
Linux 日志分析:用 ELK 搭建個人運維監控平臺
🌟 Hello,我是摘星!
🌈 在彩虹般絢爛的技術棧中,我是那個永不停歇的色彩收集者。
🦋 每一個優化都是我培育的花朵,每一個特性都是我放飛的蝴蝶。
🔬 每一次代碼審查都是我的顯微鏡觀察,每一次重構都是我的化學實驗。
🎵 在編程的交響樂中,我既是指揮家也是演奏者。讓我們一起,在技術的音樂廳里,奏響屬于程序員的華美樂章。
目錄
Linux 日志分析:用 ELK 搭建個人運維監控平臺
摘要
1. ELK Stack 架構概覽
1.1 核心組件介紹
1.2 數據流處理過程
2. 環境準備與基礎配置
2.1 系統要求
2.2 Java 環境配置
2.3 系統優化配置
3. Elasticsearch 集群部署
3.1 安裝與基礎配置
3.2 Elasticsearch 配置文件
3.3 啟動服務腳本
4. Logstash 數據處理管道
4.1 Logstash 安裝配置
4.2 日志處理配置
4.3 Grok 模式定義
5. Kibana 可視化平臺搭建
5.1 Kibana 安裝與配置
5.2 Kibana 配置文件
5.3 啟動腳本
6. Filebeat 日志收集配置
6.1 Filebeat 安裝
6.2 Filebeat 配置
7. 監控儀表板設計
7.1 系統性能監控
7.2 告警規則配置
8. 性能優化與最佳實踐
8.1 索引生命周期管理
8.3 集群健康檢查腳本
9. 安全加固與訪問控制
9.1 網絡安全配置
9.2 SSL/TLS 配置
10. 故障排查與維護
10.1 常見問題診斷
10.2 日志輪轉配置
總結
參考鏈接
關鍵詞標簽
摘要
作為一名在運維一線摸爬滾打多年的技術人,我深知日志分析在系統監控中的重要性。每當凌晨收到告警短信時,第一反應就是查看日志,但傳統的 tail -f 和 grep 命令在面對海量日志時顯得力不從心。經過不斷的實踐和踩坑,我發現 ELK Stack(Elasticsearch、Logstash、Kibana)是構建個人運維監控平臺的最佳選擇。
在這篇文章中,我將分享如何從零開始搭建一個功能完整的 ELK 日志分析平臺。我們將從基礎的環境準備開始,逐步配置 Elasticsearch 集群、部署 Logstash 數據處理管道、搭建 Kibana 可視化界面,最后通過 Filebeat 實現日志的自動收集。整個過程不僅包含詳細的配置步驟,還會分享我在實際部署中遇到的各種問題和解決方案。
通過這套監控平臺,你可以實現實時日志搜索、異常告警、性能監控、安全審計等功能。無論是 Web 服務器的訪問日志、應用程序的錯誤日志,還是系統的安全日志,都能在統一的界面中進行分析和可視化。我還會介紹如何通過自定義儀表板來監控關鍵指標,如何設置告警規則來及時發現問題,以及如何優化 ELK 性能來處理大規模日志數據。
這不僅僅是一個技術教程,更是我多年運維經驗的總結。希望通過這篇文章,能幫助更多的技術同行建立起自己的日志分析體系,讓運維工作變得更加高效和智能。
1. ELK Stack 架構概覽
1.1 核心組件介紹
ELK Stack 是由三個開源項目組成的強大日志分析解決方案:
- Elasticsearch:分布式搜索和分析引擎,負責存儲和索引日志數據
- Logstash:數據處理管道,負責收集、轉換和輸出日志數據
- Kibana:數據可視化平臺,提供搜索和圖表功能
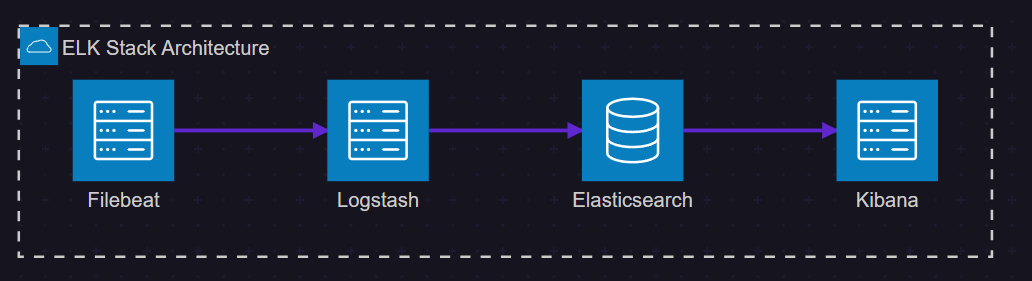
圖1:ELK Stack 架構圖 - 展示各組件間的數據流向
1.2 數據流處理過程
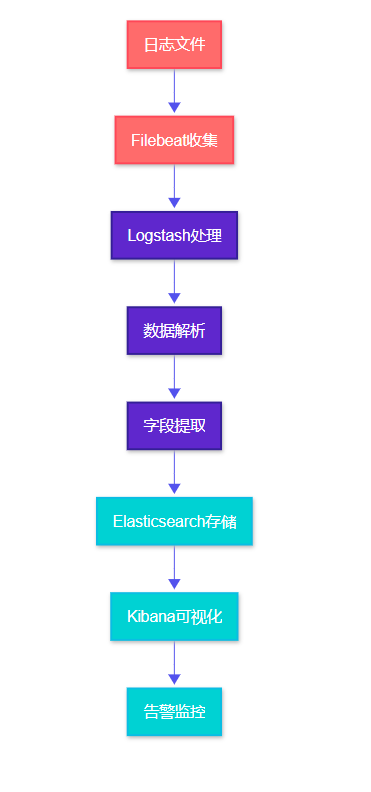
圖2:日志處理流程圖 - 從收集到可視化的完整流程
2. 環境準備與基礎配置
2.1 系統要求
在開始部署之前,我們需要確保系統滿足 ELK Stack 的運行要求:
| 組件 | 最小內存 | 推薦內存 | 磁盤空間 | Java版本 |
| Elasticsearch | 2GB | 8GB | 50GB+ | JDK 11+ |
| Logstash | 1GB | 4GB | 10GB | JDK 11+ |
| Kibana | 1GB | 2GB | 5GB | Node.js 14+ |
| Filebeat | 128MB | 512MB | 1GB | 無需Java |
2.2 Java 環境配置
#!/bin/bash
# 安裝 OpenJDK 11
sudo apt update
sudo apt install -y openjdk-11-jdk# 配置 JAVA_HOME 環境變量
echo 'export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64' >> ~/.bashrc
echo 'export PATH=$JAVA_HOME/bin:$PATH' >> ~/.bashrc
source ~/.bashrc# 驗證 Java 安裝
java -version
javac -version這段腳本首先更新系統包管理器,然后安裝 OpenJDK 11。配置環境變量是關鍵步驟,確保 ELK 組件能夠找到 Java 運行時。
