決策樹之前要不要處理缺失值
As one of the most popular classic machine learning algorithm, the Decision Tree is much more intuitive than the others for its explainability. In one of my previous article, I have introduced the basic idea and mechanism of a Decision Tree model. It demonstrated this machine learning model using an algorithm called ID3, which is one of the most classic ones for training a Decision Tree classification model.
作為最受歡迎的經典機器學習算法之一,決策樹在可解釋性方面比其他決策樹更為直觀。 在上一篇文章中,我介紹了決策樹模型的基本概念和機制。 它演示了使用稱為ID3的算法的機器學習模型,該算法是訓練決策樹分類模型的最經典模型之一。
If you are not that familiar with Decision Tree, it is highly recommended to check out the above article before reading into this one.
如果您不熟悉決策樹,強烈建議您在閱讀本文之前先閱讀以上文章。
To intuitively understand Decision Trees, it is indeed good to start with ID3. However, it is probably not a good idea to use it in practice. In this article, I’ll introduce a commonly used algorithm to build Decision Tree models — C4.5.
為了直觀地理解決策樹,從ID3開始確實不錯。 但是,在實踐中使用它可能不是一個好主意。 在本文中,我將介紹一種用于構建決策樹模型的常用算法-C4.5。
經典ID3算法的缺點 (Drawbacks of Classic ID3 Algorithm)

