文章目錄
- 大小端模式的概念
- 兩種模式出現原因
- 兩種模式的優劣
- 大小端的應用情景
- 判斷機器的字節序
大小端模式的概念
當我們查看數據在內存中的存儲情況時,我們經常會發現一個很奇怪的現象,什么現象呢?
int main()
{int i = 12;return 0;
}

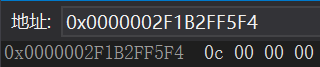
數據在內存中的存放方式似乎和我們想象的順序不太一樣,在我們的常規認知不一樣,在我們的常規認知中,它的存放方式應該是 00 00 00 0c ,那造成這個現象的原因是什么呢?
這是因為在內存中存放數據通常會采用兩種不同的存儲模式:大端存儲和小端存儲。
-
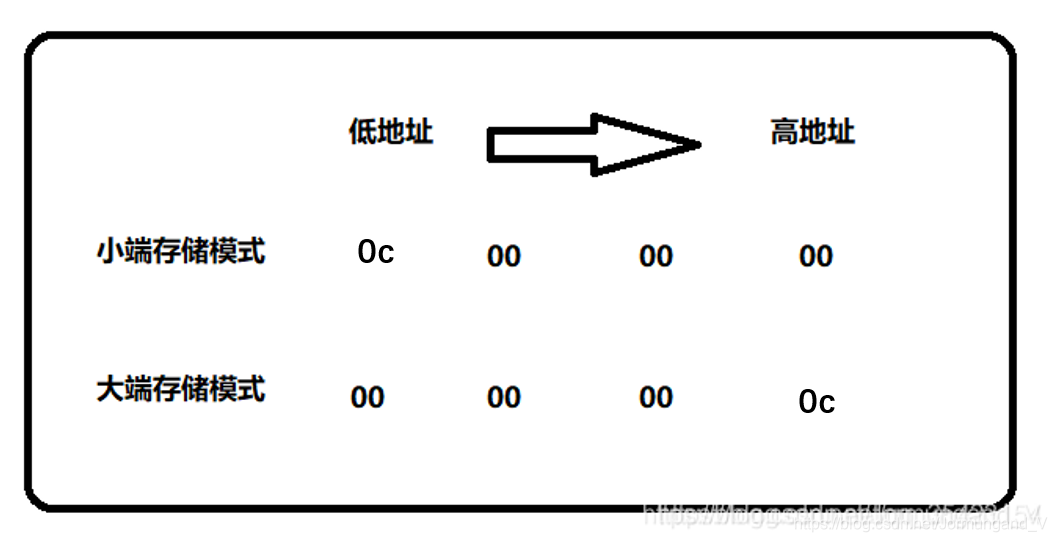
大端存儲模式:是指 數據的低位 保存在 內存的高地址 中,數據的高位 保存在 內存的低地址 中。
這樣的存儲模式有點兒類似于把數據當作字符串順序處理:地址由小向大增加,而數據從高位往低位放;這和我們的閱讀習慣一致。 -
小端存儲模式:是指 數據的低位 保存在 內存的低地址 中, 數據的高位 保存在 內存的高地址 中。
這種存儲模式將地址的高低和數據位權有效地結合起來,高地址部分權值高,低地址部分權值低。
用圖舉例:
用表舉例:
32bit寬的數 0x12345678 在CPU內存中的存放方式(假設從地址 0x4000 開始存放)為:
數據高位 -> 數據低位0x12345678
| 內存地址 | 小端模式 | 大端模式 | |
|---|---|---|---|
| 高地址 | 0x4003 | 0x12 | 0x78 |
| 0x4002 | 0x34 | 0x56 | |
| 0x4001 | 0x56 | 0x34 | |
| 低地址 | 0x4000 | 0x78 | 0x12 |
兩種模式出現原因
為什么會有大小端模式之分呢? 這是因為:
- 有些變量類型的大小大于一個字節,如:16bit的short型,32bit的long型(要看具體的編譯器)。