2.3 系統優化配置
#!/bin/bash
# 優化系統參數以支持 Elasticsearch
echo 'vm.max_map_count=262144' | sudo tee -a /etc/sysctl.conf
echo 'fs.file-max=65536' | sudo tee -a /etc/sysctl.conf# 配置用戶限制
echo 'elasticsearch soft nofile 65536' | sudo tee -a /etc/security/limits.conf
echo 'elasticsearch hard nofile 65536' | sudo tee -a /etc/security/limits.conf
echo 'elasticsearch soft nproc 4096' | sudo tee -a /etc/security/limits.conf
echo 'elasticsearch hard nproc 4096' | sudo tee -a /etc/security/limits.conf# 應用配置
sudo sysctl -p這些優化配置對于 Elasticsearch 的穩定運行至關重要,特別是 vm.max_map_count 參數,它決定了進程可以擁有的內存映射區域的最大數量。
3. Elasticsearch 集群部署
3.1 安裝與基礎配置
#!/bin/bash
# 下載并安裝 Elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.11.0-linux-x86_64.tar.gz
tar -xzf elasticsearch-8.11.0-linux-x86_64.tar.gz
sudo mv elasticsearch-8.11.0 /opt/elasticsearch# 創建專用用戶
sudo useradd -r -s /bin/false elasticsearch
sudo chown -R elasticsearch:elasticsearch /opt/elasticsearch3.2 Elasticsearch 配置文件
# /opt/elasticsearch/config/elasticsearch.yml
cluster.name: personal-monitoring
node.name: node-1
path.data: /opt/elasticsearch/data
path.logs: /opt/elasticsearch/logs# 網絡配置
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300# 集群配置
discovery.type: single-node
cluster.initial_master_nodes: ["node-1"]# 安全配置
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
xpack.security.http.ssl.enabled: false
xpack.security.transport.ssl.enabled: false# 性能優化
indices.memory.index_buffer_size: 10%
indices.memory.min_index_buffer_size: 48mb這個配置文件針對單節點部署進行了優化,關閉了 X-Pack 安全功能以簡化初始配置。在生產環境中,建議啟用安全功能。
3.3 啟動服務腳本
#!/bin/bash
# /opt/elasticsearch/bin/start-elasticsearch.sh# 設置 JVM 堆內存
export ES_JAVA_OPTS="-Xms2g -Xmx2g"# 啟動 Elasticsearch
sudo -u elasticsearch /opt/elasticsearch/bin/elasticsearch -d# 等待服務啟動
sleep 30# 檢查服務狀態
curl -X GET "localhost:9200/_cluster/health?pretty"JVM 堆內存設置遵循"不超過系統內存的50%,且不超過32GB"的原則。-d 參數表示以守護進程方式運行。
4. Logstash 數據處理管道
4.1 Logstash 安裝配置
#!/bin/bash
# 下載并安裝 Logstash
wget https://artifacts.elastic.co/downloads/logstash/logstash-8.11.0-linux-x86_64.tar.gz
tar -xzf logstash-8.11.0-linux-x86_64.tar.gz
sudo mv logstash-8.11.0 /opt/logstash
sudo chown -R elasticsearch:elasticsearch /opt/logstash4.2 日志處理配置
