思路步驟:
本文實現了從文本評論數據中提取有用信息,分析其情感分布、主題分布,并通過可視化展示。以下是具體步驟和思路:
1、數據準備與預處理
加載數據:通過 pandas 讀取文本和評論數據,并進行合并處理。
文本清洗與分詞:使用正則表達式提取中文字符,并調用 jieba 對文本進行分詞,同時去除停用詞,保留有意義的詞語。
文本篩選:篩選積極或者消極情感的評論,剔除重復內容,以確保分析的效率和數據質量。
2、特征提取
TF-IDF 特征:利用 TfidfVectorizer 提取文本特征,限制最大特征數為200,以減少維度和計算復雜度。
Word2Vec 訓練:基于分詞結果,用 gensim 訓練詞向量模型,并提取每個評論的詞向量表示。
3、特征融合與聚類
文檔向量生成:結合 TF-IDF 和 Word2Vec,將每個評論映射為固定維度的向量表示。
數據標準化:利用 StandardScaler 對特征進行標準化處理,以適應后續聚類算法。
KMeans 聚類:使用 KMeans 對評論聚類,并基于每類數據計算關鍵詞分布,提取代表性詞語。
4、情感分析與可視化
情感分析:利用 SnowNLP 提取每條評論的情感得分,根據閾值將其分類為“正面”“中性”或“負面”。
可視化展示:統計情感分布并繪制餅圖,用不同顏色表示情感類別,直觀反映用戶反饋。
5、網絡語義分析
對關鍵詞生成網絡語義分析圖。
6、主題分析:
進行一致性和困惑度計算,通過改變主題數量范圍,計算不同主題數量下的一致性和困惑度,并繪制折線圖展示結果。
