項目地址:https://localrf.github.io/
題目:Progressively Optimized Local Radiance Fields for Robust View Synthesis
來源:KAIST、National Taiwan University、Meta 、University of Maryland, College Park
提示:文章用了slam的思想,邊運動邊重建,并將場景劃分為 若干個小的TensorRT塊。每個塊單獨優化輻射場和像機pose

文章目錄
- 摘要
- 一、引言
- 二、相關工作
- 2.1 新視圖合成
- 2.2 可擴展的視圖合成
- 2.3 相機姿態估計
- 三、方法
- 3.1 公式和準備知識
- 3.2 漸進的攝像機pose和輻射場的聯合優化
- 3.3 局部輻射場
- 3.4 實施
- 3.4.1 Loss
- 3.4.2 優化配置
- 四、實驗
- 4.1.數據集
- 4.2.對比方法
- 4.3 定量分析
- 4.4 定性評價
- 4.5 局限性
- 總結
- 在這里插入圖片描述
摘要
??LocalRF:從一個隨意捕獲的視頻,重建一個大規模的場景。該任務的兩個核心挑戰。 首先,大多數現有的輻射場重建方法依賴于SFM預估計的像機pose ,這些算法經常在野外視頻中失敗。其次,單一的全局輻射場能力有限,不能在無界場景中擴展到更長的軌跡 。為了處理未知pose,我們 聯合估計具有輻射場的相機pose,并逐步優化,顯著提高重建的魯棒性。為了處理大型的無界場景, 我們在臨時窗口內,動態分配局部輻射場(逐幀訓練),這進一步提高了魯棒性(例如,即使在適度的pose 漂移下,也能表現得很好),并擴展到大型場景。實驗對TANKS 和 TEMPLES數據集,以及收集的戶外數據集的廣泛評估。
一、引言
?? 逼真視覺合成的密集場景重建有許多重要的應用,例如VR/AR(虛擬旅行、對重要文化文物的保存)、視頻處理(穩定和特殊效果)和映射(房地產、人級地圖)。近年來,在提高利用輻射場[22]進行重建的保真度方面取得了快速的進展。與大多數傳統的方法不同,輻射場可以模擬一些常見的現象,如依賴于視圖的外觀、半透明性和復雜的微觀細節。
1.1 挑戰
?? 本文目標:創建使用單一手持相機獲得的大規模場景的輻射場重建。面臨著兩個主要的挑戰: (1)估計一個長路徑的精確攝像機軌跡和(2)重建場景的大尺度輻射場。 難點:觀測到的變化可以用相機運動或輻射場建模視圖相關外觀的能力來解釋。因此,許多輻射場估計技術假設精確的pose是已知的(通常在輻射場優化期間是固定的)。然而,實踐中必須使用單獨的方法,如運動結構(SfM),來估計預處理步驟中相機的pose(SfM在手持視頻設置中經常失敗)。因為與輻射場不同,它不建模依賴于視圖的外觀,在沒有高度紋理特征的情況下,甚至在有輕微的動態運動(如搖擺的樹枝)的情況下失敗
??為了消除對已知相機姿態的依賴,Barf、NeRF–等方法[11,17,41]提出了聯合優化相機pose和輻射場。這些方法在處理幾個幀和一個良好的姿態初始化時表現良好。然而,正如我們的實驗所示,他們很難從零開始估計攝像機的長軌跡,并且經常處于局部最小值。
1.2 我們的工作。
??本文從經典的增量SfM算法和基于關鍵幀的SLAM系統中汲取靈感,提出了一種聯合位姿和輻射場的估計方法。 方法的核心是,使用重疊的局部輻射場,逐步處理視頻序列。具體地,在更新輻射場的同時,逐步估計輸入幀的pose 。為了模擬大規模的無界場景,我們動態地實例化局部輻射場,主要優點:
- 我們的方法可以擴展處理任意長的視頻,而不損失準確性,也沒有觸及內存限制。
- 增加了魯棒性,因為錯誤估計的影響是局部有限的。
