文章目錄
- UDP
- 概念
- 格式
- UDP如何實現可靠傳輸
- 基于UDP的應用層知名協議
- TCP
- 概念
- 格式
- 保證TCP可靠性的八種機制
- 確認應答、延時應答與捎帶應答
- 超時重傳
- 滑動窗口
- 滑動窗口協議
- 后退n協議
- 選擇重傳協議
- 流量控制
- 擁塞控制
- 發送窗口、接收窗口、擁塞窗口
- 快速重傳和快速恢復
- 連接管理機制
- 三次握手
- 連接超時
- 四次揮手
- TIME_WAIT
- 保活機制
- TCP的數據類型
- 交互/成塊數據流
- 帶外數據
- TCP粘包
- 基于TCP的應用層知名協議
UDP
概念
UDP協議,即用戶數據報協議。為應用層提供 不可靠、無連接、基于數據報的服務。
- 不可靠: 不保證數據從發送端正確地傳送到目的端,也無須為應用層數據保存副本,出現問題時(丟包,錯序達到等)
UDP協議只是簡單地通知應用程序發送失敗。因此,使用UDP協議的應用程序通常需要自己處理數據確認、超時重傳等邏輯。 - 無連接: 不需要建立連接也可以發送數據。通信雙方每次發送數據都需要指定接收端的地址。
- 基于數據報的服務: 每個 UDP數據報 都有一個長度,接收端必須以該長度為最小單位將其所有內容一次性讀出,否則數據將被截斷。
格式

- 16位源端端口/目的端口: 表示源端/對端的端口號,源端端口有時候可以不設置(不關心通信的端口),可以設置為
0。 - 16位數據報長度: 標志UDP首部與發送數據的長度之和,大小為 216,即
64K,65535。 - 16位校驗和: 用于檢驗 接收的數據 與 發送的數據 是否一致,不一致則丟棄 。校驗方法:二進制反碼求和,即對報文從頭開始的每個字節進行取反相加,高出16位則截斷高位,與低16位相加,得到校驗和。
面向數據報:
- 數據報長度字段只有
16位,報頭要占8個字節,所以數據報的長度不能大于64K- 8。
UDP給應用層傳下來的報文添加首部后就會直接轉交給網絡層,所以對于較大的數據,需要我們自己在應用層進行分包和包序管理。 UDP在報頭中定義了數據長度,所以傳輸的時候都是整條收發。
所以接收時緩沖區必須要足夠大,如果緩沖區小于一條數據的大小會接收失敗,因為UDP不會交付 半條數據 。
UDP如何實現可靠傳輸
依靠UDP本身是無法實現可靠傳輸的,因為無法保證數據 有序且到達 ,所以可以參考TCP的可靠性機制,在應用層也為其引入類似邏輯:
- 引入序列號,保證數據有序。
- 確認應答機制,保證對端能夠收到數據。
- 引入超時重傳機制,保證數據不會丟失。
基于UDP的應用層知名協議
- NFS: 網絡文件系統
- TFTP: 簡單文件傳輸協議
- DHCP: 動態主機配置協議
- BOOTP: 啟動協議(用于無盤設備啟動)
- DNS: 域名解析協議
TCP
概念
TCP協議,即傳輸控制協議。為應用層提供 可靠的、面向連接、基于流的服務。
- 可靠: 通過超時重傳、數據確認等方式來確保數據報被正確地發送至目的端。
- 面向連接: 雙方都必須先分配必要的內核資源以建立全雙工的連接,才能開始數據的讀寫。
- 基于流: 基于流的數據沒有邊界(長度)限制。
格式

- 16位源端端口/目的端口: 表示源端/目的端的端口號,源端端口有時候可以不設置(不關心通信的端口),可以設置為0。
- 32位序號: 序號是指發送數據的位置。每發送一次數據,就累加一次該數據字節數的大小。序號不會從
0或1開始,而是在建立連接時由計算機生成的隨機數作為其初始值(ISN,初始序號值),通過SYN包傳給接收端主機。后續報文中序號值將被設置為ISN+報文攜帶數據的第一個字節在整個字節流中的偏移。如:后續某個TCP報文段傳送的數據是字節流中的第 1025~2048 字節,那么該報文段的序號值為ISN+1025。 - 32位確認序號: 對發送端發來的TCP報文段的響應,其值是
收到的TCP報文段的序號+1。而發送端接收到這個確認序號以后可以認為在確認序號以前的數據都已經被正常接收。TCP通過序號和確認序號來實現包序管理,確保TCP數據是有序交付的。 - 4位數據偏移(首部長度): 標識該
TCP頭部有多少個32bit(4字節)。因為4位最大能表示15(24 -1)個,所以 TCP頭部最長是60字節。 - 6位保留位: 保留為今后使用,一般設置為
0。 - 6位標志位: 有六種標志位,用來描述本報文的性質:
- URG(Urgent Flag): 該位為
1時,表示包中有需要緊急處理的數據。對于需要緊急處理的數據,會在后面的緊急指針中再進行解釋。 - ACK(Acknowledge Flag): 該位為
1時,確認應答的字段變為有效。攜帶ACK標志的稱為 確認報文段 。 - PSH(Push Flag): 該位為
1時,表示接收端應該立刻從 TCP接收緩沖區中讀走數據,傳輸給上層的應用。為0時,則不需要立即讀取而是先進行緩存。 - RST(ResetFlag): 該位為
1時,要求接收方重新建立連接。攜帶RST標志的稱為 復位報文段 。下面討論產生 復位報文段 的三種情況:- 當客戶端訪問一個不存在的端口時,服務器就可以返回一個RST設置為
1的包(報文中 接受通告窗口【seq】大小為 0 ,因此不能被回應),告訴客戶端關閉連接或者重新連接。 - 可用于 異常終止 連接,不發送 結束報文段 而直接發送 復位報文段 ,發送端所有排隊等待發送的數據都將被丟棄。
- 服務器(或客戶端)關閉或者異常終止了連接 ,而客戶端(或服務器)由于斷網、重啟等原因 沒有接收到發來的結束報文段 ,恢復正常后客戶端(或服務器)還 維持著原來的連接 。客戶端(或服務器)的這種狀態稱為 半打開狀態,處于這種狀態的連接叫 半打開連接 。如果客戶端(或服務器)往 半打開連接 寫入數據,對方會回應一個 復位報文段 。
- 當客戶端訪問一個不存在的端口時,服務器就可以返回一個RST設置為
- SYN(Synchronize Flag): SYN為
1表示希望建立連接,并在其序列號的字段進行序列號初始值的設定。攜帶SYN標志的稱為 同步報文段 。 - FIN(Finish Flag): 該位為