Before we can demonstrate the major drawbacks of the ID3 algorithm, let’s have a look at what are the major building blocks of it. Basically, the important is the Entropy and Information Gain.
在我們證明ID3算法的主要缺點之前,讓我們看一下它的主要構成部分。 基本上,重要的是熵和信息增益。
熵回顧 (Recap of Entropy)
Here is the formula of Entropy:
這是熵的公式:
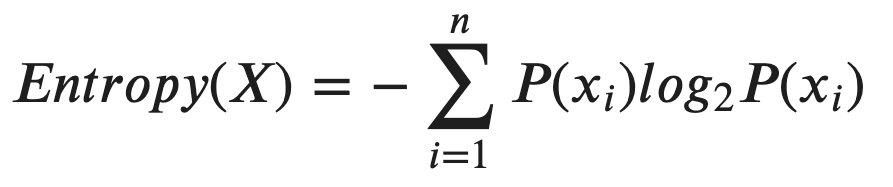
The set “X” is everything in the set of the node, and “x?” refers to the specific decision of each sample. Therefore, “P(x?)” is the probability of the set to be made with a certain decision.
集合“ X ”是節點集合中的所有內容,而“ x ”是指每個樣本的特定決策。 因此,“ P(x?) ”是通過確定的決定進行集合的概率。
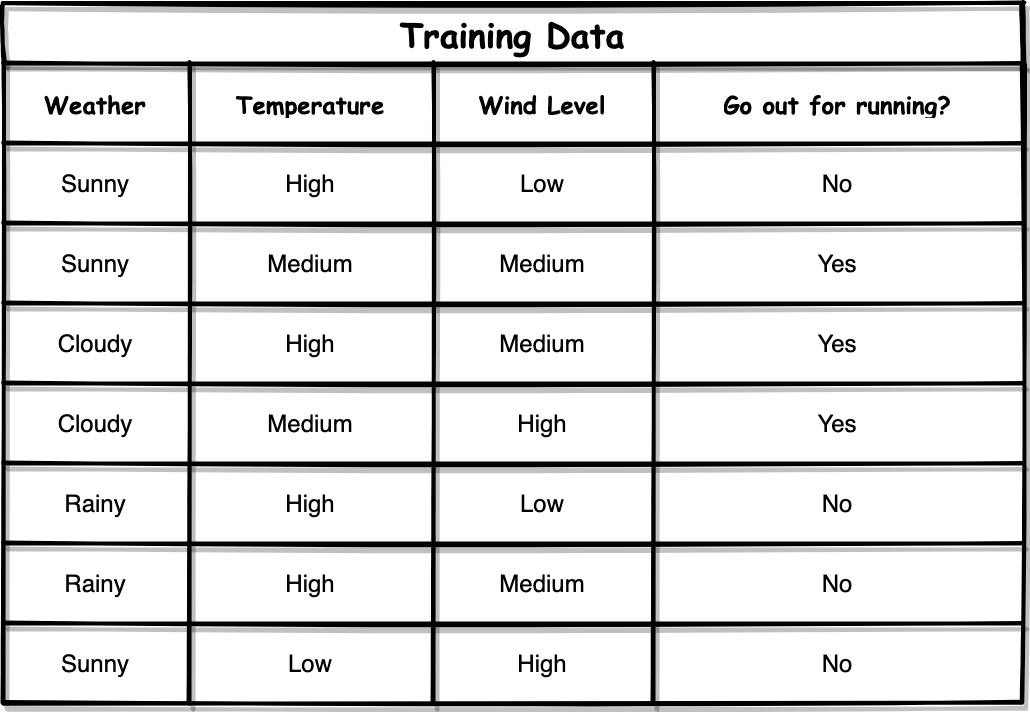
Let’s use the same training dataset as an example. Suppose that we have an internal node in our decision tree with “weather = rainy”. It is can be seen that the final decisions are both “No”. Then, we can easily calculate the entropy of this node as follows:
讓我們以相同的訓練數據集為例。 假設我們的決策樹中有一個內部節點,其“天氣=下雨天”。 可以看出,最終決定都是“否”。 然后,我們可以輕松地計算出該節點的熵,如下所示:
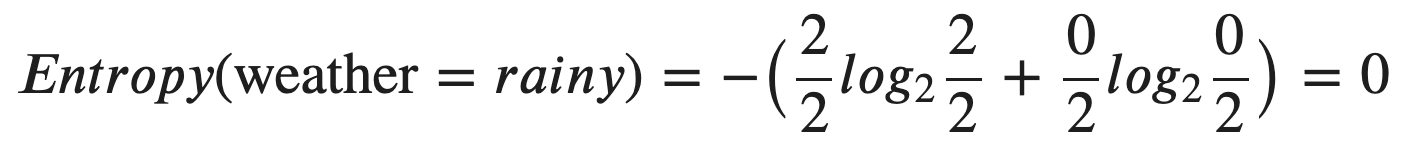
Basically, the probability of being “No” is 2/2 = 1, whereas the probability of being “Yes” is 0/2 = 0.
基本上,“否”的概率為2/2 = 1,而“是”的概率為0/2 = 0。
信息獲取回顧 (Recap of Information Gain)
On top of the concept of Entropy, we can calculate the Information Gain, which is the basic criterion to decide whether a feature should be used as a node to be split.
在熵的概念之上,我們可以計算信息增益,這是決定是否將特征用作要分割的節點的基本標準。
For example, we have three features: “Weather”, “Temperature” and “Wind Level”. When we start to build our Decision Tree using ID3, how can we decide which one of them should be used as the root node?
例如,我們具有三個功能:“天氣”,“溫度”和“風力等級”。 當我們開始使用ID3構建決策樹時,如何確定應將其中一個用作根節點?
ID3 makes use Information Gain as the criterion. The rule is that, select the feature with the maximum Information Gain among all of them. Here is the formula of calculating Information Gain:
ID3以信息增益為標準。 規則是,在所有選項中選擇具有最大信息增益的功能。 這是計算信息增益的公式:
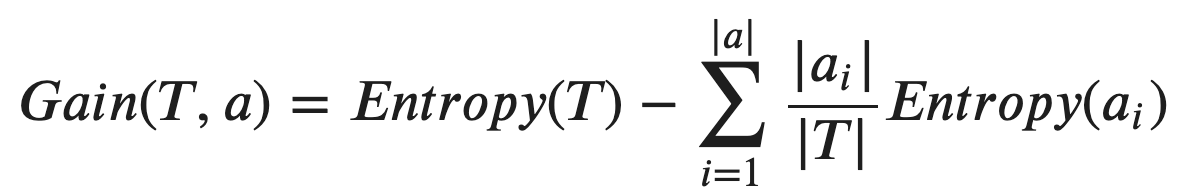
where
哪里