- 增加了銳度,因為我們使用多個輻射場來建模場景的局部細節
??實驗數據:TANKS 和 TEMPLES數據集,以及一個新的數據集 STATIC HIKES(12個戶外場景,使用4個消費者相機)。這些數據具有挑戰性,因為長手持相機軌跡,運動模糊,和復雜的外觀。
1.3 貢獻:
- 逐步估計攝像機的姿態和輻射場,從而顯著提高了魯棒性。
- 多個重疊的局部輻射場提高視覺質量,并支持大規模無界場景建模。
- 提供了一個新收集的視頻數據集,提出了現有視圖合成數據集沒有涵蓋的新挑戰。
1.4 局限性
??限制。LocalRF 聯合估計管道中的姿態,旨在從重建的輻射場中合成新的觀點,但不執行全局bundle adjustment 和 loop closure(即,不是一個完整的SLAM系統)。我們把這個重要的方向留給了未來的工作。
二、相關工作
2.1 新視圖合成
??新視角合成的目的是從多個姿態圖像中合成新的視角。近年來,神經隱式表征顯示出了很有前途的新觀點合成結果[22]。然而,實現高質量的無artifact渲染結果,仍然是一項具有挑戰性的任務。最近的工作通過解決不一致的相機曝光或照明[20,32,36]、處理動態元件[8,16,18,28,29,43]、抗鋸齒[3]、高噪聲[21]或從減少的幀數[27]中進行的優化,進一步提高了視覺質量。雖然這些基于隱式表示的方法可以產生高質量的結果,但它們需要幾天的時間來訓練。為了提高訓練效率,一些工作還探索了具有體素類結構[33,35]、張量分解[6]、光場表示[1,2]或散列體素/MLP混合[24]的更顯式表示。我們的工作還利用了TensoRF [6]最近的優勢。
2.2 可擴展的視圖合成
??已經提出了幾種方法來支持無界場景[4,47]。然而,這些方法要么需要全向(omnidirectional)輸入[10],代理幾何[42],專門的無人機拍攝[40],或衛星拍攝[44],并努力處理在地面上捕獲的單目視頻。最近,Mip-NeRF 360 [4]將背景收縮到一個收縮的空間中,而NeRF++ [47]優化了一個環境地圖來表示背景。BlockNeRF [36]是可擴展的,但需要多視圖輸入和多個觀察結果。NeRFusion [49]使用預先訓練的2D CNN和稀疏的3D CNN構造每幀局部特征體。它是可擴展的,并在大型室內場景上表現出良好的精度,但它不能處理攝像機姿態估計或無界室外場景。由于表示大多是在可選的每個場景優化之前重建的,所以同時優化姿態并不簡單。
?? 與這些約束相比,我們的方法是魯棒性的,適用于任意的長相機軌跡,并且只以隨意捕獲的單目第一人稱視頻作為輸入。
2.3 相機姿態估計
??視覺里程計(Visual odometry) 從視頻中估計相機的姿勢。它們要么是依賴通過最大化照片一致性[46,51]得到的顏色,要么是手工特征[25,26,34]。最近,基于學習的方法[ Particlesfm、Particlesfm等9,15,39,50,51]學習以自監督的方式優化攝像機軌跡,并顯示出很強的結果。類似地,許多方法擴展了NeRF,從光度損失[11,17,41]的輻射場聯合優化相機姿態。然而 ,這些方法在大場景中難以重建和合成真實的圖像,而對于具有長攝像機軌跡的單眼第一人稱視頻往往會失敗。Vox-Fusion [45]和Nice-SLAM [53]可以實現良好的姿態估計,但都是為RGB-D輸入設計的,需要精確的深度: VoxFusion分配稀疏體素網格,用Nice-SLAM來確定沿射線采樣。請注意,我們的目標并不在于估計照相機的姿勢。相反,專注于重建重疊的局部輻射場,使逼真的視圖合成。我們相信,集成諸如global bundle adjustment 等先進技術可以改善我們的結果
三、方法