進行主題建模和關鍵詞提取,使用LDA模型對分詞結果進行主題建模,并提取每個主題的關鍵詞。對主題建模結果進行可視化,使用pyLDAvis庫生成LDA主題模型的可視化結果,并保存為HTML文件。根據LDA模型計算主題之間的相關性和關鍵詞之間的權重。
7、熱度預測:通過使用增強的LSTM模型進行時間序列預測,預測社交媒體內容的“熱度”變化
數據處理實現:
數據準備與預處理在文本分析中至關重要,是后續建模與分析的基礎。本文中的數據準備與預處理主要包括以下步驟:
1、數據加載:通過 pandas 讀取評論數據 DataFrame 格式。

2、數據清洗與篩選:通過 drop_duplicates 去重,避免因重復數據影響分析結果。

3、文本預處理:對評論內容進行分詞和清洗。利用正則表達式提取中文字符后,通過 jieba 進行分詞,并加載停用詞表過濾掉無意義的高頻詞和單字。最后將處理后的分詞結果重新拼接成文本,便于后續特征提取。
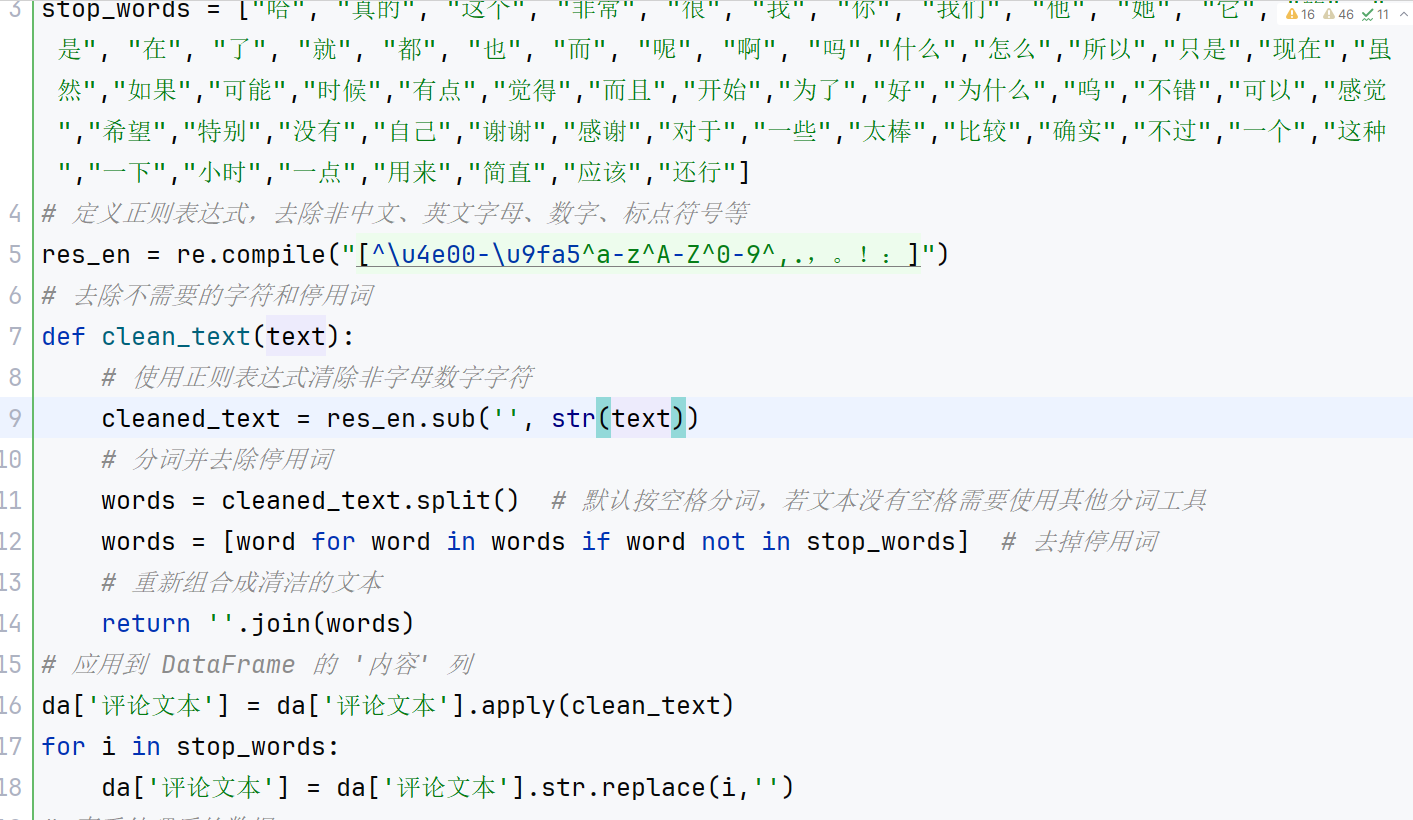
4、特征提取:結合 TF-IDF 和 Word2Vec 兩種方法提取文本特征。首先使用 TF-IDF 提取文本關鍵詞及權重,生成稀疏矩陣,再利用 Word2Vec 生成每個詞的語義向量。通過兩者結合構建文本的特征向量,為后續聚類和分類分析提供輸入。
5、標準化處理:使用 StandardScaler 對特征向量進行標準化,使其分布更均勻,有助于提升聚類和分類算法的性能。
詞頻分析:
在詞頻分析中,核心目標是統計文本中每個詞出現的頻率,以發現高頻詞和潛在的關鍵詞。實現過程中,首先需要對文本進行預處理,包括去除停用詞、標點符號等無效信息,并通過分詞工具(如 jieba)將句子拆分為詞語。然后,利用數據結構(如字典或 Counter)統計每個詞的出現次數。