# /opt/logstash/config/logstash.conf
input {# 接收 Filebeat 數據beats {port => 5044}# 直接讀取日志文件file {path => "/var/log/nginx/access.log"start_position => "beginning"type => "nginx-access"}file {path => "/var/log/nginx/error.log"start_position => "beginning"type => "nginx-error"}
}filter {# 處理 Nginx 訪問日志if [type] == "nginx-access" {grok {match => { "message" => "%{NGINXACCESS}"}}# 解析時間戳date {match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]}# 轉換數據類型mutate {convert => { "response" => "integer""bytes" => "integer""responsetime" => "float"}}# 添加地理位置信息geoip {source => "clientip"target => "geoip"}}# 處理應用程序日志if [type] == "application" {# 解析 JSON 格式日志json {source => "message"}# 提取錯誤級別if [level] {mutate {uppercase => [ "level" ]}}}
}output {# 輸出到 Elasticsearchelasticsearch {hosts => ["localhost:9200"]index => "logs-%{type}-%{+YYYY.MM.dd}"}# 調試輸出stdout {codec => rubydebug}
}這個配置文件定義了完整的數據處理管道:輸入階段接收多種數據源,過濾階段進行數據解析和轉換,輸出階段將處理后的數據發送到 Elasticsearch。
4.3 Grok 模式定義
# /opt/logstash/patterns/nginx
NGINXACCESS %{IPORHOST:clientip} - %{DATA:auth} \[%{HTTPDATE:timestamp}\] "%{WORD:verb} %{DATA:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:response:int} (?:%{NUMBER:bytes:int}|-) "(?:%{DATA:referrer}|-)" "%{DATA:agent}" %{NUMBER:responsetime:float}自定義 Grok 模式可以精確解析特定格式的日志,提取出有價值的字段信息。
5. Kibana 可視化平臺搭建
5.1 Kibana 安裝與配置
#!/bin/bash
# 下載并安裝 Kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-8.11.0-linux-x86_64.tar.gz
tar -xzf kibana-8.11.0-linux-x86_64.tar.gz
sudo mv kibana-8.11.0 /opt/kibana
sudo chown -R elasticsearch:elasticsearch /opt/kibana5.2 Kibana 配置文件
# /opt/kibana/config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
server.name: "personal-monitoring-kibana"# Elasticsearch 連接配置
elasticsearch.hosts: ["http://localhost:9200"]
elasticsearch.requestTimeout: 30000
elasticsearch.shardTimeout: 30000# 日志配置
logging.appenders.file.type: file
logging.appenders.file.fileName: /opt/kibana/logs/kibana.log
logging.appenders.file.layout.type: json# 性能優化
server.maxPayload: 1048576
elasticsearch.pingTimeout: 15005.3 啟動腳本
#!/bin/bash
# /opt/kibana/bin/start-kibana.sh# 設置 Node.js 內存限制
export NODE_OPTIONS="--max-old-space-size=2048"# 啟動 Kibana
sudo -u elasticsearch /opt/kibana/bin/kibana &# 等待服務啟動
echo "等待 Kibana 啟動..."
