HDFS定義
Hadoop Distributed File System,是一個使用 Java 實現的、分布式的、可橫向擴展的文件系
統,是 HADOOP 的核心組件
HDFS特點
- 處理超大文件
- 流式地訪問數據
- 運行于廉價的商用機器集群上;
HDFS 不適合以下場合: - 低延遲數據訪問
- 大量小文件的存儲
- 不支持多用戶寫入及任意修改文件
HDFS基本結構
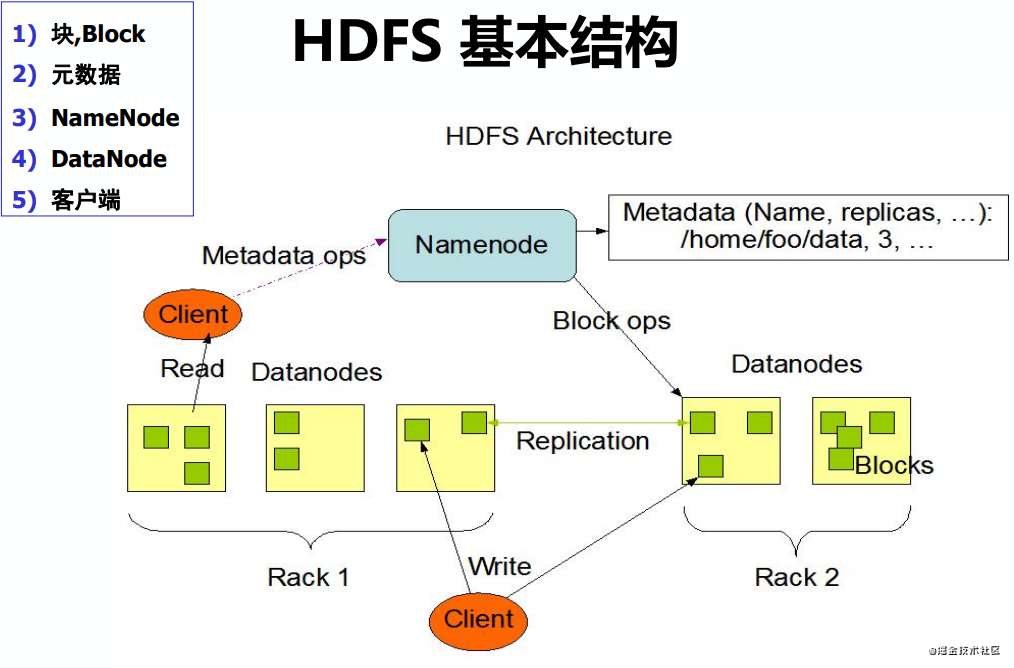
HDFS相關概念 --塊
- HDFS使用了塊的概念,默認大小128M/256M字節
- 可針對每個文件配置,由客戶端指定
- 每個塊有一個自己的全局ID
- HDFS將一個文件分為一個或數個塊來存儲
- 每個塊是一個獨立的存儲單位
- 以塊為單位在集群服務器上分配存儲
- 與傳統文件系統不同的是,如果實際數據沒有達到塊大小,則并不實際占用整個塊磁盤空間
- 如果一個文件是200M,則它會被分為2個塊: 128+72
HDFS相關概念 --元數據
- 元數據 (MetaData)包括
文件系統目錄樹信息
- 文件名,目錄名
- 文件和目錄的從屬關系
- 文件和目錄的大小,創建及最后訪問時間
- 權限
文件和塊的對應關系
- 文件由哪些塊組成
塊的存放位置
- 機器名,塊ID
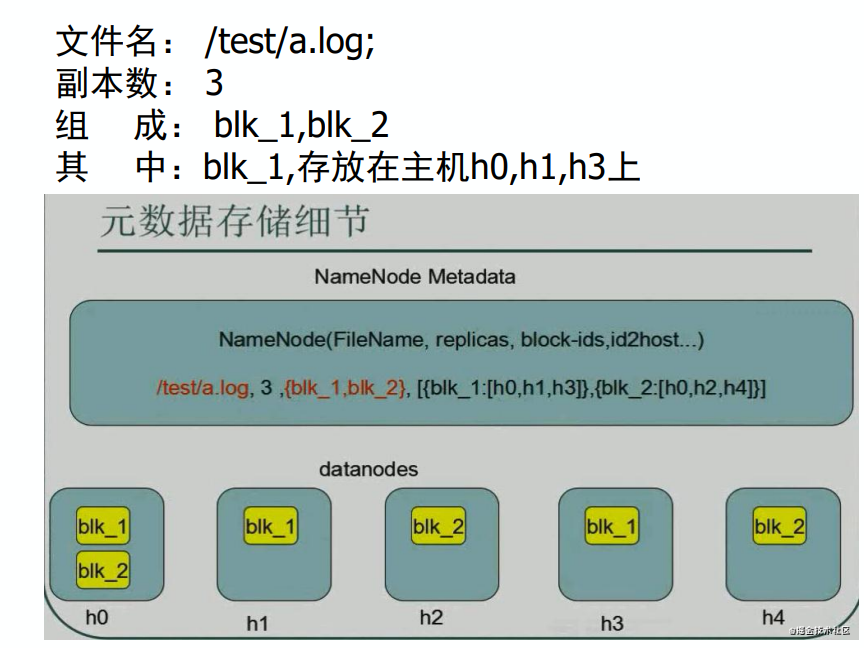
- HDFS對元數據和實際數據采取分別存儲的方法
- 元數據存儲在NameNode服務器上;
- 實際數據儲存在集群的DataNode中
HDFS相關概念 --NameNode
NameNode是用來管理文件系統命名空間的組件。一個HDFS集群只有一臺(active)NameNode
- NameNode上存放了HDFS的元數據,記錄了每個文件中各個塊所在的數據節點的位置信息。一個HDFS集群只有一份元數據,可能有單點故障問題
- 元數據工作時在NameNode內存中,以便快速查詢。1G內存大致可存放1,000,000塊對應的元數據信息。按缺省每塊64M計算,大致對應64T實際數據
