文章目錄
- 使用LangGraph進行智能體開發
- 什么是智能體?
- 核心特性
- 高層構建模塊
- 包生態系統
- 運行代理
- 基礎用法
- 輸入與輸出
- 輸入格式
- 使用自定義 Agent 狀態
- 輸出格式
- 流式輸出
- 最大迭代次數
- 其他資源
- 流式傳輸
- 代理進度監控
- LLM 令牌
- 工具更新
- 流式多模態傳輸
- 禁用流式傳輸
- 其他資源
- LangGraph 代理模型文檔
- 模型
- 工具調用支持
- 通過名稱指定模型
- 使用 `init_chat_model` 工具
- 使用特定供應商的大語言模型
- 禁用流式傳輸
- 添加模型回退機制
- 其他資源
- 工具
- 定義簡單工具
- 自定義工具
- 對模型隱藏參數
- 禁用并行工具調用
- 直接返回工具結果
- 強制使用工具
- 處理工具錯誤
- 內存操作
- 預構建工具
- MCP 集成
- 使用 MCP 工具
- 自定義 MCP 服務器
- 其他資源
- 上下文
- 提供運行時上下文
- 配置(靜態上下文)
- 狀態(可變上下文)
- 長期記憶(跨對話上下文)
- 基于上下文定制提示詞
- 工具中訪問上下文
- 從工具更新上下文
- 內存機制
- 術語說明
- 短期記憶
- 管理消息歷史記錄
- 匯總消息歷史記錄
- 修剪消息歷史記錄
- 工具內讀取狀態
- 從工具寫入
- 長期記憶
- 讀取
- 寫入
- 語義搜索
- 預構建記憶工具
- 其他資源
- 人機協同機制
- 工具調用審核機制
- 與Agent Inbox配合使用
- 其他資源
- 多智能體系統
- 監督者
- 集群
- 交接機制
- 評估
- 創建評估器
- LLM 作為評判者
- 運行評估器
- 部署指南
- 創建LangGraph應用
- 安裝依賴
- 創建 `.env` 文件
- 本地啟動LangGraph服務器
- LangGraph Studio 網頁界面
- 部署
- UI 用戶界面
- 在 UI 中運行代理
- 添加人工介入循環
- 生成式 UI
使用LangGraph進行智能體開發
https://langchain-ai.github.io/langgraph/agents/overview/
LangGraph為構建基于智能體的應用程序 提供了底層原語和高級預制組件。
本節重點介紹預制、可復用的組件,旨在幫助您快速可靠地構建智能體系統——無需從頭實現編排、記憶或人工反饋處理功能。
什么是智能體?
一個智能體由三個核心組件構成:大語言模型(LLM)、可調用的工具集,以及提供指令的提示詞。
LLM 以循環方式運作。每次迭代時,它會選擇要調用的工具,提供輸入參數,接收執行結果(即觀察值),并利用該觀察值決定下一步行動。
此循環將持續進行,直到滿足終止條件——通常是當智能體已收集足夠信息來響應用戶請求時。
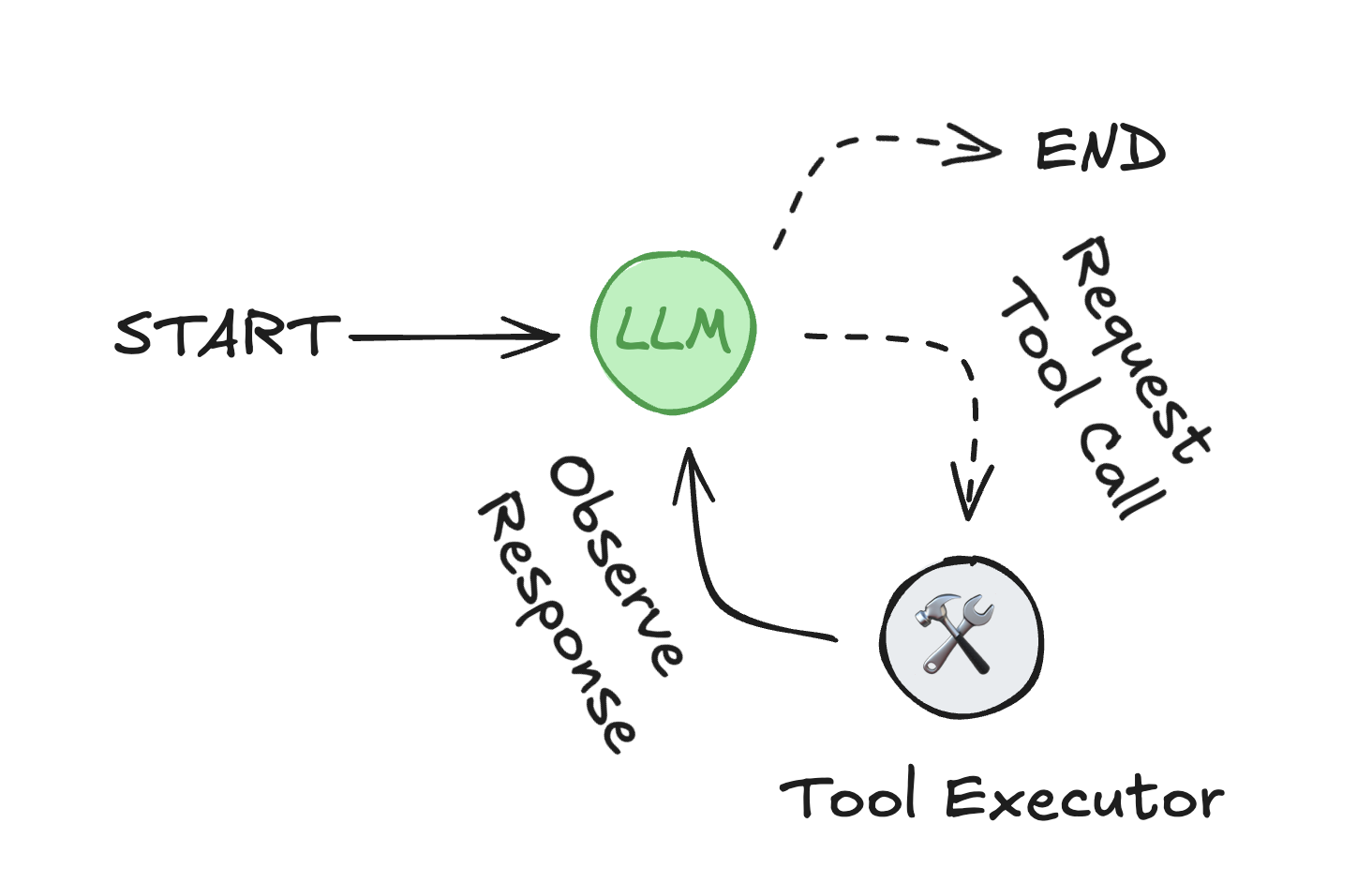
智能體循環流程:LLM通過選擇工具 并利用其輸出 來完成用戶請求。
核心特性
LangGraph 提供了一系列構建健壯、生產級智能代理系統的關鍵能力:
- 記憶集成:原生支持短期(基于會話)和長期(跨會話持久化)記憶,使聊天機器人和助手具備狀態保持能力。
- 人工介入控制:執行過程可無限期暫停以等待人工反饋——不同于受限于實時交互的 WebSocket 方案。該特性支持在工作流 任意節點 進行異步審批、修正或干預。
- 流式支持:實時流式傳輸代理狀態、模型令牌、工具輸出或組合流。
- 部署工具鏈:包含無基礎設施依賴的部署工具。LangGraph平臺支持測試、調試和部署。
- Studio:可視化IDE,用于檢查和調試工作流。
- 支持多種生產級部署方案。
高層構建模塊
LangGraph 提供了一系列預構建組件,用于實現常見的智能體行為和工作流。
這些抽象構建在 LangGraph 框架之上,既能加速生產部署,又能保持高級定制的靈活性。
使用 LangGraph 開發智能體時,您可以專注于應用程序的邏輯和行為,而無需構建和維護狀態管理、記憶存儲以及人工反饋等底層基礎設施。
包生態系統
高層級組件被組織成多個功能聚焦的獨立包。
| 包名稱 | 描述 | 安裝方式 |
|---|---|---|
langgraph-prebuilt (屬于langgraph) | 預構建組件用于創建智能體 | pip install -U langgraph langchain |
langgraph-supervisor | 構建監督者智能體的工具集 | pip install -U langgraph-supervisor |
langgraph-swarm | 構建集群多智能體系統的工具 | pip install -U langgraph-swarm |
langchain-mcp-adapters | 連接MCP服務器的工具與資源集成接口 | pip install -U langchain-mcp-adapters |
langmem | 智能體記憶管理:短期與長期記憶 | pip install -U langmem |
agentevals | 用于評估智能體性能的實用工具 | pip install -U agentevals |
(注:嚴格保留所有代碼塊、鏈接格式及專有名詞,被動語態轉換為主動表述,合并了重復的致謝段落,刪除多余空行)
運行代理
https://langchain-ai.github.io/langgraph/agents/run_agents/
代理支持同步和異步兩種執行方式:
- 使用
.invoke()或await .invoke()獲取完整響應 - 使用
.stream()或.astream()獲取增量式的流式輸出
本節將說明如何提供輸入、解析輸出、啟用流式傳輸以及控制執行限制。
基礎用法
代理(Agents)可以通過兩種主要模式執行:
- 同步模式:使用
.invoke()或.stream()方法 - 異步模式:使用
await .invoke()或配合.astream()的async for語法
同步調用
from langgraph.prebuilt import create_react_agentagent = create_react_agent(...)response = agent.invoke({"messages": [{"role": "user", "content": "what is the weather in sf"}]})
異步調用
from langgraph.prebuilt import create_react_agentagent = create_react_agent(...)
