文章目錄
- 新增 (Create)
- 全列插入
- 指定列插入
- 查詢 (Retrieve)
- 全列查詢
- 指定列查詢
- 條件查詢
- 關系元素運算符
- 模糊查詢
- 分頁查詢
- 去重:DISTINCT
- 別名:AS
- 升序 or 降序
- 更新 (Update)
- 刪除 (Delete)
- 分組(GROUP BY)
- 聯合查詢
- 內連接(inner join)
- 自連接
- 外連接
- 左連接(left join)
- 右連接(left join)
- 子查詢(嵌套查詢)
- 合并查詢
- UNION
- UNION ALL
- 聚合函數(復合函數)
- 最大最小
- 總數、總和、平均值、保留小數
- 條件函數
- IF
- CASE
- 日期函數
- 時間戳和日期的轉換
- 年月日截取
- 日期差計算
- 文本函數
新增 (Create)
全列插入
語法
INSERT INTO [表名] VALUES(參數1, 參數2, 參數3......);
示例
INSERT INTO book VALUES(4, "C++Primer", 99.9, "2000-08-02", 103);mysql> SELECT * FROM book-> ;
+------+-----------+-------+------------+------+
| id | name | price | publish | num |
+------+-----------+-------+------------+------+
| 4 | C++Primer | 100 | 2000-08-02 | 103 |
+------+-----------+-------+------------+------+
1 rows in set (0.00 sec)
這里 price 的值為 100 而不是 99.9 是因為 默認decimal為(10,0) ,也就是 0 位小數,保存的時候將小數點后面的值四舍五入。

指定列插入
即只插入部分列內容
語法
INSERT INTO [表名](列1,列2,列3.......) values(參數1, 參數2, 參數3......);
示例
mysql> INSERT INTO book(id,name,price)-> VALUES(8,"紅樓夢",94.4);
Query OK, 1 row affected, 1 warning (0.01 sec)mysql> SELECT * FROM book;
+------+-----------+-------+------------+------+
| id | name | price | publish | num |
+------+-----------+-------+------------+------+
| 4 | C++Primer | 100 | 2000-08-02 | 103 |
| 8 | 紅樓夢 | 94 | NULL | NULL |
+------+-----------+-------+------------+------+
2 rows in set (0.00 sec)
查詢 (Retrieve)
全列查詢
語法
SELECT * FROM [表名];
示例
mysql> SELECT * FROM book;
+------+-----------+-------+------------+------+
