文章目錄
- 概念
- URL
- HTTP協議的特點
- HTTP協議版本
- 格式
- 請求報文
- 首行
- 頭部
- 空行
- 正文
- 響應報文
- 首行
- 頭部
- 空行
- 正文
- Cookie與Session
- HTTP代理服務器
- 正向代理服務器
- 反向代理服務器
- 透明代理服務器
概念
先了解一下 因特網(Internet) 與 萬維網(World Wide Web)。
因特網是使用 IP(Internet Protocol,因特網協議) 連接在一起的計算機構成的網絡。因特網上有很多服務,包括萬維網,以及電子郵件、文件共享、因特網電話等。因此,萬維網(World Wide Web,簡稱Web)只是因特網上的一種服務形式。
Tim Berners-Lee 當初發明萬維網時,一共創造了三項核心技術:
- HTTP協議: 超文本傳輸協議,是用于從 萬維網服務器 傳輸 超文本 到 本地瀏覽器 的傳送協議。
- URL(Uniform Resource Locator): 統一資源定位符,用于標識唯一資源,也就是我們通常所說的網址。
- HTML(Hypertext Markup Language): 超文本標記語言,用于構造網頁的。
說到HTTP,其實主要是說萬維網。但隨著越來越多的服務甚至一些沒有 傳統Web前端界面 的服務開始使用HTTP,這個界限變得越來越模糊。比如,你可以在自己的手機應用中通過HTTP向家里的燈發出開或關的指令。
那么日常中瀏覽器向web服務器請求網頁時交互過程是怎樣的呢?
- 瀏覽器根據
DNS(Domain Name System,域名系統)服務器返回的真實地址請求網頁。DNS主要負責把對人類友好的域名www.google.com轉換為對機器友好的IP地址。
PS:我們常說的網址和域名有什么區別?比如https://www.baidu.com/這就是一個網址,而域名指的是www.baidu.com這一部分。 - 瀏覽器請求計算機建立對這個
IP地址的標準Web端口(80,QUIC協議常用)或標準安全Web端口(443,HTTPS協議常用)的TCP(Transmission Control Protocol,傳輸控制協議)連接。 - 瀏覽器連接到
Web服務器之后會請求網站。這一步就要用到HTTP了,具體細節我們在下面討論。現在,只需知道瀏覽器會使用HTTP向Google的服務器請求Google主頁就行了。 web服務器會根據請求的URL響應相關內容。訪問成功會返回HTML格式的網頁文本,訪問錯誤則會返回對應的HTTP響應碼。Web瀏覽器負責處理返回的響應。假設返回的響應是HTML,則瀏覽器就會解析HTML中的代碼,并在內存中構建DOM(Document Object Model,文檔對象模型),一種頁面的內部表現形式。處理期間,瀏覽器可能會發現正常顯示頁面還需要 其他資源(比如CSS、JavaScript和圖片)。- 如果正常顯示頁面還需要其他資源,
Web瀏覽器會請求自己需要的額外資源。而每次請求額外資源時,都必須重復1~6步。這是導致上網慢的一個重要因素,因而催生了HTTP/2,其主要目的是使得請求多資源時更有效率。 - 瀏覽器在獲取了足夠的關鍵資源后,開始在屏幕上渲染頁面。但是,選擇在屏幕上渲染的時機又是一個挑戰:如果瀏覽器等到所有資源都下載完畢才渲染,那么用戶就要等很久才能看到網頁,上網的體驗會很差。相反,如果瀏覽器過早渲染頁面,那么伴隨著更多資源下載,頁面結構也會跳來跳去。假如你正在閱讀一篇文章,而頁面突然抖動了一下,你不生氣才怪。
- 在頁面剛剛顯示在屏幕上之后,瀏覽器會在后臺繼續下載其他資源,并在處理完它們之后更新頁面。這些資源包括不那么重要的圖片和廣告追蹤腳本。因此,我們經常會看到網頁剛顯示時并沒有圖片(特別是在網速比較慢的情況下),而過了一會兒圖片才慢慢下載并顯示出來。