response = await agent.ainvoke({"messages": [{"role": "user", "content": "what is the weather in sf"}]})
輸入與輸出
智能體使用一個語言模型,該模型期望接收messages列表作為輸入。
因此,智能體的輸入和輸出 都以messages列表的形式 存儲在狀態中的messages鍵下。
輸入格式
Agent 的輸入必須是一個 包含 messages 鍵的字典。支持的格式如下:
| 格式 | 示例 |
|---|---|
| 字符串 | {"messages": "Hello"} — 將被解析為 HumanMessage |
| 消息字典 | {"messages": {"role": "user", "content": "Hello"}} |
| 消息列表 | {"messages": [{"role": "user", "content": "Hello"}]} |
| 帶自定義狀態 | {"messages": [{"role": "user", "content": "Hello"}], "user_name": "Alice"} — 需配合自定義的 state_schema 使用 |
消息會自動轉換為 LangChain 的內部消息格式。您可以在 LangChain 消息文檔 中了解更多信息。
使用自定義 Agent 狀態
您可以直接在輸入字典中添加 Agent 狀態模式中定義的額外字段。這允許基于運行時數據或先前工具輸出來實現動態行為。
完整說明請參閱 上下文指南。
注意:當 messages 接收字符串輸入時,會轉換為 HumanMessage。
此行為與 create_react_agent 中的 prompt 參數不同——后者在接收字符串時會解析為 SystemMessage。
輸出格式
代理輸出是一個包含以下內容的字典:
messages:執行過程中交換的所有消息列表(用戶輸入、助手回復、工具調用)。- 可選字段
structured_response,前提是已配置結構化輸出。 - 如果使用自定義的
state_schema,輸出中可能還包含與您定義字段對應的額外鍵。這些鍵可以保存來自工具執行或提示邏輯的更新狀態值。
有關處理自定義狀態模式及訪問上下文的更多細節,請參閱上下文指南。
流式輸出
智能代理支持流式響應,以實現更靈敏的應用程序交互。具體功能包括:
- 進度更新 - 每個步驟執行后實時推送
- LLM令牌流 - 生成過程中逐令牌輸出
- 自定義工具消息 - 任務執行期間動態發送
流式傳輸同時支持同步和異步兩種模式:
同步流式傳輸
for chunk in agent.stream({"messages": [{"role": "user", "content": "what is the weather in sf"}]},stream_mode="updates"
):print(chunk)
異步流式傳輸
async for chunk in agent.astream({"messages": [{"role": "user", "content": "what is the weather in sf"}]},stream_mode="updates"
):print(chunk)
提示: 有關完整詳情,請參閱流式處理指南。
最大迭代次數
為了控制代理執行并避免無限循環,可以設置遞歸限制。
該參數定義了代理在拋出GraphRecursionError之前能夠執行的最大步驟數。
您可以在運行時或通過.with_config()定義代理時配置recursion_limit參數:
運行時
from langgraph.errors import GraphRecursionError
from langgraph.prebuilt import create_react_agentmax_iterations = 3
recursion_limit = 2 * max_iterations + 1
agent = create_react_agent(model="anthropic:claude-3-5-haiku-latest",tools=[get_weather]
)try:response = agent.invoke({"messages": [{"role": "user", "content": "what's the weather in sf"}]},{"recursion_limit": recursion_limit},)
except GraphRecursionError:print("Agent stopped due to max iterations.")
.with_config()
from langgraph.errors import GraphRecursionError
from langgraph.prebuilt import create_react_agentmax_iterations = 3
recursion_limit = 2 * max_iterations + 1
agent = create_react_agent(model="anthropic:claude-3-5-haiku-latest",tools=[get_weather]
)
agent_with_recursion_limit = agent.with_config(recursion_limit=recursion_limit)try:response = agent_with_recursion_limit.invoke({"messages": [{"role": "user", "content": "what's the weather in sf"}]},)
except GraphRecursionError:print("Agent stopped due to max iterations.")
其他資源
- LangChain 中的異步編程
流式傳輸
https://langchain-ai.github.io/langgraph/agents/streaming/
流式傳輸是構建響應式應用程序的關鍵。您通常會需要傳輸以下幾種類型的數據:
1、智能體進度 —— 在智能體圖中每個節點執行后獲取更新。
2、大語言模型詞元 —— 當語言模型生成詞元時實時傳輸。
3、自定義更新 —— 在執行過程中從工具發出自定義數據(例如"已獲取10/100條記錄")。
您可以同時傳輸多種類型的數據。

等待是留給鴿子的。
代理進度監控
要實時獲取代理的執行進度,可以使用 stream() 或 astream() 方法,并設置參數 stream_mode="updates"。這種方式會在每個代理步驟完成后觸發事件通知。
例如,假設某個代理需要調用工具一次,您將觀察到以下更新序列:
- LLM節點:包含工具調用請求的AI消息
- 工具節點:包含執行結果的工具消息
- LLM節點:最終的AI響應
Sync
agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[get_weather],
)
for chunk in agent.stream({"messages": [{"role": "user", "content": "what is the weather in sf"}]},stream_mode="updates"
):print(chunk)print("\n")
Async
agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[get_weather],
)
async for chunk in agent.astream({"messages": [{"role": "user", "content": "what is the weather in sf"}]},stream_mode="updates"
):print(chunk)print("\n")
LLM 令牌
要實時獲取大語言模型(LLM)生成的令牌流,請使用 stream_mode="messages":
Sync
agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[get_weather],
)
for token, metadata in agent.stream({"messages": [{"role": "user", "content": "what is the weather in sf"}]},stream_mode="messages"
):print("Token", token)print("Metadata", metadata)print("\n")
Async
agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[get_weather],
)
async for token, metadata in agent.astream({"messages": [{"role": "user", "content": "what is the weather in sf"}]},stream_mode="messages"
):print("Token", token)print("Metadata", metadata)print("\n")
工具更新
要實時獲取工具執行時的更新流,可以使用 get_stream_writer.
Sync
from langgraph.config import get_stream_writerdef get_weather(city: str) -> str:"""Get weather for a given city."""writer = get_stream_writer()# stream any arbitrary datawriter(f"Looking up data for city: {city}")return f"It's always sunny in {city}!"agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[get_weather],
)for chunk in agent.stream({"messages": [{"role": "user", "content": "what is the weather in sf"}]},stream_mode="custom"
):print(chunk)print("\n")
Async
from langgraph.config import get_stream_writerdef get_weather(city: str) -> str:"""Get weather for a given city."""writer = get_stream_writer()# stream any arbitrary datawriter(f"Looking up data for city: {city}")return f"It's always sunny in {city}!"agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[get_weather],
)async for chunk in agent.astream({"messages": [{"role": "user", "content": "what is the weather in sf"}]},stream_mode="custom"
):print(chunk)print("\n")
注意:如果在工具中添加 get_stream_writer,將無法在 LangGraph 執行上下文之外調用該工具。
流式多模態傳輸
您可以通過將流模式以列表形式傳遞來指定多種流式傳輸模式:stream_mode=["updates", "messages", "custom"]:
Sync
agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[get_weather],
)for stream_mode, chunk in agent.stream({"messages": [{"role": "user", "content": "what is the weather in sf"}]},stream_mode=["updates", "messages", "custom"]
):print(chunk)print("\n")
Async
agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[get_weather],
)async for stream_mode, chunk in agent.astream({"messages": [{"role": "user", "content": "what is the weather in sf"}]},stream_mode=["updates", "messages", "custom"]
):print(chunk)print("\n")
禁用流式傳輸
在某些應用場景中,您可能需要針對特定模型禁用單個令牌的流式傳輸功能。這在多智能體系統中尤為實用,可用于控制哪些智能體輸出流式數據。
具體操作方法請參閱模型指南中關于禁用流式傳輸的章節。
其他資源
- LangGraph 中的流式處理
LangGraph 代理模型文檔
官方文檔鏈接 : https://langchain-ai.github.io/langgraph/agents/models/
代理模型支持:
- Anthropic
- OpenAI
模型
本頁介紹如何配置智能體所使用的聊天模型。
工具調用支持
要啟用工具調用代理功能,底層大語言模型(LLM)必須支持工具調用。
兼容模型列表可在LangChain集成目錄中查閱。
通過名稱指定模型
您可以通過模型名稱字符串來配置代理:
OpenAI
import os
from langgraph.prebuilt import create_react_agentos.environ["OPENAI_API_KEY"] = "sk-..."agent = create_react_agent(model="openai:gpt-4.1",# other parameters
)
Anthropic
import os
from langgraph.prebuilt import create_react_agentos.environ["ANTHROPIC_API_KEY"] = "sk-..."agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",# other parameters
)
Azure
import os
from langgraph.prebuilt import create_react_agentos.environ["AZURE_OPENAI_API_KEY"] = "..."
os.environ["AZURE_OPENAI_ENDPOINT"] = "..."
