本文是我學習以下博主視頻所作的筆記,寫的不夠清晰,建議大家直接去看這些博主的視頻,他/她們講得非常好:
基礎知識+概念:
1.【【編譯原理】期末復習 零基礎自學】,資料
2.【編譯原理—混子速成期末保過】,評論區樓主筆記
注重題型+解法:
1.【1編譯原理求語法樹的短語直接短語等等】, 對應的資料:鏈接,提取碼:ozz4
2.【編譯原理根據正規表達式構造NFA,到DFA,以及最后的DFA化簡/最小化】,對應的資料:鏈接,提取碼:uwud
在此對上述博主的產出表示感謝,也希望大家都能高分通過期末考試~
引論
一、高級語言與低級語言的定義
1. 高級語言(High-Level Language)
- 定義:
高級語言是一種接近人類自然語言(如英語)和數學表達式的編程語言,屏蔽了計算機硬件細節(如內存地址、寄存器操作),使用更抽象的語法(如函數、類、循環)描述邏輯。- 例子:Python、Java、C++、C#、JavaScript、Go 等。
- 特點:
- 可讀性強:語法接近自然語言,易于理解和維護(如
if (x > 0) { ... })。 - 平臺無關性:代碼可在不同操作系統(Windows/Linux/macOS)和硬件架構上移植,無需針對底層硬件重寫。
- 抽象程度高:提供內置數據結構(數組、對象)、內存管理(自動垃圾回收)、高級控制結構(循環、遞歸)等。
- 可讀性強:語法接近自然語言,易于理解和維護(如
2. 低級語言(Low-Level Language)
- 定義:
低級語言是直接面向計算機硬件(CPU、內存、寄存器)的編程語言,貼近機器指令格式,需手動處理底層細節。- 分類:
- 機器語言:由二進制指令(0/1序列)組成,是CPU唯一能直接執行的語言(如
10110000表示加載數據到寄存器)。 - 匯編語言:用助記符(如
MOV、ADD)替代二進制指令,需通過匯編器轉換為機器語言(如MOV AX, 1表示將數值1存入AX寄存器)。
- 機器語言:由二進制指令(0/1序列)組成,是CPU唯一能直接執行的語言(如
- 分類:
- 特點:
- 可讀性差:語法復雜,依賴硬件架構(不同CPU的匯編指令集不同,如x86、ARM)。
- 平臺依賴性強:代碼只能在特定硬件或操作系統上運行。
- 控制精細:可直接操作內存地址、寄存器,適合編寫高性能或硬件驅動程序。
二、高級語言需要編譯/鏈接的原因
1. 計算機只能執行機器語言
高級語言代碼(如C語言的 .c 文件)無法被CPU直接執行,必須經過 翻譯過程 轉換為機器語言(二進制可執行文件)。這一過程通常包括 編譯、鏈接 等步驟,目的是將抽象的高級語法轉換為CPU能理解的指令序列。
2. 編譯(Compilation)的作用
- 步驟:
- 預處理:處理
#include頭文件、#define宏定義(如展開代碼)。 - 編譯:將高級語言代碼轉換為 匯編語言(中間形式)。
- 匯編:將匯編語言轉換為 目標文件(
.o或.obj,包含二進制機器指令,但未解決外部依賴)。
- 預處理:處理
- 輸出:目標文件(二進制,但可能包含未解析的符號,如調用其他文件的函數)。
3. 鏈接(Linking)的作用
- 解決依賴:
目標文件可能引用其他文件的函數(如C標準庫的printf)或全局變量,鏈接器負責:- 合并目標文件:將多個
.o文件(如主函數和自定義函數)合并為一個整體。 - 解析符號引用:將未定義的符號(如函數名)映射到實際內存地址。
- 鏈接庫文件:引入標準庫(如C的
libc)或第三方庫的代碼。
- 合并目標文件:將多個
- 輸出:可執行文件(
.exe或無擴展名,能直接在操作系統中運行)。
三、編譯型語言 vs. 解釋型語言
高級語言按翻譯方式分為兩類:編譯型 和 解釋型,核心區別在于翻譯過程是“一次性完成”還是“邊運行邊翻譯”。
1. 編譯型語言(Compiled Language)
- 工作流程:
源代碼 → 編譯器(Compiler) → 目標代碼(機器語言)→ 鏈接器 → 可執行文件。 - 特點:
- 一次編譯,多次執行:編譯后的可執行文件可直接運行,無需重新編譯(如C語言的
.c文件編譯為.exe)。 - 執行效率高:機器語言直接由CPU執行,速度快(適合計算密集型任務,如游戲、操作系統)。
- 平臺依賴性:不同操作系統/CPU架構需重新編譯(如Windows的
.exe不能在Linux直接運行,這里如何實現跨平臺,可以參考這個視頻:【這個問題99%的人會答錯!包括我】)。
- 一次編譯,多次執行:編譯后的可執行文件可直接運行,無需重新編譯(如C語言的
- 例子:C、C++、Go、Rust。
2. 解釋型語言(Interpreted Language)
- 工作流程:
源代碼 → 解釋器(Interpreter) → 邊逐行翻譯邊執行(不生成獨立的可執行文件)。- 部分語言(如Java、Python)會先生成中間形式(字節碼),再由虛擬機(JVM、Python解釋器)解釋執行。
- 特點:
- 跨平臺性強:只要目標平臺安裝解釋器/虛擬機,代碼即可運行(如Python代碼在Windows/Linux上無需修改)。
- 執行效率較低:每次運行都需翻譯,速度慢于編譯型語言(適合快速開發、腳本任務)。
- 動態類型支持:變量類型在運行時確定,靈活性高(如Python的
x = 1和x = "hello"無需聲明類型)。
- 例子:Python、JavaScript、Ruby、PHP、Perl。
3. 混合類型(中間形式)
- Java、C#:先編譯為字節碼(平臺無關的中間代碼),再由虛擬機(JVM、.NET CLR)解釋執行,兼具編譯型的跨平臺性和解釋型的靈活性。
- Python(優化模式):可通過
pyc文件緩存字節碼,減少重復翻譯,但本質仍是解釋執行。
四、核心區別對比
| 特性 | 編譯型語言 | 解釋型語言 |
|---|---|---|
| 翻譯時機 | 運行前一次性編譯為機器碼 | 運行時逐行解釋執行 |
| 執行效率 | 高(機器碼直接執行) | 低(解釋器逐條翻譯) |
| 跨平臺性 | 差(需針對不同平臺重新編譯) | 好(依賴解釋器/虛擬機) |
| 開發效率 | 低(編譯錯誤需重新編譯) | 高(即時反饋,無需編譯步驟) |
| 典型場景 | 系統級開發、高性能計算 | 腳本編寫、Web開發、快速原型 |
| 代表語言 | C、C++、Go | Python、JavaScript、Ruby |
五、總結
- 高級語言 提升開發效率,屏蔽硬件細節;低級語言 控制硬件,實現高性能。
- 編譯/鏈接 是將高級語言轉換為機器可執行代碼的必要步驟,解決代碼依賴和平臺差異。
- 編譯型 vs. 解釋型 的選擇取決于需求:追求效率選編譯型(如C),追求靈活和跨平臺選解釋型(如Python),而Java等語言通過中間形式平衡兩者優勢。
理解這些區別有助于根據項目需求選擇合適的編程語言和開發模式。
其中我們要學習的 編譯 就是上述的一個步驟。
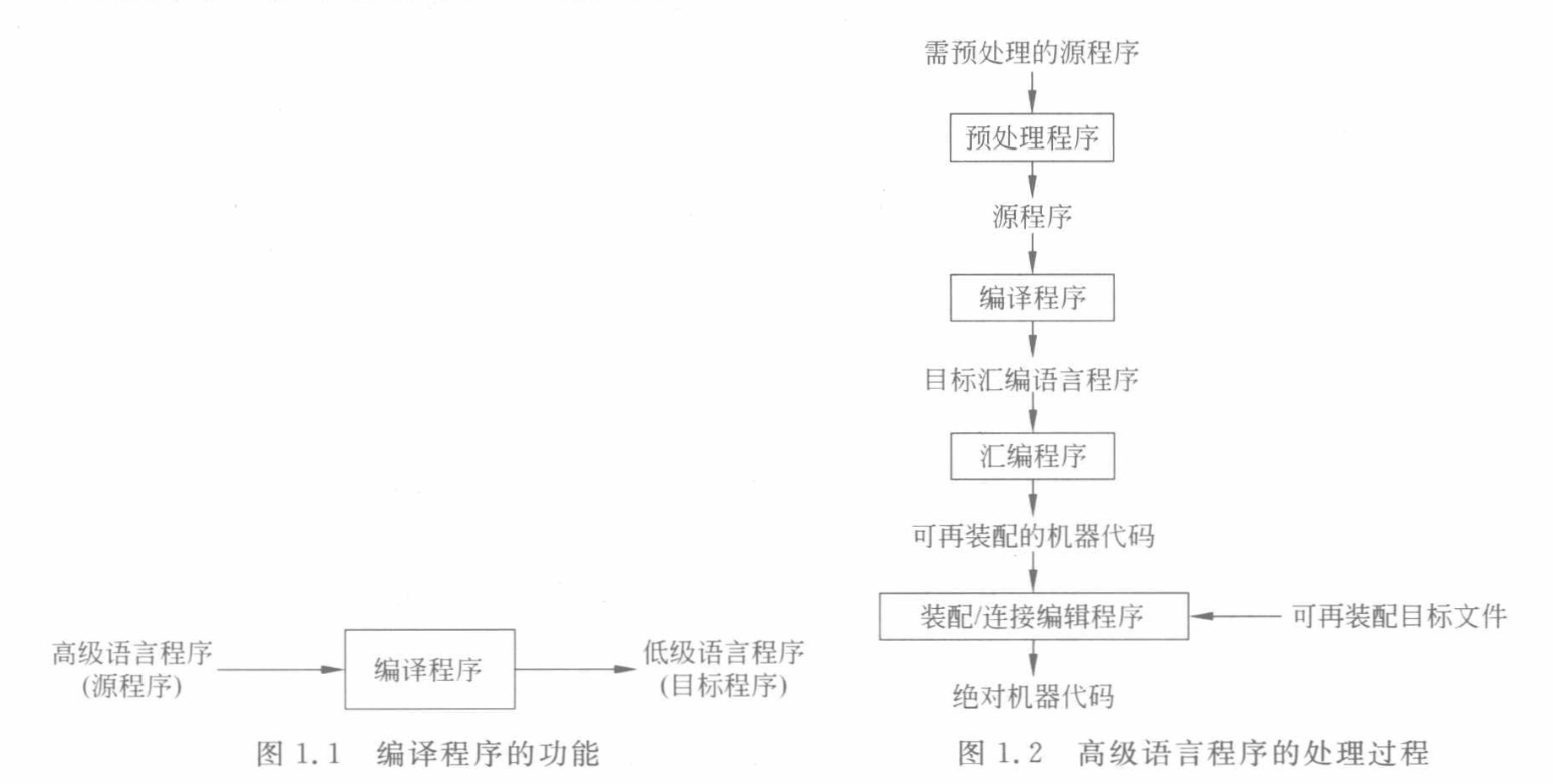
其中編譯階段又分為幾個步驟:
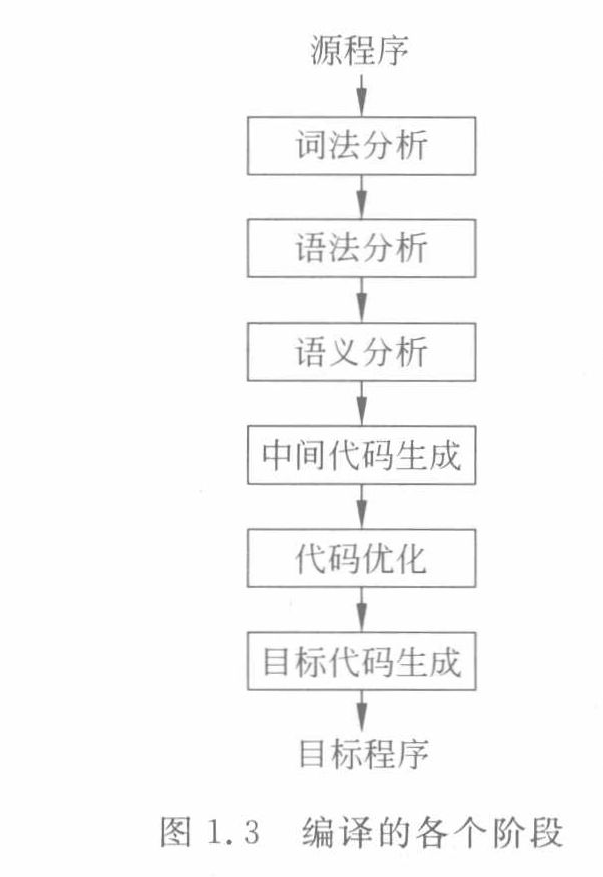
詞法分析(Lexical Analysis)
詞法分析是編譯的首個階段,此階段的詞法分析器會把C++源代碼當作字符流來處理,接著按照C++詞法規則,將其轉換為一系列有意義的詞法單元(Token)。
- 關鍵作用:
- 過濾掉注釋和空白字符(像空格、換行符這類)。
- 識別出標識符(例如變量名、函數名)、關鍵字(像int、if)、字面量(例如123、“hello”)以及運算符(如+、*)。
- 進行詞法錯誤檢查,比如檢測非法字符、不匹配的引號等問題。
- C++示例:
對于源代碼int a = 42 + b;,經過詞法分析后會生成如下詞法單元:[int] [標識符:a] [=] [字面量:42] [+] [標識符:b] [;]
語法分析(Syntax Analysis)
語法分析階段,語法分析器會依據C++的語法規則,把詞法單元構建成抽象語法樹(AST)。
- 關鍵作用:
- 驗證代碼結構是否符合C++語法規范。
- 檢測語法錯誤,例如括號不匹配、缺少分號、錯誤的if語句結構等。
- 為后續的語義分析和代碼生成搭建結構化的表示形式。
- C++示例:
對于表達式a = 42 + b;,其抽象語法樹可能呈現為:AssignmentExpr ├─ Left: Identifier(a) └─ Right: BinaryOp(+)├─ Left: Literal(42)└─ Right: Identifier(b)
語義分析(Semantic Analysis)
語義分析階段會對抽象語法樹進行靜態語義檢查,保證代碼在語義上是合法的。
- 關鍵作用:
- 類型檢查:保證操作數的類型是兼容的,例如
int和int相加,而不是int和函數指針相加。 - 符號表查詢:確認變量和函數在使用之前已經被聲明或定義。
- 檢測語義錯誤,例如變量未定義、類型不匹配、函數調用參數數量不對等。
- 類型檢查:保證操作數的類型是兼容的,例如
- C++示例:
- 錯誤示例:
int a = "hello";(類型不匹配) - 正確示例:
int a = func(42);(假設func被聲明為返回int類型)
- 錯誤示例:
中間代碼生成(Intermediate Code Generation)
該階段會把抽象語法樹轉換為與機器無關的中間表示形式(IR),像三地址碼、LLVM IR等。
- 關鍵作用:
- 簡化后續的代碼優化和目標代碼生成工作。
- 支持跨平臺編譯,因為中間代碼可以被翻譯成不同架構的機器碼。
- C++示例:
對于代碼a = (b + c) * d;,可能生成如下三地址碼:t1 = b + c t2 = t1 * d a = t2
代碼優化(Code Optimization)
代碼優化階段會對中間代碼進行轉換,以提升代碼的執行效率,同時不會改變程序的語義。
- 關鍵作用:
- 常量傳播:例如把
x = 5 + 3;優化成x = 8;。 - 死代碼消除:移除不會被執行的代碼,如
if (false) { ... }。 - 循環不變代碼外提:將循環內不會改變結果的計算移到循環外面。
- 強度削弱:把昂貴的運算(如乘法)替換為代價更低的運算(如移位)。
- 常量傳播:例如把
- C++示例:
原始代碼:
優化后的中間代碼:int a = 10; int b = a * 4; // 會被優化成 b = a << 2a = 10 b = a << 2 // 用移位替代乘法
一些問題:
- 高級語言的執行都存在中間代碼生成階段。(?)
解釋:像 Python 這類解釋型語言存在中間代碼生成階段,而直接編譯型語言(如 C 語言)可能直接生成目標代碼。
- 中間代碼所生成的依據是語法分析。(?)
解釋:在進行了語法分析和語義分析階段的工作之后,有的編譯程序將源程序變成一種內部表示形式,這種內部表示形式叫做中間語言或中間代碼。
所謂“中間代碼”是一種結構簡單、含義明確的記號系統,這種記號系統可以設計為多種多樣的形式,重要的設計原則為兩點:一是容易生成;二是容易將它翻譯成目標代碼。
- 詞法分析中,對變量分析后的輸出是該變量的值和類型。(?)
解釋:詞法分析的輸出是記號(Token),包含類型和屬性值,并非變量的實際值與類型,變量值和類型的確定發生在語義分析階段。
- 源程序經詞法分析后得到的中間結果是 (A)
A. 單詞(token)
B. 四元式
C. 語法樹
D. 語法分析程序
解釋:
- 詞法分析:輸出 Token 序列。
- 語法分析:依據 Token 序列構建出抽象語法樹(AST)。
- 中間代碼生成:生成三地址碼或者四元式等中間表示形式。
- 語法分析程序:屬于編譯程序的一個組件,并非詞法分析的輸出內容。
第一/二章:概述、文法和語言

