自定義Mapper類
class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>
{ … }
- 自定義mapper類都必須實現Mapper類,有4個類型參數,分別是:
- Object:Input Key Type-------------K1
- Text: Input Value Type-----------V1
- Text: Output Key Type-----------K2
- IntWritable: Output Value Type—V2
- 自定義mapper類須繼承Mapper類,重寫map方法;

- 執行一次map函數,即處理一行數據;
自定義Reducer類
class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable>
{ … }
- 自定義Reducer類都必須實現Reducer類,有4個類型參數,分別是:
- Text: Input Key Type-------------K2
- IntWritable: Input Value Type-----------V2
- Text: Output Key Type-----------K3
- IntWritable: Output ---------V3
- 自定義Reducer類須繼承Reducer類,重寫Reduce方法

- 執行一次Reduce函數,即處理一個Key的數據(values);
Hadoop的序列化格式
- 序列化(Serialization)是指把結構化對象轉化為字節流。
- 反序列化(Deserialization)是序列化的逆過程。即把字節流轉回結構化對象。
- Java序列化(java.io.Serializable)
Hadoop序列化格式特點:
- 緊湊:高效使用存儲空間。
- 快速:讀寫數據的額外開銷小
- 可擴展:可透明地讀取老格式的數據
- 互操作:支持多語言的交互
Hadoop序列化的作用
- 序列化在分布式環境的作用:進程間通信,永久存儲。
- Hadoop節點間通信
Writable接口
Writable接口是根據 DataInput 和 DataOutput 實現的簡單、有效的序列化對象。
- MR的任意Key和Value必須實現Writable接口
- MR的任意key必須實現WritableComparable接口。

Hadoop序列化類型,與java基本類型的轉換操作:get,set
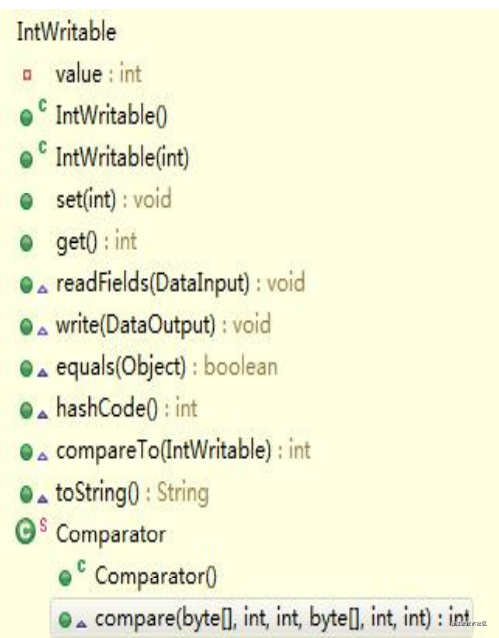
自定義類型