| id | name | price | publish | num |
+------+-----------+-------+------------+------+
| 4 | C++Primer | 100 | 2000-08-02 | 103 |
| 8 | 紅樓夢 | 94 | NULL | NULL |
+------+-----------+-------+------------+------+
2 rows in set (0.00 sec)
指定列查詢
語法
SELECT 列1,列2,列3..... FROM [表名];
示例
mysql> SELECT name, price FROM book;
+-----------+-------+
| name | price |
+-----------+-------+
| C++Primer | 100 |
| 紅樓夢 | 94 |
+-----------+-------+
2 rows in set (0.00 sec)
條件查詢
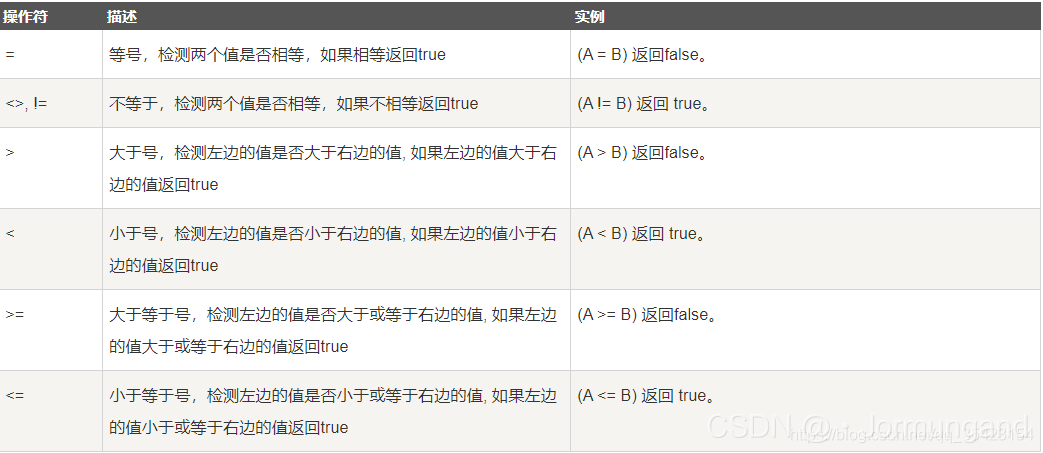
關系元素運算符
語法
SELECT * FROM [表名] WHERE [條件];
示例
mysql> SELECT * FROM book WHERE id=8;
+------+-----------+-------+---------+------+
| id | name | price | publish | num |
+------+-----------+-------+---------+------+
| 8 | 紅樓夢 | 94 | NULL | NULL |
+------+-----------+-------+---------+------+
1 row in set (0.00 sec)
模糊查詢
語法
SELECT * FROM [表名] WHERE [列名] LIKE ”%XX%“
// 查詢名字中帶XX的數據
SELECT * FROM [表名] WHERE [列名] LIKE ”XX%“
// 查詢名字中以XX開頭的數據
SELECT * FROM [表名] WHERE [列名] LIKE ”%XX“
// 查詢名字中以XX結尾的數據
分頁查詢
語法
SELECT * FROM [表名] LIMIT [每頁條數] OFFSET [偏移條數];
示例
mysql> SELECT * FROM book;
+------+-----------+-------+------------+------+
| id | name | price | publish | num |
+------+-----------+-------+------------+------+
| 4 | C++Primer | 100 | NULL | 103 |
| 4 | C++Primer | 100 | 2000-08-02 | 103 |
| 8 | 紅樓夢 | 94 | NULL | NULL |
+------+-----------+-------+------------+------+
3 rows in set (0.00 sec)// 限制顯示條數
mysql> SELECT * FROM book LIMIT 1;
+------+-----------+-------+---------+------+