- 空串,一個字符串的長度為0
- 空集,一個集合中沒有任何元素(空串也是一個元素)
- 字符串的乘積,字符串直接拼接在一起
- 集合的乘積,使用前一個集合中的元素與后一個集合中元素進行拼接。
- 集合的閉包,有限個集合的乘積。


文法
分類
- 0型文法:短語文法
- 1型文法:上下文有關文法
- 2型文法:上下文無關文法
- 3型文法:正規文法
上下文無關文法
上下文無關文法,是一個四元組,包含非終結符號、終結符號、重寫規則集合、識別符,可以理解為由 非終結符定義為非終結符/終結符 產生式組成的文法。
- 終結符號,只在產生式的右邊出現的符號。
- 第一條產生式的左部,是識別符。
- 通常使用大寫字母表示非終結符,小寫字母表示為終結符。(但并不是說,“文法中的小寫字母一定是指終結符”,在文法里,習慣上用小寫字母表示終結符,但這并非強制規定,具體要依據文法的定義來判斷符號類型。)

- 左線性文法和右線性文法,在一個文法中同時只能出現一種,這個文法才是正規文法。
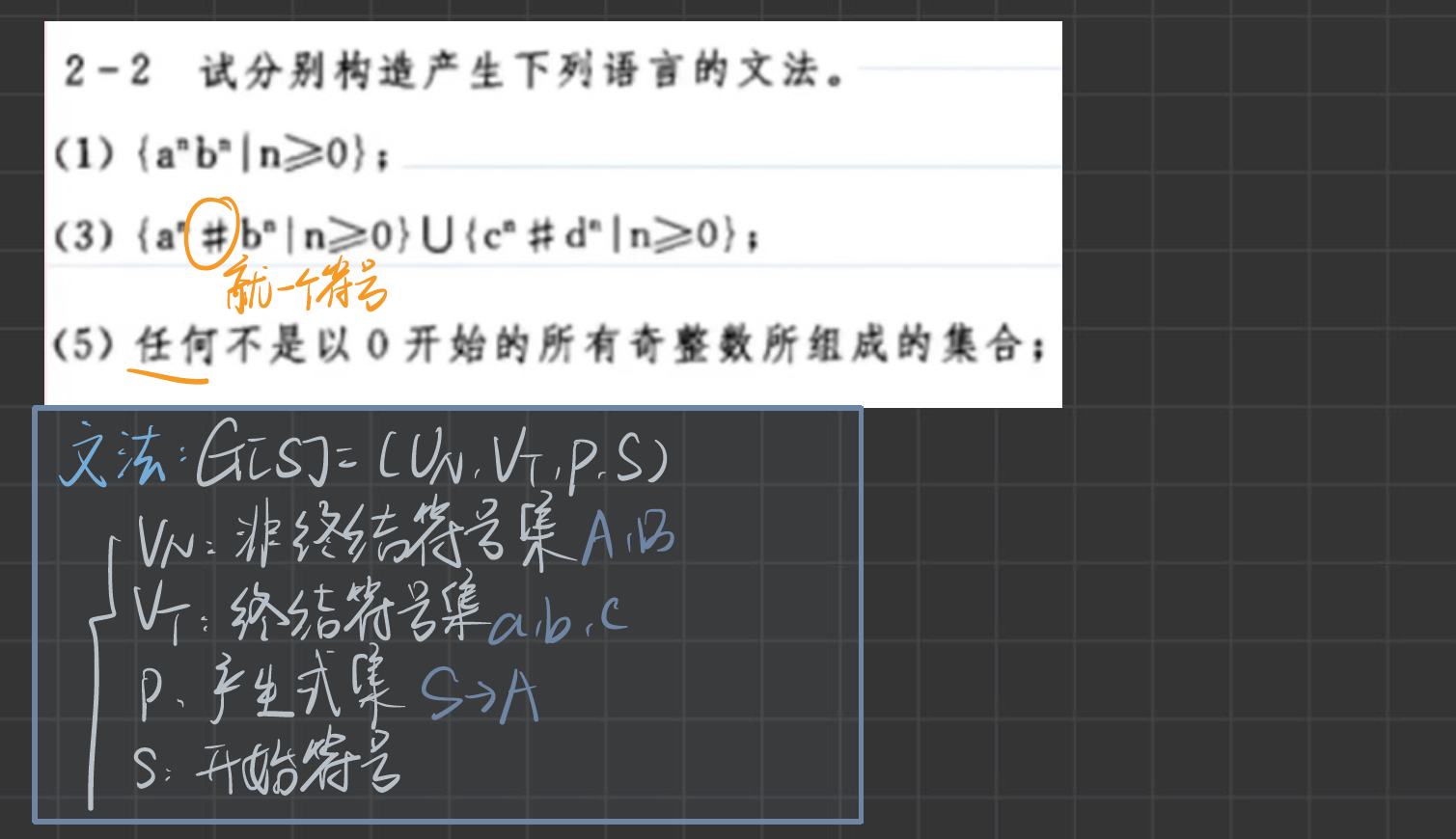

相關概念


所以,句子一定是句型。

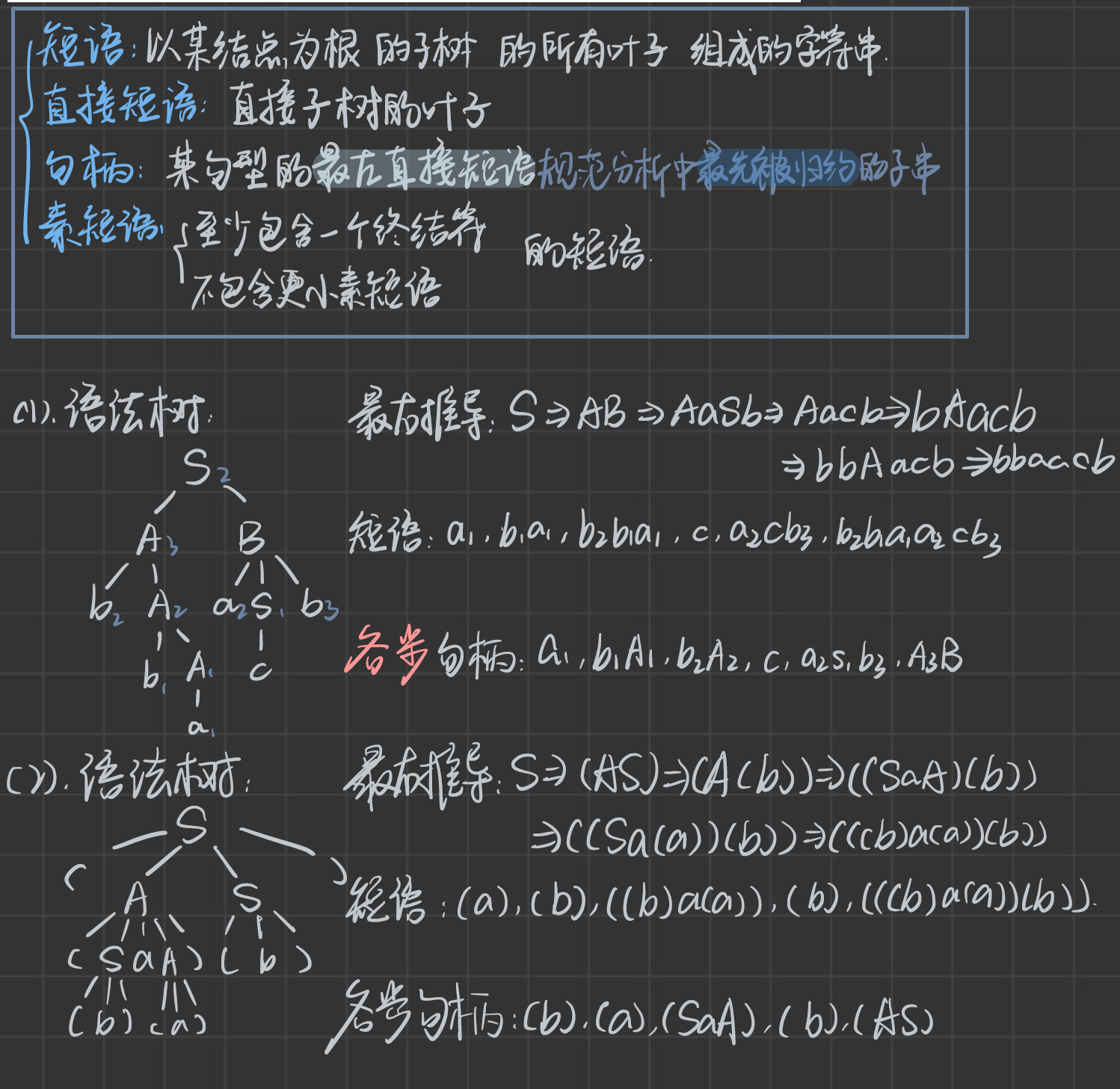
- 子樹:樹根和其向下射出的部分。
- 簡單子樹:有且只有單層分支的子樹。
- 子樹的末端結支符號串是相對于子樹根的短語。
- 簡單子樹的末端結點組成的符號串是相對于簡單子樹根的簡單短語/直接短語。(根節點能夠直接推出終結符)
- 素短語:(在短語中找,至少含有一個終結符,且不含其他更小素短語)
- 最左簡單子樹的末端結點組成的符號串是句柄。(句柄這個概念只會出現在最右推導/規范推導中才會出現的概念)
一個句型的最左 直接短語 稱為該句型的句柄。
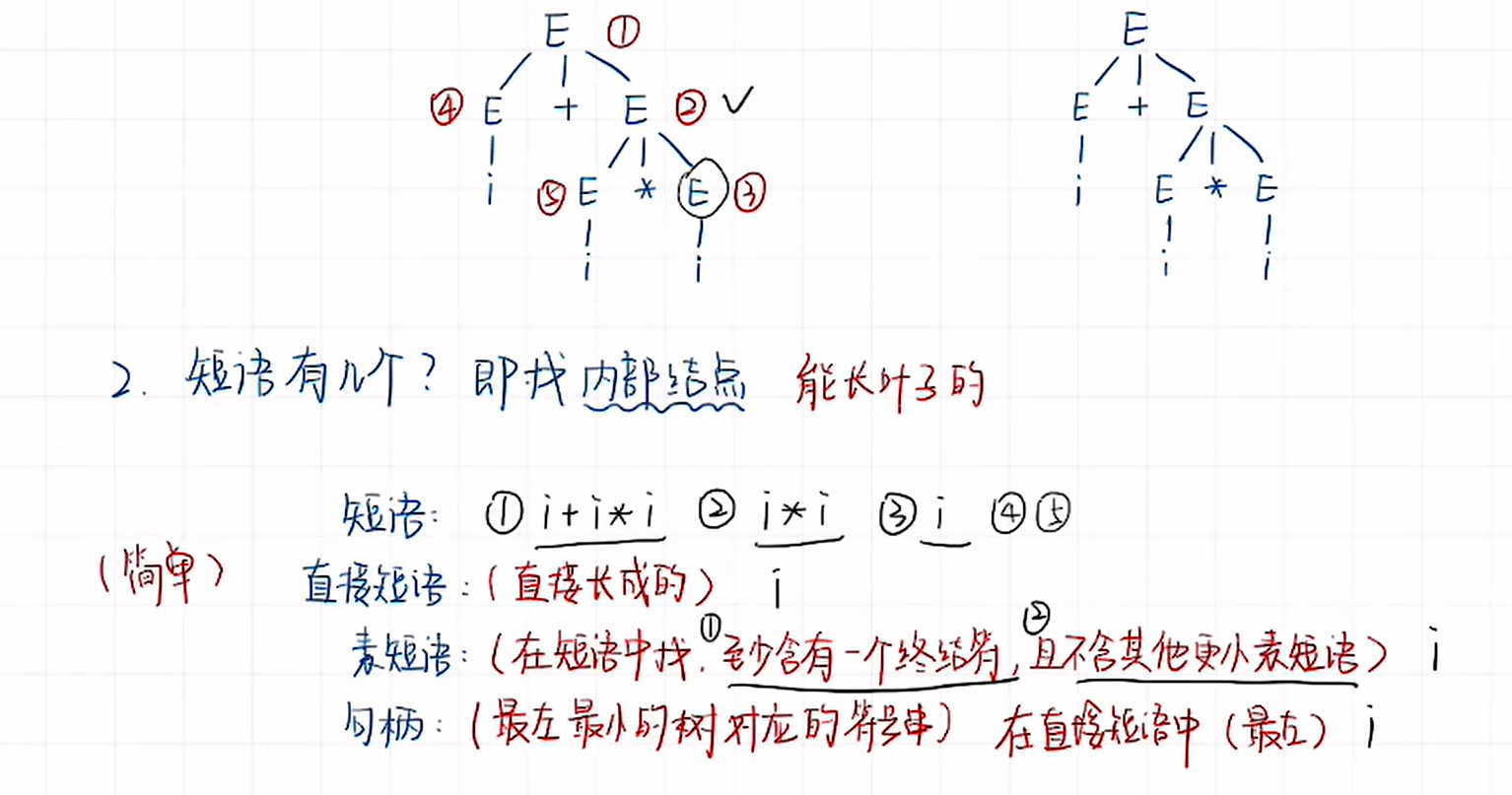

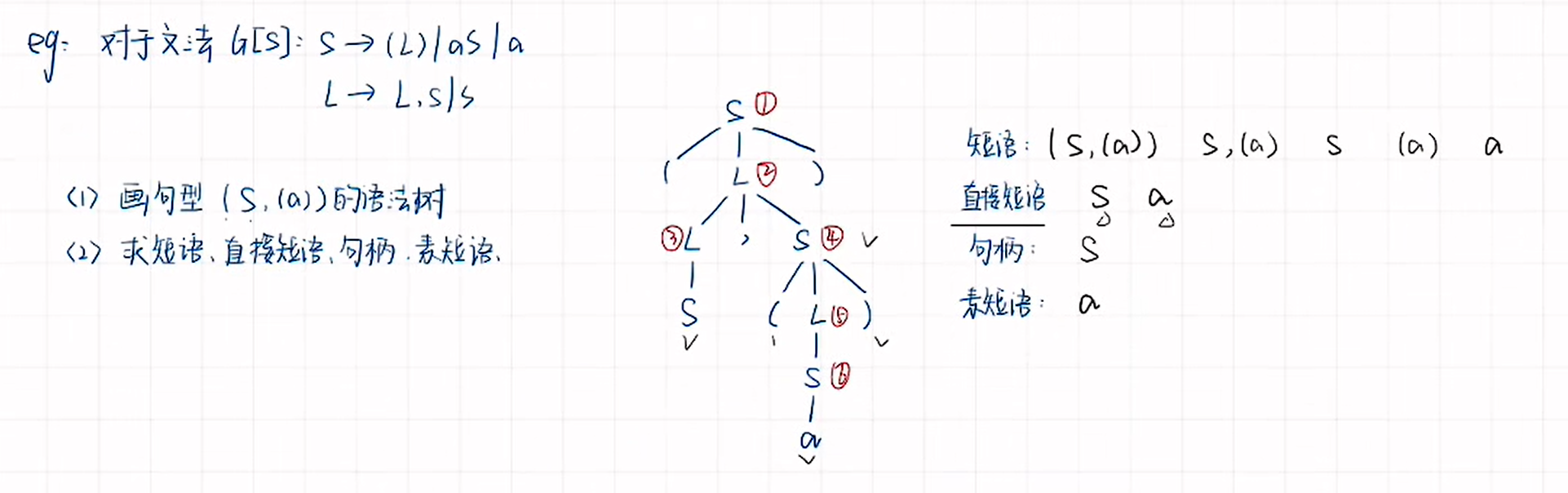

根據文法畫出語法樹,進行推導:


二義性
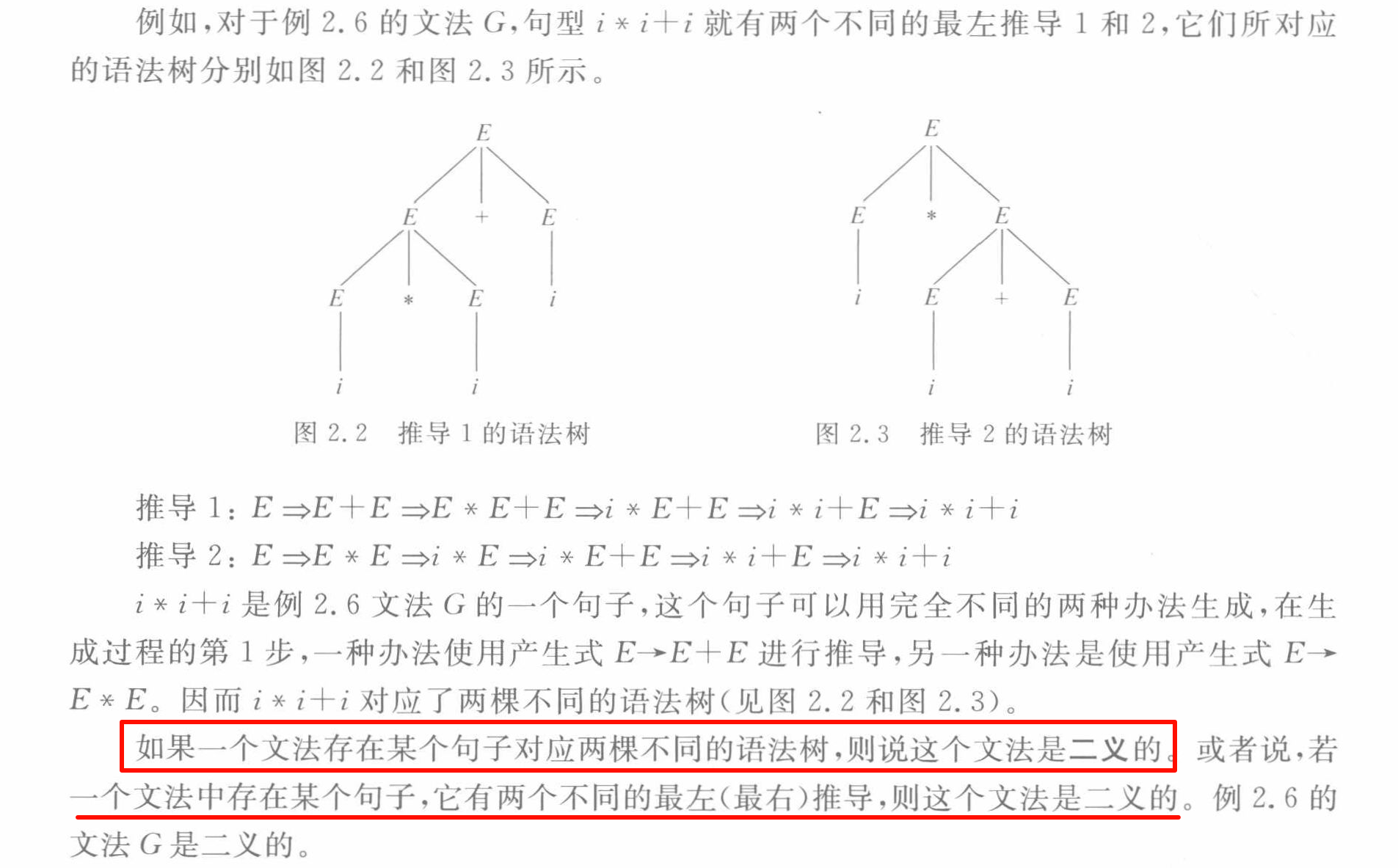
- 如果兩種推導方式畫出的樹不同,則說明該文法有二義性。
- 可能存在兩個不同的最左推導,但是它們對應的語法樹相同。
注意錯誤的說法如下(充分條件和必要條件的區別):
- 如果文法是二義的,則最左推導和最右推導必然不同(?)
- 如果文法是二義的,則最左推導和最右推導對應的語法樹必定相同。(?)

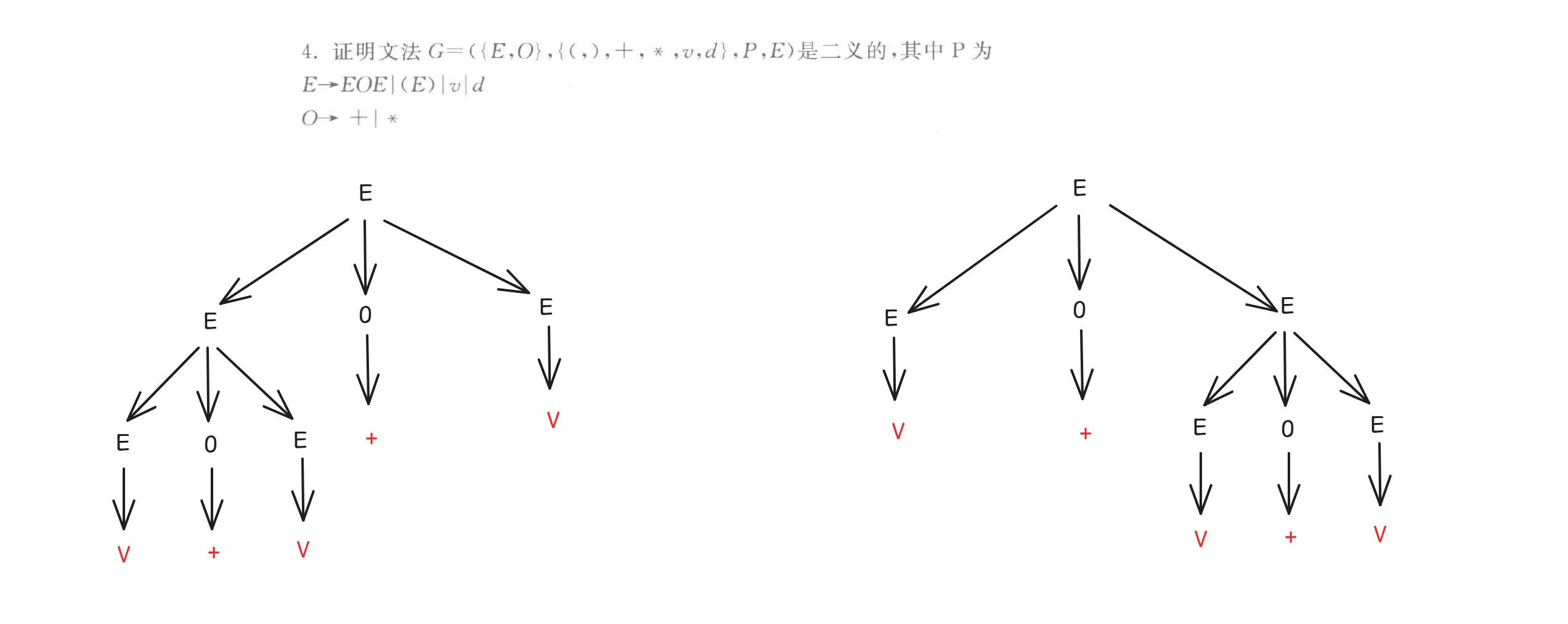
二義文法由于無法進行語法分析,沒有存在的必要。(?)
解釋: 二義文法并非無法進行語法分析,而是需要結合消除歧義的規則(如優先級、結合性)來唯一確定語法結構。在編譯實踐中,二義文法常被合理使用,以簡化文法描述并保持分析的正確性,因此具有明確的存在價值。
第三章:詞法分析
右線性文法

正規式
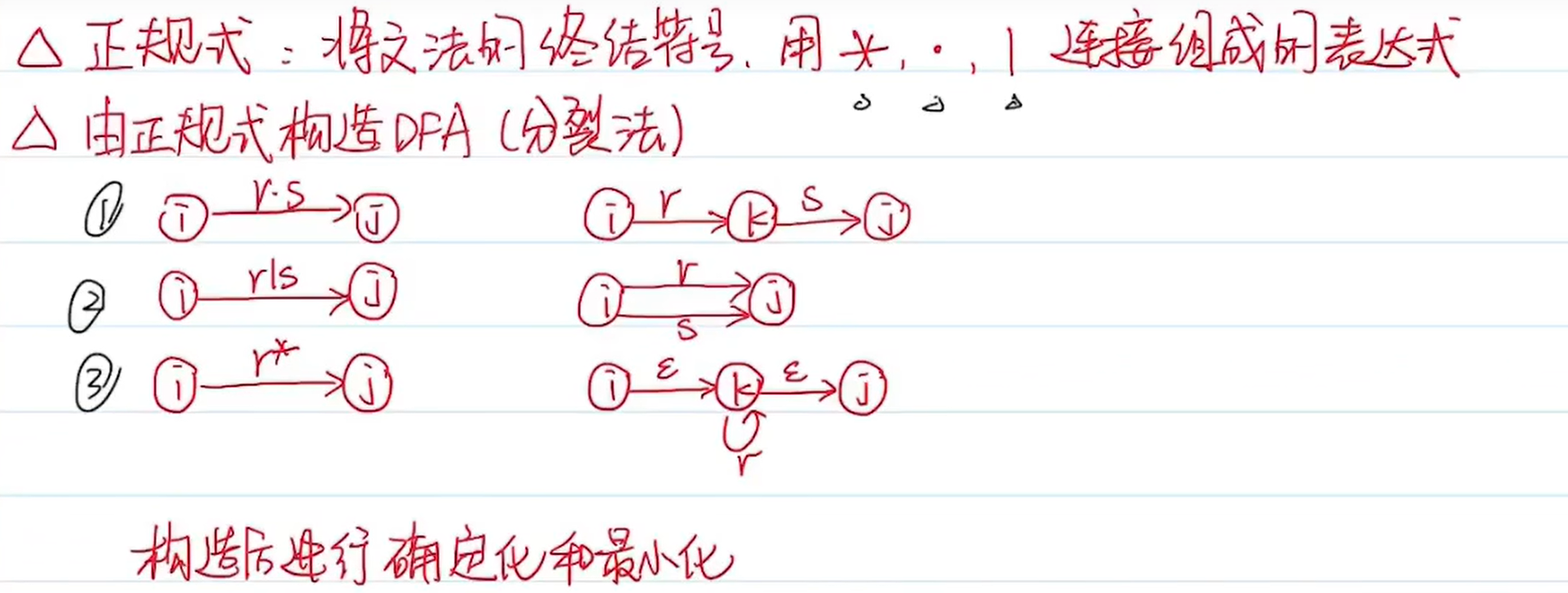

解析: 正規式的本質作用是定義和識別語言集合。當兩個正規式 M 1 M_1 M1? 和 M 2 M_2 M2? 識別的語言集合相等時,即對于任意一個字符串,若 M 1 M_1 M1?能識別(接受該字符串), M 2 M_2 M2? 也能識別,反之亦然,那么就稱這兩個正規式等價 。


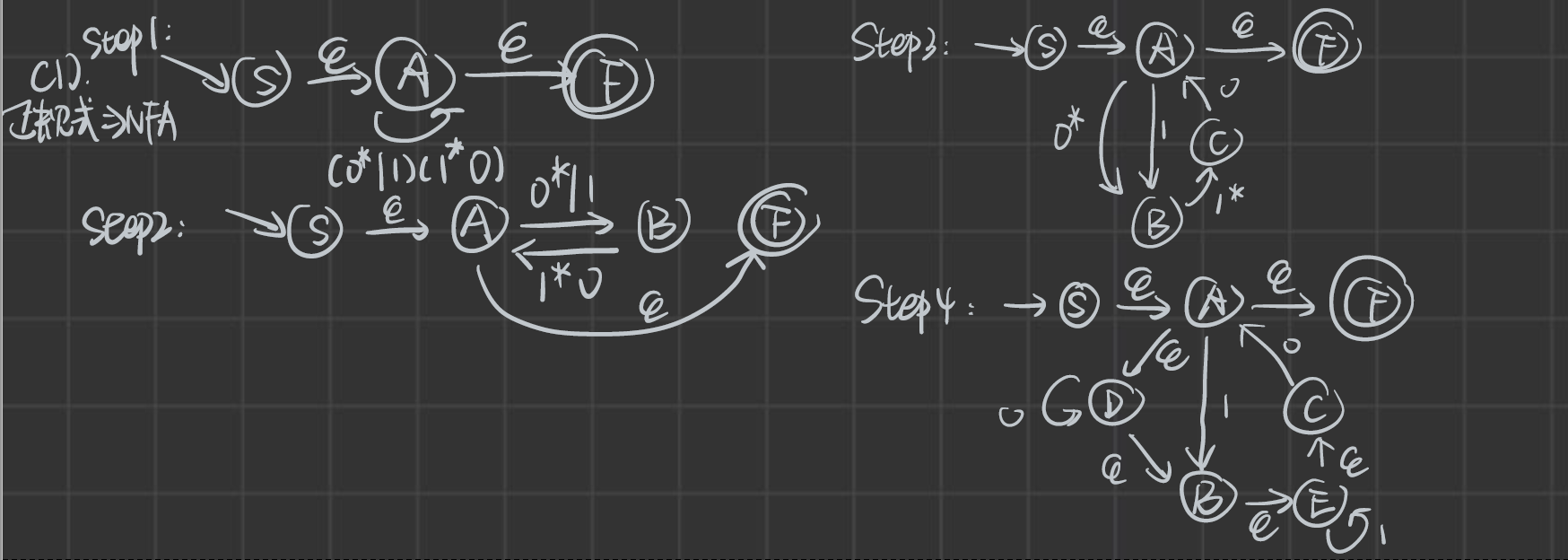
這一步可以先不看,先看后面的“根據正規式得到NFA”。



題型:
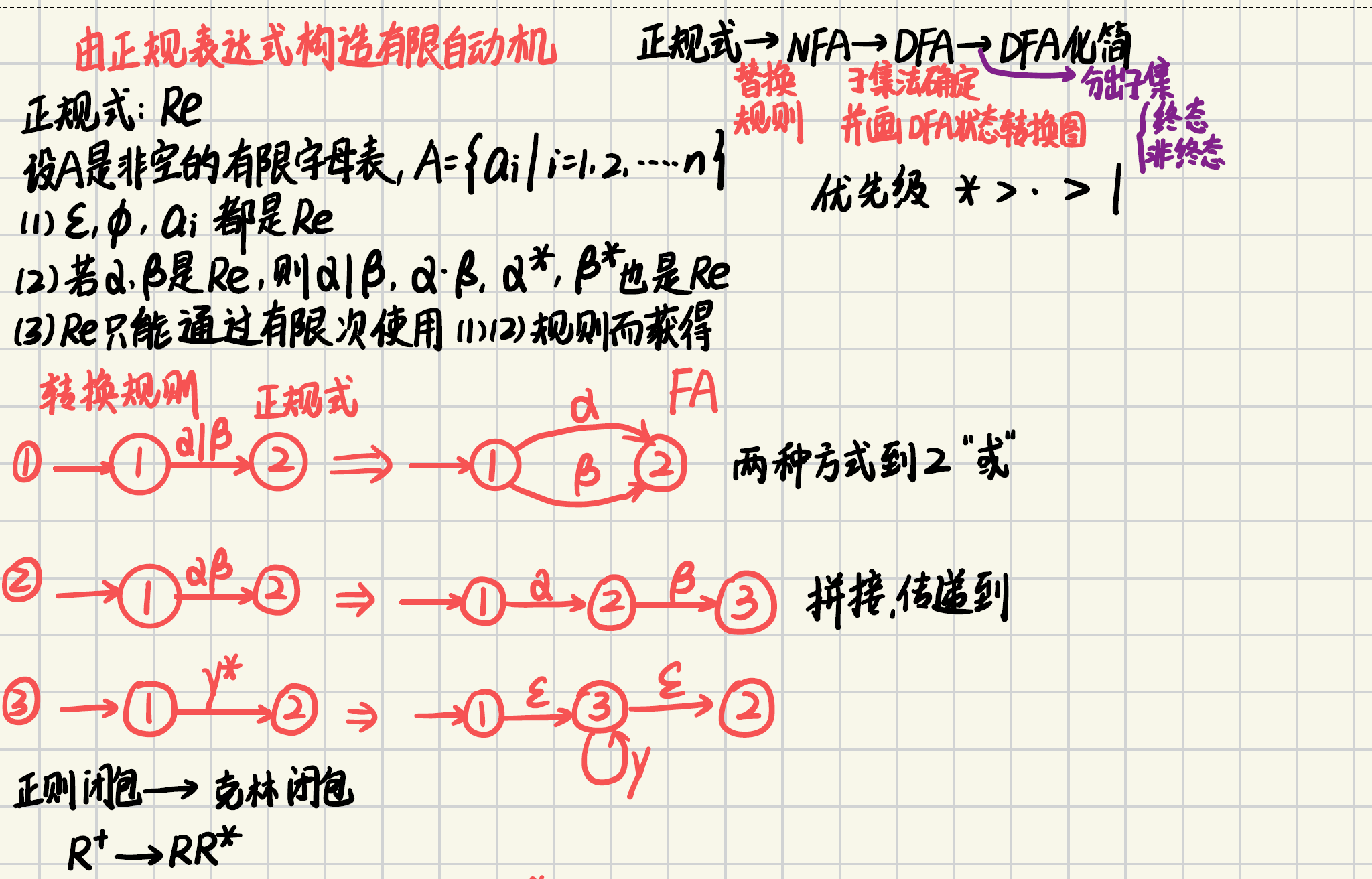
- 根據正規式畫出NFA圖
- 根據NFA圖,使用子集構造法
- 根據子集構造法,畫出DFA(新狀態集合中,凡是包含原來NFA終態的,都是新的終態)
參考視頻。
根據正規式得到NFA
參考視頻:【編譯原理根據正規表達式構造NFA,到DFA,以及最后的DFA化簡/最小化】
NFA的確定化和最小化
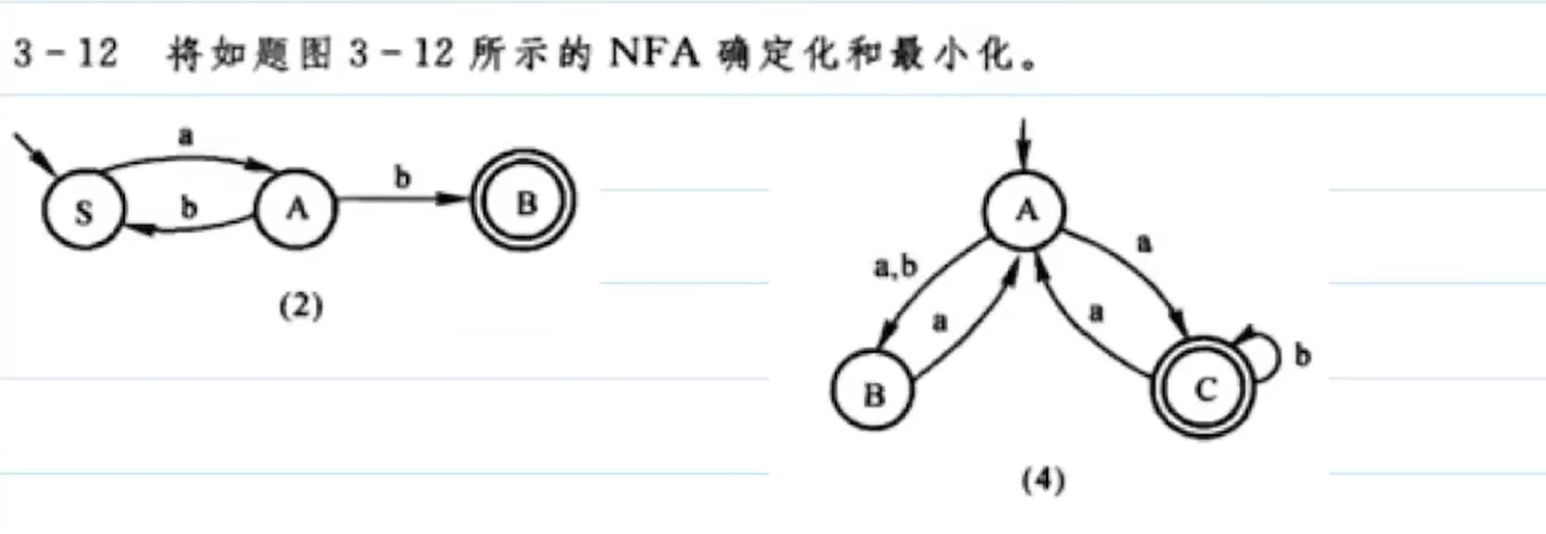
先以第(2)問進行講解:


獲取到確定化后的集合,也可以畫出對應的圖。

最小化是對已經確定好的DFA來說的,有這幾個步驟:
- 初始化,將集合換分為兩個集合:一個終態集合,一個其他集合
- 判斷其他集合是否可區分:可區分就單獨成一個集合。
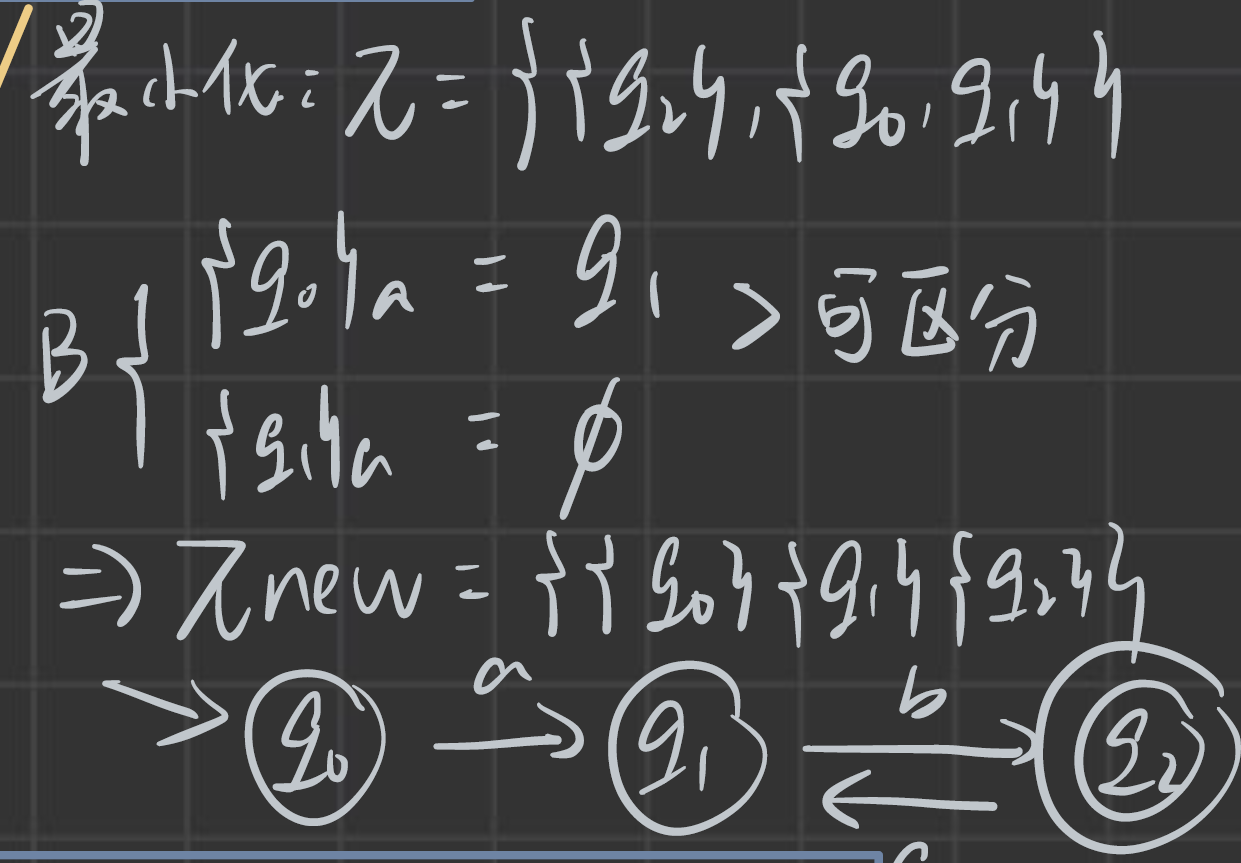
最終答案:
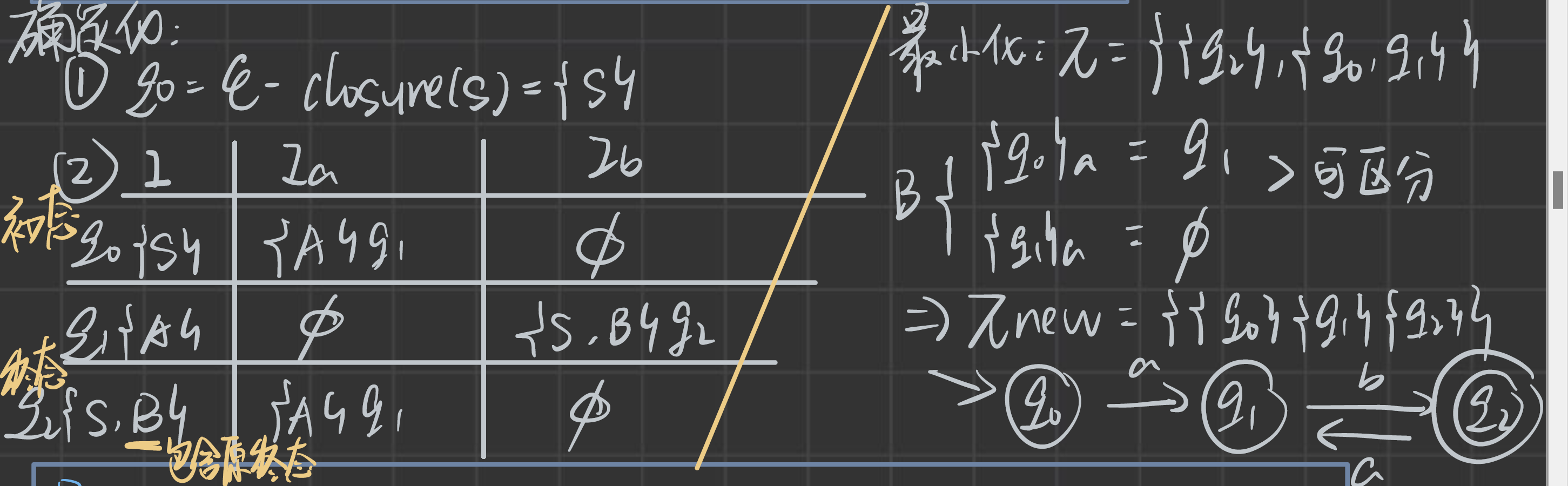
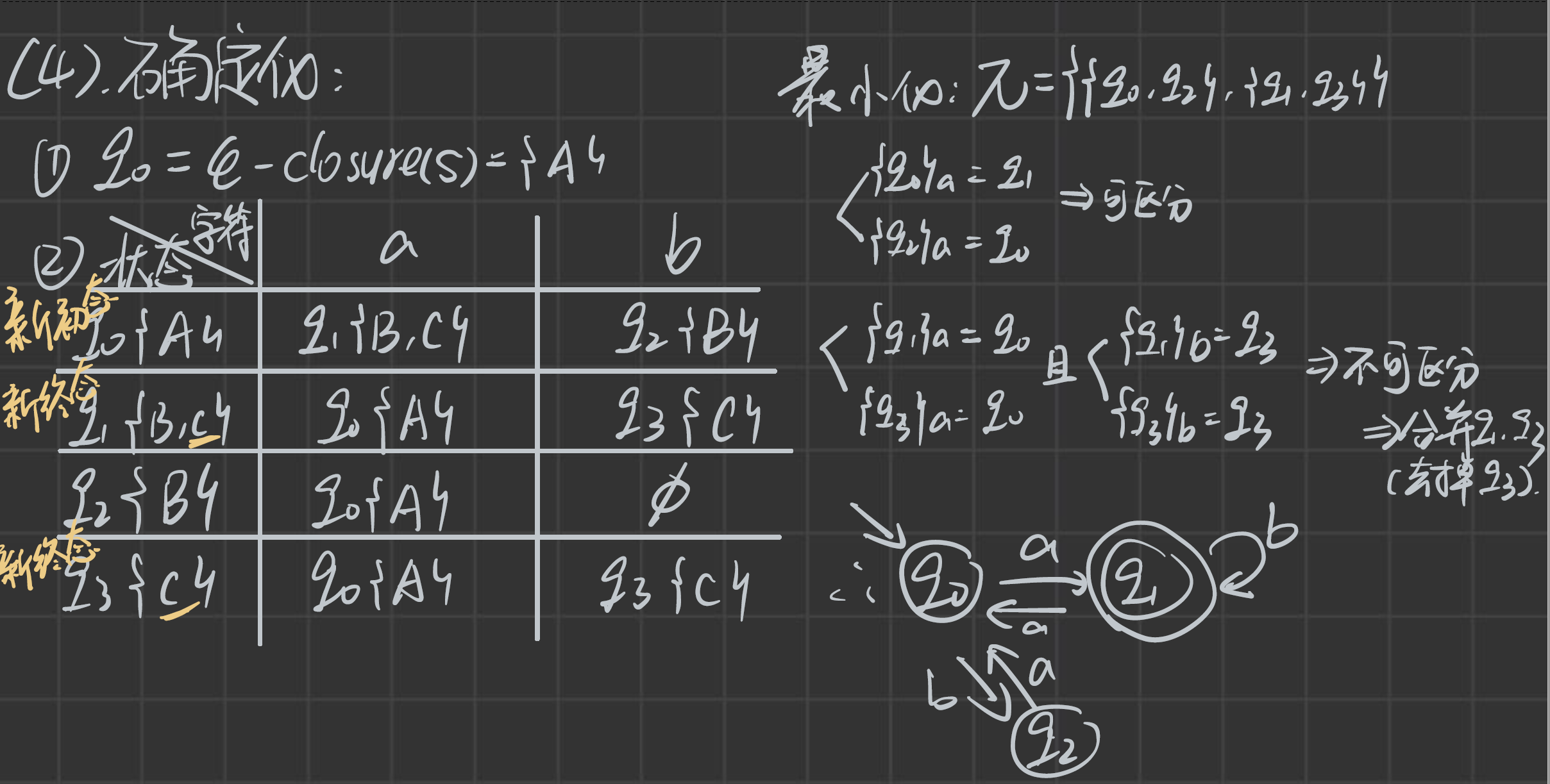
具有ε動作的NFA確定化
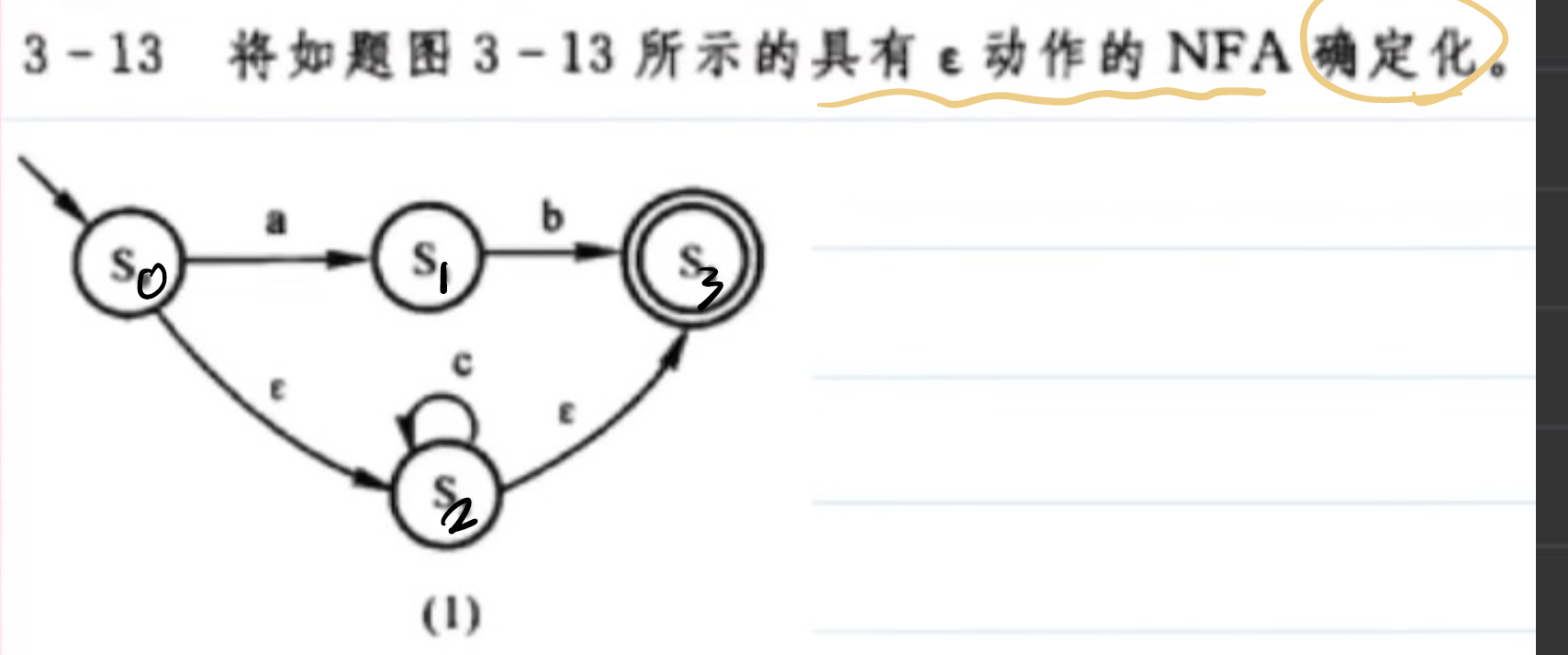