- 集群關閉時,元數據持久化到磁盤中,啟動集群時,需要將元數據裝載到內存中
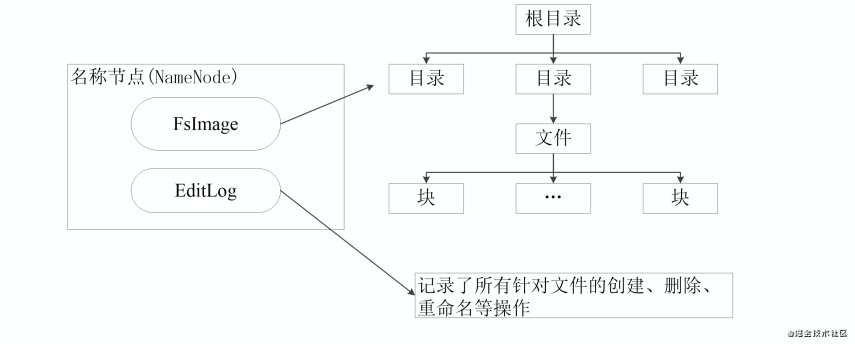
NameNode數據結構
- NameNode負責管理分布式文件系統的Namespace命名空間,保存了兩個核心數據結構:FsImage和EditLog
- FsImage用于維護文件系統樹以及文件樹中所有的文件和文件夾的元數據;
- 操作日志文件EditLog中記錄了所有針對文件的創建、刪除、重命名等操作;
NameNode 工作原理
-
在名稱節點啟動的時候,它會將FsImage文件中的內容加載到內存中,之后再執行EditLog文件中的各項操作,使得內存中的元數據和實際的同步,存在內存中的元數據支持客戶端的讀操作。
-
一旦在內存中成功建立文件系統元數據的映射,則創建一個新的FsImage文件和一個空的EditLog文件
-
在名稱節點運行期間,HDFS的所有更新操作都是直接寫到EditLog中,久而久之, EditLog文件將會變得很大。當EditLog文件非常大的時候,會導致名稱節點啟動操作非常慢,而在這段時間內HDFS系統處于安全模式,一直無法對外提供寫操作,影響了用戶的使用。
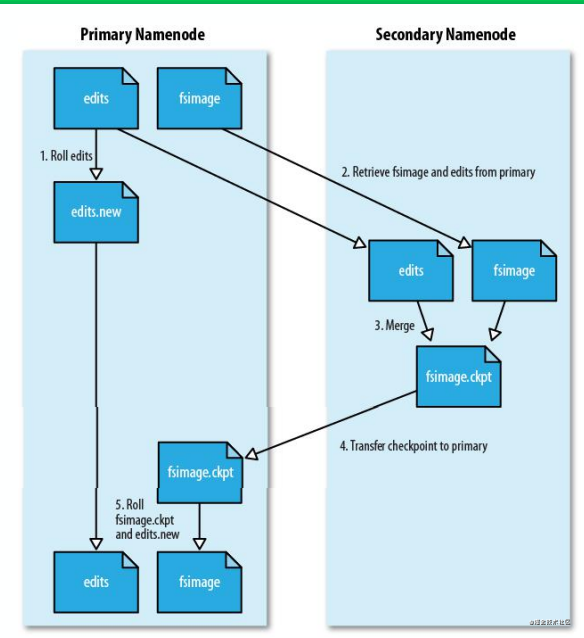
HDFS相關概念 --SecondaryNameNode
第二名稱節點是HDFS
架構中的一個組成部
分,協助NameNode完
成Fsimage和edits文件
合并工作,使得內存
中的Fsimage保持“最
新”
。
SecondaryNameNode 一般是單獨運行在一
臺機器上。
HDFS相關概念 --DataNode
- 塊的實際數據存放在DataNode上
- 每個塊會在本地文件系統產生兩個文件,一個是實際的數據文件,另一個是塊的附加信息文件,其中包括塊數據的長度、校驗和,以及時間戳
- DataNode通過心跳包(Heartbeat)與NameNode通訊
- 客戶端讀取/寫入數據的時候直接與DataNode通信