os.environ["OPENAI_API_VERSION"] = "2025-03-01-preview"agent = create_react_agent(model="azure_openai:gpt-4.1",# other parameters
)
Google Gemini
import os
from langgraph.prebuilt import create_react_agentos.environ["GOOGLE_API_KEY"] = "..."agent = create_react_agent(model="google_genai:gemini-2.0-flash",# other parameters
)
AWS Bedrock
from langgraph.prebuilt import create_react_agent# Follow the steps here to configure your credentials:
# https://docs.aws.amazon.com/bedrock/latest/userguide/getting-started.htmlagent = create_react_agent(model="bedrock_converse:anthropic.claude-3-5-sonnet-20240620-v1:0",# other parameters
)
使用 init_chat_model 工具
參考:https://blog.csdn.net/lovechris00/article/details/148014663?spm=1001.2014.3001.5501#3_381
來配置 OpenAI、Anthropic、Azure、Google Gemini、AWS Bedrock 模型
使用特定供應商的大語言模型
如果某個模型供應商未通過 init_chat_model 提供支持,您可以直接實例化該供應商的模型類。該模型必須實現 BaseChatModel 接口 并支持工具調用功能:
API參考文檔: ChatAnthropic | create_react_agent
from langchain_anthropic import ChatAnthropic
from langgraph.prebuilt import create_react_agentmodel = ChatAnthropic(model="claude-3-7-sonnet-latest",temperature=0,max_tokens=2048
)agent = create_react_agent(model=model,# other parameters
)
示例說明
上面的例子使用了 ChatAnthropic,該模型已被 init_chat_model 支持。此處展示該模式是為了說明如何手動實例化一個無法通過 init_chat_model 獲取的模型。
禁用流式傳輸
要禁用單個LLM令牌的流式傳輸,在初始化模型時設置disable_streaming=True:
init_chat_model
from langchain.chat_models import init_chat_modelmodel = init_chat_model("anthropic:claude-3-7-sonnet-latest",disable_streaming=True
)
ChatModel
from langchain_anthropic import ChatAnthropicmodel = ChatAnthropic(model="claude-3-7-sonnet-latest",disable_streaming=True
)
請參考 API 參考文檔 獲取關于 disable_streaming 的更多Info :
添加模型回退機制
您可以使用 model.with_fallbacks([...]) 方法為不同模型或不同LLM提供商添加回退方案:
init_chat_model
from langchain.chat_models import init_chat_modelmodel_with_fallbacks = (init_chat_model("anthropic:claude-3-5-haiku-latest").with_fallbacks([init_chat_model("openai:gpt-4.1-mini"),])
)
ChatModel
from langchain_anthropic import ChatAnthropic
from langchain_openai import ChatOpenAImodel_with_fallbacks = (ChatAnthropic(model="claude-3-5-haiku-latest").with_fallbacks([ChatOpenAI(model="gpt-4.1-mini"),])
)
請參考此指南獲取更多關于模型回退機制的信息。
其他資源
- 模型集成目錄
- 使用
init_chat_model進行通用初始化
工具
https://langchain-ai.github.io/langgraph/agents/tools/
工具是一種封裝函數及其輸入模式的方法,可以傳遞給支持工具調用的聊天模型。這使得模型能夠請求執行該函數并傳入特定輸入。
您既可以自定義工具,也可以使用LangChain提供的預置集成工具。
定義簡單工具
你可以將一個普通函數傳遞給 create_react_agent 作為工具使用:
API參考文檔:create_react_agent
create_react_agent 會自動將普通函數轉換為 LangChain 工具。
from langgraph.prebuilt import create_react_agentdef multiply(a: int, b: int) -> int:"""Multiply two numbers."""return a * bcreate_react_agent(model="anthropic:claude-3-7-sonnet",tools=[multiply]
)
自定義工具
如需更精細地控制工具行為,可使用 @tool 裝飾器:
API參考文檔:tool
from langchain_core.tools import tool@tool("multiply_tool", parse_docstring=True)
def multiply(a: int, b: int) -> int:"""Multiply two numbers.Args:a: First operandb: Second operand"""return a * b
你也可以使用 Pydantic 定義自定義輸入模式:
from pydantic import BaseModel, Fieldclass MultiplyInputSchema(BaseModel):"""Multiply two numbers"""a: int = Field(description="First operand")b: int = Field(description="Second operand")@tool("multiply_tool", args_schema=MultiplyInputSchema)
def multiply(a: int, b: int) -> int:return a * b
如需更多自定義選項,請參閱自定義工具指南。
對模型隱藏參數
某些工具需要僅在運行時才能確定的參數(例如用戶ID或會話上下文),這些參數不應由模型控制。
您可以將這些參數放入智能體的state或config中,并通過工具內部訪問這些信息:
API參考文檔:InjectedState | AgentState | RunnableConfig
from langgraph.prebuilt import InjectedState
from langgraph.prebuilt.chat_agent_executor import AgentState
from langchain_core.runnables import RunnableConfigdef my_tool(# This will be populated by an LLMtool_arg: str,# access information that's dynamically updated inside the agentstate: Annotated[AgentState, InjectedState],# access static data that is passed at agent invocationconfig: RunnableConfig,
) -> str:"""My tool."""do_something_with_state(state["messages"])do_something_with_config(config)...
禁用并行工具調用
部分模型提供商支持并行執行多個工具,但也允許用戶禁用此功能。
對于支持的提供商,您可以通過在model.bind_tools()方法中設置parallel_tool_calls=False來禁用并行工具調用:
API參考文檔:init_chat_model
from langchain.chat_models import init_chat_modeldef add(a: int, b: int) -> int:"""Add two numbers"""return a + bdef multiply(a: int, b: int) -> int:"""Multiply two numbers."""return a * bmodel = init_chat_model("anthropic:claude-3-5-sonnet-latest", temperature=0)
tools = [add, multiply]
agent = create_react_agent(# disable parallel tool callsmodel=model.bind_tools(tools, parallel_tool_calls=False),tools=tools
)agent.invoke({"messages": [{"role": "user", "content": "what's 3 + 5 and 4 * 7?"}]}
)
直接返回工具結果
使用 return_direct=True 可以立即返回工具結果并終止代理循環:
API參考文檔:tool
from langchain_core.tools import tool@tool(return_direct=True)
def add(a: int, b: int) -> int:"""Add two numbers"""return a + bagent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[add]
)agent.invoke({"messages": [{"role": "user", "content": "what's 3 + 5?"}]}
)
強制使用工具
要強制代理使用特定工具,可以在 model.bind_tools() 中設置 tool_choice 選項:
API參考:tool
from langchain_core.tools import tool@tool(return_direct=True)
def greet(user_name: str) -> int:"""Greet user."""return f"Hello {user_name}!"tools = [greet]agent = create_react_agent(model=model.bind_tools(tools, tool_choice={"type": "tool", "name": "greet"}),tools=tools
)agent.invoke({"messages": [{"role": "user", "content": "Hi, I am Bob"}]}
)
避免無限循環
強制使用工具而不設置停止條件可能導致無限循環。請采用以下任一防護措施:
- 為工具標記
return_direct=True,使其在執行后終止循環。 - 設置
recursion_limit來限制執行步驟的數量。
處理工具錯誤
默認情況下,代理會捕獲工具調用期間拋出的所有異常,并將這些異常作為工具消息傳遞給大語言模型(LLM)。要控制錯誤處理方式,可以通過預構建的 ToolNode 節點(該節點在 create_react_agent 中執行工具)的 handle_tool_errors 參數進行配置:
啟用錯誤處理(默認)
from langgraph.prebuilt import create_react_agentdef multiply(a: int, b: int) -> int:"""Multiply two numbers."""if a == 42:raise ValueError("The ultimate error")return a * b# Run with error handling (default)
agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[multiply]
)
agent.invoke({"messages": [{"role": "user", "content": "what's 42 x 7?"}]}
)
禁用錯誤處理
from langgraph.prebuilt import create_react_agent, ToolNodedef multiply(a: int, b: int) -> int:"""Multiply two numbers."""if a == 42:raise ValueError("The ultimate error")return a * btool_node = ToolNode([multiply],handle_tool_errors=False # (1)!
)
agent_no_error_handling = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=tool_node
)
agent_no_error_handling.invoke({"messages": [{"role": "user", "content": "what's 42 x 7?"}]}
)
自定義錯誤處理
from langgraph.prebuilt import create_react_agent, ToolNodedef multiply(a: int, b: int) -> int:"""Multiply two numbers."""if a == 42:raise ValueError("The ultimate error")return a * btool_node = ToolNode([multiply],handle_tool_errors=("Can't use 42 as a first operand, you must switch operands!" # (1)!)
)
agent_custom_error_handling = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=tool_node
