文章目錄
- 代理式檢索增強生成(Agentic RAG)
- 安裝
- 1、預處理文檔
- 2、創建檢索器工具
- 3、生成查詢
- 4、文檔分級
- 5、問題重寫
- 6、生成答案
- 7、構建流程圖
- 8、運行智能RAG代理
- 多智能體監督系統
- 安裝配置
- 1、創建工作代理
- 研究代理
- 數學代理工具
- 2、使用 `langgraph-supervisor` 創建監督器
- 3、從零開始創建監督者
- 設置代理通信機制
- 創建監督員代理
- 創建多智能體圖
- 4、創建委派任務
- 構建SQL代理
- 1、環境配置
- 選擇大語言模型
- 配置數據庫
- 數據庫交互工具
- 2、使用預構建的Agent
- 3、自定義智能體
- 后續步驟
- 如何在LangSmith中為圖運行傳遞自定義運行ID或設置標簽和元數據
- 前提條件
- 概述
- 實現方式
- TLDR
- 安裝配置
- 定義圖結構
- 運行你的圖
- 在LangSmith中查看追蹤記錄
- 設置自定義認證
- 1、創建你的應用
- 2、添加認證功能
- 3、測試你的機器人
- 4、與你的機器人對話
- 后續步驟
- 實現私密對話功能
- 前提條件
- 1、添加資源授權
- 2、測試私有對話
- 3、添加作用域授權處理器
- 下一步行動
- 連接認證提供商
- 背景
- 前提條件
- 1、安裝依賴
- 2、設置認證提供程序
- 3、實現令牌驗證
- 4、測試認證流程
- 后續步驟
- 運行時重建圖
- 先決條件
- 定義圖結構
- 無需重新構建
- 重建
- 如何使用RemoteGraph與部署進行交互
- 前提條件
- 初始化圖
- 使用 URL
- 使用客戶端
- 調用圖結構
- 異步使用
- 同步模式
- 線程級持久化
- 作為子圖使用
- 如何使用LangGraph平臺部署CrewAI、AutoGen等框架
- 安裝
- 定義自動生成代理
- 使用LangGraph封裝
- 通過LangGraph平臺部署
- 如何將LangGraph集成到React應用中
- 前提條件
- 安裝
- 示例
- 自定義用戶界面
- 加載狀態
- 線程管理
- 消息處理
- 中斷機制
- 分支管理
- 樂觀更新
- TypeScript
- 事件處理
- 了解更多
- 如何使用LangGraph實現生成式用戶界面
- 前提條件
- 教程
- 1、定義與配置UI組件
- 2、發送圖中的UI組件
- 3、在React應用中處理UI元素
- 操作指南
- 在客戶端提供自定義組件
- 組件加載時顯示加載界面
- 自定義 UI 組件的命名空間
- 從UI組件訪問和交互線程狀態
- 向客戶端組件傳遞額外上下文
- 從服務器流式傳輸 UI 消息
- 從狀態中移除UI消息
- 了解更多
代理式檢索增強生成(Agentic RAG)
https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_agentic_rag/
在本教程中,我們將構建一個檢索代理。當您希望大型語言模型(LLM)能夠決定是從向量存儲中檢索上下文還是直接響應用戶時,檢索代理非常有用。
通過本教程,我們將完成以下內容:
1、獲取并預處理用于檢索的文檔
2、為這些文檔建立語義搜索索引,并為代理創建檢索工具
3、構建一個能夠決定何時使用檢索工具的代理式RAG系統
安裝
讓我們下載所需的軟件包并設置API密鑰:
pip install -U --quiet langgraph "langchain[openai]" langchain-community langchain-text-splitters
import getpass
import osdef _set_env(key: str):if key not in os.environ:os.environ[key] = getpass.getpass(f"{key}:")_set_env("OPENAI_API_KEY")
為LangGraph開發設置LangSmith
注冊LangSmith可快速發現問題并提升LangGraph項目性能。LangSmith允許您利用追蹤數據來調試、測試和監控基于LangGraph構建的LLM應用——了解更多入門指南請點擊此處。
1、預處理文檔
1、獲取用于RAG系統的文檔。我們將使用Lilian Weng的優秀博客中最新的三篇文章。首先使用WebBaseLoader工具獲取頁面內容:
API參考:WebBaseLoader
from langchain_community.document_loaders import WebBaseLoaderurls = ["https://lilianweng.github.io/posts/2024-11-28-reward-hacking/","https://lilianweng.github.io/posts/2024-07-07-hallucination/","https://lilianweng.github.io/posts/2024-04-12-diffusion-video/",
]docs = [WebBaseLoader(url).load() for url in urls]
docs[0][0].page_content.strip()[:1000]
"Reward Hacking in Reinforcement Learning | Lil'Log\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nLil'Log\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n|\n\n\n\n\n\n\nPosts\n\n\n\n\nArchive\n\n\n\n\nSearch\n\n\n\n\nTags\n\n\n\n\nFAQ\n\n\n\n\n\n\n\n\n\n Reward Hacking in Reinforcement Learning\n \nDate: November 28, 2024 | Estimated Reading Time: 37 min | Author: Lilian Weng\n\n\n \n\n\nTable of Contents\n\n\n\nBackground\n\nReward Function in RL\n\nSpurious Correlation\n\n\nLet’s Define Reward Hacking\n\nList of Examples\n\nReward hacking examples in RL tasks\n\nReward hacking examples in LLM tasks\n\nReward hacking examples in real life\n\n\nWhy does Reward Hacking Exist?\n\n\nHacking RL Environment\n\nHacking RLHF of LLMs\n\nHacking the Training Process\n\nHacking the Evaluator\n\nIn-Context Reward Hacking\n\n\nGeneralization of Hacking Skills\n\nPeek into Mitigations\n\nRL Algorithm Improvement\n\nDetecting Reward Hacking\n\nData Analysis of RLHF\n\n\nCitation\n\nReferences\n\n\n\n\n\nReward hacking occurs when a reinforcement learning (RL) agent exploits flaws or ambiguities in the reward function to ac"
2、將獲取的文檔分割成更小的塊,以便索引到我們的向量存儲中:
API參考:RecursiveCharacterTextSplitter
from langchain_text_splitters import RecursiveCharacterTextSplitterdocs_list = [item for sublist in docs for item in sublist]text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=100, chunk_overlap=50
)
doc_splits = text_splitter.split_documents(docs_list)
doc_splits[0].page_content.strip()
"Reward Hacking in Reinforcement Learning | Lil'Log\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nLil'Log\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n|\n\n\n\n\n\n\nPosts\n\n\n\n\nArchive\n\n\n\n\nSearch\n\n\n\n\nTags\n\n\n\n\nFAQ"
2、創建檢索器工具
現在我們已經完成了文檔分割,接下來可以將它們索引到向量存儲中,用于語義搜索。
1、使用內存向量存儲和OpenAI嵌入:
API參考:InMemoryVectorStore | OpenAIEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import OpenAIEmbeddingsvectorstore = InMemoryVectorStore.from_documents(documents=doc_splits, embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
2、使用LangChain預置的create_retriever_tool創建檢索器工具:
API參考文檔:create_retriever_tool
from langchain.tools.retriever import create_retriever_toolretriever_tool = create_retriever_tool(retriever,"retrieve_blog_posts","Search and return information about Lilian Weng blog posts.",
)
3、測試工具:
retriever_tool.invoke({"query": "types of reward hacking"})
'(Note: Some work defines reward tampering as a distinct category of misalignment behavior from reward hacking. But I consider reward hacking as a broader concept here.)\nAt a high level, reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering.\n\nWhy does Reward Hacking Exist?#\n\nPan et al. (2022) investigated reward hacking as a function of agent capabilities, including (1) model size, (2) action space resolution, (3) observation space noise, and (4) training time. They also proposed a taxonomy of three types of misspecified proxy rewards:\n\nLet’s Define Reward Hacking#\nReward shaping in RL is challenging. Reward hacking occurs when an RL agent exploits flaws or ambiguities in the reward function to obtain high rewards without genuinely learning the intended behaviors or completing the task as designed. In recent years, several related concepts have been proposed, all referring to some form of reward hacking:'
3、生成查詢
現在我們將開始為智能RAG圖構建組件(節點和邊)。注意這些組件將在MessagesState上運行——該圖狀態包含一個messages鍵,其中存儲著聊天消息列表。
1、構建generate_query_or_respond節點。該節點將調用LLM基于當前圖狀態(消息列表)生成響應。根據輸入消息,它會決定使用檢索工具進行檢索,或直接回復用戶。注意我們通過.bind_tools為聊天模型提供了之前創建的retriever_tool訪問權限:
API參考:init_chat_model
from langgraph.graph import MessagesState
from langchain.chat_models import init_chat_modelresponse_model = init_chat_model("openai:gpt-4.1", temperature=0)def generate_query_or_respond(state: MessagesState):"""Call the model to generate a response based on the current state. Giventhe question, it will decide to retrieve using the retriever tool, or simply respond to the user."""response = (response_model.bind_tools([retriever_tool]).invoke(state["messages"]))return {"messages": [response]}
2、在隨機輸入上嘗試:
input = {"messages": [{"role": "user", "content": "hello!"}]}
generate_query_or_respond(input)["messages"][-1].pretty_print()
================================== Ai Message ==================================Hello! How can I help you today?
3、提出一個需要語義搜索的問題:
input = {"messages": [{"role": "user","content": "What does Lilian Weng say about types of reward hacking?",}]
}
generate_query_or_respond(input)["messages"][-1].pretty_print()
================================== Ai Message ==================================
Tool Calls:retrieve_blog_posts (call_tYQxgfIlnQUDMdtAhdbXNwIM)Call ID: call_tYQxgfIlnQUDMdtAhdbXNwIMArgs:query: types of reward hacking
4、文檔分級
1、添加一個條件邊——grade_documents——用于判斷檢索到的文檔是否與問題相關。我們將使用一個具有結構化輸出模式GradeDocuments的模型進行文檔分級。grade_documents函數將根據分級決策返回下一步應轉向的節點名稱(generate_answer或rewrite_question):
from pydantic import BaseModel, Field
from typing import LiteralGRADE_PROMPT = ("You are a grader assessing relevance of a retrieved document to a user question. \n ""Here is the retrieved document: \n\n {context} \n\n""Here is the user question: {question} \n""If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n""Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."
)class GradeDocuments(BaseModel):"""Grade documents using a binary score for relevance check."""binary_score: str = Field(description="Relevance score: 'yes' if relevant, or 'no' if not relevant")grader_model = init_chat_model("openai:gpt-4.1", temperature=0)def grade_documents(state: MessagesState,
) -> Literal["generate_answer", "rewrite_question"]:"""Determine whether the retrieved documents are relevant to the question."""question = state["messages"][0].contentcontext = state["messages"][-1].contentprompt = GRADE_PROMPT.format(question=question, context=context)response = (grader_model.with_structured_output(GradeDocuments).invoke([{"role": "user", "content": prompt}]))score = response.binary_scoreif score == "yes":return "generate_answer"else:return "rewrite_question"
2、在工具響應中使用無關文檔運行此操作:
API參考:convert_to_messages
from langchain_core.messages import convert_to_messagesinput = {"messages": convert_to_messages([{"role": "user","content": "What does Lilian Weng say about types of reward hacking?",},{"role": "assistant","content": "","tool_calls": [{"id": "1","name": "retrieve_blog_posts","args": {"query": "types of reward hacking"},}],},{"role": "tool", "content": "meow", "tool_call_id": "1"},])
}
grade_documents(input)
'rewrite_question'
3、確認相關文檔已按以下類別進行分類:
input = {"messages": convert_to_messages([{"role": "user","content": "What does Lilian Weng say about types of reward hacking?",},{"role": "assistant","content": "","tool_calls": [{"id": "1","name": "retrieve_blog_posts","args": {"query": "types of reward hacking"},}],},{"role": "tool","content": "reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering","tool_call_id": "1",},])
}
grade_documents(input)
'generate_answer'
5、問題重寫
1、構建 rewrite_question 節點。檢索工具可能會返回不相關的文檔,這表明需要改進原始用戶問題。為此,我們將調用 rewrite_question 節點:
REWRITE_PROMPT = ("Look at the input and try to reason about the underlying semantic intent / meaning.\n""Here is the initial question:""\n ------- \n""{question}""\n ------- \n""Formulate an improved question:"
)def rewrite_question(state: MessagesState):"""Rewrite the original user question."""messages = state["messages"]question = messages[0].contentprompt = REWRITE_PROMPT.format(question=question)response = response_model.invoke([{"role": "user", "content": prompt}])return {"messages": [{"role": "user", "content": response.content}]}
2、動手嘗試:
input = {"messages": convert_to_messages([{"role": "user","content": "What does Lilian Weng say about types of reward hacking?",},{"role": "assistant","content": "","tool_calls": [{"id": "1","name": "retrieve_blog_posts","args": {"query": "types of reward hacking"},}],},{"role": "tool", "content": "meow", "tool_call_id": "1"},])
}response = rewrite_question(input)
print(response["messages"][-1]["content"])
What are the different types of reward hacking described by Lilian Weng, and how does she explain them?
6、生成答案
1、構建 generate_answer 節點:如果通過評分器檢查,我們可以基于原始問題和檢索到的上下文生成最終答案:
GENERATE_PROMPT = ("You are an assistant for question-answering tasks. ""Use the following pieces of retrieved context to answer the question. ""If you don't know the answer, just say that you don't know. ""Use three sentences maximum and keep the answer concise.\n""Question: {question} \n""Context: {context}"
)def generate_answer(state: MessagesState):"""Generate an answer."""question = state["messages"][0].contentcontext = state["messages"][-1].contentprompt = GENERATE_PROMPT.format(question=question, context=context)response = response_model.invoke([{"role": "user", "content": prompt}])return {"messages": [response]}
2、試一試:
input = {"messages": convert_to_messages([{"role": "user","content": "What does Lilian Weng say about types of reward hacking?",},{"role": "assistant","content": "","tool_calls": [{"id": "1","name": "retrieve_blog_posts","args": {"query": "types of reward hacking"},}],},{"role": "tool","content": "reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering","tool_call_id": "1",},])
}response = generate_answer(input)
response["messages"][-1].pretty_print()
================================== Ai Message ==================================Lilian Weng says that reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering. These categories describe different ways in which an agent might exploit flaws in the reward system. Environment or goal misspecification involves unintended behaviors due to poorly specified objectives, while reward tampering involves directly manipulating the reward signal.
7、構建流程圖
- 從
generate_query_or_respond開始,判斷是否需要調用retriever_tool - 使用
tools_condition路由到下一步:- 如果
generate_query_or_respond返回tool_calls,則調用retriever_tool檢索上下文 - 否則直接響應用戶
- 如果
- 對檢索到的文檔內容進行問題相關性評分 (
grade_documents) 并路由到下一步:- 如果不相關,使用
rewrite_question重寫問題后再次調用generate_query_or_respond - 如果相關,則進入
generate_answer并使用ToolMessage結合檢索到的文檔上下文生成最終響應
- 如果不相關,使用
API參考:StateGraph | START | END | ToolNode | tools_condition
from langgraph.graph import StateGraph, START, END
from langgraph.prebuilt import ToolNode
from langgraph.prebuilt import tools_conditionworkflow = StateGraph(MessagesState)# Define the nodes we will cycle between
workflow.add_node(generate_query_or_respond)
workflow.add_node("retrieve", ToolNode([retriever_tool]))
workflow.add_node(rewrite_question)
workflow.add_node(generate_answer)workflow.add_edge(START, "generate_query_or_respond")# Decide whether to retrieve
workflow.add_conditional_edges("generate_query_or_respond",# Assess LLM decision (call `retriever_tool` tool or respond to the user)tools_condition,{# Translate the condition outputs to nodes in our graph"tools": "retrieve",END: END,},
)# Edges taken after the `action` node is called.
workflow.add_conditional_edges("retrieve",# Assess agent decisiongrade_documents,
)
workflow.add_edge("generate_answer", END)
workflow.add_edge("rewrite_question", "generate_query_or_respond")# Compile
graph = workflow.compile()
可視化圖表:
from IPython.display import Image, displaydisplay(Image(graph.get_graph().draw_mermaid_png()))
8、運行智能RAG代理
for chunk in graph.stream({"messages": [{"role": "user","content": "What does Lilian Weng say about types of reward hacking?",}]}
):for node, update in chunk.items():print("Update from node", node)update["messages"][-1].pretty_print()print("\n\n")
Update from node generate_query_or_respond
================================== Ai Message ==================================
Tool Calls:retrieve_blog_posts (call_NYu2vq4km9nNNEFqJwefWKu1)Call ID: call_NYu2vq4km9nNNEFqJwefWKu1Args:query: types of reward hackingUpdate from node retrieve
================================= Tool Message =================================
Name: retrieve_blog_posts(Note: Some work defines reward tampering as a distinct category of misalignment behavior from reward hacking. But I consider reward hacking as a broader concept here.)
At a high level, reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering.Why does Reward Hacking Exist?#Pan et al. (2022) investigated reward hacking as a function of agent capabilities, including (1) model size, (2) action space resolution, (3) observation space noise, and (4) training time. They also proposed a taxonomy of three types of misspecified proxy rewards:Let’s Define Reward Hacking#
Reward shaping in RL is challenging. Reward hacking occurs when an RL agent exploits flaws or ambiguities in the reward function to obtain high rewards without genuinely learning the intended behaviors or completing the task as designed. In recent years, several related concepts have been proposed, all referring to some form of reward hacking:Update from node generate_answer
================================== Ai Message ==================================Lilian Weng categorizes reward hacking into two types: environment or goal misspecification, and reward tampering. She considers reward hacking as a broad concept that includes both of these categories. Reward hacking occurs when an agent exploits flaws or ambiguities in the reward function to achieve high rewards without performing the intended behaviors.
多智能體監督系統
https://langchain-ai.github.io/langgraph/tutorials/multi_agent/agent_supervisor/
監督者是一種多智能體架構,其中專業化智能體由中央監督智能體協調。監督智能體控制所有通信流和任務委派,根據當前上下文和任務需求決定調用哪個智能體。
在本教程中,您將構建一個包含研究專家和數學專家的監督系統。通過本教程您將:
1、構建專業化的研究和數學智能體
2、使用預建的langgraph-supervisor構建協調它們的監督者
3、從零開始構建監督者
4、實現高級任務委派
安裝配置
首先,我們需要安裝必要的軟件包并設置API密鑰
pip install -U langgraph langgraph-supervisor langchain-tavily "langchain[openai]"
import getpass
import osdef _set_if_undefined(var: str):if not os.environ.get(var):os.environ[var] = getpass.getpass(f"Please provide your {var}")_set_if_undefined("OPENAI_API_KEY")
_set_if_undefined("TAVILY_API_KEY")
為 LangGraph 開發設置 LangSmith
注冊 LangSmith 可以快速發現問題并提升 LangGraph 項目的性能。LangSmith 允許您利用追蹤數據來調試、測試和監控基于 LangGraph 構建的 LLM 應用——了解更多入門指南請訪問這里。
1、創建工作代理
首先,我們創建兩個專業的工作代理——研究代理和數學代理:
- 研究代理將能夠使用Tavily API進行網絡搜索
- 數學代理將可以使用基礎數學工具(
add、multiply、divide)
研究代理
對于網頁搜索,我們將使用 langchain-tavily 中的 TavilySearch 工具:
API參考文檔:TavilySearch
from langchain_tavily import TavilySearchweb_search = TavilySearch(max_results=3)
web_search_results = web_search.invoke("who is the mayor of NYC?")print(web_search_results["results"][0]["content"])
Mayor Eric Adams has served the people of New York City as an NYPD officer, State Senator, Brooklyn Borough President, and now as the 110th Mayor of the City of New York. He gave voice to a diverse coalition of working families in all five boroughs and is leading the fight to bring back New York City’s economy, reduce inequality, improve public safety, and build a stronger, healthier city that delivers for all New Yorkers. Mayor Eric Adams has served the people of New York City as an NYPD officer, State Senator, Brooklyn Borough President, and now as the 110th Mayor of the City of New York. NYC is a trademark and service mark of the City of New York.