| id | name | price | publish | num |
+------+-----------+-------+---------+------+
| 4 | C++Primer | 100 | NULL | 103 |
+------+-----------+-------+---------+------+
1 row in set (0.00 sec)// 限制顯示條數、規定偏移量
mysql> SELECT * FROM book LIMIT 1 OFFSET 1;
+------+-----------+-------+------------+------+
| id | name | price | publish | num |
+------+-----------+-------+------------+------+
| 4 | C++Primer | 100 | 2000-08-02 | 103 |
+------+-----------+-------+------------+------+
1 row in set (0.00 sec)// 剩余數據不足LIMIT限制時,不會報錯,而是輸出所有剩余的
mysql> SELECT * FROM book LIMIT 2 OFFSET 2;
+------+-----------+-------+---------+------+
| id | name | price | publish | num |
+------+-----------+-------+---------+------+
| 8 | 紅樓夢 | 94 | NULL | NULL |
+------+-----------+-------+---------+------+
1 row in set (0.00 sec)
去重:DISTINCT
語法
SELECT DISTINCT * FROM [表名];
示例
mysql> SELECT * FROM book;
+------+-----------+-------+------------+------+
| id | name | price | publish | num |
+------+-----------+-------+------------+------+
| 4 | C++Primer | 100 | NULL | 103 |
| 4 | C++Primer | 100 | 2000-08-02 | 103 |
| 8 | 紅樓夢 | 94 | NULL | NULL |
| 4 | C++Primer | 100 | 2000-08-02 | 103 |
+------+-----------+-------+------------+------+
4 rows in set (0.00 sec)mysql> SELECT DISTINCT * FROM book;
+------+-----------+-------+------------+------+
| id | name | price | publish | num |
+------+-----------+-------+------------+------+
| 4 | C++Primer | 100 | NULL | 103 |
| 4 | C++Primer | 100 | 2000-08-02 | 103 |
