文章目錄
- 一、機器學習的步驟
- Step1 - Function with unknown
- Step2 - Define Loss from Training Data
- Step3 - Optimization
- 二、機器學習的改進
- Q1 - 線性模型有一些缺點
- Q2 - 重新詮釋機器學習的三步
- Q3 - 機器學習的擴展
- Q4 - 過擬合問題(Overfitting)
一、機器學習的步驟
如圖所示,機器學習分為以下三步:

下文按照這個步驟來進行整理
Step1 - Function with unknown
- 機器學習就是 “自動找到一個非常復雜的函數" ,其輸入是原始的數據(聲音信號、圖片、棋盤狀態等),通過這個函數,得到一個較好的答案(語音對應的文字、圖片展示的對象、棋子下一步走法等),如圖:
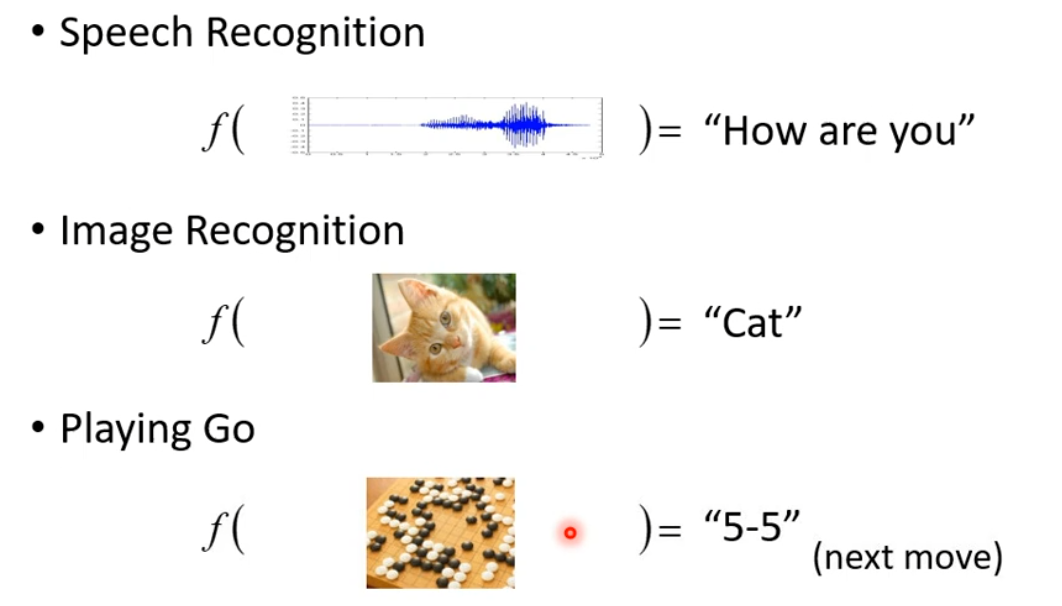
- 為了實現不同的目標,我們可以用機器學習去找不同的函數,這些任務有如下的分類:
(1)Regression:the function output a scalar;找一個數,如預測明天的氣溫、PM2.5濃度;
(2)Classification: Given options(classes),the function output the correct one;給出一個正確的選項;