1時,表示通知對方本端今后不會再有數據發送,希望斷開連接。當通信結束希望斷開連接時,通信雙方的主機之間就可以相互交換FIN位置為1的TCP段。每個主機又對對方的FIN包進行確認應答以后就可以斷開連接。不過,主機收到FIN設置為1的TCP端以后不必馬上回復一個FIN包,而是可以等到緩沖區中所有數據都已成功發送而被自動刪除之后再發。攜帶FIN標志的稱為 結束報文段 。
- URG(Urgent Flag): 該位為
- 16位窗口大小: 是TCP流量控制的一個手段。這里說的窗口,指的是接收通告窗口。它告訴對方 本端的TCP接收緩沖區 還能容納多少字節的數據,這樣對方就可以控制發送數據的速度。用于實現滑動窗口機制,來進行流量控制。
- 16位校驗和: 由發送端填充,用于檢驗接收的數據(TCP頭部+數據部分)與發送的數據是否一致,不一致則丟棄 。校驗方法CRC算法:二進制反碼求和,即對報文從頭開始的每個字節進行取反相加,高出16位則截斷高位,與低16位相加,得到校驗和。是TCP可靠傳輸的一個重要保障。
- 16位緊急指針: 是一個正的偏移量。它和序號字段的值相加表示最后一個緊急數據(帶外數據)的下一個字節的序號。
- 0-40字節選項: 選項字段用于提高TCP的傳輸性能,主要協商和描述一些信息。因為TCP首部大小最高為60字節,而前面必須的有20字節,所以選項的大小可以為0-40字節。
| kind(1字節) | length(1字節) | info(n字節) |
|---|
kind 說明選項類型;length (如果有的話)指定該選項長度 ;info (如果有的話)指選項的具體信息。
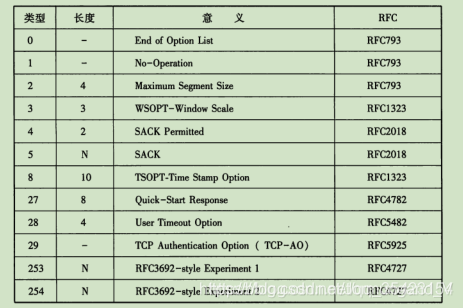
- kind=0是選項表結束選項。
- kind=1是空操作(nop)選項。 沒有特殊含義,一般用于將TCP選項的總長度填充為4字節的整數倍。
- kind=2是最大報文段長度選項。 TCP連接初始化時,通信雙方使用該選項來協商最大報文段長度(Max Segment Size,MSS)。TCP模塊通常將MSS設置為
(MTU-40)字節(減掉的這40字節包括20字節的TCP頭部和20字節的IP頭部)。這樣攜帶TCP報文段的IP數據報的長度就不會超過MTU(假設TCP頭部和IP頭部都不包含選項字段,并且這也是一般情況),從而避免本機發生IP分片。對以太網而言,MSS值是1460(1500-40)字節。- kind=3是窗口擴大因子選項。 TCP連接初始化時,通信雙方使用該選項來協商接收通告窗口的擴大因子。在TCP的頭部中,接收通告窗口大小是用
16位表示的,故最大為65535字節,但實際上TCP模塊允許的接收通告窗口大小遠不止這個數。假設TCP頭部中的接收通告窗口大小是N,窗口擴大因子(移位數)是M,那么TCP報文段的實際接收通告窗口大小是 N*2M ,或者說N左移M位。注意,M的取值范圍是0~14。我們可以通過修改proc/sys/net/ipv4/tcp_window_scaling內核變量來啟用或關閉窗口擴大因子選項。和MSS選項一樣,窗口擴大因子選項只能出現在同步報文段中,否則將被忽略。 但同步報文段本身不執行窗口擴大操作,即同步報文段頭部的接收通告窗口大小就是該TCP報文段的實際接收通告窗口大小。當連接建立好之后,每個數據傳輸方向的窗口擴大因子就固定不變了。- kind=4是選擇性確認(Selective Acknowledgment,SACK)選項。 TCP通信時,如果某個TCP報文段丟失,則TCP模塊會重傳最后被確認的TCP報文段后續的所有報文段,這樣原先已經正確傳輸的TCP報文段也可能重復發送,從而降低了TCP性能。SACK技術正是為改善這種情況而產生的,它使TCP模塊只重新發送丟失的TCP報文段,不用發送未被確認的TCP報文段之后所有報文段。我們可以通過修改/proc/sys/net/ipv4/tcp_sack內核變量來啟用或關閉選擇性確認選項。
- kind=5是SACK實際工作的選項。 該選項的參數告訴發送方本端已經收到并緩存的不連續的數據塊,從而讓發送端可以據此檢查并重發丟失的數據塊。每個塊邊沿(edge of block)參數包含一個
4字節的序號。其中 塊左邊沿 表示 不連續塊的第一個數據的序號 ,而 塊右邊沿 則表示 不連續塊的最后一個數據的序號的下一個序號 。這樣一對參數(塊左邊沿和塊右邊沿)之間的數據是沒有收到的。因為一個塊信息占用8字節,所以TCP頭部選項中實際上最多可以包含4個這樣的不連續數據塊(考慮選項類型和長度占用的2字節)。- kind=8是時間戳選項。 該選項提供了較為準確的計算通信雙方之間的回路時間(Round Trip Time,RTT)的方法,從而為TCP流量控制提供重要信息。 我們可以通過修改
/proc/sys/net/ipv4/tcp_timestamps內核變量來啟用或關閉時間戳選項。
保證TCP可靠性的八種機制
為了保證可靠傳輸,TCP提出了8種機制:
- 確認應答機制
- 延時應答機制
- 捎帶應答機制
- 超時重傳機制
- 滑動窗口機制
- 流量控制機制
- 擁塞控制機制
- 快速重傳機制
確認應答、延時應答與捎帶應答
確認應答
TCP中,確認應答機制(ACK報文) 是保證數據可靠傳輸的核心機制:
- TCP將每個字節的數據都進行了編號,即為序列號。
- 每一個ACK都帶有對應的確認序列號,意思是告訴發送者,我已經收到了哪些數據;下一次你從哪里開始發(應答)。
- 而且此時給請求和應答都對應帶上編號,既能保證數據傳輸沒有歧義,也不會浪費太多的空間和寬帶。
- TCP規定,除了第一次握手時的SYN包之外,其他TCP報文段必須攜帶 確認報文 。

延時應答
基于確認應答機制,但接收端收到發送端發來的數據后并 不立即返回ACK應答 :
- 立即返回ACK應答的話,這時候的接收緩沖區中的數據還沒能夠處理,緩存區的剩余大小就是窗口大小。
- 但實際上應用程序可能很快就會讀走接收緩沖區中的內容,因此我們 延遲一會 ,等待緩存區中數據被處理,那么剩余的緩存區就會大些。
是不是所有的包都可以延時應答?
