Hive定義
Hive 是一種數據倉庫技術,用于查詢和管理存儲在分布式環境下的大數據集。構建于Hadoop的HDFS和MapReduce上,用于管理和查詢分析結構化/非結構化數據的數據倉庫;
- 使用HQL(類SQL語句)作為查詢接口;
- 使用HDFS作為底層存儲;
- 使用MapReduce作為執行層,即將HQL語句轉譯成M/R Job然后在Hadoop執行
Hive的表其實就是HDFS的目錄/文件夾,按表名把文件夾分開。如果是分區表,則分區值是子文件夾;
Hive概述—元數據、數據、目錄
- 元數據保存在DB(Derby/MySQL)中,包括表的名字、表的列和分區及其屬性,表的屬性包括是否為外部表等,表的數據所在目錄等;
- 數據位于集群目錄下:
- 內部表:/user/hive/warehouse/表名;
- 外部表:用戶自定的目錄;
- 表的數據即文件(表對應文件夾下);上傳文件即相當于上傳數據到數據表中;文件可以有多個;表的分區對應子目錄;
Hive概述—Hive Shell
Hive Shell 把 HiveQL 查詢轉換為一系列 MapReduce 作業對任務進行并行處理, 然后返回處理結果。
Hive 采用 RDBMS 表 (table) 形式組織數據
, 并為存儲在 Hadoop上的數據提供附屬的對數據
進行展示的結構描述信息,該描述信息稱為元數據
(metadata)或表模式,以 metastore 形式存儲在
RDBMS 數據庫中。
Hive使用—內、外部表的區別
兩者的相同點:需要指定元數據;都支持分區
不同點:實際數據的存儲地點不同
- 內部表。實際數據存儲在數據倉庫目錄(默認集群/user/hive/warehouse 下)。刪除表時,表中的數據和元數據將會被同時刪除。
- 外部表。實際數據存儲在創建語句location指定的HDFS路徑中,不會移動到數據庫目錄中。如果刪除一個外部表,僅會刪除元數據,表中的數據不會被刪除。
Hive使用—分區Partition
在實際項目中,經常“按天分表 的模式設計數據庫!Hive分區類似數據庫中相應分區列的一個索引;Hive表中的一個分區對應表下的一個目錄,所有分區的數據都存儲在各自對應的子目錄中
例如:htable包含ds、city兩個分區,則相同日期、不同
城市的hdfs目錄分別為:
- /datawarehouse/htable/ds=20100301/city=GZ
- /datawarehouse/htable/ds=20100301/city=BJ
Hive使用—桶Bucket
桶對指定列進行哈希(hash)計算時,根據哈希值切分數據,每個桶對應一個文件。
例如:將屬性列user分散到32個桶中,哈希值為0、10的分別對應的文件為:
- /datawarehouse/htable/ds=20100301/city=GZ/part-00000
- /datawarehouse/htable/ds=20100301/city=GZ/part-00010
Hive使用—分區、分桶、索引
- 索引和分區最大的區別就是索引不分割數據表,分區分割數據表。
- 分區和分桶最大的區別就是分桶隨機分割數據表,分區是非隨機分割數據表。
Hive使用—Hive 表 DDL 操作
- Create/Drop/Alter 數據庫
- Create/Drop/Truncate 表
- Alter 表/分區/列
- Create/Drop/Alter 視圖
- Create/Drop/Alter 索引
- Create/Drop 函數
- Create/Drop/Grant/Revoke 角色和權限