)
agent_custom_error_handling.invoke({"messages": [{"role": "user", "content": "what's 42 x 7?"}]}
)
關于不同工具錯誤處理選項的更多信息,請參見API參考。
內存操作
LangGraph 允許從工具訪問短期和長期內存。有關詳細信息,請參閱內存指南,了解以下內容:
- 如何從短期內存讀取和寫入數據
- 如何從長期內存讀取和寫入數據
預構建工具
LangChain 支持多種預構建工具集成,可用于與 API、數據庫、文件系統、網絡數據等進行交互。
這些工具擴展了智能代理的功能,并支持快速開發。
您可以在 LangChain 集成目錄 中瀏覽完整的可用集成列表。
一些常用的工具類別包括:
- 搜索:Bing、SerpAPI、Tavily
- 代碼解釋器:Python REPL、Node.js REPL
- 數據庫:SQL、MongoDB、Redis
- 網絡數據:網頁抓取與瀏覽
- API:OpenWeatherMap、NewsAPI 等
這些集成可以通過上文示例中展示的相同 tools 參數進行配置并添加到您的智能代理中。
MCP 集成
https://langchain-ai.github.io/langgraph/agents/mcp/
模型上下文協議(MCP) 是一個開放協議,它標準化了應用程序如何向語言模型提供工具和上下文。LangGraph 代理可以通過 langchain-mcp-adapters 庫使用 MCP 服務器上定義的工具。
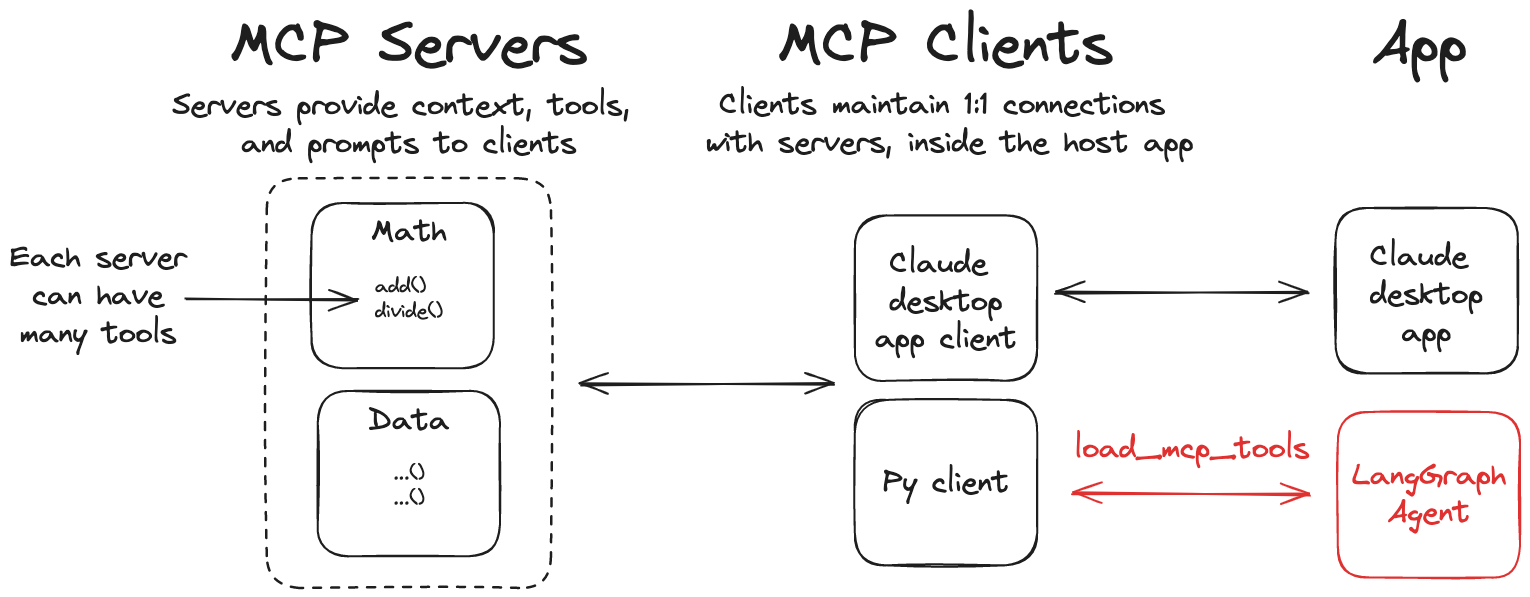
安裝 langchain-mcp-adapters 庫以在 LangGraph 中使用 MCP 工具:
pip install langchain-mcp-adapters
使用 MCP 工具
langchain-mcp-adapters 包支持代理程序使用定義在一個或多個 MCP 服務器上的工具。
代理程序可使用定義在 MCP 服務器上的工具
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.prebuilt import create_react_agentasync with MultiServerMCPClient({"math": {"command": "python",# Replace with absolute path to your math_server.py file"args": ["/path/to/math_server.py"],"transport": "stdio",},"weather": {# Ensure your start your weather server on port 8000"url": "http://localhost:8000/sse","transport": "sse",}}
) as client:agent = create_react_agent("anthropic:claude-3-7-sonnet-latest",client.get_tools())math_response = await agent.ainvoke({"messages": [{"role": "user", "content": "what's (3 + 5) x 12?"}]})weather_response = await agent.ainvoke({"messages": [{"role": "user", "content": "what is the weather in nyc?"}]})
自定義 MCP 服務器
要創建自己的 MCP 服務器,可以使用 mcp 庫。該庫提供了一種簡單的方式來定義工具并將其作為服務器運行。
安裝 MCP 庫:
pip install mcp
請使用以下參考實現來通過MCP工具服務器測試您的代理。
示例數學服務器(標準輸入輸出傳輸)
from mcp.server.fastmcp import FastMCPmcp = FastMCP("Math")@mcp.tool()
def add(a: int, b: int) -> int:"""Add two numbers"""return a + b@mcp.tool()
def multiply(a: int, b: int) -> int:"""Multiply two numbers"""return a * bif __name__ == "__main__":mcp.run(transport="stdio")
示例天氣服務器(SSE傳輸)
from mcp.server.fastmcp import FastMCPmcp = FastMCP("Weather")@mcp.tool()
async def get_weather(location: str) -> str:"""Get weather for location."""return "It's always sunny in New York"if __name__ == "__main__":mcp.run(transport="sse")
其他資源
- MCP 文檔
- MCP 傳輸協議文檔
上下文
https://langchain-ai.github.io/langgraph/agents/context/
智能體要有效運作,通常不僅需要消息列表,還需要上下文。
上下文包含消息列表之外的任何能影響智能體行為或工具執行的數據,例如:
- 運行時傳遞的信息,如
user_id或API憑證 - 在多步推理過程中更新的內部狀態
- 來自先前交互的持久化記憶或事實
LangGraph提供三種主要方式來提供上下文:
| 類型 | 描述 | 可變性 | 生命周期 |
|---|---|---|---|
| 配置 | 運行開始時傳入的數據 | ? | 單次運行有效 |
| 狀態 | 執行過程中可變的動態數據 | ? | 單次運行或會話有效 |
| 長期記憶(存儲) | 跨會話共享的數據 | ? | 跨會話持久化 |
上下文可用于:
- 調整模型看到的系統提示
- 為工具提供必要輸入
- 在持續對話中跟蹤事實
提供運行時上下文
當您需要在運行時向代理注入數據時使用此功能。
配置(靜態上下文)
Config 用于存儲不可變數據,例如用戶元數據或 API 密鑰。當您需要在程序運行期間保持不變的數值時使用此功能。
通過名為 “configurable” 的專用鍵來指定配置(該鍵名為此功能保留):
agent.invoke({"messages": [{"role": "user", "content": "hi!"}]},config={"configurable": {"user_id": "user_123"}}
)
狀態(可變上下文)
狀態在運行過程中充當短期記憶。它保存著執行期間可能變化的動態數據,例如從工具或LLM輸出中派生的值。
class CustomState(AgentState):user_name: stragent = create_react_agent(# Other agent parameters...state_schema=CustomState,
)agent.invoke({"messages": "hi!","user_name": "Jane"
})
啟用記憶功能
有關如何啟用記憶功能的更多詳情,請參閱記憶指南。這是一項強大特性,可讓您在多次調用間持久化智能體的狀態。
若不啟用該功能,狀態將僅限單次智能體運行期間有效。
長期記憶(跨對話上下文)
對于跨越多個對話或會話的上下文,LangGraph 通過 store 提供了訪問長期記憶的能力。這可用于讀取或更新持久性信息(例如用戶資料、偏好設置、歷史交互記錄)。更多詳情請參閱記憶指南。
基于上下文定制提示詞
提示詞決定了智能體的行為方式。為了融入運行時上下文,您可以根據智能體的狀態或配置動態生成提示詞。
常見應用場景:
- 個性化定制
- 角色或目標定制
- 條件行為(例如用戶是管理員時)
使用配置
from langchain_core.messages import AnyMessage
from langchain_core.runnables import RunnableConfig
from langgraph.prebuilt import create_react_agent
from langgraph.prebuilt.chat_agent_executor import AgentStatedef prompt(state: AgentState,config: RunnableConfig,
) -> list[AnyMessage]:user_name = config["configurable"].get("user_name")system_msg = f"You are a helpful assistant. User's name is {user_name}"return [{"role": "system", "content": system_msg}] + state["messages"]agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[get_weather],prompt=prompt
)agent.invoke(...,config={"configurable": {"user_name": "John Smith"}}
)
使用狀態
from langchain_core.messages import AnyMessage
from langchain_core.runnables import RunnableConfig
from langgraph.prebuilt import create_react_agent
from langgraph.prebuilt.chat_agent_executor import AgentStateclass CustomState(AgentState):user_name: strdef prompt(state: CustomState
) -> list[AnyMessage]:user_name = state["user_name"]system_msg = f"You are a helpful assistant. User's name is {user_name}"return [{"role": "system", "content": system_msg}] + state["messages"]agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[...],state_schema=CustomState,prompt=prompt
)agent.invoke({"messages": "hi!","user_name": "John Smith"
})
工具中訪問上下文
工具可以通過特殊的參數注解來訪問上下文:
- 使用
RunnableConfig獲取配置信息 - 使用
Annotated[StateSchema, InjectedState]訪問智能體狀態
提示:
這些注解會阻止大語言模型(LLM)嘗試填充這些值。這些參數將對LLM隱藏。
使用配置 | 使用狀態
def get_user_info(config: RunnableConfig,
) -> str:"""Look up user info."""user_id = config["configurable"].get("user_id")return "User is John Smith" if user_id == "user_123" else "Unknown user"agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[get_user_info],
)agent.invoke({"messages": [{"role": "user", "content": "look up user information"}]},config={"configurable": {"user_id": "user_123"}}
)
from typing import Annotated
from langgraph.prebuilt import InjectedStateclass CustomState(AgentState):user_id: strdef get_user_info(state: Annotated[CustomState, InjectedState]
) -> str:"""Look up user info."""user_id = state["user_id"]return "User is John Smith" if user_id == "user_123" else "Unknown user"agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[get_user_info],state_schema=CustomState,
)agent.invoke({"messages": "look up user information","user_id": "user_123"
})
從工具更新上下文
工具可以在執行過程中更新代理的上下文(狀態和長期記憶)。這一功能對于持久化中間結果或使信息可供后續工具或提示訪問非常有用。更多信息請參閱記憶指南。
內存機制
https://langchain-ai.github.io/langgraph/agents/memory/
LangGraph 支持兩種對構建對話代理至關重要的內存類型:
- 短期記憶:通過維護會話內的消息歷史記錄來跟蹤當前對話。
- 長期記憶:跨會話存儲用戶特定數據或應用級數據。
本指南展示如何在 LangGraph 中使用這兩種內存類型與代理交互。如需深入理解內存概念,請參閱 LangGraph 內存文檔。
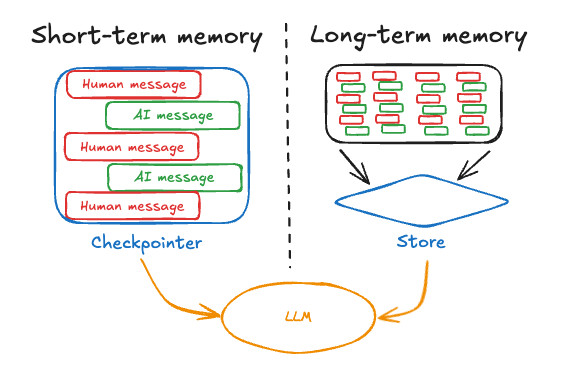
短期記憶和長期記憶都需要持久化存儲,以保持大語言模型(LLM)交互間的連續性。在生產環境中,這些數據通常存儲在數據庫中。
術語說明
在 LangGraph 中:
- 短期記憶 也被稱為 線程級內存
- 長期記憶 也被稱作 跨線程內存
線程是指通過相同 thread_id 分組的一組相關運行序列。
短期記憶
短期記憶功能使智能體能夠追蹤多輪對話。要使用該功能,您需要:
1、在創建智能體時提供一個checkpointer。該檢查點器用于持久化智能體的狀態。
2、在運行智能體時,配置中需包含thread_id參數。該線程ID是對話會話的唯一標識符。
API參考:create_react_agent | InMemorySaver
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import InMemorySavercheckpointer = InMemorySaver() # (1)!def get_weather(city: str) -> str:"""Get weather for a given city."""return f"It's always sunny in {city}!"agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[get_weather],checkpointer=checkpointer # (2)!
