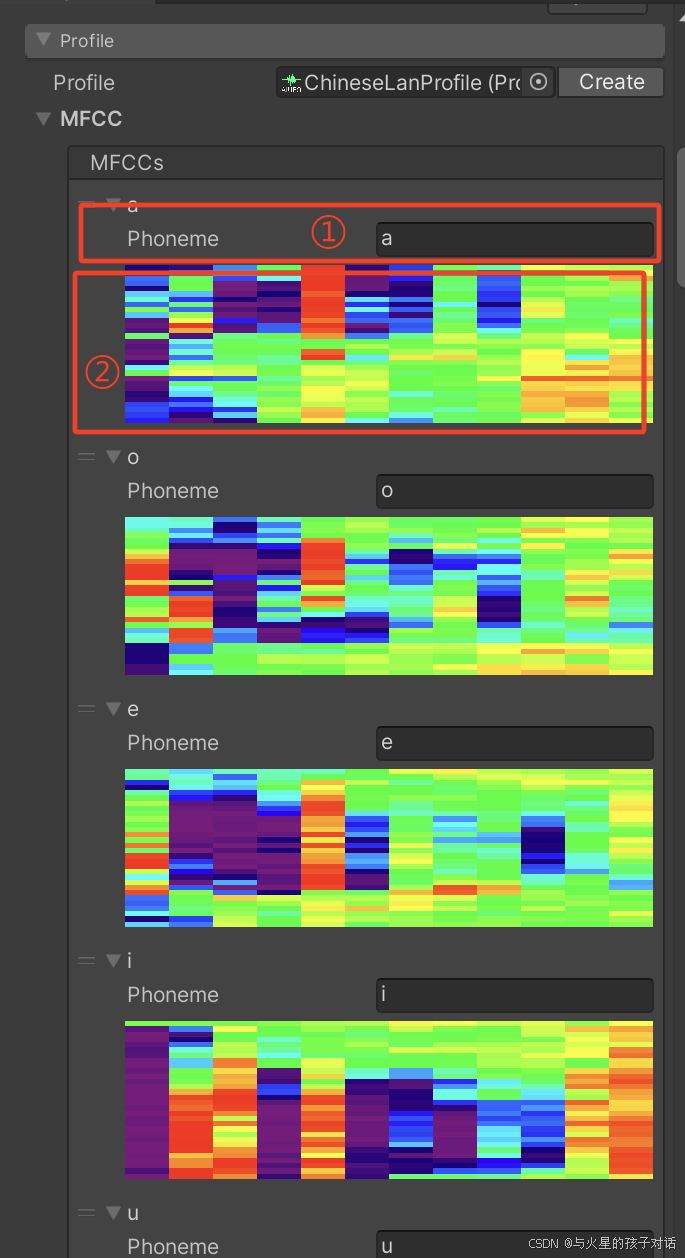
- ① 填入上個階段自己命名的音節,
- ② 錄制的頻譜
那么怎么錄制頻譜呢?
- ① 首先網上找到 a、o、e、i、u、v等音素的讀音片段,可以是mp4或者其他格式都行,我是在漢語拼音網上找的,讀音種類的數據越多越精準。
- ② 導入到Unity中
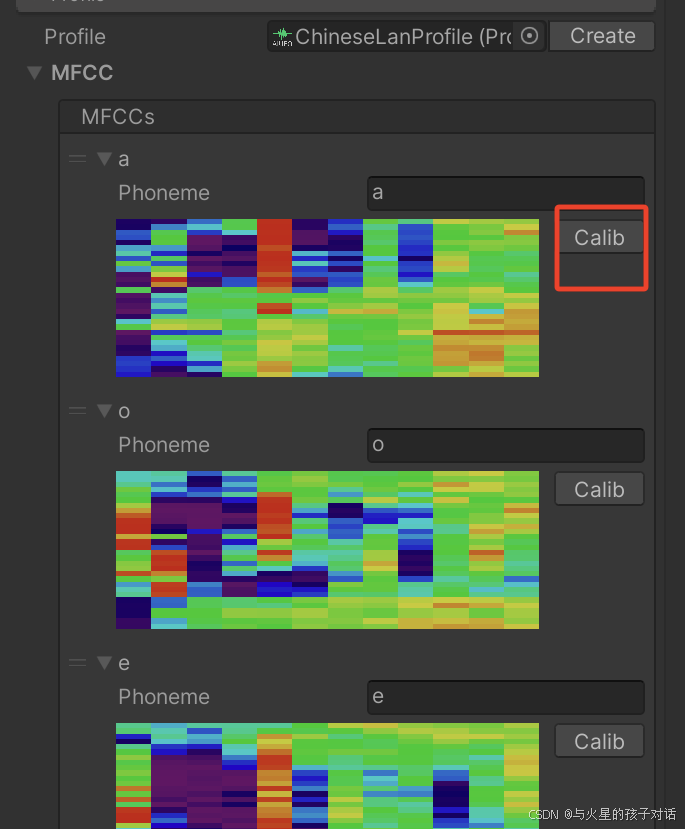
接下來就是錄制了!
- ① 首先運行Unity ,你會發現多了個按鈕 Calib
- ② 第二步,在音頻組件上播放一個音素,循環播放
- ③ 第三步,點擊Calib 按鈕,長按兩三秒,看到MFCC上有穩定均勻的頻譜寫入就代表成功了。
- ④ 第四步,重復前面的操作,將所有音素依次錄入
- ⑤ 可以點擊保存,下次可以直接使用
3. MFCC 頻譜中文數據提供
下面是我本人訓練的MFCC數據的Json文件可以導入直接用:

訓練不好的小伙伴私我,這個文件數據太大,不知道以什么格式可以上傳。
4. 運行查看效果,人物口型和聲音同步,并實時變化,中英文的訓練是一樣的。
然后就,大功告成了!!!
- 該系列基本功能差不多就完成了,就完結了,接下來我會將這些功能搭一下框架,或者把其他平臺的接入也展示出來。后續看計劃~
四. 完結
- 大家可以從第一節開始學習,完整流程基本已經實現,現在可以實現對話了。
- 下一期更新暫定:
① 更新框架
② 其他平臺的功能接入
二選一哦!- 評論告訴我,下一期更新什么

比心啦 ?(^_-)

總結
- 提示: 大家根據需求來做功能,后續繼續其他功能啦,不懂的快喊我。
- 大家可以在評論區討論其他系列下一期出什么內容,這個系列會繼續更新的
- 點贊收藏加關注哦~ 蟹蟹



