??LocalRF以一個很長的單目視頻作為輸入,目標是重建場景的輻射場和攝像機軌跡,使自由視點的新視圖合成。LocalRF選擇TensoRF [6]作為基本表示(基于其質量、合理的訓練速度和模型大小)。TensoRF用一個分解的四維張量建模場景,該張量將一個三維位置x映射到相應的體積密度σ和視圖相關的顏色c。然而,它只有在精確的已知攝像機姿態下才能實現,而TensoRF的表示能力需要提高,以便從無界場景的長軌跡中捕捉細節。
??LocalRF通過提高聯合攝像機姿態和輻射場估計的魯棒性,來解決對已知攝像機pose的需要,并將該方法擴展到處理任意長的輸入序列。提出了一種漸進式優化方案,采用一個移動的臨時窗口處理輸入視頻,并逐步更新輻射場和相機姿態。這一過程確保了新的幀被添加到相機pose和輻射場表示的良好收斂方案中,有效地防止卡在較差的局部極。此外,我們在整個優化過程中動態分配新的局部輻射場,這些場由有限數量的輸入幀(在一個時間窗口內)監督。這進一步提高了在使用固定內存處理任意長的視頻時的魯棒性。
3.1 公式和準備知識
??優化過程中,我們估計了P個相機的姿態 [ R|t ]k,k∈[1…P],以及M個局部輻射場的參數Θj,j∈[1…M]。
??給定一個像素,使用相機參數和pose來生成一個射線r。沿著這條射線采樣3D位置{xi},并查詢一個提供顏色和密度的輻射場,并體渲染光線:
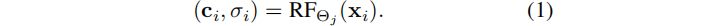

δi為兩個連續樣本點之間的距離,Ti為沿射線的累積透射率。使用輸入幀的顏色C的L1損失作為監督。 TensoRF 具有類似于BARF的[17]的顯式的粗到細的優化,并減少了收斂到局部最小值的可能性。
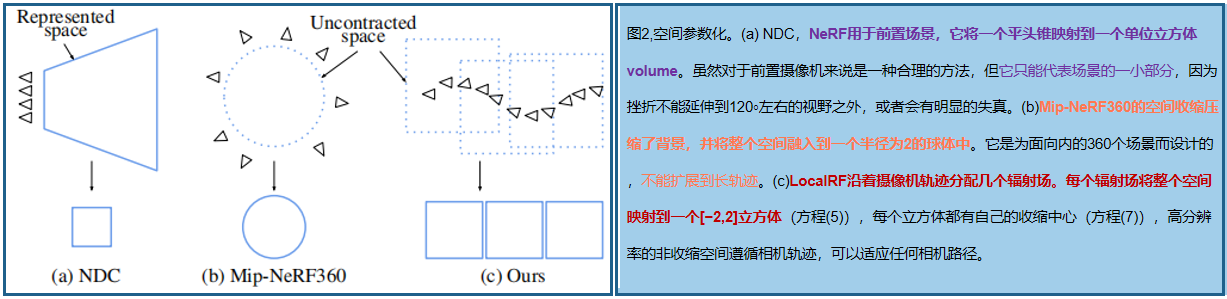
??為了處理無界的場景,利用Mip-NeRF360的收縮的場景參數化,在查詢我們的輻射場模型之前,將每個點映射到一個[?2,2]空間:
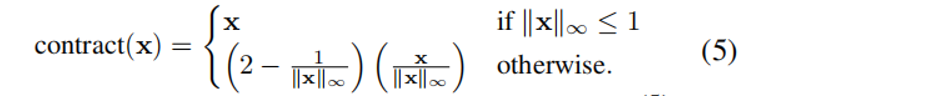 這里我們使用L∞范數來充分利用TensoRF的正方形邊界框。雖然Mip-NeRF360縮放相機pose,可以保持感興趣區域周圍的非收縮空間(原文:Mip-NeRF360 scale camera poses
這里我們使用L∞范數來充分利用TensoRF的正方形邊界框。雖然Mip-NeRF360縮放相機pose,可以保持感興趣區域周圍的非收縮空間(原文:Mip-NeRF360 scale camera poses
to keep the uncontracted space around the area of interest),但我們不能采用這種策略,因為我們聯合估計pose和輻射場(pose是未知的)。我們通過動態創建新的輻射場來實現適當的縮放。
3.2 漸進的攝像機pose和輻射場的聯合優化
??現有的姿態校準方法 [Barf、NeRF–等11,17,41] 已經證明,聯合優化輻射場和攝像機pose可以在小鏡頭場景中獲得令人滿意的效果。然而,當處理較長的序列時,聯合優化失敗了,因為估計的pose處于局部最小值(見圖4)。 為了提高魯棒性,我們只用少量的幀(實驗中為前五幀)開始優化,并逐步引入后續幀的優化 。使用軌跡末的當前幀p,來初始化新的pose (p + 1):
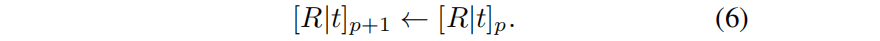
然后將 [R|t]p+1 添加到訓練參數中,新的幀的顏色,作為輻射場的監督。新幀的參數的收斂性得益于輻射場的初始化和當前估計的pose,使其不太容易陷入局部極小值。由于在軌跡的末端添加了攝像機pose,因此它還引入了一個局部性先驗,強制每個pose都接近前一個pose,而沒有明確的約束。