sleep 60# 檢查服務狀態
curl -I http://localhost:56016. Filebeat 日志收集配置
6.1 Filebeat 安裝
#!/bin/bash
# 下載并安裝 Filebeat
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.11.0-linux-x86_64.tar.gz
tar -xzf filebeat-8.11.0-linux-x86_64.tar.gz
sudo mv filebeat-8.11.0-linux-x86_64 /opt/filebeat
sudo chown -R root:root /opt/filebeat6.2 Filebeat 配置
# /opt/filebeat/filebeat.yml
filebeat.inputs:
- type: logenabled: truepaths:- /var/log/nginx/*.log- /var/log/apache2/*.logfields:logtype: webserverfields_under_root: truemultiline.pattern: '^\d{4}-\d{2}-\d{2}'multiline.negate: truemultiline.match: after- type: logenabled: truepaths:- /var/log/syslog- /var/log/auth.logfields:logtype: systemfields_under_root: true- type: logenabled: truepaths:- /opt/applications/*/logs/*.logfields:logtype: applicationfields_under_root: true# 輸出配置
output.logstash:hosts: ["localhost:5044"]# 處理器配置
processors:- add_host_metadata:when.not.contains.tags: forwarded- add_docker_metadata: ~- add_kubernetes_metadata: ~# 日志配置
logging.level: info
logging.to_files: true
logging.files:path: /opt/filebeat/logsname: filebeatkeepfiles: 7permissions: 0644這個配置文件定義了多種日志輸入源,包括 Web 服務器日志、系統日志和應用程序日志,并通過處理器添加了主機元數據。
7. 監控儀表板設計
7.1 系統性能監控
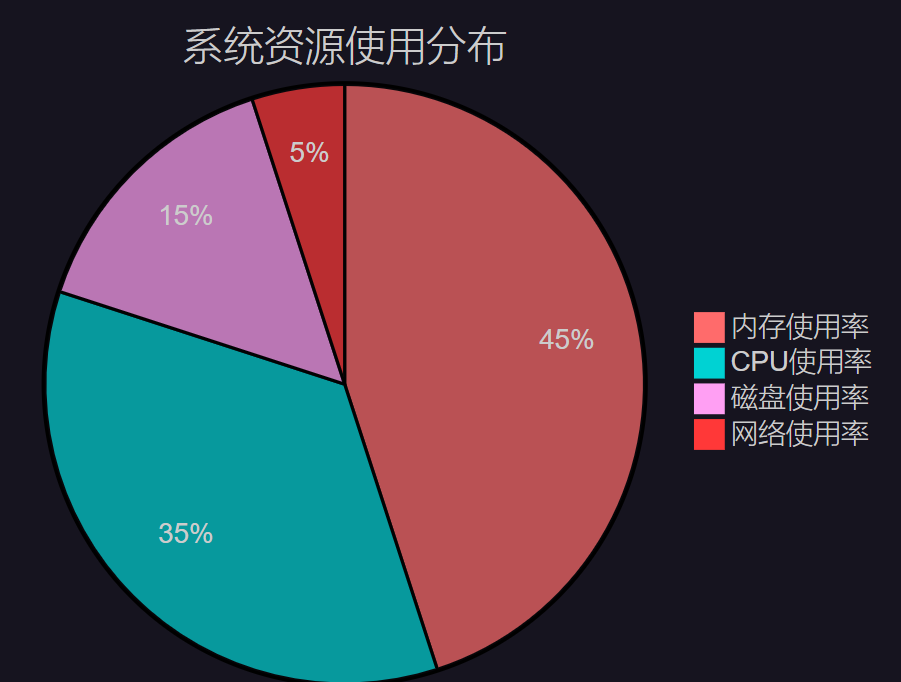
圖3:系統資源使用分布餅圖 - 展示各項資源的占用比例
7.2 告警規則配置
{"trigger": {"schedule": {"interval": "1m"}},"input": {"search": {"request": {"search_type": "query_then_fetch","indices": ["logs-*"],"body": {"query": {"bool": {"must": [{"range": {"@timestamp": {"gte": "now-5m"}}},{"match": {"level": "ERROR"}}]}}}}}},"condition": {"compare": {"ctx.payload.hits.total": {"gt": 10}}},"actions": {"send_email": {"email": {"to": ["admin@example.com"],"subject": "錯誤日志告警","body": "在過去5分鐘內檢測到超過10條錯誤日志"}}}
}這個告警規則監控錯誤級別的日志,當5分鐘內出現超過10條錯誤日志時觸發郵件告警。
8. 性能優化與最佳實踐
8.1 索引生命周期管理