將結果按頻率從高到低排序,提取高頻詞以生成詞云或柱狀圖進行可視化。此外,結合 TfidfVectorizer?提取權重更高的關鍵詞,與簡單詞頻分析的結果進行對比分析,從而提升分析的精準性和有效性。這種方法廣泛應用于文本挖掘、輿情監控等領域。結果如下:

從上述詞頻統計結果來看,熱門地標:上海的相關地標頻率較高,如“外灘”、“南京路”、“豫園”和“陸家嘴”等。這表明討論內容多圍繞上海的知名景點和城市環境,展示了上海作為熱門旅游和商業中心的吸引力。
情感表達:詞頻中出現較多如“喜歡”、“美好”、“開心”等情感詞匯,表明社交媒體上用戶發布的內容偏向于積極的情感表達,傳遞了正面的情緒和體驗。
生活方式:詞匯如“咖啡”、“旅行”、“拍照”和“體驗”等表明人們對日常生活中的休閑活動和生活方式充滿關注,尤其是與旅游、文化和休閑相關的活動。
文化與社會:部分詞匯如“歷史”、“文化”和“博物館”暗示著用戶對本地文化和歷史遺產的關注,表明了對文化深度的探討。
特征融合與聚類
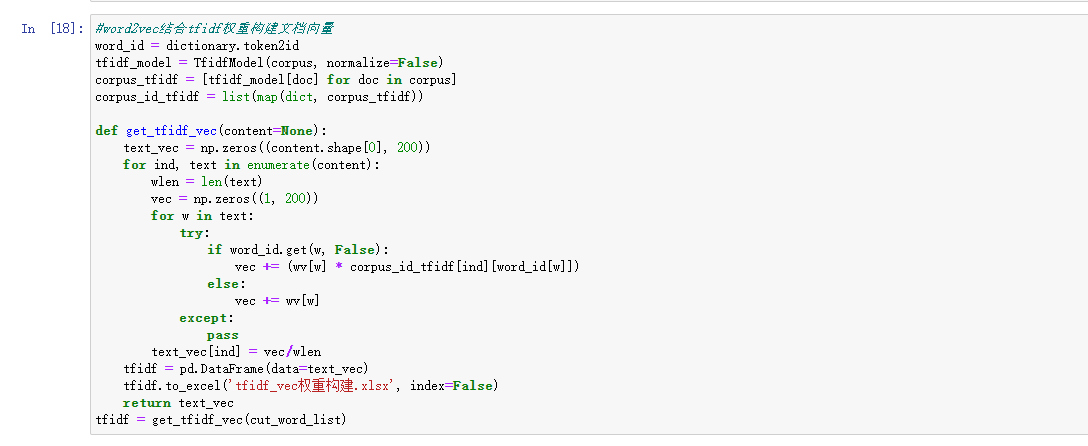
特征融合與聚類的實現通過整合多種技術對文本數據進行深度處理和分析,具體包括以下步驟:首先,進行文本預處理和分詞,將原始評論數據轉化為規范化的中文分詞文本,并去除停用詞,以提高文本分析的準確性。接著,通過 TF-IDF 提取文本的全局統計特征,將文本表示為稀疏向量;同時,利用 Word2Vec 構建詞向量模型,以捕捉詞語的語義關系。為實現特征融合,程序結合 TF-IDF 和 Word2Vec,將文本語義與重要性加權信息綜合到一個統一的文檔向量中。