| 8 | 紅樓夢 | 94 | NULL | NULL |
+------+-----------+-------+------------+------+
3 rows in set (0.00 sec)
別名:AS
語法
SELECT 列a,列b...... AS [別名] FROM [表名];
示例
mysql> SELECT name, price * num AS total FROM book;
+-----------+-------+
| name | total |
+-----------+-------+
| C++Primer | 10300 |
| C++Primer | 10300 |
| 紅樓夢 | NULL |
| C++Primer | 10300 |
+-----------+-------+
4 rows in set (0.00 sec)
–
升序 or 降序
語法
SELECT * FROM [表名] ORDER BY [列名] DESC
// DESC為降序排序,ASC為升序排序,默認為ASC。
示例
mysql> SELECT name, price * num AS total FROM book ORDER BY total;
+-----------+-------+
| name | total |
+-----------+-------+
| 紅樓夢 | NULL |
| C++Primer | 10300 |
| C++Primer | 10300 |
| C++Primer | 10300 |
+-----------+-------+
4 rows in set (0.00 sec)
更新 (Update)
語法
UPDATE [表名] SET [修改項] = [修改結果]
示例
mysql> SELECT * FROM book;
+------+-----------+-------+------------+------+
| id | name | price | publish | num |
+------+-----------+-------+------------+------+
| 4 | C++Primer | 100 | NULL | 103 |
| 4 | C++Primer | 100 | 2000-08-02 | 103 |
| 8 | 紅樓夢 | 94 | NULL | NULL |
| 4 | C++Primer | 100 | 2000-08-02 | 103 |
+------+-----------+-------+------------+------+
4 rows in set (0.00 sec)mysql> UPDATE book SET num=55 WHERE id=8;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> SELECT * FROM book;
+------+-----------+-------+------------+------+
| id | name | price | publish | num |
+------+-----------+-------+------------+------+
| 4 | C++Primer | 100 | NULL | 103 |
| 4 | C++Primer | 100 | 2000-08-02 | 103 |