- 集群運行中可以安全加入和退出一些機器
HDFS體系結構
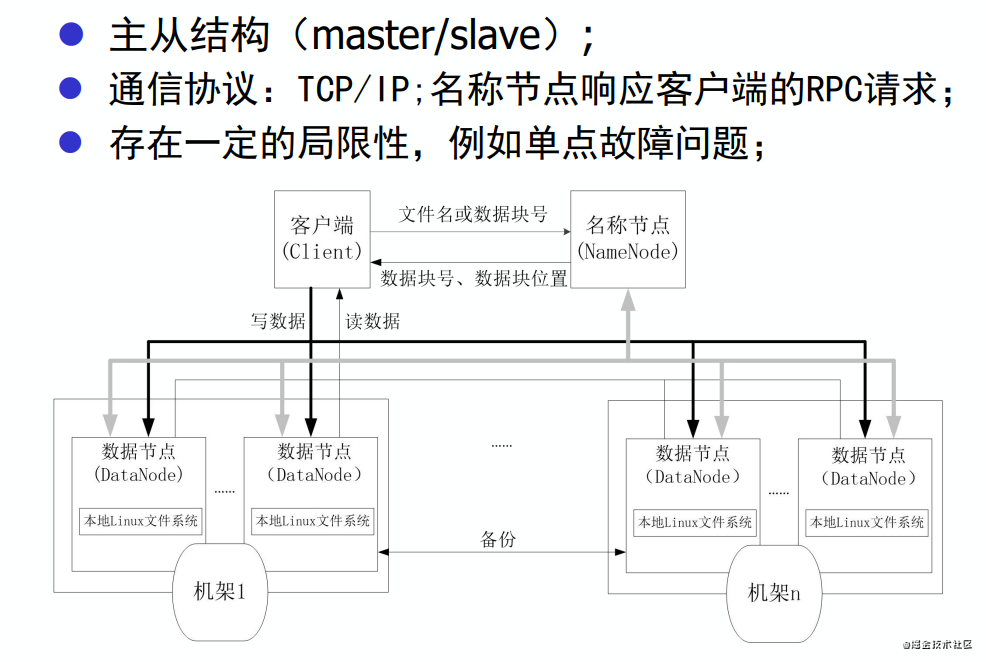
DataNode
- NameNode是一個中心服務器,單一節點,負責管理文件系統的命名空間(namespace)以及客戶端對文件的訪問;
- 文件操作,NameNode負責文件元數據的操作,DataNode負責處理文件內容的讀寫請求,數據流不經過NameNode,只會詢問它跟那個DataNode聯系;
- 副本存放在哪些DataNode上由NameNode來控制,根據全局情況做出塊放置決定,讀取文件時NameNode盡量讓用戶先讀取最近的副本,降低帶塊消耗和讀取時延
冗余存儲策略
- 每個塊在集群上會存儲多個副本(replication) –默認復制份數為3; 可以動態修改,可針對每個文件配置,由客戶端指定
- 某個塊的所有備份都是同一個ID –系統無需記錄 “哪些塊其實是同一份數據”
- 根據機架配置自動分配備份位置(Rack Awareness)
- 第一個副本:放置在上傳文件的DN;如果是集群外提交,則隨機挑選一臺磁盤不太滿,CPU不太忙的節點
- 第二個副本:放置在于第一個副本不同的機架的節點上
- 第三個副本:與第一個副本相同機架的其他節點
- 更多副本:隨機節點
- 優點:加快數據傳輸速度;容易檢查錯誤;保證數據的可靠性
錯誤恢復策略
-
名稱節點出錯
名稱節點保存了所有的元數據信息,最核心的兩大數據結構
是FsImage和Editlog。當名稱節點出錯時,就可以根據備份
SecondaryNameNode中的FsImage和Editlog數據進行恢復。 -
數據節點出錯
- 數據節點定期向名稱節點發送“心跳”信息報告狀態;
- 當數據節點發生故障,或者網絡斷網時,名稱節點就無法收到來自數據節點的心跳信息,這些數據節點就被標記為“宕機”,節點上面的所有數據都會被標記為“不可讀”,名稱節點不會再給它們發送任何I/O請求;