要創建獨立的 worker 代理,我們將使用 LangGraph 預構建的 agent。
API 參考文檔: create_react_agent
from langgraph.prebuilt import create_react_agentresearch_agent = create_react_agent(model="openai:gpt-4.1",tools=[web_search],prompt=("You are a research agent.\n\n""INSTRUCTIONS:\n""- Assist ONLY with research-related tasks, DO NOT do any math\n""- After you're done with your tasks, respond to the supervisor directly\n""- Respond ONLY with the results of your work, do NOT include ANY other text."),name="research_agent",
)
讓我們運行代理來驗證其行為是否符合預期。
我們將使用pretty_print_messages輔助工具來優雅地呈現流式代理輸出。
from langchain_core.messages import convert_to_messagesdef pretty_print_message(message, indent=False):pretty_message = message.pretty_repr(html=True)if not indent:print(pretty_message)returnindented = "\n".join("\t" + c for c in pretty_message.split("\n"))print(indented)def pretty_print_messages(update, last_message=False):is_subgraph = Falseif isinstance(update, tuple):ns, update = update# skip parent graph updates in the printoutsif len(ns) == 0:returngraph_id = ns[-1].split(":")[0]print(f"Update from subgraph {graph_id}:")print("\n")is_subgraph = Truefor node_name, node_update in update.items():update_label = f"Update from node {node_name}:"if is_subgraph:update_label = "\t" + update_labelprint(update_label)print("\n")messages = convert_to_messages(node_update["messages"])if last_message:messages = messages[-1:]for m in messages:pretty_print_message(m, indent=is_subgraph)print("\n")
for chunk in research_agent.stream({"messages": [{"role": "user", "content": "who is the mayor of NYC?"}]}
):pretty_print_messages(chunk)
Update from node agent:================================== Ai Message ==================================
Name: research_agent
Tool Calls:tavily_search (call_T4wrj7DKAG5hVtNVhjRYGdei)Call ID: call_T4wrj7DKAG5hVtNVhjRYGdeiArgs:query: current mayor of New York CityUpdate from node tools:================================= Tool Message =================================
Name: tavily_search{"query": "current mayor of New York City", "follow_up_questions": null, "answer": null, "images": [], "results": [{"title": "List of mayors of New York City - Wikipedia", "url": "https://en.wikipedia.org/wiki/List_of_mayors_of_New_York_City", "content": "The mayor of New York City is the chief executive of the Government of New York City, as stipulated by New York City's charter.The current officeholder, the 110th in the sequence of regular mayors, is Eric Adams, a member of the Democratic Party.. During the Dutch colonial period from 1624 to 1664, New Amsterdam was governed by the Director of New Netherland.", "score": 0.9039154, "raw_content": null}, {"title": "Office of the Mayor | Mayor's Bio | City of New York - NYC.gov", "url": "https://www.nyc.gov/office-of-the-mayor/bio.page", "content": "Mayor Eric Adams has served the people of New York City as an NYPD officer, State Senator, Brooklyn Borough President, and now as the 110th Mayor of the City of New York. He gave voice to a diverse coalition of working families in all five boroughs and is leading the fight to bring back New York City's economy, reduce inequality, improve", "score": 0.8405867, "raw_content": null}, {"title": "Eric Adams - Wikipedia", "url": "https://en.wikipedia.org/wiki/Eric_Adams", "content": "Eric Leroy Adams (born September 1, 1960) is an American politician and former police officer who has served as the 110th mayor of New York City since 2022、Adams was an officer in the New York City Transit Police and then the New York City Police Department (NYPD) for more than 20 years, retiring at the rank of captain.He served in the New York State Senate from 2006 to 2013, representing the", "score": 0.77731717, "raw_content": null}], "response_time": 1.31}Update from node agent:================================== Ai Message ==================================
Name: research_agentThe current mayor of New York City is Eric Adams.
數學代理工具
對于數學代理工具,我們將使用原生Python函數來實現:
def add(a: float, b: float):"""Add two numbers."""return a + bdef multiply(a: float, b: float):"""Multiply two numbers."""return a * bdef divide(a: float, b: float):"""Divide two numbers."""return a / bmath_agent = create_react_agent(model="openai:gpt-4.1",tools=[add, multiply, divide],prompt=("You are a math agent.\n\n""INSTRUCTIONS:\n""- Assist ONLY with math-related tasks\n""- After you're done with your tasks, respond to the supervisor directly\n""- Respond ONLY with the results of your work, do NOT include ANY other text."),name="math_agent",
)
讓我們運行數學代理程序:
for chunk in math_agent.stream({"messages": [{"role": "user", "content": "what's (3 + 5) x 7"}]}
):pretty_print_messages(chunk)
Update from node agent:================================== Ai Message ==================================
Name: math_agent
Tool Calls:add (call_LqyOrR1Ktr2LVLDlXpbWNAsp)Call ID: call_LqyOrR1Ktr2LVLDlXpbWNAspArgs:a: 3b: 5Update from node tools:================================= Tool Message =================================
Name: add8.0Update from node agent:================================== Ai Message ==================================
Name: math_agent
Tool Calls:multiply (call_IBXYtlEMdZrfDZ8g8bWC31pM)Call ID: call_IBXYtlEMdZrfDZ8g8bWC31pMArgs:a: 8b: 7Update from node tools:================================= Tool Message =================================
Name: multiply56.0Update from node agent:================================== Ai Message ==================================
Name: math_agent56
2、使用 langgraph-supervisor 創建監督器
為了實現我們的多智能體系統,我們將使用預構建的 langgraph-supervisor 庫中的 create_supervisor 方法:
API 參考文檔:create_supervisor | init_chat_model
from langgraph_supervisor import create_supervisor
from langchain.chat_models import init_chat_modelsupervisor = create_supervisor(model=init_chat_model("openai:gpt-4.1"),agents=[research_agent, math_agent],prompt=("You are a supervisor managing two agents:\n""- a research agent. Assign research-related tasks to this agent\n""- a math agent. Assign math-related tasks to this agent\n""Assign work to one agent at a time, do not call agents in parallel.\n""Do not do any work yourself."),add_handoff_back_messages=True,output_mode="full_history",
).compile()
from IPython.display import display, Imagedisplay(Image(supervisor.get_graph().draw_mermaid_png()))
for chunk in supervisor.stream({"messages": [{"role": "user","content": "find US and New York state GDP in 2024、what % of US GDP was New York state?",}]},
):pretty_print_messages(chunk, last_message=True)final_message_history = chunk["supervisor"]["messages"]
Update from node supervisor:================================= Tool Message =================================
Name: transfer_to_research_agentSuccessfully transferred to research_agentUpdate from node research_agent:================================= Tool Message =================================
Name: transfer_back_to_supervisorSuccessfully transferred back to supervisorUpdate from node supervisor:================================= Tool Message =================================
Name: transfer_to_math_agentSuccessfully transferred to math_agentUpdate from node math_agent:================================= Tool Message =================================
Name: transfer_back_to_supervisorSuccessfully transferred back to supervisorUpdate from node supervisor:================================== Ai Message ==================================
Name: supervisorThe US GDP in 2024 was $29.017 trillion, and New York State's GDP was $2.284 trillion. New York State accounted for approximately 7.87% of the total US GDP in 2024、```
3、從零開始創建監督者
現在讓我們從頭開始實現這個相同的多智能體系統。我們需要完成以下步驟:
1、設置監督者與各個智能體之間的通信機制
2、創建監督者智能體
3、將監督者智能體和工作智能體組合成一個統一的多智能體圖
設置代理通信機制
我們需要定義一種方式讓監督代理與工作代理進行通信。在多代理架構中,常見的實現方式是使用交接機制,即一個代理將控制權交接給另一個代理。通過交接機制可以指定:
- 目標對象:要轉移到的目標代理
- 傳遞內容:需要傳遞給該代理的Info : 我們將通過交接工具來實現這一機制,并將這些工具賦予監督代理:當監督代理調用這些工具時,會將控制權移交給工作代理,同時將完整的消息歷史記錄傳遞給該代理。
API參考文檔:tool | InjectedToolCallId | InjectedState | StateGraph | START | Command
from typing import Annotated
from langchain_core.tools import tool, InjectedToolCallId
from langgraph.prebuilt import InjectedState
from langgraph.graph import StateGraph, START, MessagesState
from langgraph.types import Commanddef create_handoff_tool(*, agent_name: str, description: str | None = None):name = f"transfer_to_{agent_name}"description = description or f"Ask {agent_name} for help."@tool(name, description=description)def handoff_tool(state: Annotated[MessagesState, InjectedState],tool_call_id: Annotated[str, InjectedToolCallId],) -> Command:tool_message = {"role": "tool","content": f"Successfully transferred to {agent_name}","name": name,"tool_call_id": tool_call_id,}return Command(goto=agent_name, # (1)!update={**state, "messages": state["messages"] + [tool_message]}, # (2)!graph=Command.PARENT, # (3)!)return handoff_tool# Handoffs
assign_to_research_agent = create_handoff_tool(agent_name="research_agent",description="Assign task to a researcher agent.",
)assign_to_math_agent = create_handoff_tool(agent_name="math_agent",description="Assign task to a math agent.",
)
1、要交接給的目標代理或節點名稱。
2、在交接過程中,將當前代理的消息添加到父級狀態中。下一個代理將能夠看到父級狀態。
3、向LangGraph表明我們需要導航到父級多代理圖中的某個代理節點。
創建監督員代理
接下來,我們將使用剛剛定義好的交接工具來創建監督員代理。這里會用到預構建的 create_react_agent 方法:
(說明:嚴格遵循了代碼保護原則,保留了所有代碼塊和API名稱的原始格式;將被動語態轉換為主動語態;保持了技術文檔的簡潔性和準確性)
supervisor_agent = create_react_agent(model="openai:gpt-4.1",tools=[assign_to_research_agent, assign_to_math_agent],prompt=("You are a supervisor managing two agents:\n""- a research agent. Assign research-related tasks to this agent\n""- a math agent. Assign math-related tasks to this agent\n""Assign work to one agent at a time, do not call agents in parallel.\n""Do not do any work yourself."),name="supervisor",
)
創建多智能體圖
將所有組件整合起來,讓我們為整個多智能體系統創建一個圖。我們將把監督者和各個智能體作為子圖節點添加進來。
API參考:END
from langgraph.graph import END# Define the multi-agent supervisor graph
supervisor = (StateGraph(MessagesState)# NOTE: `destinations` is only needed for visualization and doesn't affect runtime behavior.add_node(supervisor_agent, destinations=("research_agent", "math_agent", END)).add_node(research_agent).add_node(math_agent).add_edge(START, "supervisor")# always return back to the supervisor.add_edge("research_agent", "supervisor").add_edge("math_agent", "supervisor").compile()
)
請注意,我們已明確添加了從工作代理返回到監督者的邊緣——這意味著系統能確保將控制權交還給監督者。若希望代理直接響應用戶(例如將系統轉變為路由器模式),則可以移除這些邊緣連接。
from IPython.display import display, Imagedisplay(Image(supervisor.get_graph().draw_mermaid_png()))
for chunk in supervisor.stream({"messages": [{"role": "user","content": "find US and New York state GDP in 2024、what % of US GDP was New York state?",}]},
):pretty_print_messages(chunk, last_message=True)final_message_history = chunk["supervisor"]["messages"]
Update from node supervisor:================================= Tool Message =================================
Name: transfer_to_research_agentSuccessfully transferred to research_agentUpdate from node research_agent:================================== Ai Message ==================================
Name: research_agent
- US GDP in 2024: $29.017 trillion (nominal, current prices)
- New York state GDP in 2024: $2.284 trillion
- New York state's share of US GDP in 2024: 7.87%Update from node supervisor:================================= Tool Message =================================
Name: transfer_to_math_agentSuccessfully transferred to math_agentUpdate from node math_agent:================================== Ai Message ==================================
Name: math_agentUS GDP in 2024: $29.017 trillion
New York state GDP in 2024: $2.284 trillion
New York state's share of US GDP: 7.87%Update from node supervisor:================================== Ai Message ==================================
Name: supervisorUS GDP in 2024 was $29.017 trillion. New York state GDP in 2024 was $2.284 trillion. New York state's GDP was about 7.87% of the US GDP.
讓我們來看看完整的消息歷史記錄:
for message in final_message_history:message.pretty_print()
================================ Human Message =================================find US and New York state GDP in 2024、what % of US GDP was New York state?
================================== Ai Message ==================================
Name: supervisor
Tool Calls:transfer_to_research_agent (call_qxk9abrxWYQT6a9hPNpXiuM0)Call ID: call_qxk9abrxWYQT6a9hPNpXiuM0Args:
================================= Tool Message =================================
Name: transfer_to_research_agentSuccessfully transferred to research_agent
================================== Ai Message ==================================
Name: research_agent
Tool Calls:tavily_search (call_A3cVm1BXDD8dYv6uLwO132gg)Call ID: call_A3cVm1BXDD8dYv6uLwO132ggArgs:query: US GDP 2024search_depth: advancedtavily_search (call_77JyoUYwGDXlRNKOwvQFUUYJ)Call ID: call_77JyoUYwGDXlRNKOwvQFUUYJArgs:query: New York state GDP 2024search_depth: advanced
================================= Tool Message =================================
Name: tavily_search{"query": "US GDP 2024", "follow_up_questions": null, "answer": null, "images": [], "results": [{"url": "https://tradingeconomics.com/united-states/gdp-growth", "title": "United States GDP Growth Rate - Trading Economics", "content": "The US economy expanded an annualized 2.4% in Q4 2024, slightly higher than 2.3% in the previous estimates, primarily reflecting a downward revision to imports. Exports fell slightly less (-0.2% vs -0.5%) and imports declined more than initially anticipated (-1.9% vs -1.2%), leaving the contribution from net trade positive at 0.26 pp (vs 0.12 pp). Government expenditure also rose more (3.1% vs 2.9%) and fixed investment contracted less (-1.1% vs -1.4%), due to equipment (-8.7% vs -9%) while [...] The Gross Domestic Product (GDP) in the United States expanded 2.40 percent in the fourth quarter of 2024 over the previous quarter. GDP Growth Rate in the United States averaged 3.21 percent from 1947 until 2024, reaching an all time high of 35.20 percent in the third quarter of 2020 and a record low of -28.10 percent in the second quarter of 2020、This page provides the latest reported value for - United States GDP Growth Rate - plus previous releases, historical high and low, short-term [...] The Gross Domestic Product (GDP) in the United States expanded 2.40 percent in the fourth quarter of 2024 over the previous quarter. GDP Growth Rate in the United States is expected to be 0.90 percent by the end of this quarter, according to Trading Economics global macro models and analysts expectations. In the long-term, the United States GDP Growth Rate is projected to trend around 2.00 percent in 2026, according to our econometric models.\n%\n3Y5Y10YMAX\nExport API\nOK\nLoading...", "score": 0.9071234, "raw_content": null}, {"url": "https://www.bea.gov/data/gdp/gross-domestic-product", "title": "Gross Domestic Product | U.S. Bureau of Economic Analysis (BEA)", "content": "Real gross domestic product (GDP) increased at an annual rate of 2.4 percent in the fourth quarter of 2024 (October, November, and December), according to the third estimate released by the U.S. Bureau of Economic Analysis. In the third quarter, real GDP increased 3.1 percent. The increase in real GDP in the fourth quarter primarily reflected increases in consumer spending and government spending that were partly offset by a decrease in investment. Imports, which are a subtraction in the", "score": 0.9008183, "raw_content": null}, {"url": "https://www.nerdwallet.com/article/finance/gdp-report", "title": "GDP Report: Final Estimate Shows Growth Increased 2.4% in Q4 2024", "content": "NerdWallet's content is fact-checked for accuracy, timeliness and relevance. It undergoes a thorough review process involving writers and editors to ensure the information is as clear and complete as possible.\n\nAnna Helhoski\n\nRick VanderKnyff\n\nUpdated on April 7\n\nReal gross domestic product increased by an annual rate of 2.4% in the fourth quarter of 2024, according to the third estimate report released on March 27 by the Bureau of Economic Analysis. [...] The third estimate also showed that in 2024, the U.S. GDP grew 2.8% compared to a 2.9% increase in 2023.\n\nQ1 2025 GDP forecasts are negative\n\nA forecasting tool published by the Atlanta Federal Reserve shows negative growth for the first quarter of 2025; it expects gross domestic product (GDP) to contract by rate of -2.8%, according to data released on March 28、If the forecast is correct, it would be the first quarter where GDP declined since the first and second quarters of 2022、[...] GDP could be the next concern: On March 3, a forecasting tool published by the Atlanta Federal Reserve showed that GDP could contract by a rate of -2.8% in the first quarter of 2025、If GDP does indeed decline, it would be the first time since the first and second quarters of 2022.\n\nIn 2024, the U.S. GDP grew 2.8% compared to a 2.9% increase in 2023, according to a second estimate of real gross domestic product from the Bureau of Economic Analysis, released Feb. 27.", "score": 0.89053273, "raw_content": null}], "response_time": 1.78}
================================= Tool Message =================================
Name: tavily_search{"query": "New York state GDP 2024", "follow_up_questions": null, "answer": null, "images": [], "results": [{"url": "https://en.wikipedia.org/wiki/Economy_of_New_York_(state)", "title": "Economy of New York (state) - Wikipedia", "content": "Jump to content\nMain menu\nSearch\nDonate\nCreate account\nLog in\nPersonal tools\nToggle the table of contents\nEconomy of New York (state)\n1 language\nArticle\nTalk\nRead\nEdit\nView history\nTools\nFrom Wikipedia, the free encyclopedia\nThis article is about the overall economy of New York State. For the economy of New York City, see Economy of New York City.\nEconomy of New York\nNew York City, the economic capital of New York (state)\nStatistics\nGDP $2.3 trillion (2024)[1]\nGDP per capita $117,332 (2024)[2] [...] The economy of the State of New York is reflected in its gross state product in 2024 of $2.284 trillion, ranking third in size behind the larger states of California and Texas. If New York State were an independent nation, it would rank as the 10th largest economy in the world by nominal GDP. However, in 2019, the multi-state, New York City-centered metropolitan statistical area produced a gross metropolitan product (GMP) of $US2.0 trillion, ranking first nationally by a wide margin and would [...] Population below poverty line 13.6%[3]\nGini coefficient 0.5157 ± 0.0029 (2023)[4]\nLabour force 9,645,984 (2023)[5]\nUnemployment 4.4% (August 2024)[6]\nPublic finances\nRevenues $63.5 billion[7]\nExpenses $54.6 billion[8]", "score": 0.9511106, "raw_content": null}, {"url": "https://en.wikipedia.org/wiki/List_of_U.S._states_and_territories_by_GDP", "title": "List of U.S. states and territories by GDP - Wikipedia", "content": "GDP per capita also varied widely throughout the United States in 2024, with New York ($117,332), Massachusetts ($110,561), and Washington (state) ($108,468) recording the three highest GDP per capita figures in the U.S., while Mississippi ($53,061), Arkansas ($60,276), and West Virginia ($60,783) recorded the three lowest GDP per capita figures in the U.S. The District of Columbia, though, recorded a GDP per capita figure far higher than any U.S. state in 2024 at $263,220、[...] Overall, in the calendar year 2024, the United States' Nominal GDP at Current Prices totaled at $29.017 trillion, as compared to $25.744 trillion in 2022.\nThe three U.S. states with the highest GDPs were California ($4.080 trillion), Texas ($2.695 trillion), and New York ($2.284 trillion). The three U.S. states with the lowest GDPs were Vermont ($45.4 billion), Wyoming ($53.0 billion), and Alaska ($69.8 billion).", "score": 0.8947989, "raw_content": null}, {"url": "https://edc.nyc/sites/default/files/2025-01/NYCEDC-State-of-the-NYC-Economy-2024-v3.pdf", "title": "[PDF] State of the New York City Economy - NYCEDC", "content": "for talent faced a limited supply. STATE OF THE NEW YORK CITY ECONOMY 2024 / 21 STATE OF THE NEW YORK CITY ECONOMY 2024 / 22 After losing nearly a million jobs during the COVID-19 pandemic, New York City is now at record-high levels of private and total employment. The city’s gross city product (GCP) stands at $1.18 trillion as of 2023.24 While legacy sectors such as Finance and Insurance have continued to play a vital part in the city’s economic successes, emerging sectors like Tech, the Green [...] STATE OF THE NEW YORK CITY ECONOMY 2024 / 11 New York City’s economy is the largest in the nation, with $2 trillion in gross metropolitan product (GMP) for the metro area, representing 9% of the total US economy. As such, the city’s economy is closely intertwined with the broader national economic landscape, and US macroeconomic conditions play a significant role in shaping the economic backdrop for the city. National interest rates, inflation, gross domestic product (GDP), and employment [...] 1 Macro Trends STATE OF THE NEW YORK CITY ECONOMY 2024 / 12 Output Has Grown Faster in NYC than Nationally Since 2022 Actual and Projected US Real GDP and NYC Real GCP Growth Rates 2019 2020 2021 2022 2023 2024* 2025* NYC 2.6% -4.2% 5.5% 2.6% 2.8% 3.6% 1.9% US 2.5% -2.2% 5.8% 1.9% 2.5% 2.5% 1.4% Source: NYC OMB and US Bureau of Economic Analysis. Projections for 2024 and and 2025 from NYC OMB.", "score": 0.85797083, "raw_content": null}], "response_time": 0.63}
================================== Ai Message ==================================
Name: research_agent
- US GDP in 2024: $29.017 trillion (nominal, current prices)
- New York state GDP in 2024: $2.284 trillion
- New York state's share of US GDP in 2024: 7.87%
================================== Ai Message ==================================
Name: supervisor
Tool Calls:transfer_to_math_agent (call_m5ICqaoAtRXHWb8BI3638dJL)Call ID: call_m5ICqaoAtRXHWb8BI3638dJLArgs:
================================= Tool Message =================================
Name: transfer_to_math_agentSuccessfully transferred to math_agent
================================== Ai Message ==================================
Name: math_agent
Tool Calls:divide (call_Sf7nvyvEgIaoDlaioPmkCdqz)Call ID: call_Sf7nvyvEgIaoDlaioPmkCdqzArgs:a: 2.284b: 29.017
================================= Tool Message =================================
Name: divide0.07871247889168417
================================== Ai Message ==================================
Name: math_agentUS GDP in 2024: $29.017 trillion
New York state GDP in 2024: $2.284 trillion
New York state's share of US GDP: 7.87%
================================== Ai Message ==================================
Name: supervisorUS GDP in 2024 was $29.017 trillion. New York state GDP in 2024 was $2.284 trillion. New York state's GDP was about 7.87% of the US GDP.
