Python面試315道題
- 第一部 Python面試題基礎篇(80道)
- 1、為什么學習Python?
- 2、通過什么途徑學習的Python?
- 3、Python和Java、PHP、C、C#、C++等其他語言的對比?
- PHP
- java
- c
- c#
- c++
- 4、簡述解釋型和編譯型編程語言?
- 編譯型語言
- 特點
- 總結
- 解釋型語言
- 特點
- 總結
- 5、Python解釋器種類以及特點?
- CPython
- IPython
- PyPy
- JPython
- IronPython
- 6、位和字節的關系?
- 7、b、B、KB、MB、GB 的關系?
- 8、請至少列舉5個 PEP8 規范(越多越好)
- 9、通過代碼實現如下轉換:
- 10、請編寫一個函數實現將IP地址轉換成一個整數。
- 11、python遞歸的最大層數?
- 12、求結果:
- 13、ascii、unicode、utf-8、gbk 區別?
- 14、字節碼和機器碼的區別?
- 字節碼
- 機器碼
- 轉換關系
- 使用
- 15、三元運算規則以及應用場景?
- 16、列舉 Python2和Python3的區別?
- 17、用一行代碼實現數值交換:
- 18、Python3和Python2中 int 和 long的區別?
- 19、xrange和range的區別?
- 20、文件操作時:xreadlines和readlines的區別?
- 21、列舉布爾值為False的常見值?
- 22、字符串、列表、元組、字典每個常用的5個方法?
- 23、lambda表達式格式以及應用場景?
- 24、pass的作用?
- 25、*arg和**kwarg作用
- 26、is和==的區別
- 27、簡述Python的深淺拷貝以及應用場景?
- 28、Python垃圾回收機制?
- 29、Python的可變類型和不可變類型?
- 30、求結果:
- 31、求結果:
- 32、列舉常見的內置函數?
- 33、filter、map、reduce的作用?
- 1. map
- 2. filter
- 3. reduce
- 34、一行代碼實現9*9乘法表
- 35、如何安裝第三方模塊?以及用過哪些第三方模塊?
- 36、至少列舉8個常用模塊都有哪些?
- 37、re的match和search區別?
- 38、什么是正則的貪婪匹配?
- 1.噠噠噠噠噠噠多多多 正則表達式的貪婪與非貪婪匹配
- 2.編程中如何區分兩種模式
- 39、求結果:a. [ i % 2 for i in range(10) ] b. ( i % 2 for i in range(10) ) (Python中列表生成式和生成器的區別)
- 40、求結果:a. 1 or 2 b. 1 and 2 c. 1 < (2==2) d. 1 < 2 == 2
- 41、def func(a,b=[]) 這種寫法有什么坑?
- 42、如何實現 “1,2,3” 變成 [‘1’,’2’,’3’] ?
- 43、如何實現[‘1’,’2’,’3’]變成[1,2,3] ?
- 44、比較:a = [1,2,3] 和 b = [(1),(2),(3) ] 以及 b = [(1,),(2,),(3,) ] 的區別?
- 45、如何用一行代碼生成[1,4,9,16,25,36,49,64,81,100] ?
- 46、一行代碼實現刪除列表中重復的值 ?
- 47、如何在函數中設置一個全局變量 ?
- 48、logging模塊的作用?以及應用場景?
- 49、請用代碼簡答實現stack 。
- 實現一個棧stack,后進先出
- 50、常用字符串格式化哪幾種?
- 51、簡述 生成器、迭代器、可迭代對象 以及應用場景?
- 52、用Python實現一個二分查找的函數。
- 53、談談你對閉包的理解?
- 54、os和sys模塊的作用?
- 55、如何生成一個隨機數?
- 56、如何使用python刪除一個文件?
- 57、談談你對面向對象的理解?
- 58、Python面向對象中的繼承有什么特點?
- 59、面向對象深度優先和廣度優先是什么?
- 60、面向對象中super的作用?
- 61、是否使用過functools中的函數?其作用是什么?
- 62、列舉面向對象中帶雙下劃線的特殊方法,如:__new__、__init__
- 63、如何判斷是函數還是方法?
- 64、靜態方法和類方法區別?
- 65、列舉面向對象中的特殊成員以及應用場景
- 66、1、2、3、4、5 能組成多少個互不相同且無重復的三位數
- 67、什么是反射?以及應用場景?
- 68、metaclass作用?以及應用場景?
- 69、用盡量多的方法實現單例模式。
- 70、裝飾器的寫法以及應用場景。
- 71、異常處理寫法以及如何主動拋出異常(應用場景)
- 72、什么是面向對象的MRO
- 73、isinstance作用以及應用場景?
- 74、寫代碼并實現:
- 75、json序列化時,可以處理的數據類型有哪些?如何定制支持datetime類型?
- **JSON主要支持6種數據類型:**
- **定制支持datetime類型**
- 76、json序列化時,默認遇到中文會轉換成unicode,如果想要保留中文怎么辦?
- 77、什么是斷言(assert)?應用場景?
- 78、有用過with statement嗎?它的好處是什么?
- 79、使用代碼實現查看列舉目錄下的所有文件。
- 80、簡述 yield和yield from關鍵字。
- 迭代器和生成器的區別?
第一部 Python面試題基礎篇(80道)
你好! 閑來無事,打發時間!一共315道題,先來基礎篇80道!
1、為什么學習Python?
python優勢可以簡單說一些,對于初學者來說很簡單,從Python開始是最好的選擇。因為它易于學習,功能強大,足以構建Web應用程序并自動化無聊的東西。實際上,幾年前,腳本編寫是學習Python的主要原因,這也是我被Python吸引并首選Perl的原因,而Perl是當時另一種流行的腳本語言。
對于有經驗的程序員或已經了解Ruby,Java或JavaScript的人來說,學習Python意味著在你的工具庫中獲得一個新的強大工具,我還沒有想出一個對工具說“不”的程序員,這是你學習一門新的編程語言時的正確查找方式。
正如經典的Automate the Boring Stuff with Python一書中所提到的,Python讓你能夠自動化瑣碎的東西,讓你專注于更多令人興奮和有用的東西。
如果你是Java開發人員,那么也可以使用Groovy來實現這一點,但Groovy并未提供Python在API、庫、框架和數據科學、機器學習以及Web開發等領域的廣泛應用。
2、通過什么途徑學習的Python?
自學、培訓機構、學校里邊教授學習
3、Python和Java、PHP、C、C#、C++等其他語言的對比?
PHP
PHP即“超文本預處理器”,是一種通用開源腳本語言。PHP是在服務器端執行的腳本語言,與C語言類似,
是常用的網站編程語言。PHP獨特的語法混合了C、Java、Perl以及 PHP 自創的語法。利于學習,使用廣泛,主要適用于Web開發領域。
java
Java是一門面向對象編程語言,不僅吸收了C++語言的各種優點,還摒棄了C++里難以理解的多繼承、指針等概念,
因此Java語言具有功能強大和簡單易用兩個特征。Java語言作為靜態面向對象編程語言的代表,極好地實現了面向對象理論,
允許程序員以優雅的思維方式進行復雜的編程 [1] 。
Java具有簡單性、面向對象、分布式、健壯性、安全性、平臺獨立與可移植性、多線程、動態性等特點 [2] 。
Java可以編寫桌面應用程序、Web應用程序、分布式系統和嵌入式系統應用程序等
c
C語言是一門面向過程的、抽象化的通用程序設計語言,廣泛應用于底層開發。
C語言能以簡易的方式編譯、處理低級存儲器。C語言是僅產生少量的機器語言以及不需要任何運行環境支持便能運行的高效率程序設計語言。
盡管C語言提供了許多低級處理的功能,但仍然保持著跨平臺的特性,
以一個標準規格寫出的C語言程序可在包括類似嵌入式處理器以及超級計算機等作業平臺的許多計算機平臺上進行編譯。
c#
C#是微軟公司發布的一種面向對象的、運行于.NET Framework和.NET Core(完全開源,跨平臺)之上的高級程序設計語言。并定于在微軟職業開發者論壇(PDC)上登臺亮相。
C#是微軟公司研究員Anders Hejlsberg的最新成果。C#看起來與Java有著驚人的相似;它包括了諸如單一繼承、接口、與Java幾乎同樣的語法和編譯成中間代碼再運行的過程。
但是C#與Java有著明顯的不同,它借鑒了Delphi的一個特點,與COM(組件對象模型)是直接集成的,而且它是微軟公司 .NET windows網絡框架的主角。
C#是一種安全的、穩定的、簡單的、優雅的,由C和C++衍生出來的面向對象的編程語言。
它在繼承C和C++強大功能的同時去掉了一些它們的復雜特性(例如沒有宏以及不允許多重繼承)。
C#綜合了VB簡單的可視化操作和C++的高運行效率,以其強大的操作能力、優雅的語法風格、創新的語言特性和便捷的面向組件編程的支持成為.NET開發的首選語言。
C#是面向對象的編程語言。它使得程序員可以快速地編寫各種基于MICROSOFT .NET平臺的應用程序,MICROSOFT .NET提供了一系列的工具和服務來最大程度地開發利用計算與通訊領域。
C#使得C++程序員可以高效的開發程序,且因可調用由 C/C++ 編寫的本機原生函數,而絕不損失C/C++原有的強大的功能。
因為這種繼承關系,C#與C/C++具有極大的相似性,熟悉類似語言的開發者可以很快的轉向C#。
c++
C++是C語言的繼承,它既可以進行C語言的過程化程序設計,又可以進行以抽象數據類型為特點的基于對象的程序設計,
還可以進行以繼承和多態為特點的面向對象的程序設計。C++擅長面向對象程序設計的同時,
還可以進行基于過程的程序設計,因而C++就適應的問題規模而論,大小由之。
C++不僅擁有計算機高效運行的實用性特征,同時還致力于提高大規模程序的編程質量與程序設計語言的問題描述能力。
4、簡述解釋型和編譯型編程語言?