- 一些數據節點的不可用,會導致一些數據塊的副本數量小于冗余因子;名稱節點會定期檢查,一旦發現某個數據塊的副本數量小于冗余因子,就會啟動數據冗余復制生成新的副本;
- HDFS和其它分布式文件系統的最大區別就是可以調整冗余數據的位置。
- 數據出錯
-
網絡傳輸和磁盤錯誤等因素,都會造成數據錯誤;客戶端在讀取到數據后,會采用md5和sha1對數據塊進行校驗,以確定讀取到正確的數據;
-
在文件被創建時,客戶端就會對每一個文件塊進行信息摘錄,并把這些信息寫入到同一個路徑的隱藏文件里面
-
當客戶端讀取文件的時候,會先讀取該信息文件,然后,利用該信息文件對每個讀取的數據塊進行校驗,如果校驗出錯,客戶端就會請求到另外一個數據節點讀取該文件塊,并且向名稱節點報告這個文件塊有錯誤,名稱節點會定期檢查并且重新復制這個塊
文件權限策略
- 與Linux文件權限類似 ( chmod, chown )r: read; w:write; x:execute,權限x對于文件忽略,對于文件夾表示是否允許訪問其內容
- 如果Linux系統用戶zhangsan使用hadoop命令創建一個文件,那么這個文件在HDFS中owner是zhangsan
- HDFS的權限目的:阻止好人做錯事,而不是阻止壞人做壞事。HDFS相信,你告訴我你是誰,我就認為你是誰
安全模式
指文件系統所處的一種只讀的安全模式。HDFS啟動時會在safemode狀態
$ hadoop dfsadmin -safemode get #安全模式當前狀態信息
$ hadoop dfsadmin -safemode enter #進入安全模式
$ hadoop dfsadmin -safemode leave #解除安全模式
$ hadoop dfsadmin -safemode wait #掛起,直到安全模式結束
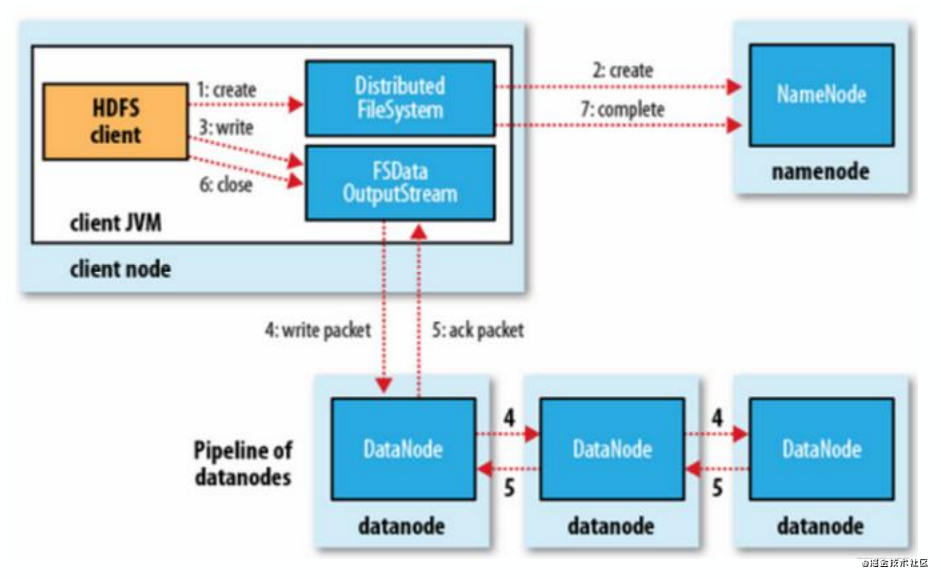
HDFS 寫操作
- 客戶端寫一個文件并不是直接寫到HDFS上;
- HDFS客戶端接收用戶數據,并把內容緩存在本地;
- 當本地緩存收集足夠一個HDFS塊大小的時候,客戶端同NameNode通訊注冊一個新的塊;
