客戶細分模型
Lets assume that you are a CEO of a company which have some X amount of customers in a city with 1000 *X population. Analyzing the trends/features of your customer and segmenting the population of the city to land new potential customers would be a very important step for any company.
假設您是一家公司的CEO,該公司在人口為1000 * X的城市中有大約X個客戶。 對于任何公司來說,分析客戶的趨勢/特征并劃分城市人口以吸引新的潛在客戶都是非常重要的一步。
This is very interesting work for an aspiring Data Scientist like me who would love to work with such real world datasets. The following article is a similar work on data provide by Avarto Financial Solutions for Udacity Nano-Degree Capstone Project.
對于像我這樣有抱負的數據科學家來說,這是一件非常有趣的工作,他們愿意使用這樣的現實世界數據集。 以下文章是Avarto Financial Solutions為Udacity Nano-Degree Capstone項目提供的數據的類似工作。
This project can we divided into three parts:
這個項目我們可以分為三個部分:
Customer Segmentation using unsupervised techniques
使用無監督技術進行客戶細分
Supervised Learning Model
監督學習模型
Kaggle Competition
Kaggle比賽
Data Overview:
數據概述:
The following the files which are given by Avarto Financial Services:
Avarto Financial Services提供的以下文件:
- Azdias.csv : Demographics data for the general population of Germany 891,211 persons (rows) x 366 features (columns) Azdias.csv:德國總人口的人口統計數據891,211人(行)x 366個特征(列)
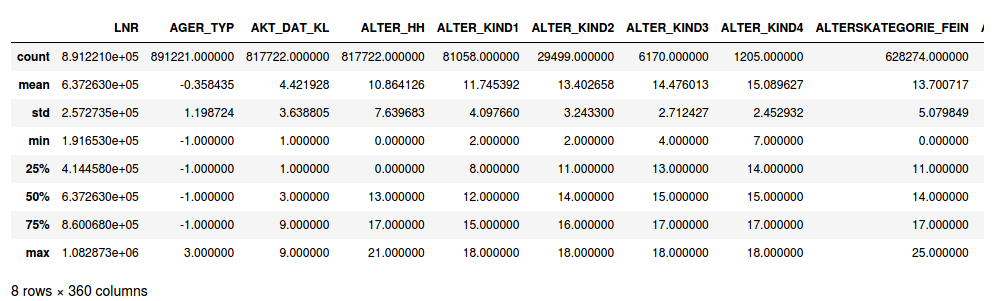
2. Customers.csv: Demographics data for customers in a mail-order company 191652 persons (rows) x 369 features (columns)
2. Customers.csv:郵購公司中客戶的人口統計數據191652人(行)x 369個特征(列)
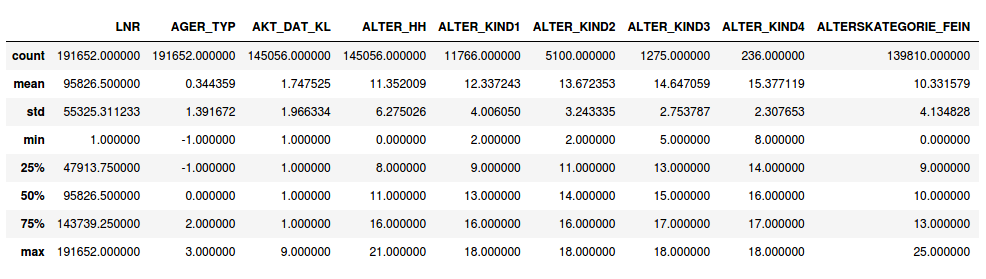
3. Train.csv: Demographics data for individuals who were targets of a marketing campaign (train) — 42,982 persons (rows) x 367 (columns)
3. Train.csv:作為營銷活動目標的個人的人口統計數據(火車)-42,982人(行)x 367(列)
4. Test.csv: Demographics data for individuals who were targets of a marketing campaign (test) — 42,833 persons (rows) x 366 (columns)
4. Test.csv:作為營銷活動目標的個人的人口統計數據(測試)-42,833人(行)x 366(列)
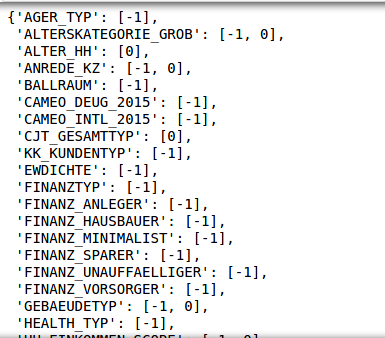
An excel for describing all the features and the explanations of each of their values was given in a seperate file. This excel was read and a dictionary was made out it for mapping all these values to NaNs.
在單獨的文件中提供了一個用于描述所有功能以及每個值的解釋的excel。 讀取了此excel,并制作了字典以將所有這些值映射到NaN。
Pre-processing Data:
預處理數據:
Initially, the number of NaNs in the Azdias dataset were less. After mapping, the unknown values of each column increased. The following figures shows the top 15 columns which had maximum number of null values after mapping of the unknown values.
最初,Azdias數據集中的NaN數量較少。 映射后,每列的未知值增加。 下圖顯示了映射未知值后具有最大空值數量的前15列。