重要提示:
您可以看到監督系統會將所有獨立代理的消息(即它們的內部工具調用循環)附加到完整消息歷史中。這意味著監督代理在每次輪轉時都能看到完整的歷史記錄。如果您希望更精細地控制以下方面:
- 輸入如何傳遞給代理:可以使用LangGraph的
Send()](https://langchain-ai.github.io/langgraph/reference/types/#langgraph.types.Send)原語,在交接時直接將數據發送給工作代理。具體示例請參考下方的[任務委派部分 - 代理輸出如何添加:通過將代理封裝在獨立的節點函數中,您可以控制將代理內部消息歷史的多少內容添加到監督器的總體消息歷史中
def call_research_agent(state):# return agent's final response,# excluding inner monologueresponse = research_agent.invoke(state)return {"messages": response["messages"][-1]}
4、創建委派任務
目前各個智能體都依賴解析完整消息歷史來確定任務。另一種方法是讓監督者明確制定任務。我們可以通過在handoff_tool函數中添加task_description參數來實現。
API參考:Send
from langgraph.types import Senddef create_task_description_handoff_tool(*, agent_name: str, description: str | None = None
):name = f"transfer_to_{agent_name}"description = description or f"Ask {agent_name} for help."@tool(name, description=description)def handoff_tool(# this is populated by the supervisor LLMtask_description: Annotated[str,"Description of what the next agent should do, including all of the relevant context.",],# these parameters are ignored by the LLMstate: Annotated[MessagesState, InjectedState],) -> Command:task_description_message = {"role": "user", "content": task_description}agent_input = {**state, "messages": [task_description_message]}return Command(goto=[Send(agent_name, agent_input)],graph=Command.PARENT,)return handoff_toolassign_to_research_agent_with_description = create_task_description_handoff_tool(agent_name="research_agent",description="Assign task to a researcher agent.",
)assign_to_math_agent_with_description = create_task_description_handoff_tool(agent_name="math_agent",description="Assign task to a math agent.",
)supervisor_agent_with_description = create_react_agent(model="openai:gpt-4.1",tools=[assign_to_research_agent_with_description,assign_to_math_agent_with_description,],prompt=("You are a supervisor managing two agents:\n""- a research agent. Assign research-related tasks to this assistant\n""- a math agent. Assign math-related tasks to this assistant\n""Assign work to one agent at a time, do not call agents in parallel.\n""Do not do any work yourself."),name="supervisor",
)supervisor_with_description = (StateGraph(MessagesState).add_node(supervisor_agent_with_description, destinations=("research_agent", "math_agent")).add_node(research_agent).add_node(math_agent).add_edge(START, "supervisor").add_edge("research_agent", "supervisor").add_edge("math_agent", "supervisor").compile()
)
注意:我們在 handoff_tool 中使用了 Send() 原語。這意味著每個工作代理不會接收到完整的 supervisor 圖狀態作為輸入,而只會看到 Send 負載的內容。在本示例中,我們將任務描述作為一條單獨的"human"消息發送。
現在讓我們用相同的輸入查詢來運行它:
for chunk in supervisor.stream({"messages": [{"role": "user","content": "find US and New York state GDP in 2024、what % of US GDP was New York state?",}]},subgraphs=True,
):pretty_print_messages(chunk, last_message=True)
Update from subgraph supervisor:Update from node agent:================================== Ai Message ==================================Name: supervisorTool Calls:transfer_to_research_agent (call_TtKzjGQBe4X9Xh0VzmjStVgZ)Call ID: call_TtKzjGQBe4X9Xh0VzmjStVgZArgs:Update from subgraph research_agent:Update from node agent:================================== Ai Message ==================================Name: research_agentTool Calls:tavily_search (call_AfeRYBJxJtmD4EKqifYcx8EI)Call ID: call_AfeRYBJxJtmD4EKqifYcx8EIArgs:query: US GDP in 2024search_depth: advancedtavily_search (call_n7Dn8QnDLu2ZpEDzswS2MOJ8)Call ID: call_n7Dn8QnDLu2ZpEDzswS2MOJ8Args:query: New York state GDP in 2024search_depth: advancedUpdate from subgraph research_agent:Update from node tools:================================= Tool Message =================================Name: tavily_search{"query": "New York state GDP in 2024", "follow_up_questions": null, "answer": null, "images": [], "results": [{"url": "https://en.wikipedia.org/wiki/Economy_of_New_York_(state)", "title": "Economy of New York (state) - Wikipedia", "content": "Jump to content\nMain menu\nSearch\nDonate\nCreate account\nLog in\nPersonal tools\nToggle the table of contents\nEconomy of New York (state)\n1 language\nArticle\nTalk\nRead\nEdit\nView history\nTools\nFrom Wikipedia, the free encyclopedia\nThis article is about the overall economy of New York State. For the economy of New York City, see Economy of New York City.\nEconomy of New York\nNew York City, the economic capital of New York (state)\nStatistics\nGDP $2.3 trillion (2024)[1]\nGDP per capita $117,332 (2024)[2] [...] The economy of the State of New York is reflected in its gross state product in 2024 of $2.284 trillion, ranking third in size behind the larger states of California and Texas. If New York State were an independent nation, it would rank as the 10th largest economy in the world by nominal GDP. However, in 2019, the multi-state, New York City-centered metropolitan statistical area produced a gross metropolitan product (GMP) of $US2.0 trillion, ranking first nationally by a wide margin and would [...] Population below poverty line 13.6%[3]\nGini coefficient 0.5157 ± 0.0029 (2023)[4]\nLabour force 9,645,984 (2023)[5]\nUnemployment 4.4% (August 2024)[6]\nPublic finances\nRevenues $63.5 billion[7]\nExpenses $54.6 billion[8]", "score": 0.9530353, "raw_content": null}, {"url": "https://en.wikipedia.org/wiki/List_of_U.S._states_and_territories_by_GDP", "title": "List of U.S. states and territories by GDP - Wikipedia", "content": "GDP per capita also varied widely throughout the United States in 2024, with New York ($117,332), Massachusetts ($110,561), and Washington (state) ($108,468) recording the three highest GDP per capita figures in the U.S., while Mississippi ($53,061), Arkansas ($60,276), and West Virginia ($60,783) recorded the three lowest GDP per capita figures in the U.S. The District of Columbia, though, recorded a GDP per capita figure far higher than any U.S. state in 2024 at $263,220、[...] Overall, in the calendar year 2024, the United States' Nominal GDP at Current Prices totaled at $29.017 trillion, as compared to $25.744 trillion in 2022.\nThe three U.S. states with the highest GDPs were California ($4.080 trillion), Texas ($2.695 trillion), and New York ($2.284 trillion). The three U.S. states with the lowest GDPs were Vermont ($45.4 billion), Wyoming ($53.0 billion), and Alaska ($69.8 billion).", "score": 0.89997756, "raw_content": null}, {"url": "https://edc.nyc/sites/default/files/2025-01/NYCEDC-State-of-the-NYC-Economy-2024-v3.pdf", "title": "[PDF] State of the New York City Economy - NYCEDC", "content": "for talent faced a limited supply. STATE OF THE NEW YORK CITY ECONOMY 2024 / 21 STATE OF THE NEW YORK CITY ECONOMY 2024 / 22 After losing nearly a million jobs during the COVID-19 pandemic, New York City is now at record-high levels of private and total employment. The city’s gross city product (GCP) stands at $1.18 trillion as of 2023.24 While legacy sectors such as Finance and Insurance have continued to play a vital part in the city’s economic successes, emerging sectors like Tech, the Green [...] STATE OF THE NEW YORK CITY ECONOMY 2024 / 11 New York City’s economy is the largest in the nation, with $2 trillion in gross metropolitan product (GMP) for the metro area, representing 9% of the total US economy. As such, the city’s economy is closely intertwined with the broader national economic landscape, and US macroeconomic conditions play a significant role in shaping the economic backdrop for the city. National interest rates, inflation, gross domestic product (GDP), and employment [...] 1 Macro Trends STATE OF THE NEW YORK CITY ECONOMY 2024 / 12 Output Has Grown Faster in NYC than Nationally Since 2022 Actual and Projected US Real GDP and NYC Real GCP Growth Rates 2019 2020 2021 2022 2023 2024* 2025* NYC 2.6% -4.2% 5.5% 2.6% 2.8% 3.6% 1.9% US 2.5% -2.2% 5.8% 1.9% 2.5% 2.5% 1.4% Source: NYC OMB and US Bureau of Economic Analysis. Projections for 2024 and and 2025 from NYC OMB.", "score": 0.8616433, "raw_content": null}], "response_time": 2.35}Update from subgraph research_agent:Update from node agent:================================== Ai Message ==================================Name: research_agent- US GDP in 2024 was $29.017 trillion (nominal, current prices) ([source](https://en.wikipedia.org/wiki/List_of_U.S._states_and_territories_by_GDP)).- New York State GDP in 2024 was $2.284 trillion ([source](https://en.wikipedia.org/wiki/Economy_of_New_York_(state))).Percentage of US GDP attributed to New York State in 2024: approximately 7.9%.Update from subgraph supervisor:Update from node agent:================================== Ai Message ==================================Name: supervisorTool Calls:transfer_to_math_agent (call_oYbIXhQQeTWlj2zvZSoStUgO)Call ID: call_oYbIXhQQeTWlj2zvZSoStUgOArgs:Update from subgraph math_agent:Update from node agent:================================== Ai Message ==================================Name: math_agentTool Calls:divide (call_K5QxmkQYFfCZw5Vzkbz43VIG)Call ID: call_K5QxmkQYFfCZw5Vzkbz43VIGArgs:a: 2.284b: 29.017Update from subgraph math_agent:Update from node tools:================================= Tool Message =================================Name: divide0.07871247889168417Update from subgraph math_agent:Update from node agent:================================== Ai Message ==================================Name: math_agentNew York state's GDP was approximately 7.87% of US GDP in 2024.Update from subgraph supervisor:Update from node agent:================================== Ai Message ==================================Name: supervisorHere are the findings:- US GDP in 2024: $29.017 trillion- New York State GDP in 2024: $2.284 trillion- New York State accounted for approximately 7.87% of US GDP in 2024、```
構建SQL代理
https://langchain-ai.github.io/langgraph/tutorials/sql-agent/
在本教程中,我們將逐步介紹如何構建一個能夠回答關于SQL數據庫問題的代理程序。
從高層次來看,該代理將完成以下工作:
1、從數據庫中獲取可用表
2、確定哪些表與問題相關
3、獲取相關表的模式結構
4、根據問題和模式信息生成查詢語句
5、使用LLM檢查查詢語句中的常見錯誤
6、執行查詢并返回結果
7、修正數據庫引擎發現的錯誤,直到查詢成功
8、根據結果生成響應
安全注意事項
構建SQL數據庫問答系統需要執行模型生成的SQL查詢語句。這樣做存在固有風險。請確保您的數據庫連接權限始終按照代理需求進行最小化范圍限定。這將減輕(但不能完全消除)構建模型驅動系統所帶來的風險。
1、環境配置
首先我們需要安裝一些依賴項。本教程將使用來自langchain-community的SQL數據庫和工具抽象層。同時還需要安裝LangChain的聊天模型組件。
pip install -U langgraph langchain_community "langchain[openai]"
為LangGraph開發配置LangSmith
注冊LangSmith可快速發現并優化LangGraph項目的性能問題。通過LangSmith,您能利用追蹤數據來調試、測試和監控基于LangGraph構建的LLM應用——了解更多入門指南請訪問這里。
選擇大語言模型
首先我們需要初始化大語言模型。任何支持工具調用功能的模型都可以使用。以下示例我們采用OpenAI。
API參考文檔:init_chat_model
from langchain.chat_models import init_chat_modelllm = init_chat_model("openai:gpt-4.1")
配置數據庫
在本教程中,我們將創建一個SQLite數據庫。SQLite是一種輕量級數據庫,易于設置和使用。我們將加載chinook示例數據庫,該數據庫模擬了一個數字媒體商店。
有關該數據庫的更多信息,請參閱此處。
為方便起見,我們已將數據庫文件(Chinook.db)托管在公共GCS存儲桶中。
import requestsurl = "https://storage.googleapis.com/benchmarks-artifacts/chinook/Chinook.db"response = requests.get(url)if response.status_code == 200:# Open a local file in binary write modewith open("Chinook.db", "wb") as file:# Write the content of the response (the file) to the local filefile.write(response.content)print("File downloaded and saved as Chinook.db")
else:print(f"Failed to download the file. Status code: {response.status_code}")
我們將使用langchain_community包中提供的一個便捷SQL數據庫封裝器來與數據庫交互。該封裝器提供了執行SQL查詢和獲取結果的簡單接口:
API參考文檔:SQLDatabase
from langchain_community.utilities import SQLDatabasedb = SQLDatabase.from_uri("sqlite:///Chinook.db")print(f"Dialect: {db.dialect}")
print(f"Available tables: {db.get_usable_table_names()}")
print(f'Sample output: {db.run("SELECT * FROM Artist LIMIT 5;")}')
Dialect: sqlite
Available tables: ['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
Sample output: [(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains')]
數據庫交互工具
langchain-community 實現了一些內置工具,用于與 SQLDatabase 進行交互,包括列出表、讀取表結構、檢查和運行查詢等工具:
API 參考:SQLDatabaseToolkit
from langchain_community.agent_toolkits import SQLDatabaseToolkittoolkit = SQLDatabaseToolkit(db=db, llm=llm)tools = toolkit.get_tools()for tool in tools:print(f"{tool.name}: {tool.description}\n")
sql_db_query: Input to this tool is a detailed and correct SQL query, output is a result from the database. If the query is not correct, an error message will be returned. If an error is returned, rewrite the query, check the query, and try again. If you encounter an issue with Unknown column 'xxxx' in 'field list', use sql_db_schema to query the correct table fields.sql_db_schema: Input to this tool is a comma-separated list of tables, output is the schema and sample rows for those tables. Be sure that the tables actually exist by calling sql_db_list_tables first! Example Input: table1, table2, table3sql_db_list_tables: Input is an empty string, output is a comma-separated list of tables in the database.sql_db_query_checker: Use this tool to double check if your query is correct before executing it. Always use this tool before executing a query with sql_db_query!
2、使用預構建的Agent
基于這些工具,我們可以用一行代碼初始化一個預構建的Agent。為了定制Agent的行為,我們需要編寫一個描述性的系統提示。
API參考文檔: create_react_agent
from langgraph.prebuilt import create_react_agentsystem_prompt = """
You are an agent designed to interact with a SQL database.
Given an input question, create a syntactically correct {dialect} query to run,
then look at the results of the query and return the answer. Unless the user
specifies a specific number of examples they wish to obtain, always limit your
query to at most {top_k} results.You can order the results by a relevant column to return the most interesting
examples in the database. Never query for all the columns from a specific table,
only ask for the relevant columns given the question.You MUST double check your query before executing it. If you get an error while
executing a query, rewrite the query and try again.DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the
database.To start you should ALWAYS look at the tables in the database to see what you
can query. Do NOT skip this step.Then you should query the schema of the most relevant tables.
""".format(dialect=db.dialect,top_k=5,
)agent = create_react_agent(llm,tools,prompt=system_prompt,
)
注意:本系統提示包含多項指令,例如始終在運行其他工具之前或之后執行特定工具。在下一節中,我們將通過圖結構強制執行這些行為,從而提供更高程度的控制,并允許我們簡化提示。
讓我們在示例查詢上運行此代理并觀察其行為:
question = "Which sales agent made the most in sales in 2009?"for step in agent.stream({"messages": [{"role": "user", "content": question}]},stream_mode="values",
):step["messages"][-1].pretty_print()
================================ Human Message =================================Which sales agent made the most in sales in 2009?
