Hadoop的三種運行模式
- 單機模式(Standalone,獨立或本地模式):安裝簡單,運行時只啟動單個進程,僅調試用途;
- 偽分布模式(Pseudo-Distributed):在單節點上同時啟動namenode、datanode、secondarynamenode、resourcemanager 、nodemanager等5個進程,模擬分布式運行的各個節點 ;
- 完全分布式模式(Fully-Distributed) :正常的Hadoop集群,由多個各司其職的節點構成
Hadoop安裝步驟
- 配置主機名、網絡、編輯hosts文件,重啟;
- 配置免密碼登陸,連接其他機器;
- Hadoop安裝(下載解壓到預定目錄下)
tar -xzvf hadoop-2.7.7.tar.gz -C 目標文件夾/hadoop- 2.7.2/ - 編輯文件(Hadoop解壓目錄下etc/hadoop/文件夾)
- 編輯該目錄下hadoop-env.sh、yarn-env.sh文件 ;
- 編輯該目錄下core-site.xml、hdfs-site.xml和mapred- site.xml、yarn-site.xml四個核心配置文件 ;
- 編輯masters、slaves(或者workers)文件;
- 復制hadoop文件夾到其他節點;
- 格式化HDFS ;
- 啟動Hadoop
預備步驟-集群時鐘同步
- 自動定時同步(設置系統定時任務)
1. crontab -e (vi操作,i插入,ESC,:wq)
2. 0 1 * * * /usr/sbin/ntpdate cn.pool.ntp.org
- 手動同步
/usr/sbin/ntpdate cn.pool.ntp.or
Step0:安裝jdk
-
上傳jdk-7u71-linux-x64(壓縮文件)到/usr/java;
不建議使用高版本JDK,查看Hadoop兼容的JDK版本; -
解壓文件(root用戶操作);
cd /usr/javatar –xzvf /usr/java/jdk-7u71-linux-x64.gz
- 修改個人用戶配置文件,vim ~/.bash_profile,在文件尾部添加(i進入編輯)
export JAVA_HOME=/usr/java/jdk1.7.0_71export PATH= $JAVA_HOME/bin: $ PATH
- 保存退出(ESC 退出編輯,:wq 存盤退出)
- 使(用戶)配置生效,source ~/.bash_profile
- 測試,java –version
Step1:網絡設置
- 橋接模式:VMnet0
- 主機模式:VMnet1
- NAT模式:VMnet8
- 關閉防火墻 (root用戶)
chkconfig iptables off (6.x指令)
systemctl disable firewalld (7.x指令)
-
修改/etc/sysconfig/network-scripts/相應的網絡配置
-
修改機器名(root用戶)
#hostnamectl set-hostname <機器名> (7.x指令)
#hostname <機器名> (6.x指令)
#vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop0 #主機名
保存退出,重啟終端,測試hostname
- 修改/etc/hosts (root用戶)
5.重啟網絡服務
systemctl restart network.service
service network restart (6.x)
Step2:ssh免密碼登錄
Hadoop運行過程中需要管理遠端Hadoop守護進
程,啟動后,NameNode是通過SSH(Secure
Shell)來無密碼登錄啟動和停止各個DataNode上
的各種守護進程的。同理,DataNode上也能使用
SSH無密碼登錄到NameNode。
- 一般情況下,只需要從master單向SSH到slave
- 在各機器上執行(在免密碼登陸的用戶下)ssh-keygen -b 1024 -t rsa 一路回車
- 在~/.ssh/下生成文件 id_rsa 、id_rsa.pub
- 生成密碼后輸入命令 ssh-copy-id hadoop
Step3:Hadoop安裝
- 上傳hadoop文件到節點/home/zkpk/hadoop目錄
- 解壓文件
– cd /home/zkpk/ – tar -zxvf hadoop-2.7.7.tar.gz
- 修改(Linux下)/etc/profile—(系統級環境設置,可選)
– vi /etc/profile #在文件最后添加以下語句