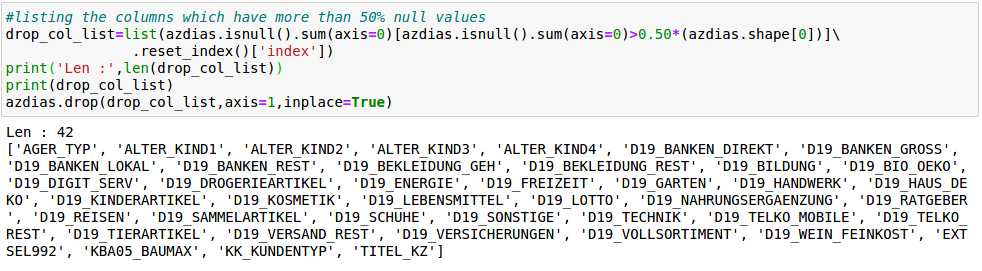
On checking the proportion of null values, there were 42 columns which had more than 50% of their values as NaNs. These columns were subsequently dropped from the dataset. One thing to note here is to store these column names which can be applied later to the customers dataset.
在檢查空值的比例時,有42列的NaN占其值的50%以上。 這些列隨后從數據集中刪除。 這里要注意的一件事是存儲這些列名,這些列名以后可以應用于客戶數據集。
There 6 features which were categorical in nature. Features such as ‘EINGEFUEGT_AM’ , ’D19_LETZTER_KAUF_BRANCHE’ were dropped because these were too detailed. Dummies were created for column ‘CAMEO_DEU_2015’ for all its individual values.
本質上有6個特征是分類的。 刪除了諸如“ EINGEFUEGT_AM”,“ D19_LETZTER_KAUF_BRANCHE”之類的功能,因為這些功能過于詳細。 為“ CAMEO_DEU_2015”列創建了所有虛擬值的虛擬變量。
The columns ‘CAMEO_INTL_2015’ and ‘CAMEO_DEUG_2015’ had arbitrary values such as ‘XX’ and ‘X’ which needed to be replaced by NaN. These values also present in ‘CAMEO_DEU_2015’ feature and was subsequently dropped after creating dummies.
列“ CAMEO_INTL_2015”和“ CAMEO_DEUG_2015”具有任意值,例如“ XX”和“ X”,需要用NaN替換。 這些值也出現在“ CAMEO_DEU_2015”功能中,并在創建虛擬變量后被刪除。
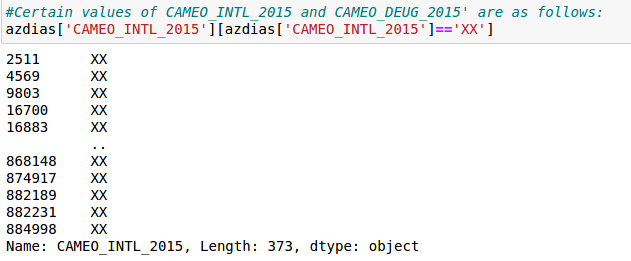
Pre-processing on three particular columns involved manipulation of data.
在三個特定列上的預處理涉及數據處理。
- ‘CAMEO_INTL_2015’ : column for international topology. This column had two internal features such as ‘WEALTH’ and ‘LIFE_CYCLE’ combined in the dataset. Thus, two independent columns were generated from this column. 'CAMEO_INTL_2015':國際拓撲列。 該列在數據集中具有兩個內部功能,例如“ WEALTH”和“ LIFE_CYCLE”。 因此,從該列中生成了兩個獨立的列。
- ‘PRAEGENDE_JUGENDJAHRE’: column for dominating movement in the person’s youth (avantgarde or mainstream). This column was dropped and another column named ‘MOVEMENT’ was generated from this column with two values. {1:mainstream,2:avantgarde} 'PRAEGENDE_JUGENDJAHRE':專欄,用于支配青年(前衛或主流)青年的運動。 刪除該列,并從該列中生成另一個名為“ MOVEMENT”的列,其中包含兩個值。 {1:主流,2:前衛}
- The ‘OST_WEST_KZ’ is converted into integer values by mapping ‘o’ to 1 and ‘w’ to 2. 通過將'o'映射為1并將'w'映射為2,將'OST_WEST_KZ'轉換為整數值。

