批歸一化層-BN層(Batch Normalization)
作用及影響:
直接作用:對輸入BN層的張量進行數值歸一化,使其成為均值為零,方差為一的張量。
帶來影響:
1.使得網絡更加穩定,結果不容易受到一些超參數的影響。
2.對于深層網絡,減少梯度消失或爆炸的可能。
3.使網絡每一層輸出結果穩定,進而加快了模型訓練的速度。
算法思想:

例如:
輸入x(i) = [1, 2, 3, 4, 5],平均值μ = 3(全局平均值) , 方差σ = 2(全局方差) ,計算公式x(i) = (x(i) - μ)/σ
→x(i) = [-1, -0.5, 0, 0.5, 1] (得到的是第i行x結果)
再用x(i)×W(權重)+b(偏差值)→y(i) (得到的是第i行y結果)
最后輸出y
Pytorch框架中的代碼實現
默認權重初始值,且不考慮偏差值b
import torch
import torch.nn as nn
import numpy as np"""
基于pytorch的網絡編寫
測試BN層
權重w為默認初始化
偏差值b=0
"""
x=torch.randn(2,10)
#x為隨機輸入。第一維是batch_size,第二維是輸入維度,這個輸入就相當于2個10維向量的矩陣
bn = torch.nn.BatchNorm1d(10)
#定義bn層,參數要與輸入的維度一致,這個維度與batch_size是無關的
print(bn.state_dict())
print(bn(x))
自定義框架中的代碼實現(受到一位兄弟的啟迪)
#weight = torch.randn(bn.state_dict()["weight"].shape)
#由于默認的bn初始化weight參數都為1,所以容易看不出最后scale的作用,這里隨機生成一個新的權重代替初始權重
#去掉這兩行當然也應當獲得一致的結果,這里相當于增加一點難度
weight = bn.state_dict()["weight"]
bn.weight = torch.nn.Parameter(weight)
#原始的初始化權重,是[1,1,1,1...],為了方便對比我們這里還是繼承初始化權重,如果需要自己設置權重可參考前面3行注釋
#取出參數
w = bn.state_dict()["weight"].numpy()
b = bn.state_dict()["bias"].numpy()
#將輸入轉成numpy數組
x = x.numpy()
#計算均值,注意是沿batch_size的維度進行均值計算
p = np.mean(x, axis=0)
#按照公式計算var
v = np.mean(np.square(x - p), axis=0)
#按照公式計算,這里e=1e-5是為了防止分母為零,查看torch源碼可以找到,torch中的e也等于1e-5
x = (x - p) / np.sqrt(v + 1e-5)
#最后的scale線性運算
y = w * x + b #偏差值b=0
print(y, "自定義bn輸出")
輸出結果對比:
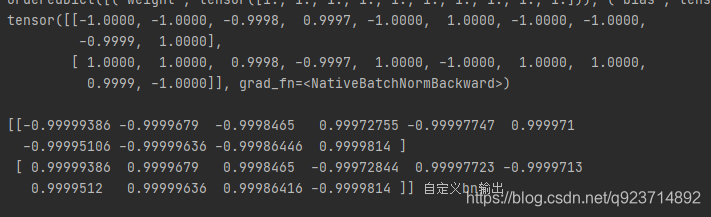
在tensor中會四舍五入保留四位小數,通過對比也可以發現結果是一樣的。






方法源碼解析(二))
)

python在anaconda安裝opencv庫及skimage庫(scikit_image庫)諸多問題解決辦法)



)

![歸 [拾葉集]](http://pic.xiahunao.cn/歸 [拾葉集])

與下采樣(縮小圖像))