- 當頁面完全被加載后,瀏覽器會停止顯示加載圖標(在多數瀏覽器上都位于地址欄旁邊),然后觸發
OnLoad JavaScript事件。根據這個事件,JavaScript就知道可以執行某些操作了。 - 此時,頁面已經完全加載了,但瀏覽器并不會停止發送請求。 網頁只包含靜態內容的時代早就過去了。如今的很多網頁其實已經是功能齊全的應用了,因此接下來瀏覽器還會發送或加載更多內容。
- 這些內容有的來自用戶輸入,比如你在
Google主頁的搜索框中填寫了一個關鍵字,但沒有按搜索按鈕就立即看到了搜索建議; - 有的來自應用驅動的操作,比如你的
QQ或者微博動態,不需要你點擊刷新按鈕就能自動刷新。
這些操作通常在后面悄悄發生,你看不到它們,特別是廣告分析腳本,它會跟蹤你在網站上的操作,并將該信息發送給站長或者廣告服務商。
- 這些內容有的來自用戶輸入,比如你在
URL
URL:統一資源定位符,用于在網絡中定位某臺主機上的某一個資源,
URL由以下幾部分組成
協議 :// 用戶名 : 密碼 @ 服務器IP地址 : 服務器端口 / 文件路徑 ? 查詢字符串 # 片段標識符
- 協議: 請求需要使用的協議,現在通常為
HTTP、HTTPS。 - 用戶名密碼: 認證用戶的用戶名密碼,為了安全一般都不會顯示。
- 服務器地址: 這里通常都不會是IP地址,而是域名,通過域名解析服務器(DNS服務器)就能夠得到服務器的IP地址。
- 服務器端口: HTTP協議的端口默認是80,但也可以選擇其他的,默認是不顯示的。
- 文件路徑: 即請求的資源在服務器上的存儲路徑。
- 查詢字符串: 客戶端請求中的額外參數,由
key=value的鍵值對組成,以&作為分隔符。 - 片段標識符: HTML的
標簽id,可以直接跳轉到頁面的某個位置。
詳情可參考這篇博客
以B站為例:

對于 ? # / : 等特殊字符,會通過 urlencode 的方式進行轉義。轉義的規則如下:
將需要轉碼的字符轉為 16進制 ,然后從右到左,取 4位(不足4位直接處理) ,每 2位 做 1位,前面加上 % ,編碼成 %XY 格式
舉例:
-
當我們在百度中搜索時:

-
但是如果我們將網址復制出來就會成這樣:

這種將 特殊字符(包括漢字) 轉變為 16進制的額過程被稱為 urlencode ,反過來就是一個 urldecode 過程。
HTTP協議的特點
-
HTTP是無連接:
無連接的含義是限制每次連接只處理一個請求。服務端處理客戶端的請求,并收到客戶的應答后,即斷開連接。采用這種方式可以節省傳輸時間,亦不用花費資源維護連接。 -
HTTP是靈活的:
只要客戶端和服務器知道如何處理的數據內容,任何類型的數據都可以通過HTTP發送。通過頭部中的Content-Type來標記正在傳輸的類型 -
HTTP是無狀態的:
無狀態是指對于事務處理沒有記憶能力,服務器不知道客戶端是什么狀態,即我們給服務器發送HTTP請求之后,服務器會根據請求給我們發送數據過來,但是發送完后不會記錄任何信息。
無狀態是一把雙刃劍,如果處理當前請求時需要之前的信息,則必須重傳,這樣可能導致每次連接傳送的數據量增大。而如果服務器不需要先前信息時,它的應答就較快。
HTTP協議版本
HTTP協議有 5 個版本,分別是 0.9、1.0、1.1、2.0、3.0 。
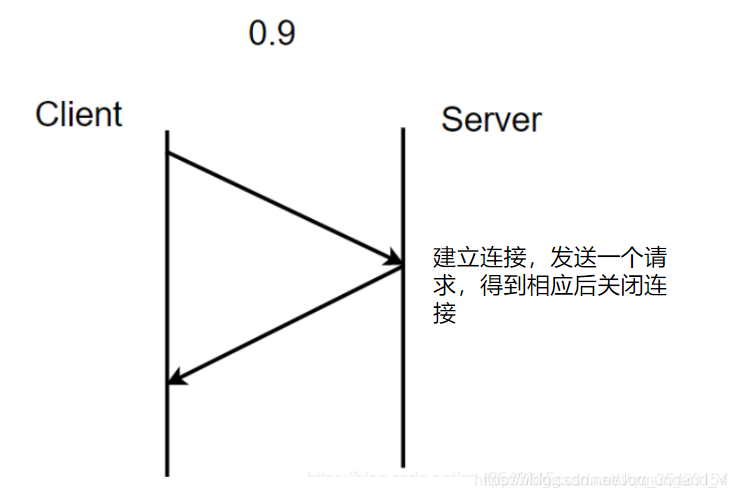
0.9版本:
- 這時的HTTP協議 沒有標準格式 ,僅用于傳輸HTML(超文本標記語言)數據。
- 請求方法只有
GET。 - 連接方式為 短連接: 建立連接,發送一個請求,得到相應后關閉連接。
1.0版本:
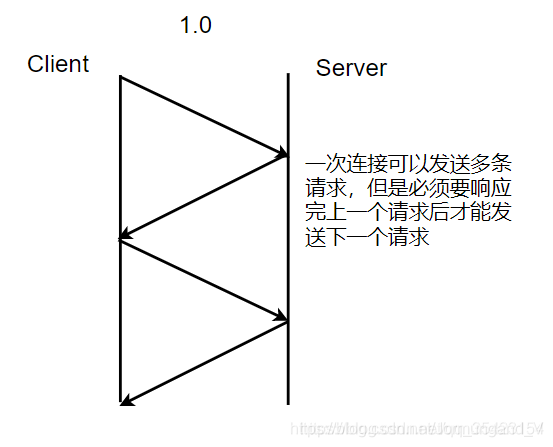
- 正式規定了HTTP協議格式,支持不同文件格式的數據流.
