文章目錄
- 物理內存
- 物理內存分配
- 外部碎片
- 內部碎片
- 伙伴系統(buddy system)
- slab分配器
物理內存
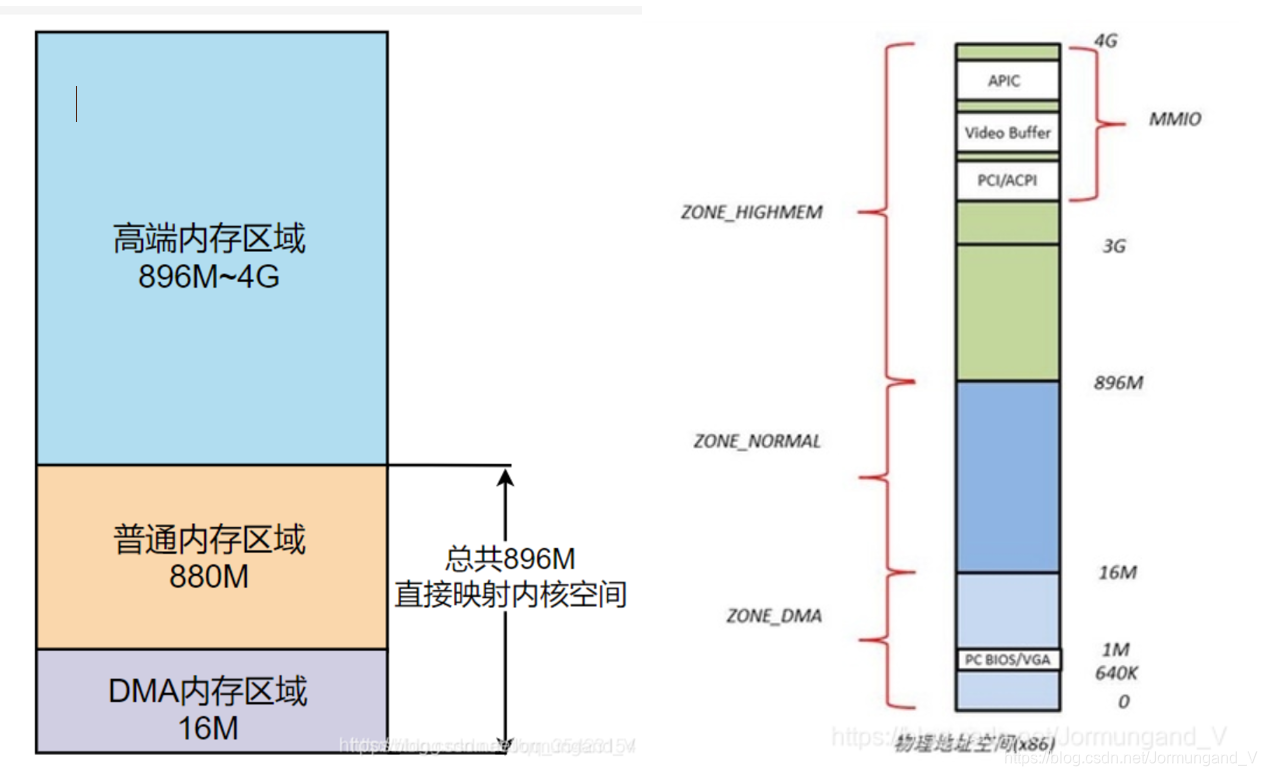
在Linux中,內核將物理內存劃分為三個區域。
在解釋DMA內存區域之前解釋一下什么是DMA:
DMA(直接存儲器訪問) 使用物理地址訪問內存,將數據從一個地址空間復制到另外一個地址空間,從而加快磁盤和內存之間數據的交換,不經過MMU(內存管理單元),這時CPU可以去干別的事,大大增加了效率。
- DMA內存區域(ZONE_DMA): 包含
0M~16M之內的內存頁框,該區域的物理頁面專門供I/O設備的DMA使用,DMA需要連續的緩沖區,為了能夠提供物理上連續的緩沖區,必須從物理地址空間專門劃分一段區域用于DMA。 - 普通內存區域(ZONE_NORMAL): 包含
16MB~896M以上的內存頁框,可以直接映射到內核空間中的直接映射區。 - 高端內存區域(ZONE_HIGHMEM): 包含
896M以上的內存頁框,不可以進行直接映射,可以通過高端內存映射區中的永久內存映射區以及臨時內存映射區(固定內存映射區中的一部分) 來對這塊物理內存進行訪問。
內存分布如下圖:
物理內存分配
在Linux中,通過分段和分頁的機制,將物理內存劃分為4k大小的內存頁(page),并且將頁作為物理內存分配與回收的基本單位。通過分頁機制我們可以靈活的對內存進行管理。
- 如果用戶申請了小塊內存,我們可以直接分配一頁給它,就可以避免因為頻繁的申請、釋放小塊內存而發起的系統調用帶來的消耗。
- 如果用戶申請了大塊內存,我們可以將多個頁框組合成一大塊內存后再進行分配,非常的靈活。
但是,這種直接的內存分配非常容易導致內存碎片的出現,下面就分別介紹內部碎片和外部碎片這兩種內存碎片。
為了方便接下來的閱讀,這里科普一下 頁 和 頁框 :
- 分頁單元認為所有的RAM被分成了固定長度的 頁框 ,頁框是主存的一部分,是一個實際的存儲區域。
- 頁 是指一系列的線性地址和包含于其中的數據,每頁被視為一個數據塊。而存放數據塊的物理內存就是 頁框 ,也就是說一個 頁框 的長度和一個 頁 的長度是一樣的, 頁 可以存放在任何頁框或磁盤中。
外部碎片
當我們需要分配大塊內存時,操作系統會將連續的頁框組合起來,形成大塊內存,來將其分配給用戶。但是,頻繁的申請和釋放內存頁,就會帶來 內存外碎片 的問題,如下圖。