)# Run the agent
config = {"configurable": {"thread_id": "1" # (3)!}
}sf_response = agent.invoke({"messages": [{"role": "user", "content": "what is the weather in sf"}]},config
)# Continue the conversation using the same thread_id
ny_response = agent.invoke({"messages": [{"role": "user", "content": "what about new york?"}]},config # (4)!
)
1、InMemorySaver 是一個檢查點工具,它將智能體的狀態存儲在內存中。在生產環境中,通常需要使用數據庫或其他持久化存儲方案。更多選項請查閱檢查點文檔。如果通過 LangGraph Platform 進行部署,該平臺會為您提供生產就緒的檢查點工具。
2、檢查點工具會被傳遞給智能體。這使得智能體能夠在多次調用間保持狀態持久化。請注意:
3、配置中需要提供唯一的 thread_id。該ID用于標識會話對話,其值由用戶控制,可以是任意字符串。
4、智能體會繼續使用相同的 thread_id 進行對話。這將使智能體能夠識別出用戶正在專門詢問紐約的天氣情況。
當智能體第二次通過相同 thread_id 被調用時,首次對話的原始消息歷史會自動包含在內,使得智能體能夠推斷出用戶正在專門詢問紐約的天氣。
LangGraph Platform 提供生產就緒的檢查點工具
如果使用 LangGraph Platform 進行部署,系統會自動將檢查點工具配置為使用生產級數據庫。
管理消息歷史記錄
長對話可能會超出LLM的上下文窗口限制。常見的解決方案包括:
- 對話摘要:維護對話的持續摘要
- 消息裁剪:刪除歷史記錄中最早或最近的N條消息
這樣可以讓智能體在不超出LLM上下文窗口的情況下持續跟蹤對話。
要管理消息歷史記錄,需要指定pre_model_hook——這是一個在調用語言模型前始終運行的函數(節點)。
匯總消息歷史記錄
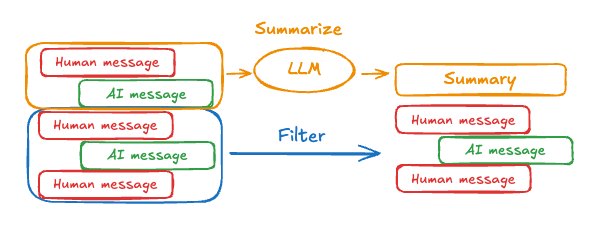
長對話可能會超出LLM的上下文窗口限制。常見的解決方案是維護對話的持續摘要。這樣可以讓智能體在不超出LLM上下文窗口的情況下跟蹤對話進度。
要匯總消息歷史記錄,您可以使用pre_model_hook配合預構建的SummarizationNode:
API參考文檔:ChatAnthropic | count_tokens_approximately | create_react_agent | AgentState | InMemorySaver
from langchain_anthropic import ChatAnthropic
from langmem.short_term import SummarizationNode
from langchain_core.messages.utils import count_tokens_approximately
from langgraph.prebuilt import create_react_agent
from langgraph.prebuilt.chat_agent_executor import AgentState
from langgraph.checkpoint.memory import InMemorySaver
from typing import Anymodel = ChatAnthropic(model="claude-3-7-sonnet-latest")summarization_node = SummarizationNode( # (1)!token_counter=count_tokens_approximately,model=model,max_tokens=384,max_summary_tokens=128,output_messages_key="llm_input_messages",
)class State(AgentState):# NOTE: we're adding this key to keep track of previous summary information# to make sure we're not summarizing on every LLM callcontext: dict[str, Any] # (2)!checkpointer = InMemorySaver() # (3)!agent = create_react_agent(model=model,tools=tools,pre_model_hook=summarization_node, # (4)!state_schema=State, # (5)!checkpointer=checkpointer,
)
1、InMemorySaver 是一個檢查點工具,它將代理的狀態存儲在內存中。在生產環境中,通常會使用數據庫或其他持久化存儲方案。更多選項請查閱檢查點文檔。若通過LangGraph平臺部署,該平臺會為您提供生產級檢查點工具。
2、context鍵被添加到代理狀態中。該鍵包含摘要節點的簿記信息,用于追蹤最近的摘要信息,確保代理不會在每次調用LLM時都執行摘要操作(這種操作可能效率低下)。
3、檢查點工具被傳遞給代理,這使得代理能在多次調用間持久化其狀態。
4、pre_model_hook被設置為SummarizationNode。該節點會在消息歷史記錄發送給LLM前進行摘要處理,自動處理摘要流程并用新摘要更新代理狀態。如需自定義實現可替換此節點,詳見create_react_agent API參考文檔。
5、state_schema被設置為自定義的State類,該類包含額外的context鍵。
修剪消息歷史記錄
要修剪消息歷史記錄,可以使用 pre_model_hook 配合 trim_messages 函數:
API參考文檔: trim_messages | count_tokens_approximately | create_react_agent
from langchain_core.messages.utils import (trim_messages,count_tokens_approximately
)
from langgraph.prebuilt import create_react_agent# This function will be called every time before the node that calls LLM
def pre_model_hook(state):trimmed_messages = trim_messages(state["messages"],strategy="last",token_counter=count_tokens_approximately,max_tokens=384,start_on="human",end_on=("human", "tool"),)return {"llm_input_messages": trimmed_messages}checkpointer = InMemorySaver()
agent = create_react_agent(model,tools,pre_model_hook=pre_model_hook,checkpointer=checkpointer,
)
要了解更多關于使用 pre_model_hook 管理消息歷史的信息,請參閱這篇操作指南。
工具內讀取狀態
LangGraph 允許智能體在工具內部訪問其短期記憶(狀態)。
API參考文檔:InjectedState | create_react_agent
from typing import Annotated
from langgraph.prebuilt import InjectedState, create_react_agentclass CustomState(AgentState):user_id: strdef get_user_info(state: Annotated[CustomState, InjectedState]
) -> str:"""Look up user info."""user_id = state["user_id"]return "User is John Smith" if user_id == "user_123" else "Unknown user"agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[get_user_info],state_schema=CustomState,
)agent.invoke({"messages": "look up user information","user_id": "user_123"
})
請參閱Context指南獲取更多信息。
從工具寫入
要在執行過程中修改代理的短期記憶(狀態),你可以直接從工具返回狀態更新。這對于持久化中間結果或使信息可供后續工具或提示訪問非常有用。
API 參考:InjectedToolCallId | RunnableConfig | ToolMessage | InjectedState | create_react_agent | AgentState | Command
from typing import Annotated
from langchain_core.tools import InjectedToolCallId
from langchain_core.runnables import RunnableConfig
from langchain_core.messages import ToolMessage
from langgraph.prebuilt import InjectedState, create_react_agent
from langgraph.prebuilt.chat_agent_executor import AgentState
from langgraph.types import Commandclass CustomState(AgentState):user_name: strdef update_user_info(tool_call_id: Annotated[str, InjectedToolCallId],config: RunnableConfig
) -> Command:"""Look up and update user info."""user_id = config["configurable"].get("user_id")name = "John Smith" if user_id == "user_123" else "Unknown user"return Command(update={"user_name": name,# update the message history"messages": [ToolMessage("Successfully looked up user information",tool_call_id=tool_call_id)]})def greet(state: Annotated[CustomState, InjectedState]
) -> str:"""Use this to greet the user once you found their info."""user_name = state["user_name"]return f"Hello {user_name}!"agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[update_user_info, greet],state_schema=CustomState
)agent.invoke({"messages": [{"role": "user", "content": "greet the user"}]},config={"configurable": {"user_id": "user_123"}}
)
更多詳情,請參閱如何從工具更新狀態。
長期記憶
利用長期記憶功能可以跨對話存儲用戶特定或應用特定的數據。這對于聊天機器人等應用場景非常有用,例如需要記住用戶偏好或其他信息的情況。
要使用長期記憶功能,您需要:
1、配置存儲以實現跨調用數據持久化
2、通過get_store函數在工具或提示中訪問存儲
讀取
一個供代理用來查詢用戶信息的工具
from langchain_core.runnables import RunnableConfig
from langgraph.config import get_store
from langgraph.prebuilt import create_react_agent
from langgraph.store.memory import InMemoryStorestore = InMemoryStore() # (1)!store.put( # (2)!("users",), # (3)!"user_123", # (4)!{"name": "John Smith","language": "English",} # (5)!
)def get_user_info(config: RunnableConfig) -> str:"""Look up user info."""# Same as that provided to `create_react_agent`store = get_store() # (6)!user_id = config["configurable"].get("user_id")user_info = store.get(("users",), user_id) # (7)!return str(user_info.value) if user_info else "Unknown user"agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[get_user_info],store=store # (8)!
)# Run the agent
agent.invoke({"messages": [{"role": "user", "content": "look up user information"}]},config={"configurable": {"user_id": "user_123"}}
)
1、InMemoryStore 是一種將數據存儲在內存中的存儲方式。在生產環境中,通常建議使用數據庫或其他持久化存儲方案。更多選項請查閱存儲文檔。若通過 LangGraph 平臺 部署,平臺將自動提供生產級存儲方案。
2、本示例中,我們使用 put 方法向存儲寫入樣本數據。具體參數說明請參閱 BaseStore.put API 文檔。
3、第一個參數是命名空間,用于對關聯數據進行分組。本例使用 users 命名空間來歸類用戶數據。
4、命名空間內的鍵值。本示例采用用戶ID作為鍵名。
5、需要為指定用戶存儲的數據內容。
6、get_store 函數用于訪問存儲。您可以在代碼任意位置(包括工具和提示中)調用該函數,它將返回代理創建時傳入的存儲實例。
7、get 方法用于從存儲檢索數據。首個參數為命名空間,次參數為鍵名,返回值為包含數據值及其元數據的 StoreValue 對象。
8、存儲實例會傳遞給代理,使代理在執行工具時可訪問存儲。您也可通過 get_store 函數在代碼任意位置訪問該存儲。
寫入
更新用戶信息的工具示例
from typing_extensions import TypedDictfrom langgraph.config import get_store
from langgraph.prebuilt import create_react_agent
from langgraph.store.memory import InMemoryStorestore = InMemoryStore() # (1)!class UserInfo(TypedDict): # (2)!name: strdef save_user_info(user_info: UserInfo, config: RunnableConfig) -> str: # (3)!"""Save user info."""# Same as that provided to `create_react_agent`store = get_store() # (4)!user_id = config["configurable"].get("user_id")store.put(("users",), user_id, user_info) # (5)!return "Successfully saved user info."agent = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[save_user_info],store=store
)# Run the agent
agent.invoke({"messages": [{"role": "user", "content": "My name is John Smith"}]},config={"configurable": {"user_id": "user_123"}} # (6)!