- 同時部分應用商已經開始使用 優化的短連接: 一次連接可以發送多條請求。
- 定義了三種請求方法:
GET、POST和HEAD方法。
1.1版本:
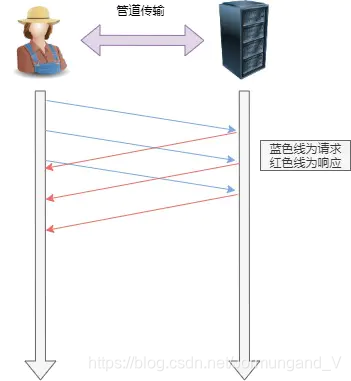
- 增加了更多的請求方法和頭部描述信息,并支持長連接和管線化傳輸。
- 新增了五種請求方法:
OPTIONS、PUT、DELETE、TRACE和CONNECT方法 - 管線化傳輸:可以連續發送多個請求,只要 按順序響應 就行,不需要響應后才發下一個請求。
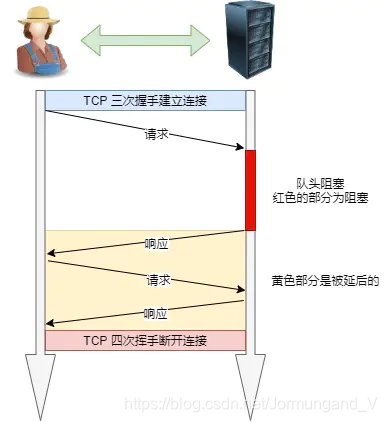
但是還存在約束條件,響應的順序必須與請求的順序保持一致,通過隊列實現,如果不一致則在 隊首阻塞 。
隊頭阻塞: 當順序發送的請求序列中的一個請求因為某種原因被阻塞時,在后面排隊的所有請求也一同被阻塞了,導致客戶端一直請求不到數據。
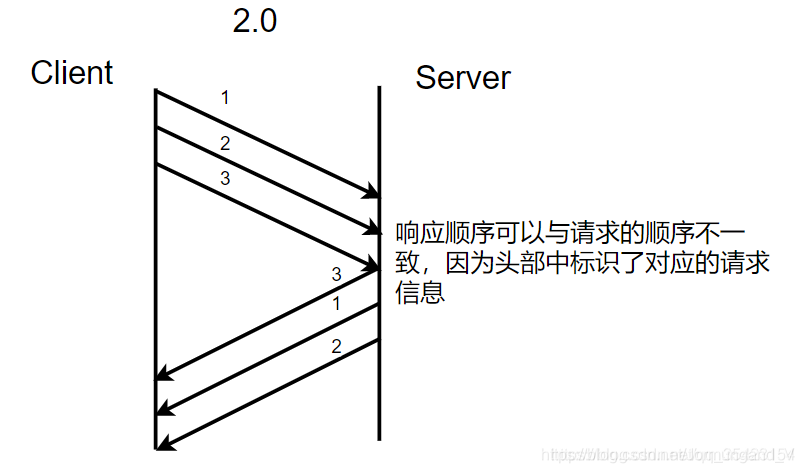
2.0版本:
- 采用二進制流傳輸,并且進行多路復用,允許服務端主動推送數據。
- 多路復用:響應順序可以與請求的順序不一致,因為頭部中標識了對應的請求信息,提高了信道的利用率。
3.0版本:
在 3.0 版本中 HTTP 采取了革命性的變化,其將網絡協議從 TCP 切換至 QUIC (Quick UDP Internet Connections), 快速 UDP 互聯網連接。 QUIC 是基于 UDP協議 的。
QUIC 協議主要解決了兩個問題:
- 線頭阻塞問題: 基于
TCP的HTTP2.0的多路復用機制,盡管從邏輯上來說,不同的流之間相互獨立,不會相互影響,但在實際傳輸方面,數據還是要一幀一幀的發送和接收,一旦某一個流的數據有丟包,則同樣會阻塞在它之后傳輸的流數據傳輸。而基于UDP的QUIC協議則可以更為徹底地解決這樣的問題,讓不同的流之間真正的實現相互獨立傳輸,互不干擾。 - 切換網絡時的連接保持: 當前移動端的應用環境,用戶的網絡可能會經常切換,比如從辦公室或家里出門,WiFi斷開,網絡切換為移動網絡。基于TCP的協議,由于切換網絡之后,IP會改變,因而之前的連接不可能繼續保持。而基于UDP的QUIC協議,則可以內建與TCP中不同的連接標識方法,從而在網絡完成切換之后,恢復之前與服務器的連接。
格式
請求報文
HTTP報文由 從客戶機到服務器的請求 和 從服務器到客戶機的響應 構成。請求報文格式如下:
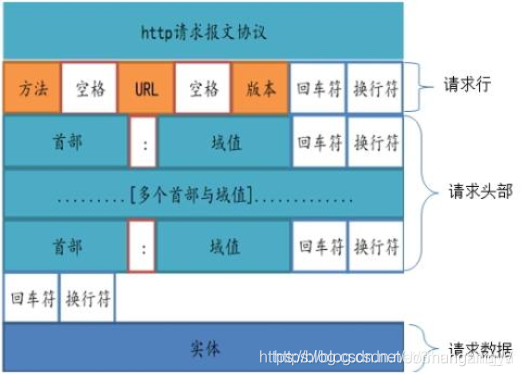
首行
[請求方法] [URL] [協議版本]\r\n
| 請求方法 | 功能 |
|---|---|
| GET | 請求指定的頁面信息,并返回實體主體。一般將數據放到 URL 中. |
| HEAD | 類似于 GET 請求,只不過返回的響應中沒有具體的內容,用于獲取報頭。 |
| POST | 向指定資源提交數據進行處理請求(例如提交表單或者上傳文件)。數據被包含在 請求正文 中。POST請求可能會導致新的資源的建立 和/或 已有資源的修改。 |
| PUT | 從客戶端向服務器傳送的數據取代指定的文檔的內容。 |
| DELETE | 請求服務器刪除指定的頁面。 |
| CONNEC | HTTP/1.1 協議中預留給能夠將連接改為管道方式的代理服務器。 |
| OPTIONS | 允許客戶端查看服務器的性能。 |
| TRACE | 回顯服務器收到的請求,主要用于測試或診斷。 |
| PATCH | 是對 PUT方法的補充,用來對已知資源進行局部更新 。 |
GET 和 POST有什么區別?