隨后,對融合后的特征進行標準化處理,消除不同特征間的量綱差異。利用標準化的特征向量,采用 KMeans 聚類算法 對評論進行分組,通過計算每個類中心點與樣本點之間的歐氏距離來確定最優聚類結果。為了分析每個類別的主要特征,利用 TF-IDF 提取每個類別中詞頻較高的重要關鍵詞,幫助理解每類評論的核心特征。這一流程有效實現了文本特征的融合和高效聚類,為后續的情感分析和分類提供了基礎。結果如下:
聚類分析:
聚類分析通過將數據集中的樣本劃分為不同的組(簇)來揭示其內在的模式或結構。在該代碼中,聚類分析的實現流程包括以下幾個關鍵步驟:
1、數據預處理
首先,對文本數據進行清洗和標準化處理。為了避免異常值的干擾,使用 np.nan_to_num 將 NaN 和無窮值替換為 0。同時,通過 StandardScaler 對特征向量進行標準化,將不同量綱的數據轉換到同一尺度上,確保聚類算法的有效性。
2、特征構建與表示
文本數據的特征表示采用兩種方法:TF-IDF 和 Word2Vec。TF-IDF 提取的是基于詞頻的重要性權重,代表文本的統計信息;Word2Vec 捕捉單詞的語義關系。這兩種方法分別生成了稀疏特征矩陣和語義特征向量,為后續聚類提供多種角度的特征支持。
3、確定最優簇數
拐點法:
1.聚類數量的選擇:
通過調整K值(簇的個數),探索不同聚類數量下的聚類效果。在代碼中,通過設置clusters參數來確定聚類數量的范圍。例如,設置clusters = 15表示嘗試聚類數量從1到15的情況。
2.總的簇內離差平方和(Total SSE)的評估:
使用K-Means算法進行聚類,并計算每個簇的樣本離差平方和(SSE)。然后,將每個簇的SSE求和,得到總的簇內離差平方和(Total SSE)。在代碼中,通過自定義函數k_SSE繪制了不同聚類數量(K值)與總的簇內離差平方和之和的折線圖。
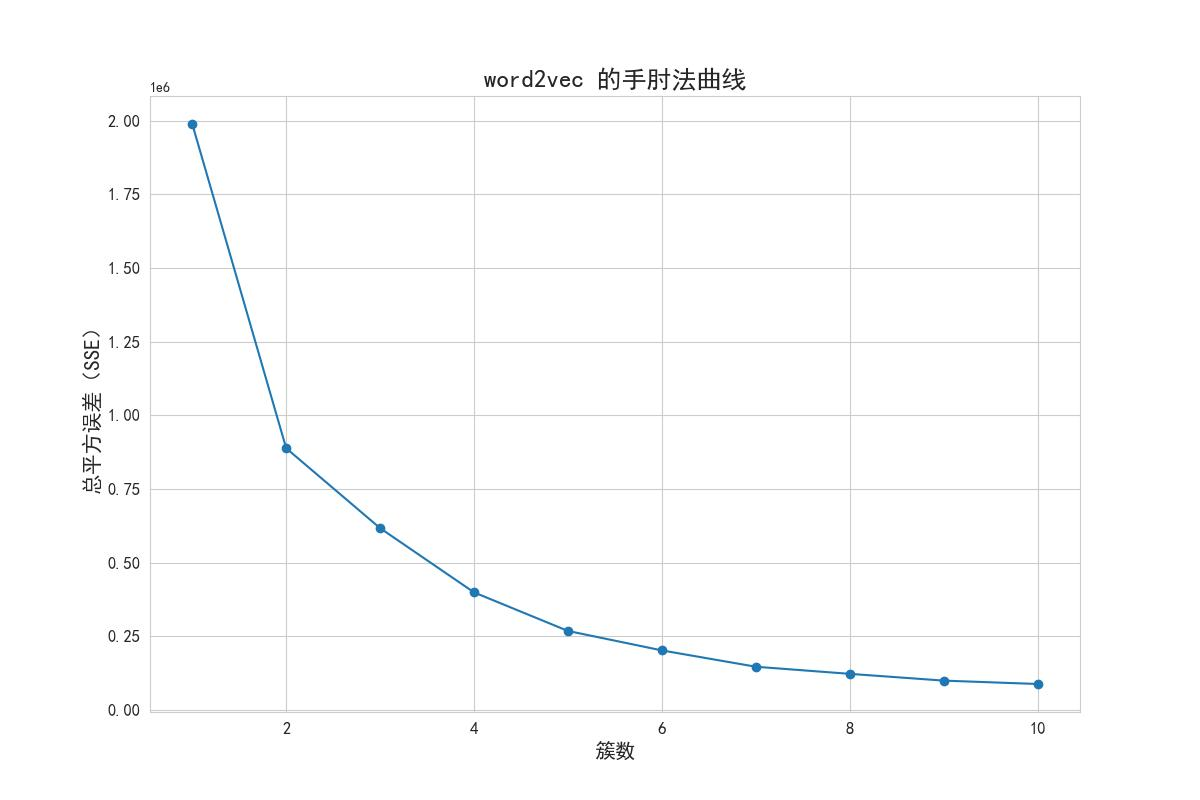
3拐點法選擇最佳聚類數量:
在折線圖中觀察聚類數量(K值)與總的簇內離差平方和之和的關系。尋找一個拐點,即曲線開始趨于平緩的位置。這個拐點對應的聚類數量通常被認為是最佳的聚類數量。在代碼中,通過繪制折線圖來觀察聚類數量與總的簇內離差平方和之和之間的關系,并根據拐點法選擇最佳的聚類數量,拐點法得出的結果如圖所示可知,該方法的拐點為4。
輪廓系數法選擇聚類數量
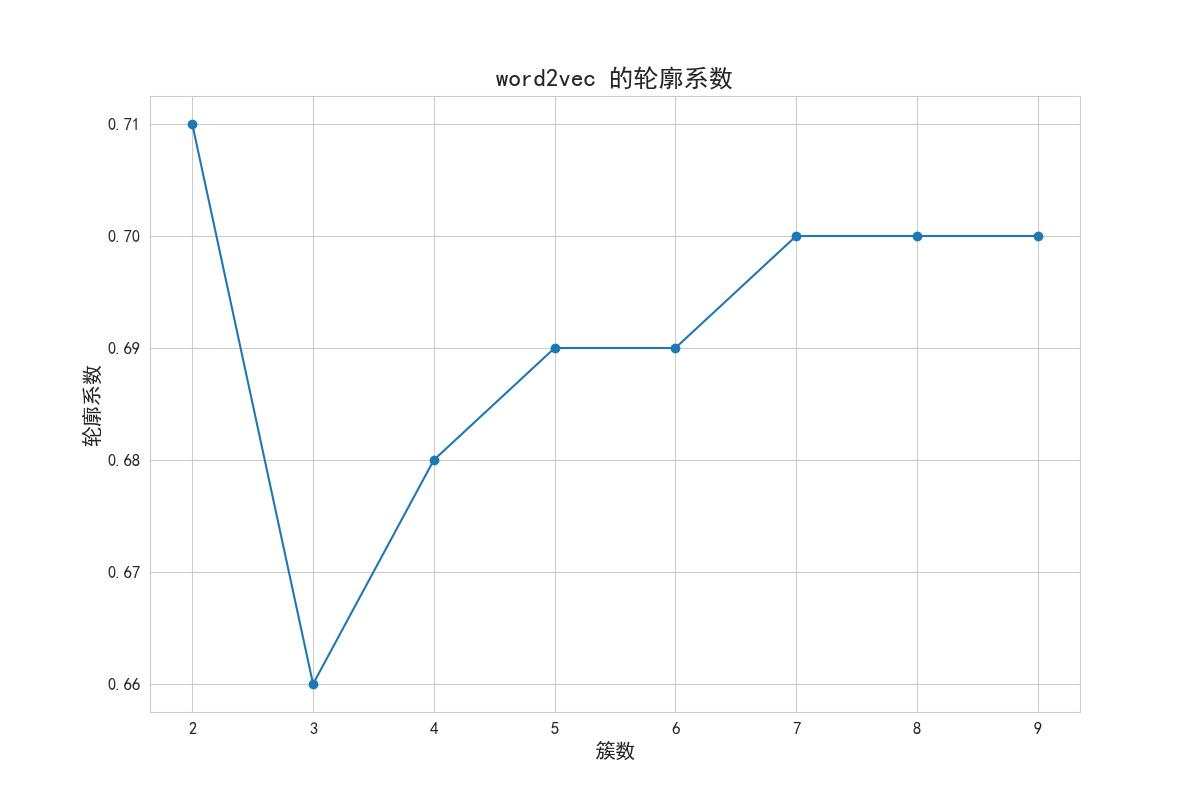
在選擇合適的聚類數量時,使用了輪廓系數法。具體做法是,對于聚類數量從2到10的范圍內的每個值,計算對應聚類數量下的輪廓系數得分。輪廓系數(silhouette score)是一種用于評估聚類質量的指標,其取值范圍為[-1, 1],越接近1表示聚類效果越好。通過繪制輪廓系數得分隨聚類數量變化的曲線圖,可以觀察到不同聚類數量下的聚類效果,并選擇最佳的聚類數量。
最后,代碼使用matplotlib庫繪制了輪廓系數得分隨聚類數量變化的曲線圖,橫坐標為聚類數量(N 簇),縱坐標為輪廓系數得分(score)。根據曲線圖可以進行觀察和判斷,選擇合適的聚類數量,輪廓系數法得到的結果如圖可知最合適聚類數=4。
聚類分析實現與結果可視化