)# You can access the store directly to get the value
store.get(("users",), "user_123").value
1、InMemoryStore 是一種將數據存儲在內存中的存儲方式。在生產環境中,通常建議使用數據庫或其他持久化存儲方案。更多選項請查閱存儲文檔。如果通過 LangGraph 平臺 部署,該平臺會為您提供生產環境就緒的存儲方案。
2、UserInfo 類是一個 TypedDict,用于定義用戶信息的結構。大語言模型(LLM)將根據此模式格式化響應內容。
3、save_user_info 函數是一個工具函數,允許代理(agent)更新用戶信息。這在聊天應用中非常實用,例如用戶需要更新個人資料信息時。
4、get_store 函數用于訪問存儲。您可以在代碼的任何位置調用它,包括工具函數和提示語中。該函數會返回代理創建時傳入的存儲實例。
5、put 方法用于向存儲中寫入數據。第一個參數是命名空間,第二個參數是鍵名。該方法會將用戶信息存入存儲系統。
6、user_id 通過配置參數傳入,用于標識需要更新信息的對應用戶。
語義搜索
LangGraph 還支持通過語義相似度在長期記憶中進行搜索。
預構建記憶工具
LangMem 是由 LangChain 維護的庫,提供用于管理智能體長期記憶的工具。具體使用示例請參閱 LangMem 文檔。
其他資源
- LangGraph中的內存管理
人機協同機制
https://langchain-ai.github.io/langgraph/agents/human-in-the-loop/
要審查、編輯和批準智能體中的工具調用,您可以使用LangGraph內置的人機協同(HIL)功能,特別是interrupt()原語。
LangGraph允許您無限期暫停執行——無論是幾分鐘、幾小時還是幾天——直到接收到人工輸入。
這一機制之所以可行,是因為智能體狀態會被檢查點保存到數據庫中,這使得系統能夠持久化執行上下文,并在之后恢復工作流,從中斷處繼續執行。
如需深入了解人機協同概念,請參閱概念指南。
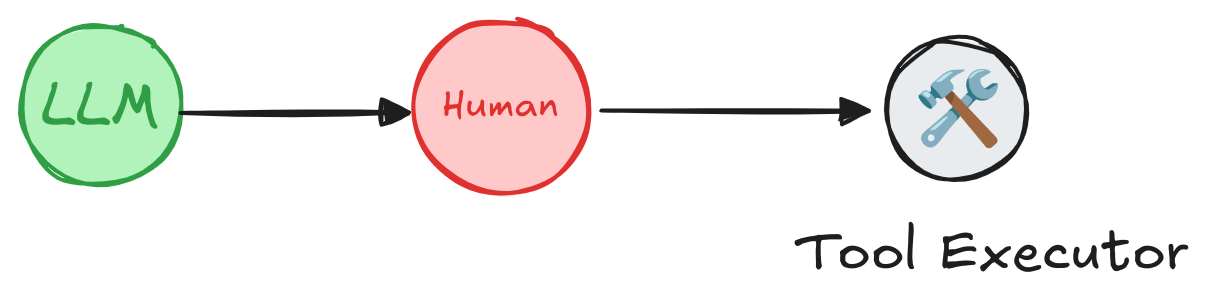
在繼續執行前,人工可以審查并編輯智能體的輸出。這對于工具調用可能涉及敏感操作或需要人工監督的應用場景尤為重要。
工具調用審核機制
要為工具添加人工審批環節,請按以下步驟操作:
1、在工具中使用 interrupt() 方法暫停執行流程
2、通過發送 Command(resume=...) 指令,根據人工輸入決定是否繼續執行
API參考文檔:InMemorySaver | interrupt | create_react_agent
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import interrupt
from langgraph.prebuilt import create_react_agent# An example of a sensitive tool that requires human review / approval
def book_hotel(hotel_name: str):"""Book a hotel"""response = interrupt( # (1)!f"Trying to call `book_hotel` with args {{'hotel_name': {hotel_name}}}. ""Please approve or suggest edits.")if response["type"] == "accept":passelif response["type"] == "edit":hotel_name = response["args"]["hotel_name"]else:raise ValueError(f"Unknown response type: {response['type']}")return f"Successfully booked a stay at {hotel_name}."checkpointer = InMemorySaver() # (2)!agent = create_react_agent(model="anthropic:claude-3-5-sonnet-latest",tools=[book_hotel],checkpointer=checkpointer, # (3)!
)
1、interrupt函數用于在特定節點暫停智能體圖。在本例中,我們在工具函數開頭調用interrupt(),這會使圖在執行工具的節點處暫停。interrupt()內的信息(如工具調用)可以呈現給人類操作員,隨后通過用戶輸入(工具調用批準、編輯或反饋)來恢復圖的執行。
2、InMemorySaver用于在工具調用循環的每一步存儲智能體狀態。這實現了短期記憶和人機協同功能。本示例中,我們使用InMemorySaver將智能體狀態存儲在內存中。在生產環境中,智能體狀態應存儲在數據庫中。
3、使用checkpointer初始化智能體。
通過stream()方法運行智能體,并傳入config對象指定線程ID。這使得智能體在后續調用中可以恢復同一會話。
config = {"configurable": {"thread_id": "1"}
}for chunk in agent.stream({"messages": [{"role": "user", "content": "book a stay at McKittrick hotel"}]},config
):print(chunk)print("\n")
你會看到代理程序一直運行,直到遇到 interrupt() 調用時暫停,等待人工輸入。
通過發送 Command(resume=...) 指令可基于人工輸入恢復代理程序的運行。
API 參考文檔:Command
from langgraph.types import Commandfor chunk in agent.stream(Command(resume={"type": "accept"}), # (1)!# Command(resume={"type": "edit", "args": {"hotel_name": "McKittrick Hotel"}}),config
):print(chunk)print("\n")
1、interrupt函數與Command對象配合使用,用于在人工提供值后恢復圖的執行。
注意:
- 保留了所有代碼塊和鏈接的原始格式
- 移除了HTML標簽及屬性
- 將被動語態轉換為主動語態
- 保持了技術術語的一致性
- 壓縮了多余的空白行
與Agent Inbox配合使用
你可以創建一個包裝器來為任何工具添加中斷功能。
以下示例提供了一個兼容Agent Inbox UI和Agent Chat UI的參考實現。
該包裝器能為任何工具添加人工干預功能
from typing import Callable
from langchain_core.tools import BaseTool, tool as create_tool
from langchain_core.runnables import RunnableConfig
from langgraph.types import interrupt
from langgraph.prebuilt.interrupt import HumanInterruptConfig, HumanInterruptdef add_human_in_the_loop(tool: Callable | BaseTool,*,interrupt_config: HumanInterruptConfig = None,
) -> BaseTool:"""Wrap a tool to support human-in-the-loop review.""" if not isinstance(tool, BaseTool):tool = create_tool(tool)if interrupt_config is None:interrupt_config = {"allow_accept": True,"allow_edit": True,"allow_respond": True,}@create_tool( # (1)!tool.name,description=tool.description,args_schema=tool.args_schema)def call_tool_with_interrupt(config: RunnableConfig, **tool_input):request: HumanInterrupt = {"action_request": {"action": tool.name,"args": tool_input},"config": interrupt_config,"description": "Please review the tool call"}response = interrupt([request])[0] # (2)!# approve the tool callif response["type"] == "accept":tool_response = tool.invoke(tool_input, config)# update tool call argselif response["type"] == "edit":tool_input = response["args"]["args"]tool_response = tool.invoke(tool_input, config)# respond to the LLM with user feedbackelif response["type"] == "response":user_feedback = response["args"]tool_response = user_feedbackelse:raise ValueError(f"Unsupported interrupt response type: {response['type']}")return tool_responsereturn call_tool_with_interrupt
1、該包裝器會創建一個新工具,在執行被包裝的工具之前調用 interrupt()。
2、interrupt() 使用了 Agent Inbox UI 預期的特殊輸入輸出格式:
- 會向
AgentInbox發送一個HumanInterrupt對象列表,用于向終端用戶渲染中斷Info : * 恢復值由AgentInbox以列表形式提供(即Command(resume=[...]))