這里關于第一行 q 0 q_0 q0?狀態到 q 2 q_2 q2?中,有 S 3 S_3 S3?狀態的解釋:假設a,b,c是各種票,空是免費通過, S 2 S_2 S2?用c票到了 S 2 S_2 S2?,然后走免費通道到了 S 3 S_3 S3?(必須先有一張票,才能走免費通道)
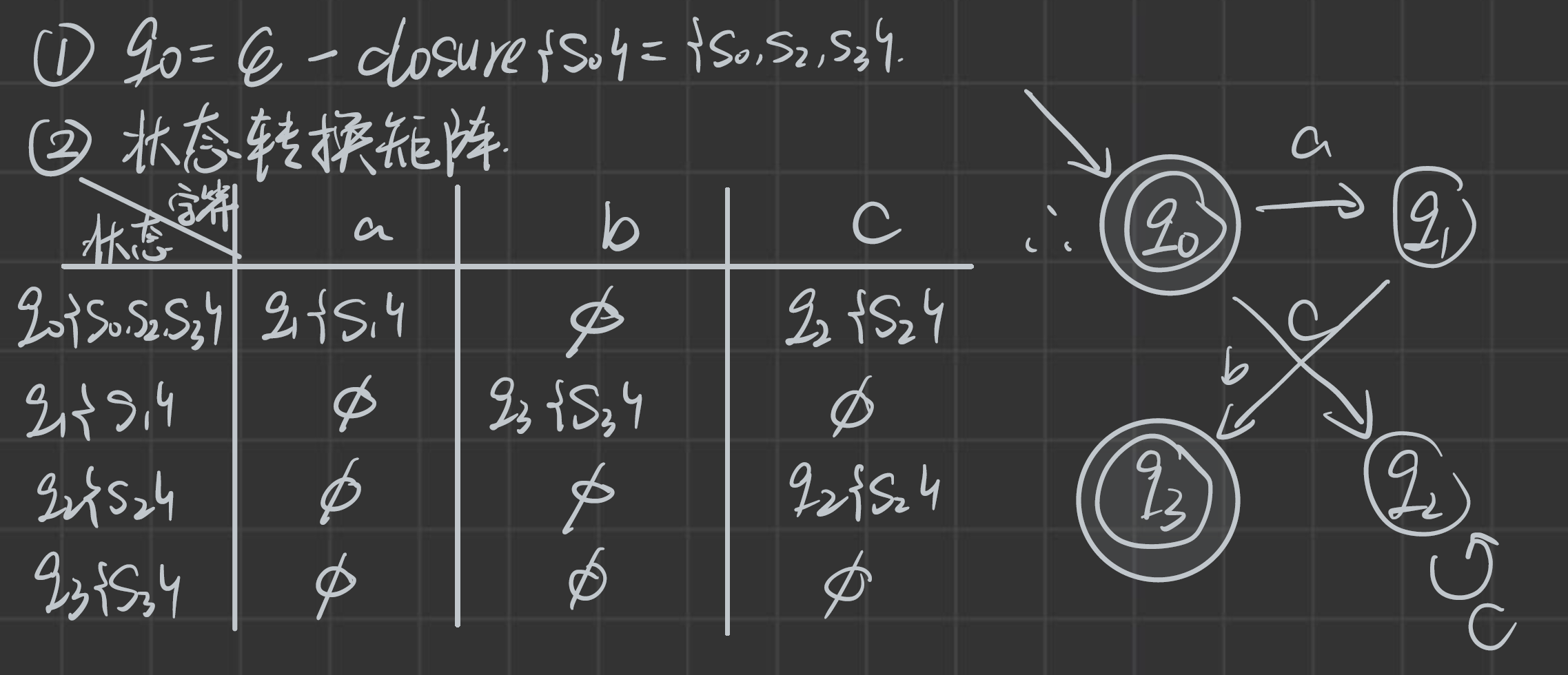

考察題目
- 沒有ε邊的有限自動機一定是DFA。(?)
解釋:
- DFA 要求每個狀態對每個輸入符號必須有且僅有一個確定的轉移。
- NFA 允許對同一輸入符號存在多個轉移(非確定性)或無轉移,即使沒有ε邊也是如此。
- 不確定的有限自動機(NFA)可能存在一個以上的起始狀態。(?)
評分標準:
(1) 正規式得2分,構造NFA得4分(共6分)
(2) 子集構造法:表格4分,DFA 4分,最簡判斷1分(9分)

(1)正規式: a ( a ∣ b ) ? b a(a|b)^*b a(a∣b)?b
這里中間部分 ( a ∣ b ) ? (a|b)^* (a∣b)?的含義在前面講解過:

中間部分的正規式可以表示為(a|b)*,但需要注意,這里中間部分可能為空,即允許字符串長度為2的情況(如ab)。因此,整個正規式可以寫成:a(a|b)*b。這個表達式表示以a開頭,中間有零個或多個a或b,最后以b結尾的所有字符串。
(2)得到NFA:
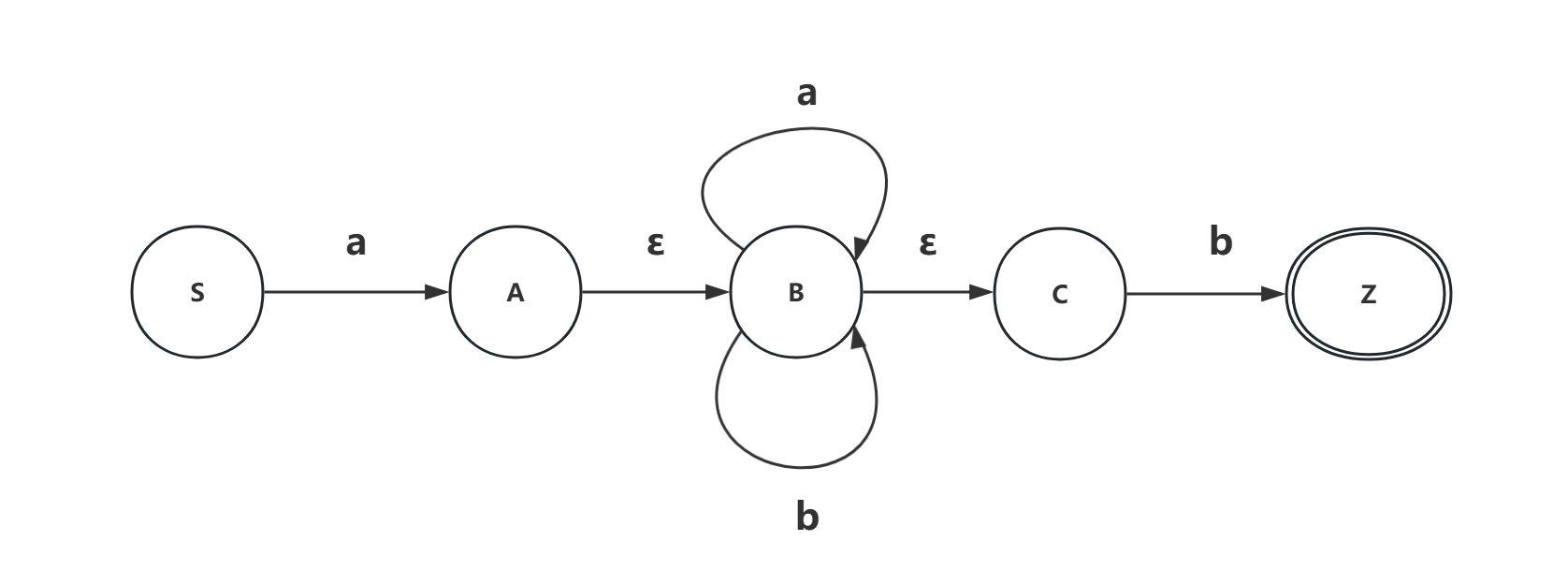
(3)根據子集構造法,得到最簡DFA:
ε-CLOSURE{S} = {S}
| I ε I_ε Iε? | I a I_a Ia? | I b I_b Ib? |
|---|---|---|
| q 0 q_0 q0?{S} | {A, B, C} q 1 q_1 q1? | ? |
| q 1 q_1 q1?{A, B, C} | {B, C} q 2 q_2 q2? | {B, C, Z} q 3 q_3 q3? |
| q 2 q_2 q2?{B, C} | {B, C} q 2 q_2 q2? | {B, C, Z} q 3 q_3 q3? |
| q 3 q_3 q3?{B, C, Z} | {B, C} q 2 q_2 q2? | {B, C, Z} q 3 q_3 q3? |
- 始態: q 0 q_0 q0?
- 終態: q 3 q_3 q3?
π = { { q 0 q_0 q0?, q 1 q_1 q1?, q 2 q_2 q2?},{ q 3 q_3 q3?}}
{ q 0 q_0 q0?, q 1 q_1 q1?, q 2 q_2 q2?}不可區分:
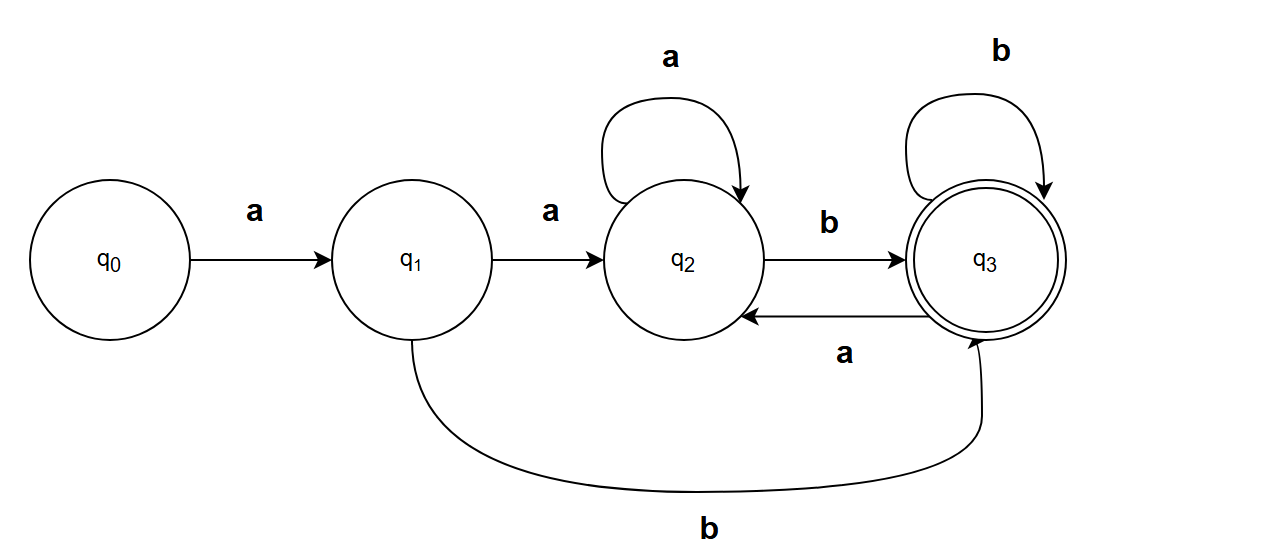
第四章:自頂向下語法分析方法
First和Follow集
求這兩個集合是后續做題的基礎,所以必須會!!!
- First(A):要找到左邊等于A的產生式,然后看產生式的右部可能出現的終結符。空串也屬于符號集。
- Follow(A):要找到產生式右部含有A的產生式,然后查看A右邊的情況,找出該非終結符后面所能跟隨的所有終結符:
- 如果A右邊是空,則將Follow(左部非終結符) 添加到結果集中
- 否則求出A右邊符號串的First集 - 空串。





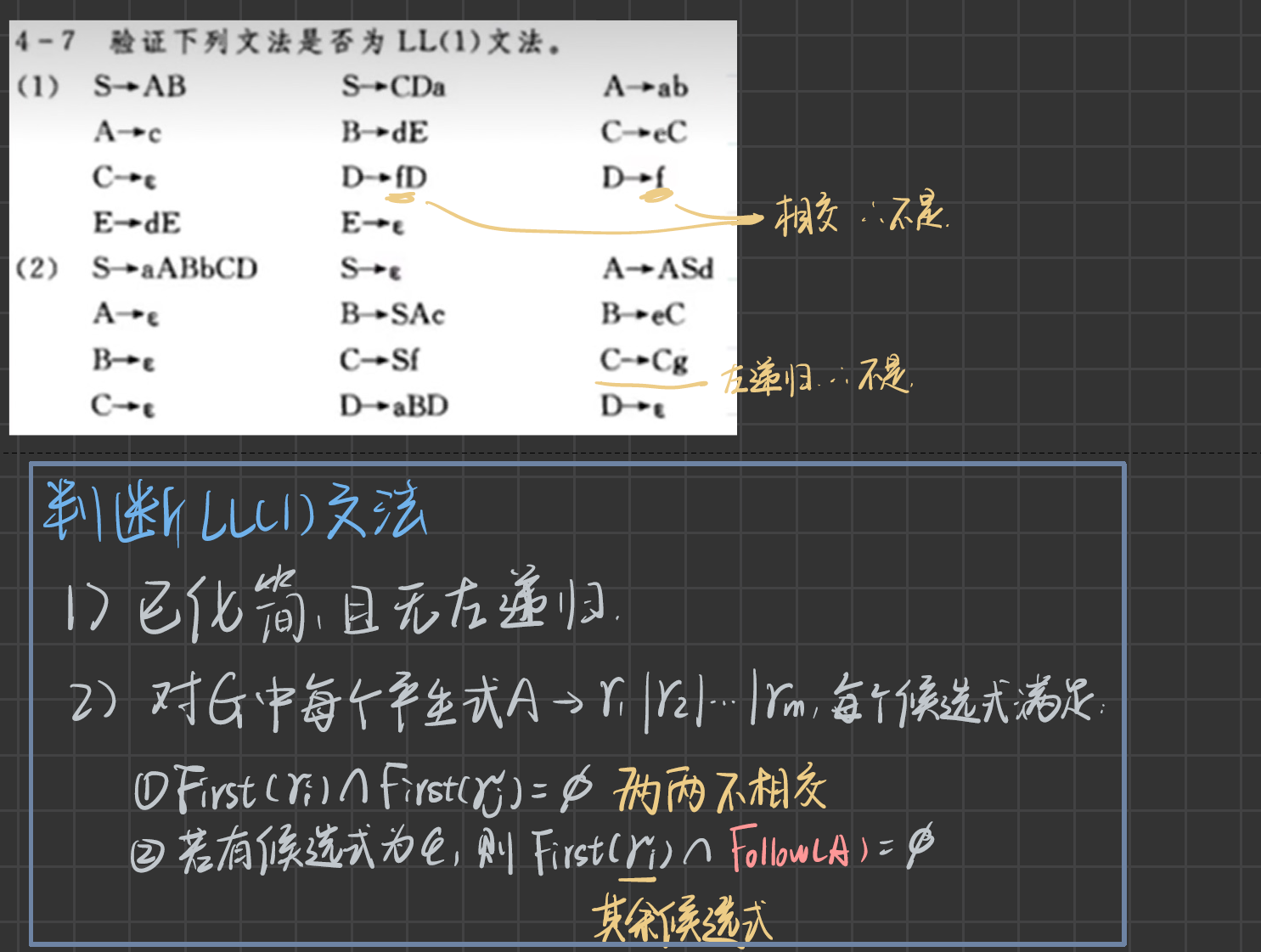
LL(1)文法
當需要選用自頂向下分析技術時(文法到字符串),必須判別所給文法是否是LL(1)文法。因而對任給文法需首先計算FIRST、FOLLOW、SELECT集合,進而判別文法是否為LL(1)文法。
LL (1) 中第一個 L 表示從左到右掃描輸入串,第二個 L 表示最左推導,1 表示向前看一個終結符。
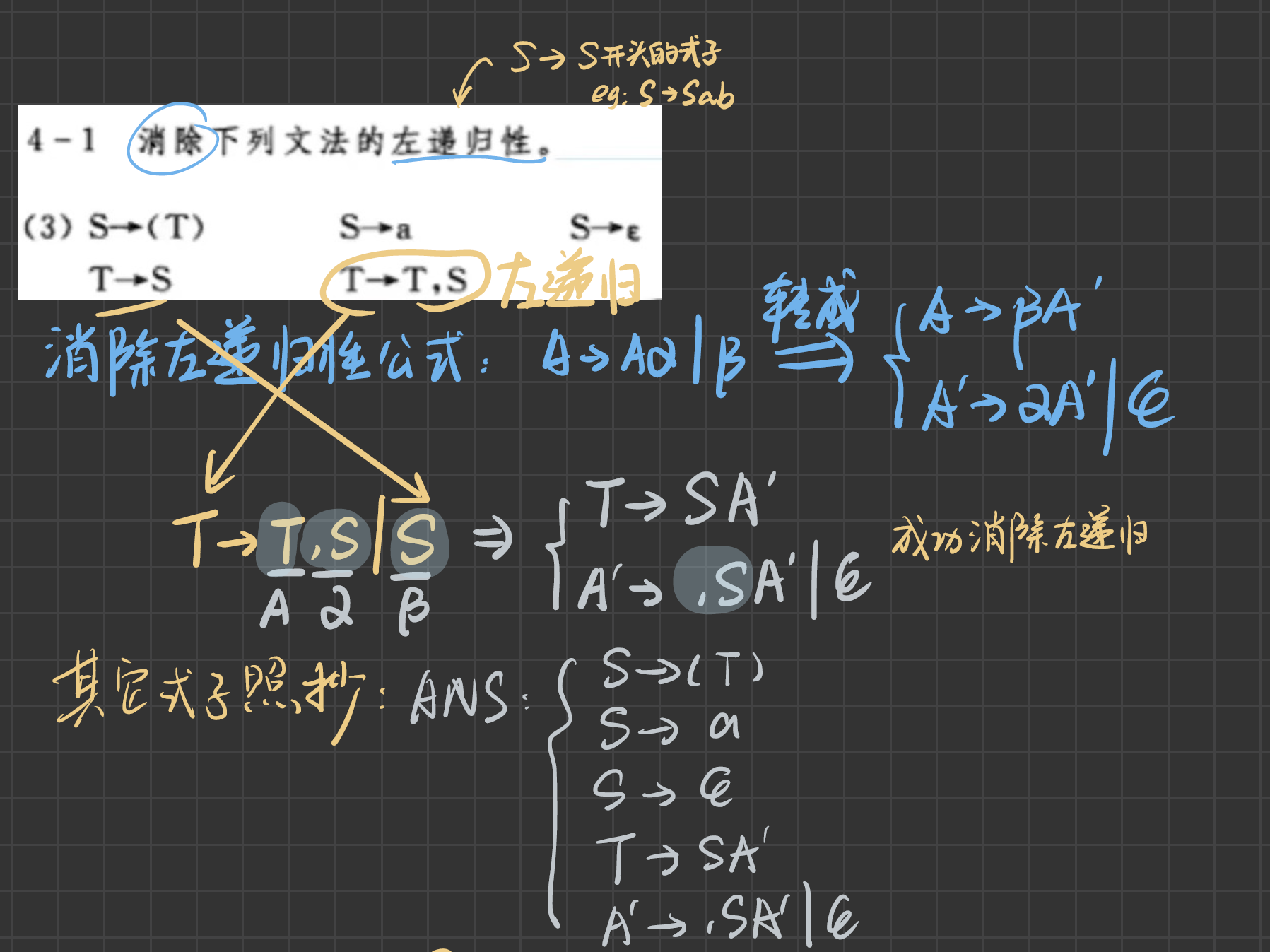
判斷一個文法是否是LL(1)文法,有兩種方式(在使用這兩個方法之前,還必須要消除文法的左遞歸和回溯):
First集的交集為空集
對于一個非終結符有多個產生式,才需要求出該非終結符的First集。

select集
選擇符號集:

- 右部推導不出空串,就是First集
- 右部可以推導出空串,就是First集-空串,左部的Follow集。

所以說,判斷一個文法是否是LL(1)文法,只需要求出 “一個非終結符號有多于兩個的產生式” 的非終結符的select集。
非LL(1)文法到LL(1)文法的等價變換
以下這兩個步驟,都是在考察LL(1)文法時要進行的第一步操作,類似于:

提取左公共因子

消除左遞歸


- 與E無關是β,這里是T
- 與E相關,出現在右邊的是α
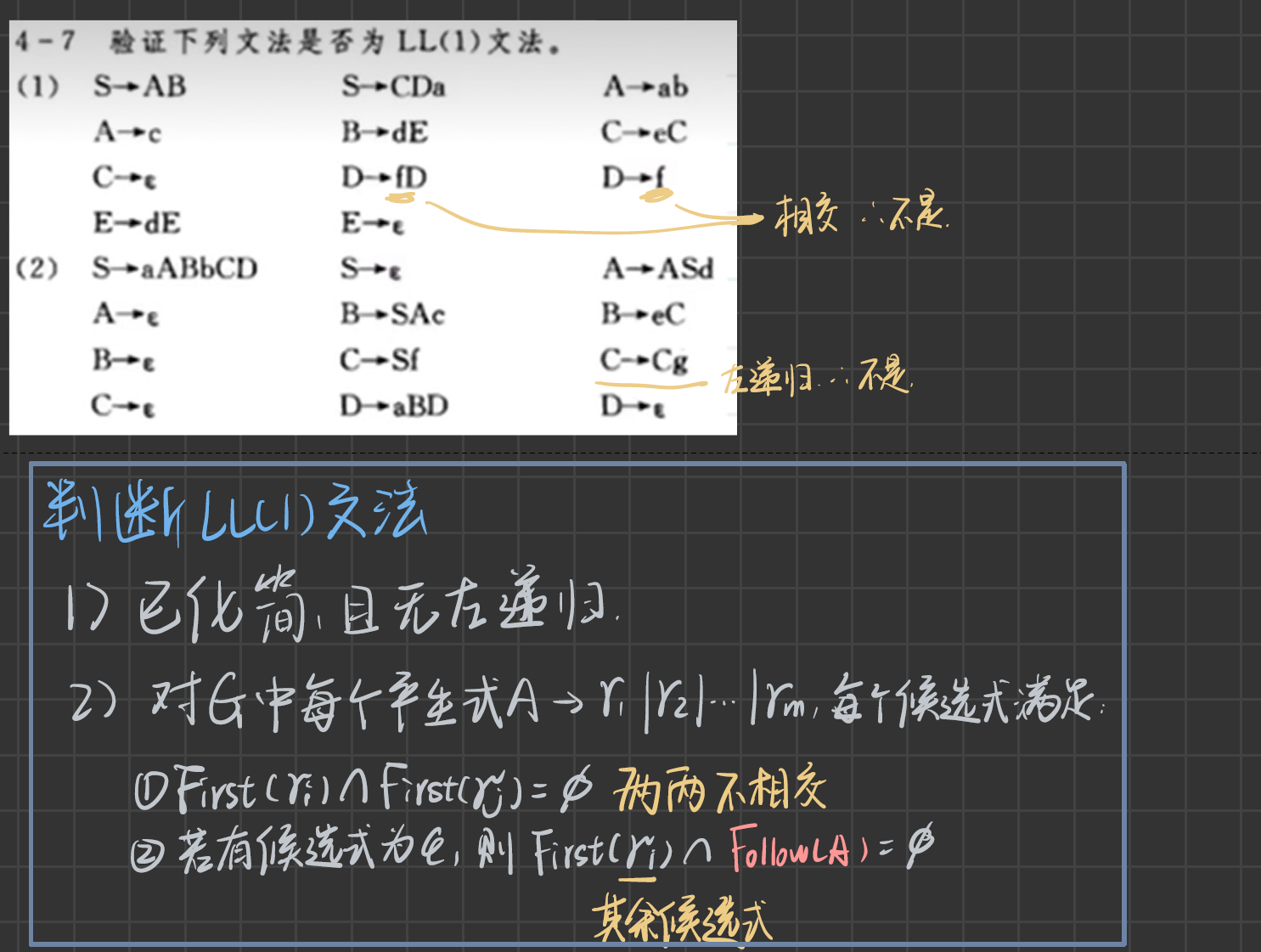


LL(1)分析的實現
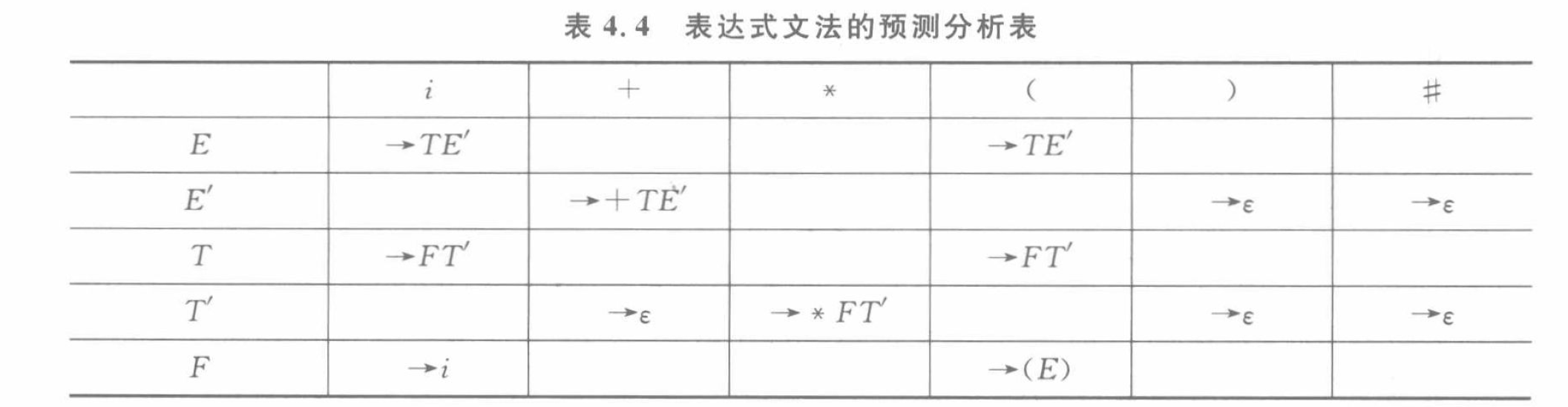
表驅動分析程序/LL(1)分析表
- 先求出First集,如果一個非終結符能推出 ε ε ε,就需要求出Follow集
- 將產生式寫到 行是非終結符,其First集為終結符的列 處



遞歸向下分析方法
- 一個非終結符對應一個子程序
- 根據產生式的右部來設計:
- 每遇到一個終結符,判斷當前讀入的單詞是否與終結符匹配,如果匹配則繼續讀下一個單詞;如果不匹配則進行錯誤處理。
- 每遇到一個非終結符,則調用對應的子程序
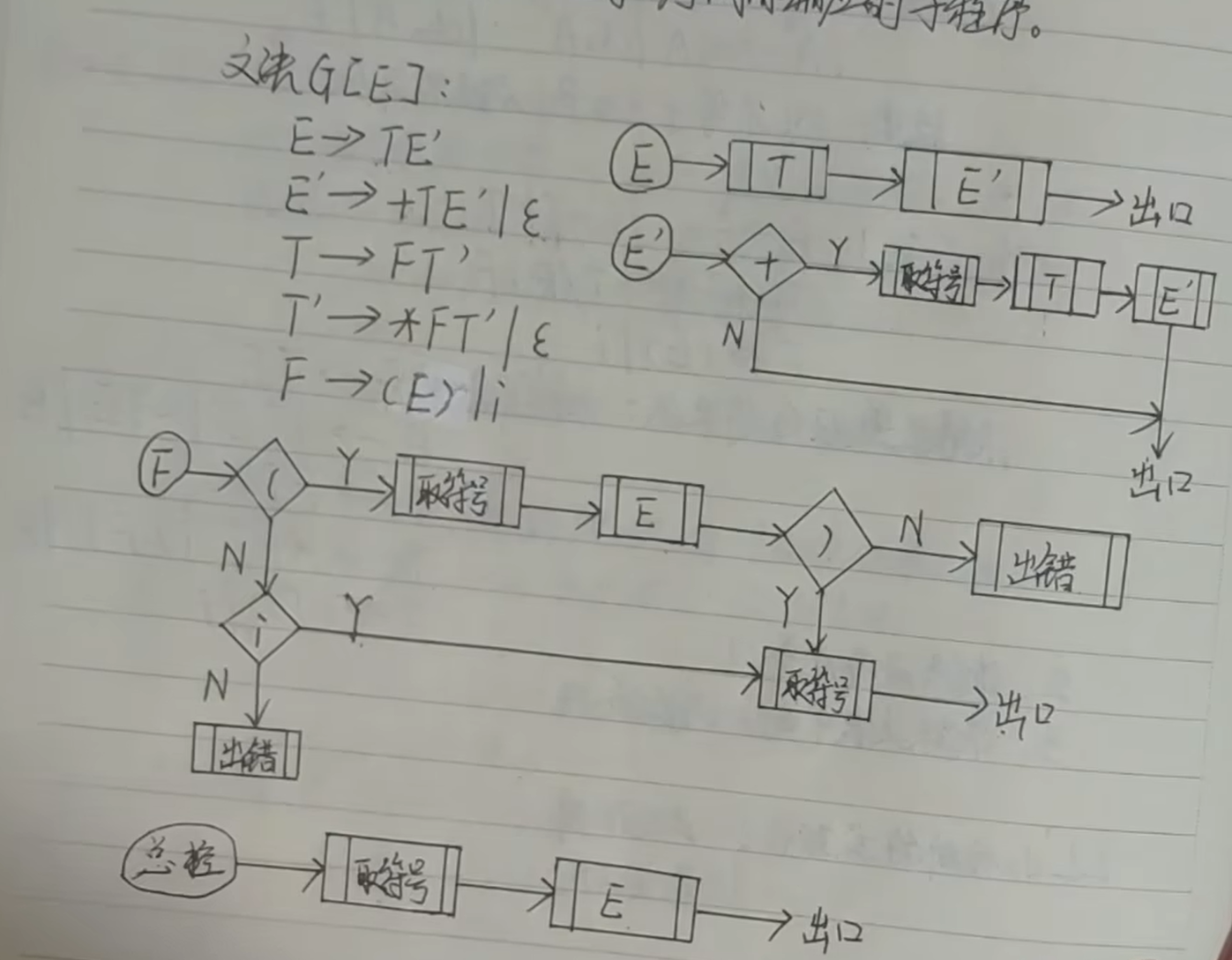
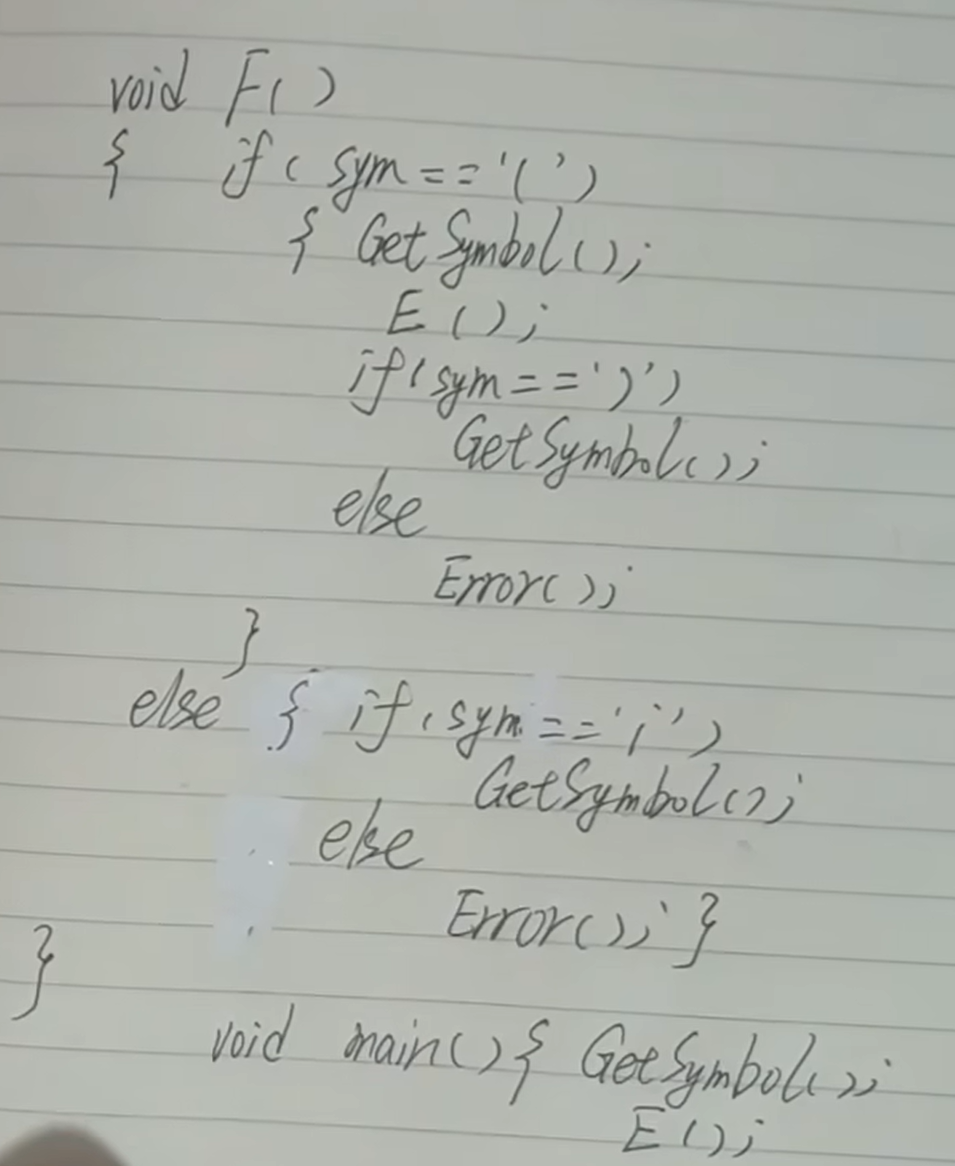
分析過程
考察題目
評分標準:文法5+集合10+分析表3+分析過程2=20

(1)消除左遞歸和左公因子后的文法:
- A → a A ′ A→a A' A→aA′
- A ′ → A B c ∣ ε A'→ABc|ε A′→ABc∣ε
- B → d B ′ B→dB' B→dB′
- B ′ → b B ′ ∣ ε B'→bB'|ε B′→bB′∣ε