================================== Ai Message ==================================
Tool Calls:sql_db_list_tables (call_0MfnhUYmRNVe03m6fYClaoa0)Call ID: call_0MfnhUYmRNVe03m6fYClaoa0Args:tool_input:
================================= Tool Message =================================
Name: sql_db_list_tablesAlbum, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
================================== Ai Message ==================================
Tool Calls:sql_db_schema (call_XwI6uES0HeZ2xCRxkkdWzB3I)Call ID: call_XwI6uES0HeZ2xCRxkkdWzB3IArgs:table_names: Employee, Invoice, InvoiceLine
================================= Tool Message =================================
Name: sql_db_schemaCREATE TABLE "Employee" ("EmployeeId" INTEGER NOT NULL, "LastName" NVARCHAR(20) NOT NULL, "FirstName" NVARCHAR(20) NOT NULL, "Title" NVARCHAR(30), "ReportsTo" INTEGER, "BirthDate" DATETIME, "HireDate" DATETIME, "Address" NVARCHAR(70), "City" NVARCHAR(40), "State" NVARCHAR(40), "Country" NVARCHAR(40), "PostalCode" NVARCHAR(10), "Phone" NVARCHAR(24), "Fax" NVARCHAR(24), "Email" NVARCHAR(60), PRIMARY KEY ("EmployeeId"), FOREIGN KEY("ReportsTo") REFERENCES "Employee" ("EmployeeId")
)/*
3 rows from Employee table:
EmployeeId LastName FirstName Title ReportsTo BirthDate HireDate Address City State Country PostalCode Phone Fax Email
1 Adams Andrew General Manager None 1962-02-18 00:00:00 2002-08-14 00:00:00 11120 Jasper Ave NW Edmonton AB Canada T5K 2N1 +1 (780) 428-9482 +1 (780) 428-3457 andrew@chinookcorp.com
2 Edwards Nancy Sales Manager 1 1958-12-08 00:00:00 2002-05-01 00:00:00 825 8 Ave SW Calgary AB Canada T2P 2T3 +1 (403) 262-3443 +1 (403) 262-3322 nancy@chinookcorp.com
3 Peacock Jane Sales Support Agent 2 1973-08-29 00:00:00 2002-04-01 00:00:00 1111 6 Ave SW Calgary AB Canada T2P 5M5 +1 (403) 262-3443 +1 (403) 262-6712 jane@chinookcorp.com
*/CREATE TABLE "Invoice" ("InvoiceId" INTEGER NOT NULL, "CustomerId" INTEGER NOT NULL, "InvoiceDate" DATETIME NOT NULL, "BillingAddress" NVARCHAR(70), "BillingCity" NVARCHAR(40), "BillingState" NVARCHAR(40), "BillingCountry" NVARCHAR(40), "BillingPostalCode" NVARCHAR(10), "Total" NUMERIC(10, 2) NOT NULL, PRIMARY KEY ("InvoiceId"), FOREIGN KEY("CustomerId") REFERENCES "Customer" ("CustomerId")
)/*
3 rows from Invoice table:
InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total
1 2 2009-01-01 00:00:00 Theodor-Heuss-Stra?e 34 Stuttgart None Germany 70174 1.98
2 4 2009-01-02 00:00:00 Ullev?lsveien 14 Oslo None Norway 0171 3.96
3 8 2009-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94
*/CREATE TABLE "InvoiceLine" ("InvoiceLineId" INTEGER NOT NULL, "InvoiceId" INTEGER NOT NULL, "TrackId" INTEGER NOT NULL, "UnitPrice" NUMERIC(10, 2) NOT NULL, "Quantity" INTEGER NOT NULL, PRIMARY KEY ("InvoiceLineId"), FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"), FOREIGN KEY("InvoiceId") REFERENCES "Invoice" ("InvoiceId")
)/*
3 rows from InvoiceLine table:
InvoiceLineId InvoiceId TrackId UnitPrice Quantity
1 1 2 0.99 1
2 1 4 0.99 1
3 2 6 0.99 1
*/
================================== Ai Message ==================================
Tool Calls:sql_db_schema (call_dHE5FKSycFhYIkdPKtpEk9rM)Call ID: call_dHE5FKSycFhYIkdPKtpEk9rMArgs:table_names: Customer
================================= Tool Message =================================
Name: sql_db_schemaCREATE TABLE "Customer" ("CustomerId" INTEGER NOT NULL, "FirstName" NVARCHAR(40) NOT NULL, "LastName" NVARCHAR(20) NOT NULL, "Company" NVARCHAR(80), "Address" NVARCHAR(70), "City" NVARCHAR(40), "State" NVARCHAR(40), "Country" NVARCHAR(40), "PostalCode" NVARCHAR(10), "Phone" NVARCHAR(24), "Fax" NVARCHAR(24), "Email" NVARCHAR(60) NOT NULL, "SupportRepId" INTEGER, PRIMARY KEY ("CustomerId"), FOREIGN KEY("SupportRepId") REFERENCES "Employee" ("EmployeeId")
)/*
3 rows from Customer table:
CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId
1 Luís Gon?alves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 S?o José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 3
2 Leonie K?hler None Theodor-Heuss-Stra?e 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 5
3 Fran?ois Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3
*/
================================== Ai Message ==================================
Tool Calls:sql_db_query_checker (call_QPtWY5cUZWgWhr13Kz6eBJkU)Call ID: call_QPtWY5cUZWgWhr13Kz6eBJkUArgs:query: SELECT e.EmployeeId, e.FirstName, e.LastName, SUM(i.Total) as TotalSales
FROM Employee e
JOIN Customer c ON e.EmployeeId = c.SupportRepId
JOIN Invoice i ON c.CustomerId = i.CustomerId
WHERE i.InvoiceDate BETWEEN '2009-01-01' AND '2009-12-31'
GROUP BY e.EmployeeId, e.FirstName, e.LastName
ORDER BY TotalSales DESC
LIMIT 1;
================================= Tool Message =================================
Name: sql_db_query_checker\`\`\`sql
SELECT e.EmployeeId, e.FirstName, e.LastName, SUM(i.Total) as TotalSales
FROM Employee e
JOIN Customer c ON e.EmployeeId = c.SupportRepId
JOIN Invoice i ON c.CustomerId = i.CustomerId
WHERE i.InvoiceDate BETWEEN '2009-01-01' AND '2009-12-31'
GROUP BY e.EmployeeId, e.FirstName, e.LastName
ORDER BY TotalSales DESC
LIMIT 1;
\`\`\`
================================== Ai Message ==================================
Tool Calls:sql_db_query (call_X747YMElSeY5D3CfhE6KzLUj)Call ID: call_X747YMElSeY5D3CfhE6KzLUjArgs:query: SELECT e.EmployeeId, e.FirstName, e.LastName, SUM(i.Total) as TotalSales
FROM Employee e
JOIN Customer c ON e.EmployeeId = c.SupportRepId
JOIN Invoice i ON c.CustomerId = i.CustomerId
WHERE i.InvoiceDate BETWEEN '2009-01-01' AND '2009-12-31'
GROUP BY e.EmployeeId, e.FirstName, e.LastName
ORDER BY TotalSales DESC
LIMIT 1;
================================= Tool Message =================================
Name: sql_db_query[(5, 'Steve', 'Johnson', 164.34)]
================================== Ai Message ==================================The sales agent who made the most in sales in 2009 was Steve Johnson, with total sales of 164.34.
效果相當不錯:智能體正確地列出了表格、獲取了模式、編寫了查詢語句、檢查了查詢,并最終執行查詢以生成最終響應。
提示:
您可以在LangSmith跟蹤記錄中查看上述運行的所有細節,包括采取的步驟、調用的工具、LLM接收到的提示等內容。
3、自定義智能體
預構建的智能體讓我們能夠快速上手,但在每個步驟中,該智能體都可以訪問完整的工具集。上文我們依賴系統提示來約束其行為——例如,我們指示智能體始終以"列出表格"工具開始,并在執行查詢前始終運行查詢檢查工具。
在LangGraph中,我們可以通過自定義智能體來實現更高程度的控制。下面我們將實現一個簡單的ReAct智能體設置,為特定的工具調用創建專用節點。我們將使用與預構建智能體相同的狀態。
我們為以下步驟構建專用節點:
- 列出數據庫表格
- 調用"獲取模式"工具
- 生成查詢
- 檢查查詢
將這些步驟放入專用節點使我們能夠:(1) 在需要時強制進行工具調用,(2) 自定義與每個步驟關聯的提示。
API參考:AIMessage | RunnableConfig | END | START | StateGraph | ToolNode
from typing import Literal
from langchain_core.messages import AIMessage
from langchain_core.runnables import RunnableConfig
from langgraph.graph import END, START, MessagesState, StateGraph
from langgraph.prebuilt import ToolNodeget_schema_tool = next(tool for tool in tools if tool.name == "sql_db_schema")
get_schema_node = ToolNode([get_schema_tool], name="get_schema")run_query_tool = next(tool for tool in tools if tool.name == "sql_db_query")
run_query_node = ToolNode([run_query_tool], name="run_query")# Example: create a predetermined tool call
def list_tables(state: MessagesState):tool_call = {"name": "sql_db_list_tables","args": {},"id": "abc123","type": "tool_call",}tool_call_message = AIMessage(content="", tool_calls=[tool_call])list_tables_tool = next(tool for tool in tools if tool.name == "sql_db_list_tables")tool_message = list_tables_tool.invoke(tool_call)response = AIMessage(f"Available tables: {tool_message.content}")return {"messages": [tool_call_message, tool_message, response]}# Example: force a model to create a tool call
def call_get_schema(state: MessagesState):# Note that LangChain enforces that all models accept `tool_choice="any"`# as well as `tool_choice=<string name of tool>`.llm_with_tools = llm.bind_tools([get_schema_tool], tool_choice="any")response = llm_with_tools.invoke(state["messages"])return {"messages": [response]}generate_query_system_prompt = """
You are an agent designed to interact with a SQL database.
Given an input question, create a syntactically correct {dialect} query to run,
then look at the results of the query and return the answer. Unless the user
specifies a specific number of examples they wish to obtain, always limit your
query to at most {top_k} results.You can order the results by a relevant column to return the most interesting
examples in the database. Never query for all the columns from a specific table,
only ask for the relevant columns given the question.DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.
""".format(dialect=db.dialect,top_k=5,
)def generate_query(state: MessagesState):system_message = {"role": "system","content": generate_query_system_prompt,}# We do not force a tool call here, to allow the model to# respond naturally when it obtains the solution.llm_with_tools = llm.bind_tools([run_query_tool])response = llm_with_tools.invoke([system_message] + state["messages"])return {"messages": [response]}check_query_system_prompt = """
You are a SQL expert with a strong attention to detail.
Double check the {dialect} query for common mistakes, including:
- Using NOT IN with NULL values
- Using UNION when UNION ALL should have been used
- Using BETWEEN for exclusive ranges
- Data type mismatch in predicates
- Properly quoting identifiers
- Using the correct number of arguments for functions
- Casting to the correct data type
- Using the proper columns for joinsIf there are any of the above mistakes, rewrite the query. If there are no mistakes,
just reproduce the original query.You will call the appropriate tool to execute the query after running this check.
""".format(dialect=db.dialect)def check_query(state: MessagesState):system_message = {"role": "system","content": generate_query_system_prompt,}# Generate an artificial user message to checktool_call = state["messages"][-1].tool_calls[0]user_message = {"role": "user", "content": tool_call["args"]["query"]}llm_with_tools = llm.bind_tools([run_query_tool], tool_choice="any")response = llm_with_tools.invoke([system_message, user_message])response.id = state["messages"][-1].idreturn {"messages": [response]}
最后,我們使用 Graph API 將這些步驟組裝成一個工作流。我們在查詢生成步驟定義了一個條件邊,當生成查詢時會路由至查詢檢查器;若不存在工具調用(即LLM已直接響應查詢),則流程終止。
def should_continue(state: MessagesState) -> Literal[END, "check_query"]:messages = state["messages"]last_message = messages[-1]if not last_message.tool_calls:return ENDelse:return "check_query"builder = StateGraph(MessagesState)
builder.add_node(list_tables)
builder.add_node(call_get_schema)
builder.add_node(get_schema_node, "get_schema")
builder.add_node(generate_query)
builder.add_node(check_query)
builder.add_node(run_query_node, "run_query")builder.add_edge(START, "list_tables")
builder.add_edge("list_tables", "call_get_schema")
builder.add_edge("call_get_schema", "get_schema")
builder.add_edge("get_schema", "generate_query")
builder.add_conditional_edges("generate_query",should_continue,
)
builder.add_edge("check_query", "run_query")
builder.add_edge("run_query", "generate_query")agent = builder.compile()
我們通過以下方式可視化該應用:
API參考文檔:CurveStyle | MermaidDrawMethod | NodeStyles
from IPython.display import Image, display
from langchain_core.runnables.graph import CurveStyle, MermaidDrawMethod, NodeStylesdisplay(Image(agent.get_graph().draw_mermaid_png()))
question = "Which sales agent made the most in sales in 2009?"for step in agent.stream({"messages": [{"role": "user", "content": question}]},stream_mode="values",
):step["messages"][-1].pretty_print()
================================ Human Message =================================Which sales agent made the most in sales in 2009?
================================== Ai Message ==================================Available tables: Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
================================== Ai Message ==================================
Tool Calls:sql_db_schema (call_rMs3sF1HVcAGggGf89ZNvtLE)Call ID: call_rMs3sF1HVcAGggGf89ZNvtLEArgs:table_names: Employee,Invoice,Customer
================================= Tool Message =================================
Name: sql_db_schemaCREATE TABLE "Customer" ("CustomerId" INTEGER NOT NULL, "FirstName" NVARCHAR(40) NOT NULL, "LastName" NVARCHAR(20) NOT NULL, "Company" NVARCHAR(80), "Address" NVARCHAR(70), "City" NVARCHAR(40), "State" NVARCHAR(40), "Country" NVARCHAR(40), "PostalCode" NVARCHAR(10), "Phone" NVARCHAR(24), "Fax" NVARCHAR(24), "Email" NVARCHAR(60) NOT NULL, "SupportRepId" INTEGER, PRIMARY KEY ("CustomerId"), FOREIGN KEY("SupportRepId") REFERENCES "Employee" ("EmployeeId")
)/*
3 rows from Customer table:
CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId
1 Luís Gon?alves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 S?o José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 3
2 Leonie K?hler None Theodor-Heuss-Stra?e 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 5
3 Fran?ois Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3
*/CREATE TABLE "Employee" ("EmployeeId" INTEGER NOT NULL, "LastName" NVARCHAR(20) NOT NULL, "FirstName" NVARCHAR(20) NOT NULL, "Title" NVARCHAR(30), "ReportsTo" INTEGER, "BirthDate" DATETIME, "HireDate" DATETIME, "Address" NVARCHAR(70), "City" NVARCHAR(40), "State" NVARCHAR(40), "Country" NVARCHAR(40), "PostalCode" NVARCHAR(10), "Phone" NVARCHAR(24), "Fax" NVARCHAR(24), "Email" NVARCHAR(60), PRIMARY KEY ("EmployeeId"), FOREIGN KEY("ReportsTo") REFERENCES "Employee" ("EmployeeId")
)/*
3 rows from Employee table:
EmployeeId LastName FirstName Title ReportsTo BirthDate HireDate Address City State Country PostalCode Phone Fax Email
1 Adams Andrew General Manager None 1962-02-18 00:00:00 2002-08-14 00:00:00 11120 Jasper Ave NW Edmonton AB Canada T5K 2N1 +1 (780) 428-9482 +1 (780) 428-3457 andrew@chinookcorp.com
2 Edwards Nancy Sales Manager 1 1958-12-08 00:00:00 2002-05-01 00:00:00 825 8 Ave SW Calgary AB Canada T2P 2T3 +1 (403) 262-3443 +1 (403) 262-3322 nancy@chinookcorp.com
3 Peacock Jane Sales Support Agent 2 1973-08-29 00:00:00 2002-04-01 00:00:00 1111 6 Ave SW Calgary AB Canada T2P 5M5 +1 (403) 262-3443 +1 (403) 262-6712 jane@chinookcorp.com
*/CREATE TABLE "Invoice" ("InvoiceId" INTEGER NOT NULL, "CustomerId" INTEGER NOT NULL, "InvoiceDate" DATETIME NOT NULL, "BillingAddress" NVARCHAR(70), "BillingCity" NVARCHAR(40), "BillingState" NVARCHAR(40), "BillingCountry" NVARCHAR(40), "BillingPostalCode" NVARCHAR(10), "Total" NUMERIC(10, 2) NOT NULL, PRIMARY KEY ("InvoiceId"), FOREIGN KEY("CustomerId") REFERENCES "Customer" ("CustomerId")
)/*
3 rows from Invoice table:
InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total
1 2 2009-01-01 00:00:00 Theodor-Heuss-Stra?e 34 Stuttgart None Germany 70174 1.98
2 4 2009-01-02 00:00:00 Ullev?lsveien 14 Oslo None Norway 0171 3.96
3 8 2009-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94
*/
================================== Ai Message ==================================
Tool Calls:sql_db_query (call_TQyoJSV78xEWHqc69PiYHjdS)Call ID: call_TQyoJSV78xEWHqc69PiYHjdSArgs:query: SELECT e.FirstName, e.LastName, SUM(i.Total) as TotalSales
FROM Employee e
JOIN Customer c ON e.EmployeeId = c.SupportRepId
JOIN Invoice i ON c.CustomerId = i.CustomerId
WHERE strftime('%Y', i.InvoiceDate) = '2009'
GROUP BY e.EmployeeId
ORDER BY TotalSales DESC
LIMIT 1;
================================== Ai Message ==================================
Tool Calls:sql_db_query (call_tSQOuxc7iQ1jvLzXSofCqK4V)Call ID: call_tSQOuxc7iQ1jvLzXSofCqK4VArgs:query: SELECT e.FirstName, e.LastName, SUM(i.Total) as TotalSales
FROM Employee e
JOIN Customer c ON e.EmployeeId = c.SupportRepId
JOIN Invoice i ON c.CustomerId = i.CustomerId
WHERE strftime('%Y', i.InvoiceDate) = '2009'
GROUP BY e.EmployeeId
ORDER BY TotalSales DESC
LIMIT 1;
================================= Tool Message =================================
Name: sql_db_query[('Steve', 'Johnson', 164.34)]
================================== Ai Message ==================================The sales agent who made the most in sales in 2009 was Steve Johnson, with total sales of 164.34.
