類別不平衡問題
- 解決方案
- 簡單方法
- 收集數據
- 調整權重
- 閾值移動
- 數據層面
- 欠采樣
- 過采樣
- 采樣方法的優劣
- 算法層面
- 代價敏感
- 集成學習:EasyEnsemble
- 總結
類別不平衡(class-imbalance)就是指分類任務中不同類別的訓練樣例數目差別很大的情況
解決方案
當問題的指標是ROC或者AUC等對類別不平衡不敏感的指標,那么此時不處理和處理的差別沒那么大;但是對于召回率為評判指標的模型則需要進行處理
簡單方法
收集數據
針對少量樣本數據,可以盡可能去擴大這些少量樣本的數據集,或者盡可能去增加他們特有的特征來豐富數據的多樣性
調整權重
可以簡單的設置損失函數的權重,更多的關注少數類。在python的scikit-learn中我們可以使用class_weight參數來設置權重。為了權衡不同類型錯誤所造成的不同損失,可為錯誤賦予“非均等代價”
閾值移動
直接基于原始訓練集進行學習,但在用訓練好的分類器進行預測時,將原本默認為0.5的閾值調整為 正例數 正例數 + 負例數 \frac{正例數}{正例數+負例數} 正例數+負例數正例數?
如果正負樣本數量相同,對于正樣本預測為 y y y,那么分類決策規則為:
y 1 ? y > 1 \frac{y}{1-y}>1 1?yy?>1
預測為正例,當正負樣本數量不同時,分別為 m + , m ? m^{+},m^{-} m+,m?,則觀測幾率為 m + m ? \frac{m^{+}}{m^{-}} m?m+?,那么當分類器預測幾率大于觀測幾率即為正例:
y 1 ? y > m + m ? \frac{y}{1-y}>\frac{m^{+}}{m^{-}} 1?yy?>m?m+?
可以變化為以下形式:
y ′ 1 ? y ′ = y 1 ? y ? m ? m + > 1 \frac{y'}{1-y'}=\frac{y}{1-y}\cdot \frac{m^{-}}{m^{+}}>1 1?y′y′?=1?yy??m+m??>1
也可以稱為“再縮放”
數據層面
欠采樣
對訓練集中多數類樣本進行“欠采樣”(undersampling),即去除一些多數類中的樣本使得正例、反例數目接近,然后再進行學習。
- 隨機欠采樣
隨機欠采樣顧名思義即從多數類中隨機選擇一些樣本組成樣本集 。然后將新樣本集與少數類樣本集合并。 - Edited Nearest Neighbor (ENN)
遍歷多數類的樣本,如果他的大部分k近鄰樣本都跟他自己本身的類別不一樣,我們就將他刪除;
過采樣
對訓練集里的少數類進行“過采樣”(oversampling),即增加一些少數類樣本使得正、反例數目接近,然后再進行學習。
- 隨機過采樣
隨機過采樣是在少數類S中隨機選擇一些樣本,然后通過復制所選擇的樣本生成樣本集E,將它們添加到S中來擴大原始數據集從而得到新的少數類集合S+E。 - SMOTE(Synthetic Minority Oversampling,合成少數類過采樣)
SMOTE是對隨機過采樣方法的一個改進算法,通過對少數類樣本進行插值來產生更多的少數類樣本。基本思想是針對每個少數類樣本,從它的k近鄰中隨機選擇一個樣本 (該樣本也是少數類中的一個),然后在兩者之間的連線上隨機選擇一點作為新合成的少數類樣本。
采樣方法的優劣
- 優點:
- 平衡類別分布,在重采樣后的數據集上訓練可以提高某些分類器的分類性能。
- 欠采樣方法減小數據集規模,可降低模型訓練時的計算開銷。
- 缺點:
- 采樣過程計算效率低下,通常使用基于距離的鄰域關系(k近鄰)來提取數據分布信息,計算開銷大。
- 易被噪聲影響,最近鄰算法容易被噪聲干擾,可能無法得到準確的分布信息,從而導致不合理的重采樣策略。
- 過采樣方法生成過多數據,會進一步增大訓練集的樣本數量,增大計算開銷,并可能導致過擬合。
- 不適用于無法計算距離的復雜數據集,如用戶ID。
算法層面
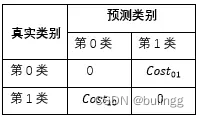
代價敏感
可用于多分類問題,代價敏感學習方法的核心要素是代價矩陣,如表所示。其中 c o s t i j cost_{ij} costij?表示將第 i i i 類樣本預測為第 j j j 類樣本的代價。若將第0類判別為第1類所造成的損失更大,則 c o s t 01 > c o s t 10 cost_{01}>cost_{10} cost01?>cost10?;損失程度相差越大, c o s t 01 , c o s t 10 cost_{01},cost_{10} cost01?,cost10?的值差別越大。當
c o s t 01 = c o s t 10 cost_{01}=cost_{10} cost01?=cost10?時為代價不敏感的學習問題。
集成學習:EasyEnsemble

1:數據中,少數標簽的為P,多數標簽的N,
為P與N在數量上的比例,T為需要采集的subset份數,也可以說是設置的基分類器的個數。
為訓練基分類器i (默認使用AdaBoost,也可以設置為其他,例如XGBoost)的訓練循環次數(iteration)。
2-5: 根據少數標簽的為P的數量,對多數標簽的N進行隨機采樣產生
,使得采樣出來的數量和P的數量一樣。
6: 把
和P結合起來,然后給基分類器i學習。這里的公式只單個基分類器的訓練過程。論文里用的基分類器是AdaBoost,而AdaBoost是由N個弱分類器組成的,j就是表示Adaboost基分類器里的第j個弱分類器.
7: 重復采樣,訓練T個這樣的基分類器。
8: 對T個基分類器進行ensemble。而這里并非直接取T個基分類的結果(0,1)進行投票,而是把n個基分類器的預測概率進行相加,最后再通過sign函數來決定分類,sgn函數就是sign函數,sgn就是把結果轉成兩個類,小于0返回-1,否則返回1。.
總結
-
通過某種方法使得不同類別的樣本對于模型學習中的Loss(或梯度)貢獻是比較均衡的
- 樣本層面
- 欠采樣、過采樣
- 數據增強:從原始數據加工出更多數據的表示,提高原數據的數量及質量,包括幾何操作、顏色變化、隨機裁剪、添加噪聲
- 損失函數層面:代價敏感學習(cost-sensitive),為不同的分類錯誤給予不同懲罰力度(權重)
- class weight:為不同類別的樣本提供不同的權重(少數類有更高的權重),從而模型可以平衡各類別的學習
- Focal loss的核心思想是在交叉熵損失函數(CE)的基礎上增加了類別的不同權重以及困難(高損失)樣本的權重
- OHEM(Online Hard Example Mining)算法的核心是選擇一些hard examples(多樣性和高損失的樣本)作為訓練的樣本,針對性地改善模型學習效果
- 模型層面:
- 選擇對類別不均衡不敏感的模型:采樣+集成樹模型(樹模型按照特征增益遞歸地劃分數據
- 采樣+集成學習:通過重復組合少數類樣本與抽樣的同樣數量的多數類樣本,訓練若干的分類器進行集成學習
- 決策及評估指標
- 分類閾值移動,以調整模型對于不同類別偏好的情況
- 采用AUC、AUPRC(更優)評估模型表現。AUC的含義是ROC曲線的面積;AUC對樣本的正負樣本比例情況是不敏感
- 樣本層面




)

)








![[線代]自用大綱](http://pic.xiahunao.cn/[線代]自用大綱)

)