3.3 局部輻射場

?? 上一步方案提供了更魯棒的pose估計,但它仍然依賴于一個單一的全局表示 ,導致問題建模長視頻: (1)任何錯誤估計(例如,離群的pose)產生全局的影響,可能導致重建崩潰。(2)具有固定容量的單一模型,不能代表任意長度視頻的細節,導致模糊(圖5b)。解決方案之一:使用類似Mega-NeRF對輻射場空間進行預分區,但是此處相機的pose在優化之前是未知的。LocalRF:當估計的相機pose軌跡,離開當前輻射場的非收縮空間時,就會動態地創建一個新的輻射場。新的輻射場集中在最后一個估計的相機pose的位置tj 處:

采樣射線時,我們使用此平移使輻射場成為中心:
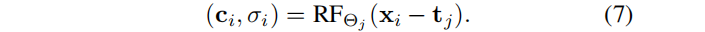
??我們用視頻幀的一個子集(包含當前輻射場所在的所有幀,以及前面的30幀),來監督每個輻射場。重疊的30幀至關重要:所有重疊輻射場的渲染顏色 C ^ \hat{C} C^j(r) 混合在一起,進一步提高了一致性。每一幀使用混合權重,在重疊區域內線性增加/減少。當創建一個新的輻射場時,停止優化以前的輻射場,并從內存中清除監控幀。
3.4 實施
3.4.1 Loss
??除了顏色的監督外,還使用相鄰幀之間的單目深度和光流。使用RAFT [38]來估計幀-幀光流Fk→k+1,k∈[1…P?1]和DPT [30]來估計每幀單目深度d。為了實現這些損失,我們首先通過交換公式(2)中樣本的距離來渲染深度圖:

??得到深度監督(兩個D都做了歸一化,因為單目估計的尺度和位移變化):
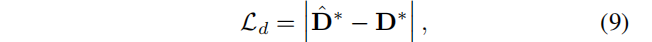
??歸一化方法仿照論文[31:Towards robust monocular depth estimation],如下:
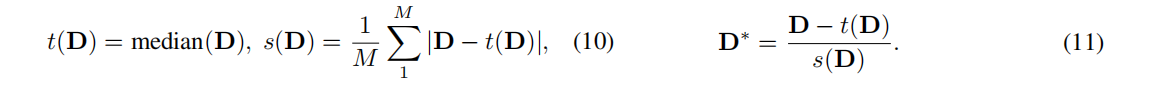
??實踐中,從batch的16張圖像中采集光線,并獲得每個圖像的比例和位移。利用相對的相機pose和渲染的深度圖中,獲得預期光流:
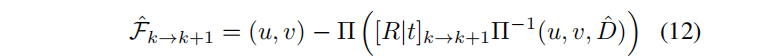
Π表示投影三維點到圖像坐標,Π?1逆投影像素坐標和深度,到一個三維點。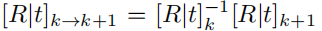 是練續兩幀之間的相對像機pose,將第k個像機空間中的點,帶到第k+1的空間中。最后將預測的流與表示法中的預測流進行比較:
是練續兩幀之間的相對像機pose,將第k個像機空間中的點,帶到第k+1的空間中。最后將預測的流與表示法中的預測流進行比較:
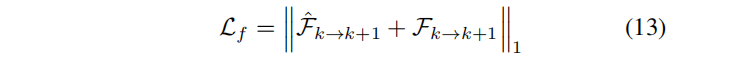
??我們使用相同的過程來監督使用反向光流Fk→k?1。光流計算直接利用了公式(12)中的姿態和場景的幾何形狀,這為其優化提供了一個清晰的梯度信號。
??
3.4.2 優化配置
?? 所有參數都使用β1 = 0.9和β1 = 0.99的Adam進行優化。我們從初始化為identity的五種姿態和一個初始的TensoRF模型開始。然后,對于每100次迭代,我們在視頻中添加下一個監督幀。優化過程中,所有的學習率、損失權重和TensoRF分辨率保持在其初始狀態,確保輻射場不會過擬合于第一幀。我們的初始學習速率為旋轉5·10?3,平移5·10?4,初始TensoRF分辨率為643,初始正則化損失權重為1,深度為0.1。漸進式幀配準,直到估計的相機pose超出了非收縮空間:∥tp?tj∥∞≥1,其中tp 最后一幀的平移,tj 是當前優化的輻射場中心。
?? 從這一新的點開始,細化了TensoRF,每添加新幀進行600次迭代(圖3c)。調度器和正則化損失呈指數級下降到0.1倍,我們將TensoRF向上采樣到6403。在此階段之后分配一個新的TensoRF,并從第一幀中禁用監督。我們重復這個過程,直到重建整個軌跡。在一個NVIDIA泰坦RTX上進行1000幀的優化需要30到40個小時。
??
??
四、實驗
4.1.數據集
??Tanks and Temples: 選擇沒有動態元素的序列(21場景中的9個),保留一個每五幀運動緩慢,降低視頻全高清分辨率(2048×1080或1920×1080),并保持第一個1000圖像方法與靜態數據加載器可以預加載圖像和射線在合理的系統內存。
??Static Hikes: 我們還收集了一個新的具有徒步旅行序列的數據集。它包含具有較大相機軌跡的手持序列,以測試可伸縮性和姿態估計的魯棒性。它包括12個1920×1080靜態戶外場景視頻,由GoPro Hero10拍攝,GoPro×9與窄視場,以及LG V60 ThinQ和三星Galaxy S21的寬攝像頭。
4.2.對比方法
