幫助學生改善學習方法
There have been numerous studies looking into the relationship between sleep, exercise, leisure, studying and happiness. The results were often quite like how we expected, though there have been debates about the relationship between sleep and happiness. However, I was wondering if we could put it in the perspective of how we spend our time in general and seeing whether a balance of time spent in different aspects of our lives would influence our happiness levels.
有許多研究探討睡眠,運動,休閑,學習和幸福之間的關系。 盡管對于睡眠與幸福之間的關系一直存在爭論,但結果通常與我們的預期非常相似。 但是,我想知道我們是否可以從總體上如何度過時光的角度來看待,看看在生活的各個方面度過的時間平衡是否會影響我們的幸福感。
Rather than chasing after more sleep, or more exercise, how should we be spending our time across the board to increase our happiness?
與其追逐更多的睡眠或更多的運動,不如我們應該花很多時間來增加幸福感?
As a university student in Singapore, I decided to do a simple survey of my peers.
作為新加坡的一名大學生,我決定對同齡人進行簡單調查。
資料說明: (Data description:)
Number of responses=45
回應數 = 45
Variables, keeping in mind that I am asking university students: — year of studies — gender — level of comfort around people (account for possible personality differences) — satisfaction (a good measure for happiness as it tends to be stable) — sleep hours (per day) — study hours (per day) — exercise hours (per week) — leisure hours (per week)
變量 ,請記住,我要問的是大學生:-學習年限-性別-人們周圍的舒適度(考慮可能的人格差異)-滿意度(幸福感的一種穩定的衡量標準,因為它趨于穩定)-睡眠時間每天)-學習時間(每天)-運動時間(每周)-閑暇時間(每周)
Next, I’ll be using Python through Jupyter Notebook to do some data cleaning. Starting with importing of the necessary packages and looking at the data.
接下來,我將通過Jupyter Notebook使用Python進行一些數據清理。 從導入必要的程序包開始,然后查看數據。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
import numpy as np
import math#loading the data
data=pd.read_csv("Happiness and how we spend our time (Responses) - Form Responses 1.csv")
data.head()
數據清理: (Data cleaning:)
1) Renaming the column header for simplicity
1)重命名列標題以簡化操作
data.columns=['Year','Gender','Being around others','Happiness score','Sleep','Study','Exercise','Leisure']2) Converting from categorical to numerical by:
2)通過以下方式從分類轉換為數值:
- taking the mean of the range of values, with a constant interval between each option (Note: get respondents to enter integers instead next time). 取值范圍的平均值,每個選項之間的間隔是固定的(注意:下次讓受訪者輸入整數)。
- replacing ‘Male’ and ‘Female’ with 1 and 0 and ‘year 1’ to ‘year 5’ to just ‘1’ to ‘5’. 用1和0替換“男”和“女”,將“ 1年”到“ 5年”替換為“ 1”到“ 5”。