在確定最優簇數后,采用 KMeans 算法對標準化后的特征向量進行聚類。KMeans 通過迭代優化簇中心,最小化樣本到其簇中心的平方誤差。聚類完成后,使用 t-SNE(t-分布鄰域嵌入)將高維特征降維至二維,以便可視化每個樣本的分布情況。根據聚類結果,繪制不同類別的樣本點,便于直觀分析各簇間的分布和相似性。
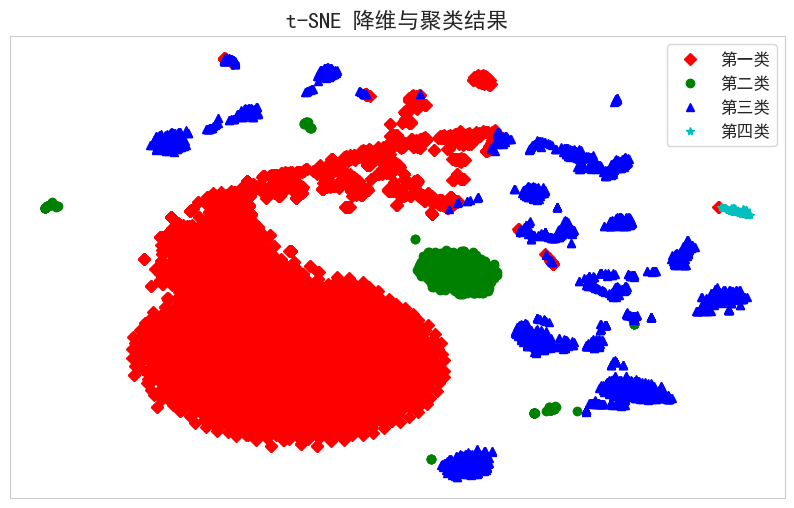
情感分析實現與結果可視化
情感分析是一種通過自然語言處理技術來識別文本中的情感傾向的方法。在給定的代碼中,首先使用 SnowNLP 庫對評論內容進行情感分析,將情感分數劃分為積極、中性和消極三種情感類別。然后,通過對各類別的不同情感數量進行統計,生成了情感分析占比的可視化圖表。通過遍歷評論內容并使用 SnowNLP 庫進行情感分析,將分數劃分為不同的情感類別,并將結果存儲在新的列表中。隨后,利用 Pandas 的 groupby 方法對情感分析結果進行分組統計,得到各情感類別下評論數量的統計結果。最后,利用 Matplotlib 庫繪制了餅圖,展示了不同情感類別在內容中的占比情況。
通過這一系列操作,實現了對評論內容進行情感分析并可視化呈現不同情感類別的占比情況,為進一步分析用戶情感傾向提供了重要參考。這樣的分析和可視化有助于了解用戶對產品的情感態度,為滿意度分析提供了有益的信息支持。
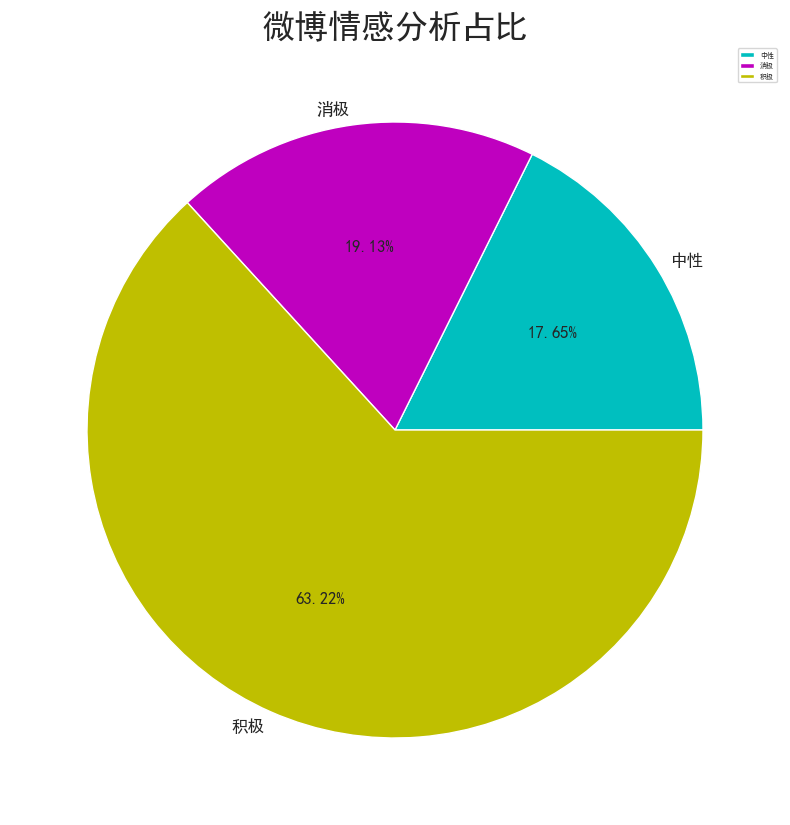
從情感分析結果來看,消極和積極的情感占比分別為19%、63&,反映出用戶情感的總體趨勢。
Lda主題分析
LDA主題分析的實現過程如下:
準備好經過數據清洗和預處理的文本數據。
使用gensim庫構建語料庫和詞袋模型,將文本數據轉換為可用于LDA模型的格式。
