介紹
系統架構微服務化以后,根據微服務獨立數據源的思想,每個微服務一般具有各自獨立的數據源,但是不同微服務之間難免需要通過數據分發來共享一些數據,這個就是微服務的數據分發問題。Netflix/Airbnb等一線互聯網公司的實踐[參考附錄1/2/3]表明,數據一致性分發能力,是構建松散耦合、可擴展和高性能的微服務架構的基礎。
本文解釋分布式微服務中的數據一致性分發問題,應用場景,并給出常見的解決方法。本文主要面向互聯網分布式系統架構師和研發經理。
為啥要分發數據?場景?

數據分發場景
我們還是要從具體業務場景出發,為啥要分發數據?有哪些場景?在實際企業中,數據分發的場景其實是非常多的。假設某電商企業有這樣一個訂單服務Order Service,它有一個獨立的數據庫。同時,周邊還有不少系統需要訂單的數據,上圖給出了一些例子:
一個是緩存系統,為了提升訂單數據的訪問性能,我們可以把頻繁訪問的訂單數據,通過Redis緩存起來;
第二個是Fulfillment Service,也就是訂單履行系統,它也需要一份訂單數據,借此實現訂單履行的功能;
第三個是ElasticSearch搜索引擎系統,它也需要一份訂單數據,可以支持前臺用戶、或者是后臺運營快速查詢訂單信息;
第四個是傳統數據倉庫系統,它也需要一份訂單數據,支持對訂單數據的分析和挖掘。
當然,為了獲得一份訂單數據,這些系統可以定期去訂單服務查詢最新的數據,也就是拉模式,但是拉模式有兩大問題:
一個是拉數據通常會有延遲,也就是說拉到的數據并不實時;
如果頻繁拉的話,考慮到外圍系統眾多(而且可能還會增加),勢必會對訂單數據庫的性能造成影響,嚴重時還可能會把訂單數據庫給拉掛。
所以,當企業規模到了一定階段,還是需要考慮數據分發技術,將業務數據同步分發到對數據感興趣的其它服務。除了上面提到的一些數據分發場景,其實還有很多其它場景,例如:
第一個是數據復制(replication)。為了實現高可用,一般要將數據復制多分存儲,這個時候需要采用數據分發。
第二個是支持數據庫的解耦拆分。在單體數據庫解耦拆分的過程中,為了實現不停機拆分,在一段時間內,需要將遺留老數據同步復制到新的數據存儲,這個時候也需要數據分發技術。
第三個是實現CQRS,還有去數據庫Join。這兩個場景我后面有單獨文章解釋,這邊先說明一下,實現CQRS和數據庫去Join的底層技術,其實也是數據分發。
第四個是實現分布式事務。這個場景我后面也有單獨文章講解,這邊先說明一下,解決分布式事務問題的一些方案,底層也是依賴于數據分發技術的。
其它還有流式計算、大數據BI/AI,還有審計日志和歷史數據歸檔等場景,一般都離不開數據分發技術。
總之,波波認為,數據分發,是構建現代大規模分布式系統、微服務架構和異步事件驅動架構的底層基礎技術。
雙寫?
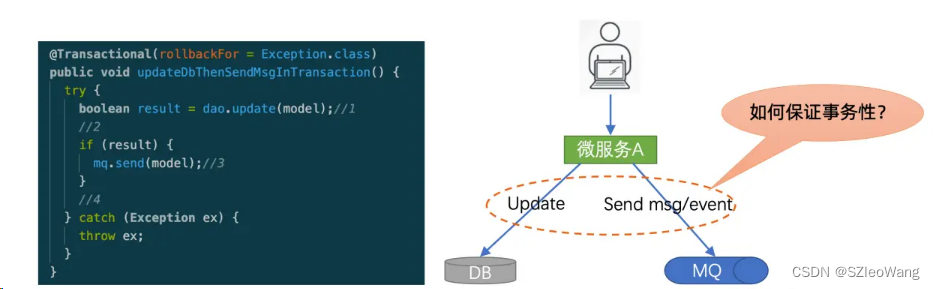
如何保證雙寫的事務性?
對于數據分發這個問題,乍一看,好像并不復雜,稍有開發經驗的同學會說,我在應用層做一個雙寫不就可以了嗎?比方說,請看上圖右邊,這里有一個微服務A,它需要把數據寫入DB,同時還要把數據寫到MQ,對于這個需求,我在A服務中弄一個雙寫,不就搞定了嗎?其實這個問題并沒有那么簡單,關鍵是你如何才能保證雙寫的事務性?
請看上圖左邊的代碼,這里有一個方法updateDbThenSendMsgInTransaction,這個方法上加了事務性標注,也就是說,如果拋異常的話,數據庫操作會回滾。我們來看這個方法的執行步驟:
第一步先更新數據庫,如果更新成功,那么result設為true,如果更新失敗,那么result設為false;
第二步,如果result為true,也就是說DB更新成功,那么我們就繼續做第三步,向mq發送消息
如果發消息也成功,那么我們的流程就走到第四步,整個雙寫事務就成功了。
如果發消息拋異常,也就是發消息失敗,那么容器會執行該方法的事務性回滾,上面的數據庫更新操作也會回滾。
初看這個雙寫流程沒有問題,可以保證事務性。但是深入研究會發現它其實是有問題的。比方說在第三步,如果發消息拋異常了,并不保證說發消息失敗了,可能只是由于網絡異常抖動而造成的拋異常,實際消息可能是已經發到MQ中,但是拋異常會造成上面數據庫更新操作的



)









)

的高維度單模態中介模型的參數估計(入門+實操))