Using the sklearn library, the SimpleImputer and StandardScaler for every column was used. Similar, process of pre-processing, imputation and standardization was applied to the customers data as well.
使用sklearn庫,每列都使用SimpleImputer和StandardScaler。 同樣,預處理,插補和標準化過程也應用于客戶數據。
Before jumping into the 1st part of the project, the number of features were reduced to 363 columns. All the columns represented float values and the data was ready to be utilize further for the customer segmentation.
在進入項目的第一部分之前,要素數量已減少到363列。 所有列均表示浮點值,數據已準備好進一步用于客戶細分。
Part 1: Customer Segment
第1部分:客戶群
Principal Component Analysis:
主成分分析:
It is not feasible to work with 363 features. Each feature would represent some amount of variance. Thus, PCA was applied to reduce the dimensionality of the data. After applying PCA for many different n_components, I decided to finalize 181 features which is exactly the half number of features of clean data.
使用363個功能不可行。 每個特征將代表一定數量的方差。 因此,應用PCA來減少數據的維數。 在將PCA應用于許多不同的n_components之后,我決定完成181個特征,這些特征恰好是干凈數據特征的一半。
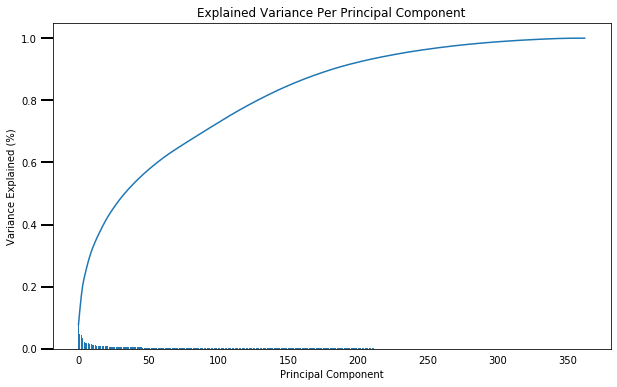
As it can be seen, 181 features roughly can give 90% of the information of the entire data. The principal components were studied in detail regarding the features which were most important.
可以看出,大約181個要素可以提供全部數據的90%的信息。 對主要組成部分進行了詳細的最重要的功能研究。
Following figures can give a rough estimation about the feature importance for the first three principal components.
下圖可以粗略地估計出前三個主要組件的功能重要性。