您可以使用 add_human_in_the_loop 包裝器將 interrupt() 添加到任何工具中,而無需將其添加到工具內部:
API 參考:InMemorySaver | create_react_agent
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.prebuilt import create_react_agentcheckpointer = InMemorySaver()def book_hotel(hotel_name: str):"""Book a hotel"""return f"Successfully booked a stay at {hotel_name}."agent = create_react_agent(model="anthropic:claude-3-5-sonnet-latest",tools=[add_human_in_the_loop(book_hotel), # (1)!],checkpointer=checkpointer,
)config = {"configurable": {"thread_id": "1"}}# Run the agent
for chunk in agent.stream({"messages": [{"role": "user", "content": "book a stay at McKittrick hotel"}]},config
):print(chunk)print("\n")
1、add_human_in_the_loop 包裝器用于為工具添加 interrupt() 功能。這使得智能體能夠暫停執行,在繼續工具調用前等待人工輸入。
你會看到智能體運行至 interrupt() 調用點時暫停,
此時它將等待人工輸入。
通過發送 Command(resume=...) 指令來根據人工輸入恢復智能體運行。
API參考文檔:Command
from langgraph.types import Command for chunk in agent.stream(Command(resume=[{"type": "accept"}]),# Command(resume=[{"type": "edit", "args": {"args": {"hotel_name": "McKittrick Hotel"}}}]),config
):print(chunk)print("\n")
其他資源
- LangGraph 中的人機交互
多智能體系統
https://langchain-ai.github.io/langgraph/agents/multi-agent/
當單個智能體需要專注于多個領域或管理大量工具時,可能會力不從心。為解決這個問題,您可以將智能體拆分為多個獨立的小型智能體,并將它們組合成一個多智能體系統。
在多智能體系統中,智能體之間需要進行通信。它們通過控制權移交機制實現交互——這是一種基礎協議,用于指定將控制權移交給哪個智能體以及傳遞給該智能體的數據負載。
目前最流行的兩種多智能體架構是:
- 監督者模式 —— 由中央監督者智能體協調各個子智能體。監督者控制所有通信流和任務分配,根據當前上下文和任務需求決定調用哪個智能體。
- 群體模式 —— 智能體根據各自專長動態地將控制權移交給其他智能體。系統會記憶最后活躍的智能體,確保在后續交互中能繼續與該智能體對話。
監督者
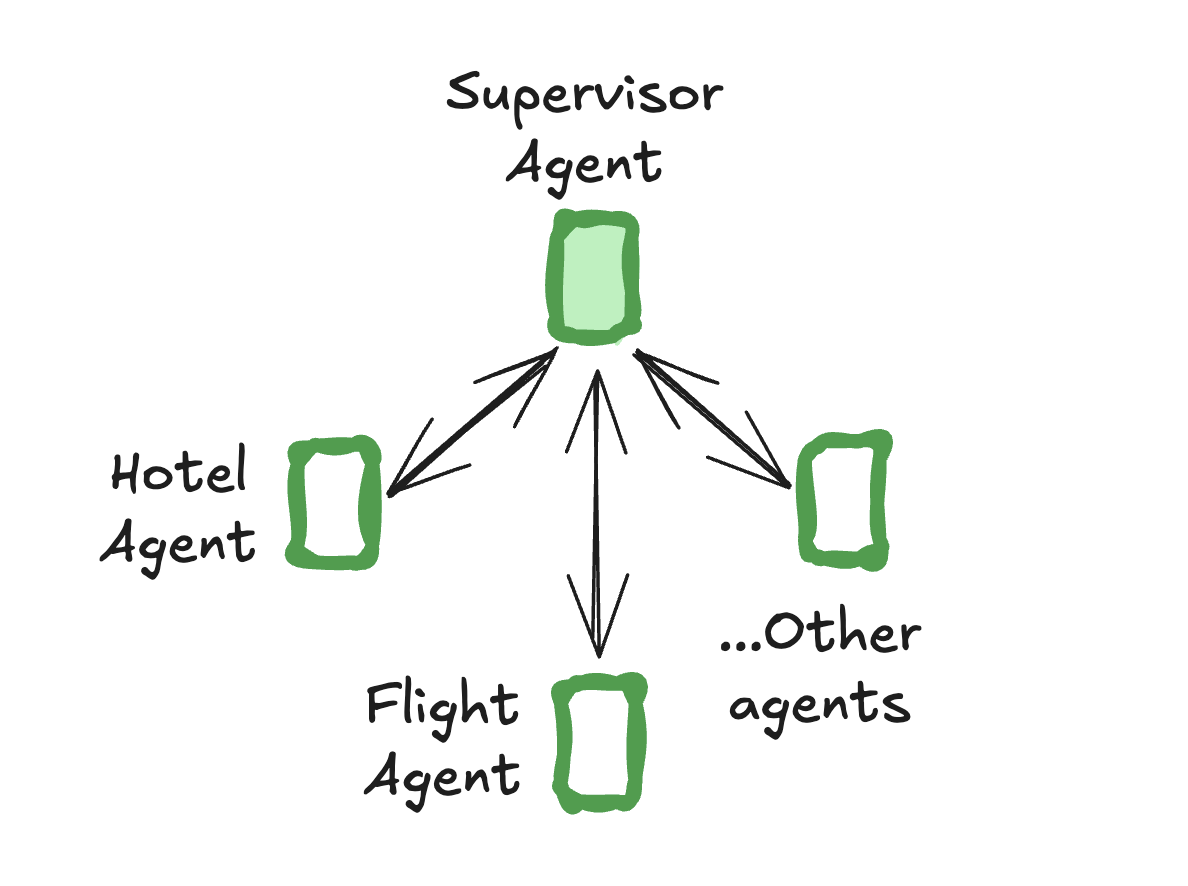
使用 langgraph-supervisor 庫來創建一個監督者多智能體系統:
pip install langgraph-supervisor
API 參考文檔: ChatOpenAI | create_react_agent | create_supervisor
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langgraph_supervisor import create_supervisordef book_hotel(hotel_name: str):"""Book a hotel"""return f"Successfully booked a stay at {hotel_name}."def book_flight(from_airport: str, to_airport: str):"""Book a flight"""return f"Successfully booked a flight from {from_airport} to {to_airport}."flight_assistant = create_react_agent(model="openai:gpt-4o",tools=[book_flight],prompt="You are a flight booking assistant",name="flight_assistant"
)hotel_assistant = create_react_agent(model="openai:gpt-4o",tools=[book_hotel],prompt="You are a hotel booking assistant",name="hotel_assistant"
)supervisor = create_supervisor(agents=[flight_assistant, hotel_assistant],model=ChatOpenAI(model="gpt-4o"),prompt=("You manage a hotel booking assistant and a""flight booking assistant. Assign work to them.")
).compile()for chunk in supervisor.stream({"messages": [{"role": "user","content": "book a flight from BOS to JFK and a stay at McKittrick Hotel"}]}
):print(chunk)print("\n")
集群
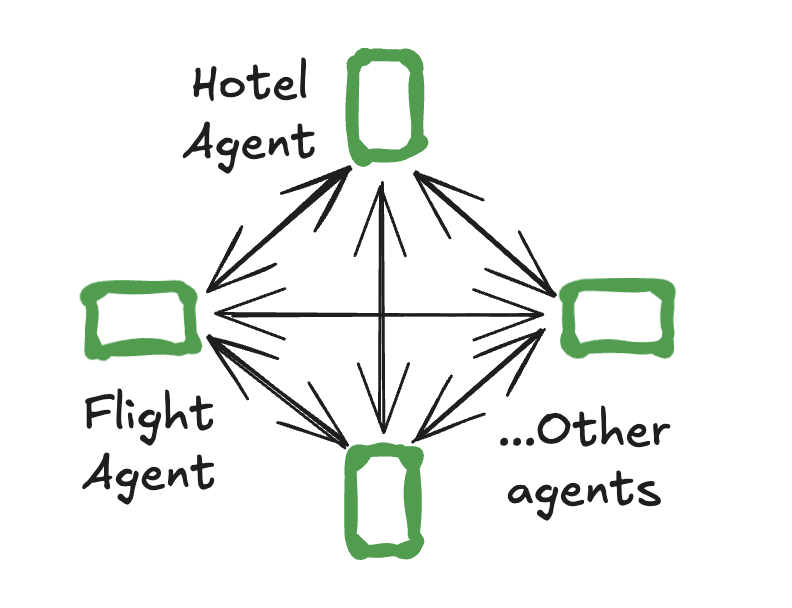
使用 langgraph-swarm 庫來創建一個集群多智能體系統:
pip install langgraph-swarm
API參考文檔:create_react_agent | create_swarm | create_handoff_tool
from langgraph.prebuilt import create_react_agent
from langgraph_swarm import create_swarm, create_handoff_tooltransfer_to_hotel_assistant = create_handoff_tool(agent_name="hotel_assistant",description="Transfer user to the hotel-booking assistant.",
)
transfer_to_flight_assistant = create_handoff_tool(agent_name="flight_assistant",description="Transfer user to the flight-booking assistant.",
)flight_assistant = create_react_agent(model="anthropic:claude-3-5-sonnet-latest",tools=[book_flight, transfer_to_hotel_assistant],prompt="You are a flight booking assistant",name="flight_assistant"
)
hotel_assistant = create_react_agent(model="anthropic:claude-3-5-sonnet-latest",tools=[book_hotel, transfer_to_flight_assistant],prompt="You are a hotel booking assistant",name="hotel_assistant"
)swarm = create_swarm(agents=[flight_assistant, hotel_assistant],default_active_agent="flight_assistant"
).compile()for chunk in swarm.stream({"messages": [{"role": "user","content": "book a flight from BOS to JFK and a stay at McKittrick Hotel"}]}
):print(chunk)print("\n")
交接機制
在多智能體交互中,交接是一種常見模式,即一個智能體將控制權移交給另一個智能體。通過交接機制可以指定:
- 目標對象:要交接的目標智能體
- 傳遞內容:需要傳遞給該智能體的Info : 該機制既被
langgraph-supervisor使用(監督者將控制權移交給單個智能體),也被langgraph-swarm使用(單個智能體可將控制權移交給其他智能體)。
要在create_react_agent中實現交接機制,你需要:
1、創建一個能將控制權轉移給其他智能體的特殊工具
def transfer_to_bob():"""Transfer to bob."""return Command(# name of the agent (node) to go togoto="bob",# data to send to the agentupdate={"messages": [...]},# indicate to LangGraph that we need to navigate to# agent node in a parent graphgraph=Command.PARENT,)
2、創建可訪問交接工具的獨立代理:
flight_assistant = create_react_agent(..., tools=[book_flight, transfer_to_hotel_assistant]
)
hotel_assistant = create_react_agent(..., tools=[book_hotel, transfer_to_flight_assistant]
)
3、定義一個包含獨立智能體作為節點的父圖:
from langgraph.graph import StateGraph, MessagesState
multi_agent_graph = (StateGraph(MessagesState).add_node(flight_assistant).add_node(hotel_assistant)...