(3)Structured Learning:讓機器產生有結構性的信息(文章、圖片等);
…
- x`Model:帶有未知參數的函數,也就是我們機器學習的目標——建立一個model解決問題。在Model中我們有一些概念:
(1)feature:來源于數據,是已知的參數。
(2)weight:與feature相乘,代表feature的重要程度。
(3)bias:預測值和真實值的偏差。

我們用以上式子來解釋:將瀏覽信息輸入,預測未來瀏覽量。
其中 y 就是我們預測的瀏覽量, x 1 x_1 x1?是我們之前的瀏覽量,w是weight,b是bias。
Step2 - Define Loss from Training Data
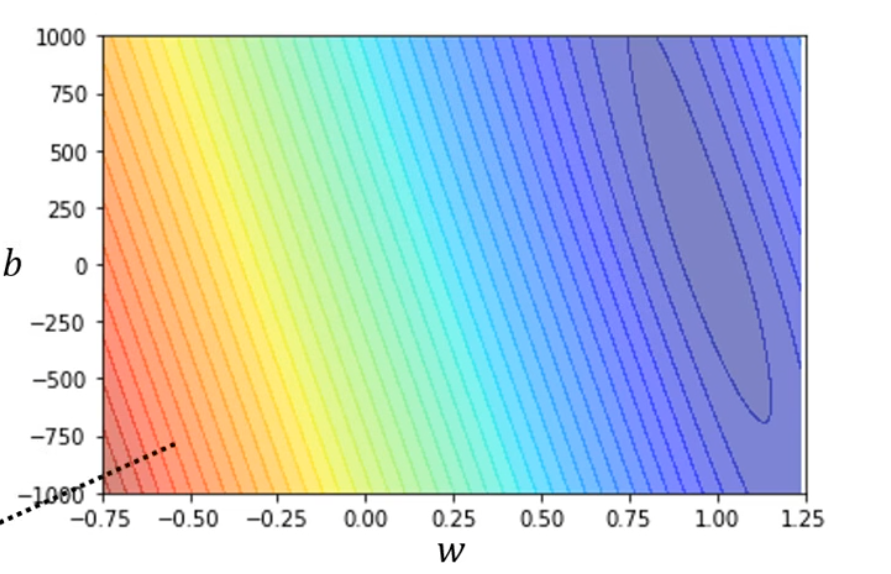
- Loss也是一個函數,其輸入是之前提到的weigth和bias,它的輸出用來衡量這兩個數值設置的好不好。
- 可以通過比對估測的值和真實的值之間的差距,使用 e = ∣ y ? y ^ ∣ e = |y - \hat{y}| e=∣y?y^?∣ (MAE) 或 e = y ? y ^ ) 2 e = y - \hat{y})^2 e=y?y^?)2 (MSE) 來衡量,其中真實的值叫做Label。