提示:
查看上述運行的 LangSmith 追蹤記錄。
后續步驟
查看本指南,了解如何使用LangSmith評估LangGraph應用程序(包括本文中的SQL代理)。
如何在LangSmith中為圖運行傳遞自定義運行ID或設置標簽和元數據
https://langchain-ai.github.io/langgraph/how-tos/run-id-langsmith/
前提條件
本指南假設您已熟悉以下內容:
- LangSmith文檔
- LangSmith平臺
- RunnableConfig
- 向追蹤記錄添加元數據和標簽
- 自定義運行名稱
概述
在IDE或終端中調試圖運行有時可能比較困難。LangSmith允許您使用追蹤數據來調試、測試和監控使用LangGraph構建的LLM應用——請參閱LangSmith文檔獲取更多入門信息。
為了更容易識別和分析圖調用期間生成的追蹤記錄,您可以在運行時設置額外的配置(參見RunnableConfig):
| 字段 | 類型 | 描述 |
|---|---|---|
| run_name | str | 此調用的追蹤運行名稱。默認為類名。 |
| run_id | UUID | 此調用的追蹤運行唯一標識符。如果未提供,將生成新的UUID。 |
| tags | List[str] | 此調用及任何子調用(例如,Chain調用LLM)的標簽。可用于篩選調用。 |
| metadata | Dict[str, Any] | 此調用及任何子調用(例如,Chain調用LLM)的元數據。鍵應為字符串,值應可JSON序列化。 |
實現方式
LangGraph圖實現了LangChain Runnable接口,并在invoke、ainvoke、stream等方法中接受第二個參數(RunnableConfig)。
LangSmith平臺允許您基于run_name、run_id、tags和metadata來搜索和篩選追蹤記錄。
TLDR
import uuid
# Generate a random UUID -- it must be a UUID
config = {"run_id": uuid.uuid4()}, "tags": ["my_tag1"], "metadata": {"a": 5}}
# Works with all standard Runnable methods
# like invoke, batch, ainvoke, astream_events etc
graph.stream(inputs, config, stream_mode="values")
本操作指南的剩余部分將展示一個完整的代理。
安裝配置
首先,我們需要安裝必要的軟件包并設置API密鑰
pip install --quiet -U langgraph langchain_openai
import getpass
import osdef _set_env(var: str):if not os.environ.get(var):os.environ[var] = getpass.getpass(f"{var}: ")_set_env("OPENAI_API_KEY")
_set_env("LANGSMITH_API_KEY")
為LangGraph開發配置LangSmith
注冊LangSmith可快速發現并優化LangGraph項目的性能問題。通過LangSmith,您能利用追蹤數據來調試、測試和監控基于LangGraph構建的LLM應用——了解更多入門指南請點擊此處。
定義圖結構
本示例將使用預構建的ReAct智能體。
API參考文檔: ChatOpenAI | create_react_agent | tool
from langchain_openai import ChatOpenAI
from typing import Literal
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool# First we initialize the model we want to use.
model = ChatOpenAI(model="gpt-4o", temperature=0)# For this tutorial we will use custom tool that returns pre-defined values for weather in two cities (NYC & SF)
@tool
def get_weather(city: Literal["nyc", "sf"]):"""Use this to get weather information."""if city == "nyc":return "It might be cloudy in nyc"elif city == "sf":return "It's always sunny in sf"else:raise AssertionError("Unknown city")tools = [get_weather]# Define the graph
graph = create_react_agent(model, tools=tools)
運行你的圖
現在我們已經定義好了圖結構,接下來運行一次并在LangSmith中查看追蹤記錄。為了讓追蹤記錄在LangSmith中易于訪問,我們將在配置中傳入一個自定義的run_id。
這要求您已設置好LANGSMITH_API_KEY環境變量。
請注意,您還可以通過設置LANGCHAIN_PROJECT環境變量來配置追蹤到哪個項目,默認情況下運行記錄會被追蹤到default項目。
import uuiddef print_stream(stream):for s in stream:message = s["messages"][-1]if isinstance(message, tuple):print(message)else:message.pretty_print()inputs = {"messages": [("user", "what is the weather in sf")]}config = {"run_name": "agent_007", "tags": ["cats are awesome"]}print_stream(graph.stream(inputs, config, stream_mode="values"))
================================ Human Message =================================what is the weather in sf
================================== Ai Message ==================================
Tool Calls:get_weather (call_9ZudXyMAdlUjptq9oMGtQo8o)Call ID: call_9ZudXyMAdlUjptq9oMGtQo8oArgs:city: sf
================================= Tool Message =================================
Name: get_weatherIt's always sunny in sf
================================== Ai Message ==================================The weather in San Francisco is currently sunny.
在LangSmith中查看追蹤記錄
既然我們已經運行了圖,現在讓我們前往LangSmith查看追蹤記錄。首先點擊您追蹤到的項目(在我們的案例中是默認項目)。您應該會看到一個名為"agent_007"的自定義運行名稱。
設置自定義認證
https://langchain-ai.github.io/langgraph/tutorials/auth/getting_started/
在本教程中,我們將構建一個僅允許特定用戶訪問的聊天機器人。我們將從LangGraph模板開始,逐步添加基于令牌的安全機制。最終,您將獲得一個在允許訪問前會檢查有效令牌的工作聊天機器人。
這是認證系列的第一部分:
1、設置自定義認證(當前所在部分)- 控制誰可以訪問您的機器人
2、實現私密對話 - 讓用戶進行私密對話
3、連接認證提供商 - 添加真實用戶賬戶并使用OAuth2進行生產環境驗證
本指南假設您已基本了解以下概念:
- 認證與訪問控制
- LangGraph平臺
注意:自定義認證僅適用于LangGraph平臺SaaS部署或企業自托管部署。
1、創建你的應用
使用LangGraph啟動模板創建一個新的聊天機器人:
pip install -U "langgraph-cli[inmem]"
langgraph new --template=new-langgraph-project-python custom-auth
cd custom-auth
模板為我們提供了一個占位符 LangGraph 應用。您可以通過安裝本地依賴項并運行開發服務器來試用它:
pip install -e .
langgraph dev
服務器將啟動并在瀏覽器中打開工作室:
- 🚀 API: http://127.0.0.1:2024
- 🎨 Studio UI: https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024
- 📚 API Docs: http://127.0.0.1:2024/docsThis in-memory server is designed for development and testing.
For production use, please use LangGraph Platform.
如果你將這項服務自托管在公共互聯網上,任何人都能訪問它!
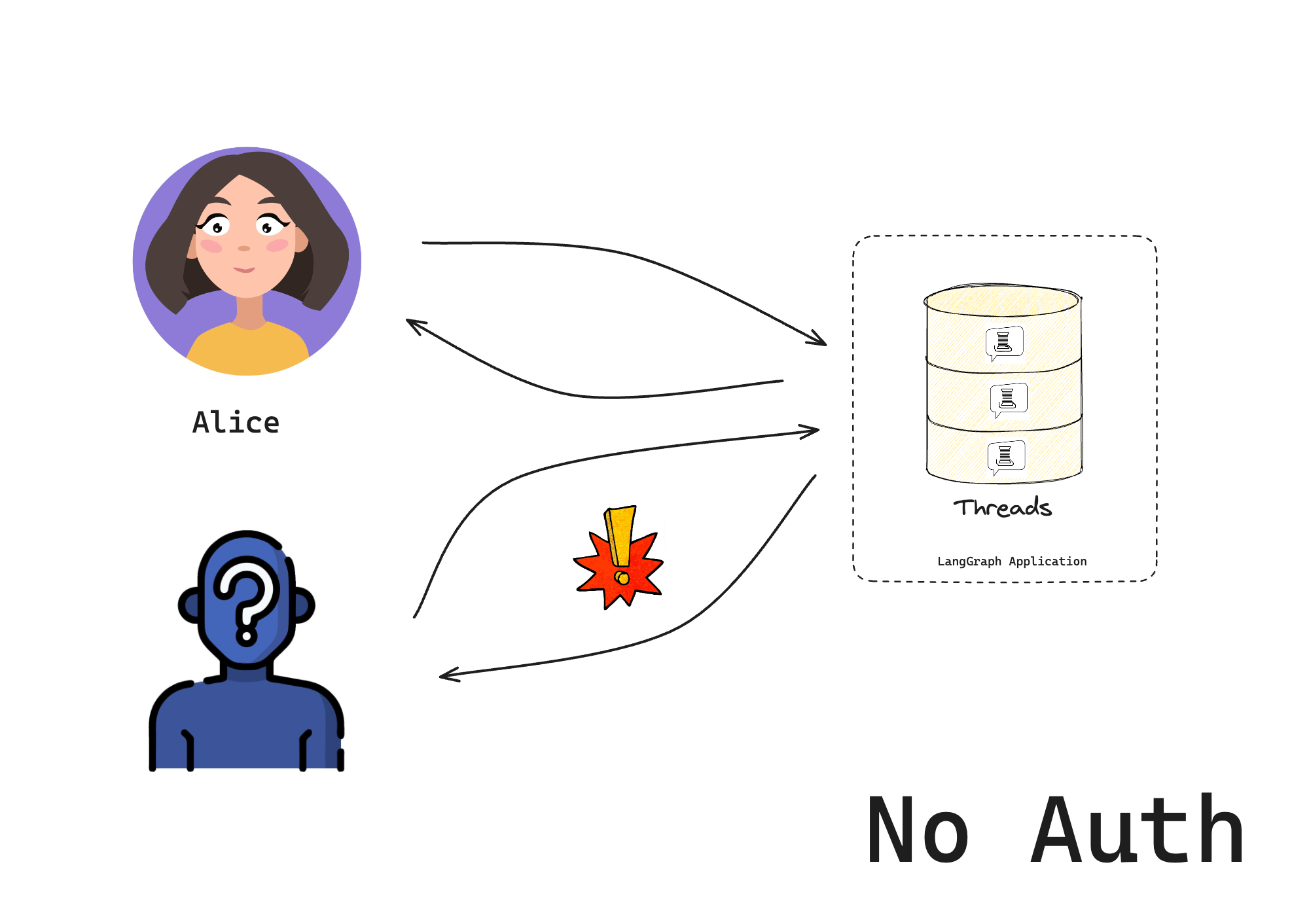
2、添加認證功能
現在你已經有了一個基礎的LangGraph應用,接下來需要為其添加認證功能。
注意:在本教程中,為了示例目的,我們將從一個硬編碼的令牌開始。在第三個教程中,你將學習如何實現"生產就緒"的認證方案。
Auth對象允許你注冊一個認證函數,LangGraph平臺會在每個請求上運行該函數。這個函數接收每個請求,并決定是否接受或拒絕。
創建一個新文件src/security/auth.py,這里將存放用于檢查用戶是否有權訪問你的機器人的代碼:
src/security/auth.py
from langgraph_sdk import Auth# This is our toy user database. Do not do this in production
VALID_TOKENS = {"user1-token": {"id": "user1", "name": "Alice"},"user2-token": {"id": "user2", "name": "Bob"},
}# The "Auth" object is a container that LangGraph will use to mark our authentication function
auth = Auth()# The `authenticate` decorator tells LangGraph to call this function as middleware
# for every request. This will determine whether the request is allowed or not
@auth.authenticate
async def get_current_user(authorization: str | None) -> Auth.types.MinimalUserDict:"""Check if the user's token is valid."""assert authorizationscheme, token = authorization.split()assert scheme.lower() == "bearer"# Check if token is validif token not in VALID_TOKENS:raise Auth.exceptions.HTTPException(status_code=401, detail="Invalid token")# Return user info if validuser_data = VALID_TOKENS[token]return {"identity": user_data["id"],}
請注意,您的身份驗證處理程序需要完成兩項重要工作:
1、檢查請求的Authorization頭是否包含有效令牌
2、返回用戶的身份信息
現在,通過將以下內容添加到langgraph.json配置文件來啟用LangGraph的身份驗證功能:
langgraph.json
{"dependencies": ["."],"graphs": {"agent": "./src/agent/graph.py:graph"},"env": ".env","auth": {"path": "src/security/auth.py:auth"}
}
3、測試你的機器人
重新啟動服務器以測試所有功能:
langgraph dev --no-browser
如果你沒有添加 --no-browser 參數,LangGraph Studio 的界面會在瀏覽器中自動打開。你可能會好奇:Studio 是如何連接到我們的服務器的?默認情況下,即使啟用了自定義認證,我們也允許來自 LangGraph Studio 的訪問。這樣能更方便地在 Studio 中開發和測試你的機器人。如需禁用這種備用認證方式,可以在認證配置中添加 disable_studio_auth: "true" 設置:
{"auth": {"path": "src/security/auth.py:auth","disable_studio_auth": "true"}
}
4、與你的機器人對話
現在,只有當你提供有效的請求頭令牌時才能訪問機器人。不過,在教程下一節添加資源授權處理器之前,用戶仍然可以訪問彼此的資源。
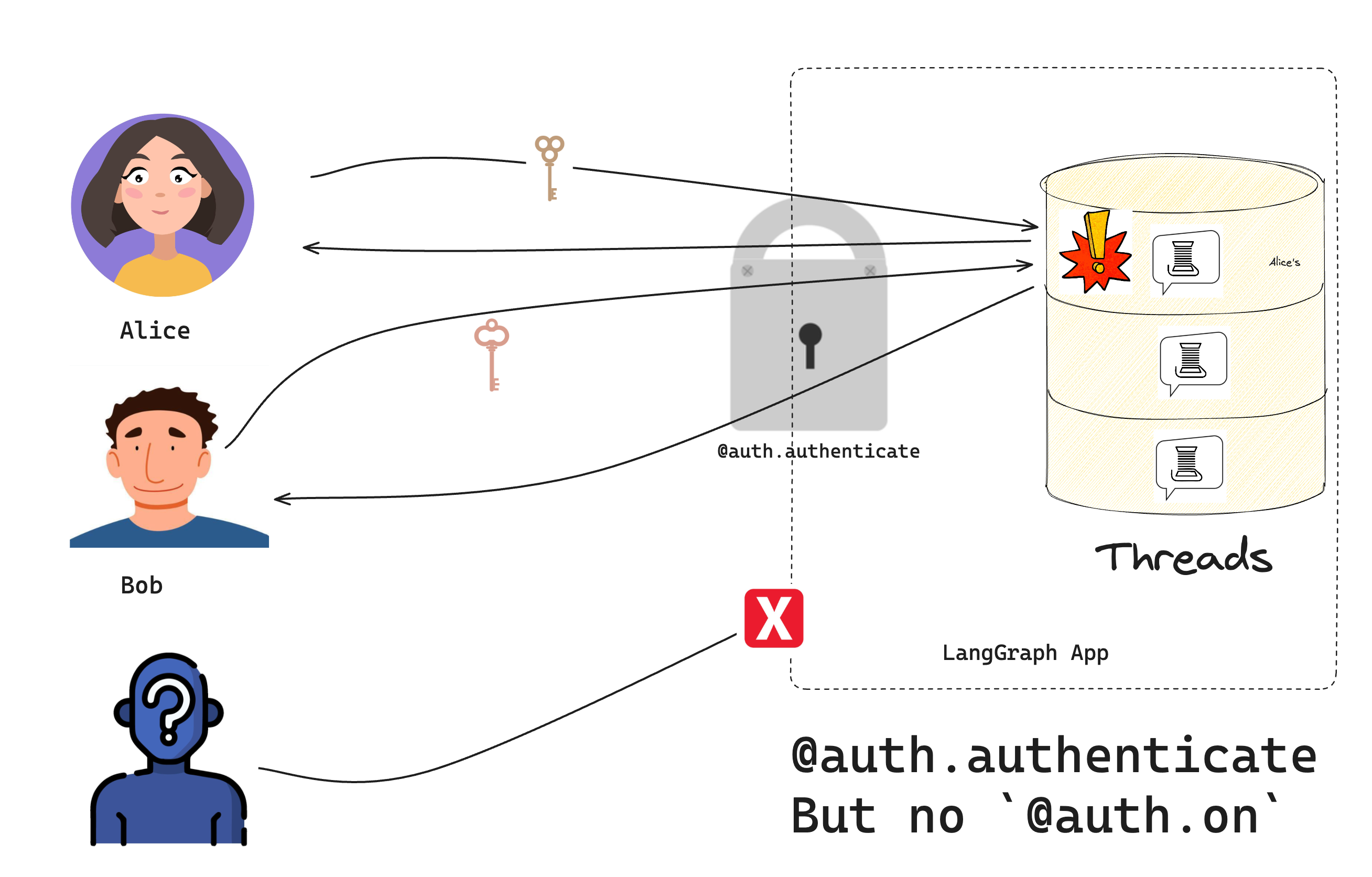
在文件或筆記本中運行以下代碼:
from langgraph_sdk import get_client# Try without a token (should fail)
client = get_client(url="http://localhost:2024")
try:thread = await client.threads.create()print("? Should have failed without token!")