- 數量限制:每隔
N(默認N=2)個包就應答一次 - 時間限制:超過最大延時時間就應答一次(默認為
200ms)
捎帶應答
在延時應答的基礎上,接受方和發送方都是 一發一收,所以,我們在發送數據的時候,將ACK以搭順風車的方式發送給對方。
超時重傳
實際網絡中會有丟包的可能,TCP模塊為每個TCP報文段都維護一個重傳定時器 ,該定時器在TCP報文段第一次發送時啟動。如果 超時時間內 未收到接收方的 確認報文段 ,TCP模塊將 重傳丟失的TCP報文段 并 重置定時器 。
兩種原因導致的超時重傳
假設 A 給 B 發送 TCP報文段 ,造成TCP報文段超時重傳有兩種原因:
- A發給B的TCP報文段丟了。
- B發給A的ACK報文段丟了。
- 如果是第一種,那對雙方沒什么影響,重發就行。
- 但是如果第二種情況,那么
B就會收到 已經確認過的TCP報文 ,那么B需要能夠識別出這是之前重復的包,我回應的ACK報文丟了?還是新的一次請求,需要新的ACK報文?這時候可以利用序列號,由于重發的TCP報文序列號跟之前一樣,因此B就知道原來是 之前回應的ACK報文丟了 ,那重發一次就好了。
超時重傳的時間
超時時間的設置是很有講究的:
- 如果超時時間設的太長,會影響整體的重傳效率;
- 如果超時時間設的太短,有可能會頻繁發送重復的包,對接收方造成困擾。
Linux 中(BSD Unix 和 Windows 也是如此),超時以 500ms 為一個單位進行控制,每次超時時間都是 500ms 的整數倍。
根據 karn算法 :RTO(新的重傳時間)= γ × RTO(舊的重傳時間)【系數 γ 的典型值是2】
- 如果重發一次之后,仍然得不到應答,等待
2*500ms后再進行重傳。 - 如果仍然得不到應答,等待
4*500ms進行重傳,依次類推。 - 累計到一定的重傳次數,TCP認為 網絡 or 對端主機 出現異常,強制關閉連接。
超時重傳的次數
Linux 有兩個重要內核參數管理TCP的超時重傳次數:
/proc/sys/net/ipv4/tcp_retries1:指定在底層IP和ARP接管之前 最少 要執行多少次重傳。默認值是3。/proc/sys/net/ipv4/tcp_retries2: 指定強制關閉連接前TCP 最多 可以執行的重傳次數 ,默認值為15(一般對應13~30min,可以用date命令測量)。
滑動窗口
從前面的確認應答機制可以看到,如果對于每一個數據,都需要等到回復確認,才發送下一個數據,就會導致效率的低下,尤其是網絡較差時,數據的往返之間過長的情況。既然這樣一收一發的效率過慢,那么一次性發送多條,就可以解決這種問題,但是如果發送的數量過多,就可能會導致緩沖區溢出而丟包,為了控制發送數據的規模,于是TCP就引入了滑動窗口機制。
在TCP首部中我們看到有一個 16位窗口大小的字段 ,那個就是滑動窗口的大小,其意味著接收方還有多大的緩沖區可以用于接收數據。發送方可以通過滑動窗口的大小來確定應該發送多少字節的數據,在三次握手的時候雙方進行協商,規定好通信時的 MSS 和 窗口大小 。當滑動窗口為 0 時,發送方一般不能再發送數據報,但有兩種情況除外:
- 可以發送 緊急數據 。
- 發送方可以發送一個
1字節的數據報來通知接收方重新聲明它希望接收的下一字節及發送方的滑動窗口大小。
發送端維護發送窗口:用于限制一次能夠發送的數據。
- 后沿:數據發送的起始位置,等待確認回復的數據,如果得到了回復,則后沿移動。
- 前沿:數據發送的結束位置,前沿減去后沿必須小于等于窗口大小,移動取決于窗口大小。
接收端維護接受窗口:用于進行數據的排序。
- 后沿:數據接受的起始位置,移動取決于是否收到后沿數據。
