文章目錄
- 進程創建
- 進程等待
- 程序替換
- 進程終止
進程創建
fork函數: 操作系統提供的創建新進程的方法,父進程通過調用 fork函數 創建一個子進程,父子進程代碼共享,數據獨有。

當調用 fork函數 時,通過 寫時拷貝技術 來拷貝父進程的信息。
寫時拷貝技術(copy on write): 子進程通過復制父進程的 PCB,使得父子進程指向同一塊物理內存,運行位置和代碼也相同。但又因為進程的獨立性,所以當某一個進程數據發生改變的時候會重新給子進程開辟物理內存,將數據拷貝過去。(之所以這樣使用是因為如果數據不修改的話還開辟空間拷貝數據會使效率降低)這也就是數據獨有的原因。
代碼共享: 通過頁表來實現訪問控制,使代碼段是只讀的,不可修改。
fork函數 的運用:
#include<iostream>
#include<unistd.h>
#include<stdlib.h>using namespace std;int main()
{cout << "hello world" << getpid() << endl;int id = fork();if(id < 0){cerr << "fork failed" << endl;}else if(id == 0){cout << "I am child process, id = " << getpid() << endl;}else{cout << "I am parent process, id = " << getpid() << endl;}return 0;
}
運行結果:

父進程調用 fork函數 后,對操作系統來說,這時看起來有兩個完全一樣的 test程序 在運行,并都從 fork() 系統調用中返回。區別在于,子進程不會從 main()函數 開始執行(因此 hello world 信息只輸出了一次),而是直接從 fork() 系統調用返回,就好像是它自己調用了fork() ,只是返回值和父進程不同罷了。
實際上,上圖的輸出結果并不是唯一答案,也有可能 子進程先于父進程執行完畢 。
vfork函數: 創建一個子進程,并且阻塞父進程,直到子進程退出或者程序替換,父進程才繼續運行。
#include <unistd.h>
pid_t vfork(void);
返回值:自進程中返回0,父進程返回子進程id.出錯返回1。
vfork 創建子進程的效率比 fork 要高,因為 vfork 所創建的子進程和父進程共用同一個虛擬地址空間。
但也因為這樣,進程之間就不具備獨立性,父子進程不能同時訪問代碼段和數據段,所以當子進程運行的時候必須要阻塞父進程,防止產生沖突。
雖然 vfork 效率高,但是 fork 因為實現了寫時拷貝技術,效率提高了不少,所以 vfork 已經很少使用了。
進程等待
之前講過,如果子進程退出時沒有給父進程返回退出的信息,父進程就會以為他并沒有退出,所以一直不釋放他的資源,使子進程進入僵死狀態。
之前的解決方法是退出父進程,但是那個不是一個合理的解決方法,這里有更好的方法,就是進程等待。
- wait: 阻塞等待任意一個進程退出,獲取退出子進程的
pid,并且釋放子進程資源。
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int*status);
返回值:
成功返回被等待進程pid,失敗返回-1。
參數:
輸出型參數,獲取子進程退出狀態,不關心則可以設置為NULL
- 阻塞:為了完成某個功能發起調用,如果不具備完成功能的條件,則調用不返回一直等待。
- 非阻塞:為了完成某個功能發起調用,如果不具備完成功能的條件,則立即報錯返回
wait函數 的運用:
#include<iostream>
#include<unistd.h>
#include<stdlib.h>
#include<sys/wait.h>using namespace std;int main()
{cout << "hello world, My id = " << getpid() << endl;int id = fork();if(id < 0){cerr << "fork failed" << endl;}else if(id == 0){cout << "I am child process, id = " << getpid() << endl;}else{int wc = wait(NULL);cout << "I am parent process, id = " << getpid() << ". My child id = " << id << ". wc: " << wc << endl;}return 0;
}
運行結果:

對比 fork函數 的運行實例可以看到,本次運行 子進程 要先于 父進程 完成,這是因為 父進程 調用了 wait() ,延遲了自己的的執行(阻塞),直到 子進程 執行完畢,wait() 才返回父進程。
但與 fork函數 的運行實例不同,本實例的運行結果是唯一的:
- 如果子進程先運行,父進程調用
wait()時子進程早已執行完畢,父進程無需阻塞自己,那么輸出結果如上沒什么可多說的。 - 如果父進程先運行,那么到調用
wait()的時候必須等待子進程運行結束后才能返回,接著輸出(父進程)自己的信息。
- waitpid: 可以指定等待一個子進程的退出。
#include<sys/wait.h>
pid_ t waitpid(pid_t pid, int *status, int options);返回值:
當正常返回的時候 waitpid 返回收集到的子進程的進程ID;
如果設置了選項 WNOHANG ,而調用中 waitpid 發現沒有已退出的子進程可收集,則返回0;
如果調用中出錯,則返回-1,這時 errno 會被設置成相應的值以指示錯誤所在;參數:
- pid:
Pid=-1,等待任一個子進程。與wait等效。
Pid>0.等待其進程ID與pid相等的子進程。
- status:
WIFEXITED(status): 若為正常終止子進程返回的狀態,則為真。(查看進程是否是正常退出)
WEXITSTATUS(status): 若WIFEXITED非零,提取子進程退出碼。(查看進程的退出碼)
- options:
WNOHANG: 若 pid 指定的子進程沒有結束,則 waitpid() 函數返回0,不予以等待。若正常結束,則返回該子進程的ID。
程序替換
創建子進程必定是想讓 子進程做與父進程不一樣的事情 ,如果采用判斷 pid 的方法來進行代碼分流,這樣的程序會非常龐大,所以還有更好的方法,就是通過 exec()函數 來實現 程序替換 。
exec: 是創建進程 API 的重要組成部分。可以讓 子進程執行與父進程不同的程序 。
程序替換: exec() 加載另一個程序的代碼和靜態數據到內存中,覆蓋自己的代碼段(以及靜態數據),堆、棧及其他控件也會被重新初始化。PCB 不再調度原來的程序,而調度這個新的程序。(只是改變了映射關系,所以原本的 PCB 和程序還在)
#include <unistd.h>`
int execl(const char *path, const char *arg, …);
int execlp(const char *file, const char *arg, …);
int execle(const char *path, const char *arg, …,char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);
乍一看這么多接口很不容易記,其實是有規律的:
- l(list) : 表示參數采用列表
- v(vector) : 參數用數組
- p(path) : 有
p自動搜索環境變量PATH - e(env) : 有
e表示自己維護環境變量
exec()函數 的運用:
#include<iostream>
#include<unistd.h>
#include<stdlib.h>
#include<sys/wait.h>
#include<string.h>using namespace std;int main(int argc, char *argv[])
{cout << "hello world, My id = " << getpid() << endl;int id = fork();if(id < 0){cerr << "fork failed" << endl;exit(1);}else if(id == 0){cout << "I am child process, id = " << getpid() << endl;char* s[3];s[0] = strdup("wc");s[1] = strdup("test");s[2] = NULL;execvp(s[0], s);cout << "This shouldn't print out." << endl;}else{int wt = wait(NULL);cout << "I am parent process, id = " << getpid() << ". My child id = " << id << ". wt: " << wt << endl;}return 0;}運行結果:

在本例中,子進程調用 execvp() 來運行字符計數程序 wc 。將計數程序 wc 作為可執行文件 test 的執行參數,輸出該文件有多少行、多少單詞、多少字節。exec() 從可執行程序 wc 中加載代碼和靜態數據以覆蓋運來的代碼段(及靜態數據),并重新初始化堆、棧及其他內存空間,然后操作系統執行該程序,將參數通過 argv 傳遞給該進程。exec() 并不創建新進程,而是直接將當前運行的程序(test)替換為不同的運行程序(wc),子程序執行 exec() 后,幾乎就像 test 從未運行過一樣,對 exec() 的成功調用永遠不會返回。
fork() 和 exec() 的組合既簡單又極其強大,fork 使用 父進程 的各種資源迅速創建一個 子進程 ,在修改 子進程 的 資源/環境 而保證 父進程 能執行 原來的需求工作 ,再將 子進程 exec 為另一個程序,從而 創建兩個并行的功能不同的進程 。
shell 也可以通過 fork() 和 exec() 方便地實現很多有用的功能。比如,上面的例子可以寫成:
prompt> wc p3.c > newfile.txt
在上面的 shell 命令中,wc 的輸出結果被 重定向(redirect) 到文件 newfile.txt 中(通過 newfile.txt 之前的大于號來指明重定向)。shell 實現結果重定向的方式也很簡單,當完成子進程的創建后,shell 在調用 exec() 之前先關閉了標準輸出(standard output ),打開了文件 newfile.txt 。這樣,即將運行的程序 wc 的輸出結果就被發送到該文件,而不是打印在屏幕上。
用代碼實現重定向:
#include<iostream>
#include<unistd.h>
#include<stdlib.h>
#include<sys/wait.h>
#include<string.h>
#include<fcntl.h>using namespace std;int main(int argc, char *argv[])
{int id = fork();if(id < 0){cerr << "fork failed" << endl;exit(1);}else if(id == 0){close(STDOUT_FILENO);open("./test.output", O_CREAT|O_WRONLY|O_TRUNC, S_IRWXU);// now exec "wc"...char* s[3];s[0] = strdup("wc");s[1] = strdup("test");s[2] = NULL;execvp(s[0], s);}else{int wt = wait(NULL);}return 0;}
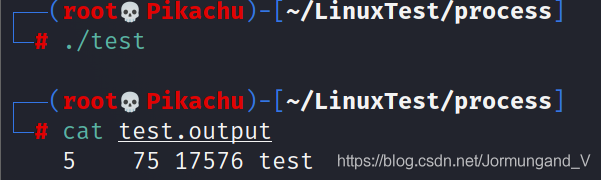
上例中 重定向的工作原理: 重定向是 基于對操作系統管理文件描述符方式的假設 。具體來說,UNIX 系統從 0 開始尋找可以使用的文件描述符。在這個例子中,STDOUT_FILENO(標準輸出文件描述符) 將成為第一個可用的文件描述符,因此在 open() 被調用時,得到賦值。然后子進程向 標準輸出文件描述符 的寫入(例如 wc 程序中 printf() 這樣的函數),都會被透明地轉向新打開的文件,而不是屏幕。
UNIX管道也是用類似的方式實現的,但用的是 pipe() 系統調用。
進程終止
在 Linux 下有三種終止進程的方法。
-
return: 只能在
main函數中使用,退出后刷新緩沖區 -
exit: 庫函數調用接口,退出刷新緩沖區
#include <unistd.h>
void exit(int status);
- _exit: 系統函數調用接口,退出不刷新緩沖區
#include <unistd.h>
void _exit(int status);
參數:status 定義了進程的終止狀態,父進程通過wait來獲取該值

調用))
【標準流和其文件描述符、fwrite函數、perror函數】)







| 數據類型、常用命令一覽、庫的操作、表的操作)


| 表的增刪查改、聚合函數(復合函數)、聯合查詢)



:模板基礎:函數模板、類模板、模板推演成函數的機制、模板實例化、模板匹配規則)

:非類型模板參數,模板特化,模板的分離編譯)