- 注冊塊成功后,NameNode給客戶端返回一個DataNode的列表; – 列表中是該塊需要存放的位置,包括冗余備份
- 客戶端向列表中的第一個DataNode寫入塊; 當完成時,第一個DataNode 向列表中的下個DataNode發送寫操作,并把數據已收到的確認信息給客戶端,同時發送確認信息給NameNode 之后的DataNode重復之上的步驟。當列表中所有DataNode都接收到數據并且由最后一個DataNode校驗數據正確性完成后,返回確認信息給客戶端
- 收到所有DN的確認信息后,客戶端刪除本地緩存;
- 客戶端繼續發送下一個塊,重復以上步驟;
- 當所有數據發送完成后,寫操作完成。
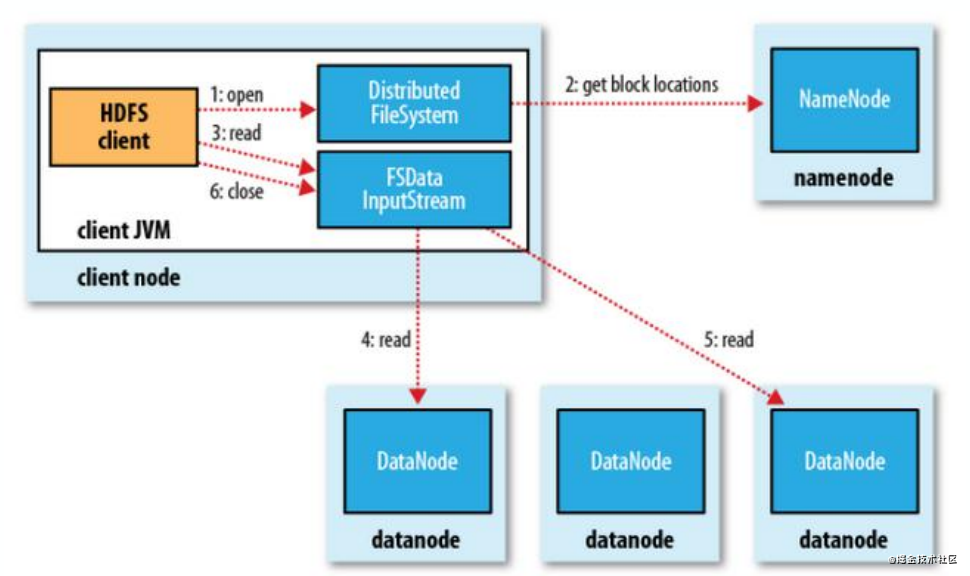
HDFS 讀操作
- 客戶端與NameNode通訊獲取文件的塊位置信息,其中包括了塊的所有冗余備份的位置信息:DataNode的列表;
- 客戶端獲取文件位置信息后直接同有文件塊的DataNode通訊,讀取文件;
- 如果第一個DataNode無法連接,客戶端將自動聯系下一個DataNode;
- 如果塊數據的校驗值出錯,則客戶端需要向NameNode報告,并自動聯系下一個DataNode。
HDFS追加寫操作
- 客戶端與NameNode通訊,獲得文件的寫保護鎖及文件最后一個塊的位置(DataNode列表)
- 客戶端挑選一個DataNode作為主寫入節點,并對其余節點上的該數據塊加鎖
- 開始寫入數據。與普通寫入流程類似,依次更新各個DataNode上的數據。更新時間戳和校驗和
- 最后一個塊寫滿,并且所有備份塊都完成寫入后,向NameNode申請下一個數據塊。
HDFS命令行
cat
- 用途:顯示一個或多個文件內容到控制臺
- 使用方法:hadoop fs -cat URI [URI …]
- 例子:
? hadoop fs -cat hdfs://host1:port1/file1
hdfs://host2:port2/file2