data=data.replace({'Year 5':5, 'Year 4':4,'Year 3':3,'Year 2':2,'Year 1':1,'Male':0,'Female':1,'0 to 1 hour':0.5,'0 to 2 hours':1,'1 to 2 hours':1.5,'3 to 4 hours':3.5,'4 to 5 hours':4.5,'5 to 6 hours':5.5,'7 to 8 hours':7.5,'0 to 4 hours':2,'5 to 9 hours':7,'9 to 10 hours':9.5,'10 to 14 hours':12,'15 to 19 hours':17,'20 to 24 hours':22,'25 to 29 hours':27,'9 or more hours a week':9.5,'More than 30 hours a week':32})3) drop the ‘Timestamp’ column and dividing ‘exercise’ and ‘leisure’ values by 7 to get a daily value
3)刪除“時間戳”列,并將“運動”和“休閑”值除以7,以獲取每日值
data=data.drop('Timestamp',axis=1)#make weekly hours to daily
data['Exercise']=data['Exercise']/7
data['Leisure']=data['Leisure']/7
data.head()4) Converting sleep, study, exercise and leisure to percentages.
4)將睡眠,學習,運動和休閑轉化為百分比。
#get the hours variables
dv=data
dv=dv.drop(['Year','Gender','Being around others','Happiness score'],axis=1)#sum of rows
sumv=dv.sum(axis=1)#making it into percentages
dv['Sleep']=100*dv['Sleep']/sumv
dv['Study']=100*dv['Study']/sumv
dv['Exercise']=100*dv['Exercise']/sumv
dv['Leisure']=100*dv['Leisure']/sumv#replacing the values
data['Sleep']=dv['Sleep']
data['Study']=dv['Study']
data['Exercise']=dv['Exercise']
data['Leisure']=dv['Leisure']#looking at data
data.head()
Now that we have the data in the form that we’d like, we can start to create data visualizations. I’ve decided to focus on personality, % of hours (sleep, study, exercise and leisure) and the happiness score.
現在我們已經有了所需形式的數據,我們可以開始創建數據可視化了。 我決定專注于性格,工作時間百分比(睡眠,學習,鍛煉和休閑)和幸福感分數。
分析: (Analysis:)
Personality and happiness:
個性與幸福:
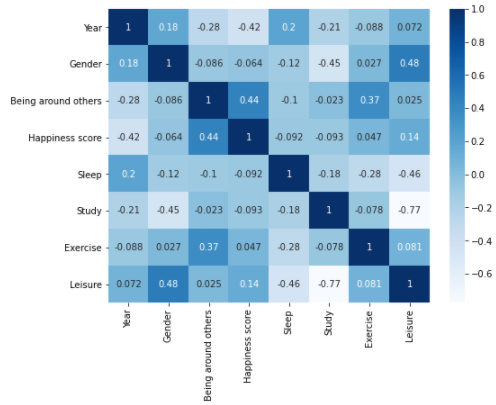
The following is the correlation heat map for those who rated themselves as being less comfortable around others (‘Being around others’<=5).
以下是針對那些自稱在其他人周圍不舒服(“在其他人周圍” <= 5)的人的相關性熱點圖。
#set size
plt.rcParams['figure.figsize'] = (8, 6)#plot data desired
d = data.loc[lambda data: data['Being around others'] <= 5]
sns.heatmap(d.corr(), cmap = 'Blues', annot = True)
plt.show()
Mean for sleep=42.11%, mean for leisure=13.98%, mean happiness score=4.92. Notice that the correlation between happiness and sleep was the highest at 0.52, correlation between happiness and leisure was -0.37.
睡眠平均值= 42.11%,休閑平均值= 13.98%,幸福分數= 4.92。 注意,幸福與睡眠之間的相關性最高,為0.52 ,幸福與休閑之間的相關性為-0.37。
Compare this to those who rated themselves as being more comfortable around others (‘Being around others’>5).
將此與那些認為自己在他人周圍更自在的人(“在他人周圍”> 5)進行比較。