- 前沿:接收緩沖區剩余空間大小加上后沿,移動取決于接收緩沖區剩余大小。
下面舉例說明,假設發送窗口尺寸為2,接收窗口尺寸為1:
- 初始態,發送方沒有幀發出,發送窗口前后沿相重合。接收方0號窗口打開,等待接收0號幀;
- 發送方打開0號窗口,表示已發出0幀但尚未確認返回信息。此時接收窗口狀態不變;
- 發送方打開0、1號窗口,表示0、1號幀均在等待確認之列。至此,發送方打開的窗口數已達規定限度,在未收到新的確認返回幀之前,發送方將暫停發送新的數據幀。接收窗口此時狀態仍未變;
- 接收方已收到0號幀,0號窗口關閉,1號窗口打開,表示準備接收1號幀。此時發送窗口狀態不變;
- 發送方收到接收方發來的0號幀確認返回信息,關閉0號窗口,表示從重發表中刪除0號幀。此時接收窗口狀態仍不變;
- 發送方繼續發送2號幀,2號窗口打開,表示2號幀也納入待確認之列。至此,發送方打開的窗口又已達規定限度,在未收到新的確認返回幀之前,發送方將暫停發送新的數據幀,此時接收窗口狀態仍不變;
- 接收方已收到1號幀,1號窗口關閉,2號窗口打開,表示準備接收2號幀。此時發送窗口狀態不變;
- 發送方收到接收方發來的1號幀收畢的確認信息,關閉1號窗口,表示從重發表中刪除1號幀。此時接收窗口狀態仍不變。
根據窗口尺寸的大小不同,滑動窗口分為 1比特滑動窗口、后退n 及 選擇重傳 三種協議:
- 1比特滑動窗口協議:發送窗口=1,接收窗口=1;
- 后退n協議:發送窗口>1,接收窗口=1;
- 選擇重傳協議:發送窗口>1,接收窗口>1。
滑動窗口協議
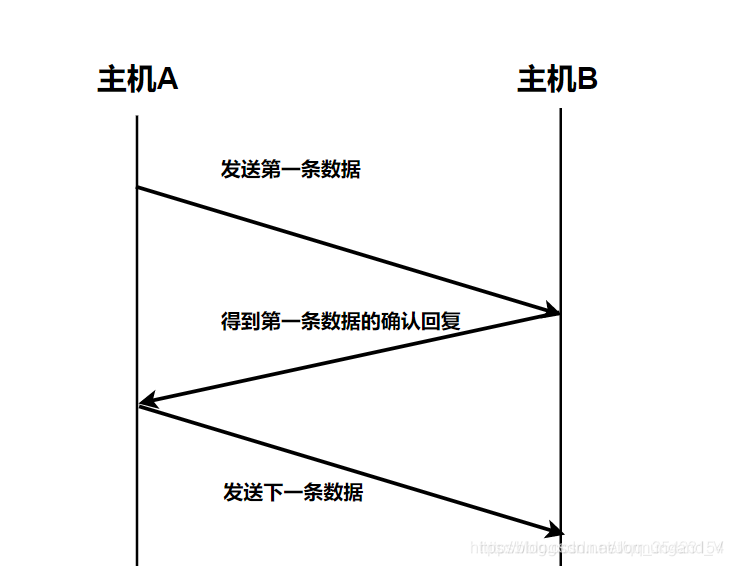
當發送窗口和接收窗口的大小固定為1時,滑動窗口協議退化為停等協議(stop-and-wait)。該協議規定發送方每發送一幀后就要停下來,得到回復后才能繼續發送下一幀。
后退n協議
由于停等協議要為每一個幀進行確認后才繼續發送下一幀,大大降低了信道利用率,因此又提出了后退n協議。
后退n協議中,發送方在發完一個數據幀后,不停下來等待應答幀,而是連續發送若干個數據幀。且發送方在每發送完一個數據幀時都要設置超時定時器。如果 某幀在計時器超時后仍未返回其確認信息,就要重發該幀及后續所有幀。
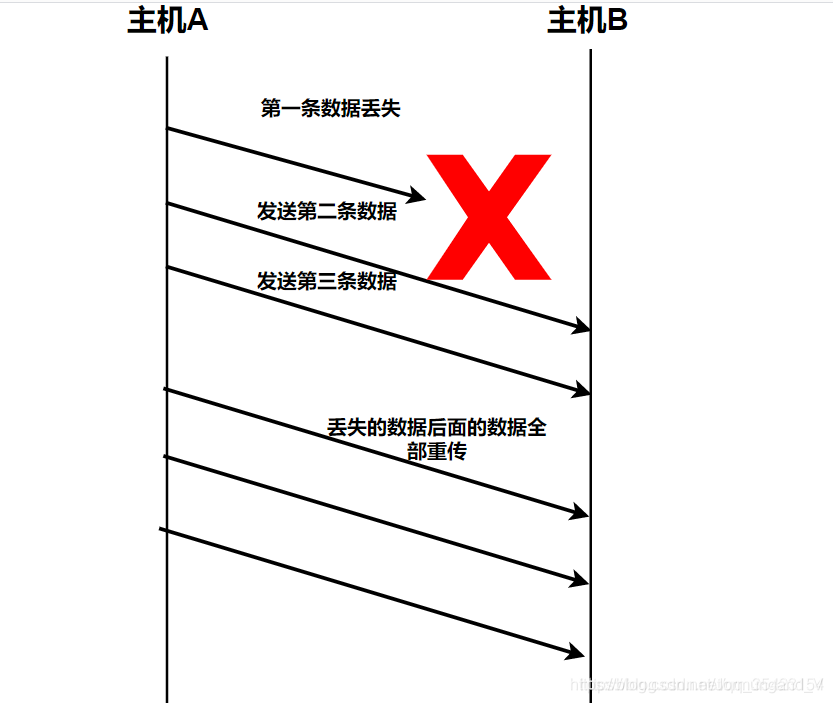
從這里不難看出,后退n協議一方面因連續發送數據幀而提高了效率,但另一方面,在重傳時又必須把原來已正確傳送過的數據幀進行重傳(僅因這些數據幀之前有一個數據幀出了錯),這種做法又使傳送效率降低。
選擇重傳協議
在后退n協議中,接收方若發現錯誤幀就不再接收后續正確到達的幀,這顯然是一種浪費,因此提出了選擇重傳協議。
選擇重傳協議(SELECTICE REPEAT)中,接收方發現某幀出錯后,其后繼續送來的正確的幀 雖然不能立即遞交給接收方的高層,但接收方仍可收下來,存放在一個緩沖區中,同時要求發送方重新傳送出錯的那一幀。 一旦收到重新傳來的幀后,就可以原已存于緩沖區中的其余幀一并按正確的順序遞交高層。
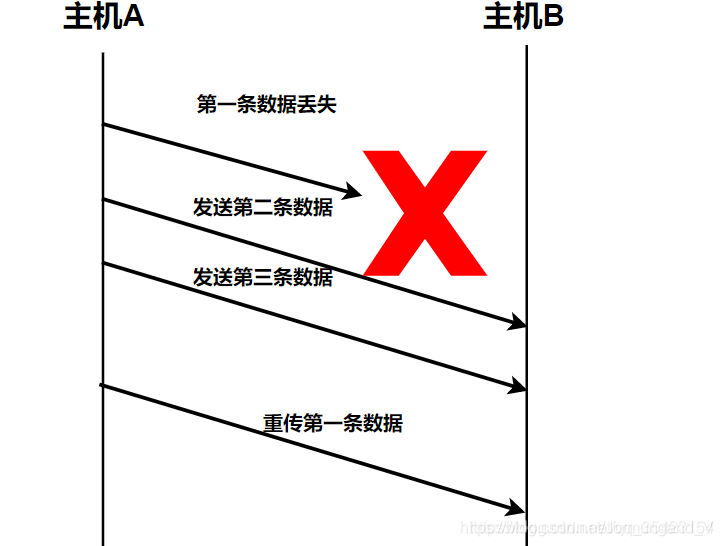
顯然,選擇重發減少了浪費,但要求接收方有足夠大的緩沖區空間。
流量控制
接收端處理數據的速度是有限的,如果發送端發的太快,導致接收端的緩沖區滿, 這個時候如果發送端繼續發送,就會造成丟包,繼而引起丟包重傳等等一系列連鎖反應。
因此TCP提出了 流量控制機制:根據接收端的處理能力,來決定發送端的發送速度。
- TCP連接階段,雙方協商窗口尺寸,同時接收方預留數據緩存區;
- 發送方根據協商的結果,發送符合窗口尺寸的數據字節流,并等待對方的確認;