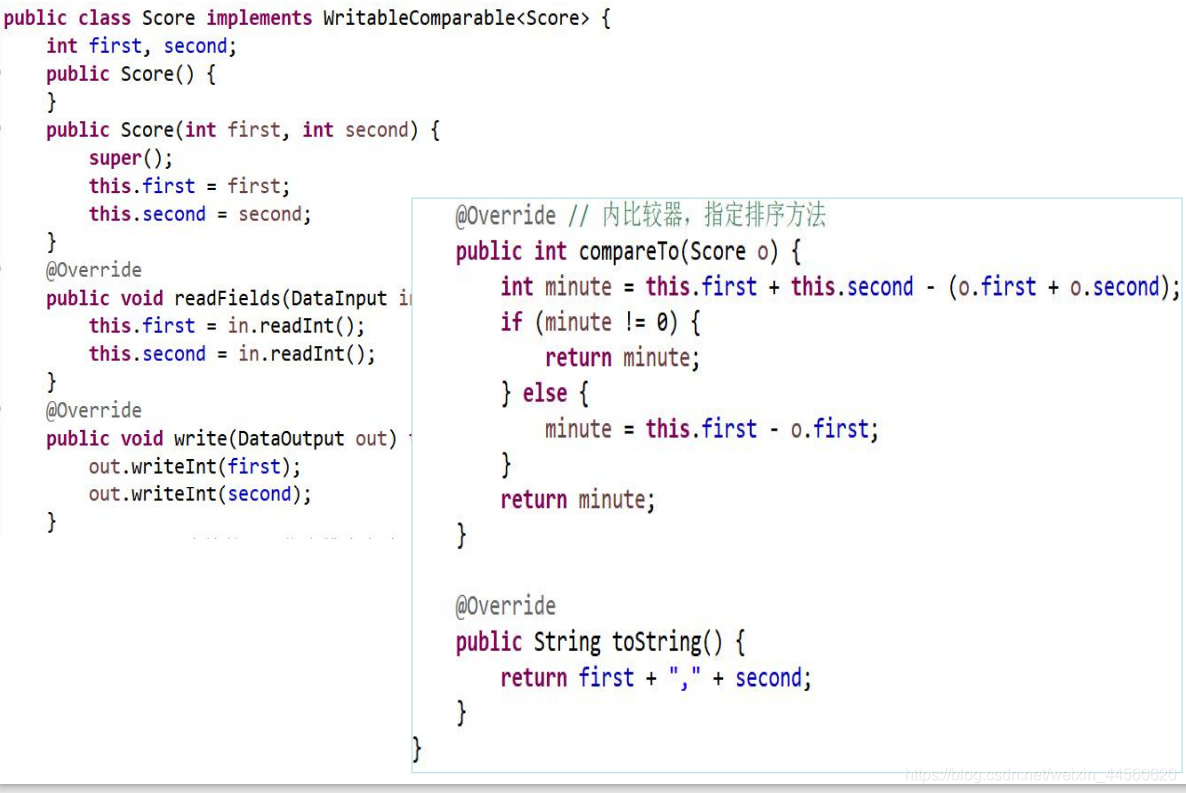
Context
它是mapper的一個內部類,簡單的說是為了在map或是
reduce任務中跟蹤App的狀態,很自然的MapContext就是記
錄了map執行的上下文,在mapper類中,這個context可以存
儲一些job conf的信息,如運行時參數、輸入文件分片信息
等
InputFormat
? TextInputFormat,默認的格式,每一行是一個單
獨的記錄,并且作為value,文件的偏移值作為key
? KeyValueInputFormat,這個格式每一行也是一個
單獨的記錄,但是Key和Value用Tab隔開,是默認
的OutputFormat,可以作為中間結果,作為下一
步MapReduce的輸入。
? SequenceFileInputFormat
- 基于塊進行壓縮的格式
- 對于幾種類型數據的序列化和反序列化操作
- 用來將數據快速讀取到Mapper類中
Partitioner類
在Map工作完成之后,每一個 Map函數會將結果
“傳到” 對應的Reducer所在的節點,此時,用戶可以提供一個Partitioner類,用
來決定一個給定的(key,value)對傳輸的具體位置;
Combiner類
Map端會產生大量的輸出,Combiner作用就是在
map端對輸出先做一次合并,以減少傳輸到
Reducer的數據量;
Output Format
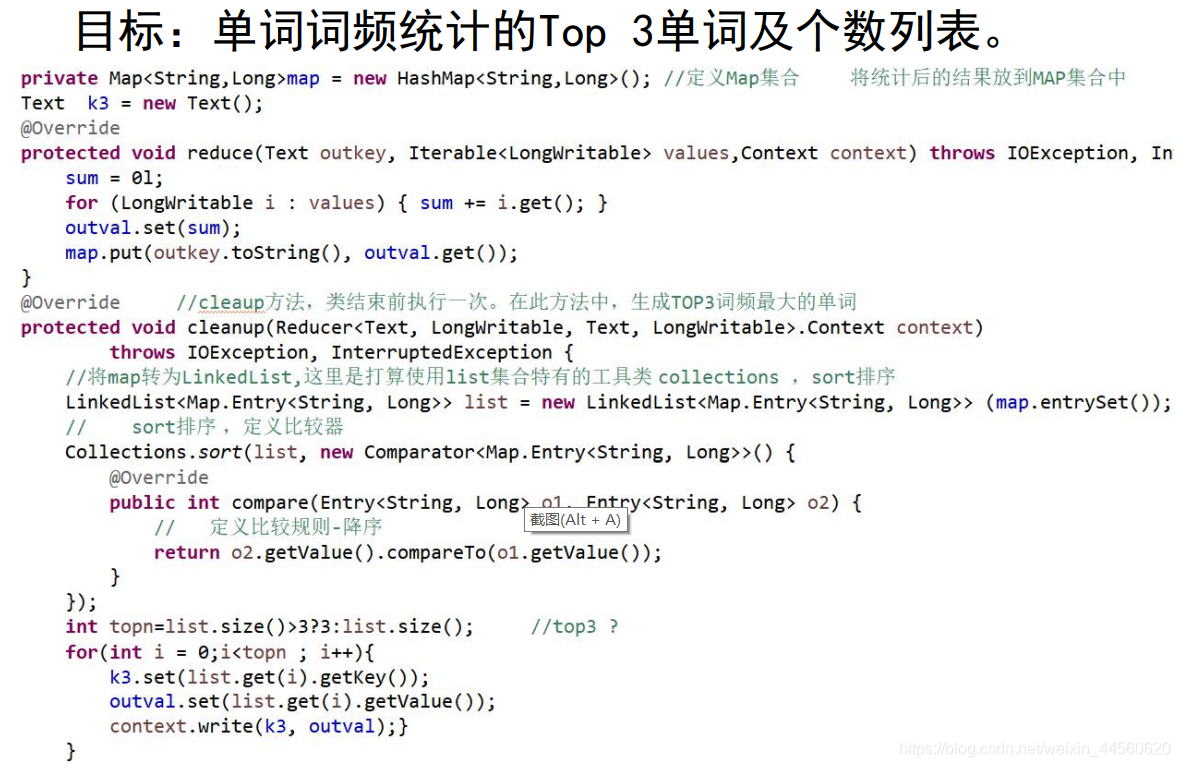
Maper、Reducer類的setup、cleaup方法
在run方法中調用了三個方法:setup方法,
map方法,cleanup方法。其中setup方法和
cleanup方法默認是不做任何操作,且它們
只被執行一次。但是setup方法一般會在map
函數之前執行一些準備工作,如作業的一些
配置信息等;cleanup方法則是在map方法運
行完之后最后執行的,該方法是完成一些結
尾清理的工作,如:資源釋放等




)


——Clustered Indexes: Stairway to SQL Server Indexes Level 3)