設置LDA模型的參數,包括主題數量、迭代次數、詞頻閾值等。
使用LDA模型訓練語料庫,并得到主題-詞語分布和文檔-主題分布。
根據需求,選擇合適的方法獲取每個主題的關鍵詞,可以是按照權重排序或者設定閾值篩選。
可以使用pyLDAvis庫對LDA模型進行可視化,生成交互式的主題模型可視化圖表,并保存為HTML文件。
分析LDA主題分析結果,根據關鍵詞和文檔-主題分布了解每個主題的含義和特點,理解文本數據中不同主題的分布情況。
可以進一步對文本數據進行主題分析,根據文檔-主題分布確定每個文檔最可能的主題,并將主題信息添加到原始數據中。
通過LDA主題分析,可以發現文本數據中的主題結構和主要內容。主題分析可以幫助我們了解文本數據的內在關聯性和分布情況,從而更好地理解文本數據的內容和意義。此外,LDA主題分析還可以用于文本分類、信息檢索和推薦系統等領域,提供有關文本數據的深入洞察和應用價值。結果如下:
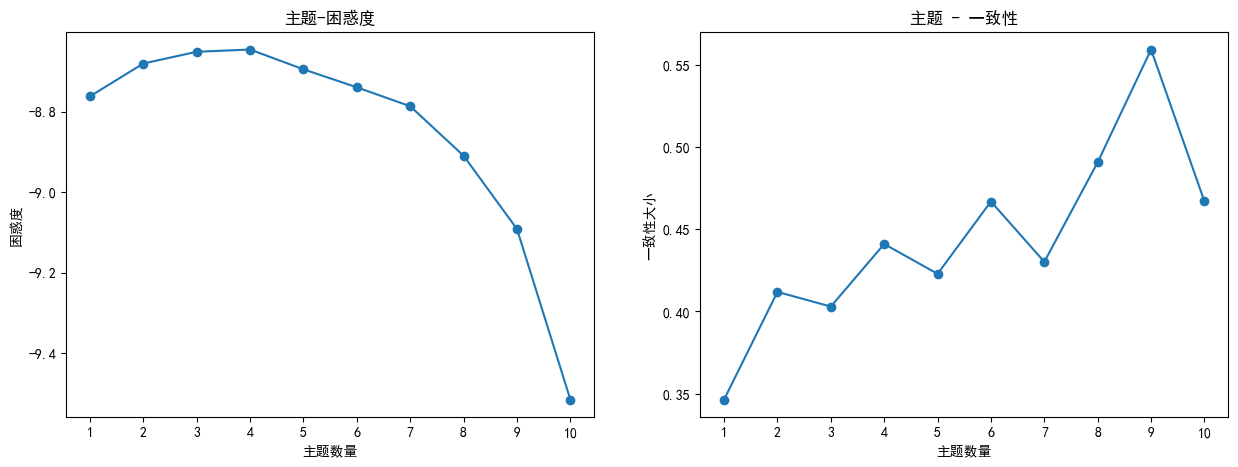
由一致性和困惑度分析曲線圖可知,最優主題數9效果最好。
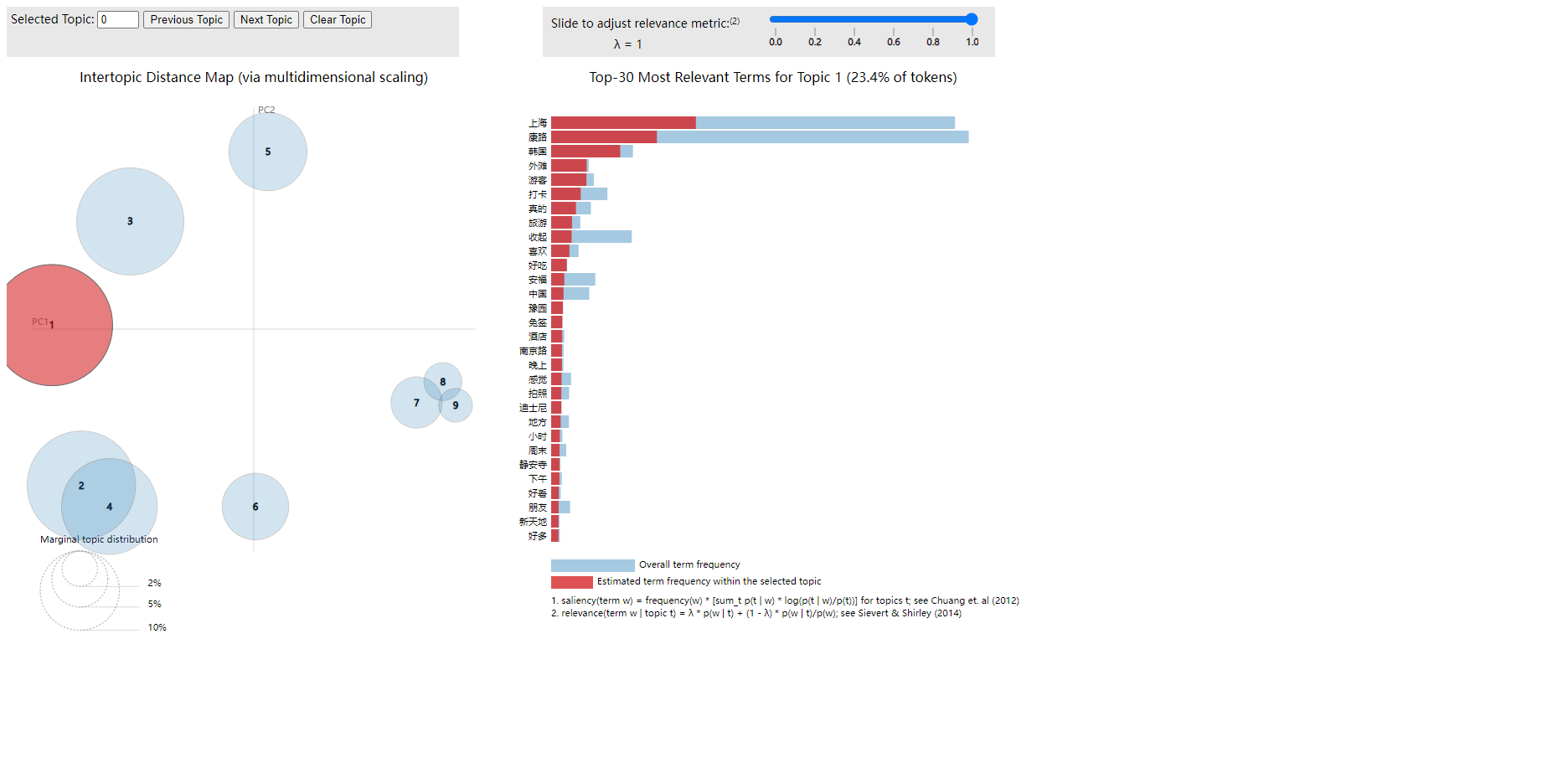
熱門話題:主題0(上海、康路、韓國等)和主題3(上海、康路、大樓等)顯示出較高的討論量和權重,表明上海及其地標性區域(如康路、外灘)在社交媒體上的關注度極高。這些內容多圍繞旅游、打卡和城市景觀,突出了上海作為重要旅游目的地和商業中心的地位。
社會與文化:主題8(歷史、文化、活動等)反映了部分用戶對上海歷史和文化活動的興趣,表現出對本地文化傳承和文化體驗的關注。
