梯度反傳
Among many of its challenges, multi-agent reinforcement learning has one obstacle that is overlooked: “credit assignment.” To explain this concept, let’s first take a look at an example…
在許多挑戰中,多主體強化學習有一個被忽略的障礙:“學分分配”。 為了解釋這個概念,讓我們首先看一個例子……
Say we have two robots, robot A and robot B. They are trying to collaboratively push a box into a hole. In addition, they both receive a reward of 1 if they push it in and 0 otherwise. In the ideal case, the two robots would both push the box towards the hole at the same time, maximizing the speed and efficiency of the task.
假設我們有兩個機器人,即機器人A和機器人B。他們正在嘗試將盒子推入一個洞中。 此外,如果他們都將其推入,他們都將獲得1的獎勵,否則將獲得0。 在理想情況下,兩個機器人都將盒子同時推向Kong,從而最大程度地提高了任務的速度和效率。
However, suppose that robot A does all the heavy lifting, meaning robot A pushes the box into the hole while robot B stands idly on the sidelines. Even though robot B simply loitered around, both robot A and robot B would receive a reward of 1. In other words, the same behavior is encouraged later on even though robot B executed a suboptimal policy. This is when the issue of “credit assignment” comes in. In multi-agent systems, we need to find a way to give “credit” or reward to agents who contribute to the overall goal, not to those who let others do the work.
但是,假設機器人A完成了所有繁重的工作,這意味著機器人A將箱子推入Kong中,而機器人B空著站在邊線上。 即使機器人B只是閑逛, 機器人A 和 機器人B都將獲得1的獎勵。換句話說, 即使機器人B執行了次優策略,以后也會鼓勵相同的行為。 這就是“信用分配”問題出現的時候。在多主體系統中,我們需要找到一種方法,向為總體目標做出貢獻的代理人而不是讓他人完成工作的代理人給予“信用”或獎勵。 。
Okay so what’s the solution? Maybe we only give rewards to agents who contribute to the task itself.
好的,那有什么解決方案? 也許我們只獎勵那些為任務本身做出貢獻的特工。
比看起來難 (It’s Harder than It Seems)
It seems like this easy solution may just work, but we have to keep several things in mind.
似乎這個簡單的解決方案可能會奏效,但我們必須牢記幾件事。
First, state representation in reinforcement learning might not be expressive enough to properly tailor rewards like this. In other words, we can’t always easily quantify whether an agent contributed to a given task and dole out rewards accordingly.
首先,強化學習中的狀態表示可能不足以適當地調整這樣的獎勵。 換句話說,我們不能總是輕松地量化代理商是否為給定任務做出貢獻并相應地發放獎勵。
Secondly, we don’t want to handcraft these rewards, because it defeats the purpose of designing multi-agent algorithms. There’s a fine line between telling agents how to collaborate and encouraging them to learn how to do so.
其次,我們不想手工獲得這些獎勵,因為它違背了設計多主體算法的目的。 在告訴代理人如何合作與鼓勵他們學習如何做之間有一條很好的界限。
一個答案 (One Answer)
Counterfactual policy gradients address this issue of credit assignment without explicitly giving away the answer to its agents.
反事實的政策梯度解決了這一信用分配問題,而沒有向其代理商明確給出答案。
The main idea behind the approach? Let’s train agent policies by comparing its actions to other actions it could’ve taken. In other words, an agent will ask itself:
該方法背后的主要思想是什么? 讓我們通過將代理的操作與它可能采取的其他操作進行比較來訓練代理策略。 換句話說,座席會問自己:
“ Would we have gotten more reward if I had chosen a different action?”
“如果我選擇其他動作, 我們會得到更多的回報嗎?”
By putting this thinking process into mathematics, counterfactual multi-agent (COMA) policy gradients tackle the issue of credit assignment by quantifying how much an agent contributes to completing a task.
通過將這種思維過程納入數學,反事實多主體(COMA)策略梯度通過量化代理對完成任務的貢獻來解決信用分配問題。
組成部分 (The Components)
COMA is an actor-critic method that uses centralized learning with decentralized execution. This means we train two networks:
COMA是一種參與者批評方法,它使用集中式學習和分散式執行。 這意味著我們訓練兩個網絡:
An actor: given a state, outputs an action
演員 :給定狀態,輸出動作
A critic: given a state, estimates a value function
評論家 :給定狀態,估計價值函數
In addition, the critic is only used during training and is removed during testing. We can think of the critic as the algorithm’s “training wheels.” We use the critic to guide the actor throughout training and give it advice on how to update and learn its policies. However, we remove the critic when it’s time to execute the actor’s learned policies.
此外,注釋器僅在訓練期間使用,而在測試期間被刪除 。 我們可以將批評者視為算法的“訓練輪”。 我們使用評論家在整個培訓過程中指導演員,并為演員提供有關如何更新和學習其政策的建議。 但是,在執行演員的學習策略時,我們會刪除批評者。
For more background on actor-critic methods in general, take a look at Chris Yoon’s in-depth article here:
要獲得有關演員批評方法的更多背景知識,請在此處查看Chris Yoon的深入文章:
Let’s start by taking a look at the critic. In this algorithm, we train a network to estimate the joint Q-value across all agents. We’ll discuss the critic’s nuances and how it’s specifically designed later in this article. However, all we need to know now is that we have two copies of the critic network. One is the network we are trying to train and the other is our target network, used for training stability. The target network’s parameters are copied from the training network periodically.
讓我們先看一下評論家。 在此算法中,我們訓練網絡以估計所有代理之間的聯合Q值 。 我們將在本文后面討論評論家的細微差別以及它是如何專門設計的。 但是,我們現在需要知道的是,我們有批評者網絡的兩個副本。 一個是我們正在嘗試訓練的網絡,另一個是我們用于訓練穩定性的目標網絡。 定期從訓練網絡復制目標網絡的參數。
To train the networks, we use on-policy training. Instead of using one-step or n-step lookahead to determine our target Q-values, we use TD(lambda), which uses a mixture of n-step returns.
為了訓練網絡,我們使用了策略訓練。 我們使用TD(lambda)而不是使用單步或n步前瞻來確定目標Q值,而是使用n步返回值的混合。
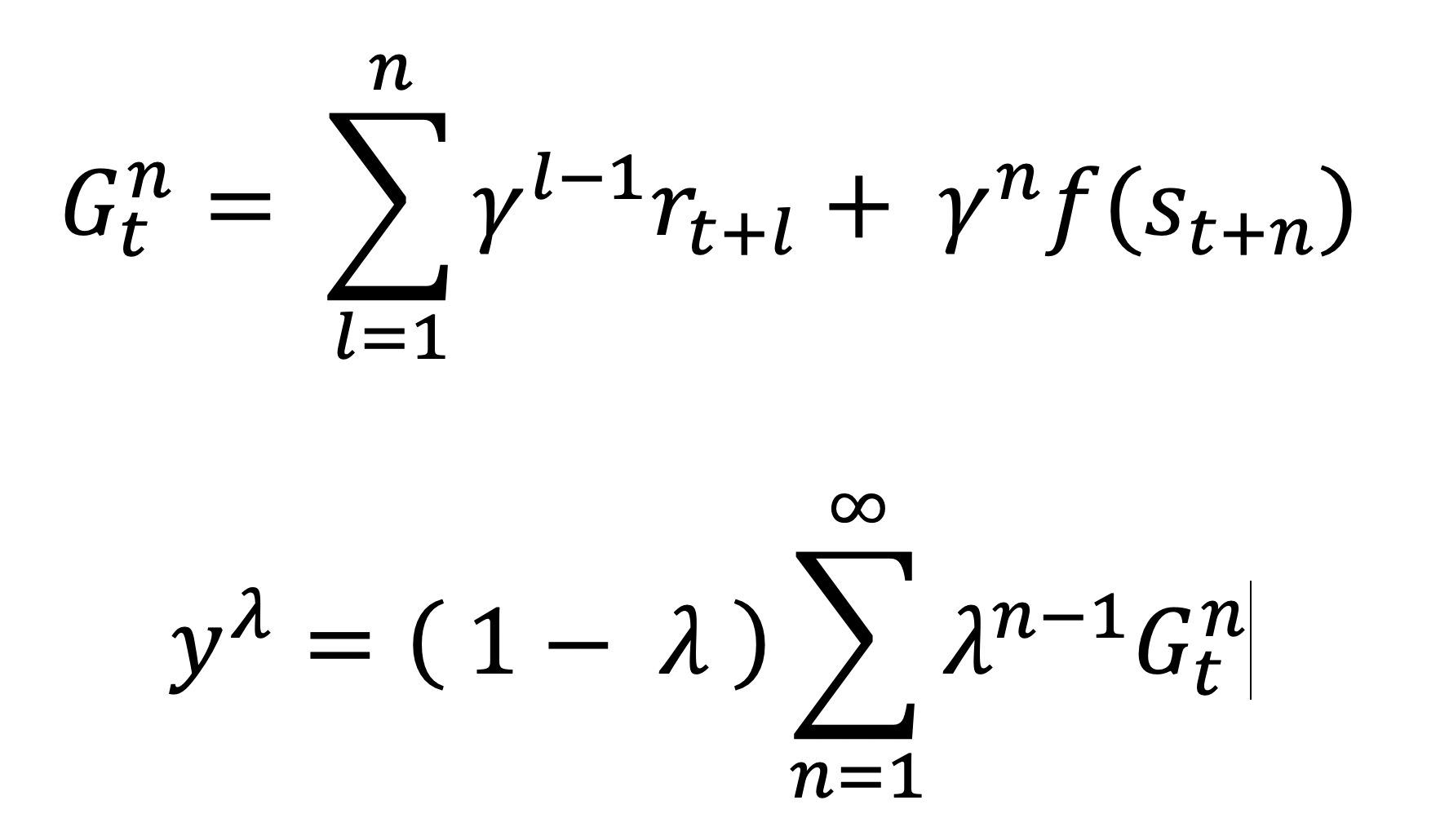
where gamma is the discount factor, r denotes a reward at a specific time step, f is our target value function, and lambda is a hyper-parameter. This seemingly infinite horizon value is calculated using bootstrapped estimates by a target network.
其中gamma是折現因子,r表示在特定時間步長的獎勵,f是我們的目標值函數,lambda是超參數。 這個看似無限的地平線值是由目標網絡使用自舉估計來計算的。
For more information on TD(lambda), Andre Violante’s article provides a fantastic explanation:
有關TD(lambda)的更多信息, Andre Violante的文章提供了一個奇妙的解釋:
Finally, we update the critic’s parameters by minimizing this function:
最后,我們通過最小化此函數來更新評論者的參數:

趕上 (The Catch)
Now, you may be wondering: this is nothing new! What makes this algorithm special? The beauty behind this algorithm comes with how we update the actor networks’ parameters.
現在,您可能想知道:這不是什么新鮮事! 是什么使該算法與眾不同? 該算法背后的美在于我們如何更新角色網絡的參數。
In COMA, we train a probabilistic policy, meaning each action in a given state is chosen with a specific probability that is changed throughout training. In typical actor-critic scenarios, we update the policy by using a policy gradient, typically using the value function as a baseline to create advantage actor-critic:
在COMA中,我們訓練概率策略,這意味著在給定狀態下的每個動作都以特定概率選擇,該概率在整個訓練過程中都會改變。 在典型的參與者批評者場景中,我們通過使用策略梯度來更新策略,通常使用價值函數作為基準來創建優勢參與者批評者:
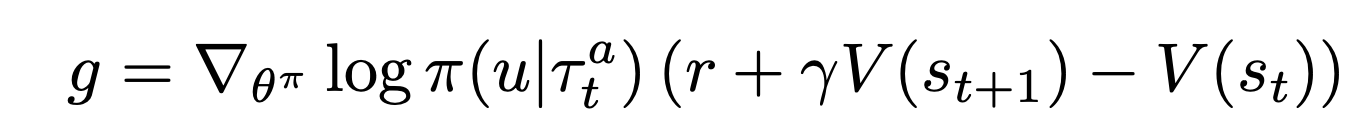
However, there’s a problem here. This fails to address the original issue we were trying to solve: “credit assignment.” We have no notion of “how much any one agent contributes to the task.” Instead, all agents are being given the same amount of “credit,” considering our value function estimates joint value functions. As a result, COMA proposes using a different term as our baseline.
但是,這里有一個問題。 這無法解決我們試圖解決的原始問題:“信用分配”。 我們沒有“任何一個特工為這項任務做出多少貢獻”的概念。 取而代之的是,考慮到我們的價值函數估算聯合價值函數 ,所有代理商都會獲得相同數量的“信用”。 因此,COMA建議使用其他術語作為我們的基準。
To calculate this counterfactual baseline for each agent, we calculate an expected value over all actions that agent can take while keeping the actions of all other agents fixed.
為了計算每個業務代表的反事實基準 , 我們在保持所有其他業務代表的動作不變的情況下 , 計算了該業務代表可以采取的所有行動的期望值。