編譯型語言
使用專門的編譯器,針對特定的平臺,將高級語言源代碼一次性的編譯成可被該平臺硬件執行的機器碼,并包裝成該平臺所能識別的可執行性程序的格式。
特點
在編譯型語言寫的程序執行之前,需要一個專門的編譯過程,把源代碼編譯成機器語言的文件,如exe格式的文件,以后要再運行時,直接使用編譯結果即可,如直接運行exe文件。因為只需編譯一次,以后運行時不需要編譯,所以編譯型語言執行效率高。
總結
一次性的編譯成平臺相關的機器語言文件,運行時脫離開發環境,運行效率高;
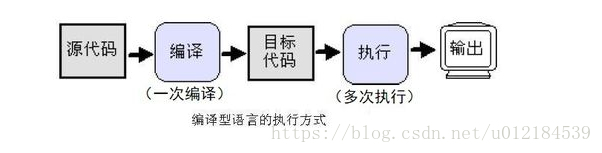
與特定平臺相關,一般無法移植到其他平臺;
現有的C、C++、Objective等都屬于編譯型語言。
解釋型語言
使用專門的解釋器對源程序逐行解釋成特定平臺的機器碼并立即執行。
特點
解釋型語言不需要事先編譯,其直接將源代碼解釋成機器碼并立即執行,所以只要某一平臺提供了相應的解釋器即可運行該程序。
總結
解釋型語言每次運行都需要將源代碼解釋稱機器碼并執行,效率較低;
只要平臺提供相應的解釋器,就可以運行源代碼,所以可以方便源程序移植;
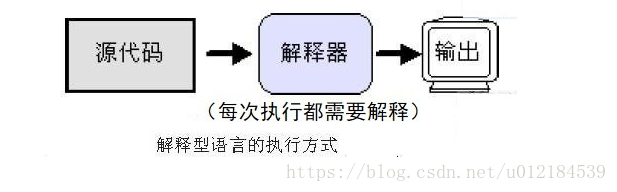
Python等屬于解釋型語言。
————————————————
版權聲明:本文為CSDN博主「雷建方」的原創文章,遵循CC 4.0 BY-SA版權協議,轉載請附上原文出處鏈接及本聲明。
原文鏈接:https://blog.csdn.net/u012184539/article/details/81348780
5、Python解釋器種類以及特點?
CPython
由C語言開發的 使用最廣的解釋器,在命名行下運行python,就是啟動CPython解釋器.
IPython
基于cpython之上的一個交互式計時器 交互方式增強 功能和cpython一樣
PyPy
目標是執行效率 采用JIT技術 對python代碼進行動態編譯,提高執行效率
JPython
運行在Java上的解釋器 直接把python代碼編譯成Java字節碼執行
IronPython
在微軟 .NET 平臺上的解釋器,把python編譯成. NET 的字節碼
6、位和字節的關系?
一個字節 = 八位
7、b、B、KB、MB、GB 的關系?
b 比特 位B ---字節KB ---千比特MB ---兆比特GB ---吉比特
1B = 8b (8個位) 一個字節 等于 8位
1 KB = 1024B
1MB = 1024KB
1GB = 1024MB
英文和數字占一個字節
中文占一個字符,也就是兩個字節
字符 不等于 字節。
字符(char)是 Java 中的一種基本數據類型,由 2 個字節組成,范圍從 0 開始,到 2^16-1。
字節是一種數據量的單位,一個字節等于 8 位。所有的數據所占空間都可以用字節數來衡量。例如一個字符占 2 個字節,一個 int 占 4 個字節,一個 double 占 8 個字節 等等。
1字符=2字節;1Byte=8bit
1k=2^10;b:位;B:字節1kb=1024 位1kB=1024 字節
8、請至少列舉5個 PEP8 規范(越多越好)
Python英文文檔 原文鏈接:link
大牛翻譯 原文鏈接:link
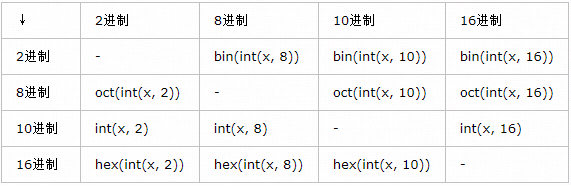
9、通過代碼實現如下轉換:
二進制轉換成十進制: v=“0b1111011”
print(int(v,2)) #123
十進制轉換成二進制: v = 18
print(bin(v)) #0b10010
八進制轉換成十進制: v = ‘011’
print(int(v,8)) #9
十進制轉換成八進制: v = 30
print(oct(v)) #0o36
十六進制轉換成十進制: v = ‘0x12’
print(int(v,16)) #18
十進制轉換成十六進制: v = 87
print(hex(v)) #0x57
10、請編寫一個函數實現將IP地址轉換成一個整數。
如 10.3.9.12 轉換規則為:
10 000010103 000000119 0000100112 00001100
再將以上二進制拼接起來計算十進制結果:00001010 00000011 00001001 00001100 = ?
#coding:utf-8
class Switch(object):def __init__(self, ip_str):self.ip_str = ip_strdef ten_switch_two(self, num):demo = list()while num > 0:ret = num % 2demo.append(str(ret))num = num // 2temp = "".join((list(reversed(demo))))head_zero = "0"*(8-len(temp))ret = head_zero + tempreturn retdef two_switch_ten(self, num):# 字符串轉列表num_list = list()for i in num:num_list.append(i)temp = 0s = len(num_list) - 1for i in num_list:temp += int(i) * 2 ** ss -= 1return tempdef run(self):# 1.切割字符串part_list = self.ip_str.split(".")# 2.循環取出每個數字轉成二進制數temp_str = ""for ip_part in part_list:temp_str += self.ten_switch_two(int(ip_part))ret = self.two_switch_ten(temp_str)print(ret)Switch("1.1.1.1").run()
11、python遞歸的最大層數?
Python的最大遞歸層數是可以設置的,默認的在window上的最大遞歸層數是 998。
可以通過sys.setrecursionlimit()進行設置,但是一般默認不會超過3925-3929這個范圍。
12、求結果:
v1 = 1 or 3 #1
v2 = 1 and 3 #3
v3 = 0 and 2 and 1 #0
v4 = 0 and 2 or 1 #1
v5 = 0 and 2 or 1 or 4 #1
v6 = 0 or False and 1 #Fslse
13、ascii、unicode、utf-8、gbk 區別?
ASCII碼使用一個字節編碼,所以它的范圍基本是只有英文字母、數字和一些特殊符號 ,只有256個字符。
在表示一個Unicode的字符時,通常會用“U+”然后緊接著一組十六進制的數字來表示這一個字符。在基本多文種平面e799bee5baa6e79fa5e98193e58685e5aeb931333337396265(英文為 Basic Multilingual Plane,簡寫 BMP。它又簡稱為“零號平面”, plane 0)里的所有字符,要用四位十六進制數(例如U+4AE0,共支持六萬多個字符);在零號平面以外的字符則需要使用五位或六位十六進制數了。舊版的Unicode標準使用相近的標記方法,但卻有些微的差異:在Unicode 3.0里使用“U-”然后緊接著八位數,而“U+”則必須隨后緊接著四位數。
Unicode能夠表示全世界所有的字節
GBK是只用來編碼漢字的,GBK全稱《漢字內碼擴展規范》,使用雙字節編碼。
UTF-8(8-bit Unicode Transformation Format)是一種針對Unicode的可變長度字符編碼,又稱萬國碼。由Ken Thompson于1992年創建。現在已經標準化為RFC 3629。UTF-8用1到6個字節編碼UNICODE字符。用在網頁上可以同一頁面顯示中文簡體繁體及其它語言(如英文,日文,韓文)。
14、字節碼和機器碼的區別?
字節碼
是一種包含執行程序、由一序列 op代碼/數據對 組成的二進制文件。
是一種中間碼,它比機器碼更抽象,需要直譯器轉譯后才能成為機器碼的中間代碼。
是編碼后的數值常量、引用、指令等構成的序列。
機器碼
是電腦的CPU可直接解讀的數據,可以直接執行,并且是執行速度最快的代碼。
轉換關系
通常是有編譯器將源碼編譯成字節碼,然后虛擬機器將字節碼轉譯為機器碼
使用
通常是跨平臺時使用,這樣能夠時代嗎很好的在其他平臺上運行。
15、三元運算規則以及應用場景?
三元運算符就是在賦值變量的時候,可以直接加判斷,然后賦值
三元運算符的功能與’if…else’流程語句一致,它在一行中書寫,代碼非常精煉,執行效率更高
格式:[on_true] if [expression] else [on_false]res = 值1 if 條件 else 值2舉例子:a,b,c = 1,2,6d = a if a > b else cprint(d)
16、列舉 Python2和Python3的區別?
鏈接:點擊我知道答案
17、用一行代碼實現數值交換:
a = 1
b = 2
a,b = b,a
print(a, b)
18、Python3和Python2中 int 和 long的區別?
int(符號整數):通常被稱為是整數或整數,沒有小數點的正或負整數;
long(長整數):無限大小的整數,這樣寫整數和一個大寫或小寫的L。
python2中有long類型
python3中沒有long類型,只有int類型
19、xrange和range的區別?