- “T” is the parent node and “a” is the set of attributes of “T” “ T”是父節點,“ a”是“ T”的屬性集
- The notation “|T|” means the size of the set 表示法“ | T |” 表示集合的大小
Using the same example, when we calculating the Information Gain for “Weather = Rainy”, we also need to take its child nodes’ Entropy into account. Specific derivation and calculating progress can be found in the article that was shared in the introduction.
使用相同的示例,當我們計算“天氣=多雨”的信息增益時,我們還需要考慮其子節點的熵。 在引言中共享的文章中可以找到特定的推導和計算進度。
使用信息增益的主要缺點 (Major Drawbacks of Using Information Gain)
The major drawbacks of using Information Gain as the criterion for determining which feature to be used as the root/next node is that it tends to use the feature that has more unique values.
使用信息增益作為確定哪個特征用作根/下一個節點的標準的主要缺點是,它傾向于使用具有更多唯一值的特征。
But why? Let me demonstrate it using an extreme scenario. Let’s say, we have got the training set with one more feature: “Date”.
但為什么? 讓我用一個極端的場景來演示它。 假設,我們為培訓設置了另一個功能:“日期”。
You might say that the feature “Date” should not be considered in this case because it intuitively will not be helpful to decide whether we should go out for running or not. Yes, you’re right. However, practically, we may have much more complicated dataset to be classified, and we may not be able to understand all the features. So, we may not always be able to determine whether a feature does make sense or not. In here, I will just use “Date” as an example.
您可能會說在這種情況下不應考慮“日期”功能,因為它從直覺上對決定我們是否應該運行不起作用沒有幫助。 你是對的。 但是,實際上,我們可能要分類的數據集要復雜得多,并且我們可能無法理解所有功能。 因此,我們可能無法始終確定某個功能是否有意義。 在這里,我僅以“日期”為例。
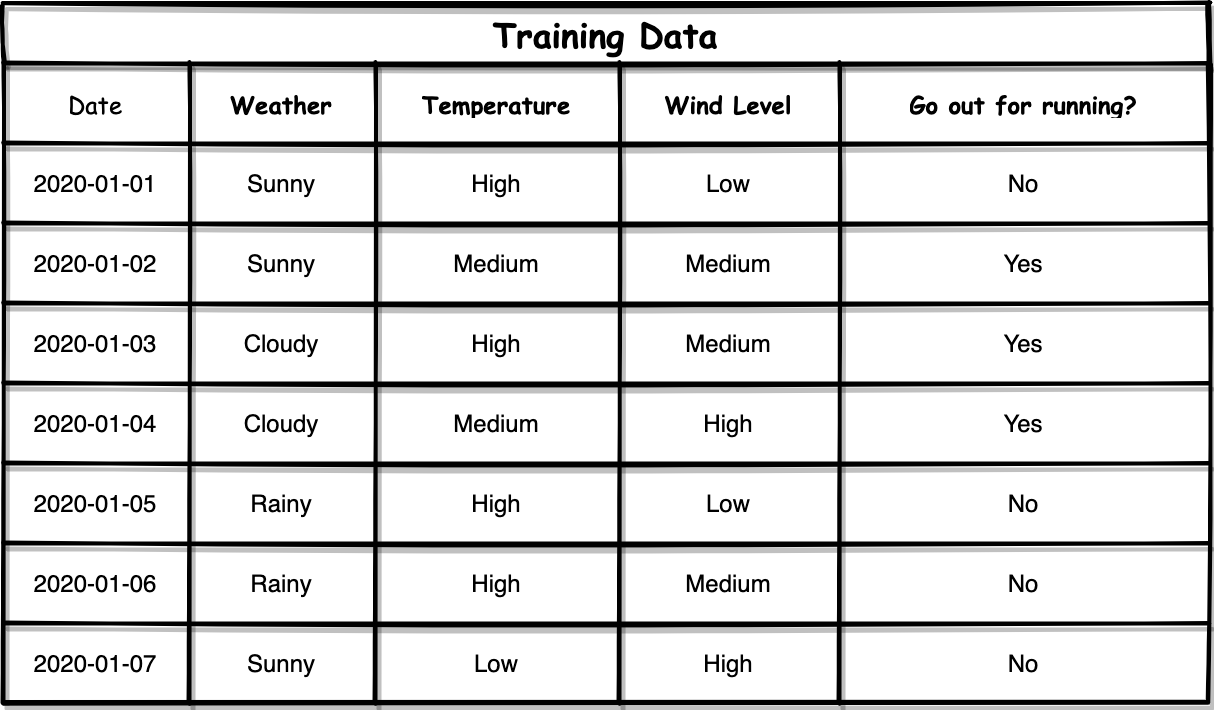
Now, let’s calculate the Information Gain for “Date”. We can start to calculate the entropy for one of the dates, such as “2020–01–01”.
現在,讓我們計算“日期”的信息增益。 我們可以開始計算其中一個日期的熵,例如“ 2020-01-01”。
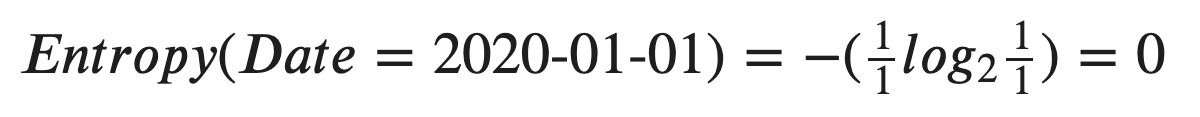
Since there is only 1 row for each date, the final decision must be either “Yes” or “No”. So, the entropy must be 0! In terms of the information theory, it is equivalent to say:
由于每個日期只有一行,因此最終決定必須為“是”或“否”。 因此,熵必須為0! 就信息論而言,它等同于說:
The date tells us nothing, because the result is just one, which is certain. So, there is no “uncertainty” at all.
日期沒有告??訴我們任何信息,因為結果只是一個,可以肯定。 因此,根本沒有“不確定性”。
Similarly, for all the other dates, their entropies are 0, too.
同樣,對于所有其他日期,它們的熵也為0。
Now, let’s calculate the entropy for the date itself.
現在,讓我們計算日期本身的熵。
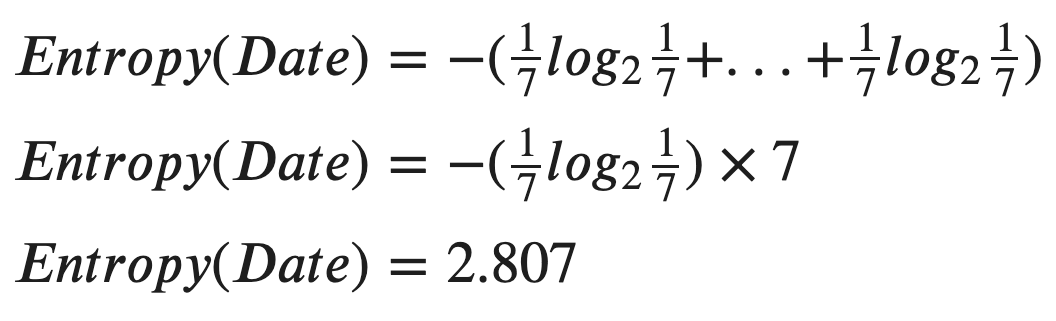
WoW, that is a pretty large number compared to the other features. So, we can calculate the Information Gain of “Date” now.
哇,與其他功能相比,這是一個很大的數目。 因此,我們現在可以計算“日期”的信息增益。
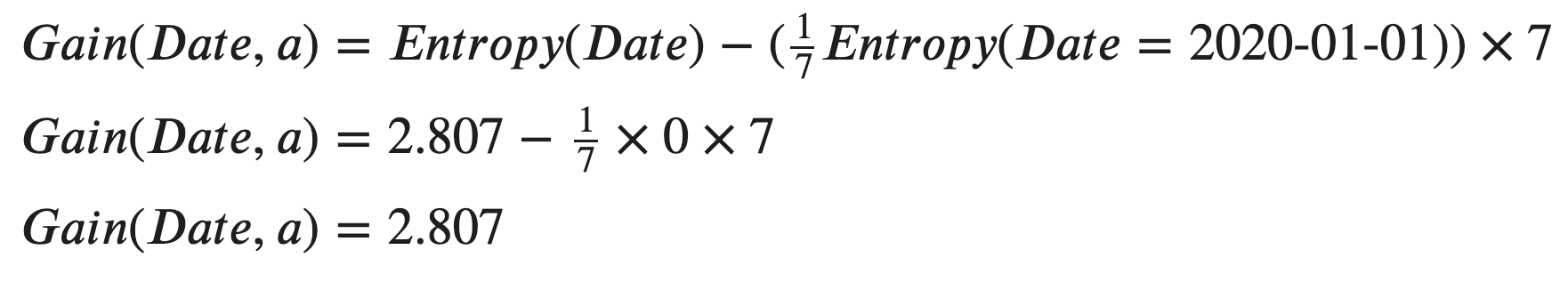
Unsurprisingly, the Information Gain of “Date” is the entropy of itself because all its attribute having entropies that are 0.
毫不奇怪,“日期”的信息增益是其自身的熵,因為其所有屬性的熵均為0。
If we calculate the Information Gain for the other three features (you can find details in the article that is linked in the introduction), they are:
如果我們計算其他三個功能的信息增益(您可以在簡介中鏈接的文章中找到詳細信息),則它們是:
- Information Gain of Weather is 0.592 信息的天氣增益為0.592
- Information Gain of Temperature is 0.522 信息的溫度增益為0.522
- Information Gain of Wind Level is 0.306 風信息增益為0.306
Obviously, the Information Gain of Date is overwhelmingly larger than the others. Also, it can be seen that it will be even larger if the training dataset is larger. After that, don’t forget that the feature “Date” actually does not make sense in deciding whether we should go out for running or not, but it is decided as the “Best” one to be the root node.
顯然,最新的信息獲取比其他的要大得多。 另外,可以看出,如果訓練數據集更大,則該范圍將更大。 此后,請不要忘記,“日期”功能在決定是否應該運行時實際上沒有意義,而是被確定為“最佳”根節點。
Even funnier, after we decided to use “Date” as our root node, we’re done :)
更有趣的是,在我們決定使用“ Date”作為根節點之后,我們就完成了:)
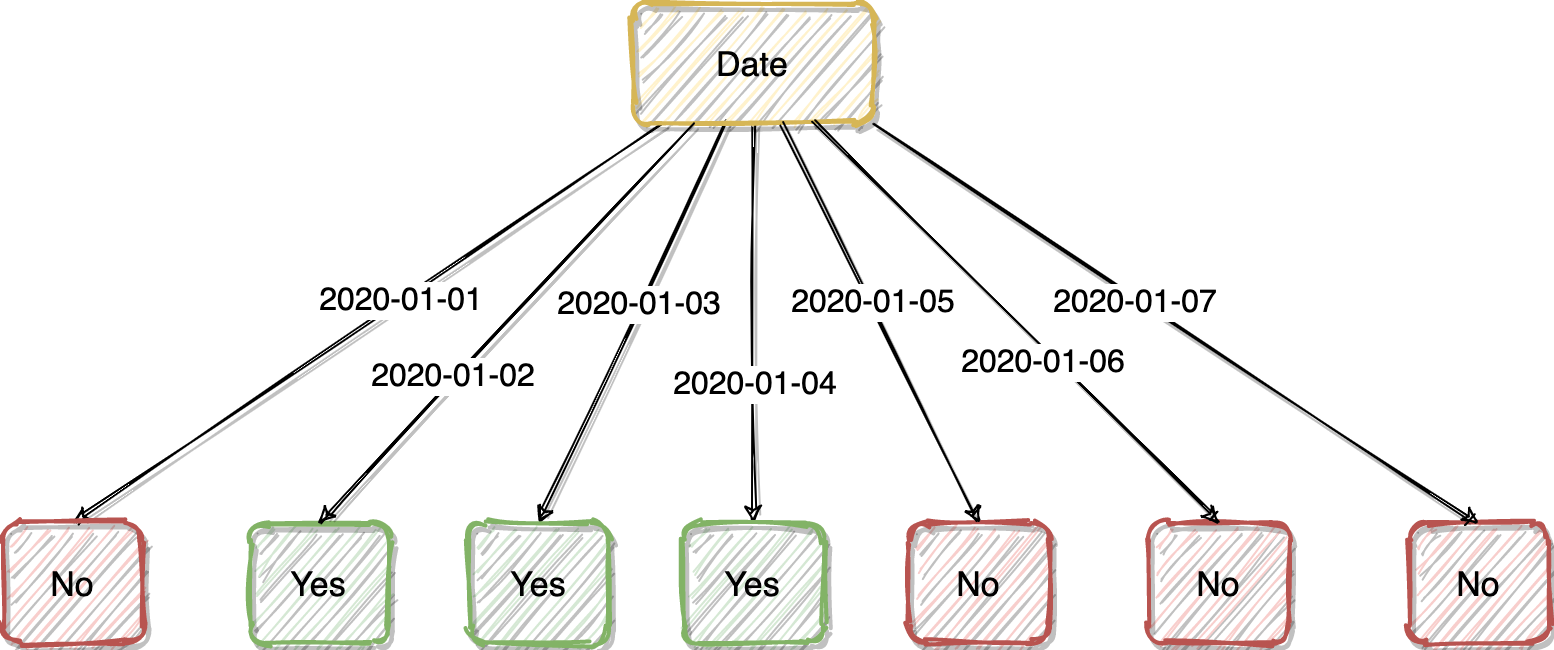
We end up with a Decision Tree as shown above. This is because the feature “Date” is too good. If we use it as the root node, all its attributes will simply tell us whether we should go out for running or not. It is not necessary to have the other features.
我們最終得到了如上所示的決策樹。 這是因為功能“日期”太好了。 如果我們將其用作根節點,則其所有屬性將簡單地告訴我們是否應該運行。 不必具有其他功能。