(2)改造后的文法是LL(1)文法。預測分析表如下:
| 非終結符 | a | b | c | d | # |
|---|---|---|---|---|---|
| A | A → a A ′ A→a A' A→aA′ | ||||
| A’ | A ′ → A B c A'→ABc A′→ABc | A ′ → ε A'→ε A′→ε | A ′ → ε A'→ε A′→ε | ||
| B | B → d B ′ B→dB' B→dB′ | ||||
| B’ | B ′ → b B ′ B'→bB' B′→bB′ | B ′ → ε B'→ε B′→ε |
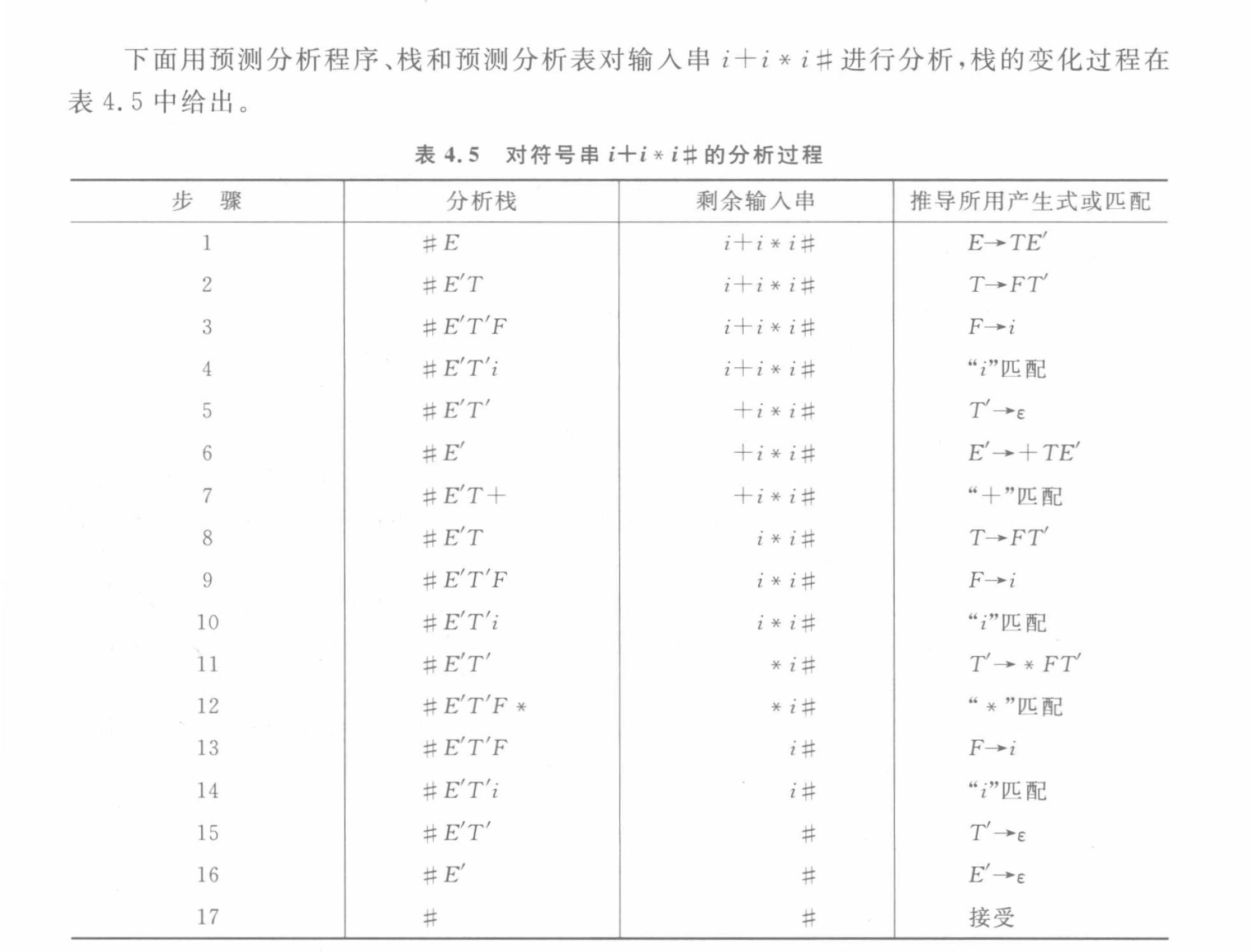
(3)輸入串 ( aadc# ) 的分析過程:
| 步驟 | 分析棧 | 剩余輸入串 | 動作 |
|---|---|---|---|
| 1 | #A | a a d c # | A → a A ′ A→a A' A→aA′ |
| 2 | #A’a | a a d c # | 匹配a |
| 3 | #A’ | a d c # | A ′ → A B c A'→ABc A′→ABc |
| 4 | #cBA | a d c # | A → a A ′ A→a A' A→aA′ |
| 5 | #cBA’a | a d c # | 匹配a |
| 6 | #cBA’ | d c # | A ′ → ε A'→ε A′→ε |
| 7 | #cB | d c # | B → d B ′ B→dB' B→dB′ |
| 8 | #cB’d | d c # | 匹配d |
| 9 | #cB’ | c # | B ′ → ε B'→ε B′→ε |
| 10 | #c | c # | 匹配c |
| 11 | # | # | 匹配#,接受 |
輸入串 ( aadc# ) 被成功分析。
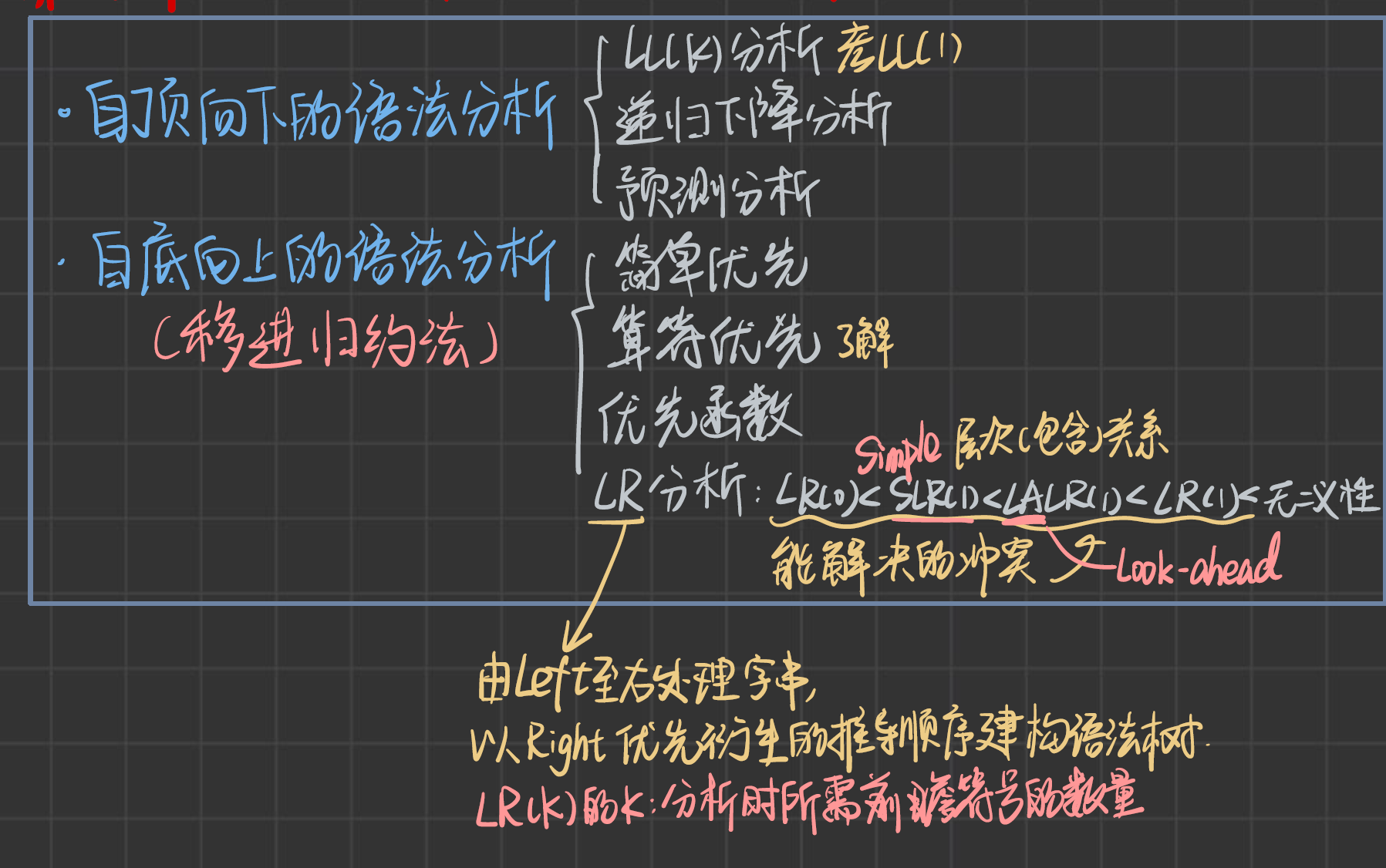
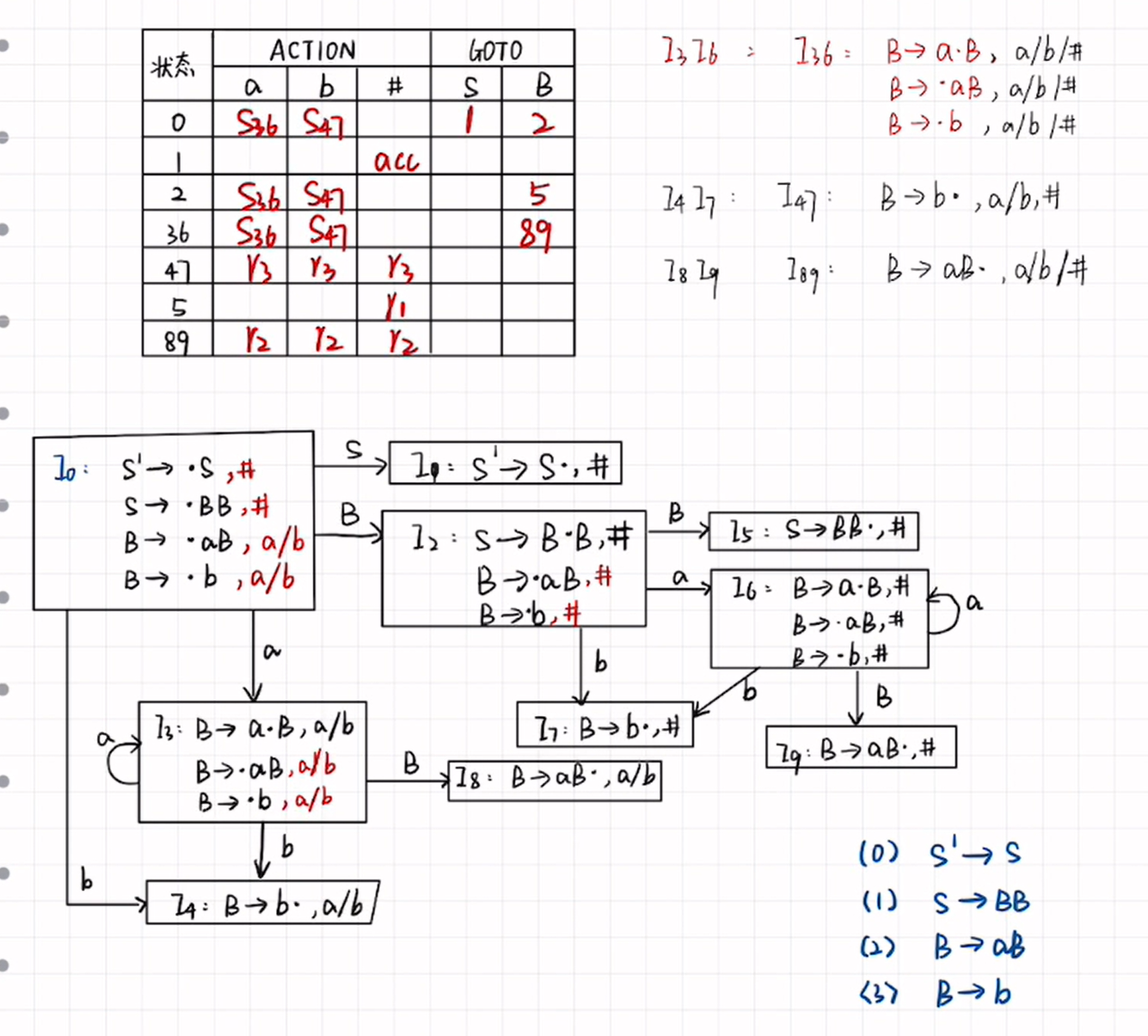
第六章:LR分析

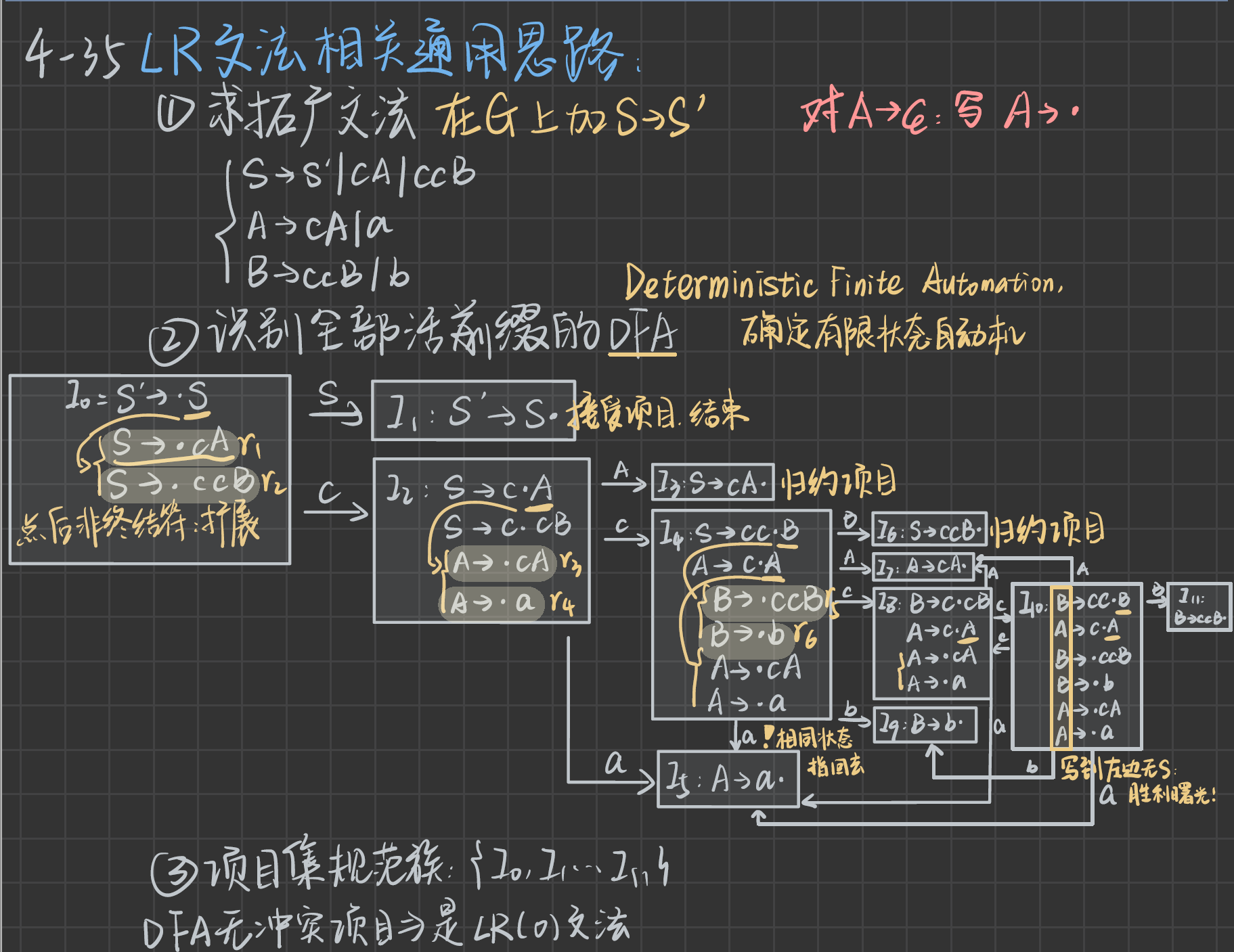
LR(0)項集規范族構造過程
- 增廣文法的變換:開始符號有多個產生式,需要對開始符號進行增廣文法的變換,使新的開始符號只有一個產生式。
- 列表的形式給出:狀態、項目集、后繼符號、后繼狀態
- 一個狀態的項目集,就是在產生式右部寫一個點,如果點后面(后繼符號)是非終結符,則需要在項目集中添加該非終結符的產生式(右部也需要帶點)

4. 還需要求 S 0 S_0 S0?的項集中每一個式子的閉包,就是把點向后移動一個,如果點后面是非終結符,就進行上面的步驟;如果是終結符/空,就結束。
5. 如果是空,其后繼符號就是把項目集抄一下,然后在前面加上一個#
6. 如果是終結符,其后繼符號就是終結符


LR(0)文法

- 如果 I i I_i Ii?里同時有歸約項目和移進項目,就是移進-歸約沖突
- 看一個狀態 I i I_i Ii?里面,是不是只存在一個歸約項目,如果狀態里有兩個歸約項目,京就是歸約-歸約沖突
- 比如 I i I_i Ii?明明是歸約狀態卻又伸出來個箭頭指向其他的狀態就說明沖突了