- 可以用如下的圖表衡量Loss與bias和weight的關系:
Step3 - Optimization
- 優化的目標就是找到一個讓Loss - e e e 更小的函數,我們將優化方法——梯度下降(Gradient Descent)也分為如下三步:
(1)(Randomly)Pick an initial value w 0 w^0 w0
(2) 取微分(bias同理):
? L ? W ∣ w = w 0 \frac{\partial L} {\partial W} \Bigg|_{w = w^0} ?W?L? ?w=w0?
(3) update w w w iteratively:通過剛剛的微分,乘上學習率 η \eta η 來更新 w w w 的值,如下:
w 1 = w 0 ? η ? L ? W ∣ w = w 0 w^1 = w^0 - \eta \frac{\partial L} {\partial W} \Bigg|_{w = w^0} w1=w0?η?W?L? ?w=w0?
注:機器學習中需要自己設置的參數(如學習率 η \eta η),叫做hyperparameters。
- 我們在 w w w 到達滿意的值或者失去耐心(到達設置的移動次數)后,取定最終的值。其中我們發現,如果學習率 η \eta η 設置的較小,我們可能陷入 Local Minima 中,而找不到最優的 Global Minima。
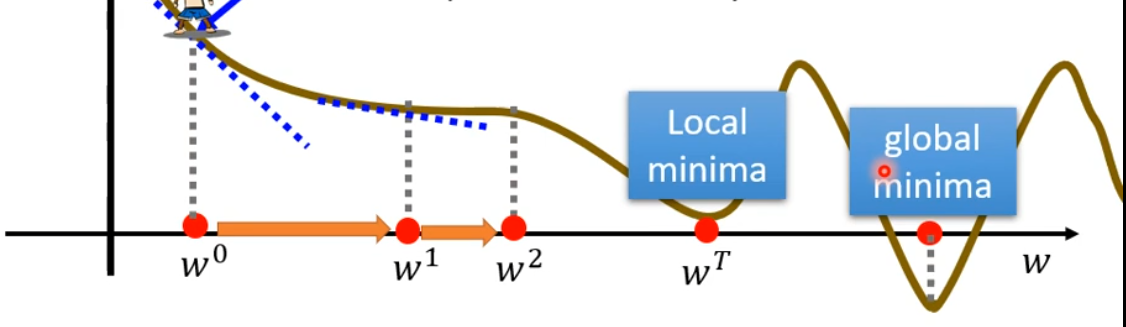
其實它不是機器學習中的難題,后續繼續進行介紹。
二、機器學習的改進
Q1 - 線性模型有一些缺點
- 線性模型(Linear model)太過于簡單,對真實情況可能做不到很好的預測:
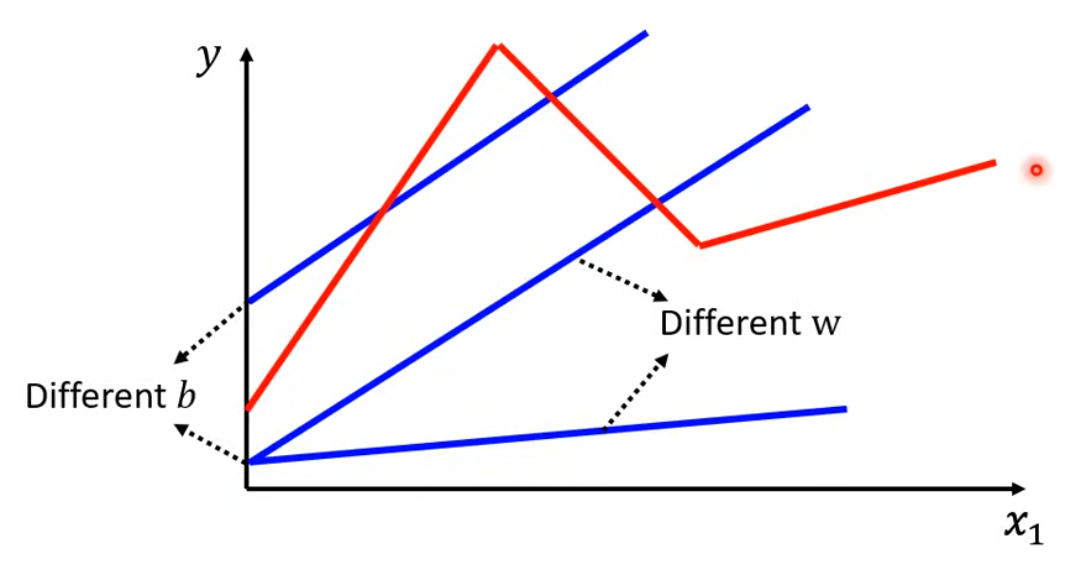
- 我們可以使用常數 + 多個函數來構建最終的模型:

轉折點越多,需要的藍色function越多。如果有足夠多的function組合在一起,也許我們就能得到足夠好的模擬效果。
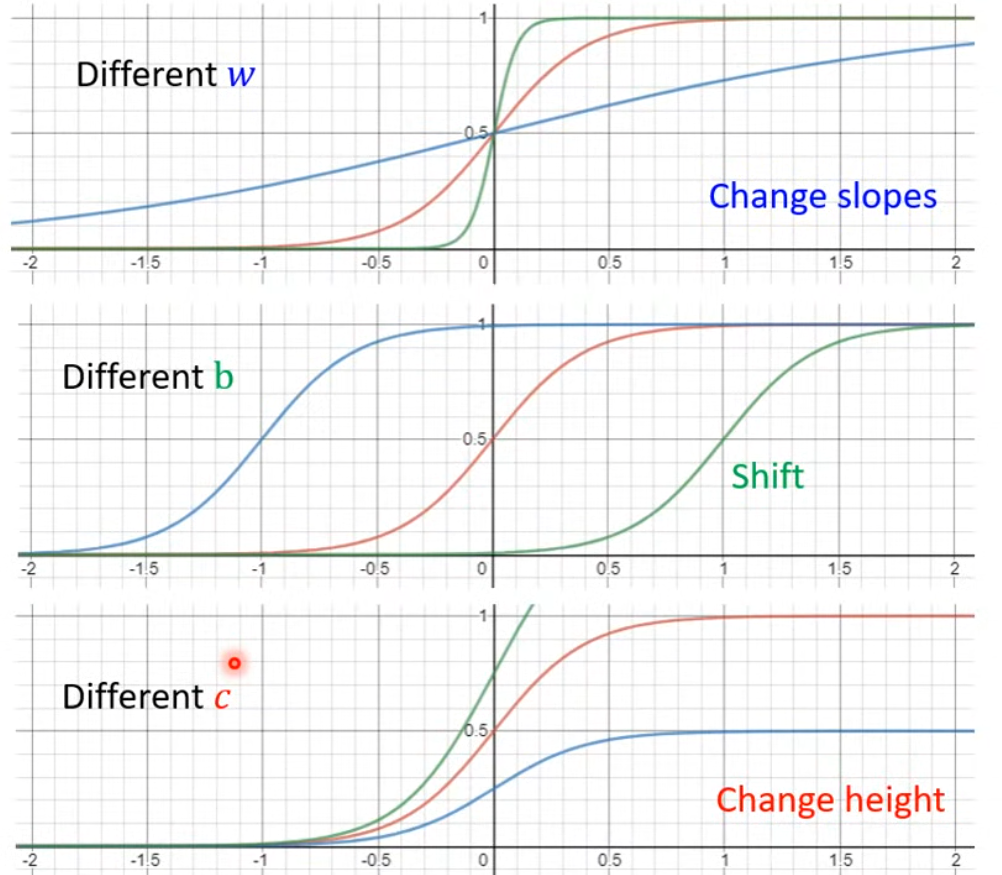
- 引入一個新的概念:激活函數(sigmoid function),其定義如下:
y = c 1 1 + e ? ( b + w x 1 ) = c s i g m o i d ( b + w x 1 ) y = c \ \frac{1}{1 + e^{-(b + wx_1)}} = c \ sigmoid(b+wx_1) y=c?1+e?(b+wx1?)1?=c?sigmoid(b+wx1?)
改變不同的參數有如下效果:
新的Model——擁有更多Feature:
y = b + ∑ i c i s i g m o i d ( b i + w i x 1 ) y = b + \sum_i{c_i}\ sigmoid(b_i + w_ix_1) y=b+i∑?ci??sigmoid(bi?+wi?x1?)
- 更加復雜的model:
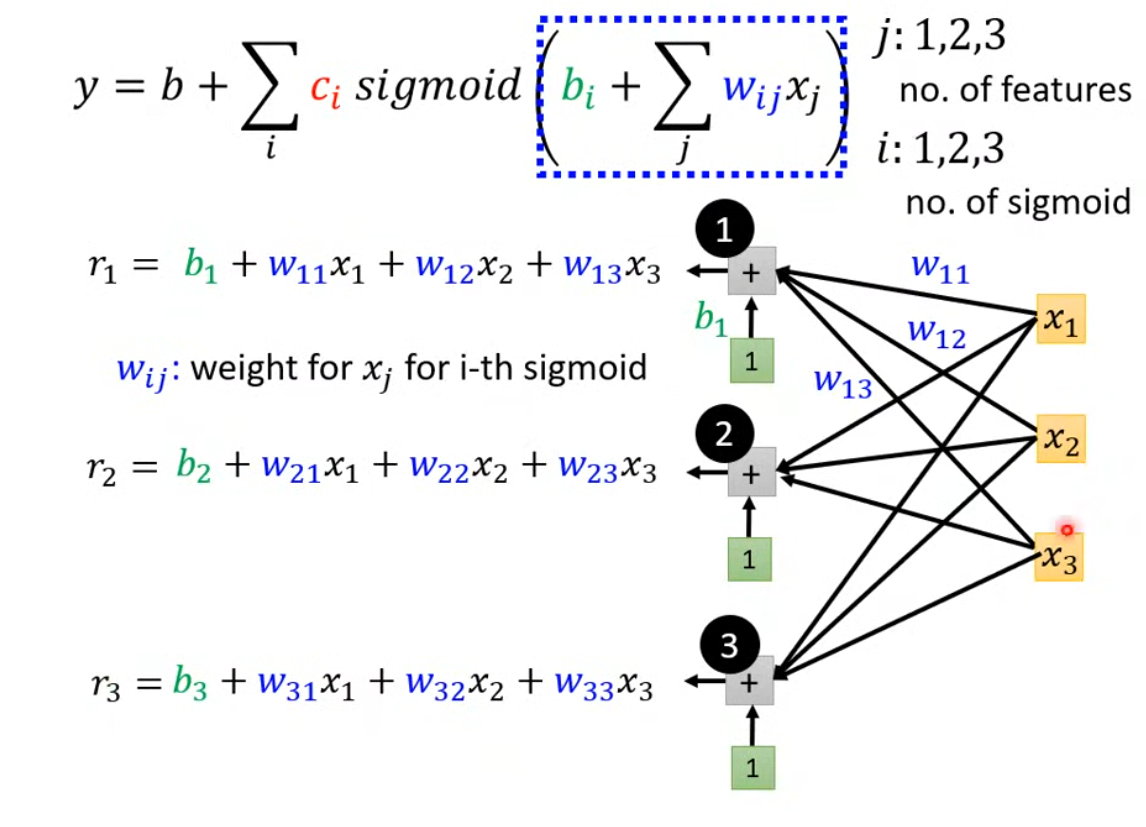
以上是三個sigmoid函數中的元素,我們還可以用線代知識對式子進行簡化:
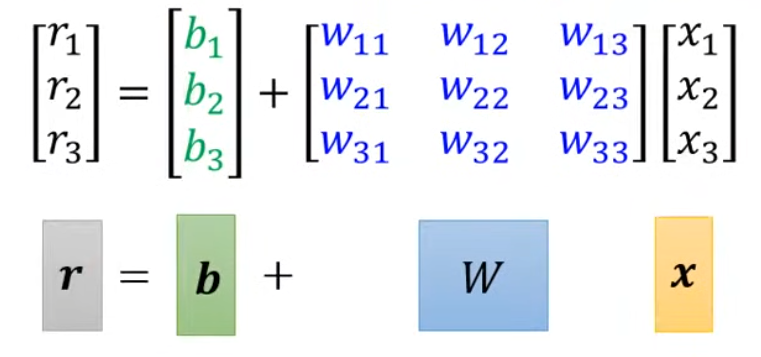
我們構建Model的流程就如下圖所示:
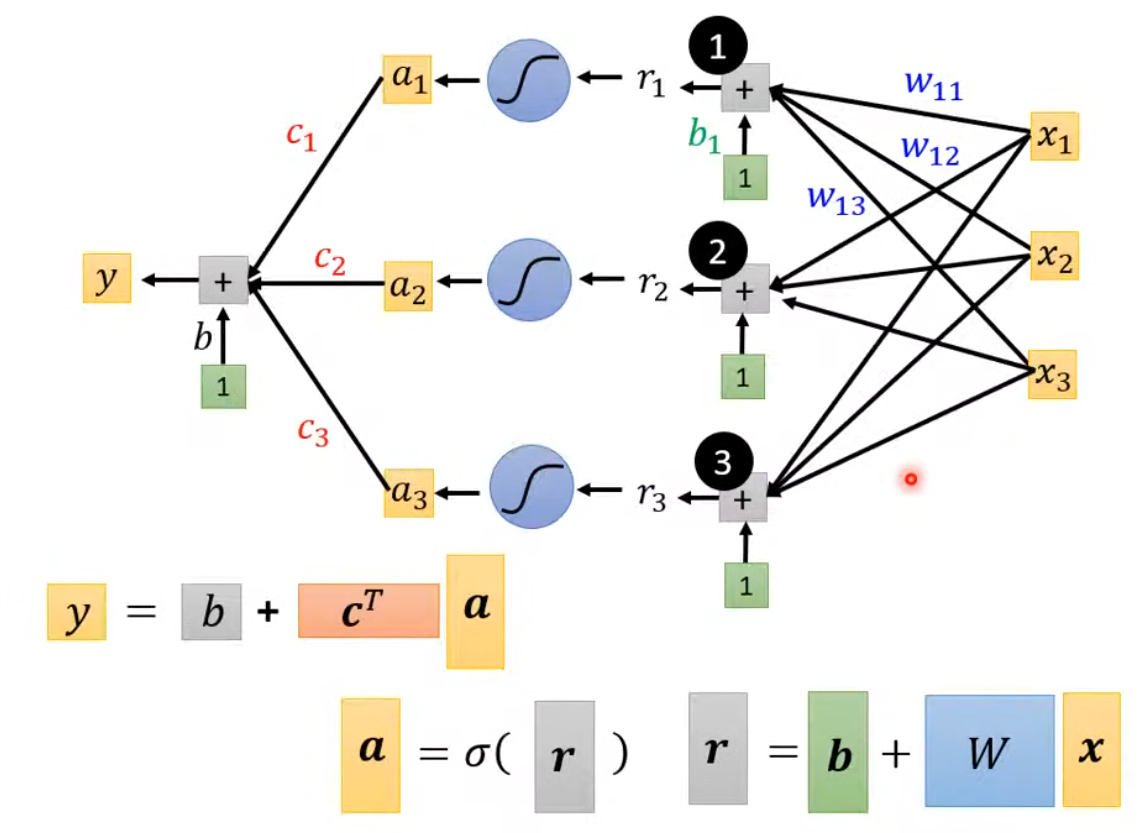
Q2 - 重新詮釋機器學習的三步
-
function with unknown:
現在我們定義的含有未知數的函數就變成了上圖中的函數: y = b + c T σ ( b + W x ) y = b + c^T \sigma(b + Wx) y=b+cTσ(b+Wx)
其中 σ \sigma σ 是激活函數 s i g m o i d sigmoid sigmoid,注意其中的兩個常數 b b b 是不同的值。 -
Define Loss from Training Data
Loss的定義沒有不同,依舊是 L = 1 N ∑ e n L = \frac{1}{N} \sum{e_n} L=N1?∑en?。 -