兩種用法介紹如下:
1.range([start], stop[, step])
返回等差數列。構建等差數列,起點是start,終點是stop,但不包含stop,公差是step。
start和step是可選項,沒給出start時,從0開始;沒給出step時,默認公差為1。
例如:
>>> range(10) #起點是0,終點是10,但是不包括10
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> range(1,10) #起點是1,終點是10,但是不包括10
[1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> range(1,10,2) #起點是1,終點是10,步長為2
[1, 3, 5, 7, 9]
>>> range(0,-10,-1) #起點是1,終點是10,步長為-1
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
>>> range(0,-10,1) #起點是0,終點是-10,終點為負數時,步長只能為負數,否則返回空
[]
>>> range(0) #起點是0,返回空列表
[]
>>> range(1,0) #起點大于終點,返回空列表
[]
2.xrange([start], stop[, step])
xrange與range類似,只是返回的是一個"xrange object"對象,而非數組list。
要生成很大的數字序列的時候,用xrange會比range性能優很多,因為不需要一上來就開辟一塊很大的內存空間。
例如:
>>> lst = xrange(1,10)
>>> lst
xrange(1, 10)
>>> type(lst)
<type 'xrange'>
>>> list(lst)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
區別如下:
1.range和xrange都是在循環中使用,輸出結果一樣。
2.range返回的是一個list對象,而xrange返回的是一個生成器對象(xrange object)。
3.xrange則不會直接生成一個list,而是每次調用返回其中的一個值,內存空間使用極少,因而性能非常好。
補充點:
#以下三種形式的range,輸出結果相同。
>>> lst = range(10)
>>> lst2 = list(range(10))
>>> lst3 = [x for x in range(10)]
>>> lst
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> lst2
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> lst3
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> lst == lst2 and lst2 == lst3
True
在使用Python3時,發現以前經常用的xrange沒有了,python3的range就是xrange
注意:Python 3.x已經去掉xrange,全部用range代替。
20、文件操作時:xreadlines和readlines的區別?
python3已經沒有這個xreadlines的方法了
這倆的區別類似于xrange和range,在使用的時候感覺不出來區別,但是二者返回值類型不一樣,帶有x的返回值是生成器,不帶的返回值是列表
21、列舉布爾值為False的常見值?
# 列舉布爾值是False的所有值print("1. ", bool(0))
print("2. ", bool(-0))
print("3. ", bool(None))
print("4. ", bool())
print("5. ", bool(False))
print("6. ", bool([]))
print("7. ", bool(()))
print("8. ", bool({}))
print("9. ", bool(0j))
print("10. ", bool(0.0))
22、字符串、列表、元組、字典每個常用的5個方法?
大神鏈接link
23、lambda表達式格式以及應用場景?
lambda表達式,通常是在需要一個函數,但是又不想費神去命名一個函數的場合下使用,也就是指匿名函數。
add = lambda x, y : x+yprint(add(1,2)) # 結果為3
應用在函數式編程中 應用在閉包中。
24、pass的作用?
空語句 do nothing保證格式完整保證語義完整
25、*arg和**kwarg作用
定義簡單的函數
首先我們可以定一個簡單的函數, 函數內部只考慮required_arg這一個形參(位置參數)
def exmaple(required_arg):print required_argexmaple("Hello, World!")>> Hello, World!
那么,如果我們調用函數式傳入了不止一個位置參數會出現什么情況?當然是會報錯!
exmaple("Hello, World!", "another string")>> TypeError: exmaple() takes exactly 1 argument (2 given)
定義函數時,使用*arg和kwarg
*arg和kwarg 可以幫助我們處理上面這種情況,允許我們在調用函數的時候傳入多個實參
def exmaple2(required_arg, *arg, **kwarg):if arg:print "arg: ", argif kwarg:print "kwarg: ", kwargexmaple2("Hi", 1, 2, 3, keyword1 = "bar", keyword2 = "foo")>> arg: (1, 2, 3)
>> kwarg: {'keyword2': 'foo', 'keyword1': 'bar'}
從上面的例子可以看到,當我傳入了更多實參的時候
*arg會把多出來的位置參數轉化為tuple
**kwarg會把關鍵字參數轉化為dict
再舉個例子,一個不設定參數個數的加法函數
def sum(*arg):res = 0for e in arg:res += ereturn resprint sum(1, 2, 3, 4)
print sum(1, 1)
>> 10
>> 2
當然,如果想控制關鍵字參數,可以單獨使用一個*,作為特殊分隔符號。限于Python 3,下面例子中限定了只能有兩個關鍵字參數,而且參數名為keyword1和keyword2
def person(required_arg, *, keyword1, keyword2):print(required_arg, keyword1, keyword2)person("Hi", keyword1="bar", keyword2="foo")
>> Hi bar foo
如果不傳入參數名keyword1和keyword2會報錯,因為都會看做位置參數!
person("Hi", "bar", "foo")>> TypeError: person() takes 1 positional argument but 3 were given
調用函數時使用*arg和**kwarg
直接上例子,跟上面的情況十分類似。反向思維。
def sum(a, b, c):return a + b + ca = [1, 2, 3]# the * unpack list a
print sum(*a)
>> 6
def sum(a, b, c):return a + b + ca = {'a': 1, 'b': 2, 'c': 3}# the ** unpack dict a
print sum(**a)
>> 6
作者:Jason_Yuan
鏈接:https://www.jianshu.com/p/e0d4705e8293
來源:簡書
著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請注明出處。
26、is和==的區別
在python中萬物即對象,所以is比較的是id值相同不相同,而==僅比較值。