- 請求緩存:
GET會被緩存,而POST不會。 POST比GET更安全,POST將數據存儲在實體中,而GET將數據存儲在url中,頁面會被瀏覽器緩存,其他人查看歷史記錄會看到提交的數據。但事實上,數據的安全性通常由HTTPS協議來保障,POST只是不能選擇HTTPS協議下的無奈之舉。GET僅支持urlencode編碼,POST由于數據是放在body中的,因此支持多種編碼。- 請求參數長度限制:由于
url是定長的(每個瀏覽器有不同的規定),因此GET請求長度有限制,POST對請求數據沒有限制。
“安全”的請求方法:
HEAD、GET、OPTIONS和TRACE只從服務器獲得資源或信息,而不對服務器做任何修改,因此被稱為安全的方法。POST、PUT、DELETE和PATCH則影響服務器上的資源。
冪等性
冪等性(idempotent):即多次連續的、重復的請求和只發送一次該請求具有完全相同的效果。
HEAD、GET、OPTIONS、PUT、DELETE和TRACE是冪等的。POST不是冪等的。
誤區
值得一提的是,雖然在上述介紹請求方法時,對他們的功能進行了解釋,但據凌桓大佬所言,如果死板地記憶請求方法和對應功能反而落入窠臼之中,例如, PUT 和 POST 往往可以實現相同的功能,在 RESTful 軟件架構風格下就是這樣。
詳情見大佬的博客。
頭部
描述本次請求的關鍵字段信息,由 key:value 形式的鍵值對組成,并且每個鍵值對以 \r\n 作為結尾。

HTTP請求報文常用的Header:

短鏈接和長連接的表示
我們在協議版本部分中提到的 短鏈接 和 長連接 ,其就是由 Connection 頭部不同的值來標識的:
close:短鏈接,處理完請求后立即關閉連接。keep-alive:長連接,處理完請求后保持一段時間以等待后續請求。
空行
空行即為 \r\n,用于間隔頭部和正文。因為頭部的每一個鍵值對以 \r\n 結束,所以一旦連續接受到兩個 \r\n 的時候就代表著頭部的接收結束。
正文
客戶端提交的數據,允許為空字符串。

響應報文
響應報文格式如下:
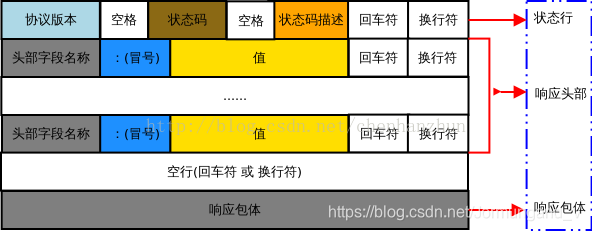
首行
[協議版本] [響應狀態碼] [響應狀態碼描述]\r\n

響應狀態碼: 對于本次請求,服務端做出的響應結果。
狀態碼描述: 對狀態碼的描述信息,可自定義。
HTTP的響應狀態碼:
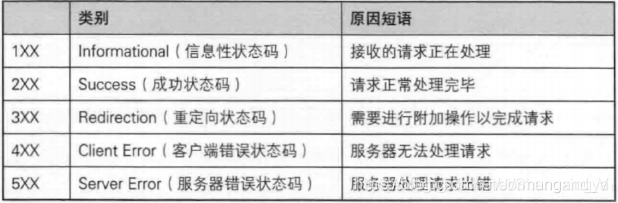
| 消息 | 描述 |
|---|---|
| 1XX Informational | 信息狀態碼,表示接受的請求正在處理。 |
| 100 Continue | 服務器僅接收到部分請求,但是一旦服務器并沒有拒絕該請求,客戶端應該繼續發送其余的請求。 |
| 101 Switching Protocols | 服務器轉換協議:服務器將遵從客戶的請求轉換到另外一種協議。 |
| 2XX Success | 成功狀態碼,表示請求正常處理完畢。 |
| 200 OK | 請求成功(其后是對 GET 和 POST 請求的應答文檔。) |
| 201 Created | 請求被創建完成,同時新的資源被創建。 |
| 202 Accepted | 供處理的請求已被接受,但是處理未完成。 |
| 203 Non-authoritative Information | 文檔已經正常地返回,但一些應答頭可能不正確,因為使用的是文檔的拷貝。 |
| 204 No Content | 沒有新文檔。瀏覽器應該繼續顯示原來的文檔。如果用戶定期地刷新頁面,而 Servlet 可以確定用戶文檔足夠新,這個狀態代碼是很有用的。 |