except Exception as e:print("? Correctly blocked access:", e)# Try with a valid token
client = get_client(url="http://localhost:2024", headers={"Authorization": "Bearer user1-token"}
)# Create a thread and chat
thread = await client.threads.create()
print(f"? Created thread as Alice: {thread['thread_id']}")response = await client.runs.create(thread_id=thread["thread_id"],assistant_id="agent",input={"messages": [{"role": "user", "content": "Hello!"}]},
)
print("? Bot responded:")
print(response)
你會看到:
1、沒有有效令牌時,我們無法訪問機器人
2、擁有有效令牌時,我們可以創建會話并進行聊天
恭喜!你已經構建了一個僅允許"已認證"用戶訪問的聊天機器人。雖然這個系統(目前)還未實現生產環境級別的安全方案,但我們已經掌握了控制機器人訪問權限的基本機制。在下一個教程中,我們將學習如何為每個用戶提供專屬的私密對話空間。
后續步驟
現在您已掌握如何控制對機器人的訪問權限,接下來可以:
1、繼續教程,前往設置私密會話了解資源授權機制
2、深入閱讀身份驗證概念
3、查閱API參考文檔獲取更多認證細節
實現私密對話功能
https://langchain-ai.github.io/langgraph/tutorials/auth/resource_auth/
在本教程中,您將擴展上一個教程中創建的聊天機器人,為每位用戶提供獨立的私密對話空間。您需要添加資源級訪問控制機制,確保用戶只能查看自己的對話線程。
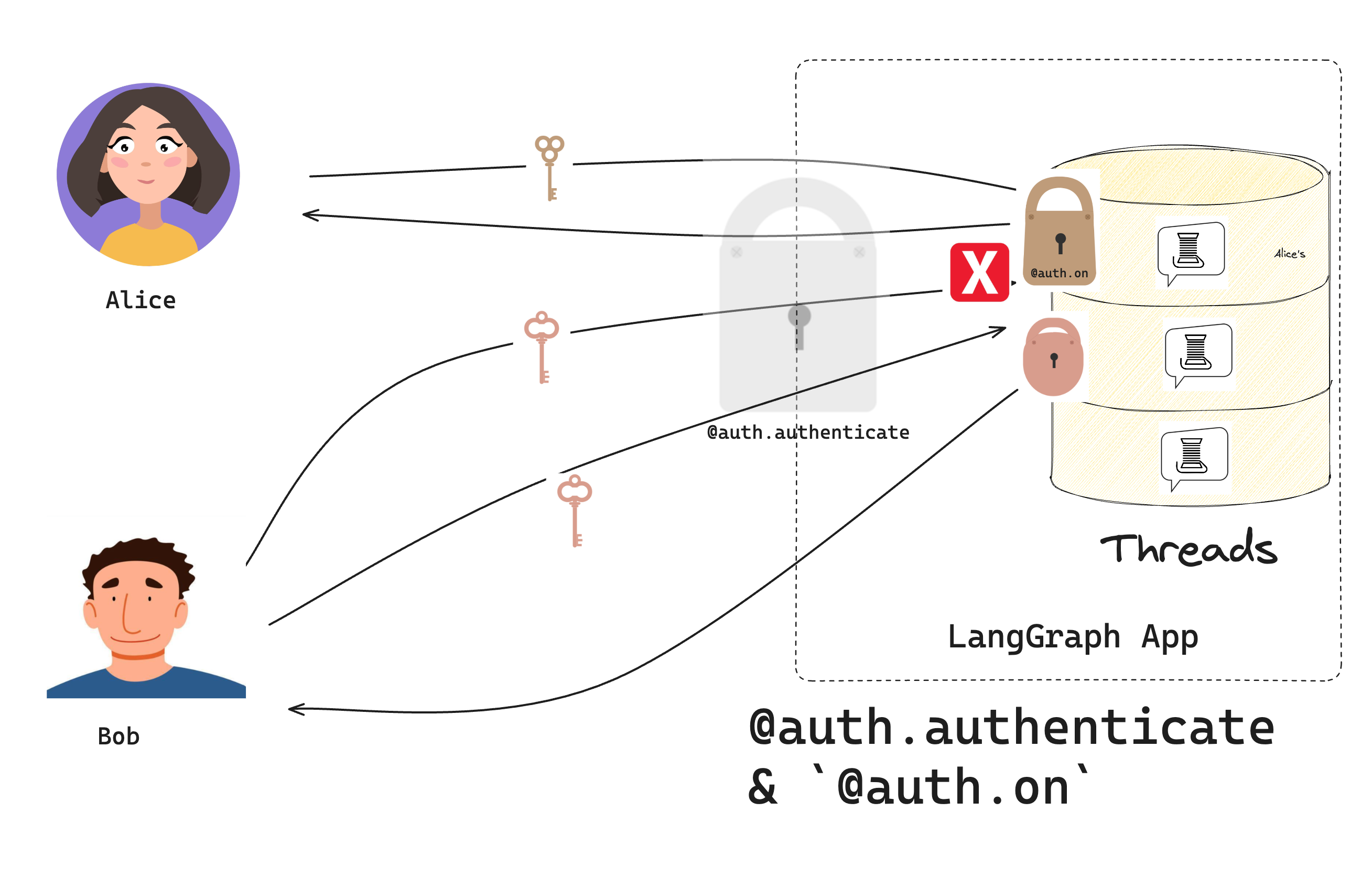
前提條件
在開始本教程前,請確保您已成功運行第一個教程中的機器人且無報錯。
1、添加資源授權
回顧上一教程,Auth 對象允許您注冊一個認證函數,LangGraph 平臺使用該函數來驗證傳入請求中的承載令牌。現在您將使用它來注冊一個授權處理器。
授權處理器是在認證成功后運行的函數。這些處理器可以為資源添加元數據(例如資源所有者信息),并過濾每個用戶可見的內容。
更新您的 src/security/auth.py 文件,添加一個在每次請求時運行的授權處理器:
src/security/auth.py
from langgraph_sdk import Auth# Keep our test users from the previous tutorial
VALID_TOKENS = {"user1-token": {"id": "user1", "name": "Alice"},"user2-token": {"id": "user2", "name": "Bob"},
}auth = Auth()@auth.authenticate
async def get_current_user(authorization: str | None) -> Auth.types.MinimalUserDict:"""Our authentication handler from the previous tutorial."""assert authorizationscheme, token = authorization.split()assert scheme.lower() == "bearer"if token not in VALID_TOKENS:raise Auth.exceptions.HTTPException(status_code=401, detail="Invalid token")user_data = VALID_TOKENS[token]return {"identity": user_data["id"],}@auth.on
async def add_owner(ctx: Auth.types.AuthContext, # Contains info about the current uservalue: dict, # The resource being created/accessed
):"""Make resources private to their creator."""# Examples:# ctx: AuthContext(# permissions=[],# user=ProxyUser(# identity='user1',# is_authenticated=True,# display_name='user1'# ),# resource='threads',# action='create_run'# )# value: # {# 'thread_id': UUID('1e1b2733-303f-4dcd-9620-02d370287d72'),# 'assistant_id': UUID('fe096781-5601-53d2-b2f6-0d3403f7e9ca'),# 'run_id': UUID('1efbe268-1627-66d4-aa8d-b956b0f02a41'),# 'status': 'pending',# 'metadata': {},# 'prevent_insert_if_inflight': True,# 'multitask_strategy': 'reject',# 'if_not_exists': 'reject',# 'after_seconds': 0,# 'kwargs': {# 'input': {'messages': [{'role': 'user', 'content': 'Hello!'}]},# 'command': None,# 'config': {# 'configurable': {# 'langgraph_auth_user': ... Your user object...# 'langgraph_auth_user_id': 'user1'# }# },# 'stream_mode': ['values'],# 'interrupt_before': None,# 'interrupt_after': None,# 'webhook': None,# 'feedback_keys': None,# 'temporary': False,# 'subgraphs': False# }# }# Does 2 things:# 1、Add the user's ID to the resource's metadata. Each LangGraph resource has a `metadata` dict that persists with the resource.# this metadata is useful for filtering in read and update operations# 2、Return a filter that lets users only see their own resourcesfilters = {"owner": ctx.user.identity}metadata = value.setdefault("metadata", {})metadata.update(filters)# Only let users see their own resourcesreturn filters
處理函數接收兩個參數:
1、ctx (AuthContext):包含當前用戶信息、用戶權限、操作的資源(“threads”、“crons”、“assistants”)以及正在執行的操作(“create”、“read”、“update”、“delete”、“search”、“create_run”)
2、value (dict):正在創建或訪問的數據。該字典的內容取決于所訪問的資源和操作。有關如何獲取更精細范圍訪問控制的信息,請參閱下方的添加范圍授權處理函數。
注意,這個簡單處理函數做了兩件事:
1、將用戶ID添加到資源的元數據中。
2、返回一個元數據過濾器,確保用戶只能看到自己擁有的資源。
2、測試私有對話
測試您的授權配置。如果設置正確,您將看到所有?標記的消息。請確保開發服務器正在運行(執行langgraph dev命令):
from langgraph_sdk import get_client# Create clients for both users
alice = get_client(url="http://localhost:2024",headers={"Authorization": "Bearer user1-token"}
)bob = get_client(url="http://localhost:2024",headers={"Authorization": "Bearer user2-token"}
)# Alice creates an assistant
alice_assistant = await alice.assistants.create()
print(f"? Alice created assistant: {alice_assistant['assistant_id']}")# Alice creates a thread and chats
alice_thread = await alice.threads.create()
print(f"? Alice created thread: {alice_thread['thread_id']}")await alice.runs.create(thread_id=alice_thread["thread_id"],assistant_id="agent",input={"messages": [{"role": "user", "content": "Hi, this is Alice's private chat"}]}
)# Bob tries to access Alice's thread
try:await bob.threads.get(alice_thread["thread_id"])print("? Bob shouldn't see Alice's thread!")
except Exception as e:print("? Bob correctly denied access:", e)# Bob creates his own thread
bob_thread = await bob.threads.create()
await bob.runs.create(thread_id=bob_thread["thread_id"],assistant_id="agent",input={"messages": [{"role": "user", "content": "Hi, this is Bob's private chat"}]}
)
print(f"? Bob created his own thread: {bob_thread['thread_id']}")# List threads - each user only sees their own
alice_threads = await alice.threads.search()
bob_threads = await bob.threads.search()
print(f"? Alice sees {len(alice_threads)} thread")
print(f"? Bob sees {len(bob_threads)} thread")
Output:
? Alice created assistant: fc50fb08-78da-45a9-93cc-1d3928a3fc37
? Alice created thread: 533179b7-05bc-4d48-b47a-a83cbdb5781d
? Bob correctly denied access: Client error '404 Not Found' for url 'http://localhost:2024/threads/533179b7-05bc-4d48-b47a-a83cbdb5781d'
For more information check: https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/404
? Bob created his own thread: 437c36ed-dd45-4a1e-b484-28ba6eca8819
? Alice sees 1 thread
? Bob sees 1 thread
這意味著:
1、每位用戶都可以創建自己的會話線程并在其中聊天
2、用戶無法查看他人的會話線程
3、線程列表僅顯示用戶自己的線程
3、添加作用域授權處理器
寬泛的@auth.on處理器會匹配所有授權事件。這種方式雖然簡潔,但意味著value字典的內容沒有明確的作用域范圍,且相同的用戶級訪問控制會應用于每個資源。如果需要更精細的控制,您還可以針對資源的特定操作進行管理。
更新src/security/auth.py文件,為特定資源類型添加處理器:
# Keep our previous handlers...from langgraph_sdk import Auth@auth.on.threads.create
async def on_thread_create(ctx: Auth.types.AuthContext,value: Auth.types.on.threads.create.value,
):"""Add owner when creating threads.This handler runs when creating new threads and does two things:1、Sets metadata on the thread being created to track ownership2、Returns a filter that ensures only the creator can access it"""# Example value:# {'thread_id': UUID('99b045bc-b90b-41a8-b882-dabc541cf740'), 'metadata': {}, 'if_exists': 'raise'}# Add owner metadata to the thread being created# This metadata is stored with the thread and persistsmetadata = value.setdefault("metadata", {})metadata["owner"] = ctx.user.identity# Return filter to restrict access to just the creatorreturn {"owner": ctx.user.identity}@auth.on.threads.read
async def on_thread_read(ctx: Auth.types.AuthContext,value: Auth.types.on.threads.read.value,
):"""Only let users read their own threads.This handler runs on read operations. We don't need to setmetadata since the thread already exists - we just need toreturn a filter to ensure users can only see their own threads."""return {"owner": ctx.user.identity}@auth.on.assistants
async def on_assistants(ctx: Auth.types.AuthContext,value: Auth.types.on.assistants.value,
):# For illustration purposes, we will deny all requests# that touch the assistants resource# Example value:# {# 'assistant_id': UUID('63ba56c3-b074-4212-96e2-cc333bbc4eb4'),# 'graph_id': 'agent',# 'config': {},# 'metadata': {},# 'name': 'Untitled'# }raise Auth.exceptions.HTTPException(status_code=403,detail="User lacks the required permissions.",)# Assumes you organize information in store like (user_id, resource_type, resource_id)
@auth.on.store()
async def authorize_store(ctx: Auth.types.AuthContext, value: dict):# The "namespace" field for each store item is a tuple you can think of as the directory of an item.namespace: tuple = value["namespace"]assert namespace[0] == ctx.user.identity, "Not authorized"
注意,現在不再使用單一的全局處理器,而是針對以下操作提供了特定的處理器:
1、創建線程
2、讀取線程
3、訪問助手
前三個處理器分別對應每個資源上的特定操作(參見資源操作),而最后一個處理器(@auth.on.assistants)則匹配assistants資源上的任意操作。對于每個請求,LangGraph 都會運行與所訪問資源及操作最匹配的特定處理器。這意味著上述四個處理器會優先運行,而非作用域寬泛的"@auth.on"全局處理器。
嘗試將以下測試代碼添加到您的測試文件中:
# ... Same as before
# Try creating an assistant. This should fail
try:await alice.assistants.create("agent")print("? Alice shouldn't be able to create assistants!")
except Exception as e:print("? Alice correctly denied access:", e)# Try searching for assistants. This also should fail
try:await alice.assistants.search()print("? Alice shouldn't be able to search assistants!")
except Exception as e:print("? Alice correctly denied access to searching assistants:", e)# Alice can still create threads
alice_thread = await alice.threads.create()
print(f"? Alice created thread: {alice_thread['thread_id']}")
Output:
? Alice created thread: dcea5cd8-eb70-4a01-a4b6-643b14e8f754
? Bob correctly denied access: Client error '404 Not Found' for url 'http://localhost:2024/threads/dcea5cd8-eb70-4a01-a4b6-643b14e8f754'
For more information check: https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/404
? Bob created his own thread: 400f8d41-e946-429f-8f93-4fe395bc3eed
? Alice sees 1 thread
? Bob sees 1 thread
? Alice correctly denied access:
For more information check: https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/500
? Alice correctly denied access to searching assistants:
恭喜!您已經構建了一個讓每位用戶都能擁有私人對話的聊天機器人。雖然當前系統采用基于令牌的簡單認證方式,但這些授權模式同樣適用于實現任何實際的認證系統。在下一個教程中,您將通過OAuth2將測試用戶替換為真實的用戶賬戶。
下一步行動
現在您已經掌握了資源訪問控制,接下來可以:
1、繼續學習連接認證提供商來添加真實用戶賬戶
2、深入了解授權模式
3、查閱API參考文檔獲取本教程中使用的接口和方法詳情
連接認證提供商
https://langchain-ai.github.io/langgraph/tutorials/auth/add_auth_server/
在上一個教程中,您添加了資源授權功能來實現用戶私密對話。但目前仍在使用硬編碼令牌進行認證,這種方式并不安全。現在您將通過OAuth2使用真實用戶賬戶來替換這些令牌。
您將繼續使用相同的Auth對象和資源級訪問控制,但會將認證升級為使用Supabase作為身份提供商。雖然本教程使用Supabase,但這些概念適用于任何OAuth2提供商。您將學習如何:
1、用真實的JWT令牌替換測試令牌
2、集成OAuth2提供商實現安全的用戶認證
3、在保持現有授權邏輯的同時處理用戶會話和元數據
背景
OAuth2 主要涉及三個角色:
1、授權服務器:身份提供商(如 Supabase、Auth0、Google),負責用戶認證并頒發令牌
2、應用后端:您的 LangGraph 應用。這部分負責驗證令牌并提供受保護資源(對話數據)
3、客戶端應用:用戶與之交互的網頁或移動應用
標準的 OAuth2 流程大致如下:
sequenceDiagramparticipant Userparticipant Clientparticipant AuthServerparticipant LangGraph BackendUser->>Client: Initiate loginUser->>AuthServer: Enter credentialsAuthServer->>Client: Send tokensClient->>LangGraph Backend: Request with tokenLangGraph Backend->>AuthServer: Validate tokenAuthServer->>LangGraph Backend: Token validLangGraph Backend->>Client: Serve request (e.g., run agent or graph)
前提條件
在開始本教程前,請確保您已滿足以下要求:
- 已正常運行第二個教程中的機器人且無報錯
- 擁有一個Supabase項目以使用其認證服務
1、安裝依賴
安裝所需的依賴項。首先進入你的 custom-auth 目錄,并確保已安裝 langgraph-cli:
cd custom-auth
pip install -U "langgraph-cli[inmem]"
2、設置認證提供程序
接下來,獲取您的認證服務器URL和用于身份驗證的私鑰。
由于您使用的是Supabase,可以在Supabase儀表板中完成此操作:
1、在左側邊欄中,點擊"? 項目設置",然后點擊"API"
2、復制您的項目URL并將其添加到.env文件中
echo "SUPABASE_URL=your-project-url" >> .env
1、復制您的服務角色密鑰并將其添加到您的 .env 文件中:
echo "SUPABASE_SERVICE_KEY=your-service-role-key" >> .env
1、復制你的"anon public"密鑰并記錄下來。稍后在設置客戶端代碼時會用到它。
SUPABASE_URL=your-project-url
SUPABASE_SERVICE_KEY=your-service-role-key
3、實現令牌驗證
在前面的教程中,您使用了 Auth 對象來驗證硬編碼令牌和添加資源所有權。
現在您需要升級認證邏輯,改為驗證來自 Supabase 的真實 JWT 令牌。主要修改集中在 @auth.authenticate 裝飾函數中:
- 不再檢查硬編碼的令牌列表,而是向 Supabase 發起 HTTP 請求來驗證令牌
- 從已驗證的令牌中提取真實的用戶信息(ID、郵箱)
- 現有的資源授權邏輯保持不變
更新 src/security/auth.py 文件實現這些功能:
src/security/auth.py
import os
import httpx
from langgraph_sdk import Authauth = Auth()# This is loaded from the `.env` file you created above
SUPABASE_URL = os.environ["SUPABASE_URL"]
SUPABASE_SERVICE_KEY = os.environ["SUPABASE_SERVICE_KEY"]@auth.authenticate
async def get_current_user(authorization: str | None):"""Validate JWT tokens and extract user information."""assert authorizationscheme, token = authorization.split()assert scheme.lower() == "bearer"try:# Verify token with auth providerasync with httpx.AsyncClient() as client:response = await client.get(f"{SUPABASE_URL}/auth/v1/user",headers={"Authorization": authorization,"apiKey": SUPABASE_SERVICE_KEY,},)assert response.status_code == 200user = response.json()return {"identity": user["id"], # Unique user identifier"email": user["email"],"is_authenticated": True,}except Exception as e:raise Auth.exceptions.HTTPException(status_code=401, detail=str(e))# ... the rest is the same as before# Keep our resource authorization from the previous tutorial
@auth.on
async def add_owner(ctx, value):"""Make resources private to their creator using resource metadata."""filters = {"owner": ctx.user.identity}metadata = value.setdefault("metadata", {})metadata.update(filters)return filters
最重要的變化是我們現在使用真實的認證服務器來驗證令牌。我們的認證處理器擁有 Supabase 項目的私鑰,可用于驗證用戶令牌并提取其信息。
4、測試認證流程
讓我們來測試新的認證流程。你可以在文件或筆記本中運行以下代碼。需要提供:
- 一個有效的電子郵箱地址
- Supabase 項目 URL(來自上文)
- Supabase 匿名公鑰(同樣來自上文)
import os
import httpx
from getpass import getpass
from langgraph_sdk import get_client# Get email from command line
email = getpass("Enter your email: ")
base_email = email.split("@")
password = "secure-password" # CHANGEME
email1 = f"{base_email[0]}+1@{base_email[1]}"
email2 = f"{base_email[0]}+2@{base_email[1]}"SUPABASE_URL = os.environ.get("SUPABASE_URL")
if not SUPABASE_URL:SUPABASE_URL = getpass("Enter your Supabase project URL: ")# This is your PUBLIC anon key (which is safe to use client-side)
# Do NOT mistake this for the secret service role key
SUPABASE_ANON_KEY = os.environ.get("SUPABASE_ANON_KEY")
if not SUPABASE_ANON_KEY:SUPABASE_ANON_KEY = getpass("Enter your public Supabase anon key: ")async def sign_up(email: str, password: str):"""Create a new user account."""async with httpx.AsyncClient() as client:response = await client.post(f"{SUPABASE_URL}/auth/v1/signup",json={"email": email, "password": password},headers={"apiKey": SUPABASE_ANON_KEY},)assert response.status_code == 200return response.json()# Create two test users
print(f"Creating test users: {email1} and {email2}")
await sign_up(email1, password)
await sign_up(email2, password)
?? 繼續之前:請檢查您的郵箱并點擊兩個確認鏈接。在用戶確認郵箱之前,Supabase 會拒絕所有 /login 請求。
現在測試用戶只能查看自己的數據。請確保服務器正在運行(執行 langgraph dev 命令)后再繼續操作。以下代碼片段需要用到您之前在設置認證提供方時從 Supabase 儀表板復制的 “anon public” 密鑰。
async def login(email: str, password: str):"""Get an access token for an existing user."""async with httpx.AsyncClient() as client:response = await client.post(f"{SUPABASE_URL}/auth/v1/token?grant_type=password",json={"email": email,"password": password},headers={"apikey": SUPABASE_ANON_KEY,"Content-Type": "application/json"},)assert response.status_code == 200return response.json()["access_token"]# Log in as user 1
user1_token = await login(email1, password)
user1_client = get_client(url="http://localhost:2024", headers={"Authorization": f"Bearer {user1_token}"}
)# Create a thread as user 1
thread = await user1_client.threads.create()
print(f"? User 1 created thread: {thread['thread_id']}")# Try to access without a token
unauthenticated_client = get_client(url="http://localhost:2024")
try:await unauthenticated_client.threads.create()print("? Unauthenticated access should fail!")
except Exception as e:print("? Unauthenticated access blocked:", e)# Try to access user 1's thread as user 2
user2_token = await login(email2, password)
user2_client = get_client(url="http://localhost:2024", headers={"Authorization": f"Bearer {user2_token}"}
)try:await user2_client.threads.get(thread["thread_id"])print("? User 2 shouldn't see User 1's thread!")
