在2025年Data+AI Summit上,Databricks發布了一系列重大更新,標志著企業數據治理進入新階段。其中,Unity Catalog的增強功能和對Apache Iceberg的全面支持尤為引人注目。這些更新不僅強化了跨平臺數據管理能力,還推動了開放數據生態的發展。本文將從技術演進、行業實踐和未來趨勢三個維度,分析這些創新如何重塑企業數據架構。
一、Unity Catalog:構建智能化的數據治理體系
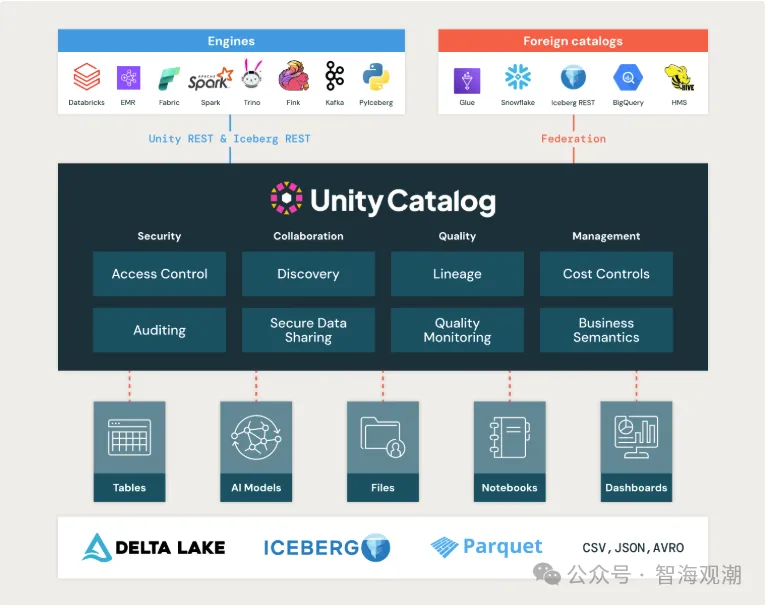
- 跨平臺統一治理:打破數據孤島
Databricks Unity Catalog的核心目標是實現跨云、跨平臺的數據治理。2025年的升級重點包括:
第三方數據源集成:支持Snowflake、BigQuery、Redshift等系統的元數據同步,用戶可在單一界面檢索所有數據資產。
開放協議支持:通過OpenLineage實現與ETL、BI工具的血緣追蹤,提升數據可觀測性。
混合云適配:通過代理網關連接本地Hadoop集群,實現混合環境下的統一權限管理。
- AI與數據治理的深度融合
隨著AI應用的普及,Unity Catalog新增了對機器學習模型和生成式AI的管理能力:
ML模型治理:記錄模型訓練數據來源、版本及部署狀態,確保可追溯性。
生成式AI支持:提供提示詞(Prompt)版本控制,避免LLM(如GPT-4o)的合規風險。
AI自動化分類:利用NLP技術自動識別敏感數據(如PII),提升分類效率。
- 性能優化與成本管理
智能分層存儲:根據訪問頻率自動遷移冷數據至對象存儲,提升查詢性能。
統一計費看板:跨云成本監控與優化建議,幫助企業減少冗余開支。
二、Apache Iceberg支持:開放數據生態的關鍵一步
- 為什么選擇Iceberg?
Apache Iceberg作為一種開放表格式,已成為數據湖倉的事實標準。Databricks的全面支持意味著:
讀寫兼容性:Iceberg可作為原生表格式,與Delta Lake并存,用戶無需遷移即可使用。
性能優化:
向量化讀取加速查詢。
Z-Order聚類優化數據布局,TPC-DS基準測試性能提升20%。
跨引擎協作:支持Spark、Flink、Trino等計算引擎,避免廠商鎖定。
- 企業落地價值
無縫遷移:提供Delta Lake到Iceberg的轉換工具,降低遷移成本。
統一治理:Iceberg表可納入Unity Catalog管理,繼承其權限、審計和血緣追蹤能力。
生態開放:企業可自由組合工具鏈(如Iceberg+Snowflake),提升靈活性。
- 對行業的影響
推動開放標準:減少對單一技術的依賴,促進數據生態多樣化。
加速湖倉一體化:Iceberg的ACID特性使其成為湖倉架構的理想選擇。
三、行業實踐:數據治理的落地與未來趨勢
- 行業核心洞察
實時數據治理:支持Kafka等流數據的元數據實時捕獲,避免事后治理延遲。
行業模板:提供金融、醫療等領域的預置分類規則(如HIPAA、GDPR合規標簽)。
未來方向:
Data Mesh支持:探索域(Domain)級別的聯邦治理模式。
量子安全:研究抗量子加密算法保護元數據安全。
- 未來數據架構的三大趨勢
統一化治理:Unity Catalog將成為跨平臺數據管理的核心。
開放化生態:Iceberg等開放格式減少技術鎖定,提升互操作性。
AI原生:從數據分類到模型管理,AI深度融入治理全流程。
Databricks 2025年的更新標志著數據治理進入新階段:
技術層面:Unity Catalog與Apache Iceberg的結合,實現了“治理+開放”的雙重優勢。
業務層面:企業可更靈活地構建數據架構,同時滿足合規與性能需求。
未來展望:隨著Data Mesh、量子計算等技術的發展,數據治理將更加智能化、分布式化。
對于企業而言,現在正是重新評估數據治理策略的時機——擁抱開放生態,利用AI賦能,才能在數據驅動的未來保持競爭力。
參考資料:
https://www.databricks.com/blog/announcing-full-apache-iceberg-support-databricks
https://www.databricks.com/blog/whats-new-databricks-unity-catalog-data-ai-summit-2025
原文鏈接:Unity Catalog與Apache Iceberg如何重塑Data+AI時代的企業數據架構



















:Pandas 與數據庫交互)