對于值大小在-5~256之間的變量,python因為有內存池緩存機制,會對該值分配內存,而不是變量,所以只要是該值的變量都指向同一個內存,即id相同。
但是,==僅比較值大小
27、簡述Python的深淺拷貝以及應用場景?
深淺拷貝用法來自copy模塊。
導入模塊:import copy
淺拷貝:copy.copy
深拷貝:copy.deepcopy
對于 數字 和 字符串 而言,賦值、淺拷貝和深拷貝無意義,因為其永遠指向同一個內存地址。
字面理解:淺拷貝指僅僅拷貝數據集合的第一層數據,深拷貝指拷貝數據集合的所有層。所以對于只有一層的數據集合來說深淺拷貝的意義是一樣的,比如字符串,數字,還有僅僅一層的字典、列表、元祖等.
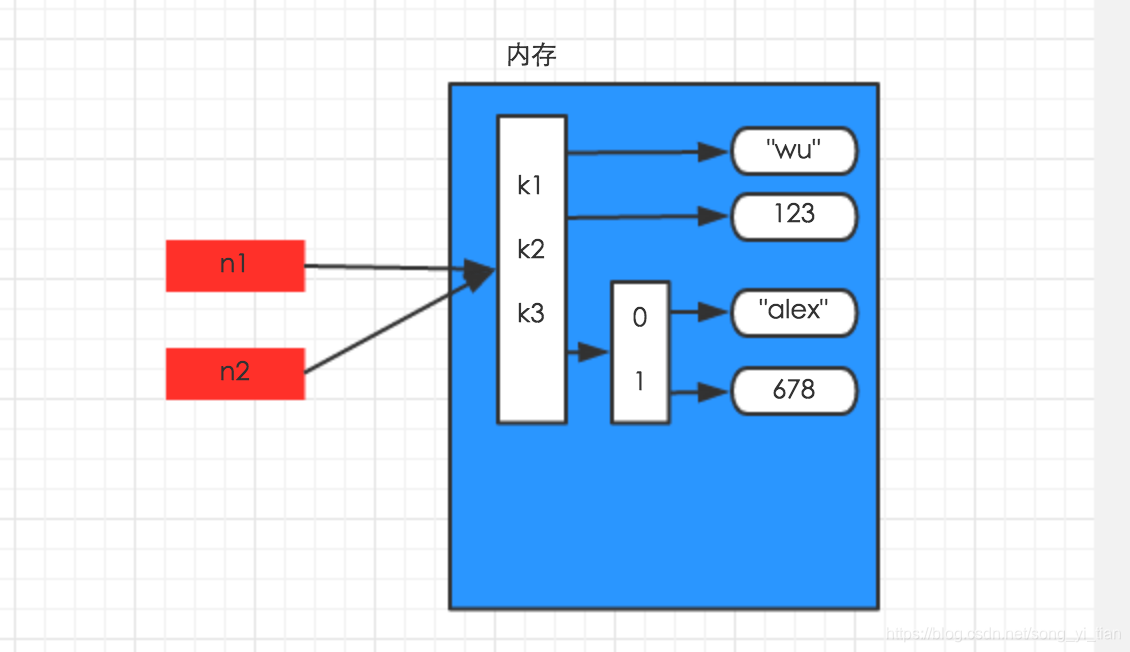
字典(列表)的深淺拷貝
賦值:
import copy
n1 = {‘k1’:‘wu’,‘k2’:123,‘k3’:[‘alex’,678]}
n2 = n1
淺拷貝:
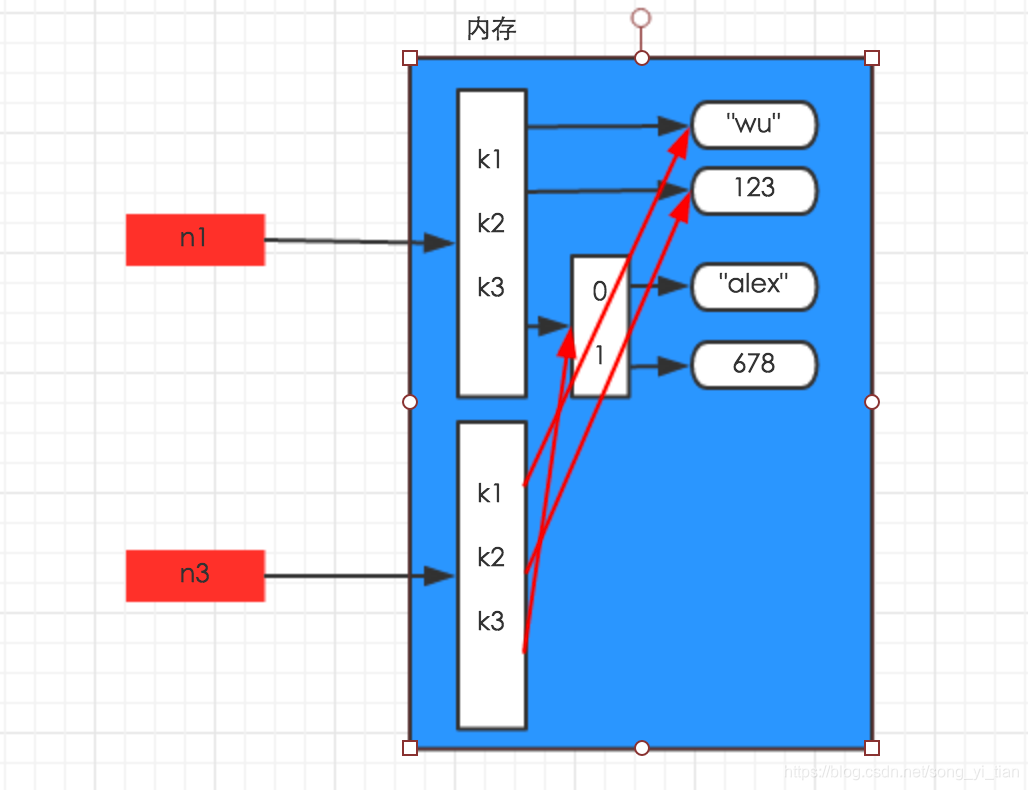
import copy
n1 = {‘k1’:‘wu’,‘k2’:123,‘k3’:[‘alex’,678]}
n3 = copy.copy(n1)
深拷貝:
import copy
n1 = {‘k1’:‘wu’,‘k2’:123,‘k3’:[‘alex’,678]}
n4 = copy.deepcopy(n1)
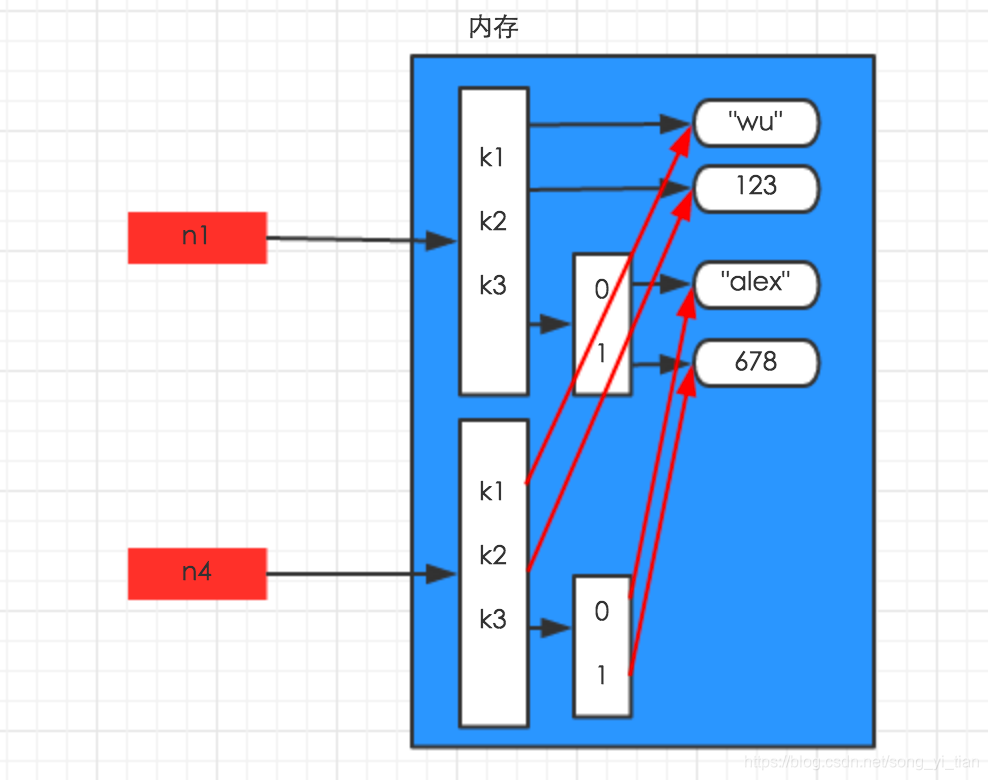
深拷貝的時候python將字典的所有數據在內存中新建了一份,所以如果你修改新的模版的時候老模版不會變。相反,在淺copy 的時候,python僅僅將最外層的內容在內存中新建了一份出來,字典第二層的列表并沒有在內存中新建,所以你修改了新模版,默認模版也被修改了。
注釋:搬運于 博客園 tank_jam
28、Python垃圾回收機制?
外部鏈接link
29、Python的可變類型和不可變類型?
可變類型 Vs 不可變類型
可變類型(mutable):列表,字典
不可變類型(unmutable):數字,字符串,元組
這里的可變不可變,是指內存中的那塊內容(value)是否可以被改變
30、求結果:
v = dict.fromkeys([‘k1’,‘k2’],[])
v[‘k1’].append(666)
print(v)
v[‘k1’] = 777
print(v)
Python 字典 fromkeys() 函數用于創建一個新字典,以序列 seq 中元素做字典的鍵,value 為字典所有鍵對應的初始值。
#運行結果
{'k1': [666], 'k2': [666]}
{'k1': 777, 'k2': [666]}
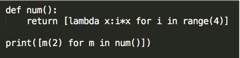
31、求結果:
[6, 6, 6, 6]
#代碼示意:
[lambda x:x*i,lambda x:x*i,lambda x:x*i,lambda x:x*i]
def num():lst = []for i in range(4):def foo(x):return x*ilst.append(foo)return lst# lst.append(lambda x:x*i)
g=num()
print(g) # [4個內存地址]
lst1=[]
for m in g:lst1.append(m(2))
print(lst1)
lambda嵌套
在外層嵌套被調用的時候,嵌套在內的lambda能夠獲取到在外層函數作用域中變量名x的值。
注:
lambda是一個表達式,而不是語句。所以lambda能夠出現在Python語法不允許def出現的地方。lambda的主體是一個單獨的表達式,而不是一個代碼塊。lambda是一個表達式,而不是語句
32、列舉常見的內置函數?
鏈接點一點 你就知道
33、filter、map、reduce的作用?
1. map
(1)map(function, iterable,……) ,第一個參數是一個函數,第二個參數是一個可迭代的對象,第一個參數function以參數序列中的每一個元素調用function函數,返回包含每次function函數返回值的一個迭代器。

運行結果如下:

在Python2中返回的是一個列表,但在Python3中返回的是一個迭代器。上述程序是在Python3中執行的。
其實上述程序還可以這樣寫

或者
*
(2)map中有多個可迭代對象

返回結果

2. filter
filter(function, iterable) filter函數用于過濾序列,過濾掉不符合條件的元素,返回由符合條件元素組成的新列表。該接收兩個參數,第一個為函數,第二個為序列,序列的每個元素作為參數傳遞給函數進行判,然后返回 True 或 False,最后將返回 True 的元素放到新列表中。
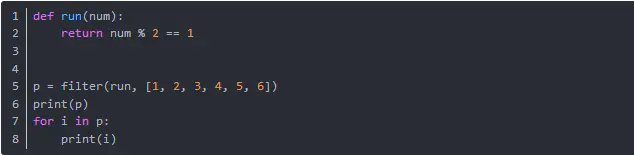
運行結果是

下面是用lambda函數寫的

當把lambda表達式的返回結果改為零時

運行結果如下

3. reduce
在Python3中沒有reduce內置函數,但在functools中有reduce類,reduce調用的格式:reduce(function, iterable),reduce的作用是將傳給function(有兩個參數 )對集合中的第1、2個元素進行操作,得到的結果再與第三個元素用function函數進行運算……
下面看一個程序

運行結果如下

作者:空口言_1d2e
鏈接:https://www.jianshu.com/p/5ef9dd70c3ab
來源:簡書
著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請注明出處。
34、一行代碼實現9*9乘法表
print ('\n'.join([' '.join(['%s*%s=%-2s' % (y,x,x*y) for y in range(1,x+1)]) for x in range(1,10)]))1*1=1
1*2=2 2*2=4
1*3=3 2*3=6 3*3=9
1*4=4 2*4=8 3*4=12 4*4=16
1*5=5 2*5=10 3*5=15 4*5=20 5*5=25
1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
35、如何安裝第三方模塊?以及用過哪些第三方模塊?
通過pip安裝第三方包很簡單,比如我要安裝pandas這個第三方模塊,我從PyPI查詢到這個模塊后,官網頁面上就提供了安裝語句:
pip install pandas
但是,但是國內的網絡環境你也知道,總是有那種或者這種的問題,導致在線安裝速度很慢;所以呢,國內就有很多PyPI這個源的鏡像,有名的就有清華大學的、豆瓣網的;我們可以設置通過這些國內的鏡像來在線安裝第三方模塊。比如我要從清華大學提供的鏡像源來安裝pandas:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
當然了,每次輸入這么一長串地址很麻煩,所以我們也可以把清華大學的鏡像源設置為默認的安裝源:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
這樣后續的安裝就都會默認從清華大學鏡像源去下載第三方模塊。以下是國內比較好用的一些鏡像源:
豆瓣:https://pypi.douban.com/simple/
阿里云:https://mirrors.aliyun.com/pypi/simple/
中國科技大學:https://pypi.mirrors.ustc.edu.cn/simple/
清華大學:https://pypi.tuna.tsinghua.edu.cn/simple/
36、至少列舉8個常用模塊都有哪些?
os模塊,路徑
re模塊,正則表達式
sys模塊,標準輸入輸出
math模塊,數學公式
json模塊,字符串與其他數據類型轉換;pickle模塊,序列化
random模塊,生成隨機數
time模塊,時間模塊
request模型,HTTP請求庫
pyqt、pymql、pygame、Django、Flask、opencv-python、pillow-python、Scrappy……
37、re的match和search區別?