| 205 Reset Content | 沒有新文檔。但瀏覽器應該重置它所顯示的內容。用來強制瀏覽器清除表單輸入內容。 |
| 206 Partial Content | 客戶發送了一個帶有 Range 頭的 GET請求 ,服務器完成了它。 |
| 3XX Redirection | 重定向狀態碼,需要進行附加操作以完成請求。 |
| 300 Multiple Choices | 多重選擇。鏈接列表。用戶可以選擇某鏈接到達目的地。最多允許五個地址。 |
| 301 Moved Permanently | 所請求的頁面已經轉移至新的 URL 。 |
| 302 Found | 所請求的頁面已經臨時轉移至新的 URL 。 |
| 303 See Other | 所請求的頁面可在別的 URL 下被找到。 |
| 304 Not Modified | 未按預期修改文檔。客戶端有緩沖的文檔并發出了一個條件性的請求(一般是提供 If-Modified-Since 頭表示客戶只想要比指定日期更新的文檔)。服務器告訴客戶,原來緩沖的文檔還可以繼續使用。 |
| 305 Use Proxy | 客戶請求的文檔應該通過Location頭所指明的代理服務器提取。 |
| 306 Unused | 此代碼被用于前一版本。目前已不再使用,但是代碼依然被保留。 |
| 307 Temporary Redirect | 被請求的頁面已經臨時移至新的 URL 。 |
| 4XX Client Error | 客戶端狀態錯誤碼:表示服務器無法處理請求。 |
| 400 Bad Request | 服務器未能理解請求。 |
| 401 Unauthorized | 被請求的頁面需要用戶名和密碼。 |
| 401.1 | 登錄失敗。 |
| 401.2 | 服務器配置導致登錄失敗。 |
| 401.3 | 由于 ACL(訪問控制列表) 對資源的限制而未獲得授權。 |
| 401.4 | 篩選器授權失敗。 |
| 401.5 | ISAPI/CGI 應用程序授權失敗。 |
| 401.7 | 訪問被 Web服務器 上的 URL 授權策略拒絕。這個錯誤代碼為 IIS 6.0 所專用。 |
| 402 Payment Required | 此代碼尚無法使用。 |
| 403 Forbidden | 對被請求頁面的訪問被禁止。 |
| 403.1 | 執行訪問被禁止。 |
| 403.2 | 讀訪問被禁止。 |
| 403.3 | 寫訪問被禁止。 |
| 403.4 | 要求 SSL(安全套接字協議) 。 |
| 403.5 | 要求 SSL 128位證書 。 |
| 403.6 | IP地址被拒絕。 |
| 403.7 | 要求客戶端證書。 |
| 403.8 | 站點訪問被拒絕。 |
| 403.9 | 用戶數過多。 |
| 403.10 | 配置無效。 |
| 403.11 | 密碼更改。 |
| 403.12 | 拒絕訪問映射表。 |
| 403.13 | 客戶端證書被吊銷。 |
| 403.14 | 拒絕目錄列表。 |
| 403.15 | 超出客戶端訪問許可。 |
| 403.16 | 客戶端證書不受信任或無效。 |
| 403.17 | 客戶端證書已過期或尚未生效。 |
| 403.18 | 在當前的應用程序池中不能執行所請求的 URL 。這個錯誤代碼為 IIS 6.0 所專用。 |
| 403.19 | 不能為這個應用程序池中的客戶端執行 CGI 。這個錯誤代碼為 IIS 6.0 所專用。 |