For cluster segmentation, initially the Elbow method was implemented to identify the ideal number of clusters for k-means clustering. The sum of squared errors was calculated for each number of cluster using the MiniBatchKmeans.
對于聚類分割,最初采用Elbow方法來確定k均值聚類的理想聚類數。 使用MiniBatchKmeans為每個簇數計算平方誤差總和。
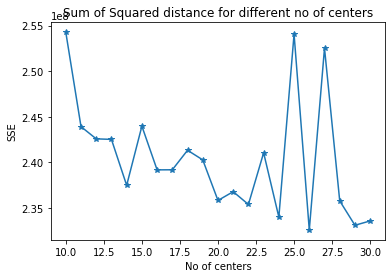
Using the same pipeline, the customers data set was transformed. The number of clusters used was 30. Although, number of clusters=26 would also suffice the needs. The Kmeans algorithm with number of clusters as 30 was used to fit_predict the PCA fitted azdias data. The same model was used to transform the PCA transformed customers data. The below plot shows the similarity of both the datasets for the 30 clusters.
使用相同的管道,轉換了客戶數據集。 使用的群集數為30。盡管,群集數= 26也可以滿足需求。 使用簇數為30的Kmeans算法來fit_預測PCA擬合的azdias數據。 使用相同的模型來轉換PCA轉換的客戶數據。 下圖顯示了30個聚類的兩個數據集的相似性。
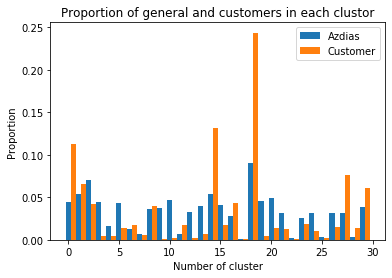
From the above figure, it would be ideal to plot the differences between the proportion of customers and azdias. This difference in proportion would be useful to predict the group of general population which can be considered as potential future customers.
根據上圖,繪制客戶和azdias比例之間的差異是理想的。 這種比例上的差異將有助于預測可被視為潛在未來客戶的普通人群。
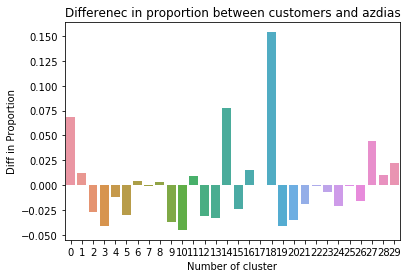
It can be clearly found out that, general audience in the clusters of #18, #14, and #0 would be an ideal choice or have a potential to become future customers. The azdias data points of people in groups #10,#9,#19, and #3 would be considered as non target audience for the mail order company.
可以清楚地發現,在#18,#14和#0集群中的一般受眾將是理想的選擇,或者具有成為未來客戶的潛力。 #10,#9,#19和#3組中人員的azdias數據點將被視為郵購公司的非目標受眾。
Part 2: Supervised Learning Model
第2部分:監督學習模型
In order to predict whether a person would be a target or non_target for the mail_order company, it would be ideal to model a supervised model. The training data provides the demographic data for such individuals which can be classified as target and non target. The labels for these data points are given to train the supervised model.
為了預測某個人是郵購公司的目標還是非目標,對受監管模型進行建模是理想的。 訓練數據為此類個人提供了人口統計數據,可以將其分類為目標和非目標。 這些數據點的標簽用于訓練監督模型。
Taking a look at the responses, it can be found that the training data is imbalanced in terms its responses.Only 12% of the total responses are 1 (i.e. targets) while others are non-targets. Thus, the data is subjected to predicting non targets more often the targets.
看一下響應,可以發現訓練數據的響應是不平衡的。總響應中只有12%是1(即目標),而其他不是目標。 因此,更經常地對數據進行非目標預測。
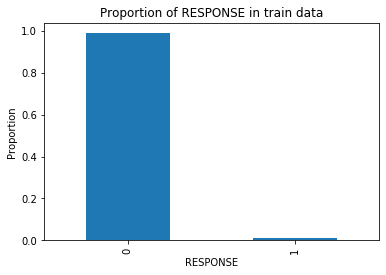
In order to tackle this problem, two steps were taken.
為了解決這個問題,采取了兩個步驟。
- Using the Stratified Cross Fold Validation : This type of cross validation technique was used because Stratified Kfold maintains the proportion of each class in every fold. In other words, for two fold Stratified cross fold validation, each fold would get 0.06% of target data points and 0.44% of non target data points. 使用分層交叉折疊驗證:之所以使用這種類型的交叉驗證技術,是因為分層Kfold保持每個折疊中每個類別的比例。 換句話說,對于兩次分層交叉折疊驗證,每一次折疊將獲得0.06%的目標數據點和0.44%的非目標數據點。