– export JAVA_HOME=/usr/java – export HADOOP_HOME=/home/zkpk/hadoop
– export PATH=$JAVA_HOME/bin:$PATH::$HADOOP_HOME/bin – 保存退出
– source /etc/profile //切記修改后,使之立即生效
– 如果指定了用戶級的環境變量(.bash_profile),可不編輯;
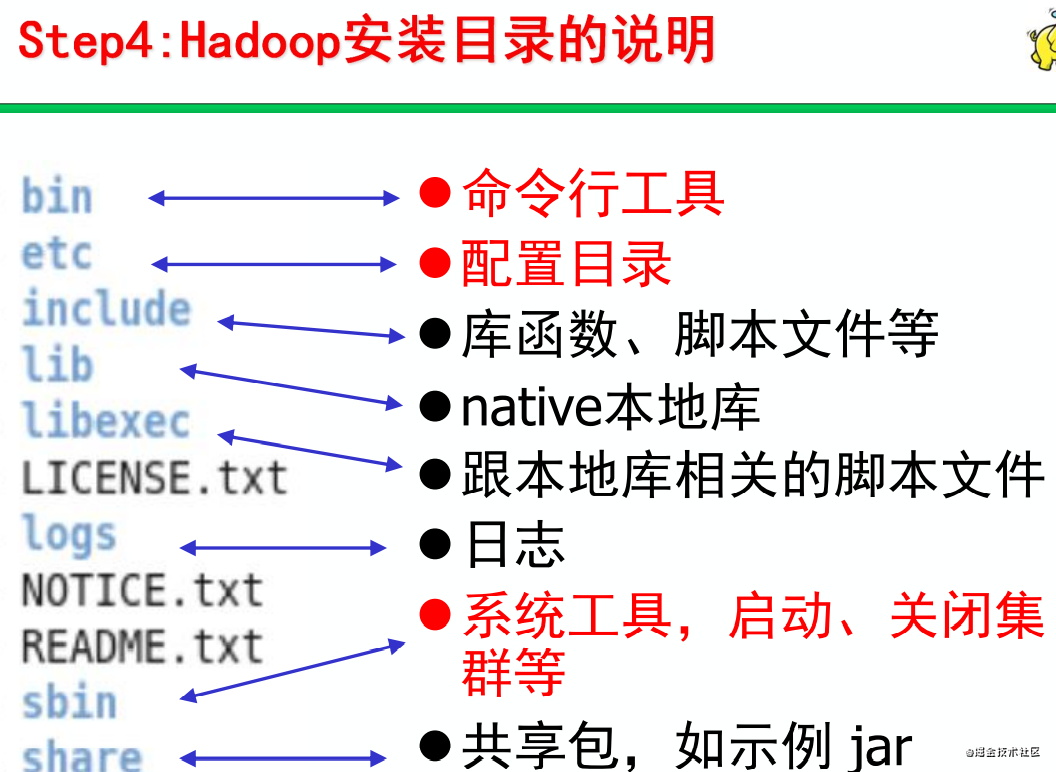
Step4:修改配置文件
hadoop安裝目錄下的配置文件路徑,即$HADOOP_HOME/etc/hadoop
- 修改hadoop-env.sh、yarn-env.sh
- export JAVA_HOME=/usr/java/jdk1.7.0_71/
- 保存退出
- 配置core-site.xml,增加以下內容
- master機器名的9000端口
- 集群數據目錄
– <property>
– <name>fs.default.name</name>
– <value>hdfs://hadoop0:9000</value>
– </property>
– <property>
– <name>hadoop.tmp.dir</name>
– <value>/home/zkpk/hadoopdata</value>
– </property>
- 配置hdfs-site.xml
- 保存副本數量
– <property>
– <name>dfs.replication</name>
– <value>2</value>
– </property>
- 配置mapred-site.xml
- 使用YARN進行資源調度和任務管理
– <property>
– <name> mapreduce.framework.name </name>
– <value>yarn</value>
– </property>
- 配置yarn-site.xml
– <property>
– <name>yarn.resourcemanager.hostname</name>
– <value>hadoop0</value>
– </property>
– <property>
– <name> yarn.nodemanager.aux-services</name>
– <value>mapreduce_shuffle</value>
– </propert>
Step5:編輯masters、slaves(或者workers)文件
- 配置masters
- 管理NN機器名稱
Hadoop0
- 配置slaves(workers),可以包含master
- 數據節點DN的機器名稱
hadoop1
hadoop2
hadoop3
- 說明:一行一個主機名
Step6:復制hadoop文件夾到其他節點
- 把hadoop0的hadoop目錄、jdk目錄、/etc/hosts、/etc/profile復制到hadoop1,hadoop2、hadoop3節點
- 復制master機器的hadoop安裝目錄到slave機器的用戶目錄(slave的 /home/zkpk/hadoop-2.7.7)
#cd $HADOOP_HOME/..
scp -r hadoop-2.7.7 hadoop1:~/
scp -r hadoop-2.7.7 hadoop2:~/
scp -r hadoop-2.7.7 hadoop3:
Step7:格式化HDFS
第一次啟動Hadoop前,必須先格式化namenode
cd $HADOOP_HOME /bin
hdfs namenode –format
Step8:啟動Hadoop
cd $HADOOP_HOME/sbin
./start-all.sh //啟動所有
# 可分兩步啟動: start-dfs.sh 、start-yarn.sh
# 第一步啟動文件系統,start-dfs.sh
# 出錯時,查看logs,檢查相關配置文件:hdfs-site.xml,core-site.xml
# 第二步啟動yarn計算框架,start-yarn.sh
# 出錯時,查看logs,檢查相關配置文件:yarn-site.xml,mapred-site.xml
停止Hadoop
~/hadoop-2.5.2/sbin/stop-all.sh
或者分兩步停止hadoop集群
可分兩步停止: start-yarn.sh、start-dfs.sh
# 第一步停止yarn, stop-yarn.sh
# 第二步停止文件系統,stop-dfs.sh








)




)