Mean for sleep=45.64%, mean for leisure=15.21%, mean happiness score=6.81. The correlation between happiness and sleep was the highest at 0.24, correlation between happiness and leisure was -0.0028.
睡眠平均值= 45.64%,休閑平均值= 15.21%,幸福分數= 6.81。 幸福與睡眠的相關性最高,為0.24,幸福與休閑的相關性為-0.0028 。
Every other correlation was surprisingly negative! Although I expected sleep to have a high correlation with happiness as people may prefer to be alone, activities like leisure having a negative correlation with happiness is quite unexpected. This seems to suggest that for people who are less comfortable around others are more likely to be influenced by the amount of time they spend sleeping, while the other factors do not seem to be an important factor that influences their happiness. At the same time, spending more time on leisure appears to have a negative correlation with their happiness, though this may not be as prominent in people who rated themselves as being more comfortable with others.
其他所有相關性都令人驚訝地為負! 盡管我期望人們可能更喜歡一個人,但睡眠與幸福具有高度相關性,但休閑等活動與幸福具有負相關性卻是出乎意料的。 這似乎表明,對于那些與他人較不舒服的人,他們更可能會受到睡眠時間的影響,而其他因素似乎并不是影響他們幸福感的重要因素。 同時,花更多的時間在休閑上似乎與他們的幸福感呈負相關,盡管這在那些認為自己與他人更舒適的人中并不那么突出。
If we take a look at the mean value for exercise and leisure, it appears that more time spent on sleeping might be beneficial to those who are less comfortable around others. Perhaps a further dissection and examination on personality might grant further insights into what makes us happy. Nonetheless, it appears that perhaps happiness and personality seems to have some correlation.
如果我們看一下運動和休閑的平均值,那么似乎更多的時間在睡眠上可能對那些不太舒服的人有益。 也許對人格的進一步剖析和考察可能會給我們帶來什么使我們快樂的更多見解。 然而,似乎幸福和個性似乎之間存在某種關聯。
Sleep is a more important factor in those who are less comfortable around others compared to their counterparts.
對于那些與他人相比不那么舒服的人,睡眠是一個更重要的因素。
Balanced hours and happiness:
平衡的時間和幸福:
Next, let’s look at how spending different proportion of our time correlates with happiness scores.Balanced: all components <50%
接下來,讓我們看看度過不同時間的時間與幸福感分數如何相關。 平衡:所有組件<50%
Happiness score: mean=6.80, sd=2.00. Correlation between being around others and happiness =0.44.
幸福評分: 平均值= 6.80,標準偏差= 2.00 。 周圍人與幸福之間的相關性= 0.44 。
Unbalanced: any component ≥ 50%
不平衡:任何成分≥50%