1、match()函數只檢測RE是不是在string的開始位置匹配,search()會掃描整個string查找匹配;
2、也就是說match()只有在0位置匹配成功的話才有返回,如果不是開始位置匹配成功的話,match()就返回none。
例如:
import re
print(re.match('super', 'superstition').span()) # (0,5)
print(re.match('super', 'insuperable')) # None
3、search()會掃描整個字符串并返回第一個成功的匹配:
例如:
import re
print(re.search('super', 'superstition').span()) #(0,5)
print(re.search('super', 'insuperable')) # <_sre.SRE_Match object; span=(2, 7), match='super'>
4、其中span函數定義如下,返回位置信息:
span([group]):
返回(start(group), end(group))。
數據類型是:<class ‘tuple’>
38、什么是正則的貪婪匹配?
1.噠噠噠噠噠噠多多多 正則表達式的貪婪與非貪婪匹配
如:String str=“abcaxc”;
Patter p=“ab*c”;
貪婪匹配:正則表達式一般趨向于最大長度匹配,也就是所謂的貪婪匹配。如上面使用模式p匹配字符串str,結果就是匹配到:abcaxc(ab*c)。
非貪婪匹配:就是匹配到結果就好,就少的匹配字符。如上面使用模式p匹配字符串str,結果就是匹配到:abc(ab*c)。
2.編程中如何區分兩種模式
默認是貪婪模式;在量詞后面直接加上一個問號?就是非貪婪模式。
量詞:{m,n}:m到n個
*:任意多個
+:一個到多個
?:0或一個
. :除\n之外的任意字符
39、求結果:a. [ i % 2 for i in range(10) ] b. ( i % 2 for i in range(10) ) (Python中列表生成式和生成器的區別)
[0, 1, 0, 1, 0, 1, 0, 1, 0, 1]<generator object <genexpr> at 0x0000016CD8EFE8E0>
列表生成式語法:
[xx for x in range(0,10)] //列表生成式,這里是中括號
//結果復 [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
(xx for x in range(0,10)) //生成器, 這里是小括號
//結果 <generator object at 0x7f0b072e6140>
二者的區別很明顯:
一個直接返回了表達式的結果列表, 而另一個是一個對象,該對象包含了對表達式結果的計算引用, 通過循環可以直接輸出
g = (x*x for x in range(0,10))
for n in g:
print n
結果
0
1
4
9
16
25
36
49
64
81
當表達式的結果數量較少的時候, 使用列表生成式制還好, 一旦數量級過大, 那么列表生成式就會占用很大的內存,
而生成器并不是立即把結果寫入內存, 而是保存的一種計算方式, 通過不斷的獲取, 可以獲取到相應的位置的值,所以占用的內存僅僅是zd對計算對象的保存
40、求結果:a. 1 or 2 b. 1 and 2 c. 1 < (2==2) d. 1 < 2 == 2
12FalseTrue實際上這涉及到了Python的 鏈式對比(ChainedComparisons)。在其他語言中,有一個變量 x,如果要判斷x是否大于1,小于5,可能需要這樣寫代碼:
if (x > 1 and x < 5)
但是在Python中,可以這樣寫代碼:
if 1 < x < 5
Python能夠正確處理這個鏈式對比的邏輯。回到最開始的問題上, 等于符號和 <小于符號,本質沒有什么區別。所以實際上 22>1也是一個鏈式對比的式子,它相當于 2==2and2>1。此時,這個式子就等價于 TrueandTrue。所以返回的結果為True。
注:True相當于1,False相當于0
41、def func(a,b=[]) 這種寫法有什么坑?
def func(a,b = []):b.append(1)print(a,b)func(a=2)
func(2)
func(2)'''2 [1]2 [1, 1]2 [1, 1, 1]函數的默認參數是一個list 當第一次執行的時候實例化了一個list 第二次執行還是用第一次執行的時候實例化的地址存儲 所以三次執行的結果就是 [1, 1, 1] 想每次執行只輸出[1] ,默認參數應該設置為None
'''
42、如何實現 “1,2,3” 變成 [‘1’,’2’,’3’] ?
a = '1,2,3'
a1 = a.split(',')
list = []
for n in a1:list.append(n)
print(list)
43、如何實現[‘1’,’2’,’3’]變成[1,2,3] ?
a = ['1','2','3']
list = []
for i in a:list.append(int(i))print(list)
44、比較:a = [1,2,3] 和 b = [(1),(2),(3) ] 以及 b = [(1,),(2,),(3,) ] 的區別?
a = [1,2,3]
b = [(1),(2),(3) ]
c = [(1,),(2,),(3,) ]
print(f'他們分別都是列表:{a},{b},{c}')
print(f'他們的類型都是:{type(a)},{type(b)},{type(c)}')
print(f'其中元素類型為:{[type(x) for x in a]},{[type(x) for x in b]},{[type(x) for x in c]}')他們分別都是列表:[1, 2, 3],[1, 2, 3],[(1,), (2,), (3,)]
他們的類型都是:<class 'list'>,<class 'list'>,<class 'list'>
其中元素類型為:[<class 'int'>, <class 'int'>, <class 'int'>],[<class 'int'>, <class 'int'>, <class 'int'>],[<class 'tuple'>, <class 'tuple'>, <class 'tuple'>]
45、如何用一行代碼生成[1,4,9,16,25,36,49,64,81,100] ?
print([i*i for i in range(1,11)])
46、一行代碼實現刪除列表中重復的值 ?
print(set([1, 4, 9, 16, 25, 36, 49, 64, 81, 100,100]))
47、如何在函數中設置一個全局變量 ?
python中的global語句是被用來聲明全局變量的。
a = 10
def function():global aa += 1return a
function()
print(x)
#注解:如果注釋掉global 代碼
#會報錯:UnboundLocalError: local variable 'a' referenced before assignment
48、logging模塊的作用?以及應用場景?
logging
模塊定義的函數和類為應用程序和庫的開發實現了一個靈活的事件日志系統
作用:可以了解程序運行情況,是否正常
在程序的出現故障快速定位出錯地方及故障分析
49、請用代碼簡答實現stack 。
Stack() 創建一個新的空棧
push(item) 添加一個新的元素item到棧頂
pop() 彈出棧頂元素
peek() 返回棧頂元素
is_empty() 判斷棧是否為空
size() 返回棧的元素個數
實現一個棧stack,后進先出
class Stack:def __init__(self):self.items = []def is_empty(self):# 判斷是否為空return self.items == []def push(self,item):# 加入元素self.items.append(item)def pop(self):# 彈出元素return self.items.pop()def peek(self):# 返回棧頂元素return self.items[len(self.items)-1]def size(self):# 返回棧的大小return len(self.items)if __name__ == "__main__":stack = Stack()stack.push("H")stack.push("E")stack.push("L")print(stack.size()) # 3print(stack.peek()) # L print(stack.pop()) # Lprint(stack.pop()) # Eprint(stack.pop()) # H
50、常用字符串格式化哪幾種?
1.占位符%
%d 表示那個位置是整數;%f 表示浮點數;%s 表示字符串。
print('Hello,%s' % 'Python')
print('Hello,%d%s%.2f' % (666, 'Python', 9.99)) # 打印:Hello,666Python10.00
2.format
print('{k} is {v}'.format(k='python', v='easy')) # 通過關鍵字
print('{0} is {1}'.format('python', 'easy')) # 通過關鍵字
51、簡述 生成器、迭代器、可迭代對象 以及應用場景?
可以參考
簡書鏈接參考:點擊進入
CSMN 生成器和迭代器區別:點擊進入
52、用Python實現一個二分查找的函數。
data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35]def binary_search(dataset,find_num):if len(dataset) > 1:mid = int(len(dataset) / 2)if dataset[mid] == find_num: # find itprint("找到數字", dataset[mid])elif dataset[mid] > find_num: # 找的數在mid左面print("\033[31;1m找的數在mid[%s]左面\033[0m" % dataset[mid])return binary_search(dataset[0:mid], find_num)else: # 找的數在mid右面print("\033[32;1m找的數在mid[%s]右面\033[0m" % dataset[mid])return binary_search(dataset[mid + 1:], find_num)else:if dataset[0] == find_num: # find itprint("找到數字啦", dataset[0])else:print("沒的分了,要找的數字[%s]不在列表里" % find_num)binary_search(data,20)
53、談談你對閉包的理解?