Using advanced bagging/boosting techniques: Ensemble learning is method of building a model on top of other models. Adaboost Regressor, Gradient Boosting Regressor, and XGBoost Regressor in Scikit-learn are all ensemble classifiers built on top of Decision tree model (by default).
使用高級裝袋/增強技術:集成學習是在其他模型之上構建模型的方法。 Scikit-learn中的Adaboost Regressor,Gradient Boosting Regressor和XGBoost Regressor都是基于決策樹模型(默認情況下)構建的集成分類器。
These ensemble models work great both for classification and for regression problems and in general has the following benefits:
這些集成模型對于分類和回歸問題均適用,并且通常具有以下優點:
- improves the stability and accuracy of machine learning algorithms; 提高機器學習算法的穩定性和準確性;
- reduces variance of a single estimate from one model as they combine several estimates from several models; 減少來自一個模型的單個估計的方差,因為它們組合了來自多個模型的多個估計;
- helps to avoid overfitting. 有助于避免過度擬合。
The models are initially fitted on the training data which was splitted into training and validation data using the Stratified K-fold technique with n_fold=7.
首先將模型擬合到訓練數據上,然后使用n_fold = 7的分層K折技術將其分為訓練和驗證數據。
Model Evaluation:
模型評估:
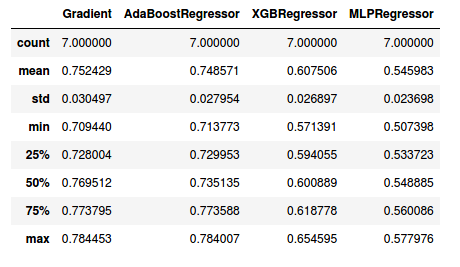
ROC_AUC was selected to be the metric. To evaluate the models, the training data was split into training and validation data with test_size=0.3. Then, the training data was split into percentages from 30 to 100 of the training size and the corresponding roc_auc for training and validation were plotted.
選擇ROC_AUC作為度量標準。 為了評估模型,將訓練數據分為test_size = 0.3的訓練和驗證數據。 然后,將訓練數據分成訓練大小的30%到100%的百分比,并繪制相應的roc_auc進行訓練和驗證。
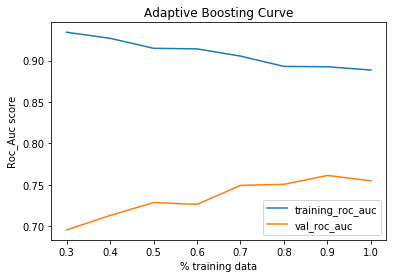
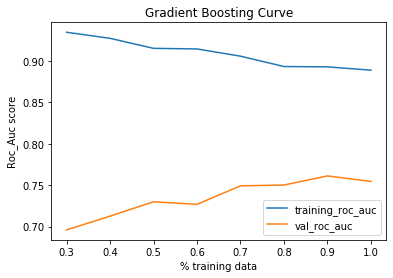
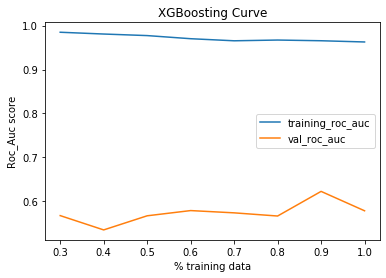
As it can be seen that, the XGBoost Regressor does not perform well with the max val roc_auc of 0.65. The remaining models have similar roc_auc. These models were further fined tuned by hyper-paramater tuning using grid search.
可以看出,在最大val roc_auc為0.65的情況下,XGBoost回歸器的性能不佳。 其余模型具有類似的roc_auc。 通過使用網格搜索的超參數調整對這些模型進行了進一步的調整。
Grid Search
網格搜索
The Adaptive Boosting was further fined tuned by tweaking learning_rate and n_estimators. It was found that smaller learning rates and larger n_estimators were giving the best results. Gradient Boosting Regression was also fined similarly and was able to interpret similar trends. However, it takes longer time to run this model. Although, XG Boosting (Extreme Boosting) was not performing well enough, it was fined tuned further by tweaking learning rate and gamma.
通過調整learning_rate和n_estimators進一步調整了自適應提升。 結果發現,較小的學習率和較大的n_estimator給出最佳結果。 梯度提升回歸也被類似地罰款,并且能夠解釋類似的趨勢。 但是,運行此模型需要更長的時間。 盡管XG Boosting(Extreme Boosting)的性能不夠好,但通過調整學習率和伽瑪系數進一步對其進行了微調。