Hive使用—Hive 表 DML 操作
- 將文件中的數據Load到 Hive 表中
- select 操作
- 將 select 查詢結果插入 hive 表中
- 將 select 查詢結果寫入文件
- Hive 表 ACID 事務特性
Hive使用—Hive數據類型
基本數據類型:
- tinyint/smallint/int/bigint 整數類型
- float/double 浮點類型
- boolean 布爾類型
- string/varchar/char 字符串類型
復雜數據類型: - array:數組類型,由一系列相同的數據類型的元素組成
- map:集合類型,包含key->value鍵值對,可通過key訪問元素。
- struct:結構類型,可以包含不同數據類型的元素,這些元素可以通過“點語法”的方式來得到所需要的元素。
時間類型: - Date: 日期(年月日)
- Timestamp: 是unix的一個時間偏移量
- select unix_timestamp(); 查看系統的時間偏移
Hive使用—Hive表操作語法
創建表
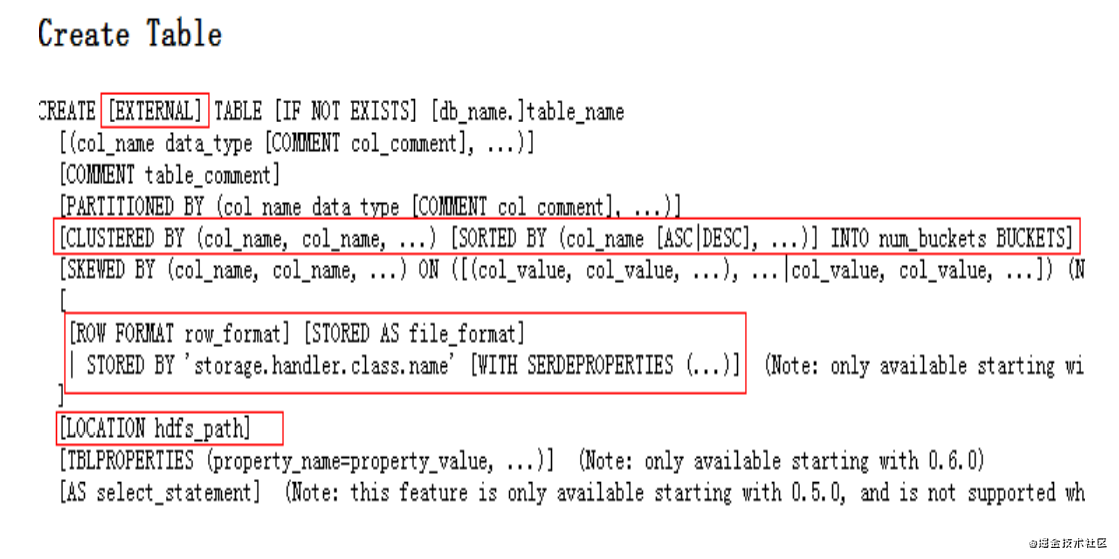
- external 外部表,類似于mysql的csv引擎
- partitioned by 指定分區字段
- clustered by sorted by 可以對表和分區對某個列進行分桶操作,也可以利用sorted by對某個字段進行排序
- row format delimited fields terminated by ‘\t’ 指定數據行中字段間的分隔符和數據行分隔符
- stored as 指定數據文件格式:textfile sequence rcfile inputformat (自定義的inputformat 類)
- location 指定數據文件存放的hdfs目錄
內部表建表指令(示例)
CREATE TABLE pokes (foo INT, bar STRING) row format delimited fields terminated by ‘\t’;
外部表建表指令(示例)
CREATE external TABLE ext_pokes (foo INT, bar STRING) row format delimited fields terminated by ‘\t’ location ‘/data/extpokes’
刪除表
- drop table [IF EXISTS] table_name
- 刪除內部表時會刪除元數據和表數據文件
- 刪除外部表(external)時只刪除元數據
修改表


Hive使用—HiveQL加載數據
加載文件數據:(local 本地、hdfs)文件數據到指定的表分區
LOAD DATA LOCAL INPATH '/user/myname/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15');
從指定表中選取數據插入到其他表中
FROM src
INSERT OVERWRITE TABLE dest1 SELECT src.*
WHERE src.key < 100
INSERT OVERWRITE TABLE dest2 SELECT src.key,
src.value WHERE src.key >= 100 and src.key < 200
Hive使用—HiveQL Select語句

Hive使用—分區表

Hive使用—桶的使用




















)