- 有些處理器的位數大于8位,例如16位或者32位的處理器。那么其中的寄存器的寬度必定大于一個字節。
總而言之,就是一個字節無法滿足我們的存儲需求,因此就誕生了大端小端這兩種存儲模式。
兩種模式的優劣
大端小端沒有誰優誰劣,各自優勢便是對方劣勢:
- 小端模式 :
- 強制轉換數據不需要調整字節內容,1、2、4字節的存儲方式一樣。
- CPU做數值運算時從內存中依次從低位到高位取數據進行運算,直到最后刷新高位的符號位,這樣的運算方式會更高效。
- 大端模式 :符號位的判定固定為第一個字節,容易判斷正負。
大小端的應用情景
一般操作系統都是小端,而JAVA、通訊協議是大端的。
對于處理器而言:
- 小端模式:Intel的80X86系列芯片,ARM處理器默認采用小端、但可以切換成大端。
- 大端模式:KEIL C51、PowerPC、IBM、Sun。
判斷機器的字節序
那么我們該如何判斷當前機器的字節序是大端還是小端?
以 int 變量 i=258 為例,i 的16進制形式為 i=0102 ,用圖來表示 i 以兩種方式存儲的結果:
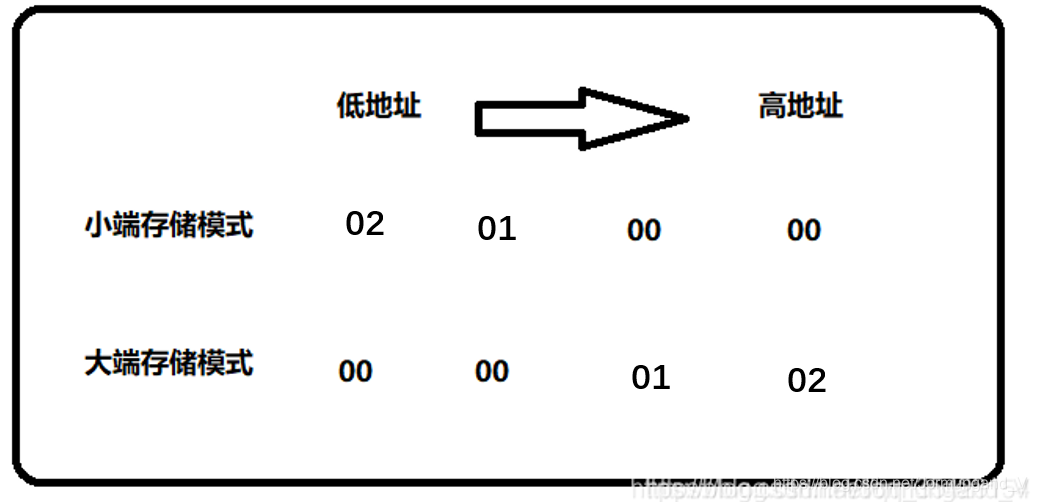
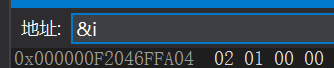
在 小端存儲模式 中 最低位字節 存放的為 02,大端存儲模式 中放的為 00 。因此可以通過強制轉換的方法,將一個四個字節的 int 數據截斷為一個字節的 char 數據,即可得到這個低位的數據,再進行判斷,如果為 02 則說明該機器為 小端存儲模式,如果為 00 則說明為 大端存儲模式 。
代碼實現:
int main()
{int i = 258;char ch = (char)i;if (ch == 02)printf("小端存儲\n");elseprintf("大端存儲\n");return 0;
}
運行結果:

驗證:




、進程地址空間)


調用))
【標準流和其文件描述符、fwrite函數、perror函數】)







| 數據類型、常用命令一覽、庫的操作、表的操作)


| 表的增刪查改、聚合函數(復合函數)、聯合查詢)