| 403.20 | Passport 登錄失敗。這個錯誤代碼為 IIS 6.0 所專用。 |
| 404 Not Found | 服務器無法找到被請求的頁面。 |
| 404.0 | (無)–沒有找到文件或目錄。 |
| 404.1 | 無法在所請求的端口上訪問Web站點。 |
| 404.2 | Web服務擴展鎖定策略阻止本請求。 |
| 404.3 | MIME 映射策略阻止本請求。 |
| 405 Method Not Allowed | 請求中指定的方法不被允許。 |
| 406 Not Acceptable | 服務器生成的響應無法被客戶端所接受。 |
| 407 Proxy Authentication Required | 用戶必須首先使用代理服務器進行驗證,這樣請求才會被處理。 |
| 408 Request Timeout | 請求超出了服務器的等待時間。 |
| 409 Conflict | 由于沖突,請求無法被完成。 |
| 410 Gone | 被請求的頁面不可用。 |
| 411 Length Required | Content-Length(POST請求報文的長度) 未被定義。如果無此內容,服務器不會接受請求。 |
| 412 Precondition Failed | 請求中的前提條件被服務器評估為失敗。 |
| 413 Request Entity Too Large | 由于所請求的實體的太大,服務器不會接受請求。 |
| 414 Request-url Too Long | 由于 URL 太長,服務器不會接受請求。當post請求被轉換為帶有很長的查詢信息的get請求時,就會發生這種情況。 |
| 415 Unsupported Media Type | 由于媒介類型不被支持,服務器不會接受請求。 |
| 416 Requested Range Not Satisfiable | 服務器不能滿足客戶在請求中指定的Range頭。 |
| 417 Expectation Failed | 執行失敗。 |
| 423 | 鎖定的錯誤。 |
| 5XX Server Error | 服務器狀態錯誤碼:表示服務器處理請求出錯。 |
| 500 Internal Server Error | 請求未完成。服務器遇到不可預知的情況。 |
| 500.12 | 應用程序正忙于在Web服務器上重新啟動。 |
| 500.13 | Web服務器太忙。 |
| 500.15 | 不允許直接請求 Global.asa 。 |
| 500.16 | UNC(通用命名規則) 授權憑據不正確。這個錯誤代碼為 IIS 6.0 所專用。 |
| 500.18 | URL 授權存儲不能打開。這個錯誤代碼為 IIS 6.0 所專用。 |
| 500.100 | 內部 ASP(動態服務器設備) 錯誤。 |
| 501 Not Implemented | 請求未完成。服務器不支持所請求的功能。 |
| 502 Bad Gateway | 請求未完成。服務器從上游服務器收到一個無效的響應。 |
| 502.1 | CGI 應用程序超時。 |
| 502.2 | CGI 應用程序出錯。 |
| 503 Service Unavailable | 請求未完成。服務器臨時過載或宕機。 |
| 504 Gateway Timeout | 網關超時。 |
| 505 HTTP Version Not Supported | 服務器不支持請求中指明的HTTP版本。 |
頭部
描述本次響應的關鍵字段信息,由 key:value 形式的鍵值對組成,并且每個鍵值對以 \r\n 作為結尾。