except Exception as e:print("? User 2 blocked from User 1's thread:", e)
輸出結果應如下所示:
? User 1 created thread: d6af3754-95df-4176-aa10-dbd8dca40f1a
? Unauthenticated access blocked: Client error '403 Forbidden' for url 'http://localhost:2024/threads'
? User 2 blocked from User 1's thread: Client error '404 Not Found' for url 'http://localhost:2024/threads/d6af3754-95df-4176-aa10-dbd8dca40f1a'
您的身份驗證與授權機制協同工作:
1、用戶必須登錄才能訪問機器人
2、每個用戶只能查看自己的會話線程
所有用戶均由Supabase認證提供商管理,因此您無需實現額外的用戶管理邏輯。
后續步驟
您已成功為LangGraph應用構建了一個生產就緒的認證系統!讓我們回顧一下您已完成的工作:
1、設置認證服務提供商(本示例使用Supabase)
2、添加了支持郵箱/密碼驗證的真實用戶賬戶
3、將JWT令牌驗證集成到LangGraph服務端
4、實現完善的授權機制,確保用戶只能訪問自己的數據
5、建立了可應對未來認證需求的基礎架構 🚀
現在您已擁有生產級認證系統,建議考慮:
1、使用您喜歡的框架構建Web界面(可參考自定義認證模板示例)
2、通過認證概念指南深入了解認證與授權的其他方面
3、閱讀參考文檔后進一步自定義處理程序和配置
運行時重建圖
https://langchain-ai.github.io/langgraph/cloud/deployment/graph_rebuild/
您可能需要為新運行使用不同配置重新構建圖。例如,根據配置的不同,您可能需要使用不同的圖狀態或圖結構。本指南將展示如何實現這一點。
注意:在大多數情況下,基于配置自定義行為應通過單一圖處理,其中每個節點可以讀取配置并據此改變其行為
先決條件
在開始之前,請確保先查閱此操作指南了解如何為部署設置您的應用程序。
定義圖結構
假設你有一個應用程序,其中包含一個簡單的圖結構,該結構會調用大語言模型(LLM)并將響應返回給用戶。應用程序的文件目錄結構如下:
my-app/
|-- requirements.txt
|-- .env
|-- openai_agent.py # code for your graph
其中圖定義在 openai_agent.py 文件中。
無需重新構建
在標準LangGraph API配置中,服務器使用的是定義在openai_agent.py頂層的已編譯圖實例,其結構如下所示:
API參考文檔:ChatOpenAI | END | START
from langchain_openai import ChatOpenAI
from langgraph.graph import END, START, MessageGraphmodel = ChatOpenAI(temperature=0)graph_workflow = MessageGraph()graph_workflow.add_node("agent", model)
graph_workflow.add_edge("agent", END)
graph_workflow.add_edge(START, "agent")agent = graph_workflow.compile()
為了讓服務器識別您的圖,您需要在LangGraph API配置(langgraph.json)中指定包含CompiledStateGraph實例的變量路徑,例如:
{"dependencies": ["."],"graphs": {"openai_agent": "./openai_agent.py:agent",},"env": "./.env"
}
重建
為了讓你的圖表在每次使用自定義配置重新運行時都能重建,你需要重寫 openai_agent.py,改為提供一個函數,該函數接收配置并返回一個圖表(或已編譯的圖表)實例。假設我們希望為用戶 ID 為 ‘1’ 的情況返回現有的圖表,而為其他用戶返回一個工具調用代理。我們可以按如下方式修改 openai_agent.py:
API 參考:ChatOpenAI | END | START | StateGraph | add_messages | ToolNode | tool | BaseMessage | RunnableConfig
from typing import Annotated
from typing_extensions import TypedDict
from langchain_openai import ChatOpenAI
from langgraph.graph import END, START, MessageGraph
from langgraph.graph.state import StateGraph
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode
from langchain_core.tools import tool
from langchain_core.messages import BaseMessage
from langchain_core.runnables import RunnableConfigclass State(TypedDict):messages: Annotated[list[BaseMessage], add_messages]model = ChatOpenAI(temperature=0)def make_default_graph():"""Make a simple LLM agent"""graph_workflow = StateGraph(State)def call_model(state):return {"messages": [model.invoke(state["messages"])]}graph_workflow.add_node("agent", call_model)graph_workflow.add_edge("agent", END)graph_workflow.add_edge(START, "agent")agent = graph_workflow.compile()return agentdef make_alternative_graph():"""Make a tool-calling agent"""@tooldef add(a: float, b: float):"""Adds two numbers."""return a + btool_node = ToolNode([add])model_with_tools = model.bind_tools([add])def call_model(state):return {"messages": [model_with_tools.invoke(state["messages"])]}def should_continue(state: State):if state["messages"][-1].tool_calls:return "tools"else:return ENDgraph_workflow = StateGraph(State)graph_workflow.add_node("agent", call_model)graph_workflow.add_node("tools", tool_node)graph_workflow.add_edge("tools", "agent")graph_workflow.add_edge(START, "agent")graph_workflow.add_conditional_edges("agent", should_continue)agent = graph_workflow.compile()return agent# this is the graph making function that will decide which graph to
# build based on the provided config
def make_graph(config: RunnableConfig):user_id = config.get("configurable", {}).get("user_id")# route to different graph state / structure based on the user IDif user_id == "1":return make_default_graph()else:return make_alternative_graph()
最后,你需要在langgraph.json中指定圖表生成函數(make_graph)的路徑:
{"dependencies": ["."],"graphs": {"openai_agent": "./openai_agent.py:make_graph",},"env": "./.env"
}
更多關于LangGraph API配置文件的詳細信息,請參閱此處。
如何使用RemoteGraph與部署進行交互
https://langchain-ai.github.io/langgraph/how-tos/use-remote-graph/
前提條件
- LangGraph平臺
- LangGraph服務端
RemoteGraph是一個接口,它允許您像操作常規本地定義的LangGraph圖(例如CompiledGraph)一樣與LangGraph平臺部署進行交互。本指南將向您展示如何初始化RemoteGraph并與之交互。
初始化圖
初始化 RemoteGraph 時,必須始終指定以下參數:
name:要交互的圖名稱。該名稱與部署時langgraph.json配置文件中的圖名稱一致。api_key:有效的 LangSmith API 密鑰。可通過環境變量 (LANGSMITH_API_KEY) 設置,或直接通過api_key參數傳入。如果LangGraphClient/SyncLangGraphClient初始化時已傳入api_key參數,也可通過client/sync_client參數提供該密鑰。
此外,還需提供以下任一參數:
url:要交互的部署 URL。傳入url參數后,同步和異步客戶端將基于該 URL、請求頭(如提供)及默認配置值(如超時等)創建。client:用于異步交互的LangGraphClient實例(例如使用.astream()、.ainvoke()、.aget_state()、.aupdate_state()等方法)。sync_client:用于同步交互的SyncLangGraphClient實例(例如使用.stream()、.invoke()、.get_state()、.update_state()等方法)。
注意:若同時傳入 client/sync_client 和 url 參數,前者將覆蓋后者。若未提供 client/sync_client/url 任一參數,運行時 RemoteGraph 將拋出 ValueError 異常。
使用 URL
Python
from langgraph.pregel.remote import RemoteGraphurl = <DEPLOYMENT_URL>
graph_name = "agent"
remote_graph = RemoteGraph(graph_name, url=url)
Javascript
import { RemoteGraph } from "@langchain/langgraph/remote";const url = `<DEPLOYMENT_URL>`;
const graphName = "agent";
const remoteGraph = new RemoteGraph({ graphId: graphName, url });
使用客戶端
Python
from langgraph_sdk import get_client, get_sync_client
from langgraph.pregel.remote import RemoteGraphurl = <DEPLOYMENT_URL>
graph_name = "agent"
client = get_client(url=url)
sync_client = get_sync_client(url=url)
remote_graph = RemoteGraph(graph_name, client=client, sync_client=sync_client)
Javascript
import { Client } from "@langchain/langgraph-sdk";
import { RemoteGraph } from "@langchain/langgraph/remote";const client = new Client({ apiUrl: `<DEPLOYMENT_URL>` });
const graphName = "agent";
const remoteGraph = new RemoteGraph({ graphId: graphName, client });
調用圖結構
由于 RemoteGraph 是一個實現了與 CompiledGraph 相同方法的 Runnable,因此您可以像平常操作已編譯圖結構那樣與之交互,即通過調用 .invoke()、.stream()、.get_state()、.update_state() 等方法(以及它們的異步版本)。
異步使用
注意:要異步使用圖表,在初始化 RemoteGraph 時必須提供 url 或 client 參數。
Python
# invoke the graph
result = await remote_graph.ainvoke({"messages": [{"role": "user", "content": "what's the weather in sf"}]
})# stream outputs from the graph
async for chunk in remote_graph.astream({"messages": [{"role": "user", "content": "what's the weather in la"}]
}):print(chunk)
Javascript
// invoke the graph
const result = await remoteGraph.invoke({messages: [{role: "user", content: "what's the weather in sf"}]
})// stream outputs from the graph
for await (const chunk of await remoteGraph.stream({messages: [{role: "user", content: "what's the weather in la"}]
})):console.log(chunk)
同步模式
注意:要同步使用圖數據庫,在初始化 RemoteGraph 時必須提供 url 或 sync_client 參數。
Python
# invoke the graph
result = remote_graph.invoke({"messages": [{"role": "user", "content": "what's the weather in sf"}]
})# stream outputs from the graph
for chunk in remote_graph.stream({"messages": [{"role": "user", "content": "what's the weather in la"}]
}):print(chunk)
線程級持久化
默認情況下,圖的運行(即調用.invoke()或.stream())是無狀態的——圖的檢查點和最終狀態不會被持久化。如果您希望持久化圖運行的輸出(例如,為了實現人在回路功能),可以創建一個線程并通過config參數提供線程ID,這與常規編譯圖的操作方式相同:
Python
from langgraph_sdk import get_sync_client
url = <DEPLOYMENT_URL>
graph_name = "agent"
sync_client = get_sync_client(url=url)
remote_graph = RemoteGraph(graph_name, url=url)# create a thread (or use an existing thread instead)
thread = sync_client.threads.create()# invoke the graph with the thread config
config = {"configurable": {"thread_id": thread["thread_id"]}}
result = remote_graph.invoke({"messages": [{"role": "user", "content": "what's the weather in sf"}]
}, config=config)# verify that the state was persisted to the thread
thread_state = remote_graph.get_state(config)
print(thread_state)
Javascript
import { Client } from "@langchain/langgraph-sdk";
import { RemoteGraph } from "@langchain/langgraph/remote";const url = `<DEPLOYMENT_URL>`;
const graphName = "agent";
const client = new Client({ apiUrl: url });
const remoteGraph = new RemoteGraph({ graphId: graphName, url });// create a thread (or use an existing thread instead)
const thread = await client.threads.create();// invoke the graph with the thread config
const config = { configurable: { thread_id: thread.thread_id }};
const result = await remoteGraph.invoke({messages: [{ role: "user", content: "what's the weather in sf" }],
}, config);// verify that the state was persisted to the thread
const threadState = await remoteGraph.getState(config);
console.log(threadState);
作為子圖使用
注意:如果需要在包含 RemoteGraph 子圖節點的圖中使用 checkpointer,請確保使用 UUID 作為線程 ID。
由于 RemoteGraph 的行為與常規 CompiledGraph 相同,因此也可以將其作為子圖嵌入到另一個圖中。例如:
Python
from langgraph_sdk import get_sync_client
from langgraph.graph import StateGraph, MessagesState, START
from typing import TypedDicturl = <DEPLOYMENT_URL>
graph_name = "agent"
remote_graph = RemoteGraph(graph_name, url=url)# define parent graph
builder = StateGraph(MessagesState)
# add remote graph directly as a node
builder.add_node("child", remote_graph)
builder.add_edge(START, "child")
graph = builder.compile()# invoke the parent graph
result = graph.invoke({"messages": [{"role": "user", "content": "what's the weather in sf"}]
})
print(result)# stream outputs from both the parent graph and subgraph
for chunk in graph.stream({"messages": [{"role": "user", "content": "what's the weather in sf"}]
}, subgraphs=True):print(chunk)
Javascript
import { MessagesAnnotation, StateGraph, START } from "@langchain/langgraph";
import { RemoteGraph } from "@langchain/langgraph/remote";const url = `<DEPLOYMENT_URL>`;
const graphName = "agent";
const remoteGraph = new RemoteGraph({ graphId: graphName, url });// define parent graph and add remote graph directly as a node
const graph = new StateGraph(MessagesAnnotation).addNode("child", remoteGraph).addEdge(START, "child").compile()// invoke the parent graph
const result = await graph.invoke({messages: [{ role: "user", content: "what's the weather in sf" }]
});
console.log(result);// stream outputs from both the parent graph and subgraph
for await (const chunk of await graph.stream({messages: [{ role: "user", content: "what's the weather in la" }]
}, { subgraphs: true })) {console.log(chunk);
}
如何使用LangGraph平臺部署CrewAI、AutoGen等框架
https://langchain-ai.github.io/langgraph/how-tos/autogen-langgraph-platform/
LangGraph平臺為智能體部署提供了基礎設施。該平臺與LangGraph無縫集成,同時也兼容其他框架。實現方式是將智能體封裝為單個LangGraph節點,使其成為整個圖結構。
這種部署方式能帶來諸多優勢,包括:水平可擴展的基礎設施、處理突發操作的任務隊列、支持短期記憶的持久層,以及長期記憶功能。
本指南將演示如何部署AutoGen智能體,但該方法同樣適用于CrewAI、LlamaIndex等其他框架定義的智能體。
安裝
%pip install autogen langgraph
import getpass
import osdef _set_env(var: str):if not os.environ.get(var):os.environ[var] = getpass.getpass(f"{var}: ")_set_env("OPENAI_API_KEY")
定義自動生成代理
在這里,我們定義自己的AutoGen代理。參考自https://github.com/microsoft/autogen/blob/0.2/notebook/agentchat_web_info.ipynb
import autogen
import osconfig_list = [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}]llm_config = {"timeout": 600,"cache_seed": 42,"config_list": config_list,"temperature": 0,
}autogen_agent = autogen.AssistantAgent(name="assistant",llm_config=llm_config,
)user_proxy = autogen.UserProxyAgent(name="user_proxy",human_input_mode="NEVER",max_consecutive_auto_reply=10,is_termination_msg=lambda x: x.get("content", "").rstrip().endswith("TERMINATE"),code_execution_config={"work_dir": "web","use_docker": False,}, # Please set use_docker=True if docker is available to run the generated code. Using docker is safer than running the generated code directly.llm_config=llm_config,system_message="Reply TERMINATE if the task has been solved at full satisfaction. Otherwise, reply CONTINUE, or the reason why the task is not solved yet.",
)
使用LangGraph封裝
現在我們將AutoGen智能體封裝為一個單獨的LangGraph節點,并使其成為整個圖結構。這主要涉及為節點定義輸入和輸出模式——即使手動部署也需要完成這項工作,因此不會增加額外負擔。
API參考文檔:StateGraph
from langgraph.graph import StateGraph, MessagesStatedef call_autogen_agent(state: MessagesState):last_message = state["messages"][-1]response = user_proxy.initiate_chat(autogen_agent, message=last_message.content)# get the final response from the agentcontent = response.chat_history[-1]["content"]return {"messages": {"role": "assistant", "content": content}}graph = StateGraph(MessagesState)
graph.add_node(call_autogen_agent)
graph.set_entry_point("call_autogen_agent")
graph = graph.compile()
通過LangGraph平臺部署
您現在可以像往常一樣使用LangGraph平臺進行部署。更多詳情請參閱這些說明。
如何將LangGraph集成到React應用中
https://langchain-ai.github.io/langgraph/cloud/how-tos/use_stream_react/
前提條件
- LangGraph平臺
- LangGraph服務
useStream() React鉤子提供了一種無縫集成LangGraph到React應用的方式。它處理了所有流式傳輸、狀態管理和分支邏輯的復雜性,讓你能專注于構建出色的聊天體驗。
主要特性:
- 消息流式處理:處理消息分塊流以形成完整消息
- 自動狀態管理:管理消息、中斷、加載狀態和錯誤
- 對話分支:從聊天歷史中的任意點創建替代對話路徑
- UI無關設計:可使用自定義組件和樣式
下面我們來探索如何在React應用中使用useStream()。
useStream()為創建定制聊天體驗提供了堅實基礎。如需預構建的聊天組件和界面,我們也推薦查看CopilotKit和assistant-ui。
安裝
npm install @langchain/langgraph-sdk @langchain/core
示例
"use client";import { useStream } from "@langchain/langgraph-sdk/react";
import type { Message } from "@langchain/langgraph-sdk";export default function App() {const thread = useStream<{ messages: Message[] }>({apiUrl: "http://localhost:2024",assistantId: "agent",messagesKey: "messages",});* return (<div><div>{thread.messages.map((message) => (<div key={message.id}>{message.content as string}</div>))}</div><formonSubmit={(e) => {e.preventDefault();const form = e.target as HTMLFormElement;const message = new FormData(form).get("message") as string;form.reset();thread.submit({ messages: [{ type: "human", content: message }] });}}><input type="text" name="message" />{thread.isLoading ? (<button key="stop" type="button" onClick={() => thread.stop()}>Stop</button>) : (<button keytype="submit">Send</button>)}</form></div>);
}
自定義用戶界面
useStream() 鉤子函數在幕后處理了所有復雜的狀態管理,為您提供了簡潔的接口來構建用戶界面。以下是開箱即用的功能:
- 線程狀態管理
- 加載與錯誤狀態處理
- 中斷機制
- 消息處理與更新
- 分支支持
以下是如何有效使用這些功能的示例:
加載狀態
isLoading 屬性可以告訴你數據流何時處于活動狀態,使你可以:
- 顯示加載指示器
- 在處理期間禁用輸入字段
- 顯示取消按鈕
export default function App() {const { isLoading, stop } = useStream<{ messages: Message[] }>({apiUrl: "http://localhost:2024",assistantId: "agent",messagesKey: "messages",});* return (<form>{isLoading && (<button key="stop" type="button" onClick={() => stop()}>Stop</button>)}</form>);
}
線程管理
通過內置的線程管理功能跟蹤對話。您可以訪問當前線程ID,并在新線程創建時收到通知:
const [threadId, setThreadId] = useState<string | null>(null);const thread = useStream<{ messages: Message[] }>({apiUrl: "http://localhost:2024",assistantId: "agent",* threadId: threadId,onThreadId: setThreadId,
});
我們建議將 threadId 存儲在 URL 的查詢參數中,以便用戶在頁面刷新后能恢復對話。
消息處理
useStream() 鉤子會持續追蹤從服務端接收到的消息分片,并將它們拼接成完整的消息。拼接完成的消息分片可通過 messages 屬性獲取。
默認情況下,messagesKey 設置為 messages,此時新的消息分片會被追加到 values["messages"] 中。如果您將消息存儲在其他鍵名下,可以修改 messagesKey 的值。
import type { Message } from "@langchain/langgraph-sdk";
import { useStream } from "@langchain/langgraph-sdk/react";export default function HomePage() {const thread = useStream<{ messages: Message[] }>({apiUrl: "http://localhost:2024",assistantId: "agent",messagesKey: "messages",});* return (<div>{thread.messages.map((message) => (<div key={message.id}>{message.content as string}</div>))}</div>);
}
在底層實現中,useStream() 鉤子會使用 streamMode: "messages-tuple" 模式,從圖節點內部的任何 LangChain 聊天模型調用中接收消息流(即獨立的 LLM 令牌)。有關消息流的更多信息,請參閱流式傳輸指南。
中斷機制
useStream() 鉤子函數提供了 interrupt 屬性,該屬性會存儲來自線程的最新中斷信息。您可以通過中斷機制實現以下功能:
- 在執行某個節點前渲染確認界面
- 等待人工輸入,使智能體能夠向用戶提出澄清性問題
更多關于中斷機制的使用方法,請參閱如何處理中斷指南。
const thread = useStream<{ messages: Message[] }, { InterruptType: string }>({apiUrl: "http://localhost:2024",assistantId: "agent",messagesKey: "messages",
});if (thread.interrupt) {return (<div>Interrupted! {thread.interrupt.value}<buttontype="button"onClick={() => {// `resume` can be any value that the agent acceptsthread.submit(undefined, { command: { resume: true } });}}>Resume</button></div>);