{"policy": {"phases": {"hot": {"actions": {"rollover": {"max_size": "5GB","max_age": "1d"}}},"warm": {"min_age": "7d","actions": {"allocate": {"number_of_replicas": 0}}},"cold": {"min_age": "30d","actions": {"allocate": {"number_of_replicas": 0}}},"delete": {"min_age": "90d"}}}
}8.3 集群健康檢查腳本
#!/bin/bash
# elk-health-check.sh# 檢查 Elasticsearch 集群健康狀態
check_elasticsearch() {echo "檢查 Elasticsearch 健康狀態..."health=$(curl -s "localhost:9200/_cluster/health" | jq -r '.status')case $health in"green")echo "? Elasticsearch 狀態:健康";;"yellow")echo "?? Elasticsearch 狀態:警告";;"red")echo "? Elasticsearch 狀態:嚴重"exit 1;;*)echo "? Elasticsearch 無響應"exit 1;;esac
}# 檢查 Logstash 狀態
check_logstash() {echo "檢查 Logstash 狀態..."if pgrep -f logstash > /dev/null; thenecho "? Logstash 運行正常"elseecho "? Logstash 未運行"exit 1fi
}# 檢查 Kibana 狀態
check_kibana() {echo "檢查 Kibana 狀態..."status=$(curl -s -o /dev/null -w "%{http_code}" "localhost:5601/api/status")if [ "$status" = "200" ]; thenecho "? Kibana 運行正常"elseecho "? Kibana 狀態異常 (HTTP: $status)"exit 1fi
}# 執行所有檢查
check_elasticsearch
check_logstash
check_kibanaecho "🎉 ELK Stack 整體狀態良好"這個健康檢查腳本可以定期執行,確保 ELK Stack 各組件正常運行。
9. 安全加固與訪問控制
9.1 網絡安全配置
#!/bin/bash
# 配置防火墻規則
sudo ufw allow 22/tcp # SSH
sudo ufw allow 5601/tcp # Kibana
sudo ufw deny 9200/tcp # Elasticsearch (僅內網訪問)
sudo ufw deny 5044/tcp # Logstash (僅內網訪問)# 啟用防火墻
sudo ufw --force enable9.2 SSL/TLS 配置
# elasticsearch.yml SSL 配置
xpack.security.enabled: true
xpack.security.http.ssl.enabled: true
xpack.security.http.ssl.key: /opt/elasticsearch/config/certs/elasticsearch.key
xpack.security.http.ssl.certificate: /opt/elasticsearch/config/certs/elasticsearch.crt
xpack.security.http.ssl.certificate_authorities: /opt/elasticsearch/config/certs/ca.crt10. 故障排查與維護
10.1 常見問題診斷
| 問題類型 | 癥狀 | 可能原因 | 解決方案 |
| 內存不足 | 服務頻繁重啟 | JVM堆內存設置過小 | 調整ES_JAVA_OPTS參數 |