HTTP響應報文常用的Header:

Set-Cookie
關于 Cookie 的具體內容下文會有講解,這里簡單提一下 Set-Cookie 頭部一般由哪些值構成:
Cookie的名字- ecpires:
Cookie的生存時間 - domain:
Cookie生效的域名 - path :
Cookie生效的路徑
空行
同請求報文空行。
正文
服務端響應的實體資源

顯示為亂碼的原因是使用的是 HTTPS 協議,該協議會對響應的內容加密,中間者無法直接查看明文內容。
Cookie與Session
因為 HTTP 是無狀態的,但在實際情況中,我們還是需要保持狀態的。那么如何讓 HTTP 來保持狀態呢?答案就是借助 Header 中的 Cookie 和 Session 。
cookie 是什么?
Cookie 是服務器(通過應答報文的頭部字段“Set-Cookie”)發送給客戶端的保存了用戶信息的字符串。客戶端每次向服務器發送請求都需要帶上 Cookie (通過請求報文的頭部字段“Cookie”),以便于服務器區分不同的客戶端。
舉個例子,618作為一個大型的購物節,在一天的不同時間段,不同店鋪中,會有著許多不同的活動,為了達到最大折扣,我們通常會在一天內多次進入如淘寶、京東等購物網站進行購物,但是因為 HTTP 是無狀態的,所以它并不會記錄我們的任何信息,所以我們在每次訪問時都需要重新登陸來確認用戶的身份,這是一種很麻煩的事情。所以為 HTTP 加入了 Cookie 來幫助其維持狀態。
Cookie 分為兩類:
- 以文件方式存在硬盤空間上的
長期性的 cookie - 停留在瀏覽器所占內存中的
臨時性的 cookie
有了 Cookie 之后,我們只需要一次登錄就能夠以 該登錄狀態 訪問 同一域名的不同頁面 ,沒必要繁瑣的每個頁面都登錄同樣的用戶以維持登陸狀態。
cookie 的運作方式:
在每次通信后,會將 服務端的一些臨時驗證信息(比如常見的詢問用戶是否要保存登陸密碼)保存在客戶端的 cookie 文件中。這樣下次通信時,就可以通過讀取 cookie 中保存的驗證信息,將其傳遞給服務端,來維持客戶端的狀態,這樣就可以避免多次登錄。
為什么需要 session ? 什么是 session ?
Cookie 的使用不夠安全 ,因為 Cookie 保存在客戶端(瀏覽器),很容易被腳本、爬蟲等截取,所以 Cookie 需要搭配 Session 使用。
Session 其實就是服務端為客戶端創建的一種信息管理機制,其中描述了客戶端的身份認證信息和狀態信息,并且將其保存在 服務端 。 服務端每次通信結束后都會將 Session id(本次會話的ID)保存在客戶端的 Cookie 中,客戶端在下次通信時通過 Cookie 將保存的 Session id 傳遞給服務端,這樣服務端就可以通過對應的 Session id 來查找到客戶端的身份認證信息和狀態信息,來為客戶端維持狀態,避免重復登錄。
如果客戶端的瀏覽器禁用了 Cookie ,那么還能使用 Session 嗎?
一般這種情況下,會使用一種叫做 URL重寫 的技術來進行會話跟蹤,即每次 HTTP 交互,URL 后面都會被附加上一個諸如 sid=xxxxx 這樣的參數,服務端據此來識別用戶。
Cookie 與 Session 的區別是什么?
- Cookie : 保存在客戶端上的一種存儲機制,用于持續與服務端進行信息傳遞的一種手段。
- Session: 保存在服務端上的一種數據結構,通過
Cookie傳遞Session id來查找到對應的 身份狀態信息 ,來實現狀態維持。
為什么 Session 要比 Cookie 更安全?