假設我們這塊內存塊中有10個頁框,我們一開始先是分配了3個頁框給 進程A ,而后又分配了5個頁框給 進程B 。當進程A結束后,其釋放了申請的3個頁框,此時我們剩余空間就是內存塊起始位置的3個頁框,以及末尾位置的2個頁框。
假如此時我們運行了 進程C ,其需要5個頁框的內存,此時雖然這塊內存中還剩下5個頁框,但是由于我們頻繁的申請和釋放小塊空間導致內存碎片化,因此如果我們想申請5個頁框的空間,只能到其他的內存塊中申請,這塊內存的空閑頁框就被浪費了。
要想解決 外部碎片 的問題,無非就兩種方法:
- 外碎片問題的本質就是
空閑頁框不連續,所以可以將非連續的空閑頁框映射到連續的虛擬地址空間,如果現存的空閑頁框總大小滿足進程的需求,則允許將一個進程分散地分配到許多不相鄰的分區中,從而避免直接申請新的內存塊; - 記錄現存的
連續空閑頁框塊的情況,如果有 能滿足的小塊內存需求 直接從記錄中分配 相等或大于 內存需求的連續空閑頁框塊,從而避免直接申請新的內存塊。
第一種方法就是將上面舉例中的 C進程 一部分分配到前面的 3個頁框 , 另一部分分配到后面的 2個頁框 ,如此一來不用申請新的內存塊即可滿足C進程的需求,詳細內容將在分頁知識中講述。
第二種方法就是,雖然 C進程 要申請新的內存塊,但是如果接下來 A進程 又開始運行,那我們就將 B進程 所在的內存塊中 3塊連續空閑頁框塊 分配給 A進程 而不是直接申請新的 10塊連續頁框 分配給 A進程 。
Linux選擇了第二種方法,引入 伙伴系統算法 ,來解決 外部碎片 的問題。
內部碎片
內部碎片 是 頁 的未被利用的空閑區域。一開始的時候也說了,由于頁是物理內存分配的基本單位,因此即使我們需求的內存很小,Linux也會至少給我們分配 4k 的內存頁,此時會造成內存浪費。
舉個例子:當一個進程需要 7K 大小的內存時,我們必須給他分配 2個頁框 以滿足需求,但是第 2 個頁框我們只使用了其中 3K 的內存,因此有 1K 的內存被浪費掉了。