如果在一個函數的內部定義了另一個函數,外部的我們叫他外函數,內部的我們叫他內函數。
閉包:
在一個外函數中定義了一個內函數,內函數里運用了外函數的臨時變量,并且外函數的返回值是內函數的引用。這樣就構成了一個閉包。
一般情況下,在我們認知當中,如果一個函數結束,函數的內部所有東西都會釋放掉,還給內存,局部變量都會消失。但是閉包是一種特殊情況,如果外函數在結束的時候發現有自己的臨時變量將來會在內部函數中用到,就把這個臨時變量綁定給了內部函數,然后自己再結束。
# 閉包函數的實例
# outer是外部函數 a和b都是外函數的臨時變量
def outer(a):b = 10# inner是內函數def inner():# 在內函數中 用到了外函數的臨時變量print(a + b)# 外函數的返回值是內函數的引用return innerif __name__ == '__main__':# 在這里我們調用外函數傳入參數5# 此時外函數兩個臨時變量 a是5 b是10 ,并創建了內函數,然后把內函數的引用返回存給了demo# 外函數結束的時候發現內部函數將會用到自己的臨時變量,這兩個臨時變量就不會釋放,會綁定給這個內部函數demo = outer(5)# 我們調用內部函數,看一看內部函數是不是能使用外部函數的臨時變量# demo存了外函數的返回值,也就是inner函數的引用,這里相當于執行inner函數demo() # 15demo2 = outer(7)demo2() # 17
閉包有啥用??!!
3.1裝飾器!!!裝飾器是做什么的??其中一個應用就是,我們工作中寫了一個登錄功能,我們想統計這個功能執行花了多長時間,我們可以用裝飾器裝飾這個登錄模塊,裝飾器幫我們完成登錄函數執行之前和之后取時間。
3.2面向對象!!!經歷了上面的分析,我們發現外函數的臨時變量送給了內函數。大家回想一下類對象的情況,對象有好多類似的屬性和方法,所以我們創建類,用類創建出來的對象都具有相同的屬性方法。閉包也是實現面向對象的方法之一。在python當中雖然我們不這樣用,在其他編程語言入比如avaScript中,經常用閉包來實現面向對象編程
3.3實現單例模式!! 其實這也是裝飾器的應用。單例模式畢竟比較高大,需要有一定項目經驗才能理解單例模式到底是干啥用的,我們就不探討了。
————————————————[搬運于]
原文鏈接:https://blog.csdn.net/sinolover/article/details/104254502
54、os和sys模塊的作用?
os與sys模塊的官方解釋如下:
os:這個模塊提供了一種方便的使用操作系統函數的方法。
sys:這個模塊可供訪問由解釋器使用或維護的變量和與解釋器進行交互的函數。
總結:os模塊負責程序與操作系統的交互,提供了訪問操作系統底層的接口;sys模塊負責程序與python解釋器的交互,提供了一系列的函數和變量,用于操控python的運行時環境。
os 常用方法:
os.remove(‘path/filename’) 刪除文件
os.rename(oldname, newname) 重命名文件
os.walk() 生成目錄樹下的所有文件名
os.chdir(‘dirname’) 改變目錄
os.mkdir/makedirs(‘dirname’)創建目錄/多層目錄
os.rmdir/removedirs(‘dirname’) 刪除目錄/多層目錄
os.listdir(‘dirname’) 列出指定目錄的文件
os.getcwd() 取得當前工作目錄
os.chmod() 改變目錄權限
os.path.basename(‘path/filename’) 去掉目錄路徑,返回文件名
os.path.dirname(‘path/filename’) 去掉文件名,返回目錄路徑
os.path.join(path1[,path2[,…]]) 將分離的各部分組合成一個路徑名
os.path.split(‘path’) 返回( dirname(), basename())元組
os.path.splitext() 返回 (filename, extension) 元組
os.path.getatime\ctime\mtime 分別返回最近訪問、創建、修改時間
os.path.getsize() 返回文件大小
os.path.exists() 是否存在
os.path.isabs() 是否為絕對路徑
os.path.isdir() 是否為目錄
os.path.isfile() 是否為文件
sys 常用方法:
sys.argv 命令行參數List,第一個元素是程序本身路徑
sys.modules.keys() 返回所有已經導入的模塊列表
sys.exc_info() 獲取當前正在處理的異常類,exc_type、exc_value、exc_traceback當前處理的異常詳細信息
sys.exit(n) 退出程序,正常退出時exit(0)
sys.hexversion 獲取Python解釋程序的版本值,16進制格式如:0x020403F0
sys.version 獲取Python解釋程序的版本信息
sys.maxint 最大的Int值
sys.maxunicode 最大的Unicode值
sys.modules 返回系統導入的模塊字段,key是模塊名,value是模塊
sys.path 返回模塊的搜索路徑,初始化時使用PYTHONPATH環境變量的值
sys.platform 返回操作系統平臺名稱
sys.stdout 標準輸出
sys.stdin 標準輸入
sys.stderr 錯誤輸出
sys.exc_clear() 用來清除當前線程所出現的當前的或最近的錯誤信息
sys.exec_prefix 返回平臺獨立的python文件安裝的位置
sys.byteorder 本地字節規則的指示器,big-endian平臺的值是’big’,little-endian平臺的值是’little’
sys.copyright 記錄python版權相關的東西
sys.api_version 解釋器的C的API版本
55、如何生成一個隨機數?
# 導入 random(隨機數) 模塊
import randomprint(random.randint(0, 9))
56、如何使用python刪除一個文件?
os.remove(path)
刪除文件 path. 如果path是一個目錄, 拋出 OSError錯誤。如果要刪除目錄,請使用rmdir().
57、談談你對面向對象的理解?
面向過程:的程序設計的核心是過程(流水線式思維),過程即解決問題的步驟,面向過程的設計就好比精心設計好一條流水線,考慮周全什么時候處理什么東西。
優點是:極大的降低了寫程序的復雜度,只需要順著要執行的步驟,堆疊代碼即可。
缺點是:一套流水線或者流程就是用來解決一個問題,代碼牽一發而動全身。
應用場景:一旦完成基本很少改變的場景,著名的例子有Linux內核,git,以及Apache HTTP Server等。
面向對象:的程序設計的
優點是:解決了程序的擴展性。對某一個對象單獨修改,會立刻反映到整個體系中,如對游戲中一個人物參數的特征和技能修改都很容易。
缺點:可控性差,無法向面向過程的程序設計流水線式的可以很精準的預測問題的處理流程與結果,面向對象的程序一旦開始就由對象之間的交互解決問題,即便是上帝也無法預測最終結果。于是我們經常看到一個游戲人某一參數的修改極有可能導致陰霸的技能出現,一刀砍死3個人,這個游戲就失去平衡。
應用場景:需求經常變化的軟件,一般需求的變化都集中在用戶層,互聯網應用,企業內部軟件,游戲等都是面向對象的程序設計大顯身手的好地方。
58、Python面向對象中的繼承有什么特點?
減少代碼和靈活制定新類
子類具有父類的屬性和方法
子類不能繼承父類的私有屬性/方法
子類可以添加新的方法
子類可以修改父類的方法
59、面向對象深度優先和廣度優先是什么?
Python的類可以繼承多個類,Python的類如果繼承了多個類,那么其尋找方法的方式有兩種:
1、當類是經典類時,多繼承情況下,會按照深度優先方式查找 ;
2、當類是新式類時,多繼承情況下,會按照廣度優先方式查找 。
簡單點說就是:經典類是縱向查找(深度優先),新式類是橫向查找(廣度優先)
經典類和新式類的區別就是,在聲明類的時候,新式類需要加上object關鍵字。
在python3中默認全是新式類
60、面向對象中super的作用?
什么是super?
super() 函數是用于調用父類(超類)的一個方法。
super 是用來解決多重繼承問題的,直接用類名調用父類方法在使用單繼承的時候沒問題,但是如果使用多繼承,會涉及到查找順序(MRO)、重復調用(鉆石繼承)等種種問題。
MRO 就是類的方法解析順序表, 其實也就是繼承父類方法時的順序表。
語法
以下是 super() 方法的語法:
super(type[, object-or-type])
參數
·type -- 類。·object-or-type -- 類,一般是 self
Python3.x 和 Python2.x 的一個區別是: Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx :
Python3.x 實例:
class A:pass
class B(A):def add(self, x):super().add(x)
Python2.x 實例:class A(object): # Python2.x 記得繼承 objectpass
class B(A):def add(self, x):super(B, self).add(x)
具體應用示例:
舉個例子
class Foo: def bar(self, message): print(message)
>>> Foo().bar("Hello, Python.")
Hello, Python.
當存在繼承關系的時候,有時候需要在子類中調用父類的方法,此時最簡單的方法是把對象調用轉換成類調用,需要注意的是這時self參數需要顯式傳遞,例如:
class FooParent: def bar(self, message): print(message)
class FooChild(FooParent): def bar(self, message): FooParent.bar(self, message)
>>> FooChild().bar("Hello, Python.")
Hello, Python.
這樣做有一些缺點,比如說如果修改了父類名稱,那么在子類中會涉及多處修改,另外,Python是允許多繼承的語言,如上所示的方法在多繼承時就需要重復寫多次,顯得累贅。為了解決這些問題,Python引入了super()機制,例子代碼如下:
class FooParent: def bar(self, message): print(message)
class FooChild(FooParent): def bar(self, message): super(FooChild, self).bar(message) >>> FooChild().bar("Hello, Python.")