- 接收端將 接收緩沖區空閑大小 放入 TCP 首部中的 窗口大小字段,通過ACK報文通知發送端。窗口大小字段越大,說明網絡的吞吐量越高;
- 發送方根據確認信息,改變窗口的尺寸,增加或者減少發送未得到確認的字節流中的字節數。
- 如果接收端緩沖區滿了,就會將窗口置為0,這時發送方不再發送數據,但是需要定期發送一個窗口探測數據段,詢問接收端當前 接收緩沖區的空閑大小 。
- 如果出現發送擁塞,發送窗口縮小為原來的一半,同時將超時重傳的時間間隔擴大一倍。
而在傳輸過程中,發送窗口(SWND)的大小并不僅僅取決于接收窗口(RWND),還取決于下文將提到的擁塞窗口(CWND)。
擁塞控制
擁塞控制的作用是:提高網絡利用率、降低丟包率,并保證網絡資源對每條數據流的公平性。
擁塞控制有四個部分:
- 慢啟動(slow start)
- 擁塞避免(congestion avoidance)
- 快速重傳(fast retransmit)
- 快速恢復(fast recovery)
擁塞控制算法或者部分或者全部實現了上述四個部分。/proc/sys/net/ipv4/tcp_congestion_control 文件指示當前所使用擁塞控制算法。
這里介紹一個擁塞控制算法——Nagle算法
Nagle算法:為了盡可能發送大塊數據,避免網絡中充斥著許多小數據塊。 主要用于解決交互數據流(見下文)帶來的網絡擁塞。
- 要求一個TCP連接通信雙方在任意時刻都最多只能發送一個未被確認的TCP報文段,在該TCP報文段的確認到達之前不能發送新的TCP報文段。
- 發送方在等待ACK報文的同時收集本端下次需要發送的微量數據,并在確認到來時以一個TCP報文段將它們全部發送出去。這樣就大大減少了網絡上的微小TCP報文段的數量。
Nagle更詳細的發送規則:
- 如果包長度達到MSS,則允許發送;
- 如果該包含有FIN,則允許發送;
- 設置了TCP_NODELAY選項,則允許發送;
- 未設置TCP_CORK選項時,若所有發出去的小數據包(包長度小于MSS)均被確認,則允許發送;
- 上述條件都未滿足,但發生了超時(一般為200ms),則立即發送。
發送窗口、接收窗口、擁塞窗口
- 擁塞控制的最終受控變量是 發送端向網絡一次連續寫入的數據量 ,被稱為 發送窗口(SWND,Send Window)。
- 發送窗口限定了發送端能連續發送的TCP報文段數量。這些TCP報文段 數據部分的最大長度 稱為 發送者最大段大小(SMSS)。 其值一般等于 最大報文長度(MSS)。
- 發送端要合理選擇SWND大小,太小需要在網絡上頻繁的傳輸確認信息,導致通信效率下降;太大容易產生多次丟包重傳(從快速局域網進入慢速局域網、接收端緩存不夠溢出),導致網絡擁塞。
- 接收端 可以通過 接收窗口(RWND)來控制 發送端 的 SWND。但還不夠,發送端還引入了 擁塞窗口(CWND,Congestion Window)這個狀態變量。SWND值 是 RWND 和 CWND 中的較小值。
擁塞窗口
- 發送開始的時候,定義擁塞窗口初始值為
IW(Initial Window),大小為1個MSS; - 每收到一個ACK應答,擁塞窗口:
CWND*=2。
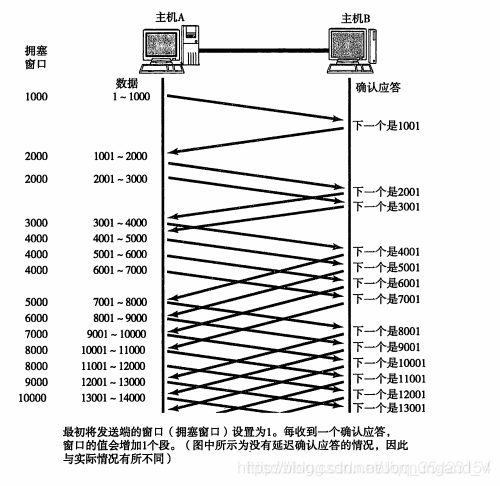
第二點就是上面提到的 慢啟動 :TCP模塊一開始并不清楚網絡的實際情況,因為需要用一種試探的方式平滑地增加CWND的大小。但慢啟動實際上并不慢,如果不加限制,慢啟動必然使得CWND指數級增長,并最終導致網絡擁塞。為了避免網絡擁塞,擁塞控制定義了 慢啟動門限(slow start threshold size,ssthresh) 這個狀態變量。當CWND大小超過該值時,TCP擁塞控制將進入 擁塞避免階段。