| 磁盤空間 | 索引創建失敗 | 磁盤空間不足 | 清理舊索引或擴容 |
| 網絡連接 | 組件間通信失敗 | 防火墻阻斷 | 檢查端口配置 |
| 配置錯誤 | 服務啟動失敗 | 配置文件語法錯誤 | 驗證YAML語法 |
10.2 日志輪轉配置
#!/bin/bash
# /etc/logrotate.d/elk-logs/opt/elasticsearch/logs/*.log {dailymissingokrotate 30compressdelaycompressnotifemptycreate 644 elasticsearch elasticsearchpostrotate/bin/kill -USR1 `cat /opt/elasticsearch/logs/elasticsearch.pid 2> /dev/null` 2> /dev/null || trueendscript
}/opt/logstash/logs/*.log {dailymissingokrotate 14compressdelaycompressnotifemptycreate 644 elasticsearch elasticsearch
}最佳實踐提醒
"在運維監控中,預防勝于治療。定期的健康檢查、合理的資源規劃和及時的告警響應,是保障系統穩定運行的三大支柱。"
總結
通過這次 ELK Stack 個人監控平臺的搭建實踐,我深刻體會到了日志分析在現代運維中的重要價值。從最初的環境準備到最終的性能優化,每一個環節都充滿了技術挑戰和學習機會。
在整個部署過程中,我遇到了許多典型問題:Elasticsearch 的內存配置需要根據實際硬件資源進行調優,Logstash 的 Grok 模式需要針對不同的日志格式進行定制,Kibana 的儀表板設計需要平衡美觀性和實用性。這些問題的解決過程讓我對 ELK Stack 的架構原理有了更深入的理解。
特別值得一提的是索引生命周期管理策略的設計。通過合理的熱溫冷數據分層存儲,不僅能夠有效控制存儲成本,還能保證查詢性能。我設置的90天數據保留策略在滿足業務需求的同時,也避免了磁盤空間的無限增長。
在安全方面,雖然為了簡化初始部署關閉了 X-Pack 安全功能,但在生產環境中,我強烈建議啟用 SSL/TLS 加密和基于角色的訪問控制。網絡層面的防火墻配置也是必不可少的安全措施。
性能監控和告警機制的建立讓這個平臺具備了真正的實用價值。通過自定義的儀表板,我可以實時監控系統的關鍵指標;通過靈活的告警規則,能夠在問題發生的第一時間收到通知。這種主動式的監控方式大大提升了運維效率。
回顧整個項目,我認為最大的收獲不僅僅是技術技能的提升,更是對監控體系建設的系統性思考。一個優秀的監控平臺不僅要能夠收集和展示數據,更要能夠從海量信息中提取有價值的洞察,為業務決策提供數據支撐。
未來,我計劃在這個基礎平臺上繼續擴展功能,比如集成機器學習算法進行異常檢測,添加更多的數據源支持,以及開發自定義的監控插件。技術的學習永無止境,但正是這種持續的探索和實踐,讓我們在技術的道路上不斷前行。
我是摘星!如果這篇文章在你的技術成長路上留下了印記
👁? 【關注】與我一起探索技術的無限可能,見證每一次突破
👍 【點贊】為優質技術內容點亮明燈,傳遞知識的力量
🔖 【收藏】將精華內容珍藏,隨時回顧技術要點
💬 【評論】分享你的獨特見解,讓思維碰撞出智慧火花
🗳? 【投票】用你的選擇為技術社區貢獻一份力量
技術路漫漫,讓我們攜手前行,在代碼的世界里摘取屬于程序員的那片星辰大海!
參考鏈接
- Elasticsearch 官方文檔
- Logstash 配置指南
- Kibana 用戶手冊
- Filebeat 參考文檔
- ELK Stack 最佳實踐
關鍵詞標簽
ELK Stack 日志分析 Elasticsearch Logstash Kibana 運控 系統監控 日志收集 數據可視化 性能優化維監

)


(IP地址、子網和公網、NAPT、代理))



-關于token)





)
![[Maven 基礎課程]第一個 Maven 項目](http://pic.xiahunao.cn/[Maven 基礎課程]第一個 Maven 項目)