| 8 | 紅樓夢 | 94 | NULL | 55 |
| 4 | C++Primer | 100 | 2000-08-02 | 103 |
+------+-----------+-------+------------+------+
4 rows in set (0.00 sec)
刪除 (Delete)
語法
DELETE FROM [表名];
示例
mysql> DELETE FROM book WHERE id=4;
Query OK, 3 rows affected (0.00 sec)mysql> SELECT * FROM book;
+------+-----------+-------+---------+------+
| id | name | price | publish | num |
+------+-----------+-------+---------+------+
| 8 | 紅樓夢 | 94 | NULL | 55 |
+------+-----------+-------+---------+------+
1 row in set (0.00 sec)
分組(GROUP BY)
分組的意思是根據所選 列名 對數據進行分組,可以理解為作為分組依據的 列 不會變動,而對其余列按照要求進行相關操作,最后對照著 列中的項 展示對應的結果。
語法
SELECT * FROM [表名] WHERE [條件] GROUP BY [列名]
SELECT * FROM [表名] GROUP BY [列名] HAVING [過濾條件]
// WHERE 后跟的條件里不允許使用聚合函數,但 HAVING 后面的過濾條件可以。
示例
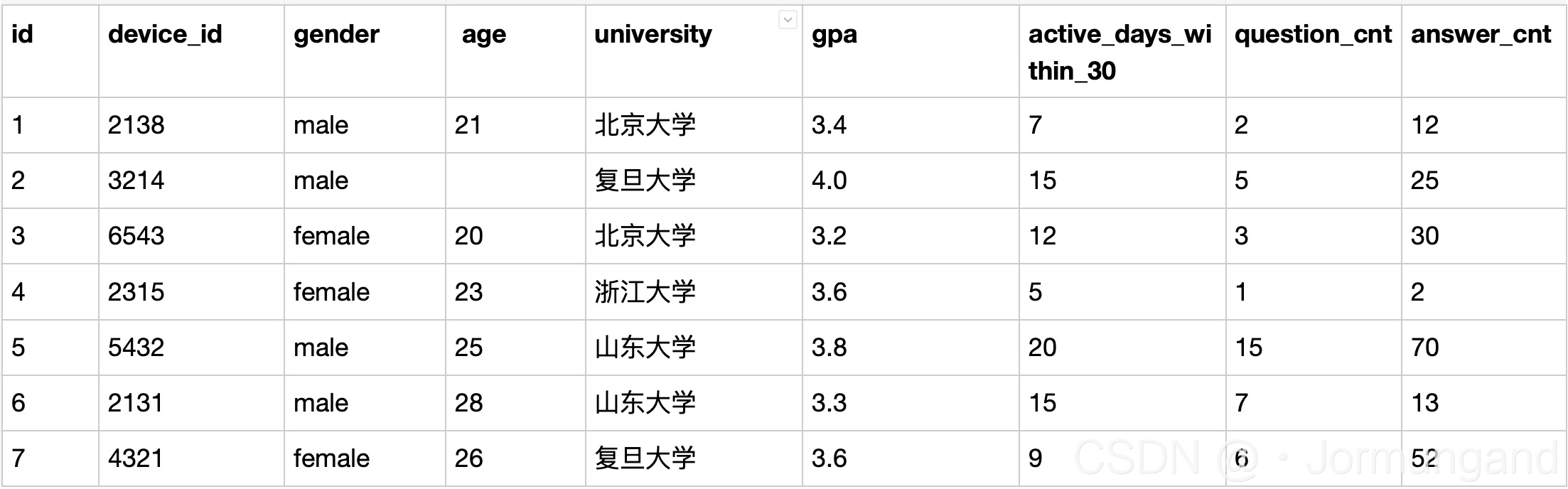
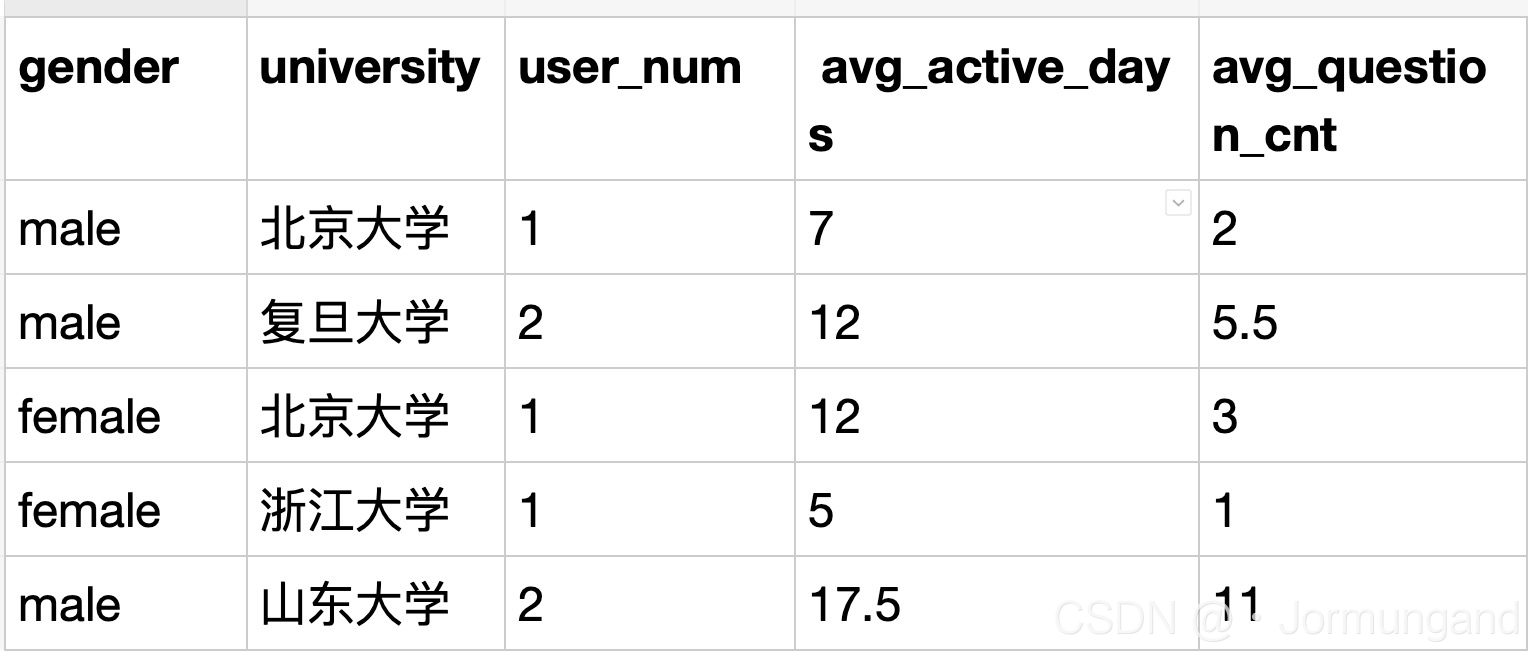
SELECT gender, university, count(device_id) AS user_num,
avg(active_days_within_30) AS avg_active_days,
avg(question_cnt) as avg_question_cnt
FROM user_profile GROUP BY university, gender;
聯合查詢
內連接(inner join)
內連接即查找兩個表中的 交集 ,找到兩個表中同時符合條件的數據,進行連接。
語法
select 字段 from 表1 別名1 [inner] join 表2 別名2 on 連接條件 and 其他條件;
select 字段 from 表1 別名1,表2 別名2 where 連接條件 and 其他條件;
自連接
自連接是特殊的內連接,即與本表進行連接,需要對表名進行 別名顯示 。
語法
select 字段 from 表名1 別名1 [inner] join 表名2 別名2 on 連接條件 and 其他條件;
外連接
外連接又分左外連接和右外連接。簡單來說就是,以左表的數據為基準就是左連接,以右表的數據為基準就是右連接。
左連接(left join)
對于左連接,以左表的數據為基準,在右表中查找符合條件的數據,找不到的以 NULL 展示。
語法
select 字段名 from 表名1 left join 表名2 on 連接條件;
// 以 表1 為左基準,查詢 表2 中的符合數據