Session ID 是放在 Cookie 里,想要攻破 Session ,首先要破解 Cookie 。而即使得到 Session ID:
- 第一,
Session ID是要有人登錄,或者啟動session_start才會有,你不知道什么時候會有人登錄。 - 第二,
Session ID是加密的,第二次session_start的時候,前一次的Session ID就失效了。換言之,Session是針對某一次通信而言,會話結束Session也就隨著消失了,Session消失了Session ID也失效了,而想在短時間內破解加了密的Session ID是很難的。
HTTP代理服務器
在 HTTP通信鏈 上,客戶端和目標服務器之間通常存在某些中轉代理服務器。它們最基本的功能是連接,此外還包括安全性、緩存、內容過濾、訪問控制管理等功能。一個 HTTP請求 可能被多個代理服務器轉發,后面的服務器稱為前面服務器的 上游服務器 。代理服務器分為:正向代理服務器、反向代理服務器、透明代理服務器。
正向代理服務器
概念
要求客戶端自己設置代理服務器的地址。客戶的每次請求都將直接發送到該代理服務器,并由代理服務器來請求目標資源。
處于防火墻內的局域網機器要訪問 Internet,或者要訪問一些被屏蔽掉的國外網站,就需要用到正向代理服務器。
優點
可以使用緩沖特性(由 mod_cache 提供)減少網絡使用率
反向代理服務器
概念
被設置在服務器端,因而客戶端無須進行任何設置。反向代理是指用代理服務器來接收 Internet 上的連接請求,然后將請求轉發給內部網絡上的服務器,并將從內部服務器上得到的結果返回給客戶端。對于用戶而言,反向代理服務器就相當于目標服務器。
各大網站通常分區域設置了多個代理服務器,所以在不同的地方 ping 同一個域名可能得到不同的 IP地址,因為這些 IP地址 實際上是 代服務器的IP地址 。
優點
- 可用來作為
Web加速: 即使用反向代理作為Web服務器的前置機來降低網絡和服務器的負載,提高訪問效率。
例如:在內部服務器前放置兩臺反向代理服務器,分別連接到教育網和公網,這樣公網用戶就可以直接通過公網線路訪問學校服務器,從而避開了公網和教育網之間擁擠的鏈路。 - 提高內部服務器的安全性: 外部網絡用戶通過反向代理訪向內部服務器,只能看到反向代理服務器的IP地址和端口號,內部服務器對于外部網絡來說是完全不可見。而且反向代理服務器上沒有保存任何的信息資源,所有的網頁程序都保存在內部服務器上,對反向代理服務器的攻擊并不能使真的網頁信息系統受到破壞。
- 節約了有限的
IP資源: 校園網內部服務器除使用教育網地址外,也會采用公網的IP地址對外提供服務,公網分配的IP地址數目是有限的,如果每個服務器都分配一個公網地址,那是不可能的,通過反向代理技術很好的解決了IP地址不足的問題。
透明代理服務器
概念
透明代理只能設置在網關上,客戶端根本不需要知道有代理服務器的存在,它改變你的 request fields(報文) ,并會傳送 真實IP ,多用于路由器的 NAT轉發 中。注意,加密的透明代理則是屬于 匿名代理 ,意思是不用設置使用代理了,例如:Garden 2 程序。透明代理可以看作正向代理的一種特殊情況。
原理
假設 A 為內部網絡客戶機,B 為外部網絡服務器,C 為防火墻。
- 當
A對B有連接請求時,TCP連接請求被防火墻C截取并加以監控。 - 截取后當發現連接需要使用代理服務器時,
A和C之間首先建立連接。 - 然后
防火墻C建立相應的代理服務通道與目標B建立連接。 - 由此通過
代理服務器C建立A和目標地址B的數據傳輸途徑。
從用戶的角度看,A 和 B 的連接是直接的,而實際上 A 是通過 代理服務器C 和 B 建立連接的。反之,當 B 對 A 有連接請求時原理相同。由于這些連接過程是自動的,不需要客戶端手工配置代理服務器,甚至用戶根本不知道代理服務器的存在,因而對用戶來說是透明的。
| 數據類型、常用命令一覽、庫的操作、表的操作)


| 表的增刪查改、聚合函數(復合函數)、聯合查詢)



:模板基礎:函數模板、類模板、模板推演成函數的機制、模板實例化、模板匹配規則)

:非類型模板參數,模板特化,模板的分離編譯)




)