Let’s take a step back here and dissect this equation. The first term is just the Q-value associated with the joint state and joint action (all agents). The second term is an expected value. Looking at each individual term in that summation, there are two values being multiplied together. The first is the probability this agent would’ve chosen a specific action. The second is the Q-value of taking that action while all other agents kept their actions fixed.
讓我們退后一步,剖析這個方程。 第一項只是與關節狀態和關節動作(所有主體)相關的Q值。 第二項是期望值。 看一下該求和中的每個單獨的項,有兩個值相乘在一起。 首先是該特工選擇特定動作的可能性。 第二個是在所有其他代理保持其動作固定的同時執行該動作的Q值。
Now, why does this work? Intuitively, by using this baseline, the agent knows how much reward this action contributes relative to all other actions it could’ve taken. In doing so, it can better distinguish which actions will better contribute to the overall reward across all agents.
現在,為什么這樣做呢? 憑直覺,通過使用此基準,代理可以知道此操作相對于它可能已經執行的所有其他操作有多少獎勵。 這樣,它可以更好地區分哪些行為將更好地為所有代理提供總體獎勵。
COMA proposes using a specific network architecture helps make computing the baseline more efficient [1]. Furthermore, the algorithm can be extended to continuous action spaces by estimating the expected value using Monte Carlo Samples.
COMA提出使用特定的網絡體系結構有助于使基準線的計算效率更高[1]。 此外,通過使用蒙特卡洛樣本估計期望值,可以將該算法擴展到連續動作空間。
結果 (Results)
COMA was tested on StarCraft unit micromanagement, pitted against various central and independent actor critic variations, estimating both Q-values and value functions. It was shown that the approach outperformed others significantly. For official reported results and analysis, check out the original paper [1].
COMA已在StarCraft單位的微觀管理上進行了測試,與各種中央和獨立演員評論家的變化進行了對比,從而估算了Q值和值函數。 結果表明,該方法明顯優于其他方法。 有關官方報告的結果和分析,請查看原始論文[1]。
結論 (Conclusion)
Nobody likes slackers. Neither do robots.
沒有人喜歡懶人。 機器人也沒有。
Properly allowing agents to recognize their personal contribution to a task and optimizing their policies to best use this information is an essential part of making robots collaborate. In the future, better decentralized approaches may be explored, effectively lowering the learning space exponentially. However, this is easier said than done, as with all problems of these sorts. But of course, this is a strong milestone to letting multi-agents function at a far higher, more complex level.
適當地允許代理識別他們對任務的個人貢獻并優化其策略以最佳地利用此信息,這是使機器人進行協作的重要組成部分。 將來,可能會探索更好的分散方法,從而有效地減少學習空間。 但是,對于所有這些問題,說起來容易做起來難。 但是,當然,這是使多代理在更高,更復雜的級別上起作用的重要里程碑。
翻譯自: https://towardsdatascience.com/counterfactual-policy-gradients-explained-40ac91cef6ae
梯度反傳
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390789.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390789.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390789.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

三款功能強大代碼比較工具Beyond compare、DiffMerge、WinMerge

shell腳本_Shell腳本

大數據與Hadoop


facebook.com_如何降低電子商務的Facebook CPM

Python中的If,Elif和Else語句

Hadoop安裝及配置

漏洞發布平臺-安百科技

Android 微信分享圖片

蒙蒂霍爾問題_常見的邏輯難題–騎士和刀,蒙蒂·霍爾和就餐哲學家的問題解釋...

西格爾零點猜想_我從埃里克·西格爾學到的東西

C/C++實現刪除字符串的首尾空格

assign復制對象_JavaScript標準對象:assign,values,hasOwnProperty和getOwnPropertyNames方法介紹...


深度學習算法和機器學習算法_啊哈! 4種流行的機器學習算法的片刻
)
Python第一次周考(0402)

express 路由中間件_Express通過示例進行解釋-安裝,路由,中間件等

ASP.NET 頁面之間傳值的幾種方式

Mapreduce原理和YARN