The final models after the grid search and fine tuning the hyper parameters are as follows:
在網格搜索和微調超參數之后的最終模型如下:

All the three models were able to get 76% accuracy on the training data.
這三個模型在訓練數據上都能獲得76%的準確性。

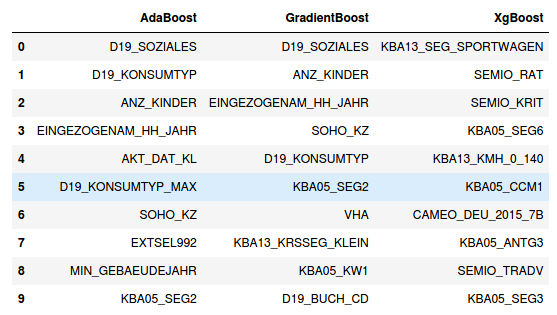
These models were traced back to figure out which feature stands as the most important out of the 363 clean features. It is found out that, the feature ‘D19_SOZIALES’ is the most important feature for two out the three models.
追溯這些模型以找出363個清潔功能中最重要的功能。 結果發現,對于三個模型中的兩個,特征“ D19_SOZIALES”是最重要的特征。
Part 3: Kaggle Competition
第3部分:Kaggle比賽
The cleaning data process was applied to the test data as well. The training data was fit on all the three models and predictions on test data for each model was submitted to Kaggle. As we were allowed to submit 5 submissions per, all the three predictions were submitted. The Gradient Boosting submission was the best, getting an accuracy of 79.959 on Kaggle.
清潔數據處理也適用于測試數據。 訓練數據適合所有三個模型,并且每個模型的測試數據預測已提交給Kaggle。 由于我們每個人可以提交5份意見書,因此所有三個預測均已提交。 梯度增強提交是最好的,在Kaggle上獲得了79.959的準確性。
In order to improve the accuracy, one can refine all the parameters of the models. Other models such as DecisionTreeRegressor can also be tried. One advice would be to try data augmentation technique. Try adding customer dataset points to the training data to handle the imbalance nature.
為了提高精度,可以對模型的所有參數進行細化。 也可以嘗試使用其他模型,例如DecisionTreeRegressor。 一種建議是嘗試使用數據增強技術。 嘗試將客戶數據集點添加到訓練數據中以處理不平衡性。
Improvements:
改進之處:
- Different cut off for dropping the columns in the datasets can be used. Eg 0.30 null values. 可以使用不同的截距來刪除數據集中的列。 例如0.30空值。
- Different Imputation techniques can be used like Median, Max etc. The features can also be divided into log attributes which are skewed, into mixed attributes and numerical attributes. 可以使用不同的插補技術,例如中位數,最大值等。特征還可以分為偏斜的對數屬性,混合屬性和數值屬性。
- Standardization can also changed like MinMaxScaler etc. 標準化也可以更改,例如MinMaxScaler等。
- Different Models like SVR, DecisionTreeClassifier can be test 可以測試SVR,DecisionTreeClassifier等不同模型
- Data Augmentation technique can be implemented to handle the imbalance nature of the dataset. Data points from customers data can be added to the training data to increase the positive responses in the training data. 可以實施數據增強技術來處理數據集的不平衡性質。 來自客戶數據的數據點可以添加到培訓數據中,以增加培訓數據中的積極響應。
Summary:
摘要:
In this project, provided by Udacity partners at Bertelsmann Arvato Analytics, the real-life demographics data of Germany population and customer segment was analyzed.
在這個由Bertelsmann Arvato Analytics的Udacity合作伙伴提供的項目中,分析了德國人口和客戶群的真實人口統計數據。
- In the first part of the project, pre-processing of the data was done. This was the most challenging part of the project. Conversion of mixed attributes and categorical features into numerical attributes consumes most time in this project. Following the data cleaning part was the imputation and standardization of the dataset. 在項目的第一部分,對數據進行了預處理。 這是該項目最具挑戰性的部分。 在此項目中,將混合屬性和分類特征轉換為數字屬性會花費大量時間。 數據清理部分之后是數據集的插補和標準化。