cwnd < ssthresh,慢開始算法。cwnd>ssthresh,擁塞避免算法。采用 加法增大 的策略,即CWND不再以2倍的方式增加,而是轉變為每次加1的方式。cwnd = ssthresh,兩者皆可。

正如上圖所示,擁塞避免并不能避免網絡擁塞發生,它只是 將CWND由指數增長拉低到線性增長,降低出現擁塞的可能。 當網絡擁塞發生時,CWND迅速縮小,那么 發送端是如何判斷擁塞發生的呢?
- 傳輸超時,或者說TCP重傳定時器溢出。
- 接收到重復的確認報文段。
擁塞控制對這兩種情況有不同的處理方式:
- 第一種情況:慢啟動和擁塞避免。
- 第二種情況:快速重傳和快速恢復。如果第二種情況發生在重傳定時器溢出之后,則也被當成第一種情況來對待。
當發送端檢測出 擁塞發生 是由于第一種情況,會執行 擁塞避免 :
ssthresh = CWND/2:CWND是擁塞發生時的擁塞窗口大小。CWND=MSS:重置CWND的值,重新開始慢啟動。
快速重傳和快速恢復
快速重傳
假設發送方發送了 M1–M4 四個分組,接收方收到了 M1、M2、M4 ,接收方不能確認 M4,因為 M3 沒有收到。 此時接收方可以什么都不干,但 快重傳算法要求接收方繼續發送對M2的確認:
- 發送方還會試著發送
M5、M6,接收方繼續發送對M2的重復確認,這樣可以讓發送方知道M3并沒有被傳過來。按照規定,只要發送方收到三個重復確認(加上一個正常確認,總共發送了4個ACK報文),就立即重傳確認序號指向的數據(對方未收到的報文段M3),這樣 比起等待 M3 超時后進行重傳效率快了很多,因此被叫做快速重傳。
快速恢復

當出現了快重傳的情況時,就說明當前網絡狀況存在問題,但是又由于我們能夠連續三次收到確認應答,就說明了當前的問題并不是很嚴重,沒有必要重新進行慢開始。所以當前會:
- 將
ssthresh設置為當前CWND大小的一半 - 將 CWND 設置為
新的ssthresh - 然后實行擁塞避免算法
由于跳過了慢開始階段直接進行擁塞避免,因此被稱為快恢復。
連接管理機制
這篇關于三次握手四次揮手的博客很全:面試官,不要再問我三次握手和四次揮手
三次握手

- 第一次握手:客戶端發送網絡包,服務端收到了。
這樣 服務端 就能得出結論:客戶端的發送能力、服務端的接收能力是正常的。 - 第二次握手:服務端發包,客戶端收到了。
這樣 客戶端 就能得出結論:服務端的接收、發送能力,客戶端的接收、發送能力是正常的。 不過此時 服務器并不能確認客戶端的接收能力是否正常。 - 第三次握手:客戶端發包,服務端收到了。
這樣 服務端 就能得出結論:客戶端的接收、發送能力正常,服務器自己的發送、接收能力也正常。
socket 接口與三次握手:

為什么握手不能兩次?即客戶端發起SYN連接,服務端確認后回復ACK+SYN就直接建立連接。
如果只有兩次就能建立連接,那就代表著就容易產生這種情況:
- 如客戶端發出連接請求,但因連接請求報文丟失而未收到確認,于是客戶端再重傳一次連接請求。
- 客戶端收到了第二個請求報文的確認,與服務器建立了連接。數據傳輸完畢后,就釋放了連接。
- 然而第一個丟失的請求報文段只是在某些網絡結點長時間滯留了。假定這個滯留時間未超過MSL,并且延誤到連接釋放以后的某個時間才到達服務端。
- 此時服務端誤認為客戶端又發出一次新的連接請求,于是就向客戶端發出確認報文段,同意建立連接,不采用三次握手,只要服務端發出確認,就建立新的連接了。
- 但此時客戶端并不想和服務器建立連接,因此忽略服務端發來的確認,也不發送數據,則服務端一致等待客戶端發送數據,浪費資源。
為什么不用四次?