Happiness score: mean=5.60, sd=2.80. Correlation between sleep and happiness=0.7, correlation between study and happiness=-0.4. *those who entered the unbalanced group were due to study or sleep ≥ 50%
幸福評分: 平均值= 5.60,標準偏差= 2.80。 睡眠與幸福之間的相關性= 0.7 ,學習與幸福之間的相關性= -0.4。 *進入失衡組的人是由于學習或睡眠≥50%
Looking at the mean, it appears that ensuring that we have a balanced distribution of hours across the 4 factors correlates with higher levels of happiness. However, let’s take a look at the regression line for happiness and sleep for unbalanced hours with correlation of 0.7!
從均值來看,似乎可以確保我們在這四個因素上的小時數均衡分配與更高水平的幸福感相關。 但是,讓我們看一下相關系數為0.7的幸福感和不平衡時間睡眠的回歸線!
#nbal is the data with only rows that are not balanced
x = nbal['Sleep']
y = nbal['Happiness score']
plt.plot(x, y, 'o')
m, b = np.polyfit(x, y, 1)
plt.plot(x, m*x + b)
If i look at only data of those with ‘Sleep’ ≥ 50% of hours:Happiness mean=7.17, sd=1.22Maybe we all just need a higher % of time for sleep. When I relaxed the criteria to ≥ 40%, the mean happiness score fell to 6.49. Furthermore, it appears that it’s spending >50% of our time on studying that brought down the mean (mean of those with ≥ 50% studying hours = 3.4285, sd=2.88).
如果我僅查看“睡眠”≥50%的那些人的數據:幸福平均= 7.17,sd = 1.22也許我們所有人都只需要更長的時間才能入睡。 當我將標準放寬到≥40%時,平均幸福感得分降至6.49。 此外,似乎花費了我們超過50%的時間在學習上降低了平均值(學習時間≥50%的人的平均值= 3.4285,sd = 2.88)。
Those with ≥50% of hours spent on sleep across ‘Sleep’, ‘Study’, ‘Exercise’, ‘Leisure’ had a happiness mean score of 7.17.
那些在“睡眠”,“學習”,“鍛煉”,“休閑”中花費≥50%的睡眠時間的人的幸福平均得分為7.17。
結論: (Conclusion:)
If you read all of the above, thank you so much because I spent a lot of time trying to code and getting the values I needed for analysis! Otherwise, here’s a quick summary:Question that I wanted to answer: Does the proportion of time spent on different activities influence our happiness levels?
如果您閱讀了以上所有內容,則非常感謝,因為我花了很多時間嘗試編碼并獲取分析所需的值! 否則,這里是一個簡短的摘要: 我想回答的問題:花在不同活動上的時間比例會影響我們的幸福感嗎?
Yes, it does! Students with a more balanced proportion of hours spent across activities appear to have a positive correlation with happiness levels.
是的,它確實! 學生在各項活動中花費的時間比例更均衡的情況似乎與幸福感水平呈正相關。
Findings:
發現:
1) Positive correlation between sleep and happiness throughout 2) Personality has an influence on the types of activities that correlates with our happiness (e.g sleep and leisure) 3) Those who have a more balanced spread of hours seem to be happier than those who had unbalanced hours 4) Those with ≥50% of their time, across the variables, spent on sleeping had higher mean score for happiness 5) Those with ≥50% of their time, across the variables, spent on studying had lower mean score for happiness.
1)整個過程中睡眠與幸福之間呈正相關 2) 人格對與我們的幸福相關的活動類型有影響(例如睡眠和休閑)3)時間分布更均衡的人似乎比那些快樂的人更快樂時間不平衡4)在變量中≥50%的時間花費在睡眠上的人的平均幸福分數較高 5)在變量中≥50%的時間花費在學習上的人的幸福平均分數較低 。
Rather than chasing after more sleep, or more exercise, how should we be spending our time across the board to increase our happiness?
與其追逐更多的睡眠或更多的運動,不如我們應該花很多時間來增加幸福感?
- Spend more % of our time sleeping. Sounds simple yet difficult in a competitive/work-centric environment. 花更多的時間睡覺。 在競爭/以工作為中心的環境中聽起來很簡單卻很困難。
- Alternatively, try to balance the number of hours we spent in different activities (do not spend too much time on a single activity!) 或者,嘗試平衡我們在不同活動上花費的時間(不要在單個活動上花費太多時間!)
Nonetheless, glad to have learnt a lot of python and data visualization from this mini-project and trying to milk all the information that it’s trying to tell me! Do let me know if there are other areas I could look at or your thoughts on the results! Would try to get a larger data set the next time.
但是,很高興從這個小型項目中學到了很多python和數據可視化,并嘗試提取所有試圖告訴我的信息! 請讓我知道我是否還有其他需要關注的方面或您對結果的看法! 下次將嘗試獲取更大的數據集。
翻譯自: https://towardsdatascience.com/how-should-students-spend-their-time-to-improve-their-happiness-a8bab76fb3c4
幫助學生改善學習方法
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389638.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389638.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389638.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Spring Boot 靜態資源訪問原理解析

深挖“窄帶高清”的實現原理

學習總結5 - bootstrap學習記錄1__安裝

519. 隨機翻轉矩陣

模型的搜索和優化方法綜述:

Redis 服務安裝

熊貓數據集_對熊貓數據框使用邏輯比較


ansbile--playbook劇本案例

5938. 找出數組排序后的目標下標

決策樹之前要不要處理缺失值_不要使用這樣的決策樹

說說 C 語言中的變量與算術表達式

gl3520 gl3510_帶有gl gl本機的跨平臺地理空間可視化

uiautomator +python 安卓UI自動化嘗試

5922. 統計出現過一次的公共字符串

Python+Appium尋找藍牙/wifi匹配

power bi中的切片器_在Power Bi中顯示選定的切片器

字符串匹配 sunday算法

5939. 半徑為 k 的子數組平均值