- For the Unsupervised learning part, PCA was applied to the cleaned dataset containing 363 features. The number of features were reduced to 181 after applying PCA which represents approx 90% of the data. Elbow method was used to determine the number of clusters in the kmeans algorithm. After applying Kmeans to both the datasets, it can be seen that the general population in cluster number #18, #14, and #0 would be an ideal choice or have a potential to become future customers. The azdias data points of people in groups #10,#9,#19, and #3 would be considered as non target audience for the mail order company. 對于無監督學習部分,將PCA應用于包含363個特征的清理數據集。 應用PCA后,特征數量減少到181,這代表了大約90%的數據。 kmeans算法中使用肘方法確定聚類數。 將Kmeans應用于這兩個數據集后,可以看出群集編號18、14和0的總體人口將是理想選擇,或者具有成為未來客戶的潛力。 #10,#9,#19和#3組中人員的azdias數據點將被視為郵購公司的非目標受眾。
- A supervised learning algorithm was built using advanced regression models like AdaBoost, GradientBoost and XGBoost. Techniques to handle imbalanced data like Stratified cross fold techniques were also learnt. ROC_AUC curves for these models were plotted to evaluate them. These models were further fined tuning using pipelines and gridsearch methods as learnt from the nano degree program. 使用高級回歸模型(如AdaBoost,GradientBoost和XGBoost)構建了監督學習算法。 還學習了處理不平衡數據的技術,例如分層交叉折疊技術。 繪制了這些模型的ROC_AUC曲線以對其進行評估。 這些模型通過使用管道和網格搜索方法(從納米程度程序中獲悉)進行了進一步的優化調整。
- A Kaggle score of 0.79959 was obtained from fine-tuned GradientBoost Regressor model. These results could be improved more by data augmentation techniques and further fine tuning other parameters of the model. 從微調的GradientBoost回歸模型獲得了0.79959的Kaggle分數。 通過數據增強技術和進一步微調模型的其他參數,可以進一步改善這些結果。
5. Improvements like different imputation, standardization and data augmentation techniques were also discussed which can augment the performance of this project further.
5.還討論了諸如不同歸因,標準化和數據增強技術之類的改進,這些改進可以進一步提高該項目的性能。
This project be very useful as it could be applied to various fields. I would like to thank again Avarto Financial Solutions for providing this real world datasets. A big thanks to all the instructors and team members of Udacity for their constant support during the nano degree journey.
該項目非常有用,因為它可以應用于各個領域。 我還要再次感謝Avarto Financial Solutions提供了這個真實的數據集。 非常感謝Udacity的所有講師和團隊成員在納米學位之旅中的不斷支持。
The project workbooks can be found here.[https://github.com/RuchitDoshi/Avarto_Customer_Segmentation]
項目工作簿可以在這里找到。[ https://github.com/RuchitDoshi/Avarto_Customer_Segmentation]
翻譯自: https://medium.com/@ruchitsd/customer-segmentation-and-supervised-learning-model-for-avarto-financial-solutions-374c946c99ac
客戶細分模型
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390795.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390795.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390795.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

用 Go 編寫一個簡單的 WebSocket 推送服務

leetcode 231. 2 的冪

Java概述、環境變量、注釋、關鍵字、標識符、常量
的內容)
寫游戲軟件要學什么_為什么要寫關于您所知道的(或所學到的)的內容

leetcode 342. 4的冪

梯度反傳_反事實政策梯度解釋

三款功能強大代碼比較工具Beyond compare、DiffMerge、WinMerge

shell腳本_Shell腳本

大數據與Hadoop


facebook.com_如何降低電子商務的Facebook CPM

Python中的If,Elif和Else語句

Hadoop安裝及配置

漏洞發布平臺-安百科技

Android 微信分享圖片

蒙蒂霍爾問題_常見的邏輯難題–騎士和刀,蒙蒂·霍爾和就餐哲學家的問題解釋...

西格爾零點猜想_我從埃里克·西格爾學到的東西

C/C++實現刪除字符串的首尾空格