右連接(left join)
對于右連接,以右表的數據為基準,在左表中查找符合條件的數據,找不到的以 NULL 展示。
語法
select 字段 from 表名1 right join 表名2 on 連接條件;
// 以 表1 為右基準,查詢 表2 中的符合數據
子查詢(嵌套查詢)
子查詢又叫做嵌套查詢(窗口查詢),其實就是嵌入 其他sql語句 中的 select語句 ,一般用于 查詢的條件是另一條語句的結果 這一情況。
語法
select 字段 from 表名 where 查詢條件=(select 列名 from 表名 where 查詢條件);
示例
(題源牛客)找到每個學校gpa最低的同學來做調研,請你取出相應數據。
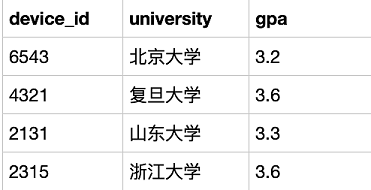
SELECT device_id, university, gpa
FROM user_profile
WHERE gpa IN( # IN 可替換為 = ANYSELECT min(gpa)FROM user_profileGROUP BY university
)
GROUP BY university # 保證學校名不重復
ORDER BY university; # 保證與題目要求輸出順序一致
合并查詢
UNION
該操作符用于取得兩個結果集的并集。當使用該操作符時,會自動去掉結果集中的重復行。
語法
select 字段 from 表名 where 查詢條件
UNION
select 列名 from 表名 where 查詢條件;
同樣的結果也可以通過 or語句 來得到
select 字段 from 表名 where 查詢條件1 or 查詢條件2;
但是OR這個邏輯運算符會忽略索引、掃描全表,所以在海量數據查詢中性能會下降很多。
UNION ALL
該操作符用于取得兩個結果集的并集。當使用該操作符時,不自動去掉結果集中的重復行。
語法
select 字段 from 表名 where 查詢條件
UNION ALL
select 列名 from 表名 where 查詢條件;
聚合函數(復合函數)
最大最小
MAX():返回查詢到的數據的最大值MIN():返回查詢到的數據的最小值
語法
SELECT max([列名]) FROM [表名]
// 查詢對應列中最大的數據
SELECT min([列名]) FROM [表名]
// 查詢對應列中最小的數據
示例
mysql> SELECT * FROM class;
+------+------+-------+
| id | num | name |
+------+------+-------+
| NULL | NULL | li |
| NULL | NULL | chen |
| NULL | NULL | zhang |
+------+------+-------+
3 rows in set (0.00 sec)mysql> SELECT max(name) FROM class-> ;
+-----------+
| max(name) |
+-----------+
| zhang |
+-----------+
1 row in set (0.00 sec)
總數、總和、平均值、保留小數
COUNT():返回查詢到的數據的數量SUM():返回查詢到的數據的總和AVG():返回查詢到的數據的平均值ROUND():返回查詢數據的保留小數結果,常與sum、avg搭配。