四次握手可以用但完全沒有必要,建立連接的SYN和確認回復的ACK報文是可以一起發送的(上文提到過的 捎帶應答),沒有必要分開來增加操作。
連接超時
類似超時重傳機制。
如果客戶端訪問一個距離它很遠,或者由于網絡繁忙,導致 服務器對于客戶端發送出的同步報文段沒有應答。 此時客戶端將進行多次重連,若仍然聯系不上,則通知應用程序連接超時:
- 超時重連報文一般會有
5個,這是由/proc/sys/net/ipv4/tcp_syn_retries內核變量定義的,(加上第一個正常的請求報文也就是說,通知應用程序連接超時之前,最多會發送 6 個TCP同步報文段請求與服務器連接)。 - 每次發重連請求報文段的時間間隔是遞增的:
1s 、 2s 、 4s 、 8s 、 16s 、 32s。也就是 每次重連的超時時間都增加一倍 ,如果不增加的話,那么后五次發送沒有意義,同樣的時間第一個到不了顯然后五個很大概率從也到不了。
服務端發送了SYN和ACK后,沒有收到客戶端的ACK,服務端如何處理?
說明客戶端可能不在線,此時發送一個RST重置連接,并且釋放已有資源。
四次揮手

- 第一次揮手: 客戶端:我要說的話已經說完了。
- 第二次揮手: 服務端:你要說的我都聽到了,但是我的話還沒說完。
- 第三次揮手: 服務端:我要說的話也說完了。
- 第四次揮手: 客戶端:既然我們都說完了,那就結束通話吧。
半關閉狀態 與 如何檢測連接是否被對方關閉
在第二次揮手完成后,客戶端不會再向服務端發送數據,但允許繼續接收對方的數據。客戶端這種狀態為 半關閉狀態。 socket網絡編程接口通過 shutdown函數 提供了對半關閉的支持,Linux 也提供了諸多檢測連接是否被對方關閉的方法,例如:收到結束報文段時,read 系統調用返回 0 。
為什么不是三次揮手?
就像上面所說的,處于 半關閉狀態 是為了接受對方未發送完的數據,但是如果 服務器收到客戶端的FIN報文時湊巧也沒有數據要發送給客戶端了 ,那么客戶端可以從 FIN_WAIT1狀態 直接進入 TIME_WAIT狀態 ,也就是服務器 不發送 ACK 報文 ,而是 直接發送 FIN+ACK 報文 (從)。此時就是三次揮手。
TIME_WAIT
什么是MSL?
MSL(Maximum Segment Lifetime) :最長報文段壽命,它是任何報文在網絡上存在的最長時間,超過這個時間報文將被丟棄。
TIME_WAIT狀態存在的原因
主動關閉端 收到 被動關閉端 的 (FIN,ACK)報文 后并不立刻進入 CLOSED狀態 。而是等待 2MSL 時間。
- 防止 舊連接 的
TCP報文段出現在 新連接 中。 - 確保 主動關閉端 最后一次
ACK 報文能到達 被動關閉端 ,這樣 被動關閉端 就可以進入CLOSED狀態。
第二點詳細來說:
如果過了一個MSL時間,被動關閉端還沒有收到主動關閉端第四次揮手報文,被動關閉端啟動 超時重傳機制 ,重發第三次揮手報文,主動關閉端再一次收到第三次揮手報文 ,就知道自己之前發送的第四次揮手報文丟了,因此重置時間等待計時器為2MSL,并且重發ACK報文,從而確保雙方都可以進入CLOSED狀態。
如果總是能收到第三次揮手報文、但第四次揮手報文一直丟,那也只能一直發第三次揮手報文了,直到達到超時重傳次數上限,被動關閉端不再重傳,直接進入CLOSED狀態。下面我們分析另一種情況:如果第二次重傳的 第三次揮手報文 丟了怎么辦呢?
首先明確如果第二次重傳的 第三次揮手報文 丟了,肯定要進行第三次重傳,那就分為下面兩種情況:
- 若干個(超時重傳次數上限)第三次揮手報文 都丟在半路上了,那么主動關閉端早已進入
CLOSED狀態。被動關閉端根據 超時重傳機制 ,此時TCP認為網絡或者對端主機出現異常,強制關閉連接。 - 如果 第三次重傳 的 第三次揮手報文 到達主動關閉端,但此時已經過了2MSL,那么主動關閉端會進入
CLOSED狀態,此時主動關閉端不會理會這個報文,而是直接丟棄,不會發送ACK報文回應。那么其實就跟上一種情況沒什么區別了。
更多關于重傳的內容可以參考這篇博客。
避免TIME_WAIT狀態
有時候我們希望避免 TIME_WAIT狀態,比如:服務端 主動關閉連接之后想立刻與 剛斷開的客戶端 重新連接。但是因為服務端總使用同一個 知名服務端口號 與客戶端通信,舊連接的斷開導致這個 知名服務端口號 仍處于 TIME_WAIT狀態 ,導致不能立即重新建立連接。那么有兩種方法避免 TIME_WAIT狀態 :
- 通過
socket選項SO_REUSEADDR來強制進程 立即使用 處于TIME_WAIT狀態的 舊連接 占用的 端口 。 - 修改內核參數
/proc/sys/net/ipv4/tcp_tw_recycle來快速回收被關閉的socket,從而使得TCP連接根本就不進入TIME_WAIT狀態。
值得一提的是,由于客戶端一般使用系統自動分配的臨時端口號來建立連接,基于隨機性,臨時端口號一般和程序上一次使用的端口號(還處于TIME_WAIT的連接使用的端口號)不同,因此客戶端程序一般可以立即重啟。
一臺主機上出現大量的TIME_WAIT是什么原因?如何處理?
TIME_WAIT狀態是出現在主動關閉方的,如果出現大量的TIME_WAIT,就說明有大量的連接被主動關閉,可能是惡意攻擊或者爬蟲等。處理方法——使用上文中 避免TIME_WAIT狀態的兩種方法。
一臺主機上出現大量的CLOSE_WAIT是什么原因?如何處理?