如上圖,倘若我們需求的只有幾個字節,那該內存頁中又有大量的空間未被使用,就造成了內存浪費的問題,而如果我們頻繁的進行小塊內存的申請,這種浪費現象就會愈發嚴重。
內碎片問題的本質就是 頁內空閑內存 無法被其他進程再次利用。而 SLAB分配器 就可以 對內部碎片進行再利用 ,從而解決內部碎片問題。
伙伴系統(buddy system)
什么是伙伴系統算法呢?其實就是 把相同大小的連續頁框塊用鏈表串起來 ,這使頁框之間看起來就像是手拉手的伙伴,這也就是其名字的由來。
伙伴系統將所有的空閑頁框分組為11塊鏈表,每個塊鏈表分別包含大小為1,2,4,8,16,32,64,128,256,512和1024個連續頁框的頁框塊,即2的0~10次方,最大可以申請 1024 個連續頁框,對應 4MB(最大連續頁框數 * 每個頁的大小 = 1024 * 4k) 大小的連續內存。每個頁框塊的第一個頁框的物理地址是該塊大小的整數倍。

因為任何正整數都可以由 2^n 的和組成,所以我們總能通過拆分與合并,來找到合適大小的內存塊分配出去,減少了外部碎片產生 。
倘若我們需要分配1MB的空間,即256個頁框的塊,我們就會去查找在256個頁框的鏈表中是否存在一個空閑塊,如果沒有,則繼續往下查找更大的鏈表,如查找512個頁框的鏈表。如果存在空閑塊,則將其拆分為兩個256個頁框的塊,一個用來進行分配,另一個則放入256個頁框的鏈表中。
釋放時也同理,它會將多個連續且空閑的頁框塊進行合并為一個更大的頁框塊,放入更大的鏈表中。
slab分配器
雖然伙伴系統很好的解決了外部碎片的問題,但是它還是以頁作為內存分配和釋放的單位,而我們在實際的應用中則是以字節為單位,例如我們要申請2個字節的空間,其還是會向我們分配一頁,也就是 4096字節(4K) 的內存,因此其還是會存在內部碎片的問題。
為了解決這個問題,slab分配器就應運而生了。其以 字節 為基本單位,專門用于對 小塊內存 進行分配。slab分配器并未脫離伙伴系統,而是對伙伴系統的補充,它將伙伴系統分配的大內存進一步細化為小內存分配(對內部碎片的再利用)。
那么它的原理是什么呢?
對于內核對象,生命周期通常是這樣的: 分配內存->初始化->釋放內存 。而內核中如文件描述符、pcb等小對象又非常多,如果按照伙伴系統按頁分配和釋放內存,不僅存在大量的空間浪費,還會因為頻繁對小對象進行 分配-初始化-釋放 這些操作而導致性能的消耗。
所以為了解決這個問題,對于內核中這些需要重復使用的小型數據對象,slab通過一個緩存池來緩存這些常用的已初始化的對象 。
- 當我們需要申請這些小對象時,就會直接從緩存池中的slab列表中分配一個出去。
- 而當我們需要釋放時,我們不會將其返回給伙伴系統進行釋放,而是將其重新保存在緩存池的slab列表中。
通過這種方法,不僅避免了內部碎片的問題,還大大的提高了內存分配的性能。
PS:這里說的 緩存池 是對真正的緩存—— 硬件緩存(cache) 原理的一種模仿:
- 硬件緩存是為了解決快速的CPU和速度較慢的內存之間速度不匹配的問題,CPU訪問cache的速度要快于內存,如果將常用的數據放到硬件緩存中,使用時CPU
直接訪問cache而不再訪問內存,從而提升系統速度。 - 而這里的
緩存池實際上使在內存中預先開辟一塊空間,使用時直接從這一塊空間中去取所需對象(訪問的是內存而不是cache),是SLAB分配器為了便于對小塊內存的管理而建立的。
下面就由大到小,來畫出底層的數據結構:

slab 分配器把每一個 請求的內存 稱之為 對象 ,每種 對象 分配一個 高速緩存(kmem_cache) ,所有的 高速緩存 通過雙鏈表組織在一起,形成 高速緩存鏈表(cache_chain) ,每個 高速緩存 所占內存區被劃分為多個 slab ,這些 slab 都屬于一個 slab列表 ,每個 slab列表 是一段連續的內存塊,并包含3種類型的 slabs鏈表 :
- slabs_full(完全分配的slab)
- slabs_partial(部分分配的slab)
- slabs_empty(空slab,或者沒有對象被分配)。
slab 是 slab分配器的 最小單位 ,在具體實現上一個 slab 由一個或者多個連續的物理頁組成(通常只有一頁)。單個 slab 可以在 slab鏈表 中進行移動,例如一個 未滿的slab節點 ,其原本在 slabs_partial 鏈表中,如果它由于分配對象而變滿,就需要從原先的 slabs_partial 中刪除,插入到完全分配的鏈表 slabs_full 中。
舉個具象的例子:
slab分配器 將進程描述符和索引節點對象放在一個 cache_chain ,該 cache_chain 下轄兩個 kmem_cache :一個 kmem_cache 用于存放進程描述符,而另一個 kmem_cache 存放索引節點對象,然后這些 kmem_cache 又被劃分為多個 slab ,每個 slab 都管轄著若干個對象(進程描述符/索引節點對象),而這些 slab 又根據狀態(已滿、半滿、全空)分布在3個 slabs鏈表 中,3個 slabs鏈表 共同構成一個 slab列表 。
舉個例子以說明slab的分配過程:
如果在 cache_chain 里有一個名叫 inode_cachep 的 kmem_cache 節點,它存放了一些 inode 對象。當內核請求分配一個新的 inode 對象時,slab分配器 就開始工作了:
- 首先要查看
inode_cachep的slabs_partial鏈表,如果slabs_partial非空,就從中選中一個slab, 返回一個指向已分配但未使用的inode結構的指針。 完事之后,如果這個slab滿了,就把它從slabs_partial中刪除,插入到slabs_full中去,結束; - 如果
slabs_partial為空,也就是沒有半滿的slab,就會到slabs_empty中尋找。如果slabs_empty非空,就選中一個slab, 返回一個指向已分配但未使用的inode結構的指針 ,然后將這個slab從slabs_empty中刪除,插入到slabs_partial(或者slab_full)中去,結束; - 如果
slabs_empty也為空,那么沒辦法,cache_chain內存已經不足,只能新創建一個slab了。
內核中slab分配對象的全過程:
- 根據對象的類型找到
cache_chain中對應的高速緩存kmem_cache - 如果
slabs_partial鏈表非空,則選擇其中一個slab,將slab中一個未分配的對象分配給需求來源。如果分配之后這個slab已滿,則移動這個slab到slabs_full鏈表 - 如果
slabs_partial鏈表沒有未分配的空間,則去查看slabs_empty鏈表 - 如果
slabs_empty非空,則選擇其中一個slab,將slab中一個未分配的對象分配給需求來源,同時移動slab進入slabs_partial鏈表中 - 如果
slabs_empty也沒有未分配的空間,則說明此時空間不足,就會請求伙伴系統分頁,并創建新的空閑slab節點放入slabs_empty鏈表中,回到步驟3
從上面可以看出,slab分配器的本質其實就是 將內存按使用對象不同再劃分成不同大小的空間,即對內核對象的緩存操作 。



、進程地址空間)


調用))
【標準流和其文件描述符、fwrite函數、perror函數】)







| 數據類型、常用命令一覽、庫的操作、表的操作)


| 表的增刪查改、聚合函數(復合函數)、聯合查詢)