}
分支管理
對于每條消息,您可以使用 getMessagesMetadata() 獲取該消息首次出現時的檢查點。然后,您可以從首次出現檢查點的前一個檢查點創建新運行,從而在線程中創建新分支。
可以通過以下方式創建分支:
1、編輯之前的用戶消息
2、請求重新生成之前的助手消息
"use client";import type { Message } from "@langchain/langgraph-sdk";
import { useStream } from "@langchain/langgraph-sdk/react";
import { useState } from "react";function BranchSwitcher({branch,branchOptions,onSelect,
}: {branch: string | undefined;branchOptions: string[] | undefined;onSelect: (branch: string) => void;
}) {if (!branchOptions || !branch) return null;const index = branchOptions.indexOf(branch);* return (<div className="flex items-center gap-2"><buttontype="button"onClick={() => {const prevBranch = branchOptions[index - 1];if (!prevBranch) return;onSelect(prevBranch);}}>Prev</button><span>{index + 1} / {branchOptions.length}</span><buttontype="button"onClick={() => {const nextBranch = branchOptions[index + 1];if (!nextBranch) return;onSelect(nextBranch);}}>Next</button></div>);
}function EditMessage({message,onEdit,
}: {message: Message;onEdit: (message: Message) => void;
}) {const [editing, setEditing] = useState(false);* if (!editing) {return (<button type="button" onClick={() => setEditing(true)}>Edit</button>);}* return (<formonSubmit={(e) => {e.preventDefault();const form = e.target as HTMLFormElement;const content = new FormData(form).get("content") as string;form.reset();onEdit({ type: "human", content });setEditing(false);}}><input name="content" defaultValue={message.content as string} /><button type="submit">Save</button></form>);
}export default function App() {const thread = useStream({apiUrl: "http://localhost:2024",assistantId: "agent",messagesKey: "messages",});* return (<div><div>{thread.messages.map((message) => {const meta = thread.getMessagesMetadata(message);const parentCheckpoint = meta?.firstSeenState?.parent_checkpoint;return (<div key={message.id}><div>{message.content as string}</div>{message.type === "human" && (<EditMessagemessage={message}onEdit={(message) =>thread.submit({ messages: [message] },{ checkpoint: parentCheckpoint })}/>)}{message.type === "ai" && (<buttontype="button"onClick={() =>thread.submit(undefined, { checkpoint: parentCheckpoint })}><span>Regenerate</span></button>)}<BranchSwitcherbranch={meta?.branch}branchOptions={meta?.branchOptions}onSelect={(branch) => thread.setBranch(branch)}/></div>);})}</div><formonSubmit={(e) => {e.preventDefault();const form = e.target as HTMLFormElement;const message = new FormData(form).get("message") as string;form.reset();thread.submit({ messages: [message] });}}><input type="text" name="message" />{thread.isLoading ? (<button key="stop" type="button" onClick={() => thread.stop()}>Stop</button>) : (<button key="submit" type="submit">Send</button>)}</form></div>);
}
對于高級使用場景,您可以使用 experimental_branchTree 屬性獲取線程的樹狀表示,這可用于為非基于消息的圖表渲染分支控件。
樂觀更新
您可以在向代理發起網絡請求之前,樂觀地更新客戶端狀態。這種方式能夠為用戶提供即時反饋,例如在代理尚未收到請求時,就立即顯示用戶消息。
const stream = useStream({apiUrl: "http://localhost:2024",assistantId: "agent",messagesKey: "messages",
});const handleSubmit = (text: string) => {const newMessage = { type: "human" as const, content: text };* stream.submit({ messages: [newMessage] },{optimisticValues(prev) {const prevMessages = prev.messages ?? [];const newMessages = [...prevMessages, newMessage];return { ...prev, messages: newMessages };},});
};
TypeScript
useStream() 鉤子對使用 TypeScript 編寫的應用非常友好,你可以為狀態指定類型以獲得更好的類型安全性和 IDE 支持。
// Define your types
type State = {messages: Message[];context?: Record<string, unknown>;
};// Use them with the hook
const thread = useStream<State>({apiUrl: "http://localhost:2024",assistantId: "agent",messagesKey: "messages",
});
你也可以選擇性地為不同場景指定類型,例如:
ConfigurableType:用于config.configurable屬性的類型(默認:Record<string, unknown>)InterruptType:用于中斷值的類型——即interrupt(...)函數的內容(默認:unknown)CustomEventType:用于自定義事件的類型(默認:unknown)UpdateType:用于提交函數的類型(默認:Partial<State>)
const thread = useStream<State,{UpdateType: {messages: Message[] | Message;context?: Record<string, unknown>;};InterruptType: string;CustomEventType: {type: "progress" | "debug";payload: unknown;};ConfigurableType: {model: string;};}
>({apiUrl: "http://localhost:2024",assistantId: "agent",messagesKey: "messages",
});
如果你正在使用 LangGraph.js,也可以復用你的圖注解類型。但請確保僅導入注解模式的類型,以避免引入整個 LangGraph.js 運行時(例如通過 import type { ... } 指令)。
import {Annotation,MessagesAnnotation,type StateType,type UpdateType,
} from "@langchain/langgraph/web";const AgentState = Annotation.Root({...MessagesAnnotation.spec,context: Annotation<string>(),
});const thread = useStream<StateType<typeof AgentState.spec>,{ UpdateType: UpdateType<typeof AgentState.spec> }
>({apiUrl: "http://localhost:2024",assistantId: "agent",messagesKey: "messages",
});
事件處理
useStream() 鉤子提供了多個回調選項,幫助您響應不同事件:
onError:發生錯誤時觸發onFinish:流結束時觸發onUpdateEvent:收到更新事件時觸發onCustomEvent:收到自定義事件時觸發。參閱流式傳輸指南了解如何傳輸自定義事件onMetadataEvent:收到元數據事件時觸發,該事件包含運行ID和線程ID
了解更多
- JS/TS SDK 參考文檔
如何使用LangGraph實現生成式用戶界面
https://langchain-ai.github.io/langgraph/cloud/how-tos/generative_ui_react/
前提條件
- LangGraph平臺
- LangGraph服務端
useStream()React Hook
生成式用戶界面(Generative UI)使智能體能夠超越純文本交互,生成豐富的用戶界面。這可以創建更具交互性和上下文感知的應用程序,其中界面會根據對話流程和AI響應動態調整。
LangGraph平臺支持將React組件與圖代碼協同定位。這樣您可以專注于為圖構建特定的UI組件,同時輕松集成到現有聊天界面(如Agent Chat)中,并且僅在真正需要時加載代碼。
教程
1、定義與配置UI組件
首先創建你的第一個UI組件。每個組件都需要提供一個唯一標識符,該標識符將用于在圖代碼中引用該組件。
src/agent/ui.tsx
const WeatherComponent = (props: { city: string }) => {return <div>Weather for {props.city}</div>;
};export default {weather: WeatherComponent,
};
接下來,在 langgraph.json 配置文件中定義您的 UI 組件:
{"node_version": "20","graphs": {"agent": "./src/agent/index.ts:graph"},"ui": {"agent": "./src/agent/ui.tsx"}
}
ui 部分指向圖表將使用的 UI 組件。默認情況下,我們建議使用與圖表名稱相同的鍵名,但您也可以按需拆分組件,更多細節請參閱自定義 UI 組件的命名空間。
LangGraph 平臺會自動打包您的 UI 組件代碼和樣式,并將其作為可通過 LoadExternalComponent 組件加載的外部資源提供服務。部分依賴項(如 react 和 react-dom)會被自動排除在打包范圍之外。
平臺還開箱即用地支持 CSS 和 Tailwind 4.x,因此您可以在 UI 組件中自由使用 Tailwind 類以及 shadcn/ui。
src/agent/ui.tsx
import "./styles.css";const WeatherComponent = (props: { city: string }) => {return <div className="bg-red-500">Weather for {props.city}</div>;
};export default {weather: WeatherComponent,
};
src/agent/styles.css
@import "tailwindcss";
2、發送圖中的UI組件
Python
src/agent.py
import uuid
from typing import Annotated, Sequence, TypedDictfrom langchain_core.messages import AIMessage, BaseMessage
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph
from langgraph.graph.message import add_messages
from langgraph.graph.ui import AnyUIMessage, ui_message_reducer, push_ui_messageclass AgentState(TypedDict): # noqa: D101messages: Annotated[Sequence[BaseMessage], add_messages]ui: Annotated[Sequence[AnyUIMessage], ui_message_reducer]async def weather(state: AgentState):class WeatherOutput(TypedDict):city: strweather: WeatherOutput = (await ChatOpenAI(model="gpt-4o-mini").with_structured_output(WeatherOutput).with_config({"tags": ["nostream"]}).ainvoke(state["messages"]))message = AIMessage(id=str(uuid.uuid4()),content=f"Here's the weather for {weather['city']}",)# Emit UI elements associated with the messagepush_ui_message("weather", weather, message=message)return {"messages": [message]}workflow = StateGraph(AgentState)
workflow.add_node(weather)
workflow.add_edge("__start__", "weather")
graph = workflow.compile()
JS
使用 typedUi 工具從您的代理節點發出 UI 元素:
src/agent/index.ts
import {typedUi,uiMessageReducer,
} from "@langchain/langgraph-sdk/react-ui/server";import { ChatOpenAI } from "@langchain/openai";
import { v4 as uuidv4 } from "uuid";
import { z } from "zod";import type ComponentMap from "./ui.js";import {Annotation,MessagesAnnotation,StateGraph,type LangGraphRunnableConfig,
} from "@langchain/langgraph";const AgentState = Annotation.Root({...MessagesAnnotation.spec,ui: Annotation({ reducer: uiMessageReducer, default: () => [] }),
});export const graph = new StateGraph(AgentState).addNode("weather", async (state, config) => {// Provide the type of the component map to ensure// type safety of `ui.push()` calls as well as// pushing the messages to the `ui` and sending a custom event as well.const ui = typedUi<typeof ComponentMap>(config);const weather = await new ChatOpenAI({ model: "gpt-4o-mini" }).withStructuredOutput(z.object({ city: z.string() })).withConfig({ tags: ["nostream"] }).invoke(state.messages);const response = {id: uuidv4(),type: "ai",content: `Here's the weather for ${weather.city}`,};// Emit UI elements associated with the AI messageui.push({ name: "weather", props: weather }, { message: response });return { messages: [response] };}).addEdge("__start__", "weather").compile();
3、在React應用中處理UI元素
在客戶端,你可以使用 useStream() 和 LoadExternalComponent 來展示UI元素。
src/app/page.tsx
"use client";import { useStream } from "@langchain/langgraph-sdk/react";
import { LoadExternalComponent } from "@langchain/langgraph-sdk/react-ui";export default function Page() {const { thread, values } = useStream({apiUrl: "http://localhost:2024",assistantId: "agent",});* return (<div>{thread.messages.map((message) => (<div key={message.id}>{message.content}{values.ui?.filter((ui) => ui.metadata?.message_id === message.id).map((ui) => (<LoadExternalComponent key={ui.id} stream={thread} message={ui} />))}</div>))}</div>);
}
在幕后,LoadExternalComponent 會從 LangGraph 平臺獲取 UI 組件的 JS 和 CSS 文件,并在 shadow DOM 中渲染它們,從而確保這些組件的樣式與應用程序的其他部分相互隔離。
操作指南
在客戶端提供自定義組件
如果您的客戶端應用中已加載了相關組件,可以直接提供一個組件映射表,無需從LangGraph平臺獲取UI代碼即可直接渲染。
const clientComponents = {weather: WeatherComponent,
};<LoadExternalComponentstream={thread}message={ui}components={clientComponents}
/>;
組件加載時顯示加載界面
當組件正在加載時,你可以提供一個備用界面進行渲染。
<LoadExternalComponentstream={thread}message={ui}fallback={<div>Loading...</div>}
/>
自定義 UI 組件的命名空間
默認情況下,LoadExternalComponent 會使用 useStream() 鉤子中的 assistantId 來獲取 UI 組件的代碼。您可以通過向 LoadExternalComponent 組件提供 namespace 屬性來自定義此行為。
src/app/page.tsx
<LoadExternalComponentstream={thread}message={ui}namespace="custom-namespace"
/>
langgraph.json
{"ui": {"custom-namespace": "./src/agent/ui.tsx"}
}
從UI組件訪問和交互線程狀態
您可以通過使用 useStreamContext 鉤子在UI組件內部訪問線程狀態。
import { useStreamContext } from "@langchain/langgraph-sdk/react-ui";const WeatherComponent = (props: { city: string }) => {const { thread, submit } = useStreamContext();return (<><div>Weather for {props.city}</div><buttononClick={() => {const newMessage = {type: "human",content: `What's the weather in ${props.city}?`,};submit({ messages: [newMessage] });}}>Retry</button></>);
};
向客戶端組件傳遞額外上下文
您可以通過向LoadExternalComponent組件提供meta屬性,來向客戶端組件傳遞額外的上下文信息。
<LoadExternalComponent stream={thread} message={ui} meta={{ userId: "123" }} />
然后,你可以通過使用 useStreamContext 鉤子在 UI 組件中訪問 meta 屬性。
import { useStreamContext } from "@langchain/langgraph-sdk/react-ui";const WeatherComponent = (props: { city: string }) => {const { meta } = useStreamContext<{ city: string },{ MetaType: { userId?: string } }>();* return (<div>Weather for {props.city} (user: {meta?.userId})</div>);
};
從服務器流式傳輸 UI 消息
您可以通過 useStream() 鉤子的 onCustomEvent 回調,在節點執行完成前流式傳輸 UI 消息。這在 LLM 生成響應時更新 UI 組件特別有用。
import { uiMessageReducer } from "@langchain/langgraph-sdk/react-ui";const { thread, submit } = useStream({apiUrl: "http://localhost:2024",assistantId: "agent",onCustomEvent: (event, options) => {options.mutate((prev) => {const ui = uiMessageReducer(prev.ui ?? [], event);return { ...prev, ui };});},
});
然后,您可以通過調用 ui.push() 或 push_ui_message() 并傳入要更新的 UI 消息的相同 ID,來推送對該 UI 組件的更新。
Python
from typing import Annotated, Sequence, TypedDictfrom langchain_anthropic import ChatAnthropic
from langchain_core.messages import AIMessage, AIMessageChunk, BaseMessage
from langgraph.graph import StateGraph
from langgraph.graph.message import add_messages
from langgraph.graph.ui import AnyUIMessage, push_ui_message, ui_message_reducerclass AgentState(TypedDict): # noqa: D101messages: Annotated[Sequence[BaseMessage], add_messages]ui: Annotated[Sequence[AnyUIMessage], ui_message_reducer]class CreateTextDocument(TypedDict):"""Prepare a document heading for the user."""title: strasync def writer_node(state: AgentState):model = ChatAnthropic(model="claude-3-5-sonnet-latest")message: AIMessage = await model.bind_tools(tools=[CreateTextDocument],tool_choice={"type": "tool", "name": "CreateTextDocument"},).ainvoke(state["messages"])tool_call = next((x["args"] for x in message.tool_calls if x["name"] == "CreateTextDocument"),None,)if tool_call:ui_message = push_ui_message("writer", tool_call, message=message)ui_message_id = ui_message["id"]# We're already streaming the LLM response to the client through UI messages# so we don't need to stream it again to the `messages` stream mode.content_stream = model.with_config({"tags": ["nostream"]}).astream(f"Create a document with the title: {tool_call['title']}")content: AIMessageChunk | None = Noneasync for chunk in content_stream:content = content + chunk if content else chunkpush_ui_message("writer",{"content": content.text()},id=ui_message_id,message=message,# Use `merge=rue` to merge props with the existing UI messagemerge=True,)return {"messages": [message]}
JS
import {Annotation,MessagesAnnotation,type LangGraphRunnableConfig,
} from "@langchain/langgraph";
import { z } from "zod";
import { ChatAnthropic } from "@langchain/anthropic";
import {typedUi,uiMessageReducer,
} from "@langchain/langgraph-sdk/react-ui/server";
import type { AIMessageChunk } from "@langchain/core/messages";import type ComponentMap from "./ui";const AgentState = Annotation.Root({...MessagesAnnotation.spec,ui: Annotation({ reducer: uiMessageReducer, default: () => [] }),
});async function writerNode(state: typeof AgentState.State,config: LangGraphRunnableConfig
): Promise<typeof AgentState.Update> {const ui = typedUi<typeof ComponentMap>(config);* const model = new ChatAnthropic({ model: "claude-3-5-sonnet-latest" });const message = await model.bindTools([{name: "create_text_document",description: "Prepare a document heading for the user.",schema: z.object({ title: z.string() }),},],{ tool_choice: { type: "tool", name: "create_text_document" } }).invoke(state.messages);* type ToolCall = { name: "create_text_document"; args: { title: string } };const toolCall = message.tool_calls?.find((tool): tool is ToolCall => tool.name === "create_text_document");* if (toolCall) {const { id, name } = ui.push({ name: "writer", props: { title: toolCall.args.title } },{ message });const contentStream = await model// We're already streaming the LLM response to the client through UI messages// so we don't need to stream it again to the `messages` stream mode..withConfig({ tags: ["nostream"] }).stream(`Create a short poem with the topic: ${message.text}`);let content: AIMessageChunk | undefined;for await (const chunk of contentStream) {content = content?.concat(chunk) ?? chunk;ui.push({ id, name, props: { content: content?.text } },// Use `merge: true` to merge props with the existing UI message{ message, merge: true });}}* return { messages: [message] };
}
ui.tsx
function WriterComponent(props: { title: string; content?: string }) {return (<article><h2>{props.title}</h2><p style={{ whiteSpace: "pre-wrap" }}>{props.content}</p></article>);
}export default {weather: WriterComponent,
};
從狀態中移除UI消息
類似于通過追加RemoveMessage從狀態中移除消息的方式,您也可以通過調用remove_ui_message/ui.delete并傳入UI消息的ID,從狀態中移除UI消息。
from langgraph.graph.ui import push_ui_message, delete_ui_message# push message
message = push_ui_message("weather", {"city": "London"})# remove said message
delete_ui_message(message["id"])
JS
// push message
const message = ui.push({ name: "weather", props: { city: "London" } });// remove said message
ui.delete(message.id);
了解更多
- JS/TS SDK 參考文檔





:解釋器風格)











 咖啡售賣官網實例)