Yes, you may have a face like this fish at the moment, so do I.
是的,您現在可能有一張像這樣的魚的臉,我也是。
解決信息增益限制 (Fix the Information Gain Limitation)

The easiest fix of the Information Gain limitation that exists in ID3 Algorithm is from another Decision Tree algorithm called C4.5. The basic idea of reducing this issue is to use Information Gain Ratio rather than Information Gain.
ID3算法中存在的信息增益限制的最簡單解決方法來自另一種稱為C4.5的決策樹算法。 減少此問題的基本思想是使用信息增益比而不是信息增益。
Specifically, Information Gain Ratio is simply adding a penalty on the Information Gain by dividing with the entropy of the parent node.
具體而言,信息增益比只是通過除以父節點的熵來對信息增益添加懲罰。
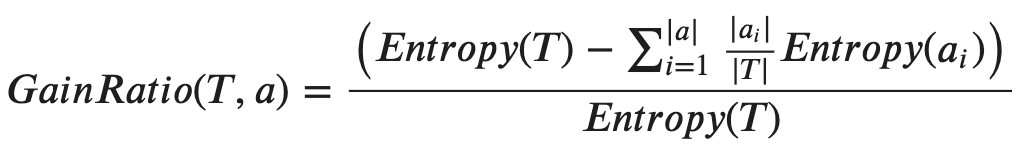
In other words,
換一種說法,
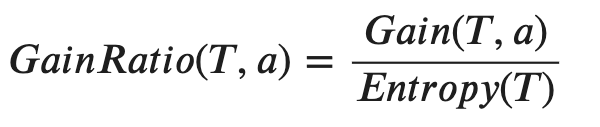
Therefore, if we’re using C4.5 rather than ID3, the Information Gain Ratio of the feature “Date” will be as follows.
因此,如果我們使用的是C4.5而不是ID3,則“日期”功能的信息增益比如下。
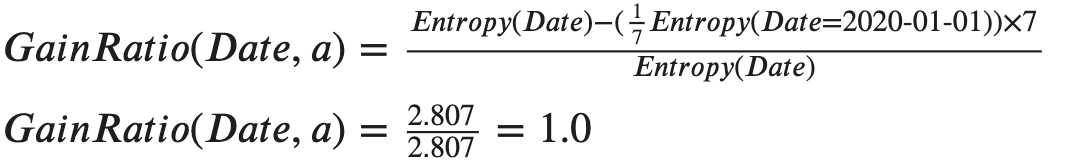
Well, it is indeed still the largest one compared to the other features, but don’t forget that we are really using an extreme example where each attribute value of the feature “Date” will have only one row. In practice, Information Gain Ratio will be quite enough to avoid most of the scenarios that Information Gain will cause bias.
嗯,與其他功能相比,它確實仍然是最大的功能,但是請不要忘記,我們確實使用了一個極端的示例,其中“ Date”功能的每個屬性值將只有一行。 實際上,信息增益比率將足以避免大多數情況下信息增益會引起偏差。
C4.5的其他改進 (Other Improvements of C4.5)