語法
SELECT count([列名]) FROM [表名]
// 查詢對應列中數據的總數
SELECT sum([列名]) FROM [表名]
// 查詢對應列中數據的和
SELECT avg([列名]) FROM [表名]
// 查詢對應列中數據的平均值
SELECT round([數據], n) FROM [表名]
// 查詢對應數據保留n位小數的結果,數據可以為count、avg的結果
條件函數
IF
條件函數 if(x,a,b)表示如果 x 成立、則返回 a;否則返回 b 。常用來劃分查詢結果的輸出情況。
語法
SELECT IF(X, A, B) AS [列名] FROM [表名]
示例
(題源牛客)現在運營想要將用戶劃分為25歲以下和25歲及以上兩個年齡段,分別查看這兩個年齡段用戶數量:
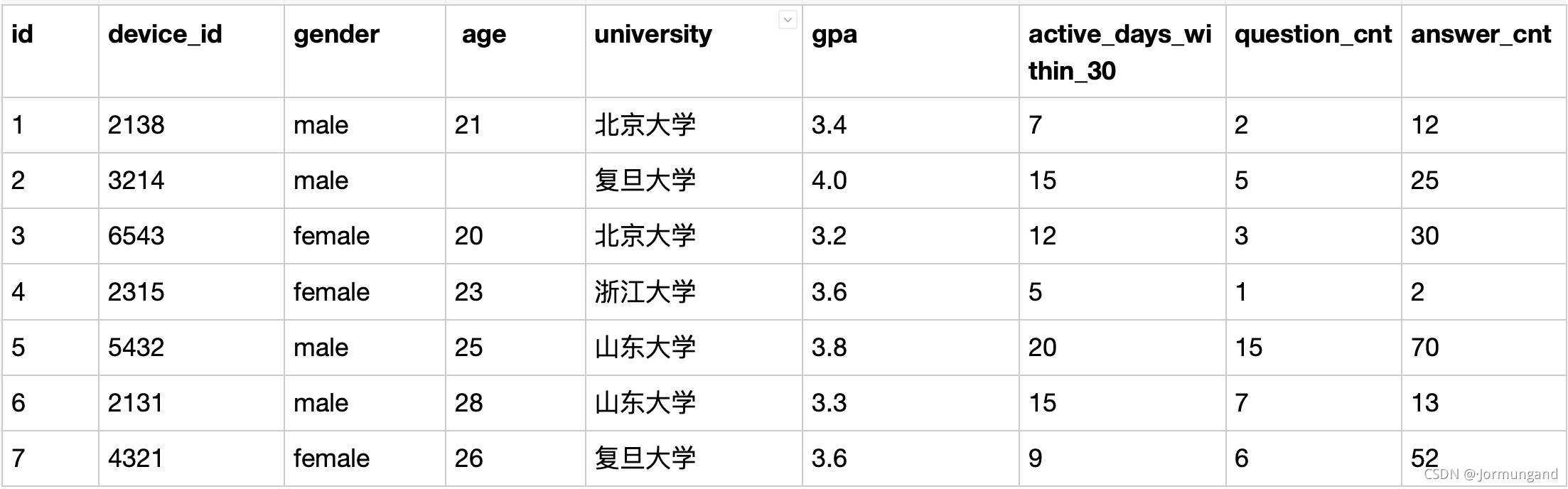
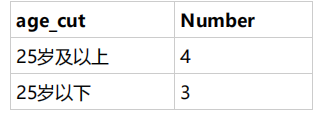
SELECT if(age>=25, '25歲以及上', '25歲以下') AS age_cut,
COUNT(device_id) AS Number FROM user_profile
GROUP BY age_cut;
CASE
數據庫中的 case運算符 類似于 C語言 中的 switch語句 ,WHEN 用來羅列情況,THEN 將情況與輸出結果相對應,ELSE 總結未羅列的情況,END 標識語句結束。
語法
SELECT
CASEWHEN [條件] THEN [輸出結果]WHEN [條件] THEN [輸出結果]ELSE [輸出結果]
END
AS [列名] FROM [表名]
示例
(題源牛客)現在運營想要將用戶劃分為20歲以下,20-24歲,25歲及以上三個年齡段,分別查看不同年齡段用戶的明細情況,請取出相應數據。


SELECT device_id, gender,
CASEWHEN age>=25 THEN '25歲以上'WHEN age BETWEEN 20 AND 24 THEN "20-24歲"WHEN age<20 THEN '20歲以下'ELSE '其他'
END
AS age_cut FROM user_profile
日期函數
時間戳和日期的轉換
時間戳是數據庫中自動生成的唯一二進制數字,表明數據庫中數據修改發生的相對順序,其記錄形式類似:1627963699 ,在實際工作環境中,對于用戶行為發生的時間通常都是用時間戳進行記錄。
from_unixtime 可以將時間戳轉換成日期,其使用語法如下:
# 時間戳所在列轉換
SELECT
from_unixtime([時間戳所在列], 'yyyy-MM-dd’) AS [列名] # 日期格式有’yyyy-MM-dd’ 和 ‘yyyyMMdd’,這里選用前者
From [表名]
# 單個時間戳轉換
SELECT from_unixtime([時間戳], [日期格式]) AS [列名]
unix_timestamp 可以將日期轉換成時間戳,其使用語法如下:
- 如果日期值格式滿足
yyyy-MM-dd HH:mm:ss,則無需指定日期格式:
SELECT unix_timestamp([日期值]) AS [列名]
- 如果日期值格式不滿足
yyyy-MM-dd HH:mm:ss,則必須指定日期格式:
SELECT unix_timestamp(‘2021-09-02','yyyy-MM-dd’) AS [列名]
