什么是Attention機制?
Attention機制的本質來自于人類視覺注意力機制。人們在看東西的時候一般不會從到頭看到尾全部都看,往往只會根據需求觀察注意特定的一部分。
簡單來說,就是一種權重參數的分配機制,目標是協助模型捕捉重要信息。具體一點就是,給定一組<key,value>,以及一個目標(查詢)向量query,attention機制就是通過計算query與每一組key的相似性,得到每個key的權重系數,再通過對value加權求和,得到最終attention數值。
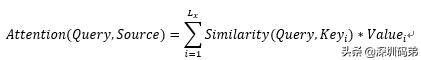
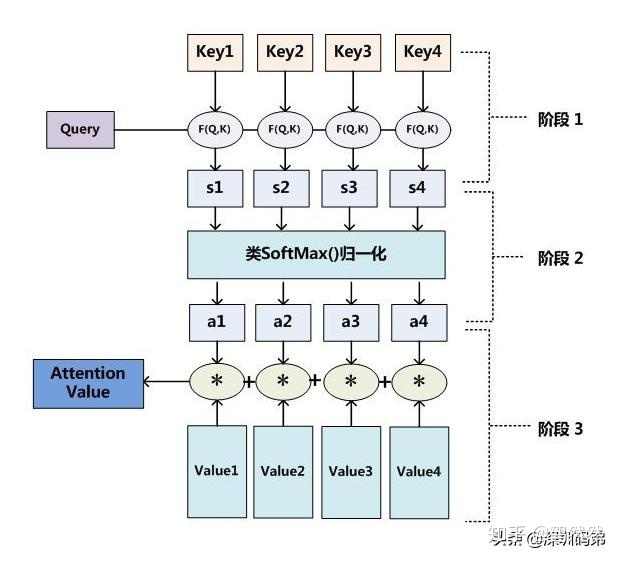
優缺點:
優點:
- 一步到位獲取全局與局部的聯系,不會像RNN網絡那樣對長期依賴的捕捉會收到序列長度的限制。
- 每步的結果不依賴于上一步,可以做成并行的模式
- 相比CNN與RNN,參數少,模型復雜度低。(根據attention實現方式不同,復雜度不一)
缺點:
- 沒法捕捉位置信息,即沒法學習序列中的順序關系。這點可以通過加入位置信息,如通過位置向量來改善,具體可以參考最近大火的BERT模型。
應用領域:
在這主要介紹幾篇論文或經典文檔。
自然語言處理:
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
- Generating Wikipedia by Summarizing Long Sequences
- Universal Transformers
計算機視覺:
- Image Transformer
- Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
推薦系統:
- Deep Interest Network for Click-Through Rate Prediction
- Deep Interest Evolution Network for Click-Through Rate Prediction
- Learning Tree-based Deep Model for Recommender Systems
Attention常見實現方法
- 多層感知機:
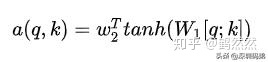
該方法主要是將Q,K拼接,然后一起通過一個激活函數為tanh的全連接層,再跟權重矩陣做乘積,在數據量夠大的情況下,該方法一般來說效果都不錯。
2.Dot Product / scaled-dot Product:
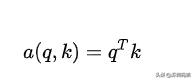
該方法適用于query與key維度相同情景,通過q轉置后與k點積。在權重值過大的情況下,可以將數據標準化,即scaled-dot Product。
3.Bilinear:
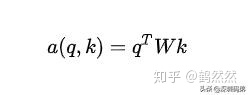
通過一個權重矩陣直接建立query與key的關系,權重矩陣可以隨機初始化也可以使用預設的。
4.cosine
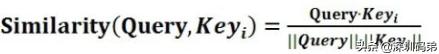
即計算兩個向量的cosine相似度。
self-attention
該方法即Q,K,V都來自于同一個輸入,其余計算過程,基本同上常用方法。
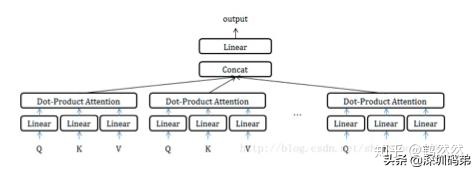
Multi-Head Attention
該方法可以理解成attention版本的ensemble,不同head學習不同的子空間語義。權值計算也同上常用方法。
推薦系統中的attention機制
現在推薦系統的趨勢基本是朝著海量數據+復雜模型的方向發展,相信將來會取代人工精細特征+簡單模型的方式。
這里主要介紹阿里的din模型:
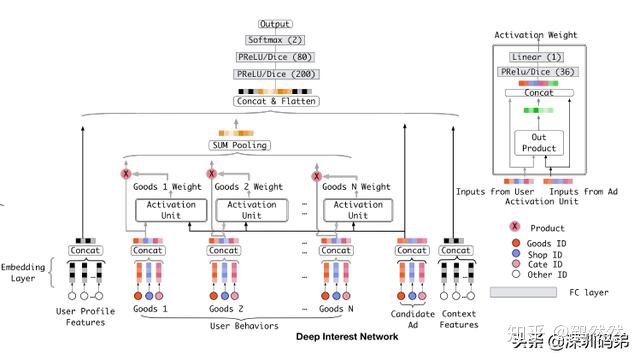
模型的主要思想在于用戶的興趣是無序的,比如在電商場景下,用戶A的歷史行為序列包含游泳用品,牛奶,女裝。而當前展示的廣告是女裝,它便只能激活女裝的這個興趣,即在當前展示廣告面前,用戶的興趣是多峰的。
基于此,通過target廣告與用戶行為序列key做attention,捕獲當前最可能被激活的那個峰。
具體算法實現便是通過target與行為序列做attention,再將輸出與其他特征拼接之后通過全連接層得到最終輸出。
相似的應用場景還有TDM模型,DIEN模型等。
小弟在此拋磚引玉,希望各位看官多多指點
--受傷的總是我)







!!!...)
)




)

-------輸入映射(含面試題))


)