CLOSE_WAIT狀態是在 被動關閉方 收到 主動關閉方的FIN 后進入的,此時 被動關閉方 會等待 上層應用 處理積壓數據,處理結束后才會發送FIN。而如果出現大量的CLOSE_WAIT,則說明 被動關閉方的上層應用處理有問題 ,沒有正確的關閉SOCKET釋放資源,所以此時就不會發送FIN,導致一直卡在CLOSE_WAIT。解決方法:查代碼bug,因為問題出在服務器程序里……
保活機制
在TCP通信中,如果兩端長時間沒有數據往來(默認7200秒),則每隔一段時間(默認75秒),服務端就會向客戶端發送一個保活探測數據報,讓客戶端進行回復,如果多次(默認9次)沒有收到響應,則代表連接已經斷開。
通過保活機制來確保如果有一端斷開,能夠及時處理。
TCP的數據類型
交互/成塊數據流
TCP報文段所攜帶的應用程序數據按照長度分為兩種:交互數據、成塊數據。
交互數據流
交互數據僅包含很少的字節。使用交互數據的應用程序或協議對實時性要求很高。 如:telnet、ssh等。
在廣域網上的交互數據流可能經受很大的延遲,攜帶交互數據的微小TCP報文段數量很多(一個鍵入就可能導致一個TCP報文段),很可能導致網絡擁塞。交互數據流導致的網絡擁塞可通過Nagle算法解決。
成塊數據流
成塊數據的長度通常為TCP報文段允許的最大數據長度(40字節)。使用成塊數據的應用程序或協議對傳輸效率要求很高。比如:ftp。
帶外數據
概念
帶外數據(Out Of Band):用于迅速通告對方本端發生的重要事件。因此,帶外數據比普通數據(也成為帶內數據)有更高的優先級,應該總是立即被發送。帶外數據的傳輸可以使用一條獨立的傳輸層連接,也可以映射到傳輸普通數據的連接中。 實際應用中,帶外數據的使用很少見,已知的僅有telnet、ftp等遠程非活躍程序。
UDP沒有實現帶外數據傳輸,TCP也沒有真正的帶外數據。但是TCP利用頭部中的 緊急指針標志 和 緊急指針 兩個字段,給應用程序提供了一種緊急方式。緊急方式利用傳輸普通數據的連接來傳輸緊急數據,來模擬帶外數據的傳輸。
格式
發送端一次發送的多字節帶外數據中只有最后一字節被當作帶外數據,其他數據被當成普通數據。帶有帶外數據的TCP報文段頭部將被設置 URG標志 ,緊急指針指向最后一個帶外數據的下一個字節。
發送
如果含有帶外數據的數據流很長,TCP模塊將以多個TCP報文段來發送,每個報文段都設置URG標志,并且它們的緊急指針指向同一個位置——數據流中帶外數據的下一個位置,但只有一個TCP報文段真正攜帶帶外數據。
接收
接收端在接收到URG標志時開始檢查緊急指針,根據指向位置確定帶外數據位置,并將它讀入只有 1 字節 的 帶外緩存 中。如果上層應用程序沒有及時將帶外數據從帶外緩存中讀出,則下一個數據流的帶外數據(如果有的話)將覆蓋它。
上面討論的接收過程是默認方式,而當給TCP連接設置了SO_OBBINLINE選項(詳見socket編程的相關博客)后,帶外數據和普通數據一樣存放在 TCP接收緩沖區 中,這種情況下如何區分帶外數據和普通數據呢?
- 緊急指針可以指出帶外數據的位置
- socket編程接口也提供了系統調用來識別帶外數據
TCP粘包
對于TCP來說,每當創建一個 socket 的時候,就會同時在內核中創建一個 接收緩沖區 和 發送緩沖區 。
-
接收緩沖區: 對于接收到的數據,并非像UDP一樣一條一條往上交付,而是先將接收到的數據放入緩沖區,再根據上層所需要的長度,從接收緩沖區中取出相應的數據交付。
-
發送緩沖區: 對于發送的數據并不會直接發送,而是先存入發送緩沖區。如果數據過大,則會被拆分成多個TCP數據包發送(成塊數據流)。而如果數據過小(交互數據流),則會在發送緩沖區中等待,積累一定的微量數據后再從發送緩沖區中取出數據發送。【延遲發送機制,亦可選擇不存入緩沖區直接發送。】
-
優點: 這種傳輸方式比較靈活,對于多個小數據,會合并為一條大的數據一次性發送過去,這樣就大大的減少了發送端IO的次數和網絡中的報文數量。接收方式也很靈活,接收端可以從接收緩沖區任意讀取想要的數據,不必像UDP一樣必須交付一條完整的報文。
-
缺點: 因為數據會在緩沖區中進行合并或者拆分,這就導致了數據直接的邊界無法控制,所以TCP交付上層應用程序的這條數據可能并非一條完整的數據,而是半條或者多條數據,從而導致上層會將多條數據按照一條來處理。這也就是TCP粘包問題。
TCP粘包:TCP可能將多條數據按照一條交付給上層應用程序。
解決方案:自行管理邊界
- 每條數據之間以特殊字符進行間隔(如果數據中有該字符可能要轉義處理)
- 數據定長傳輸,不夠則補位(數據如果過短,則會傳遞大量無用的補位數據)
- 應用層協議頭部定義數據長度(這里可以參考
HTTP協議和UDP協議的做法)- HTTP協議: 頭部以
\r\n表示結束,并且在頭部的Content-Length確定正文長度。 - UDP協議: 在首部中定義了數據報長度,確保每次只交付一條完整的數據。
- HTTP協議: 頭部以
基于TCP的應用層知名協議
- HTTP
- HTTPS
- SSH
- Telnet
- FTP
- SMTP


| 數據類型、常用命令一覽、庫的操作、表的操作)


| 表的增刪查改、聚合函數(復合函數)、聯合查詢)



:模板基礎:函數模板、類模板、模板推演成函數的機制、模板實例化、模板匹配規則)

:非類型模板參數,模板特化,模板的分離編譯)




)