? hadoop fs -cat file:///file3
/user/hadoop/file4
put/copyFromLocal
- 用途:將本地一個或多個文件導入HDFS。以上兩個命令唯一的不同時copyFromLocal的源只能是本地文件,而put可以讀取stdin的數據
- 使用方法:hadoop fs -put/copyFromLocal UR
- 例子:
? hadoop fs -put localfile.txt /user/hadoop/hadoopfile.txt
? hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir
? hadoop fs -put localfile hdfs://host:port/hadoop
get/copyToLocal
- 用途:將HDFS中的一個或多個文件導出到本地文件系統
- 使用方法: hadoop fs -get/copyToLocal [-ignorecrc] [-crc] URI < localsrc>
- 例子:
? hadoop fs -get /user/hadoop/hadoopfile localfile
? hadoop fs -get hdfs://host:port/user/hadoop/file localfile
ls
- 用途:列出文件夾目錄信息,lsr 遞歸顯示文件
- 使用方法: hadoop fs -ls/lsr -h UR
ls
- 用途:檢查dfs的文件的健康狀況; 只能運行在master上
- 使用方法: hadoop fsck [GENERIC_OPTIONS]
[- move | -delete | -openforwrite] [-files [-blocks [-locations | -racks]]
啟動HDFS服務

關閉HDFS服務


)




)






)


——Clustered Indexes: Stairway to SQL Server Indexes Level 3)