年月日截取
可以從完整日期格式中提取出年月日:
語法
SELECT year([日期值]), month([日期值]), day([日期值]) FROM [表名]
# 提取一列的年月日則可以將 日期值 改為 列名
示例
(題源牛客)計算出2021年8月每天用戶練習題目的數量,請取出相應數據。


SELECT DAY(date) AS day, COUNT(question_id) AS question_cnt
FROM question_practice_detail
WHERE YEAR(date)='2021' AND MONTH(date)='08'
GROUP BY day;
日期差計算
datedff
datediff 的作用為計算兩個日期之間的天數間隔。
語法
datediff(date1, date2)
返回起始時間 date1 和結束時間 date2 之間的天數,date1 大于 date2 的情況下,返回的天數為正數;date1 小于 date2 的情況下,返回的天數為負數。
date_sub
語法
date_sub (string startdate, interval int day)
返回開始日期 startdate 減少 day 天后的日期。
date_add
語法
date_add(string startdate, interval int day)
返回開始日期 startdate 增加 day 天后的日期。
示例
(題源牛客)查看用戶在某天刷題后第二天還會再來刷題的平均概率。請取出相應數據。
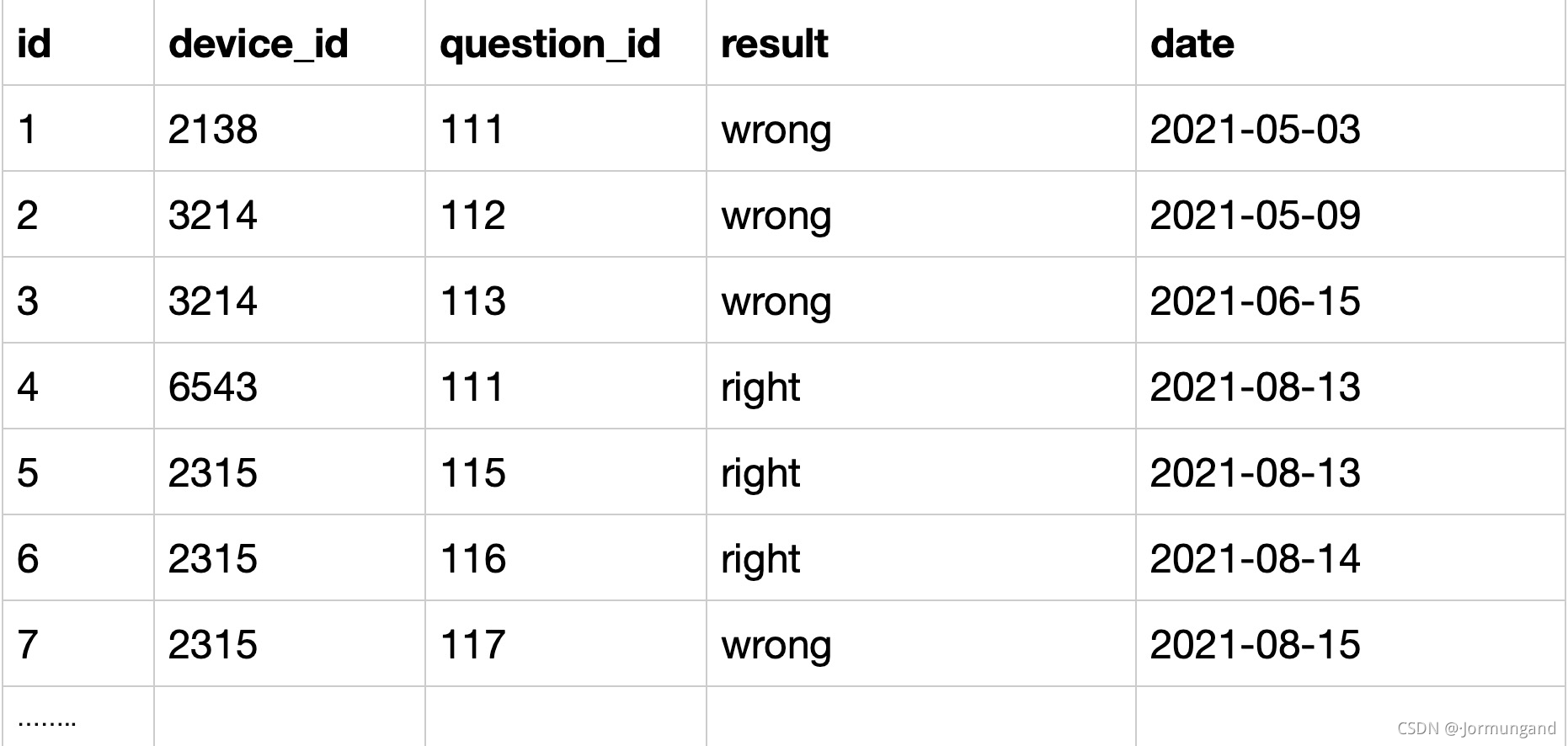

SELECT COUNT(q2.device_id)/COUNT(q1.device_id) AS avg_ret
FROM(SELECT DISTINCT device_id, dateFROM question_practice_detail
) q1
LEFT JOIN(SELECT DISTINCT device_id,date_sub(date, INTERVAL 1 DAY) AS dateFROM question_practice_detail
) q2
USING(date, device_id);
# USING 等同于 ON q1.date=q2.date AND q1.device_id=q2.device_id;
文本函數
LOCATE(substr, str):返回子串substr在字符串str中第一次出現的位置,如不存在,則返回0;POSITION(substr IN str):LOCATE函數作用相同;LEFT(str, length):從左邊開始截取str,length是截取的長度;RIGHT(str, length):從右邊開始截取str,length是截取的長度;SUBSTRING_INDEX(str, substr, n):返回字符substr在str中第n次出現位置之前的字符串,n若為負數,則表倒數;SUBSTRING(str , n, m):返回字符串str從第n個字符截取長度為m個字符;REPLACE(str, n, m):將字符串str中的n字符替換成m字符;LENGTH(str):計算字符串str的長度。



:模板基礎:函數模板、類模板、模板推演成函數的機制、模板實例化、模板匹配規則)

:非類型模板參數,模板特化,模板的分離編譯)




)