In my opinion, using Information Gain Ratio is the most significant improvement from ID3 to C4.5. Nevertheless, there are more improvements in C4.5 that you should know.
我認為,使用信息增益比率是從ID3到C4.5的最大改進。 但是,您應該知道C4.5還有更多改進。
PEP(悲觀錯誤修剪) (PEP (Pessimistic Error Pruning))
If you are not familiar with the concept “Pruning” of Decision Tree, again, you may need to check out my previous article that is attached in the introduction of this article.
如果您不熟悉決策樹的“修剪”概念,則可能需要查看本文簡介中附帶的我以前的文章。
PEP is another significant improvement in C4.5. Specifically, it will prune the tree in a top-down manner. For every internal node, the algorithm will calculate its error rate. Then, try to prune this branch to compare the error rate before and after the pruning. So, it is decided whether we should reserve this branch.
PEP是C4.5的另一個重大改進。 具體來說,它將以自頂向下的方式修剪樹。 對于每個內部節點,算法將計算其錯誤率。 然后,嘗試修剪此分支以比較修剪前后的錯誤率。 因此,決定是否應保留此分支。
Some characteristics of PEP:
PEP的一些特征:
- It is one of the Post-Pruning methods. 它是修剪后的方法之一。
- It prunes the tree without the dependency of a validation dataset. 它修剪樹而不依賴驗證數據集。
- Usually quite good to avoid overfitting, and consequently improve the performance in classifying unknown data. 通常很好避免過度擬合,因此提高了對未知數據進行分類的性能。
離散連續特征 (Discretising the Continuous Features)
C4.5 supports continuous values. So, we are not limited to have “Low”, “Medium” and “High” such categorical values. Instead, C4.5 will automatically detect the thresholds of the continuous value that can generate the maximum Information Gain Ratio and then split the node using this threshold.
C4.5支持連續值。 因此,我們不限于具有“低”,“中”和“高”這樣的分類值。 取而代之的是,C4.5將自動檢測可產生最大信息增益比的連續值的閾值,然后使用該閾值拆分節點。
摘要 (Summary)