??無界戶外場景對比:Mip-NeRF360和NeRF++ 。Mip-NeRF360結合Instant-NGP[24]的哈希編碼和Mip-NeRF360的場景收縮,有效地表示無限的場景。預處理的poes采用MultiNeRF[23]的腳本來運行COLMAP。我們還比較了可伸縮表示Mega-NeRF[40](我們的實驗使用2×2網格大小)。SCNeRF需要COLMAP作為初始化:在我們的實驗中,當使用NeRF和NeRF++基從頭優化姿態時失敗(我們得到NaN渲染)。因此,我們必須從完全自我校準的評估中排除SCNeRF。
4.3 定量分析
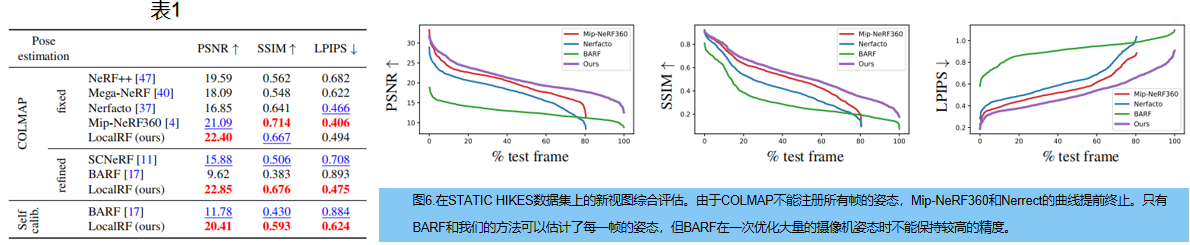
??定量評價新視圖,選擇每10幀作為測試圖像。表1顯示了合成視圖和相應的GT視圖之間的PSNR、SSIM和LPIPS 。平均值在PSNR的平方誤差域計算,SSIM的√ 1 ? S S I M ˉ \bar{1?SSIM} 1?SSIMˉ?。
??使用COLMAP姿態,LocalRF獲得了與Mip-NeRF360 [4]相似的質量。Mega-NeRF [40]為不同類型的輸入數據設計,盡管使用了幾個輻射場,但質量較低。與其他自校準輻射場方法[11,17]相比,我們在從頭開始優化姿態時獲得了更好的結果,這要歸功于我們的漸進優化,允許一次從頭開始估計更少的參數,并在相機姿態之前增加了一個靈活的局部性。圖6顯示,在具有更長的軌跡和更具挑戰性的場景的靜態上升數據集上,LocalRF始終獲得了比自校準的BARF [17]方法更好的結果。依賴于COLMAP的Mip-NeRF360 [4]不能對19.5%的測試幀產生結果。
4.4 定性評價
圖7、8、9顯示了定性結果,感興趣可以翻到最后;表2顯示了消融實驗的結果,同樣放在最后面。
4.5 局限性
??實驗表明,LocalRF可以穩健地估計長相機的軌跡,同時保持高分辨率的表示。然而,我們的pose估計和漸進方案假設我們使用的是一個沒有拍攝變化的連續視頻。這意味著 LocalRF不適合于從沒有連貫性的非結構化幀集合中重建場景。我們也不處理動態元素 。在圖8的最后一行中的動態元素會導致模糊的區域。我們觀察到的另一個限制是,突然的旋轉會破壞姿態估計,導致圖像渲染不佳。
總結
??提出了一種從隨意拍攝的視頻中重建大場景輻射場的新方法。LocalRF的核心思想是:1)一種聯合估計攝像機姿態和輻射場的漸進優化方案;2)動態實例化局部輻射場。實驗對兩個數據集做了廣泛評估,證明了魯棒性和保真度。
??
??
??
??
??
??
??
??
以下是定性實驗結果:
圖7:在 TANKS 和 TEMPLES數據集新視圖。(a)和(b)局部性允許對照明變化和姿態估計失敗具有更強的魯棒性。?因為遵循軌跡的較少收縮的空間,得到更清晰的結果:

圖8: STATIC HIKES上結果:局部輻射場允許我們保持整個軌跡的銳度。一些依賴于預處理姿態的Mip-NeRF360結果缺失了。我們的方法可以穩健地優化姿態,即使在其他方法不太可靠的場景中也能取得良好的結果。

圖9:輸入路徑偏差。LocalRF可以渲染偏離輸入路徑的新視圖:

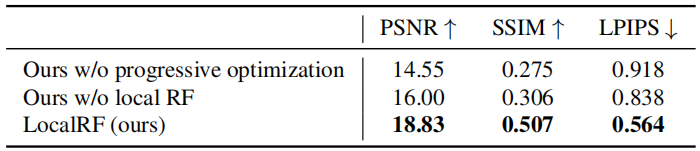
表2:STATIC HIKES數據集上的消融結果:
d \sqrt{d} d? 1 0.24 \frac {1}{0.24} 0.241? x ˉ \bar{x} xˉ x ^ \hat{x} x^ x ~ \tilde{x} x~ ? \epsilon ?
? \phi ?








)
)



)
(std::tuple)(三))




)