)
綜合以上內容,以下是實現一個簡單多代理系統的方法,該系統包含兩個代理——航班預訂助手和酒店預訂助手:
API參考文檔:tool | InjectedToolCallId | create_react_agent | InjectedState | StateGraph | START | Command
from typing import Annotated
from langchain_core.tools import tool, InjectedToolCallId
from langgraph.prebuilt import create_react_agent, InjectedState
from langgraph.graph import StateGraph, START, MessagesState
from langgraph.types import Commanddef create_handoff_tool(*, agent_name: str, description: str | None = None):name = f"transfer_to_{agent_name}"description = description or f"Transfer to {agent_name}"@tool(name, description=description)def handoff_tool(state: Annotated[MessagesState, InjectedState], # (1)!tool_call_id: Annotated[str, InjectedToolCallId],) -> Command:tool_message = {"role": "tool","content": f"Successfully transferred to {agent_name}","name": name,"tool_call_id": tool_call_id,}return Command( # (2)!goto=agent_name, # (3)!update={"messages": state["messages"] + [tool_message]}, # (4)!graph=Command.PARENT, # (5)!)return handoff_tool# Handoffs
transfer_to_hotel_assistant = create_handoff_tool(agent_name="hotel_assistant",description="Transfer user to the hotel-booking assistant.",
)
transfer_to_flight_assistant = create_handoff_tool(agent_name="flight_assistant",description="Transfer user to the flight-booking assistant.",
)# Simple agent tools
def book_hotel(hotel_name: str):"""Book a hotel"""return f"Successfully booked a stay at {hotel_name}."def book_flight(from_airport: str, to_airport: str):"""Book a flight"""return f"Successfully booked a flight from {from_airport} to {to_airport}."# Define agents
flight_assistant = create_react_agent(model="anthropic:claude-3-5-sonnet-latest",tools=[book_flight, transfer_to_hotel_assistant],prompt="You are a flight booking assistant",name="flight_assistant"
)
hotel_assistant = create_react_agent(model="anthropic:claude-3-5-sonnet-latest",tools=[book_hotel, transfer_to_flight_assistant],prompt="You are a hotel booking assistant",name="hotel_assistant"
)# Define multi-agent graph
multi_agent_graph = (StateGraph(MessagesState).add_node(flight_assistant).add_node(hotel_assistant).add_edge(START, "flight_assistant").compile()
)# Run the multi-agent graph
for chunk in multi_agent_graph.stream({"messages": [{"role": "user","content": "book a flight from BOS to JFK and a stay at McKittrick Hotel"}]}
):print(chunk)print("\n")
1、訪問代理狀態
2、Command原語允許將狀態更新和節點轉移作為單一操作指定,非常適合實現交接功能。
3、要交接的目標代理或節點名稱。
4、在交接過程中,獲取代理的消息并將其添加到父級狀態中。下一個代理將看到父級狀態。
5、向LangGraph表明我們需要導航到父級多代理圖中的代理節點。
注意:此交接實現基于以下假設:
- 多代理系統中每個代理接收全局消息歷史記錄(跨所有代理)作為輸入
- 每個代理將其內部消息歷史記錄輸出到多代理系統的全局消息歷史中
查看LangGraph的監督器和集群文檔,了解如何自定義交接功能。
評估
https://langchain-ai.github.io/langgraph/agents/evals/
要評估智能體的性能,你可以使用LangSmith的評估功能。首先需要定義一個評估函數來評判智能體的結果,例如最終輸出或執行軌跡。根據評估技術的不同,這個過程可能涉及也可能不涉及參考輸出:
def evaluator(*, outputs: dict, reference_outputs: dict):# compare agent outputs against reference outputsoutput_messages = outputs["messages"]reference_messages = reference["messages"]score = compare_messages(output_messages, reference_messages)return {"key": "evaluator_score", "score": score}
要開始使用,你可以使用 AgentEvals 包中預置的評估器:
pip install -U agentevals
創建評估器
評估智能體性能的常見方法是通過將其軌跡(調用工具的順序)與參考軌跡進行對比來實現。
import json
from agentevals.trajectory.match import create_trajectory_match_evaluatoroutputs = [{"role": "assistant","tool_calls": [{"function": {"name": "get_weather","arguments": json.dumps({"city": "san francisco"}),}},{"function": {"name": "get_directions","arguments": json.dumps({"destination": "presidio"}),}}],}
]
reference_outputs = [{"role": "assistant","tool_calls": [{"function": {"name": "get_weather","arguments": json.dumps({"city": "san francisco"}),}},],}
]# Create the evaluator
evaluator = create_trajectory_match_evaluator(trajectory_match_mode="superset", # (1)!
)# Run the evaluator
result = evaluator(outputs=outputs, reference_outputs=reference_outputs
)
1、指定軌跡比較方式。superset模式會接受輸出軌跡作為有效結果,只要它是參考軌跡的超集。其他可選模式包括:strict(嚴格匹配)、unordered(無序匹配)以及subset(子集匹配)。
下一步,了解更多關于如何自定義軌跡匹配評估器的信息。
LLM 作為評判者
你可以使用 LLM 作為評判者的評估器,它利用大語言模型(LLM)將實際軌跡與參考輸出進行對比,并輸出一個評分:
import json
from agentevals.trajectory.llm import (create_trajectory_llm_as_judge,TRAJECTORY_ACCURACY_PROMPT_WITH_REFERENCE
)evaluator = create_trajectory_llm_as_judge(prompt=TRAJECTORY_ACCURACY_PROMPT_WITH_REFERENCE,model="openai:o3-mini"
)
運行評估器
要運行評估器,首先需要創建一個 LangSmith 數據集。若使用預構建的 AgentEvals 評估器,數據集需符合以下結構:
- input:
{"messages": [...]}調用 agent 時輸入的 messages 數組 - output:
{"messages": [...]}agent 輸出中預期的 message 歷史記錄。進行軌跡評估時,可僅保留 assistant 類型的 messages
API 參考文檔: create_react_agent
from langsmith import Client
from langgraph.prebuilt import create_react_agent
from agentevals.trajectory.match import create_trajectory_match_evaluatorclient = Client()
agent = create_react_agent(...)
evaluator = create_trajectory_match_evaluator(...)experiment_results = client.evaluate(lambda inputs: agent.invoke(inputs),# replace with your dataset namedata="<Name of your dataset>",evaluators=[evaluator]
)
部署指南
https://langchain-ai.github.io/langgraph/agents/deployment/
要部署您的LangGraph智能體,需要創建并配置一個LangGraph應用。該設置同時支持本地開發環境和生產環境部署。
主要功能:
- 🖥? 本地開發服務器
- 🧩 Studio可視化調試Web界面
- ?? 云端部署與🔧自主托管兩種選項
- 📊 LangSmith集成(用于調用鏈追蹤和可觀測性)
系統要求:
- ? 必須擁有LangSmith賬戶。您可以免費注冊并使用基礎免費套餐。
創建LangGraph應用
pip install -U "langgraph-cli[inmem]"
langgraph new path/to/your/app --template new-langgraph-project-python
這將創建一個空的LangGraph項目。您可以通過將src/agent/graph.py中的代碼替換為您的智能體代碼來進行修改。例如:
API參考文檔:create_react_agent
from langgraph.prebuilt import create_react_agentdef get_weather(city: str) -> str:"""Get weather for a given city."""return f"It's always sunny in {city}!"graph = create_react_agent(model="anthropic:claude-3-7-sonnet-latest",tools=[get_weather],prompt="You are a helpful assistant"
)
安裝依賴
在新建的LangGraph應用根目錄下,以edit模式安裝依賴項,這樣服務器就會使用你的本地修改:
pip install -e .
創建 .env 文件
你會在新建的 LangGraph 應用根目錄下找到一個 .env.example 文件。請在應用根目錄下創建一個 .env 文件,并將 .env.example 文件的內容復制到其中,填寫必要的 API 密鑰:
LANGSMITH_API_KEY=lsv2...
ANTHROPIC_API_KEY=sk-
本地啟動LangGraph服務器
langgraph dev
這將在本地啟動LangGraph API服務器。如果運行成功,你會看到類似以下輸出:
準備就緒!
- API地址: http://localhost:2024
- 文檔: http://localhost:2024/docs
- LangGraph Studio網頁界面: https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024
查看這篇教程了解更多關于本地運行LangGraph應用的信息。
LangGraph Studio 網頁界面
LangGraph Studio Web 是一個專用用戶界面,可連接至 LangGraph API 服務器,實現本地應用程序的可視化、交互和調試功能。通過在 langgraph dev 命令輸出中提供的 URL 訪問 LangGraph Studio 網頁界面,即可測試您的流程圖。
- LangGraph Studio 網頁界面:https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024
部署
當您的 LangGraph 應用在本地運行后,即可通過 LangGraph 平臺進行部署。有關所有支持部署模式的詳細說明,請參閱部署選項指南。
UI 用戶界面
https://langchain-ai.github.io/langgraph/agents/ui/
您可以使用預構建的聊天界面Agent Chat UI來與任何LangGraph智能體進行交互。通過已部署版本是最快捷的入門方式,該界面支持您與本地和已部署的圖結構進行交互。
在 UI 中運行代理
首先,在本地設置 LangGraph API 服務器,或將您的代理部署到 LangGraph 平臺。
然后,訪問 Agent Chat UI,或克隆倉庫并在本地運行開發服務器:
提示:
該 UI 開箱即用支持渲染工具調用和工具結果消息。如需自定義顯示哪些消息,請參閱 Agent Chat UI 文檔中的隱藏聊天消息部分。
添加人工介入循環
Agent Chat UI 全面支持人工介入循環工作流。要體驗該功能,請將src/agent/graph.py中的代理代碼(來自部署指南)替換為這個代理實現:
重要提示:
當您的LangGraph代理使用HumanInterrupt模式進行中斷時,Agent Chat UI能發揮最佳效果。如果不使用該模式,雖然Agent Chat UI仍能渲染傳遞給interrupt函數的輸入,但將無法完整支持恢復執行圖的功能。
生成式 UI
您也可以在 Agent Chat UI 中使用生成式 UI。
生成式 UI 允許您定義 React 組件,并通過 LangGraph 服務器將其推送到用戶界面。有關構建生成式 UI LangGraph 代理的更多文檔,請閱讀 這些文檔。


















:解釋器風格)