In this article, I have illustrated why ID3 is not ideal. The major reason is that the criterion it uses — Information Gain — might significantly bias to those features have larger numbers of distinct values.
在本文中,我已說明了為什么ID3不理想。 主要原因是它使用的標準-信息增益-可能會嚴重偏向那些具有大量不同值的功能。
The solution has been given in another Decision Tree algorithm called C4.5. It evolves the Information Gain to Information Gain Ratio that will reduce the impact of large numbers of distinct values of the attributes.
該解決方案已在另一種稱為C4.5的決策樹算法中給出。 它改進了信息增益與信息增益之比,從而減少了屬性的大量不同值的影響。
Again, if you feel that you need more context and basic knowledge about Decision Trees, please check out my previous article.
同樣,如果您覺得需要更多有關決策樹的知識和基礎知識,請查閱我以前的文章。
翻譯自: https://towardsdatascience.com/do-not-use-decision-tree-like-this-369769d6104d
決策樹之前要不要處理缺失值
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389627.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389627.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389627.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

說說 C 語言中的變量與算術表達式

gl3520 gl3510_帶有gl gl本機的跨平臺地理空間可視化

uiautomator +python 安卓UI自動化嘗試

5922. 統計出現過一次的公共字符串

Python+Appium尋找藍牙/wifi匹配

power bi中的切片器_在Power Bi中顯示選定的切片器

字符串匹配 sunday算法

5939. 半徑為 k 的子數組平均值

Adobe After Effects CS6 操作記錄

數據庫邏輯刪除的sql語句_通過數據庫的眼睛查詢sql的邏輯流程


5940. 從數組中移除最大值和最小值

BZOJ4127Abs——樹鏈剖分+線段樹

數據挖掘流程_數據流挖掘

北門外的小吃街才是我的大學食堂

786. 第 K 個最小的素數分數
![[LeetCode]最長公共前綴(Longest Common Prefix)](http://pic.xiahunao.cn/[LeetCode]最長公共前綴(Longest Common Prefix))
[LeetCode]最長公共前綴(Longest Common Prefix)

域嵌套太深_pyspark如何修改嵌套結構域