分析表和分析過程

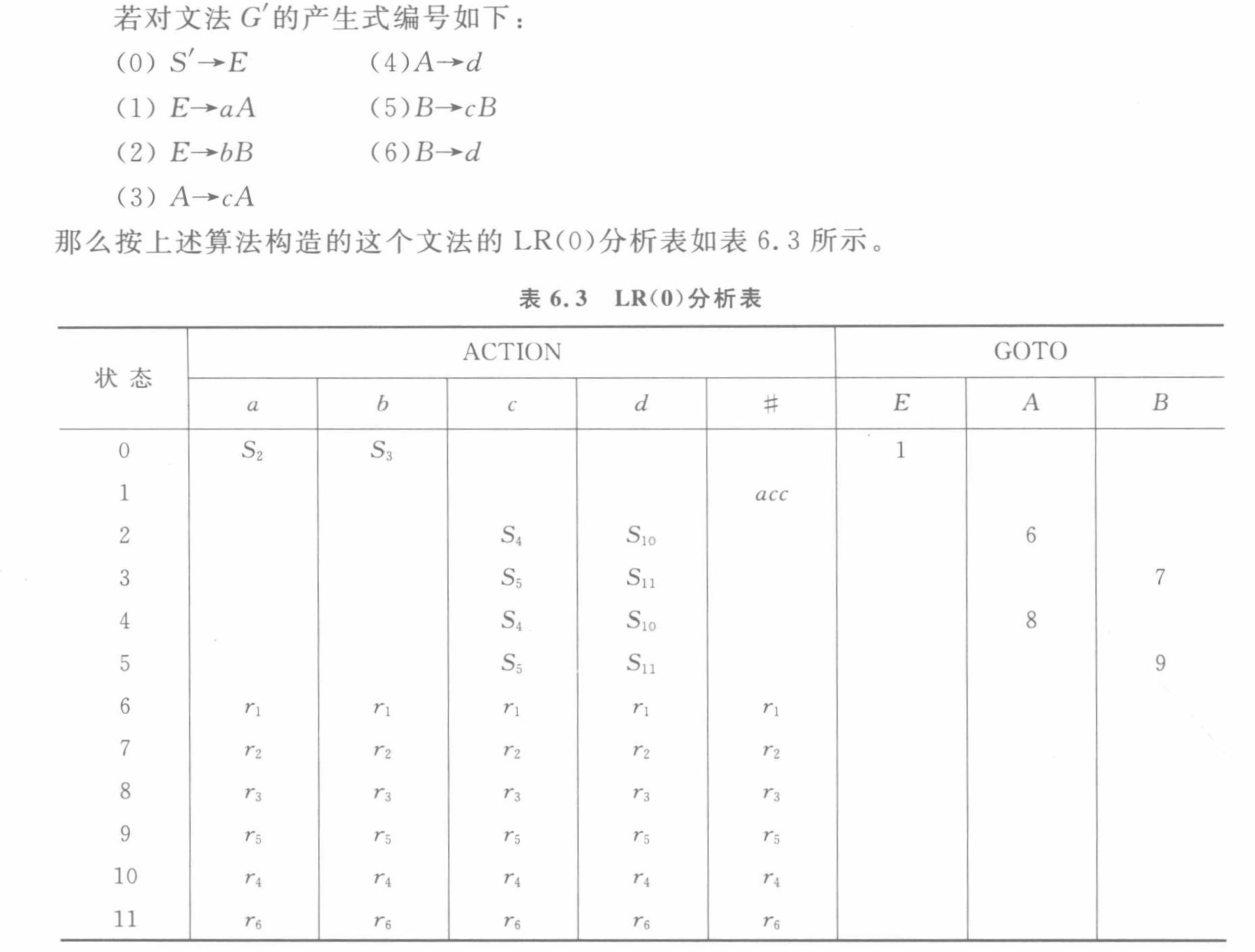
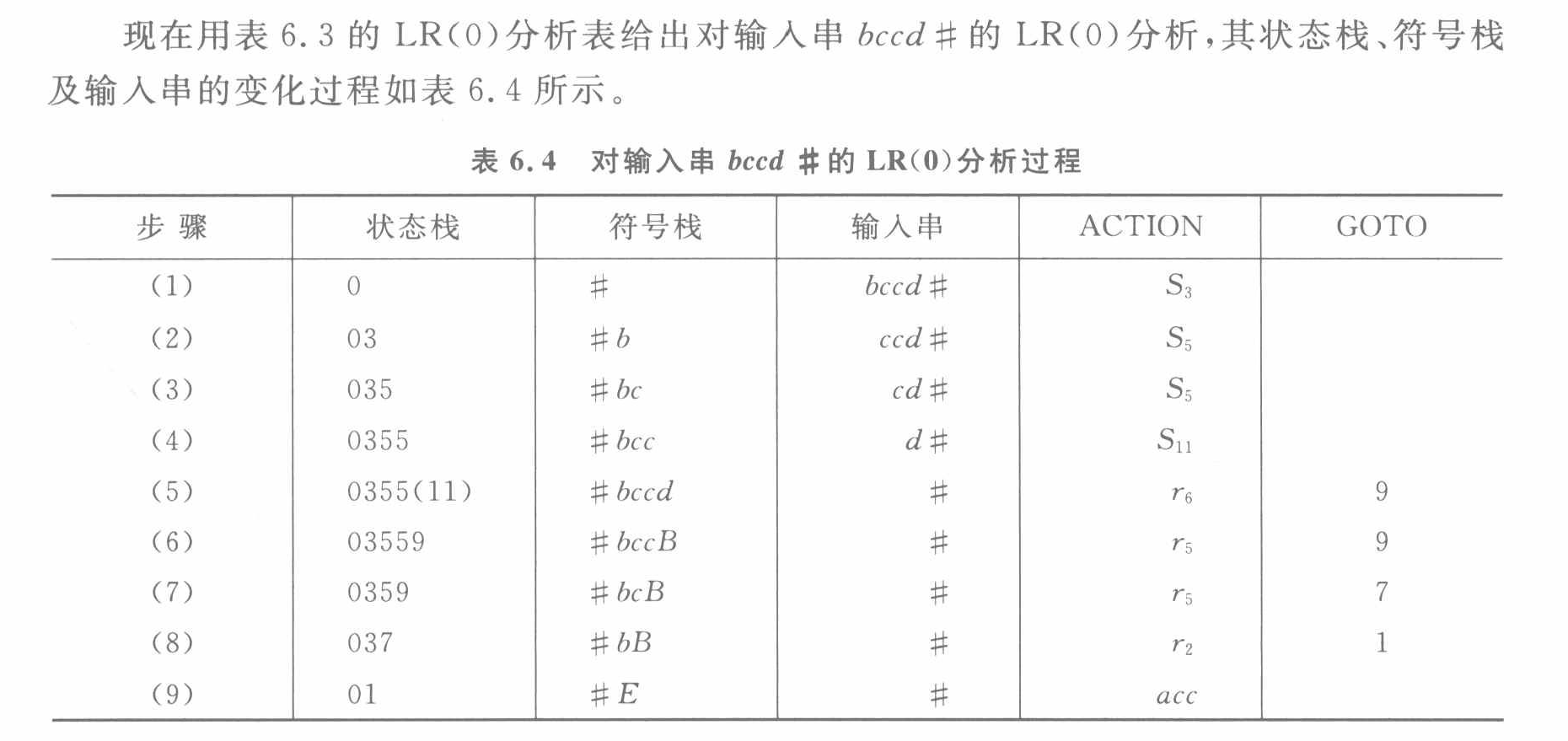
- 遇到 r i r_i ri?時,使用第 i 個歸約式進行出棧歸約,并且GOTO[狀態棧頂狀態, 非終結符],如GOTO[5, B] = 9
- 將 GOTO[狀態棧頂狀態, 非終結符] 放到狀態棧中,非終結符放到符號棧中。
- 直到 棧頂狀態,輸入串 = acc,結束
SLR(1)分析
判定
沖突項目集的簡單向前看1集合的交集為空集,則是SLR(1)語法:
- 歸約-移進沖突:歸約項的FOLLOW集,與移進項的終結符的交集。
- 歸約-歸約沖突:求兩者FOLLOW集的交集

分析表
與LR(0)分析表不同的是,對于歸約項不要將一行全使用 r i r_i ri?進行填寫,而只是在FOLLOW(A)集合所在列填寫。


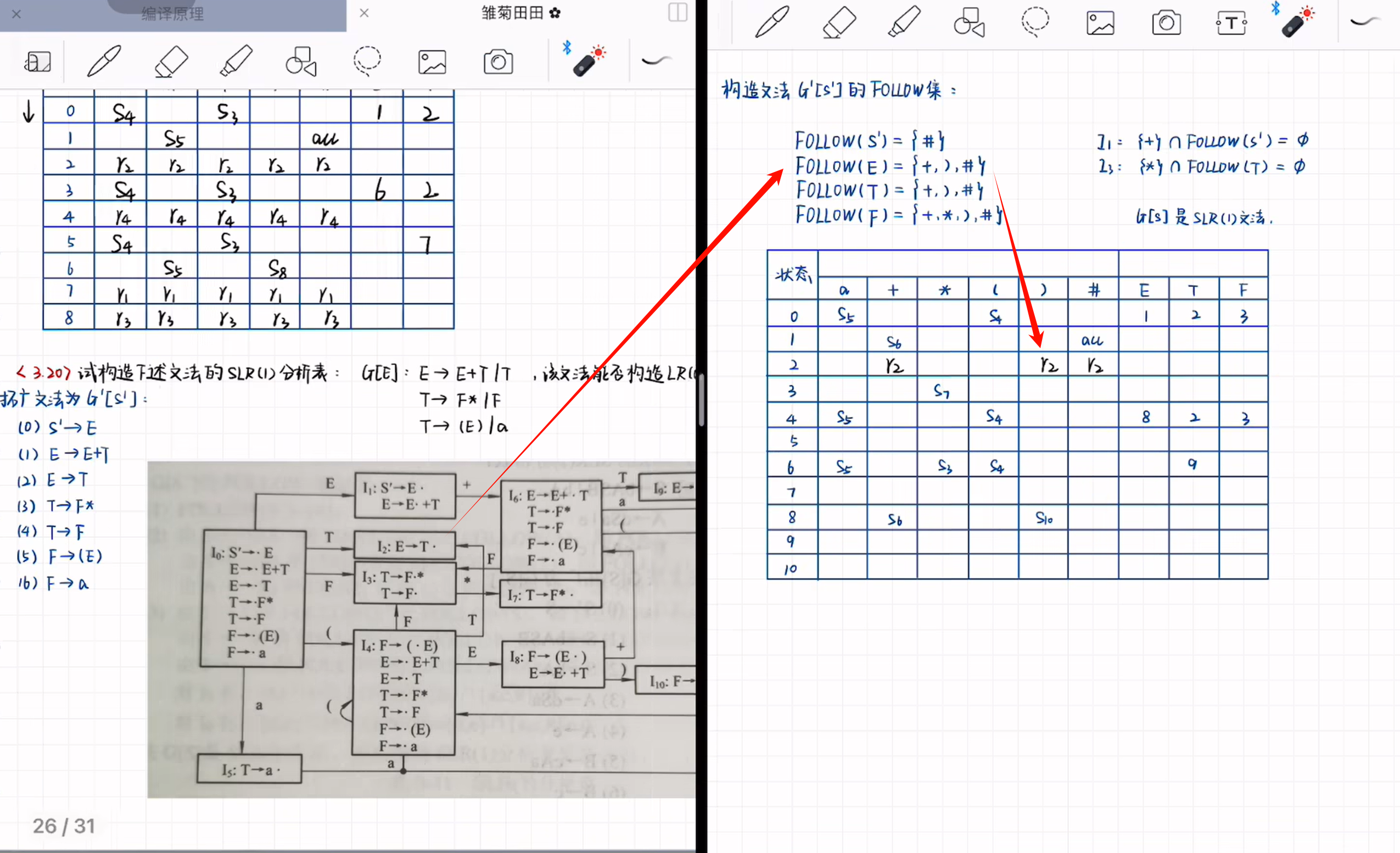
分析過程
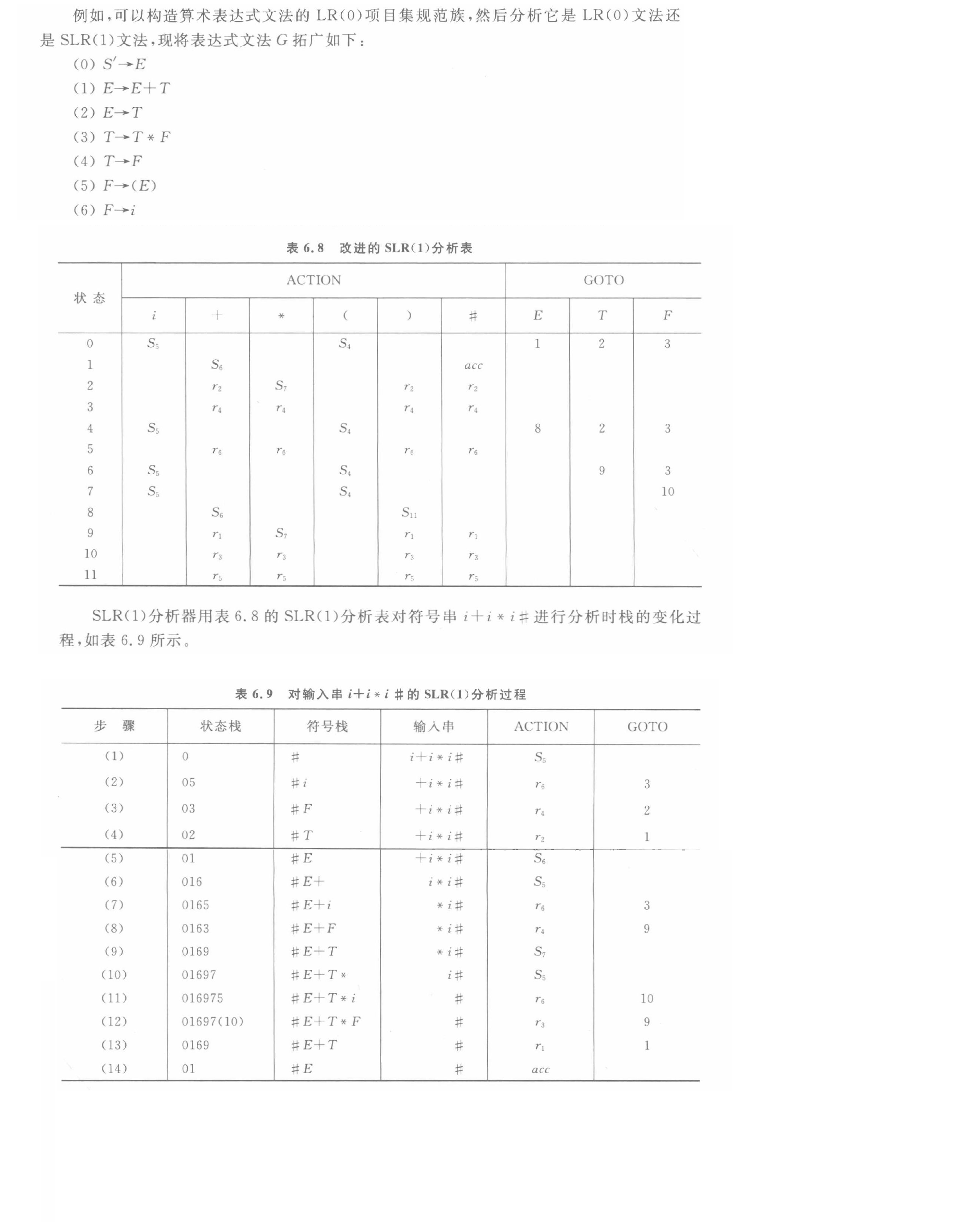
LR(1)文法

- 后繼狀態的向前搜索符,就是前一個狀態的向前搜索符。
- 當前集合的擴展閉包的向前搜索符,連接字符串的First集
沖突如何解決?
- 歸約-歸約沖突,向前搜索符不相交,就可以解決沖突
- 歸約-移進沖突,歸約項看向前搜索符,移進項還是看點后面的終結符。
表格:
- 歸約項的列,由向前搜索符決定。寫成 r i r_i ri?
- 移進項的列,由點后面的終結符決定
LR1會使同心集分裂,所以它的狀態數(項目集數)是最多的。
LALR(1)分析
- 拓廣文法
- 合并同心集:產生式相同,合并向前搜索符
- 重新構造表
如何區分LR文法
【11編譯原理如何區別LR(0),SLR(1),LR(1),LALR(1)文法】
逆波蘭表達式
找主運算符的原則:
- 括號內的表達式要先看作一個整體;
- 運算符優先級越低,也是主運算符;
- 在逆波蘭表達式中越是右邊的,越是主運算符
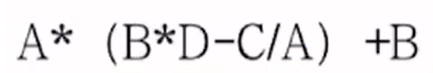
對于這個中綴表達式:
- 先將括號內部的表達式看作一個整體: E 1 = ( B ? D ? C / A ) E_1 = (B*D-C/A) E1?=(B?D?C/A),表達式變為 A ? E 1 + B A*E_1+B A?E1?+B
- 對于 A ? E 1 + B A*E_1+B A?E1?+B表達式,比較*和+的優先級,+的優先級較低,作為主運算符,寫在逆波蘭表達式的最后: ( A ? E 1 ) B + (A*E_1)B+ (A?E1?)B+










:解釋器風格)