消費與生活:主題7(豪車、生活、活動等)和主題5(共享單車、無聲等)則展示了用戶對現代生活方式、消費和時尚趨勢的熱衷,尤其是與高端消費和社交活動相關的討論較為頻繁。
Lstm預測
通過使用增強的LSTM模型進行時間序列預測,旨在預測社交媒體內容的“熱度”變化。代碼首先進行數據預處理,通過時間特征工程處理數據集的“發布時間”列,并提取出星期幾和月份等特征。接著,構建了一個新的熱度指標,這個指標結合了博文的轉發數、點贊數和評論數,且使用7日滾動平均來平滑數據。
數據標準化通過RobustScaler處理,以應對可能的異常值。之后,定義了TimeSeriesDataset類,這個類將數據集轉換成適用于LSTM模型的格式,每個樣本包含14天的歷史數據,目標是預測第15天的熱度值。
增強的LSTM模型包括LSTM層、批歸一化層和全連接層,用于捕捉時間序列數據中的模式和趨勢。訓練過程中使用MSE損失函數和Adam優化器,并采用學習率調度和早停策略來防止過擬合。
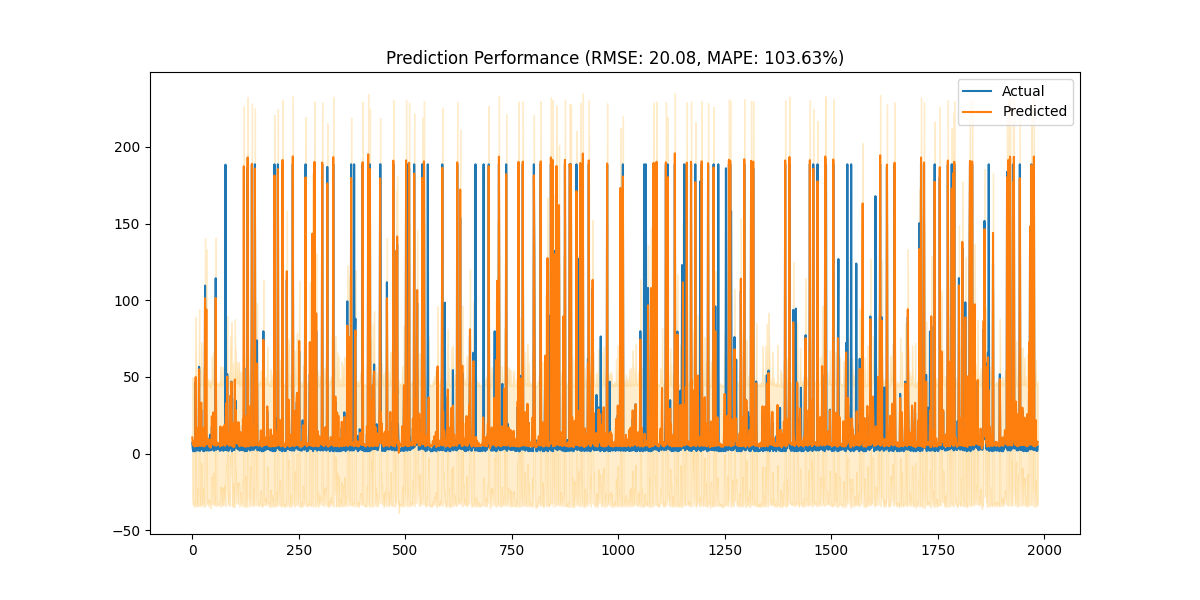
在訓練完成后,評估函數會計算預測的RMSE(均方根誤差)和MAPE(平均絕對百分比誤差),并通過圖表顯示實際值與預測值的對比。此外,代碼還實現了未來7天的熱度預測,結合時間特征并輸出結果。
最終,這個模型能夠在時間序列數據的基礎上對未來熱度進行有效的預測如下圖:










![[論文閱讀] 人工智能 + 軟件工程 | NoCode-bench:評估LLM無代碼功能添加能力的新基準](http://pic.xiahunao.cn/[論文閱讀] 人工智能 + 軟件工程 | NoCode-bench:評估LLM無代碼功能添加能力的新基準)