Hello, Python
表面上看 super(FooChild, self).bar(message)方法和FooParent.bar(self, message)方法的結果是一致的,實際上這兩種方法的內部處理機制大大不同,當涉及多繼承情況時,就會表現出明顯的差異來,直接給例子:
代碼一:
class A: def __init__(self): print("Enter A") print("Leave A")
class B(A): def __init__(self): print("Enter B") A.__init__(self) print("Leave B")
class C(A): def __init__(self): print("Enter C") A.__init__(self) print("Leave C")
class D(A): def __init__(self): print("Enter D") A.__init__(self) print("Leave D")
class E(B, C, D): def __init__(self): print("Enter E") B.__init__(self) C.__init__(self) D.__init__(self) print("Leave E")
E()
結果為:Enter E
Enter B
Enter A
Leave A
Leave B
Enter C
Enter A
Leave A
Leave C
Enter D
Enter A
Leave A
Leave D
Leave E
執行順序很好理解,唯一需要注意的是公共父類A被執行了多次。
代碼二:
class A: def __init__(self): print("Enter A") print("Leave A")
class B(A): def __init__(self): print("Enter B") super(B, self).__init__() print("Leave B")
class C(A): def __init__(self): print("Enter C") super(C, self).__init__() print("Leave C")
class D(A): def __init__(self): print("Enter D") super(D, self).__init__() print("Leave D")
class E(B, C, D): def __init__(self): print("Enter E") super(E, self).__init__() print("Leave E")
E()
結果:
Enter E
Enter B
Enter C
Enter D
Enter A
Leave A
Leave D
Leave C
Leave B
Leave E
在super機制里可以保證公共父類僅被執行一次,至于執行的順序,是按照MRO(Method Resolution Order):方法解析順序 進行的。
轉載于:https://www.cnblogs.com/zhuifeng-mayi/p/9221562.html
MRO 參考鏈接:點擊進入
61、是否使用過functools中的函數?其作用是什么?
參考鏈接:點擊進入
1、偏函數:from functools import partial
用于其他進制的字符串與十進制數據之間的轉換
import functoolsdef transform(params):foo = functools.partial(int,base=2)print(foo(params))
transform('1000000') # 64
transform('100000') # 32
2、用于修復裝飾器
import functoolsdef deco(func):@functools.wraps(func) # 加在最內層函數正上方def wrapper(*args, **kwargs):return func(*args, **kwargs)return wrapper@deco
def index():'''哈哈哈哈'''x = 10print('from index')print(index.__name__)
print(index.__doc__)# 加@functools.wraps
# index
# 哈哈哈哈# 不加@functools.wraps
# wrapper
# None
即:用來保證被裝飾函數在使用裝飾器時不改變自身的函數名和應有的屬性,
避免被別人發現該函數是被裝飾器裝飾過的。
__doc__為文檔字符串,文檔字符串寫在Python文件的第一行,三個引號包含起來的字符串。
為什么要寫文檔字符串?
因為規范的書寫文檔字符串可以通過sphinx等工具自動生成文檔。
文檔字符串的風格有很多。
Plain
Epytext
reStucturedText
Numpy
Google
我們可以在pycharm上進行自定義設置默認的文檔字符串風格。暫時推薦reStructuredText吧,緊湊,sphinx御用
62、列舉面向對象中帶雙下劃線的特殊方法,如:new、init
new 在實例化對象時觸發,即控制著對象的創建
init 在對象創建成功后觸發,完成對象屬性的初始化
call 在調用對象時觸發,也就是對象()時觸發
setattr 在給對象賦值時觸發,對象的屬性若不存在則先創建
getattr 在對象.屬性時觸發,該屬性必須不存在
mro 打印當前類的繼承順序
dict 打印出當前操作對象名稱空間的屬性和值
str 在打印對象時,觸發,執行內部的代碼
doc 類的文檔字符串
63、如何判斷是函數還是方法?
二者都是解決問題的實現功能
函數:通過函數名直接調用
方法:通過附屬者的點語法去調用
變量:通過變量名訪問變量值
屬性:通過附屬者.語法去調用
64、靜態方法和類方法區別?
@classmethod
類方法:可以被類與對象調用的方法,第一個參數一定是當前類本身,對象調用的時候,本質上還是通過類去調用該方法的,可以通過id去證明。id(cls)
實例方法就是普通的方法,只是參數列表里的參數不會出現self和cls
@staticmethod
靜態方法:直接通過類|實例.靜態方法調用。被該方法修飾的函數,不需要self參數和cls參數,使用的方法和直接調用函數一樣
邏輯上來說,實例方法類本身和其對象都可以調用,
類方法是專屬于類的
靜方法可以被類和對象調用,
類方法、靜態方法 在被類直接調用時,沒有經過實例化的過程,因此可以減少內存資源的占用。
65、列舉面向對象中的特殊成員以及應用場景
參考鏈接:點解進入
66、1、2、3、4、5 能組成多少個互不相同且無重復的三位數
#for循環遍歷
list = []
for i in range(1,6):for j in range(1,6):for k in range(1,6):if i != j and i != k and j != k:li = [i ,j ,k]list.append(li)print(len(list)) #60
67、什么是反射?以及應用場景?
python的反射,它的核心本質其實就是利用字符串的形式去對象(模塊)中操作(查找/獲取/刪除/添加)成員,一種基于字符串的事件驅動!
如何利用字符串驅動不同的事件,比如導入模塊、調用函數等等,這些都是python的反射機制,是一種編程方法、設計模式的體現,凝聚了高內聚、松耦合的編程思想,不能簡單的用執行字符串來代替。詳細鏈接:點擊進入
68、metaclass作用?以及應用場景?
metaclass用來指定類是由誰創建的。
類的metaclass 默認是type。我們也可以指定類的metaclass值。在python3中
class MyType(type):def __call__(self, *args, **kwargs):return 'MyType'class Foo(object, metaclass=MyType):def __init__(self):return 'init'def __new__(cls, *args, **kwargs):return cls.__init__(cls)def __call__(self, *args, **kwargs):return 'call'obj = Foo()
print(obj) # MyType
69、用盡量多的方法實現單例模式。
單例概念:單例模式是一種常用的軟件設計模式。在它的核心結構中只包含一個被稱為單例類的特殊類。通過單例模式可以保證系統中一個類只有一個實例而且該實例易于外界訪問,從而方便對實例個數的控制并節約系統資源。如果希望在系統中某個類的對象只能存在一個,單例模式是最好的解決方案。
單例模式的要點有三個:一是某個類只能有一個實例;二是它必須自行創建這個實例;三是它必須自行向整個系統提供這個實例。
從具體實現角度來說,就是以下三點:一是單例模式的類只提供私有的構造函數,二是類定義中含有一個該類的靜態私有對象,三是該類提供了一個靜態的共有函數用于創建或獲取它本身的靜態私有對象。
講解詳情:點擊進入
70、裝飾器的寫法以及應用場景。
#裝飾器的寫法:
def wrapper(func):def inner(*args,**kwargs):'被裝飾之前的操作'ret = func(*args,**kwargs)'被裝飾之后的操作'return retreturn inner
裝飾器的應用場景
1,引入日志
2,函數執行時間統計
3,執行函數前預備處理
4,執行函數后清理功能
5,權限校驗等場景
6,緩存
7,事務處理
PS: Django在1.7版本之后,官方建議,中間件的寫法也采用裝飾器的寫法
詳見:點擊進入
71、異常處理寫法以及如何主動拋出異常(應用場景)
異常處理的常規寫法:try:執行的主體函數except Exception as e:print(str(e))主動拋出異常:raise TypeError('出現了不可思議的異常')#TypeError可以是任意的錯誤類型
72、什么是面向對象的MRO
Python是支持面向對象編程的,同時也是支持多重繼承的。
而支持多重繼承,正是Python的方法解析順序(Method Resoluthion Order, 或MRO)問題出現的原因所在。
MRO 參考鏈接:點擊進入
73、isinstance作用以及應用場景?
isinstance作用:來判斷一個對象是否是一個已知的類型;
其第一個參數(object)為對象,第二個參數為類型名(int…)或類型名的一個列表((int,list,float)是一個列表)。其返回值為布爾型(True or flase)。
若對象的類型與參數二的類型相同則返回True。若參數二為一個元組,則若對象類型與元組中類型名之一相同即返回True。
簡單來說就是判斷object是否與第二個參數的類型相同,舉例如下:
# -*- coding: utf-8 -*-
p = '123'
print "1.",isinstance(p,str)#判斷P是否是字符串類型
a = "中國"
print isinstance(a,unicode) #判斷a是否是Unicode編碼
print isinstance(a,(unicode,str))#判斷a所屬類型是否包含在元組中
list1 = [1,2,3,4,5]
print isinstance(list1,list)#判斷list1是否是列表的類型
74、寫代碼并實現:
Given an array of integers, return indices of the two numbers such that they add up to a specific target.You may assume that each input wouldhave exactly one solution, and you may not use the same element twice.(給定一個整數數組,返回兩個數字的索引,使它們加起來等于一個特定的目標。您可以假設每個輸入都會只有一個解決方案,并且不能兩次使用相同的元素。)
Example:
Given nums = [2, 7, 11, 15], target = 9,
Because nums[0] + nums[1] = 2 + 7 = 9,
return [0, 1]
#方法一
nums = [2, 7, 11, 15]
target = 9def twosum(array,target):newarray=list(enumerate(array))newarray.sort(key=lambda x:x[1])i=0j=len(newarray)-1while i<j:sumtwo=newarray[i][1]+newarray[j][1]if sumtwo>target:j-=1elif sumtwo<target:i+=1elif sumtwo==target:index1,index2=newarray[i][0]+1,newarray[j][0]+1print('index=%d, index2=%d'%(index1,index2))return index1,index2
twosum(nums,target)
#方法二
nums = [2, 7, 11, 15]
target = 9def twosum(array,target):for j in range(len(nums)):num1 = nums[j]for k in range(len(nums)):num2 = nums[k]if num1 + num2 == target and j != k:print("兩個數的下標是{},{}".format(j,k))twosum(nums,target)
75、json序列化時,可以處理的數據類型有哪些?如何定制支持datetime類型?