Optimization of New Model
在新模型中,feature包含 W 、 b 、 C T W 、b、 C^T W、b、CT 等,我們將其全部放入一個新的矩陣 θ \theta θ 中, θ = [ θ 1 θ 2 θ 3 ] \theta = \begin{bmatrix} \theta1 \\ \theta2 \\ \theta3 \\ \end{bmatrix} θ= ?θ1θ2θ3? ?
即將feature的元素依次放入 θ \theta θ。
現在我們引入一個新的向量 gradient(梯度)來表示優化效果:
g = [ ? L ? θ 1 ∣ θ = θ 0 ? L ? θ 2 ∣ θ = θ 0 . . . ] g = ? L ( θ 0 ) g = \begin{bmatrix} \frac{\partial L}{\partial \theta_1} |_{\theta = \theta_0} \\ \\ \frac{\partial L}{\partial \theta_2} |_{\theta = \theta_0} \\ ... \end{bmatrix} \; g = \nabla L(\boldsymbol{\theta}^0) g= ??θ1??L?∣θ=θ0???θ2??L?∣θ=θ0??...? ?g=?L(θ0)
逐步更新參數,取得更好的結果 θ ? = a r g m i n L \theta^* = arg\ min_{}L θ?=arg?min?L 。
Q3 - 機器學習的擴展
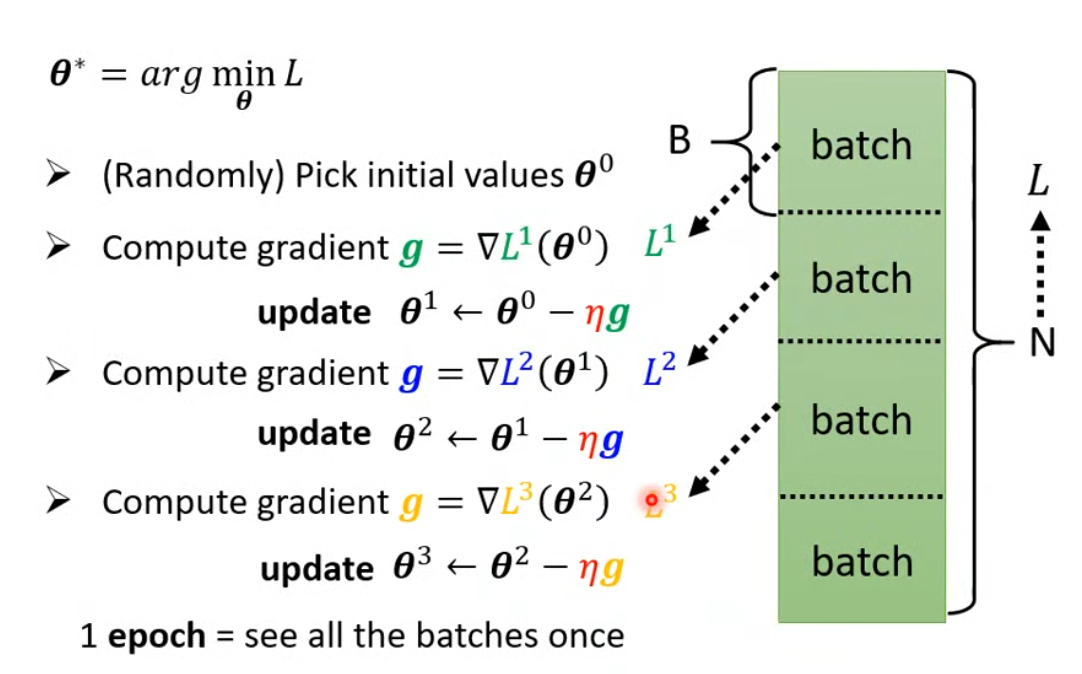
在實際的機器學習中,我們會將完整的數據集分為不同的batch分別進行訓練,每訓練完一個batch,就更新一次模型參數(即進行一次梯度下降)。
優點:
(1) 節省內存:如果你一次用整個數據集訓練(叫做 full-batch),對大數據來說會爆內存。
(2) 更快訓練:batch 可以并行計算,訓練過程更高效。
(3) 提高泛化性:每次用不同的 batch 做梯度估計,有“抖動”,反而能避免陷入局部最優。
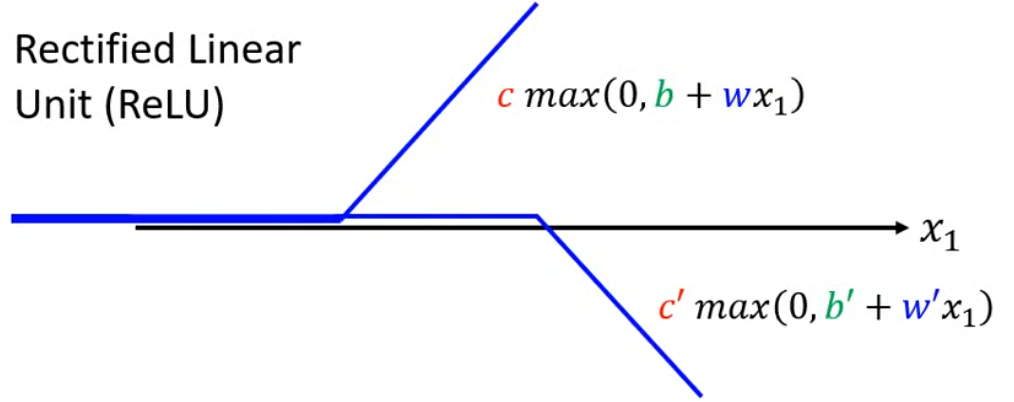
此外,激活函數還不僅僅局限于sigmoid,還有ReLU:
定義:
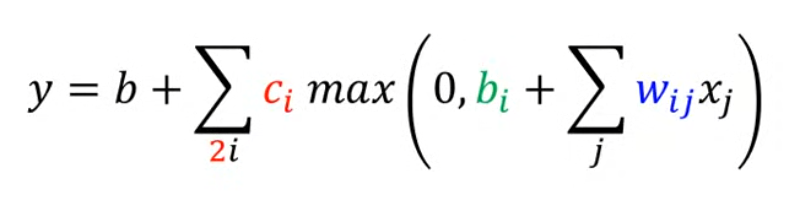
Q4 - 過擬合問題(Overfitting)
再訓練資料上模型表現的較好,但是在新資料上表現差的問題,我們稱之為過擬合(Overfitting)

我們應該選擇在未訓練數據上表現更好的。










 咖啡售賣官網實例)