JSON(JavaScript Object Notation)是用于Web上數據交換的最廣泛使用的數據格式。JSON是一種基于輕量級文本的數據交換格式,它完全獨立于語言。它基于JavaScript編程語言的一個子集,易于理解和生成。
JSON主要支持6種數據類型:
● 字符串(String)
● Number
● Boolean
● null/empty
● 對象(Object)
● 數組(Array)
注意: string,number,boolean,null是簡單數據類型或基元數據類型,而對象和數組則稱為復雜數據類型。
字符串(String):JSON字符串必須用雙引號編寫,如C語言,JSON中有各種特殊字符(轉義字符),您可以在字符串中使用,如\(反斜杠),/(正斜杠),b(退格),n (新行),r(回車),t(水平制表符)等。
示例:
{ "name":"Vivek" }
{ "city":"Delhi\/India" }
here / is used for Escape Character / (forward slash).
Number:以10為基數表示,不使用八進制和十六進制格式。
示例:
{ "age": 20 }
{ "percentage": 82.44}
Boolean:此數據類型可以是true或false。
示例:
{ "result" : true }
Null:這只是一個空值。
示例:
{"result" : true,"grade" :, //empty"rollno" : 210
}
Object:它是在{}(花括號)之間插入的一組名稱或值對。鍵必須是字符串,并且應該是唯一的,并且多個鍵和值對由(逗號)分隔。
語法:
{ key : value, .......}
示例:
{
"People":{ "name":"Peter", "age":20, "score": 50.05}
}
Array:它是一個有序的值集合,以[(左括號)和以…結尾(右括號)開頭。數組的值用(逗號)分隔。
語法:
[ value, …]
示例:
{
"people":[ "Sahil", "Vivek", "Rahul" ]
}
{"collection" : [{"id" : 101},{"id" : 102},{"id" : 103}]
}
JSON文檔的示例:
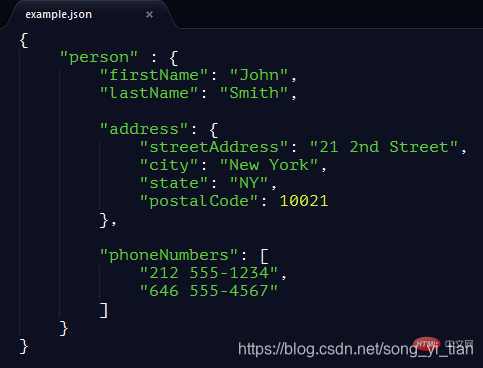
參考鏈接:搬運工
定制支持datetime類型
import json
from json import JSONEncoder
from datetime import datetime
class ComplexEncoder(JSONEncoder):def default(self, obj):if isinstance(obj, datetime):return obj.strftime('%Y-%m-%d %H:%M:%S')else:return super(ComplexEncoder,self).default(obj)
d = {"hello":"你好",'name':'alex','data':datetime.now()}
print(json.dumps(d,cls=ComplexEncoder,ensure_ascii=False))
# {"hello": "你好", "name": "alex", "data": "2020-05-05 23:40:53"}
注解:strftime()函數的使用方法
trftime()函數可以把YYYY-MM-DD HH:MM:SS格式的日期字符串轉換成其它形式的字符串。
strftime()的語法是strftime(格式, 日期/時間, 修正符, 修正符, …)
它可以用以下的符號對日期和時間進行格式化:
%d 日期, 01-31
%f 小數形式的秒,SS.SSS
%H 小時, 00-23
%j 算出某一天是該年的第幾天,001-366
%m 月份,00-12
%M 分鐘, 00-59
%s 從1970年1月1日到現在的秒數
%S 秒, 00-59
%w 星期, 0-6 (0是星期天)
%W 算出某一天屬于該年的第幾周, 01-53
%Y 年, YYYY
%% 百分號
strftime()的用法舉例如下:
from datetime import datetime
print(datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
76、json序列化時,默認遇到中文會轉換成unicode,如果想要保留中文怎么辦?
在序列化時,中文漢字總是被轉換為unicode碼,在dumps函數中添加參數ensure_ascii=False即可解決。
77、什么是斷言(assert)?應用場景?
Python的assert是用來檢查一個條件,如果它為真,就不做任何事。如果它為假,則會拋出AssertError并且包含錯誤信息。
斷言應該用于:
☆防御型的編程
☆運行時檢查程序邏輯
☆檢查約定
☆程序常量
☆檢查文檔
大神鏈接:點擊解惑
78、有用過with statement嗎?它的好處是什么?
with語句的作用是通過某種方式簡化異常處理,它是所謂的上下文管理器的一種
用法舉例如下:
with open('output.txt', 'w') as f:f.write('Hi there!')
當你要成對執行兩個相關的操作的時候,這樣就很方便,以上便是經典例子,with語句會在嵌套的代碼執行之后,自動關閉文件。這種做法的還有另一個優勢就是,無論嵌套的代碼是以何種方式結束的,它都關閉文件。如果在嵌套的代碼中發生異常,它能夠在外部exception handler catch異常前關閉文件。如果嵌套代碼有return/continue/break語句,它同樣能夠關閉文件。原文鏈接
79、使用代碼實現查看列舉目錄下的所有文件。
思路分析:遍歷一個文件夾,肯定是需要用到os模塊了,os.listdir()方法可以列舉某個文件夾內的所有文件和文件夾,os.path.isdir函數用于判斷是否為文件夾。由于文件夾內肯定有多層次結構,那么應該要定義一個函數,然后使用遞歸的方式來實現枚舉所有文件列表了。
import osdef dirpath(lpath, lfilelist):list = os.listdir(lpath)for f in list:file = os.path.join(lpath, f) #拼接完整的路徑if os.path.isdir(file): #判斷如果為文件夾則進行遞歸遍歷dirpath(file, lfilelist)else:lfilelist.append(file)return lfilelistlfilelist = dirpath(os.getcwd(), [])
for f in lfilelist:print(f)
os.getcwd()是用于獲取當前腳本所在的文件夾
80、簡述 yield和yield from關鍵字。
1、可迭代對象與迭代器的區別
可迭代對象:指的是具備可迭代的能力,即enumerable. 在Python中指的是可以通過for-in 語句去逐個訪問元素的一些對象,比如元組tuple,列表list,字符串string,文件對象file 等。
迭代器:指的是通過另一種方式去一個一個訪問可迭代對象中的元素,即enumerator。在python中指的是給內置函數iter()傳遞一個可迭代對象作為參數,返回的那個對象就是迭代器,然后通過迭代器的next()方法逐個去訪問。
#迭代器案例分析
list = [1,2,3,4,5]
li = iter(list)
print(next(li))
print(next(li))
print(next(li))
# 1
# 2
# 3
2、生成器
生成器的本質就是一個逐個返回元素的函數,即“本質——函數”
生成器有什么好處?
最大的好處在于它是“延遲加載”,即對于處理長序列問題,更加的節省存儲空間。即生成器每次在內存中只存儲一個值,比如打印一個斐波拉切數列:原始的方法可以如下所示:
def fab(max): n, a, b = 0, 0, 1 L = [] while n < max: L.append(b) a, b = b, a + b n = n + 1 return L
這樣做最大的問題在于將所有的元素都存儲在了L里面,很占用內存,而使用生成器則如下所示
def fab(max):n, a, b = 0, 0, 1while n < max:yield b #每次迭代時值加載這一個元素,而且替換掉之前的那一個元素,這樣就大大節省了內存。而且程序在遇見yield語句時會停下來,這是后面使用yield阻斷原理進行多線程編程的一個啟發a, b = b, a + bn = n + 1
生成器其實就是下面這個樣子,寫得簡單一些就是一次返回一條,如下:
def generator():for i in range(5):yield idef generator_1():yield 1yield 2yield 3yield 4yield 5
上面這兩種方式是完全等價的,只不過前者更簡單一些。
3、什么又是yield from呢?
簡單地說,yield from generator 。實際上就是返回另外一個生成器。如下所示:
def generator1():item = range(10)for i in item:yield idef generator2():yield 'a'yield 'b'yield 'c'yield from generator1() #yield from iterable本質上等于 for item in iterable: yield item的縮寫版yield from [11,22,33,44]yield from (12,23,34)yield from range(3)for i in generator2() :print(i)
從上面的代碼可以看出,yield from 后面可以跟的式子有“ 生成器 元組 列表等可迭代對象以及range()函數產生的序列”
上面代碼運行的結果為:
a
b
c
0
1
2
3
4
5
6
7
8
9
11
22
33
44
12
23
34
0
1
轉載于:https://www.cnblogs.com/petrolero/p/9803621.html
迭代器和生成器的區別?
迭代器是一個更抽象的概念,任何對象,如果它的類有 next 方法和 iter 方法返回自己本身,對于 string、list、dict、tuple 等這類容器對象,使用 for 循環遍歷是很方便的。在后臺 for 語句對容器對象調用 iter()函數,iter()是 python 的內置函數。iter()會返回一個定義了 next()方法的迭代器對象,它在容器中逐個訪問容器內元素,next()也是 python 的內置函數。在沒有后續元素時,next()會拋出一個 StopIteration 異常。
生成器(Generator)是創建迭代器的簡單而強大的工具。它們寫起來就像是正規的函數,只是在需要返回數
據的時候使用 yield 語句。每次 next()被調用時,生成器會返回它脫離的位置(它記憶語句最后一次執行的位置
和所有的數據值)
區別:生成器能做到迭代器能做的所有事,而且因為自動創建了 iter()和 next()方法,生成器顯得特別簡潔,而且生成器也是高效的,使用生成器表達式取代列表解析可以同時節省內存。除了創建和保存程序狀態的自動方法,當發生器終結時,還會自動拋出 StopIteration 異常。


















--受傷的總是我)
